
graph TD
A["대한민국"] --> B(("네이버"))
B ----> E[잡브레인]
B ----> H[라이팅젤]
B --> C[모카]
B --> D[뤼튼]
B --> F[킵그로우]
style A fill:#FF6655AA
style B fill:#88ffFF
1 챗GPT LLM 이해하기
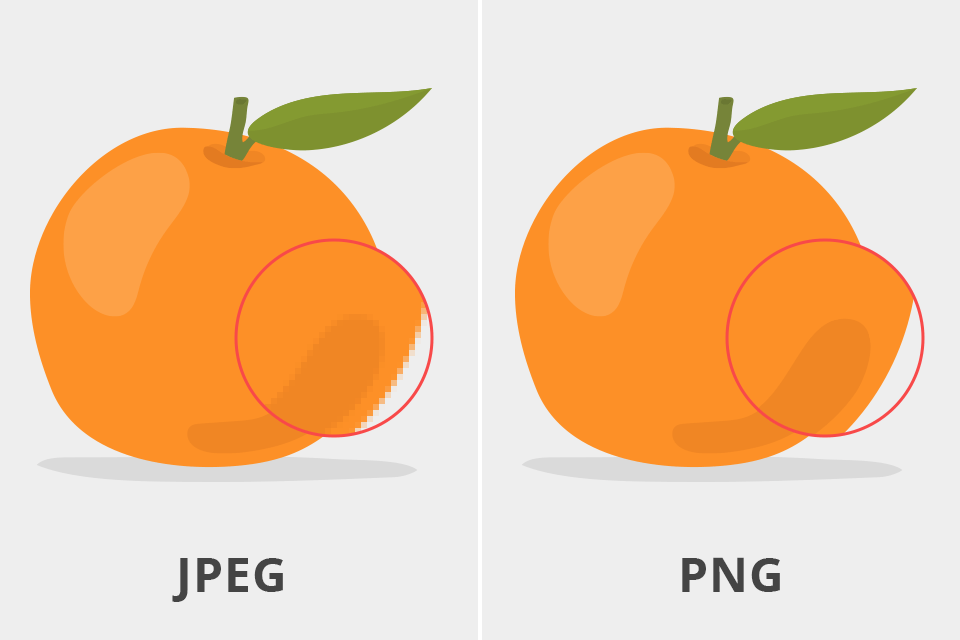
1.1 JPEG 압축
ChatGPT는 인터넷에서 방대한 양의 데이터를 학습하여 이를 정말 잘 압축한 하나의 저장소로 이해할 수 있다. 따라서, 압축을 풀게 되면 정확히 원본을 복원할 수 있는 부분도 있지만, 그렇지 못한 부분도 당영히 있게 된다.
ChatGPT를 “웹의 흐릿한 JPEG”으로 비유하고 있다. JPEC 기술 자체는 손실 압축기술로 무손실 압축기술로 대표적인 PNG와 대비된다. 흐릿한 이미지가 선명하지 않거나 정확하지 않은 것처럼 ChatGPT도 항상 완벽한 답변을 제공하거나 모든 질문을 제대로 이해하는 것도 아니다. 하지만 사용자와의 대화를 기반으로 끊임없이 학습하고 개선하고 있다. 더 많은 사람들이 ChatGPT를 사용할수록 사람의 언어를 더 잘 이해하고 반응할 수 있게 개발된 기술이다.
ChatGPT와 유사한 인공지능 프로그램이 너무 강력해지거나 인간을 대체할 수 있다고 우려하는 사람들도 있지만, ChatGPT는 단순히 작업을 더 쉽고 효율적으로 만드는 데 사용할 수 있는 강력한 도구일 뿐이므로 사람을 능가하거나 지배할 가능성은 거의 없다. 인공지능(ChatGPT)을 책임감 있고 윤리적으로 사용되도록 하는 것은 결국 사용자 귀책이다.
ChatGPT가 간단한 숫자계산에 문제가 있는 것은 웹상에 산재된 숫자 계산 데이터를 바탕으로 계산을 흉내낼 수는 있으나 이와 같은 방식으로 ChatGPT가 학습한 것은 명백히 잘못된 것이다. 사칙연산에 대한 일반적인 원리를 이해하게 되면 웹상에 나온 사칙연산 문제를 정확히 해결할 뿐만 아니라 웹상에 나와있지 않는 계산문제도 풀 수 있으나 현재는 그렇지 못하다.
