코드
library(Convert2Docx)
Converter(pdf_file = "data/2303.08774.pdf",
docx_filename = "data/2303.08774.docx")arXiv GPT-4 Technical Report 보고서를 다운로드 받아 PDF 보고서에서 GPT-4 성능을 평가해보자. (OpenAI, 2023)
PDF 문서를 Convert2Docx 패키지를 활용하여 워드파일로 변환시킨다. 페이지가 많아 제법 시간이 소요된다.
library(Convert2Docx)
Converter(pdf_file = "data/2303.08774.pdf",
docx_filename = "data/2303.08774.docx")docxtractr 패키지를 설치하고 docx_extract_tbl() 함수로 PDF 파일에 담긴 표를 추출한다.
library(docxtractr)
gpt_docx <- docxtractr::read_docx("data/2303.08774.docx")
tbl_01 <- docx_extract_tbl(gpt_docx, 3) %>%
janitor::clean_names()
tbl_01
#> # A tibble: 34 × 4
#> exam gpt_4 gpt_4_no_vision gpt_3_5
#> <chr> <chr> <chr> <chr>
#> 1 Uniform Bar Exam (MBE+MEE+MPT) 298 /… 298 / 400 (~90… 213 / …
#> 2 LSAT 163 (… 161 (~83rd) 149 (~…
#> 3 SAT Evidence-Based Reading & Writing 710 /… 710 / 800 (~93… 670 / …
#> 4 SAT Math 700 /… 690 / 800 (~89… 590 / …
#> 5 Graduate Record Examination (GRE) Quantitative 163 /… 157 / 170 (~62… 147 / …
#> 6 Graduate Record Examination (GRE) Verbal 169 /… 165 / 170 (~96… 154 / …
#> 7 Graduate Record Examination (GRE) Writing 4 / 6… 4 / 6 (~54th) 4 / 6 …
#> 8 USABO Semifinal Exam 2020 87 / … 87 / 150 (99th… 43 / 1…
#> 9 USNCO Local Section Exam 2022 36 / … 38 / 60 24 / 60
#> 10 Medical Knowledge Self-Assessment Program 75 % 75 % 53 %
#> # ℹ 24 more rowsLSAT 시험과 Uniform Bar Exam 시험은 두 가지 다른 시험이다. LSAT은 로스쿨 입학을 위한 시험이며, Uniform Bar Exam은 변호사 자격증을 얻기 위한 시험이다.
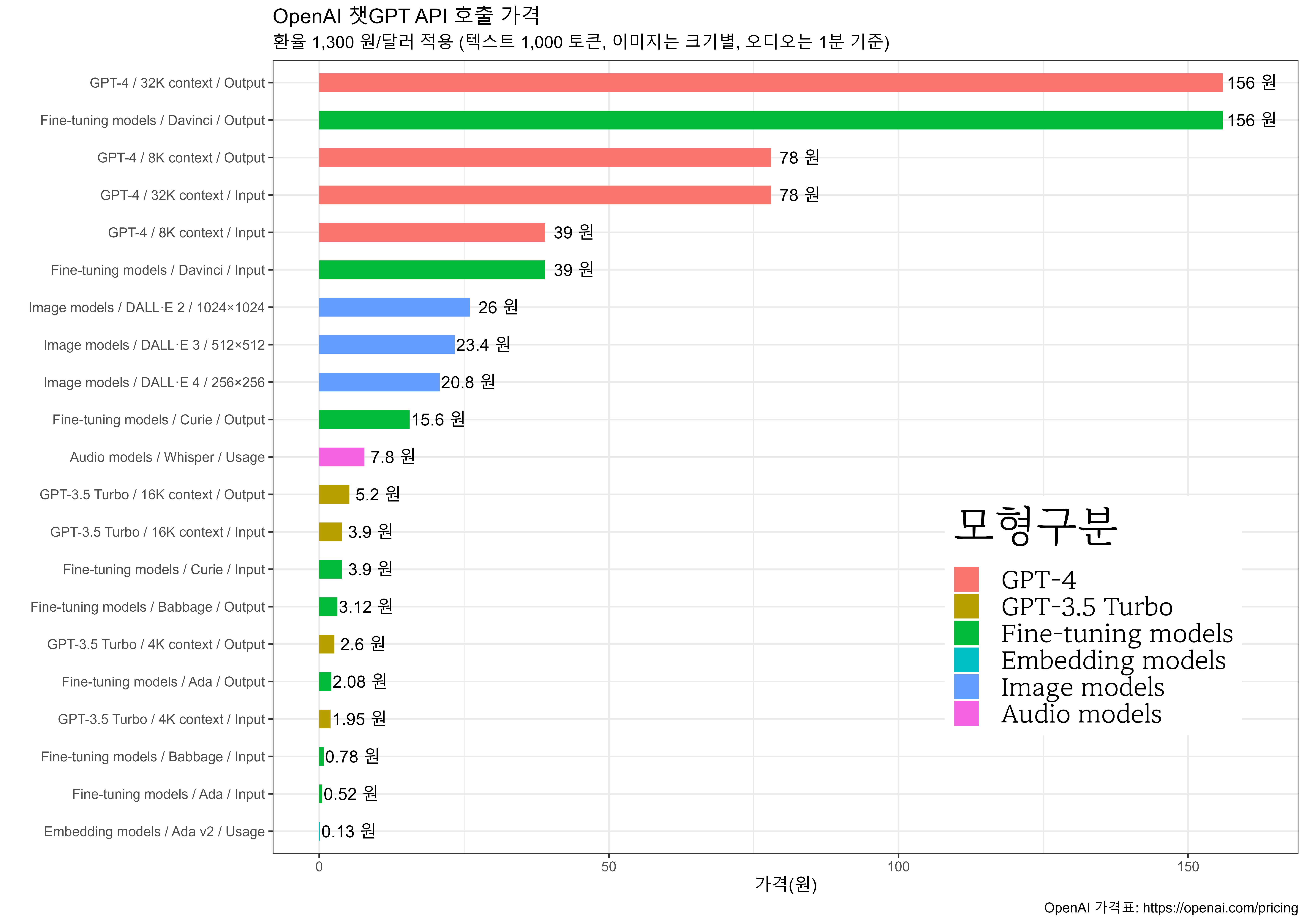
