graph TD
A[요구사항] --> B[아키텍쳐/디자인]
B --> C[구현]
C --> D[검증/테스트]
D --> E[유지보수]
1 작업흐름
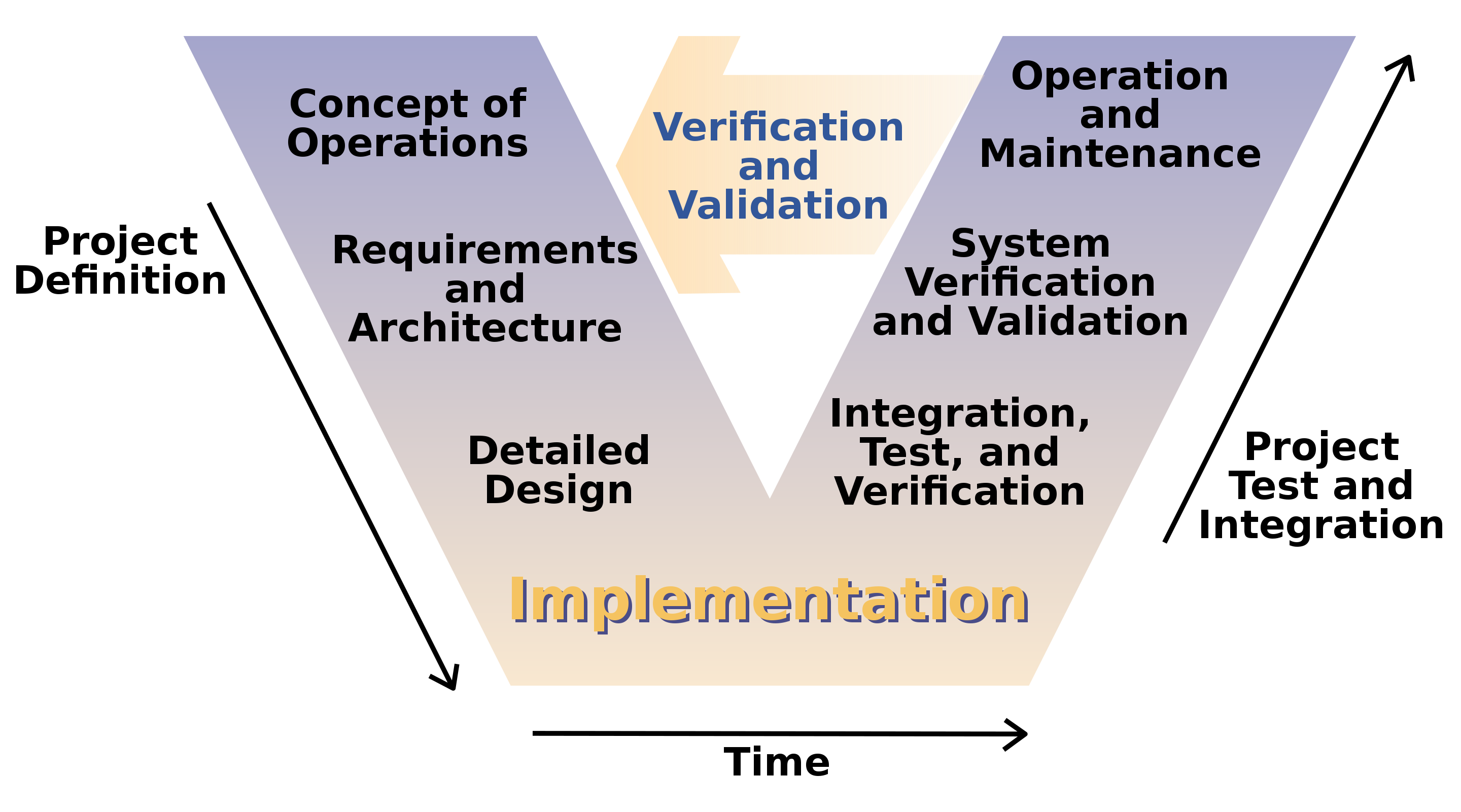
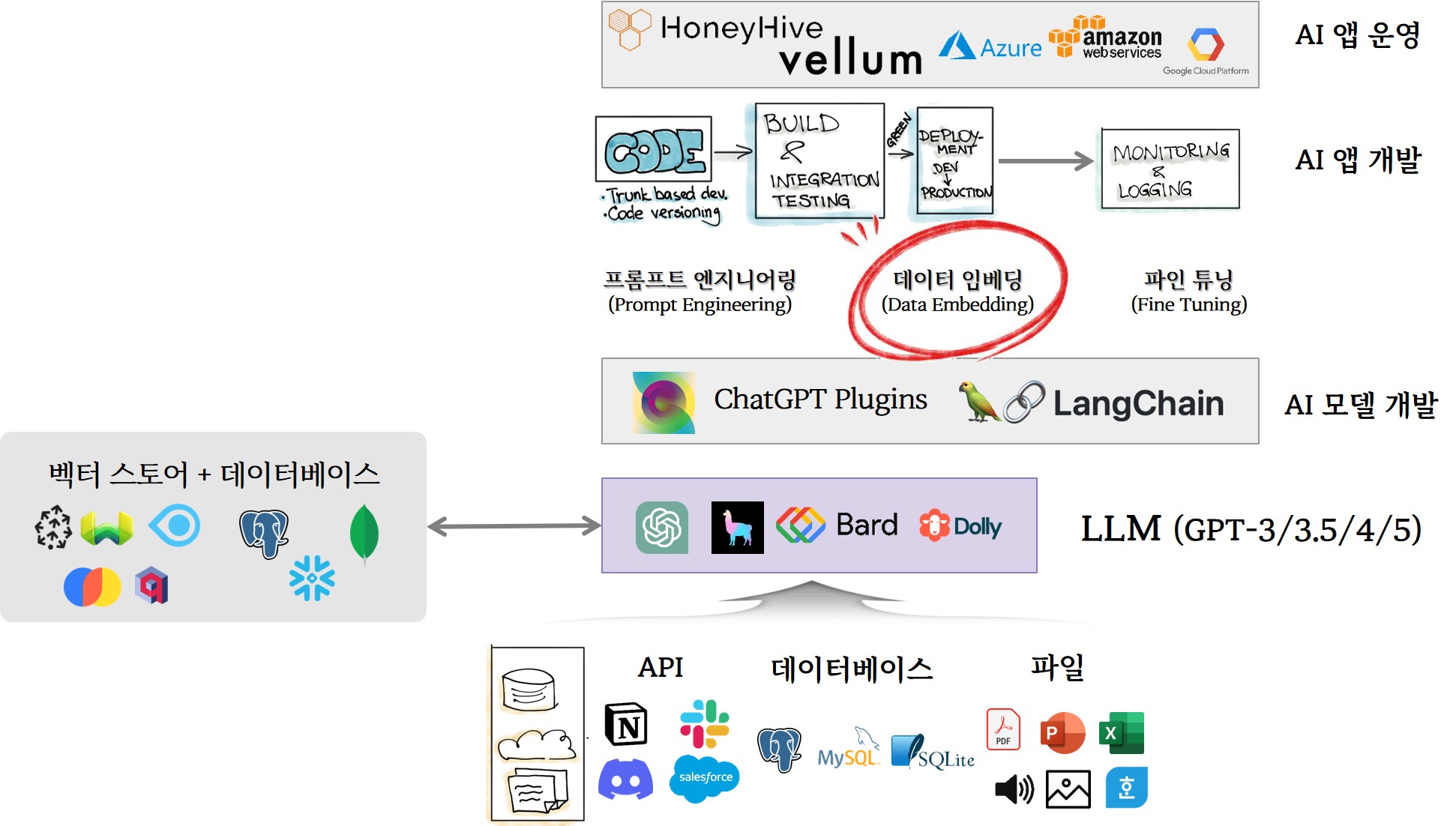
AI 앱 개발은 전통적으로 검증된 개발방법론에 기반한다. 한가지 중요한 점은 거대언어모형(LLM)이 엔진으로 중요한 역할을 수행한다. 비유를 하자면 운영체제 UNIX에 비견된다. 강력한 데이터 기반 LLM 엔진을 바탕으로 다양한 고성능 AI 앱 개발이 가능하다.