![]()


1.2 제록스 복사기
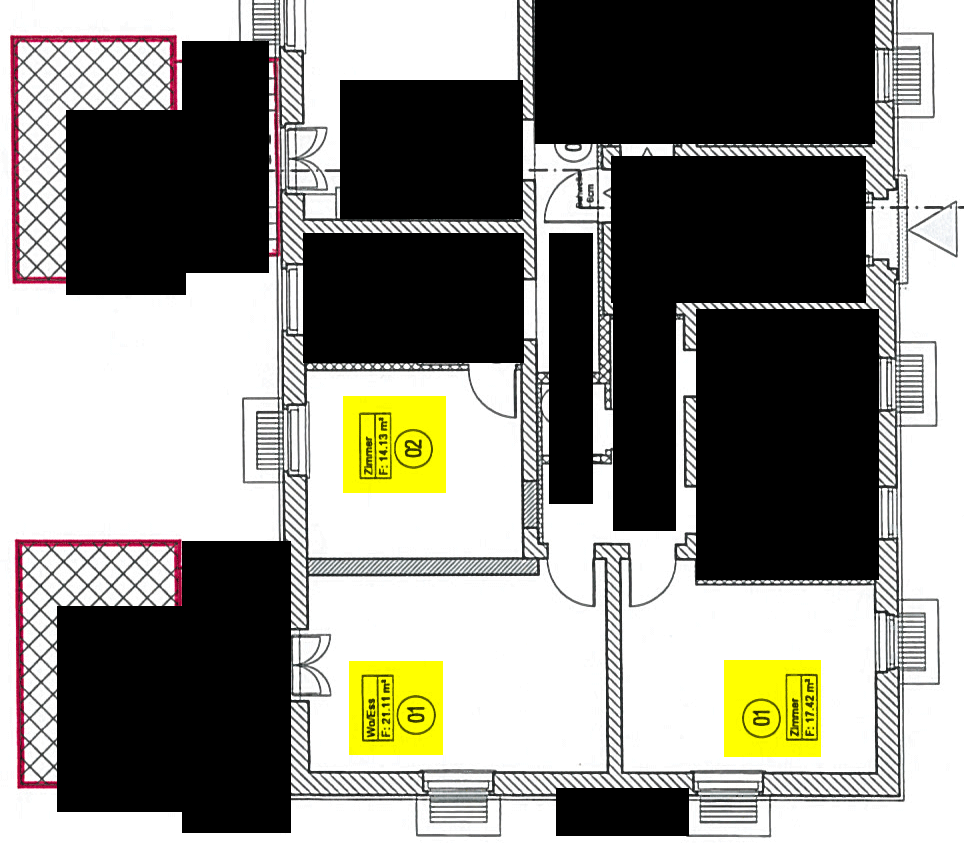
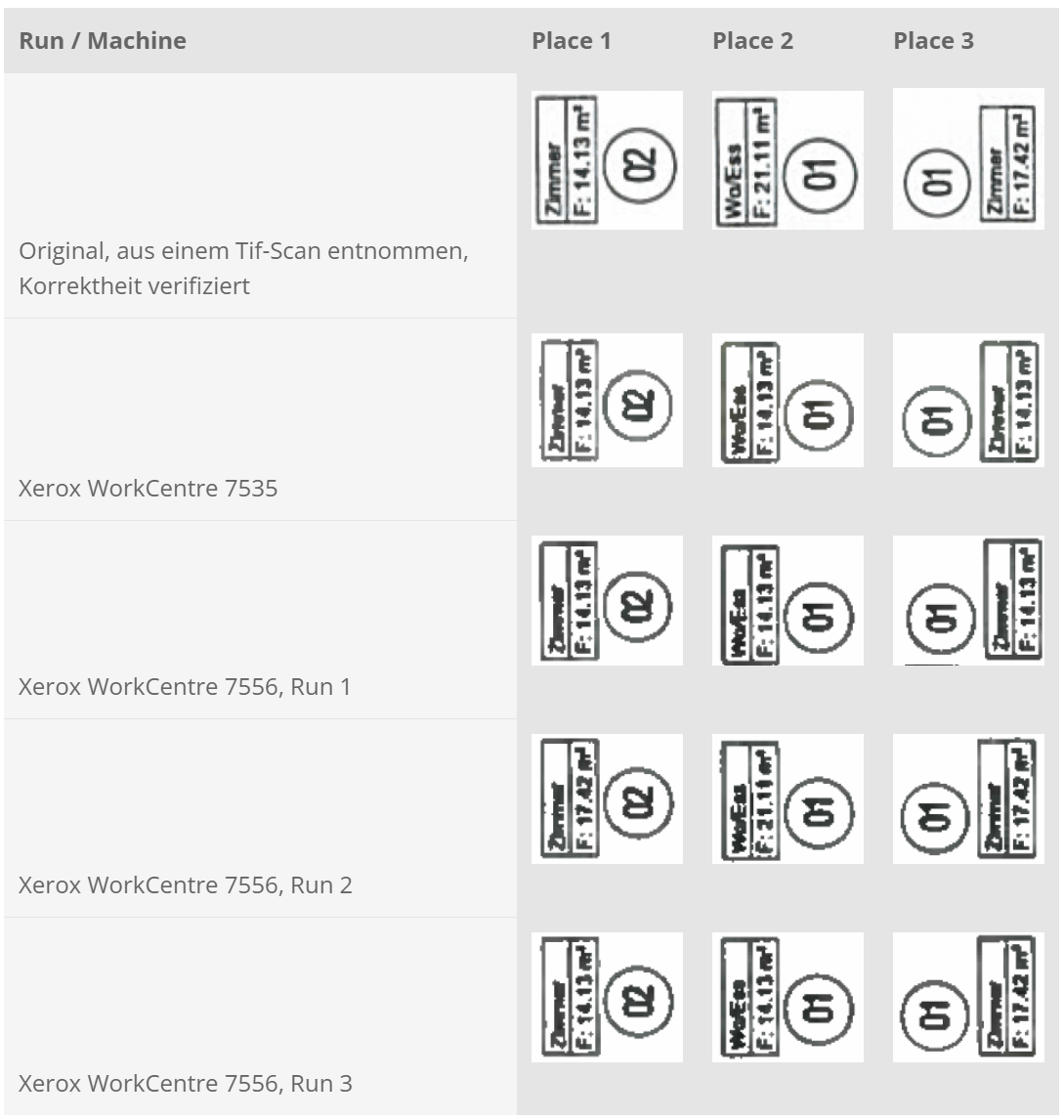
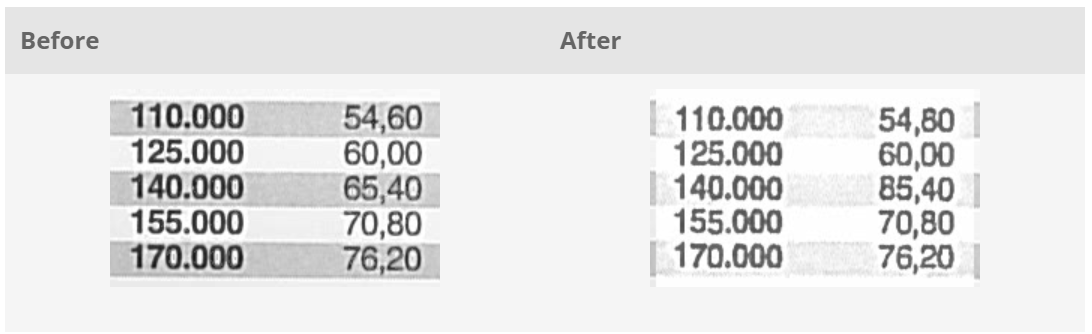
독일 과학자(David Kriesel)가 제록스 복사기에서 문서에 있는 숫자를 변경하는 결함을 발견했다. 제록스 프린터가 방의 면적을 14.13m²에서 17.42m²로 넓혔고, 다른 프린터는 21.11m²에서 14.13m²로 줄였다. 숫자 문자열 중간에 특정 숫자(예: “6” 또는 “8”)가 나타나면 복사기가 해당 숫자를 다른 숫자로 바꾸는 경우가 많았다. 예를 들어, ’682’가 ’882’가 될 수 있습니다.
