import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
seoul_response = openai.Embedding.create(
model="text-embedding-ada-002",
input="대한민국 수도는 서울입니다.",
)
seoul_embedding = seoul_response["data"][0]['embedding']
print(f'벡터길이: {len(seoul_embedding)}')
#> 벡터길이: 1536
print(f'벡터 일부: {seoul_embedding[:10]}')
#> 벡터 일부: [0.014582998119294643, -0.018063032999634743, 0.004872684367001057, -0.013805408962070942, -0.031180081889033318, 0.025176068767905235, -0.034519895911216736, 0.011357911862432957, -0.007960736751556396, -0.0020682618487626314]1 ChatGPT
ChatGPT는 간단히 말해 생성형 사전 학습된 트랜스포머(Generative Pre-trained Transformer)의 약자로, OpenAI의 GPT-3/GPT-4 거대 언어 모델 제품군에 기반한 챗봇으로 지도학습과 강화학습기법을 적용하여 미세조정(fine-tuned)된 제품이자 서비스다.
1.1 GPT-4
GPT-4는 GPT-3보다 10배 많은 1조 8천억 개의 파라미터, 120개 계층을 갖는 아키텍쳐를 갖고 있다. OpenAI는 16개 전문가(MoE, Mixture of Experts)와 1,100억 개의 다층 퍼셉트론 파라미터를 갖는 전문가 혼합 모델로 구현되었으며, 13조 개의 토큰이 포함된 학습 데이터셋을 사용했다. 훈련 비용은 3,200 ~ 6,300만 달러로 GPT-4는 이전 버전보다 추론 비용이 약 3배 더 높지만, 분산 데이터센터에서 128개 GPU 클러스터 위에서 동작하는 추론 아키텍쳐를 갖고 있다.
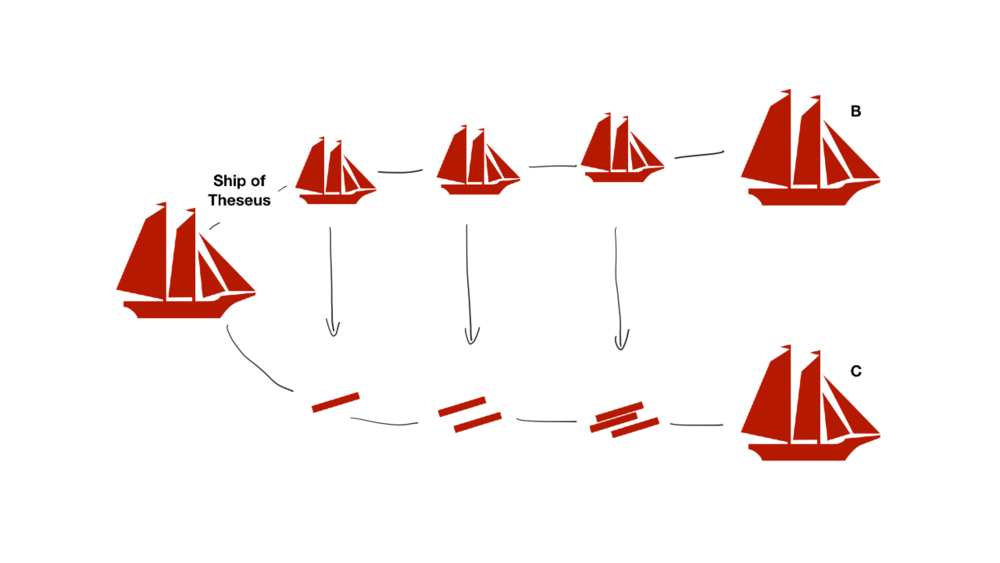
OpenAI의 전략은 테세우스의 배(Theseus’s Ship) 와 유사하다고 볼 수 있다.
1.2 GPT-3
OpenAI GPT-3 모형은 크게 세가지가 있다.