2 거대언어모형
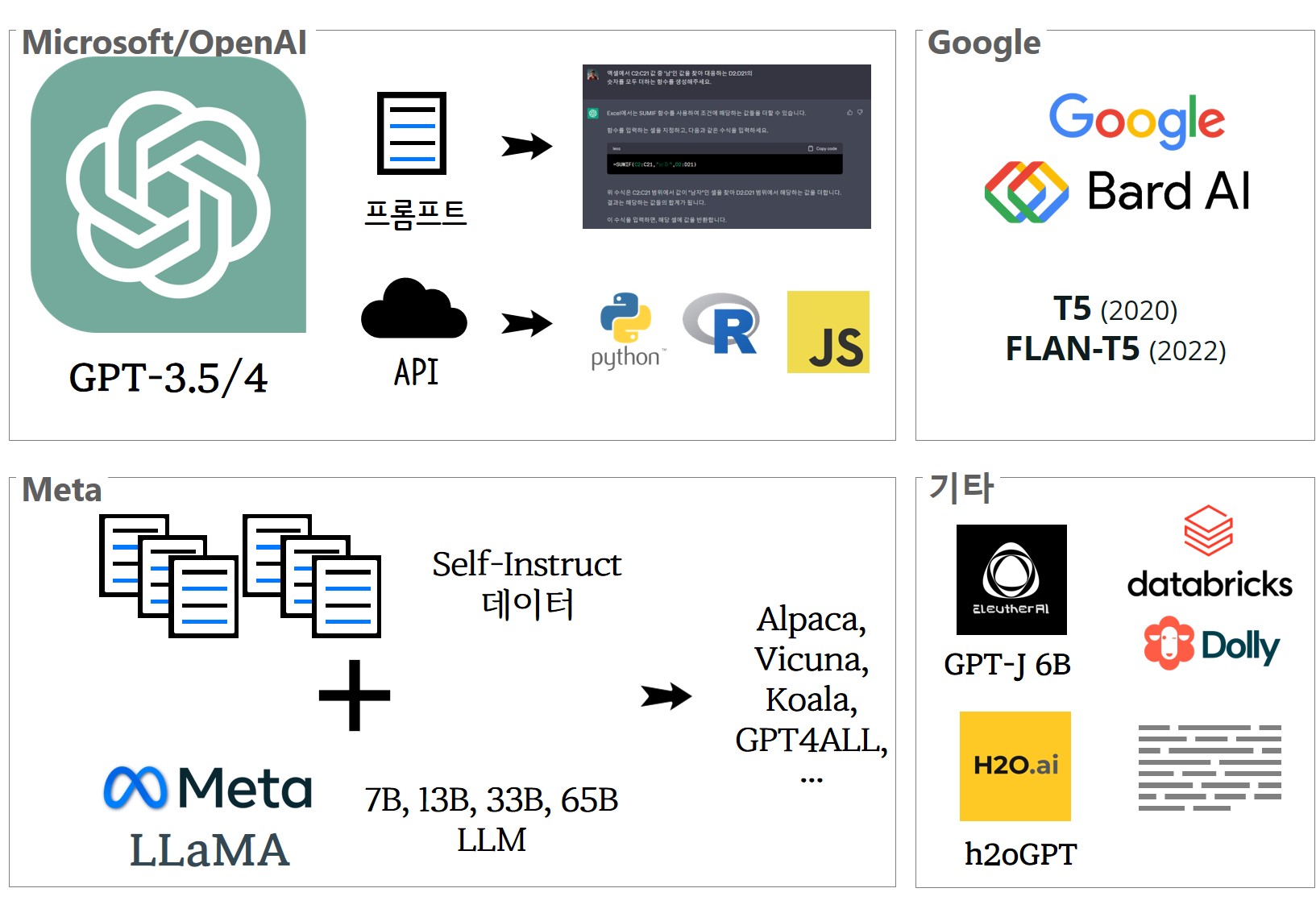
거대언어모형(LLM)을 중심으로 다양한 생태계가 생겨나고 소멸하고 있다. 가장 먼저 포문을 연 OpenAI 챗GPT는 GPT-3.5/4 LLM을 챗 인터페이스와 API 서비스를 통해 생성형 AI 시장을 열었으며 First Mover의 잇점을 최대한 이용하는 전략을 구사하고 있다. 뒤를 이어 메타(페이스북)는 LLaMA를 비상업적 라이선스 제약을 두기는 했지만 오픈소스 소프트웨어 형태로 시장에 풀어 다양한 LLM 모형이 개발되도록 생태계를 확대하고 있다. 구글은 기존 T5/FLAN-T5에 이어 바드(Bard)를 출시하여 마이크로소프트/OpenAI에 맞서고 있다. 그외 Eleuther.ai GPT-J-6B, 데이터브릭스 돌리, H2O.ai h2oGPT 등 GPT 계열 LLM이 대거 출시되고 있다.