처음에 건물 설계도를 스캔하고 분석하려고 할 때 이 문제를 발견했다. 원본에는 이러한 오류가 없었지만 스캔한 사본에서 특정 숫자가 변경된 것을 발견했다. 결국 그들은 사본을 만드는 과정에서 숫자가 변경된, 사용 중인 Xerox 복사기에 문제가 있다는 사실을 깨달았다.
이 결함은 제록스 복사기에 사용되는 압축 알고리즘과 관련된 것으로 특정 숫자가 서로 가까이 있으면 알고리즘이 이를 다른 숫자로 착각하고 그에 따라 숫자를 바꾼 것이다. 이 문제가 일부 고급 모델을 포함한 다양한 제록스 복사기에 존재한다는 사실도 발견했다.

2 패러다임

- Pre-Software: Special-purpose computer
- Software 1.0: Design the Algorithm
- Software 2.0: Design the Dataset
- Software 3.0: Design the Prompt
- Software 1.0: Design the Algorithm
- Software 2.0: Design the Dataset
- Software 3.0: Design the Prompt
2.1 기계학습
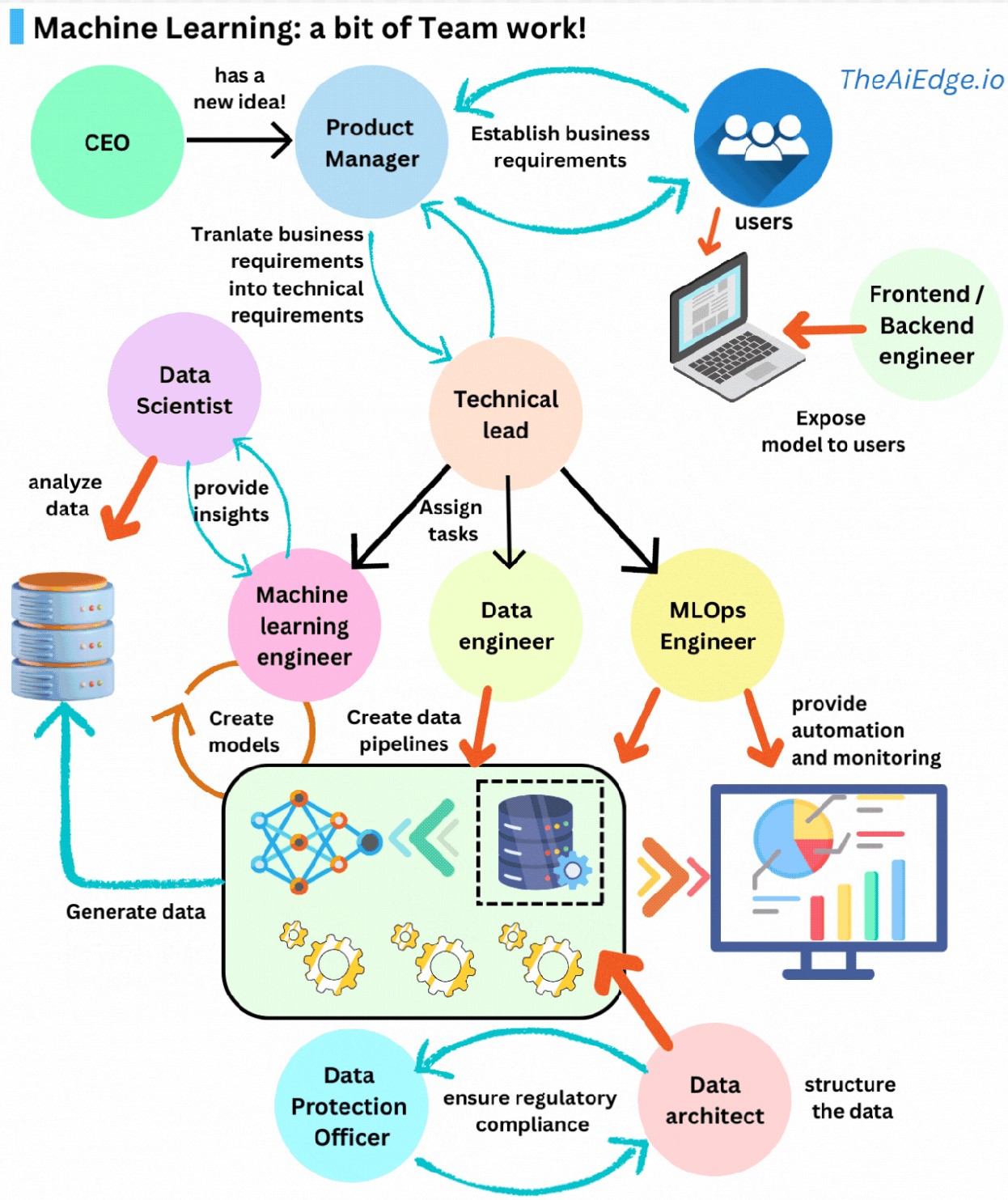
머신러닝은 혼자서 할 수 있는 일이 아닙니다! ML 솔루션을 구축할 때는 고객부터 고객까지 엔드투엔드로 생각하는 것이 중요합니다. 이는 설계, 계획 및 실행에 도움이 됩니다. 계획의 일환으로 누가 언제 참여해야 하는지 이해하는 것이 중요합니다. 일반적인 프로젝트를 살펴보겠습니다.

