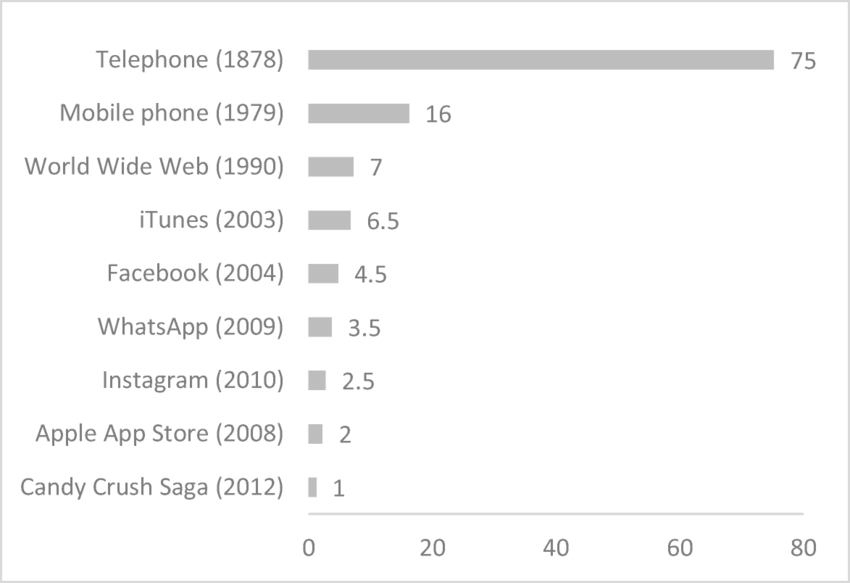
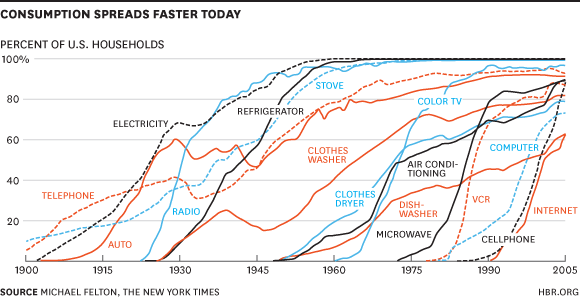
## 언어 콘텐츠contents_raw<-read_html(x ='https://en.wikipedia.org/wiki/Languages_used_on_the_Internet')%>%html_element(xpath ='//*[@id="mw-content-text"]/div[1]/table[1]')%>%html_table()%>%set_names(c("순위", "언어", "비중"))contents_tbl<-contents_raw%>%mutate(비중 =parse_number(비중))%>%## 대한민국 이하 기타 ------------mutate(언어 =ifelse(순위>=17, "기타", 언어))%>%group_by(언어)%>%summarise(비중 =sum(비중))%>%ungroup()%>%arrange(desc(비중))contents_gt<-contents_tbl%>%## 표 gt()%>%gt_theme_nytimes()%>%tab_options(table.width =pct(75))%>%tab_header( title =md("**인터넷 콘텐츠 상위 언어별 통계**"), subtitle ="한국어 포함 상위 17개 언어")%>%tab_source_note( source_note ="출처:https://en.wikipedia.org/wiki/Languages_used_on_the_Internet")%>%cols_align( align ="center", columns =c(언어, 비중))%>%fmt_number( columns =c(비중), decimals =1)%>%cols_label( 비중 ="비중(%)")%>%tab_footnote( footnote ="한국어보다 비중이 낮은 인도네이사, 체코, 우크라이나 등", locations =cells_body(columns =언어, rows =2))contents_gt%>%gtsave("images/contents_gt.png")
Tensorflow, Keras, Pytorch, Fast.ai 가 차례로 등장하며 딥러닝 개발 프레임워크의 전성기를 구가했다. 최근 5년동안 Google 추세를 살펴보자.
코드
library(gtrendsR)extrafont::loadfonts()result<-gtrends(keyword =c("pytorch","fastai", "tensorflow", "keras"), geo ="", time="today+5-y", low_search_volume =TRUE)gtrends_framework_g<-result$interest_over_time%>%as_tibble()%>%mutate(keyword =factor(keyword, levels =c("keras", "pytorch", "tensorflow", "fastai")))%>%mutate(hits =parse_number(hits))%>%ggplot(aes(x =date, y =hits, color =keyword))+geom_line()+theme_bw(base_family ="NanumBarunpen")+labs(x ="", y ="검색수", color ="프레임워크", title ="딥러닝 프레임워크 구글 검색 추세")+theme(legend.title =element_text(size =16), legend.text =element_text(size =14))# ragg always works for macragg::agg_png("images/dl_framework.png", width =297, height =210, units ="mm", res =300)gtrends_framework_gdev.off()
3.2 chatGPT 출현
chatGPT 출현이후 Tensorflow, Keras, Pytorch, Fast.ai 는 어떻게 전개될 것인지 최근 1년동안 Google 추세를 살펴보자.
코드
chatGPT_result<-gtrends(keyword =c("pytorch","fastai", "tensorflow", "keras", "chatGPT"), geo ="", time="today 12-m", low_search_volume =TRUE)gtrends_chatGPT_g<-chatGPT_result$interest_over_time%>%as_tibble()%>%mutate(keyword =factor(keyword, levels =c("chatGPT", "keras", "pytorch", "tensorflow", "fastai")))%>%mutate(hits =parse_number(hits))%>%mutate(date =as.Date(date))%>%ggplot(aes(x =date, y =hits, color =keyword))+geom_line()+theme_bw(base_family ="NanumBarunpen")+labs(x ="", y ="검색수", color ="프레임워크", title ="chatGPT와 딥러닝 프레임워크 구글 검색 추세")+scale_x_date(date_labels ="%Y-%m")+theme(legend.title =element_text(size =16), legend.text =element_text(size =14))# ragg always works for macragg::agg_png("images/chatGPT_framework.png", width =297, height =210, units ="mm", res =300)gtrends_chatGPT_gdev.off()
3.3 파이썬과 chatGPT
chatGPT 출현이후 파이썬, tensorflow, pytorch 최근 1년동안 Google 추세를 살펴보자.