- GPT-3/GPT-4
- Codex
- 콘텐츠 필터 모델
GPT-3은 자연어 처리 및 생성을 담당하는 모델로 인간의 언어 즉, 자연어처럼 보이는 텍스트를 이해할 수 있다. 한걸음 더 들어가면 속도와 성능에 따라 4가지 모델(A, B, C, D)로 구분된다.
- text-davinci-003
- text-curie-001
- text-babbage-001
- text-ada-001
성능기준으로 보면 다음과 같이 정렬할 수 있는데 비용도 그에 따라 높아진다는 의미도 함축한다.
text-davinci-003 > text-curie-001 > text-babbage-001 > text-ada-001
따라서, OpenAI는 다빈치 모델(text-davinci-003)을 통해 원하는 결과를 얻은 후에 다른 모델을 사용해 볼 것을 권장하는데 이유는 훨씬 저렴한 비용으로 많은 수의 유사한 작업을 수행할 수 있기 때문이다.
1.2.1 text-ada-001
2,048개의 토큰 및 2019년 10월까지의 데이터 학습하여 이후 모형과 비교하여 정확도나 성능에서 다소 밀리는 모습이지만 최적화를 통해 매우 빠르고 비용이 가장 저렴하다.
1.2.2 text-babbage-001
2,048개의 토큰과 2019년 10월까지의 데이터 학습되었고 간단한 분류와 의미론적 분류에 효과적이다.
1.2.3 text-curie-001
최대 2048개의 토큰을 지원하며 text-davinci-003 다음으로 뛰어난 성능을 보이는 GPT-3 모델이다. 2019년 10월까지의 데이터로 학습되었기 때문에 text-davinci-003보다 정확도가 떨어지지만, 번역, 복잡한 분류, 텍스트 분석 및 요약에 좋은 성능을 보이고 있어 text-davinci-003와 비교하여 가성비가 높다고 평가되고 있다.
1.2.4 text-davinci-003
2021년 9월까지의 데이터로 훈련되었기 때문에 최신 정보를 제공하지 못한다는 한계는 있지만, 앞선 GPT-3 모형과 비교하여 더 높은 품질을 제공한다. 장점 중 하나는 최대 4,000개 토큰까지 요청할 수 있다는 점이 이전 모형과 큰 차별점이 된다.
1.3 코덱스(Codex)
코덱스는 프로그래밍 코드 이해 및 생성을 위한 것으로 code-davinci-002와 code-cushman-001가 있다. 또한, 코덱스는 GitHub Copilot을 구동하는 모델이기도 하다. 파이썬, 자바스크립트, 고, 펄, PHP, 루비, 스위프트, 타입스크립트, SQL, 셸 등 12개 이상의 프로그래밍 언어를 지원할 뿐만 아니라 자연어로 표현된 주석(comment)를 이해하고 사용자를 대신하여 요청된 작업을 수행할 수 있다.
1.3.1 code-cushman-001
복잡한 작업을 수행하는 데 있어서는 code-davinci-002가 더 강력하지만, 많은 코드 생성 작업을 수행할 수 있고 code-davinci-002 보다 더 빠르고 저렴하다는 장점이 있다.
1.3.2 code-davinci-002
자연어를 코드로 번역하는 데 탁월할 뿐만 아니라 코드를 자동 완성할 뿐만 아니라 보충 요소 삽입도 지원한다. 최대 8,000개의 토큰을 처리할 수 있으며 2021년 6월까지의 데이터로 학습되었다.
1.4 콘텐츠 필터
민감한 콘텐츠 제거하기 위한 필터 모형이다. 민감하거나 안전하지 않을 수 있는 API 생성 텍스트를 감지할 수 있다. 사용자가 사용할 AI 응용프로그램을 개발할 경우, 필터를 사용하여 모델이 부적절한 콘텐츠를 반환하는지 감지할 수 있다. 이 필터는 텍스트를 다음 3가지 범주로 나눈다.