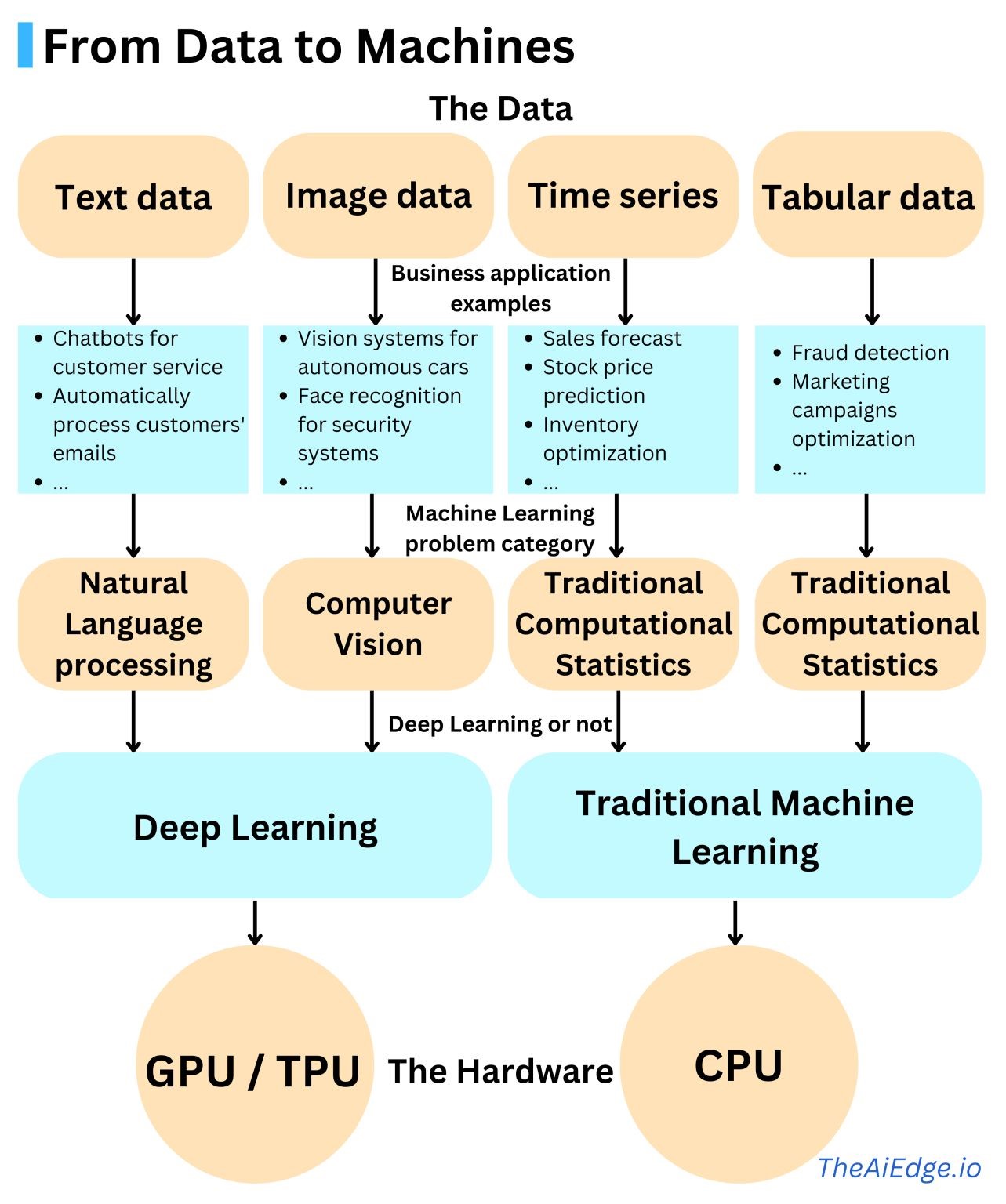
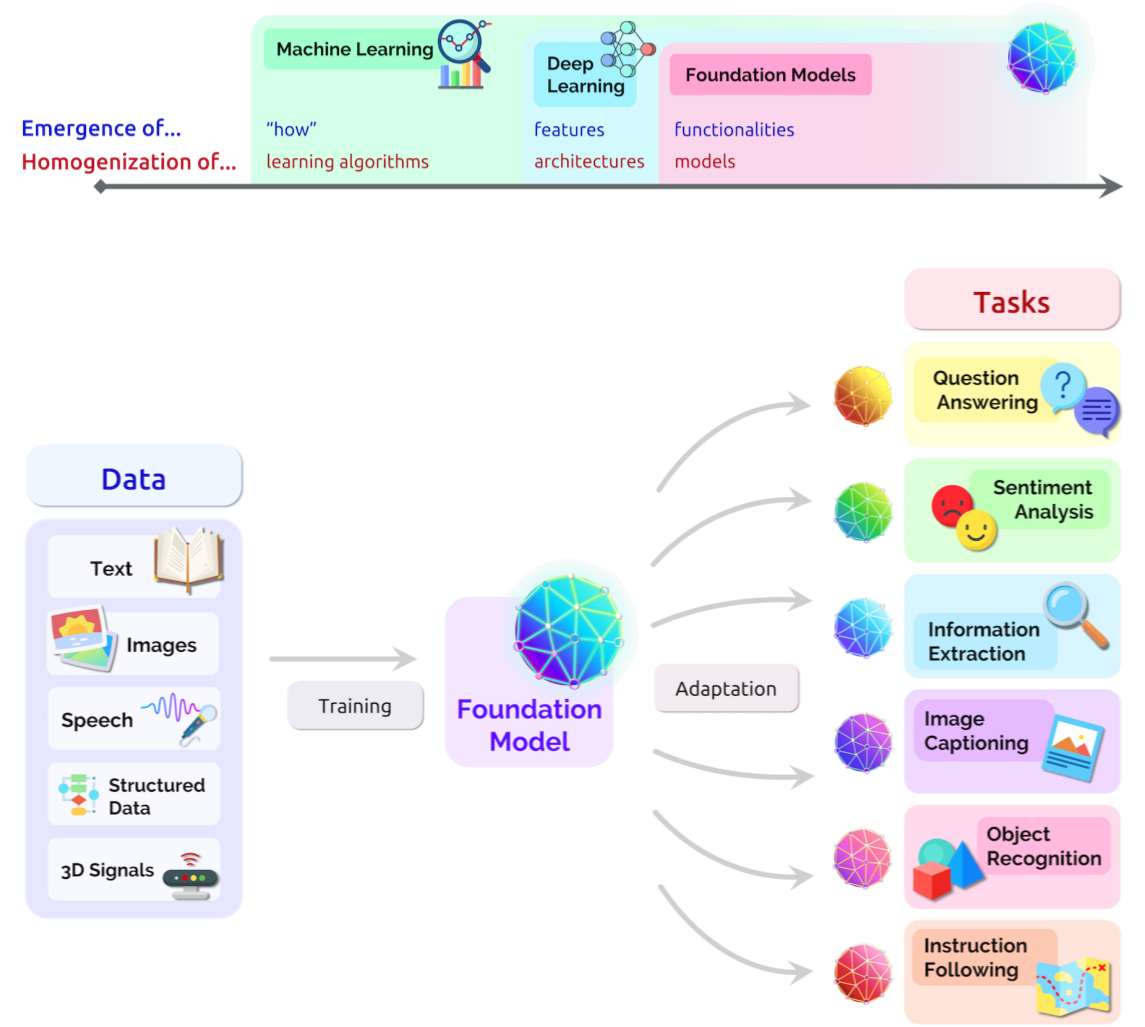
인공지능(AI) 시스템 구축을 위한 새로운 패러다임이 탄생했다. 기초모형(Foundation Model)은 광범위한 데이터에 대해 학습된 모델로, 광범위한 실무하위 작업에 활용할 수 있다. 현재 BERT, GPT-3, CLIP [Radford 외. 2021] 등을 예로 들 수 있다. (Bommasani 기타, 2021)
- 패러다임: (비신경망)지도학습 (Fully Supervised Learning)
- 전성기: 2015년까지 최고 전성기 구가
-
특징
- 주로 비신경망 기계학습이 사용
- 수작업으로 Feature를 추출
-
대표작
- 수작업 Feature 추출 후 SVM(support vector machine) 기계학습 모형
- 수작업 Feature 추출 후 CRF(conditional random fields)
- 패러다임: 신경망 지도학습(Fully Supervised Learning)
- 전성기: 대략 2013~2018
-
특징
- 신경망(Neural Network) 의존
- 수작업으로 Feature를 손볼 필요는 없으나 신경망 네트워크는 수정해야 함(LSTM vs CNN)
- 종종 사전학습된 언어모형을 사용하나 임베딩(embedding) 같은 얕은(shallow) Feature를 적용
-
대표작
- 텍스트 분류작업에 CNN 사용
- 패러다임: 사전학습(pre-training), 미세조정(fine-tuning)