코드
python_result<-gtrends(keyword =c("chatGPT", "pytorch","python", "tensorflow", "keras"), geo ="", time="today 12-m", low_search_volume =TRUE)python_chatGPT_g<-python_result$interest_over_time%>%as_tibble()%>%mutate(keyword =factor(keyword, levels =c("chatGPT", "python", "keras", "pytorch", "tensorflow")))%>%mutate(hits =parse_number(hits))%>%mutate(date =as.Date(date))%>%ggplot(aes(x =date, y =hits, color =keyword))+geom_line()+theme_bw(base_family ="NanumBarunpen")+labs(x ="", y ="검색수", color ="프레임워크", title ="파이썬, chatGPT, 주요 딥러닝 프레임워크 구글 검색 추세")+scale_x_date(date_labels ="%Y-%m")+theme(legend.title =element_text(size =16), legend.text =element_text(size =14))# ragg always works for macragg::agg_png("images/python_chatGPT_g.png", width =297, height =210, units ="mm", res =300)python_chatGPT_gdev.off()
현대백화점이 광고 카피와 판촉행사 소개문 등 마케팅 문구 제작을 위해 특별히 ’고용’한 인공지능(AI) 카피라이팅 시스템은 네이버 ’하이버클로바’를 기본 엔진으로 추가학습(최근 3년 동안 사용한 광고 카피, 판촉행사에서 쓴 문구 중 소비자 호응이 컸던 데이터 1만여건을 집중적으로 학습)하여 개발
웹툰을 제작하는 스튜디오에서는 웹툰 작가들과 어시스트들이 매우 노동집약적인 작업으로 창작활동을 하고 있다. 현재 웹툰 제작 공정은 콘티, 스케치, 라인(펜선), 채색, 배경, 출판 작업의 순서로 이뤄진다. 한국만화영상진흥원과 협력하는 실제 웹툰 작가들은 특정작업이 아닌 모든 공정에서 제작 생산성 향상을 위한 자동화 기술이 필요하다는 결론에 도달함. (김현진, 2021)
8 시장 와해 사례
8.1 공상과학소설
공상과학 및 판타지 잡지 클라크스월드(Clarkesworld)는 AI가 생성한 소설라는 비난을 받은 후 신규 공상과학소설이 급증한 것이 AI 기계로 작성된 원인을 큰 것으로 파악하고 2월 20일부터 공식적으로 투고를 중단했다.
Song, A. K. (2019). The digital entrepreneurial ecosystem—a critique and reconfiguration. Small Business Economics, 53(3), 569–590.
김현진. (2021). 웹툰 이미지 제작공정 단계별 활용 가능한 스케치 관련 인공지능 기술. 한국정보과학회.