- 안전(safe)
- 민감(sensitive)
- 안전하지 않음(unsafe)
2 임베딩
임베딩(Embedding) 일반적으로 실수 벡터의 형태로 텍스트 데이터를 수치로 표현한 것으로, 이를 통해서 표현된 벡터는 연속적인 벡터 공간에서 텍스트 데이터에 내재된 의미(semantic)를 포착한다.
실용적인 관점에서 임베딩은 실제 객체와 관계를 벡터로 표현하는 방식이다. 동일한 벡터 공간을 사용하여 두 사물이 얼마나 유사한지 측정하는 데 사용한다.
2.1 텍스트 벡터 표현
text-embedding-ada-002 모델은 빠르고 가성비가 뛰어난 임베딩 모델이다. “대한민국 수도는 서울입니다.” 이라는 문서를 벡터로 표현하면 다음과 같다. 즉, 1,536 차원을 갖는 공간에 하나의 점으로 표현될 수 있다.
마찬가지로 일본의 수도 도쿄도 벡터로 표현할 수 있다.
tokyo_response = openai.Embedding.create(
model="text-embedding-ada-002",
input="일본 수도는 동경입니다.",
)
tokyo_embedding = tokyo_response["data"][0]['embedding']
print(f'벡터길이: {len(tokyo_embedding)}')
#> 벡터길이: 1536
print(f'벡터 일부: {tokyo_embedding[:10]}')
#> 벡터 일부: [0.010957648046314716, -0.013234060257673264, 0.009729413315653801, -0.011890077032148838, -0.03179261088371277, 0.03436483070254326, -0.029786281287670135, 0.008629790507256985, 0.01711810939013958, -0.0014733985299244523]3 OpenAI, 챗GPT, OpenAI API
