코드
# install.packages("reticulate")
library(reticulate)
# conda_list()
use_condaenv(condaenv = "r-reticulate")
# py_install(packages = c("pandas", "scikit-learn"))
reticulate 패키지로 콘다 파이썬 환경을 구축한다. 필요한 경우 패키지도 설치한다.
# install.packages("reticulate")
library(reticulate)
# conda_list()
use_condaenv(condaenv = "r-reticulate")
# py_install(packages = c("pandas", "scikit-learn"))펭귄 데이터를 다운로드 받아 로컬 컴퓨터 data 폴더에 저장시킨다.
library(tidyverse)
fs::dir_create("data")
download.file(url = "https://raw.githubusercontent.com/dataprofessor/data/master/penguins_cleaned.csv", destfile = "data/penguins_cleaned.csv")
penguin_df <- readr::read_csv("data/penguins_cleaned.csv")
penguin_df
#> # A tibble: 333 × 7
#> species island bill_length_mm bill_depth_mm flipper_length…¹ body_…² sex
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr>
#> 1 Adelie Torgersen 39.1 18.7 181 3750 male
#> 2 Adelie Torgersen 39.5 17.4 186 3800 fema…
#> 3 Adelie Torgersen 40.3 18 195 3250 fema…
#> 4 Adelie Torgersen 36.7 19.3 193 3450 fema…
#> 5 Adelie Torgersen 39.3 20.6 190 3650 male
#> 6 Adelie Torgersen 38.9 17.8 181 3625 fema…
#> 7 Adelie Torgersen 39.2 19.6 195 4675 male
#> 8 Adelie Torgersen 41.1 17.6 182 3200 fema…
#> 9 Adelie Torgersen 38.6 21.2 191 3800 male
#> 10 Adelie Torgersen 34.6 21.1 198 4400 male
#> # … with 323 more rows, and abbreviated variable names ¹flipper_length_mm,
#> # ²body_mass_g파이썬 sklearn 패키지로 펭귄 성별예측 모형을 구축하자.
# "code/penguin_sex_clf.py"
import pandas as pd
penguins = pd.read_csv('data/penguins_cleaned.csv')
penguins_df = penguins[['bill_length_mm', 'bill_depth_mm', 'flipper_length_mm', 'body_mass_g', 'sex']]
# Ordinal feature encoding
# https://www.kaggle.com/pratik1120/penguin-dataset-eda-classification-and-clustering
df = penguins_df.copy()
target_mapper = {'male':0, 'female':1}
def target_encode(val):
return target_mapper[val]
df['sex'] = df['sex'].apply(target_encode)
# Separating X and Y
X = df.drop('sex', axis=1)
Y = df['sex']
# Build random forest model
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X, Y)source_python("code/penguin_sex_clf.py")
clf
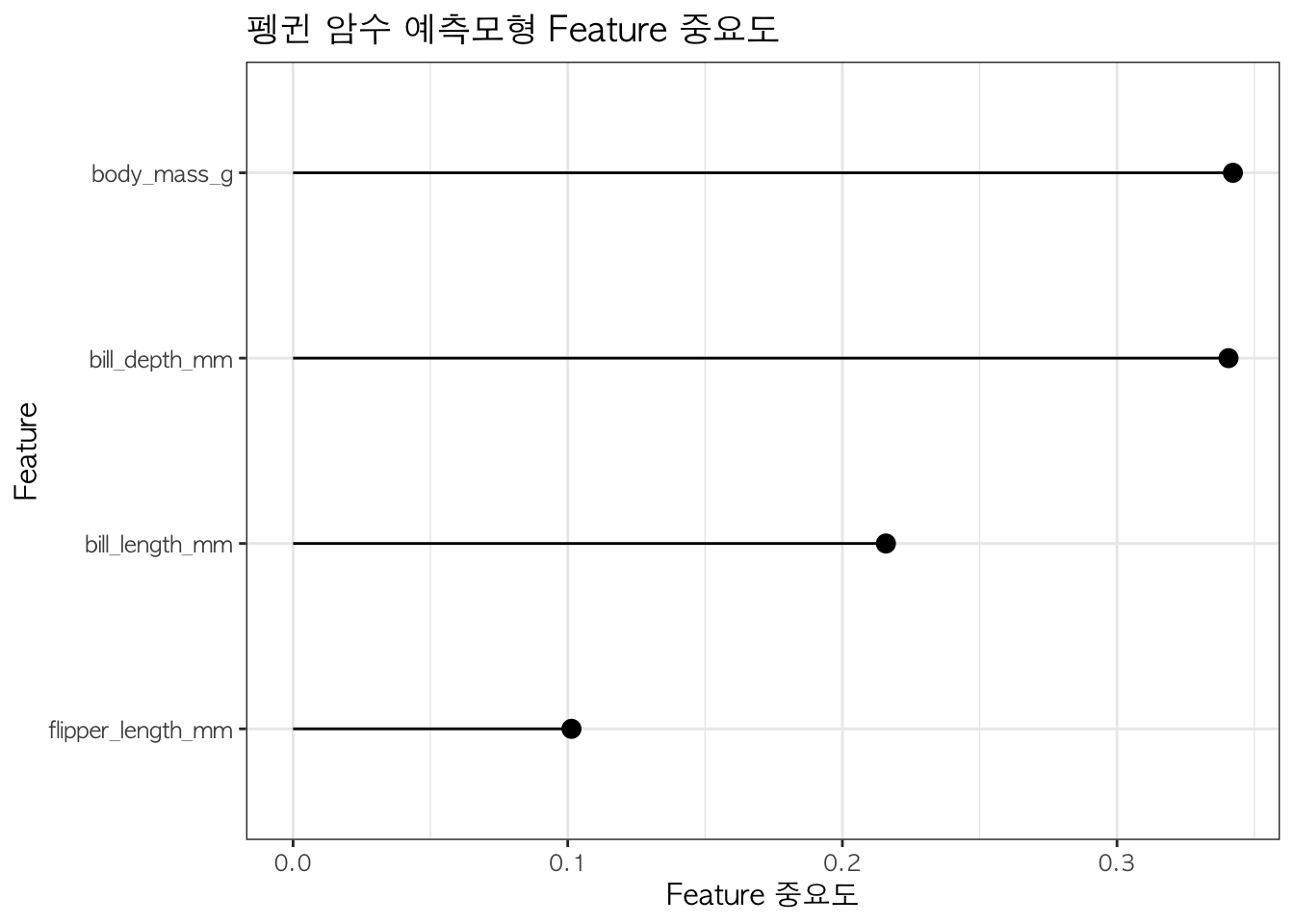
#> RandomForestClassifier()파이썬 기계학습 결과를 R로 가져와서 변수 중요도를 시각화한다.
feat_tbl <- tibble(features = clf$feature_names_in_,
importance = clf$feature_importances_)
feat_tbl %>%
ggplot(aes(x = fct_reorder(features, importance), y = importance)) +
geom_point(size = 3) +
geom_segment( aes(x=features, xend=features, y=0, yend=importance)) +
labs(y = "Feature 중요도", x = "Feature",
title = "펭귄 암수 예측모형 Feature 중요도") +
coord_flip() +
theme_bw(base_family = "AppleGothic")