소스 코드
---title: "chatGPT"subtitle: "추세 트렌드"author: - name: 이광춘 url: https://www.linkedin.com/in/kwangchunlee/ affiliation: 한국 R 사용자회 affiliation-url: https://github.com/bit2rtitle-block-banner: true#title-block-banner: "#562457"format: html: css: css/quarto.css theme: flatly code-fold: true toc: true toc-depth: 3 toc-title: 목차 number-sections: true highlight-style: github self-contained: falsefilters: - lightboxlightbox: autolink-citations: yesknitr: opts_chunk: message: false warning: false collapse: true comment: "#>" R.options: knitr.graphics.auto_pdf: trueeditor_options: chunk_output_type: consolebibliography: bibliography.bibcsl: apa-single-spaced.csl ---# 백만~1억 사용자 {{< fa solid rocket >}}백만, 5천만, 1억 가입자를 가질 때까지 걸린 소요시간을 보면 chatGPT 의 영향력을 파악할 수 있다.:::{.panel-tabset}## 전화기부터![[@song2019digital]](images/time-to-reach-springer.png)## 기술 진화](images/hbr_trends.png)## chatGPT 백만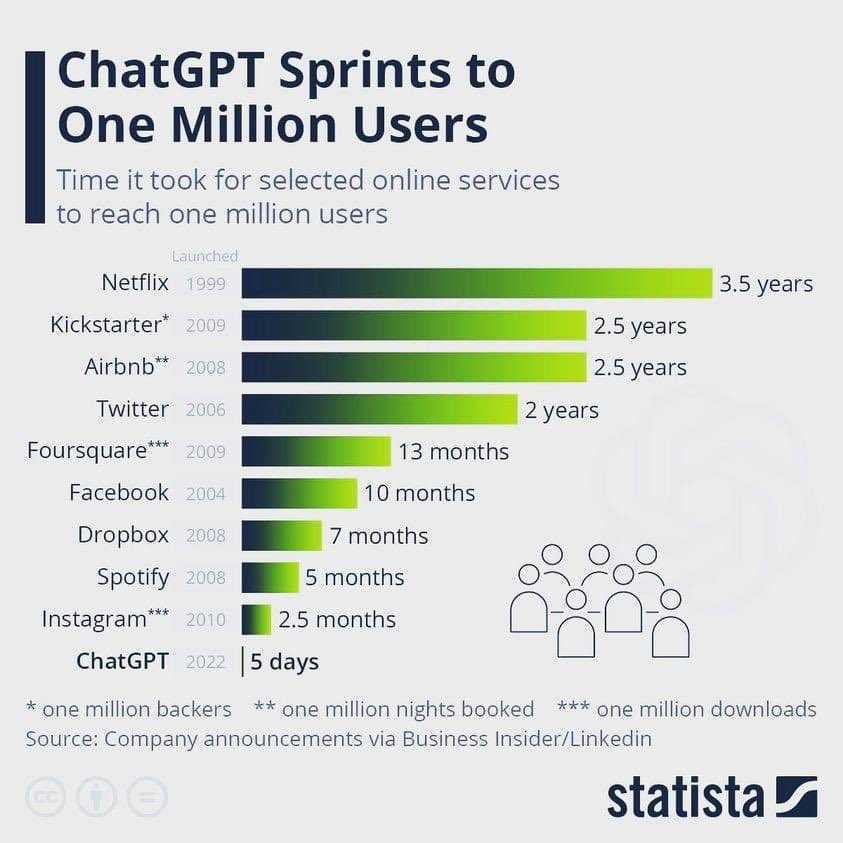## 빅3 서비스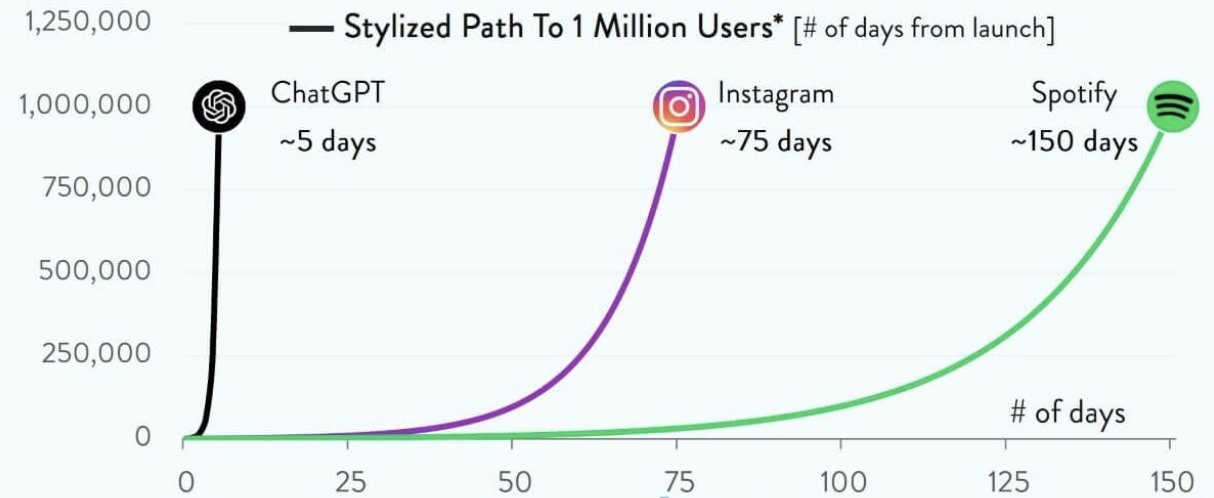## 1억명 (소요 달수)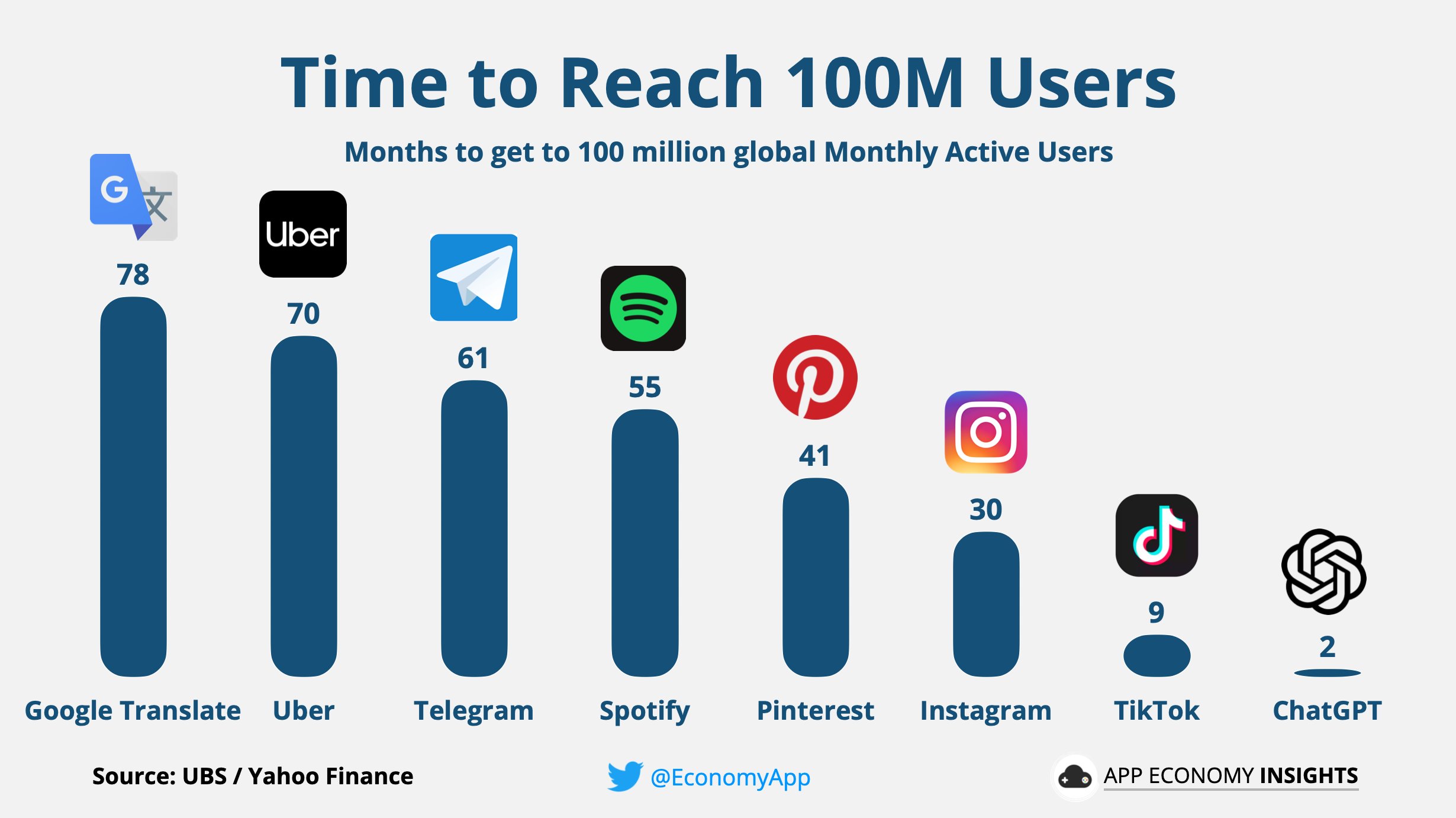:::# 데이터 {{< fa solid database >}}## 인터넷 데이터 {{< fa solid globe >}}GPT 개발에 자원에 해당되는 언어 데이터셋에 대해 살펴보자.위키백과 [Languages used on the Internet](https://en.wikipedia.org/wiki/Languages_used_on_the_Internet)에서 데이터를 확인해보자. 특히, 웹사이트 제작에 사용된 언어를 비중으로 살펴보자.