OpenAI, 챗GPT(ChatGPT), OpenAI API를 명확히 구분하는 것이 필요하다.
- OpenAI: 회사명
- 챗GPT(ChatGPT): AI 응용프로그램 (AI 챗팅 서비스)
- OpenAI API: OpenAI 인공지능 모형을 활용하는 API 서비스
3.1 인터페이스
OpenAI API는 OpenAI에서 개발한 GPT-3, GPT-4 모델을 통해 AI 기능을 개발하고 있는 다양한 제품과 서비스에 담아내는 과정이다. 제품과 서비스를 개발하면서 머리 뿐만 아니라 다른 다양한 재료도 데이터, API 혹은 파일 형태로 담아낼 수 있다.
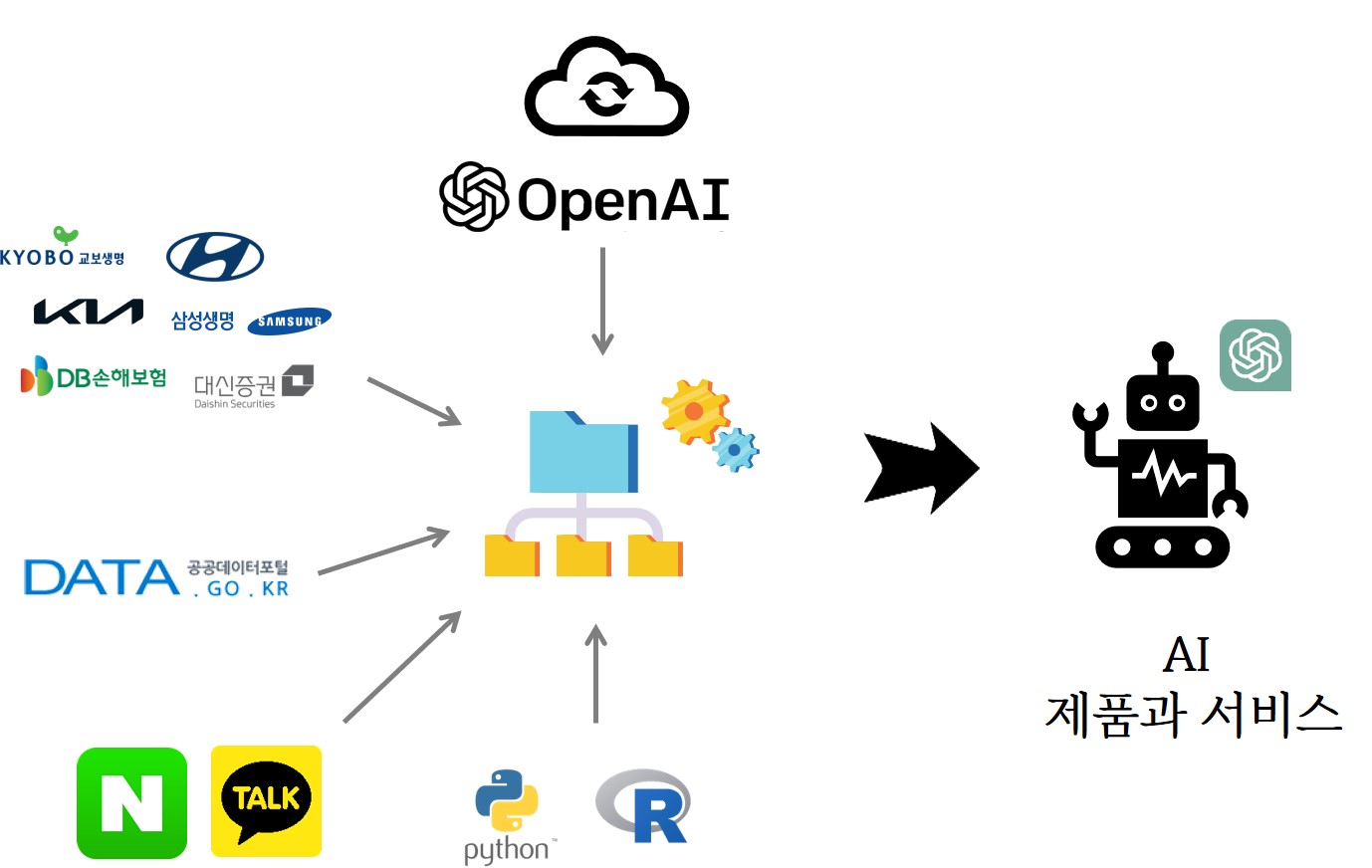
3.2 고려사항
OpenAI는 3월에 채팅 완료(Chat Completion) API를 도입했으며, 현재 API GPT 사용량의 97%를 차지하고 있다.
2020년 6월에 도입된 초기 Completion API는 언어 모델과 상호 작용할 수 있는 자유형 텍스트 프롬프트를 제공하기 위해 도입되었다. 이후 보다 구조화된 프롬프트 인터페이스(structured prompt interface)를 통해 더 나은 결과를 제공할 수 있다는 사실을 알게 되었다. 채팅 기반 패러다임은 이전의 사용 사례와 새로운 대화 요구 사항의 대부분을 처리하는 동시에 더 높은 유연성과 구체성을 제공하는 강력한 것으로 입증되었다. 특히 채팅 완료 API의 구조화된 인터페이스(예: 시스템 메시지, 함수 호출)와 멀티턴(Multi-turn) 대화 기능을 통해 개발자는 대화 환경과 광범위한 완료 작업을 구축할 수 있다.