- 전성기: 2017~현재
-
특징
- 사전학습된 언어모형을 전체 모형의 초기값으로 사용
- 아키텍쳐 디자인에 작업이 덜 필요하지만 목적함수(Objective function) 엔지니어링은 필요
-
대표작
- BERT → Fine Tuning
- 패러다임: 사전학습(pre-training), 프롬프트(Prompt), 예측(Predict)
- 전성기: 2019~현재
-
특징
- NLP 작업이 언어모형(Language Model)에 전적으로 의존
- 얕던 깊던 Feature 추출, 예측 등 작업이 전적으로 언어모형에 의존
- 프롬프트 공학이 필요
-
대표작
- GPT3
3 Prompt engineering
- Instructions
- Question
- Input data
- Examples
4 생성 AI
- generation: text → image
- classification: image → text
- transformation: image → image (or text → text)
- GPT-3
- Dalle.2 (text-to-image)
- Meta’s AI (text-to-video)
- Google AI (text-to-video)
- Stable Diffusion (text-to-image)
- Tesla AI (humanoid robot + self-driving)
- text-to-gif (T2G)
- text-to-3D (T2D)
- text-to-text (T2T)
- text-to-NFT (T2N)
- text-to-code (T2C)
- text-to-image (T2I)
- text-to-audio (T2S)
- text-to-video (T2V)
- text-to-music (T2M)
- text-to-motion (T2Mo)
- brain-to-text (B2T)
- image-to-text (I2T)
- speech-to-text (S2T)
- audio-to-audio (A2A)
- tweet-to-image (Tt2I)
- text-to-sound (T2S)
5 기업 생태계

네이버는 ’클로바 스튜디오’를 다양한 스타트업이 활용하여 서비스를 출시하고 있다.
- 임플로이랩스잡 브레인(Job Brain): AI 자소서 생성 기능에 적용, 완성도 높은 자소소
- 앱플랫폼 라이팅젤: 대입 취업 자소서 자동왕성 기능에 적용
- 아스타 컴퍼니 모카: 상품언어, 광고 헤드라인, 세일즈 카피 생성 기능에 활용
- 뤼튼테크놀로지 뤼튼: 광고카피, 제품소개 문구 등 AI 카피라이팅 서비스에 활용
- 유니트컴즈 킵그로우: 고객사 인스타그램에 게시물을 주기적으로 포스팅해주는 기능에 적용
참고문헌
Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., Arx, S. von, Bernstein, M. S., Bohg, J., Bosselut, A., Brunskill, E., 기타. (2021). On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258.