```{r}#| eval: false## 언어 콘텐츠contents_raw <-read_html(x ='https://en.wikipedia.org/wiki/Languages_used_on_the_Internet') %>%html_element(xpath ='//*[@id="mw-content-text"]/div[1]/table[1]') %>%html_table() %>%set_names(c("순위", "언어", "비중"))contents_tbl <- contents_raw %>%mutate(비중 =parse_number(비중)) %>%## 대한민국 이하 기타 ------------mutate(언어 =ifelse(순위 >=17, "기타", 언어)) %>%group_by(언어) %>%summarise(비중 =sum(비중)) %>%ungroup() %>%arrange(desc(비중))contents_gt <- contents_tbl %>%## 표 gt() %>%gt_theme_nytimes() %>%tab_options(table.width =pct(75)) %>%tab_header(title =md("**인터넷 콘텐츠 상위 언어별 통계**"),subtitle ="한국어 포함 상위 17개 언어") %>%tab_source_note(source_note ="출처:https://en.wikipedia.org/wiki/Languages_used_on_the_Internet") %>%cols_align(align ="center",columns =c(언어, 비중)) %>%fmt_number(columns =c(비중),decimals =1 ) %>%cols_label( 비중 ="비중(%)" ) %>%tab_footnote(footnote ="한국어보다 비중이 낮은 인도네이사, 체코, 우크라이나 등",locations =cells_body(columns = 언어, rows =2) ) contents_gt %>%gtsave("images/contents_gt.png")```## GPT-3 언어 데이터 {{< fa solid brain >}}GPT-3 개발에 투입된 문서갯수를 언어별로 살펴보자.```{r}#| eval: truelibrary(tidyverse)library(gt)library(countrycode)library(rvest)library(gtExtras)## 언어 코드 lang_tbl <-read_html(x ='http://www.lingoes.net/en/translator/langcode.htm') %>%html_element(css ='body > table') %>%html_table() %>%set_names(c("언어", "언어명"))gpt_raw <-read_csv("https://raw.githubusercontent.com/openai/gpt-3/master/dataset_statistics/languages_by_document_count.csv")gpt_tbl <- gpt_raw %>%set_names(c("언어", "문서수", "비중")) %>%mutate(비중 =parse_number(비중) /100) %>%mutate(누적문서 =cumsum(문서수)) %>%mutate(누적비중 = 누적문서 /sum(문서수)) %>%top_n(문서수, n =28) gpt_gt <- gpt_tbl %>%left_join(lang_tbl, by ="언어") %>%select(언어, 언어명, 문서수, 비중, 누적비중) %>%## 표 