| 구분 | 이전 모형 | 신 모형 |
|---|---|---|
| Chat Completion API | gpt-3.5-turbo | gpt-3.5-turbo |
| Completion API | ada | ada-002 |
| Completion API | babbage | babbage-002 |
| Completion API | curie | curie-002 |
| Completion API | davinci | davinci-002 |
| Completion API | davinci-instruct-beta | gpt-3.5-turbo-instruct |
| Completion API | curie-instruct-beta | gpt-3.5-turbo-instruct |
| Completion API | text-ada-001 | gpt-3.5-turbo-instruct |
| Completion API | text-babbage-001 | gpt-3.5-turbo-instruct |
| Completion API | text-curie-001 | gpt-3.5-turbo-instruct |
| Completion API | text-davinci-001 | gpt-3.5-turbo-instruct |
| Completion API | text-davinci-002 | gpt-3.5-turbo-instruct |
| Completion API | text-davinci-003 | gpt-3.5-turbo-instruct |
| Embeddings Model | code-search-ada-code-001 | text-embedding-ada-002 |
| Embeddings Model | code-search-ada-text-001 | text-embedding-ada-002 |
| Embeddings Model | code-search-babbage-code-001 | text-embedding-ada-002 |
| Embeddings Model | code-search-babbage-text-001 | text-embedding-ada-002 |
| Embeddings Model | text-search-ada-doc-001 | text-embedding-ada-002 |