3 LangChain
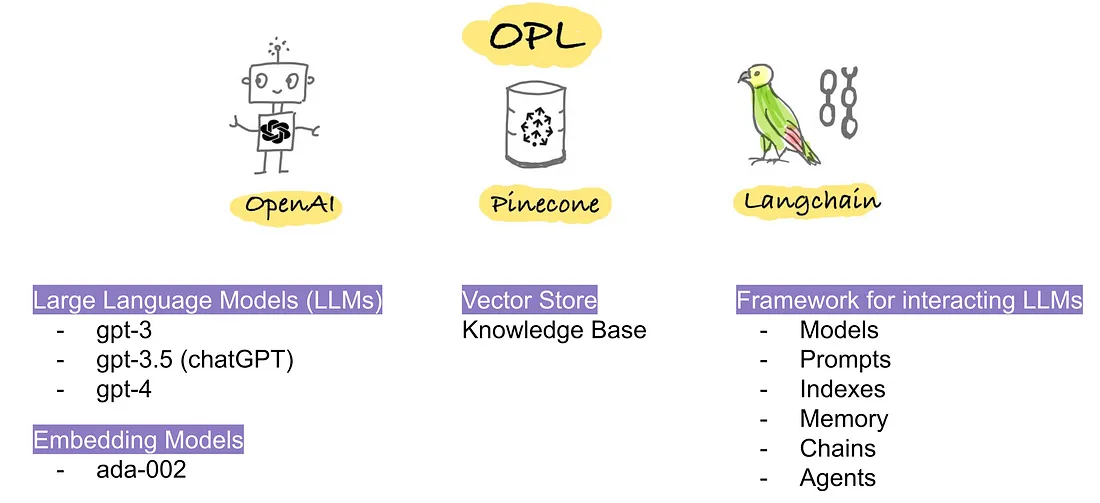
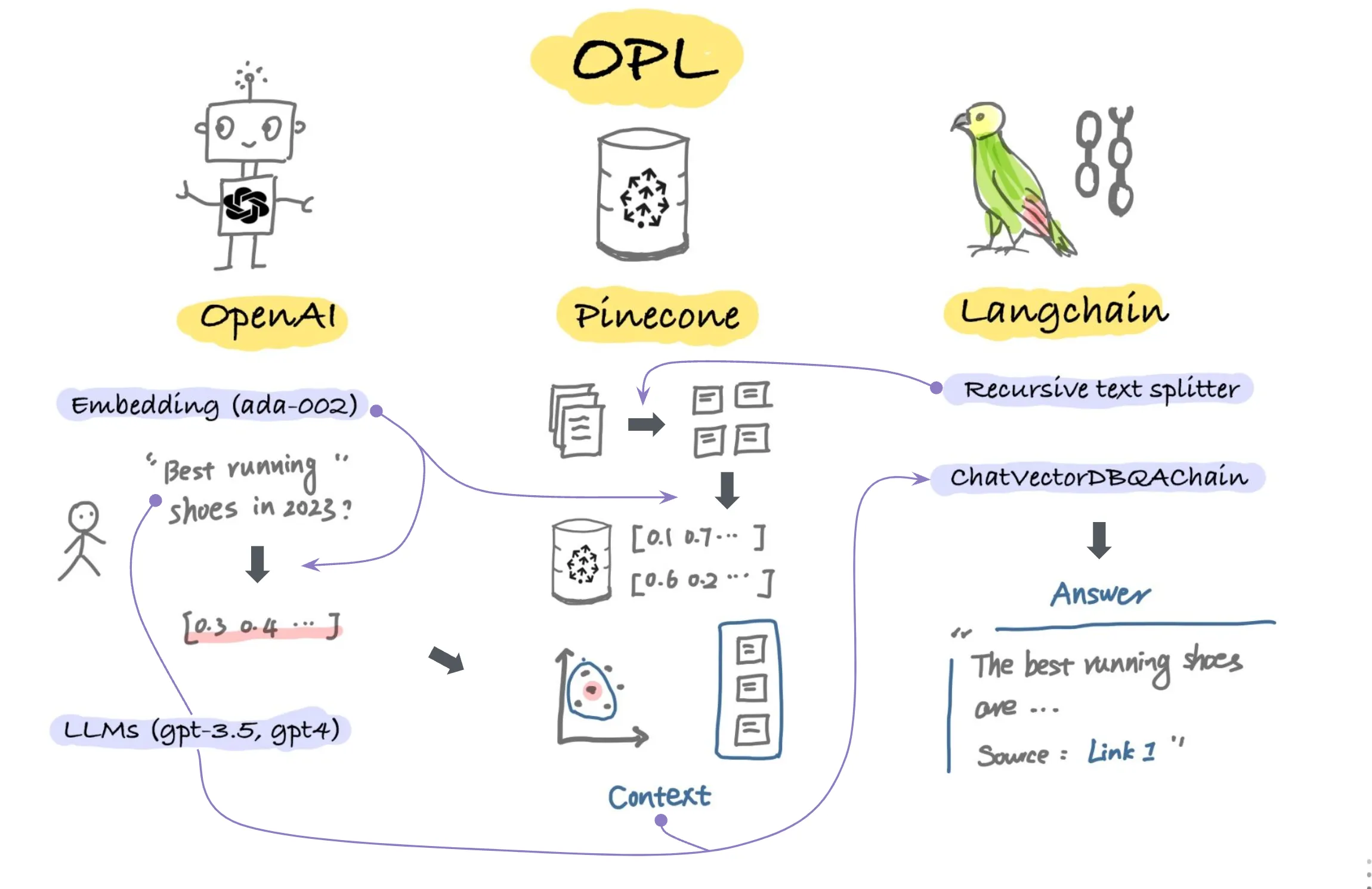
랭체인(LangChain) 대규모 언어 모델(LLM)로 구동되는 애플리케이션을 만들기 위한 프레임워크 중 하나로 랭체인을 사용하면 NLP 전문가가 아니더라도 이전에는 어렵고 광범위한 전문 지식이 필요했던 AI 앱을 쉽게 개발할 수 있다. (Yang, 2023)

4 헬로월드
4.1 환경설정
LangChain 에서 OpenAI chatGPT를 호출하여 원하는 작업을 수행한다. 먼저 openai와 langchain을 설치한다.
!pip3 install openai langchainOPENAI_API_KEY를 환경변수를 넣어두고 OpenAI() 함수에서 호출하여 사용할 수 있도록 한다.
import os
from langchain.llms import OpenAI
os.environ['OPENAI_API_TOKEN'] = os.environ.get('OPENAI_API_KEY')4.2 농담
그리고 나서, 농담으로 헬로월드를 찍어본다. model_name을 비롯한 인수를 응답속도, 정확도, 간결함, 창의성, 비용 등을 고려하여 지정하여 원하는 결과를 얻어낸다.
llm = OpenAI(model_name="text-davinci-003", n=1, temperature=0.9)