gt() %>%gt_theme_nytimes() %>%tab_options(table.width =pct(100)) %>%tab_header(title =md("**GPT-3 언어모형 개발에 사용된 언어별 문서 통계**"),subtitle ="한국어 포함 상위 28개 언어") %>%tab_source_note(source_note ="자료출처: https://github.com/openai/gpt-3/blob/master/dataset_statistics/languages_by_document_count.csv") %>%tab_spanner(label ="언어코드와 언어명",columns =c(언어, 언어명)) %>%tab_spanner(label ="통계수치",columns =c(문서수, 비중, 누적비중)) %>%cols_align(align ="center",columns =c(언어, 언어명)) %>%# tab_style(# style = cell_text(size = px(12)),# locations = cells_body(# columns = c(문서수, 비중, 누적비중)# )# ) %>% fmt_percent(columns =c(비중, 누적비중),decimals =2 ) %>%fmt_number(columns = 문서수,decimals =0,sep_mark ="," ) %>%gt_highlight_rows(rows =c(1,28),fill ="lightgrey",target_col = 언어 ) %>%sub_missing(columns =everything(),missing_text ="-" ) %>%cols_width( 언어 ~px(10), 언어명 ~px(10), 문서수 ~px(20), 비중 ~px(30), 누적비중 ~px(30) )gpt_gt# gpt_gt %>%# gtsave("images/gpt_lang.png")```<!-- 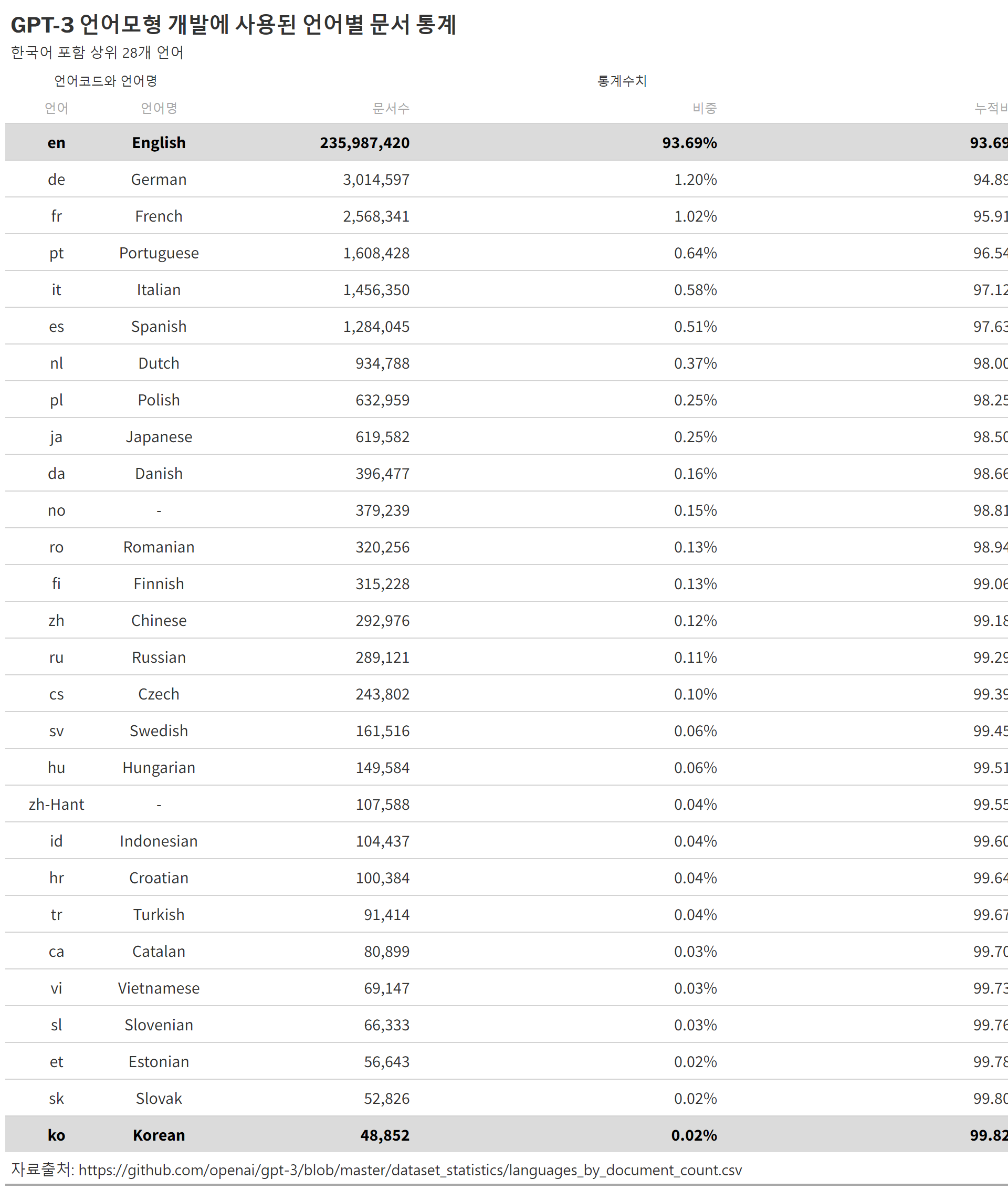 --># 구글 트렌드 {{< fa brands google >}}## chatGPT 이전Tensorflow, Keras, Pytorch, Fast.ai 가 차례로 등장하며 딥러닝 개발 프레임워크의 전성기를 구가했다.최근 5년동안 Google 추세를 살펴보자.```{r}#| eval: falselibrary(gtrendsR)extrafont::loadfonts()result <-gtrends(keyword =c("pytorch","fastai", "tensorflow", "keras"), geo ="", time="today+5-y", low_search_volume =TRUE)gtrends_framework_g <- result$interest_over_time %>%as_tibble() %>%mutate(keyword =factor(keyword, levels =c("keras", "pytorch", "tensorflow", "fastai"))) %>%mutate(hits =parse_number(hits)) %>%ggplot(aes(x = date, y = hits, color = keyword)) +geom_line() +theme_bw(base_family ="NanumBarunpen") +labs(x ="", y ="검색수",color ="프레임워크",title ="딥러닝 프레임워크 구글 검색 추세") +theme(legend.title =element_text(size =16),legend.text =element_text(size =14))# ragg always works for macragg::agg_png("images/dl_framework.png", width =297, height =210, units ="mm", res =300)gtrends_framework_gdev.off()```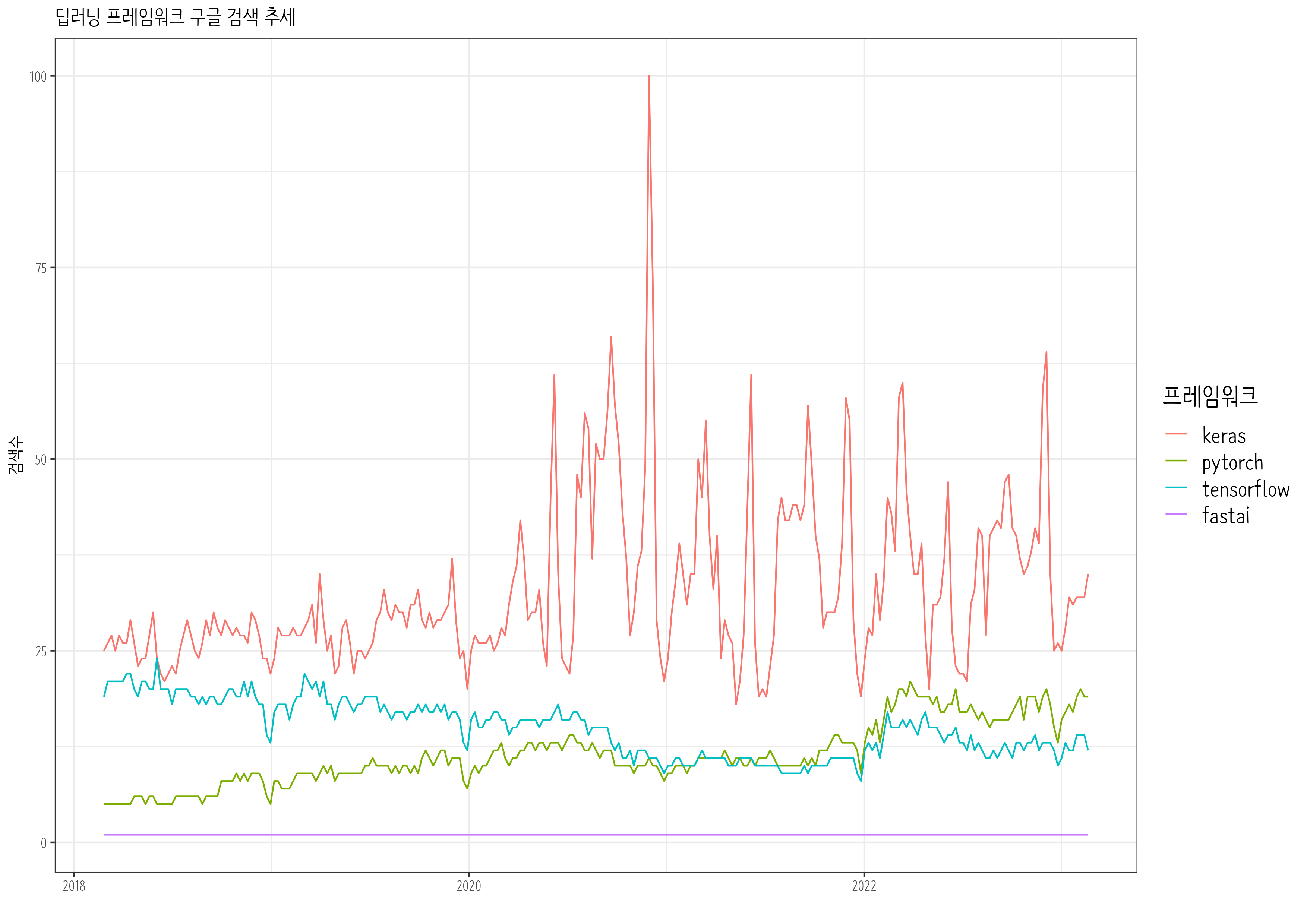## chatGPT 출현chatGPT 출현이후 Tensorflow, Keras, Pytorch, Fast.ai 는 어떻게 전개될 것인지최근 1년동안 Google 추세를 살펴보자.```{r}#| eval: falsechatGPT_result <-gtrends(keyword =c("pytorch","fastai", "tensorflow", "keras", "chatGPT"), geo ="", time="today 12-m", low_search_volume =TRUE)gtrends_chatGPT_g <- chatGPT_result$interest_over_time %>%as_tibble() %>%mutate(keyword =factor(keyword, levels =c("chatGPT", "keras", "pytorch", "tensorflow", "fastai"))) %>%mutate(hits =parse_number(hits)) %>%mutate(date =as.Date(date)) %>%ggplot(aes(x = date, y = hits, color = keyword)) +geom_line() +theme_bw(base_family ="NanumBarunpen") +labs(x ="", y ="검색수",color ="프레임워크",title ="chatGPT와 딥러닝 프레임워크 구글 검색 추세") +scale_x_date(date_labels ="%Y-%m") +theme(legend.title =element_text(size =16),legend.text =element_text(size =14))# ragg always works for macragg::agg_png("images/chatGPT_framework.png", width =297, height =210, units ="mm", res =300)gtrends_chatGPT_gdev.off()```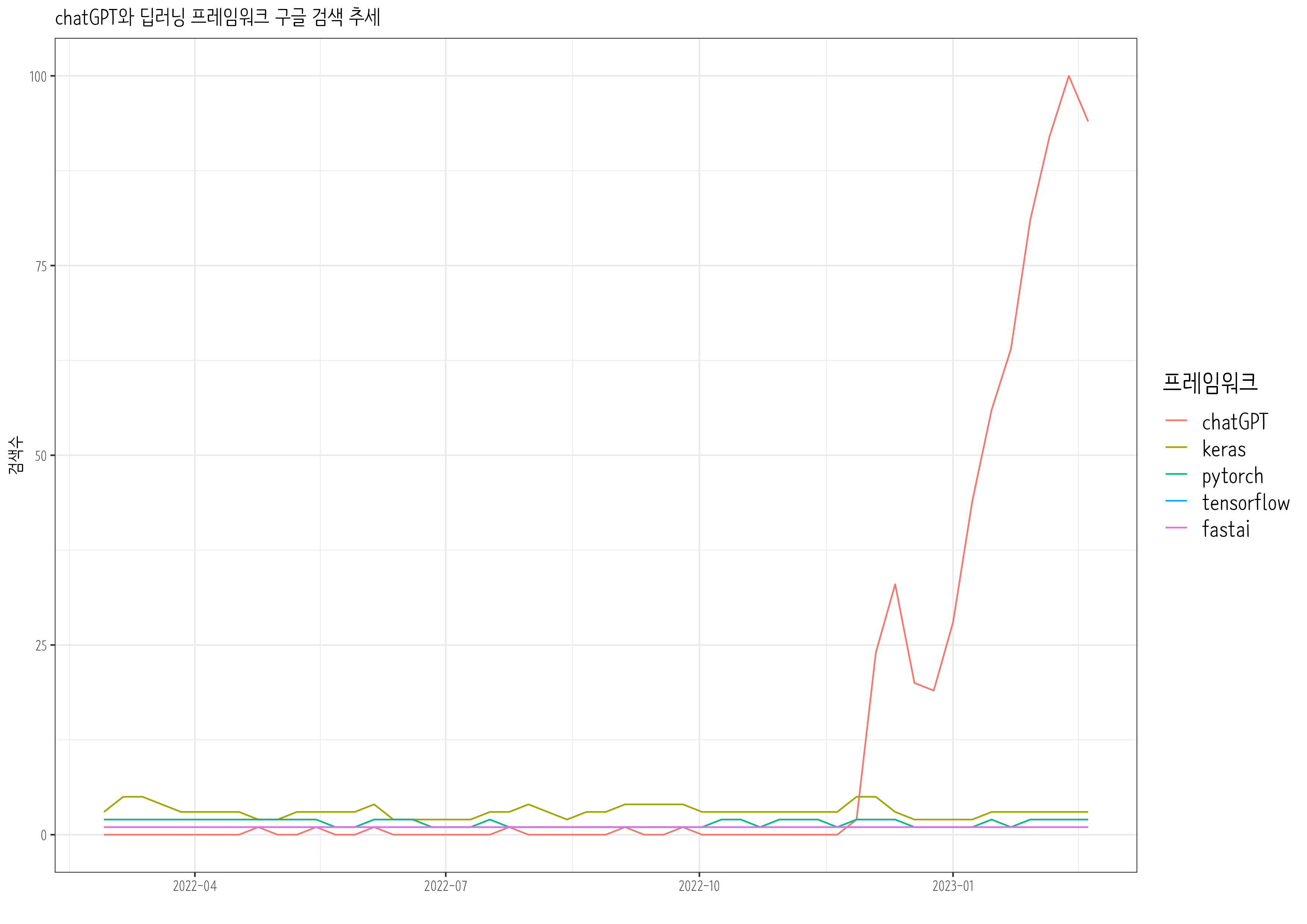## 파이썬과 chatGPTchatGPT 출현이후 파이썬, tensorflow, pytorch 최근 1년동안 Google 추세를 살펴보자.