| Embeddings Model | text-search-ada-query-001 | text-embedding-ada-002 |
| Embeddings Model | text-search-babbage-doc-001 | text-embedding-ada-002 |
| Embeddings Model | text-search-babbage-query-001 | text-embedding-ada-002 |
| Embeddings Model | text-search-curie-doc-001 | text-embedding-ada-002 |
| Embeddings Model | text-search-curie-query-001 | text-embedding-ada-002 |
| Embeddings Model | text-search-davinci-doc-001 | text-embedding-ada-002 |
| Embeddings Model | text-search-davinci-query-001 | text-embedding-ada-002 |
| Embeddings Model | text-similarity-ada-001 | text-embedding-ada-002 |
| Embeddings Model | text-similarity-babbage-001 | text-embedding-ada-002 |
| Embeddings Model | text-similarity-curie-001 | text-embedding-ada-002 |
| Embeddings Model | text-similarity-davinci-001 | text-embedding-ada-002 |
3.3 API
OpenAI는 크게 3가지 서비스를 제공하고 있다.
API 문서를 통해 다양한 API 서비스를 확인할 수 있다.
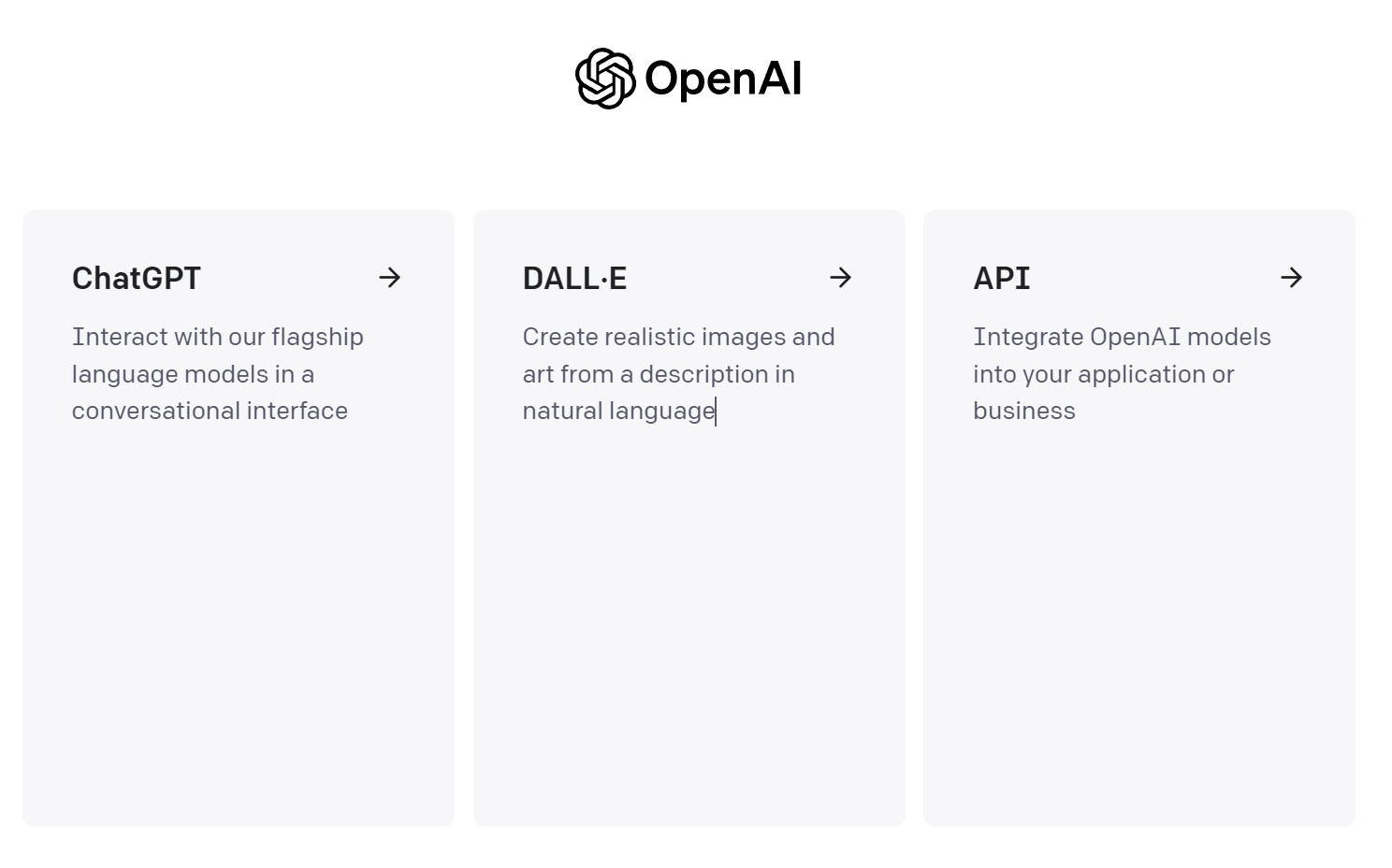
4 도구
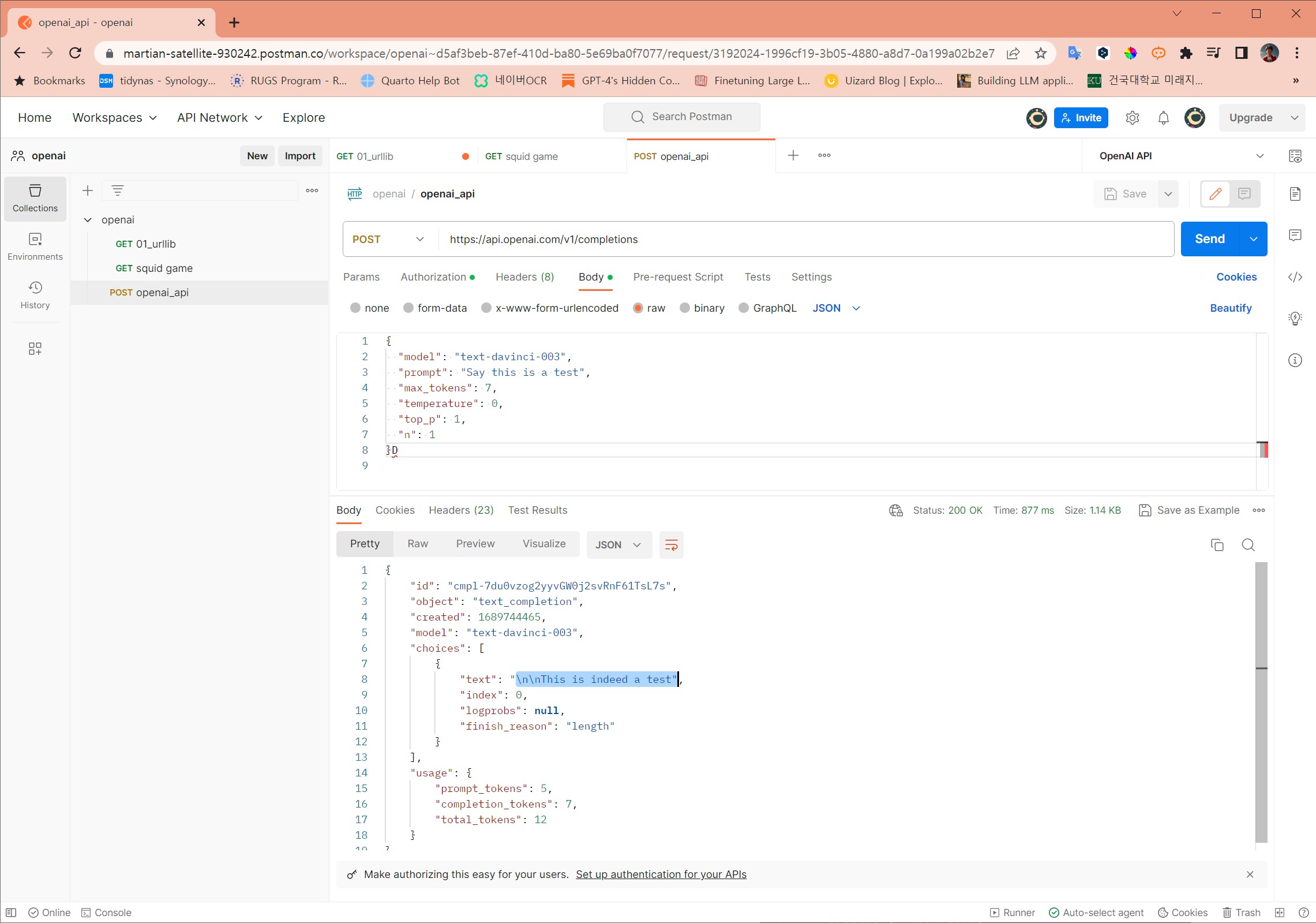
Postman을 사용하여 실제 AI 제품 및 서비스 개발이 들어가기 전에 기능을 확인한다.
-
GET: 펭귄 csv 파일으로 바로 다운로드 받을 수 있다. -
GET+ Params: API-KEY를 매개변수로 전달하여 “오징어 게임” JSON 데이터를 가져올 수 있다. -
POST+ API-KEY: 인증(Authorization) 과정을 거쳐 챗 완성(Chat Completion) 기능을 작성한 프롬프트를 전송하여 GPT-3.5 모델로부터 받아올 수 있다.