llm("재미있는 농담해 주세요")
#> '\n\n도둑이 의자를 훔쳐갔는데 사람들이 "몸통만 훔쳐갔네!"라고 했어요.\n\n도둑이 답하기로 "의자가 제 몸통이에요!"라고 했어요.'3개 농담을 뽑아보자.
llm_result = llm.generate(["재미있는 농담해 주세요"]*3)
llm_jokes = llm_result.generations
llm_jokes
#> [[Generation(text='\n\nQ. 날개가 있는 동물은 무엇인가요?\nA. 새요!', generation_info={'finish_reason': 'stop', 'logprobs': None})], [Generation(text='\nQ. 바람에 비가 내려가면 어떻게 합니까?\nA. 열쇠를 놓치지 말고 집에 들어가세요!', generation_info={'finish_reason': 'stop', 'logprobs': None})], [Generation(text='\n\nQ. 무엇이 비비는 질문이었다고 하면? \n\nA. 비가 왜 오는 걸까요?', generation_info={'finish_reason': 'stop', 'logprobs': None})]]4.3 프롬프트 템플릿
프롬프트 템플릿을 작성하여 해당 작업을 수행토록 지시할 수 있다. 예를 들어 회사명을 작명하는데 대표적으로 잘 작명된 회사명을 제시하고 제약 조건을 추가로 둔 후 회사명 작명지시를 수행시킬 수 있다.