```{r}#| eval: falsepython_result <-gtrends(keyword =c("chatGPT", "pytorch","python", "tensorflow", "keras"), geo ="", time="today 12-m", low_search_volume =TRUE)python_chatGPT_g <- python_result$interest_over_time %>%as_tibble() %>%mutate(keyword =factor(keyword, levels =c("chatGPT", "python", "keras", "pytorch", "tensorflow"))) %>%mutate(hits =parse_number(hits)) %>%mutate(date =as.Date(date)) %>%ggplot(aes(x = date, y = hits, color = keyword)) +geom_line() +theme_bw(base_family ="NanumBarunpen") +labs(x ="", y ="검색수",color ="프레임워크",title ="파이썬, chatGPT, 주요 딥러닝 프레임워크 구글 검색 추세") +scale_x_date(date_labels ="%Y-%m") +theme(legend.title =element_text(size =16),legend.text =element_text(size =14))# ragg always works for macragg::agg_png("images/python_chatGPT_g.png", width =297, height =210, units ="mm", res =300)python_chatGPT_gdev.off()```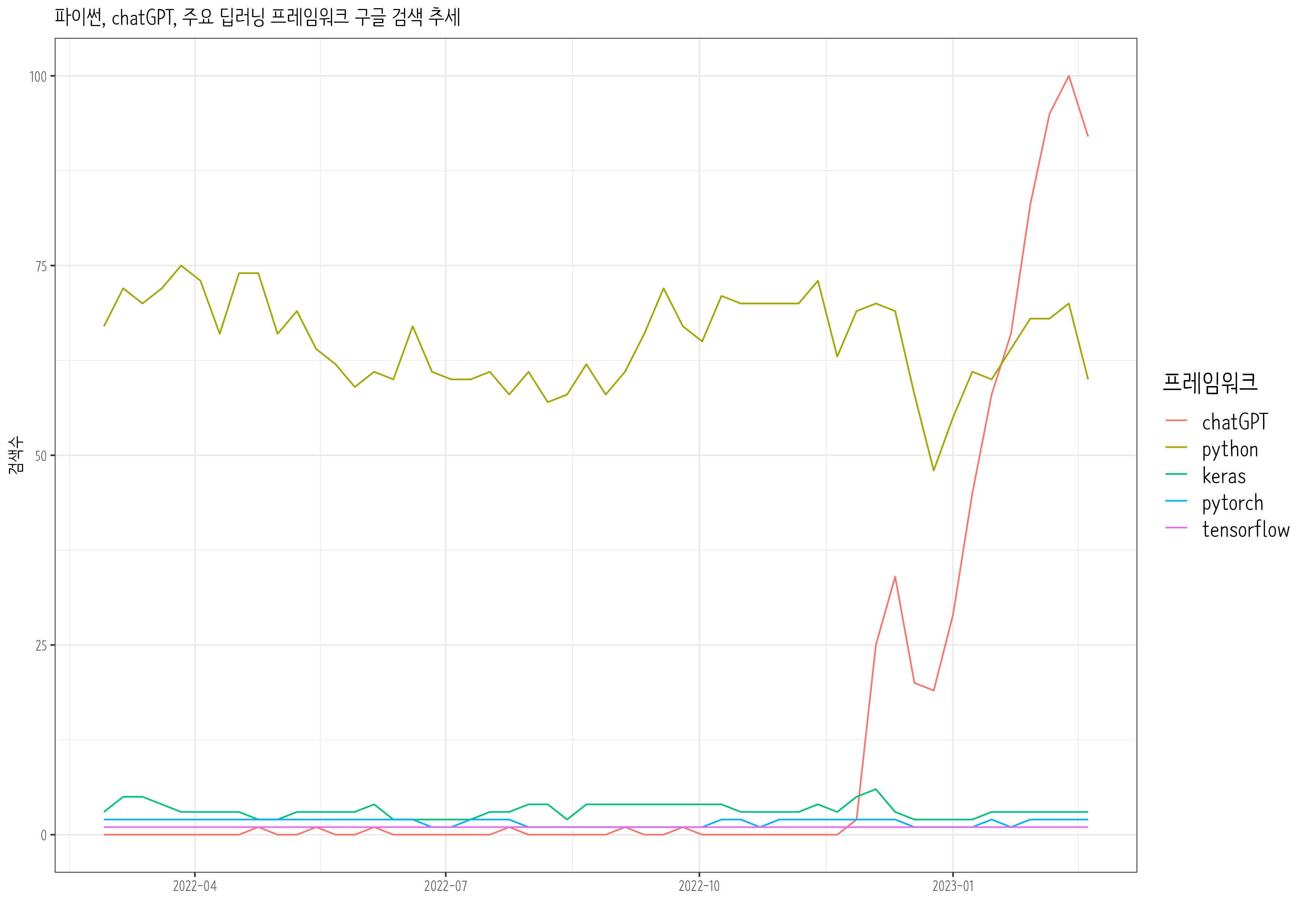# 주요회사 {{< fa brands windows >}}[출처: [CBInsights (January 25, 2023), "The state of generative AI in 7 charts"](https://www.cbinsights.com/research/generative-ai-funding-top-startups-investors/)]{.aside}생성 AI 분야 활동하고 있는 기업과 투자금액, 활동분야가 `CBInsights` 보고서를 통해 공개되었다.:::{.panel-tabset}## 생성 AI 회사## 생성 AI 회사 투자금액## 생성 AI 회사 활동분야:::[[생성 AI 상세](https://docs.google.com/spreadsheets/d/14rYP2H31-MmZFeYF_BsLTeArnasZ31JJPEo46fmBjLQ/edit?usp=sharing)]{.aside}# 프롬프트 시장[Promptbase.com](https://promptbase.com/)은 사람들이 글을 쓸 주제에 대한 아이디어를 떠올릴 수 있도록 도와주는 웹사이트입니다. 막막할 때 무엇을 써야 할지 모를 때 많은 제안을 해줄 수 있는 정말 똑똑한 친구가 있는 것과 같습니다.따라서 학교 프로젝트나 에세이를 작성 중이거나 그냥 재미로 글을 쓰고 싶을 때 Promptbase.com으로 이동하면 다양한 아이디어를 선택할 수 있습니다. 