5 OpenAI API 헬로월드
OpenAI 회사가 제시하고 있는 기준에 맞춰 따라줘야 OpenAI API를 사용할 수 있다. 이를 위해 먼저 회원가입을 통한 계정을 생성하고 본인 인증과 과금을 위한 API KEY를 생성하고 프로그래밍 언어에서 쉽게 사용할 수 있도록 파이썬의 경우 openai 패키지를 설치하고 문법에 맞춰 코드를 작성하면 된다.
OpenAI API 생성 웹사이트에서 계정을 생성한다.
API keys 웹사이트에서 API KEY를 발급받는다.
API Reference 안내에 따라 openai 패키지를 설치한다.
$ pip install openaiAPI키를 직접 파이썬 프로그램에 명시하고 결과를 확인한다.
import openai
openai.api_key = "sk-xxxxxxxxxxxxxxxxxxxxxxxxxx"
response = openai.Completion.create(
model="text-davinci-003",
prompt="OpenAI API가 뭔가요?"
)
print(response){
"choices": [
{
"finish_reason": "length",
"index": 0,
"logprobs": null,
"text": "\n\nOpenAI API\ub294 \uc778\uacf5"
}
],
"created": 1689745304,
"id": "cmpl-7duESieoaT985f4IKPskfcYQ3AH7F",
"model": "text-davinci-003",
"object": "text_completion",
"usage": {
"completion_tokens": 14,
"prompt_tokens": 15,
"total_tokens": 29
}
}import requests
from dotenv import load_dotenv
import os
load_dotenv()
#> True
openai.api_key = os.getenv('OPENAI_API_KEY')
response = openai.Completion.create(
model="text-davinci-003",
prompt="OpenAI API가 뭔가요?"
)
print(response["choices"][0]['text'])OpenAI API는 OpenAI가