4.3.1 영문
랭체인 문서에 나와있는 예제를 사용해서 PromptTemplate으로 프롬프트를 완성해보자.
from langchain import PromptTemplate
template = """
I want you to act as a naming consultant for new companies.
Here are some examples of good company names:
- search engine, Google
- social media, Facebook
- video sharing, YouTube
The name should be short, catchy and easy to remember.
What is a good name for a company that makes {product}?
"""
prompt = PromptTemplate(
input_variables = ["product"],
template = template,
)
socks_prompt = prompt.format(product="colorful socks")library(reticulate)
socks_prompt_chr <- py$socks_prompt
cat(socks_prompt_chr)
#>
#> I want you to act as a naming consultant for new companies.
#>
#> Here are some examples of good company names:
#>
#> - search engine, Google
#> - social media, Facebook
#> - video sharing, YouTube
#>
#> The name should be short, catchy and easy to remember.
#>
#> What is a good name for a company that makes colorful socks?앞서 프롬프트 템플릿을 지정한 후 실행을 통해 원하는 회사명 작명 작업을 수행시킨다.
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
print(chain.run("colorful socks"))
#>
#> BrightSox.4.3.2 국문
앞서 제작된 영문회사 작명 템플릿을 번역하여 국내 몇가지 회사를 사례로 넣어 chatGPT에 작업을 지시한다.
k_template = """
신규 회사명을 작명하는 컨설턴트로 활동해 주셨으면 합니다.
다음은 좋은 회사 이름 몇 가지 사례입니다:
- 케이티, 통신
- 놀부, 외식프랜차이즈
- 율도국, 브랜드제작
- 크몽, 아웃소싱 플랫폼
이름은 짧고 눈에 잘 띄며 기억하기 쉬워야 합니다.
{k_product} 제품을 잘 만드는 회사의 좋은 이름은 무엇인가요?
"""
k_prompt = PromptTemplate(
input_variables = ["k_product"],
template = k_template,
)
k_socks_prompt = k_prompt.format(k_product="양말")앞서 프롬프트 템플릿을 지정한 후 실행을 통해 원하는 회사명 작명 작업을 수행시킨다.
from langchain.chains import LLMChain
k_chain = LLMChain(llm = llm, prompt = k_prompt)
k_socks_result = k_chain.run("양말")cat(py$k_socks_result)
#>
#> - 슬립그랩, 스타플래그, 소다르트, 스위트스웨이드, 코싱클럽, 레이크페리4.4 요약
한글은 영어에 비해 토큰 크기가 크다. 이를 위해서 text-davinci-003 모델이 소화할 수 있는 토큰보다 크기를 줄여야한다. 대한민국 대통령 취임사 중 박근혜 대통령 취임사에서 대략 2,000 토큰 크기를 대상으로 문서 요약을 수행해보자.
from langchain import OpenAI, PromptTemplate, LLMChain
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains.mapreduce import MapReduceChain
from langchain.prompts import PromptTemplate
llm = OpenAI(temperature=0)
text_splitter = CharacterTextSplitter()
with open('data/state_of_the_union.txt') as f:
# with open('data/취임사.txt') as f:
inaugural_address = f.read()
texts = text_splitter.split_text(inaugural_address)
from langchain.docstore.document import Document
docs = [Document(page_content=t) for t in texts[:]]
from langchain.chains.summarize import load_summarize_chain
chain = load_summarize_chain(llm, chain_type="map_reduce")
chain.run(docs)참고문헌
Yang, W. (2023). Building LLMs-Powered Apps with OPL Stack - OPL: OpenAI, Pinecone, and Lanchain for knowledge-based AI assistant. Medium.com. https://towardsdatascience.com/building-llms-powered-apps-with-opl-stack-c1d31b17110f