가장 마음에 드는 것을 골라 글쓰기를 시작하면 됩니다!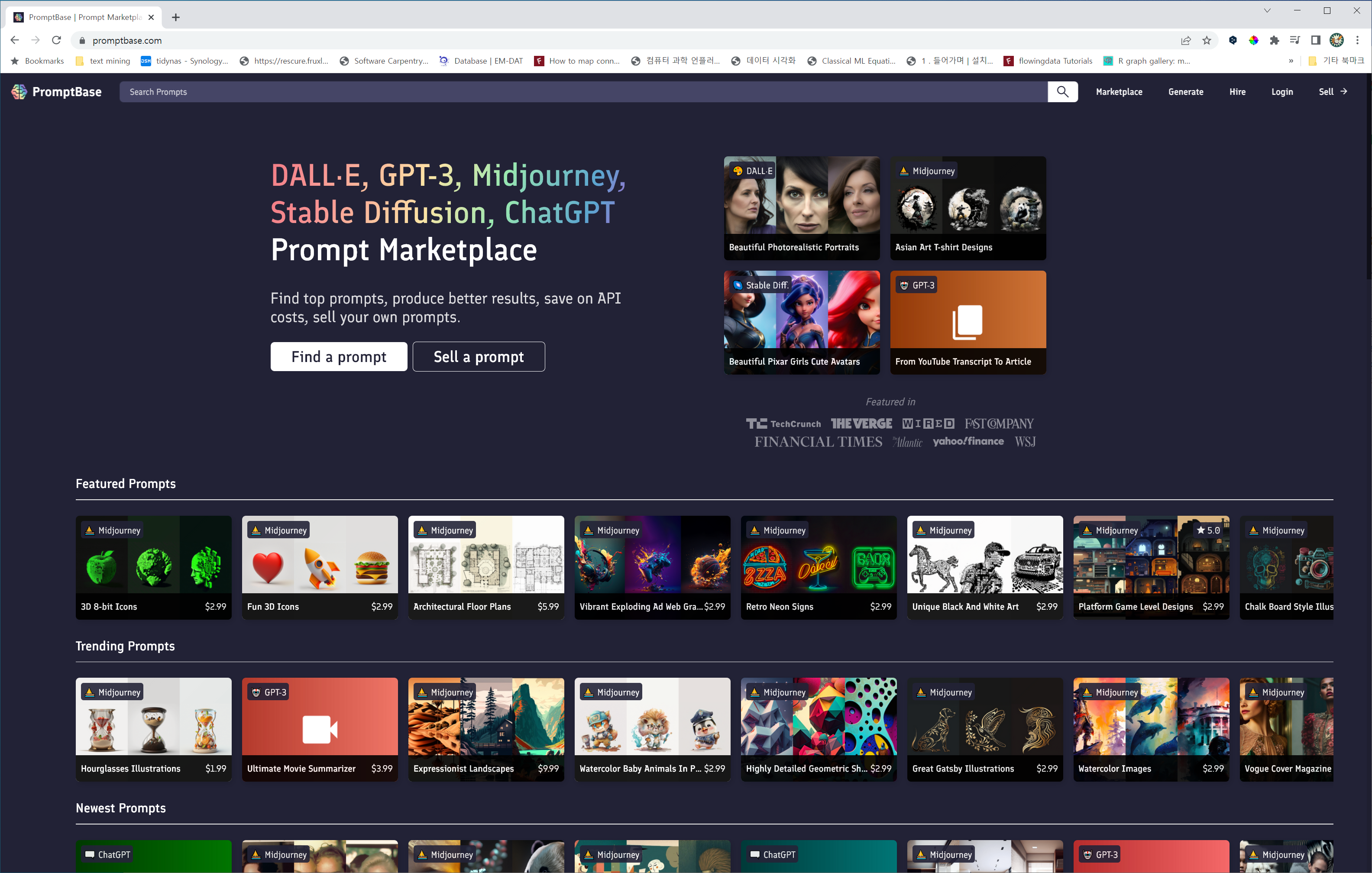# AI를 바라보는 관점AI를 바라보는 다양한 관점이 존재한다.## 트위터 샌티아고[Santiago `@svpino`](https://twitter.com/svpino):::{#santiago layout-ncol=2}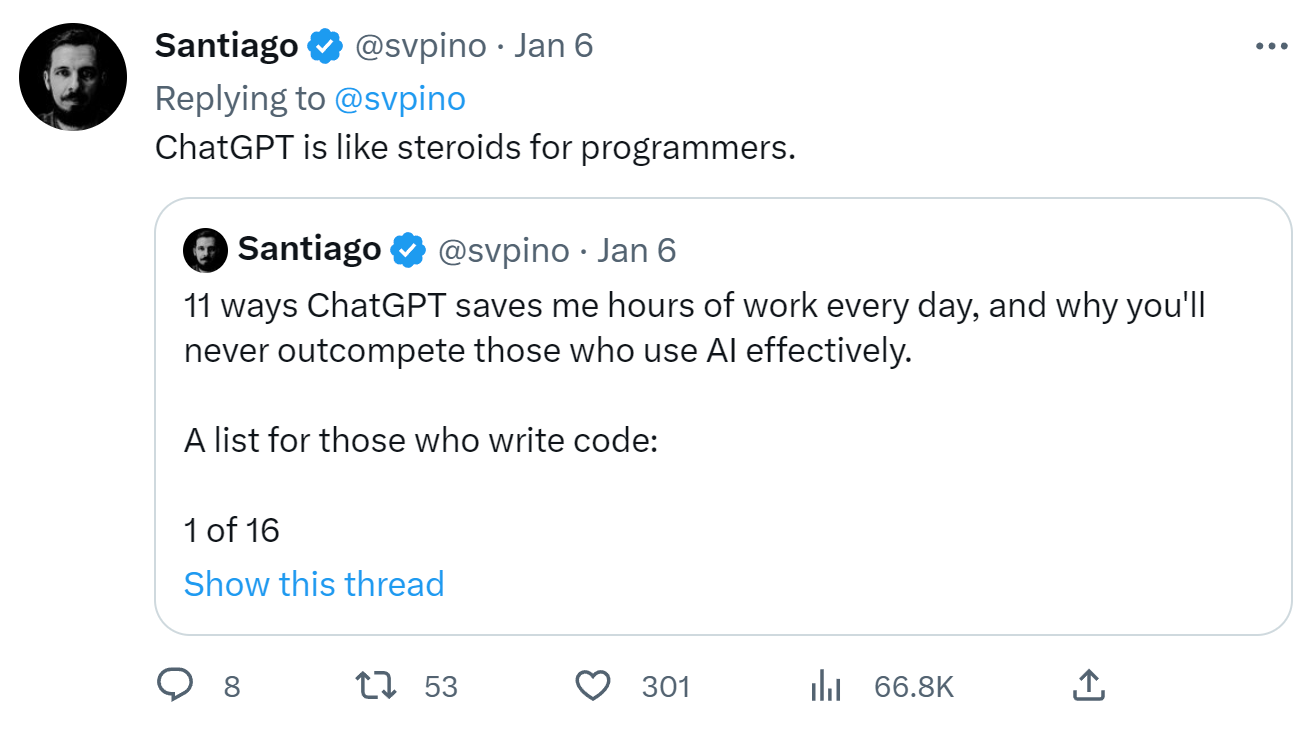:::## 버스탄 두남자# AI 생산성 현장## 현대백화점현대백화점 관계자는 “이 달 초부터 2주간 시행한 관련 부처 테스트에서 통상 2주가량 소요되던 카피라이팅 업무시간이 루이스 도입 뒤 평균 3~4시간으로 줄었다”[[유선희 (2023-02-26), 광고 카피도 AI가 쓴다…현대백화점 ‘루이스’ 시스템 도입, 한겨레신문](https://www.hani.co.kr/arti/economy/economy_general/1081222.html)]{.aside}현대백화점이 광고 카피와 판촉행사 소개문 등 마케팅 문구 제작을 위해 특별히 ‘고용’한 인공지능(AI) 카피라이팅 시스템은 네이버 ‘하이버클로바’를 기본 엔진으로 추가학습(최근 3년 동안 사용한 광고 카피, 판촉행사에서 쓴 문구 중 소비자 호응이 컸던 데이터 1만여건을 집중적으로 학습)하여 개발:::{.panel-tabset}### AI 직원### 활용화면### 루이스:::## 마이크로소프트:::: {.columns}::: {.column width="60%"}:::::: {.column width="40%"}- 신규 코드의 **40%**가 Copilot으로 작성- **75%의 개발자**가 업무에 더 큰 성취감을 느꼈습니다.- **87%의 개발자**가 정신적 노력을 절약하는 데 도움이 되었다고 답했습니다.:::::::## 이미지웹툰을 제작하는 스튜디오에서는 웹툰 작가들과 어시스트들이 매우 노동집약적인 작업으로 창작활동을 하고 있다.현재 웹툰 제작 공정은 콘티, 스케치, 라인(펜선), 채색, 배경, 출판 작업의 순서로 이뤄진다.한국만화영상진흥원과 협력하는 실제 웹툰 작가들은 특정작업이 아닌 모든 공정에서 제작 생산성 향상을 위한 자동화 기술이 필요하다는 결론에 도달함. [@webtoon2021]# 시장 와해 사례 {{< fa solid book >}}## 공상과학소설공상과학 및 판타지 잡지 클라크스월드(Clarkesworld)는 AI가 생성한 소설라는 비난을 받은 후 신규 공상과학소설이 급증한 것이 AI 기계로 작성된 원인을 큰 것으로 파악하고 2월 20일부터 공식적으로 투고를 중단했다. [[Neil Clark (2023-02-15), "A Concerning Trend", CLARKESWORLD MAGAZINE](http://neil-clarke.com/a-concerning-trend/)]{.aside}:::{#sci-fiction layout-ncol=2}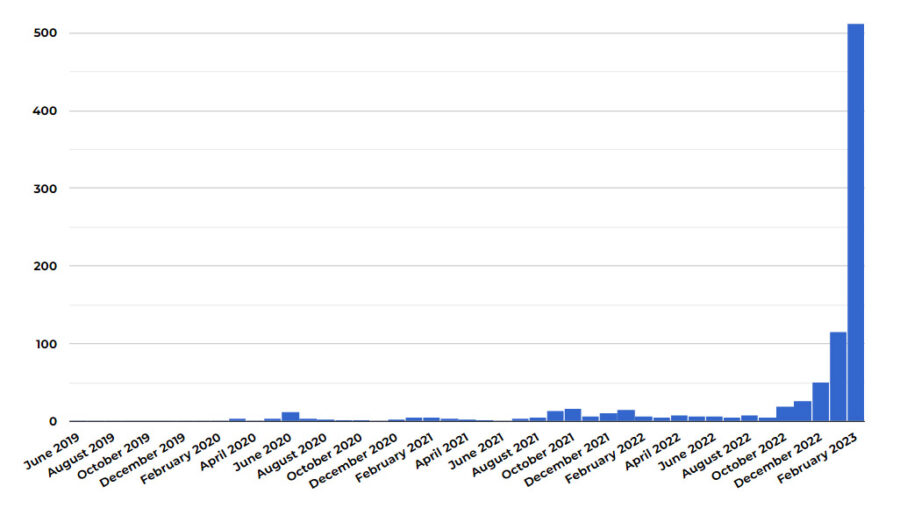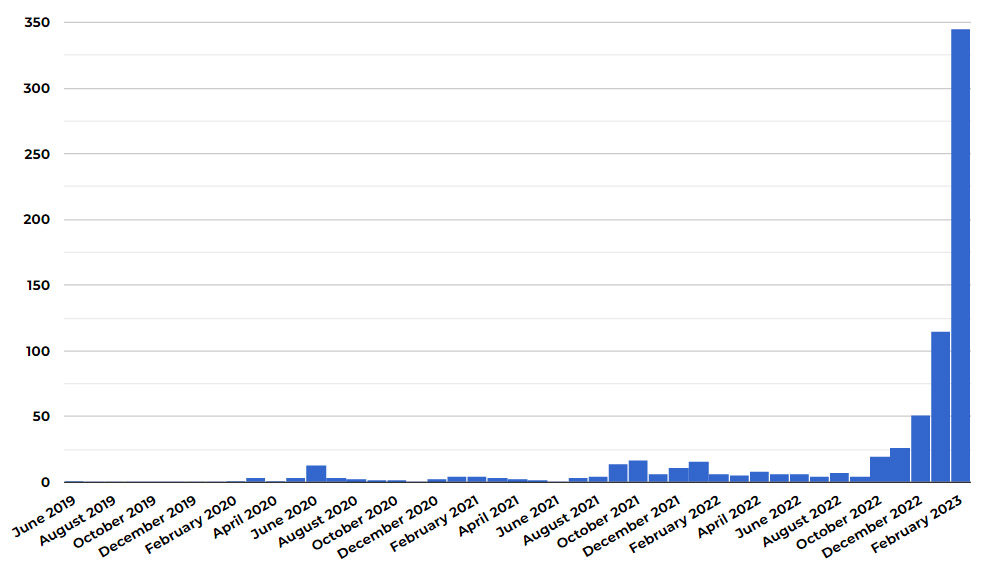:::