해당 데이터에서 GPT-4 LSAT 성적을 뽑아내서 미국 로스쿨 대학별 입학점수와 비교해보자.
| exam | gpt_4 | gpt_3_5 |
|---|---|---|
| Uniform Bar Exam (MBE+MEE+MPT) | 298 / 400 (~90th) | 213 / 400 (~10th) |
| LSAT | 163 (~88th) | 149 (~40th) |
publiclegal 웹사이트에서 2020 Raw Data Law School Rankings 데이터와 결합시켜 GPT-4 실력을 갈음해보자. 상위 10여개 대학을 제외하고 로스쿨 입학에 큰 문제는 없어보이는 실력을 보여주고 있다.
library(rvest)
extrafont::loadfonts()
lsat_raw <- read_html('https://www.ilrg.com/rankings/law/')
lsat_tbl <- lsat_raw %>%
html_elements('.table-responsive') %>%
html_table(header = TRUE) %>%
.[[1]] %>%
janitor::row_to_names(1) %>%
janitor::clean_names()
lsat_rank <- lsat_tbl %>%
pull(law_school) %>% dput()
lsat_g <- lsat_tbl %>%
select(no, law_school, lsat_low, lsat_median, lsat_high) %>%
mutate(law_school = factor(law_school, levels = lsat_rank) %>% fct_rev) %>%
mutate_if(is.character, as.integer) %>%
ggplot(aes(x = law_school, y = lsat_median, group=law_school)) +
geom_point() +
geom_linerange(aes(ymin = lsat_low, ymax= lsat_high), colour = "blue") +
geom_hline(yintercept=163, linetype='dotted', col = 'red')+
annotate("text", x = "New York University", y = 163, size =5, label = "GPT-4", hjust = 1.1,
color = "red") +
coord_flip() +
theme_bw(base_family = "MaruBuri Bold") +
labs(x = "",
y = "",
title = "미국 변호사 입학시험 점수(LSAT)",
subtitle = "LSAT 중위점수 및 하한과 상한",
caption = "2020 Law School Rankings, https://www.ilrg.com/rankings/law/")
ragg::agg_png("images/lsat_g.png", width = 297, height = 210, units = "mm", res = 600)
lsat_g
dev.off()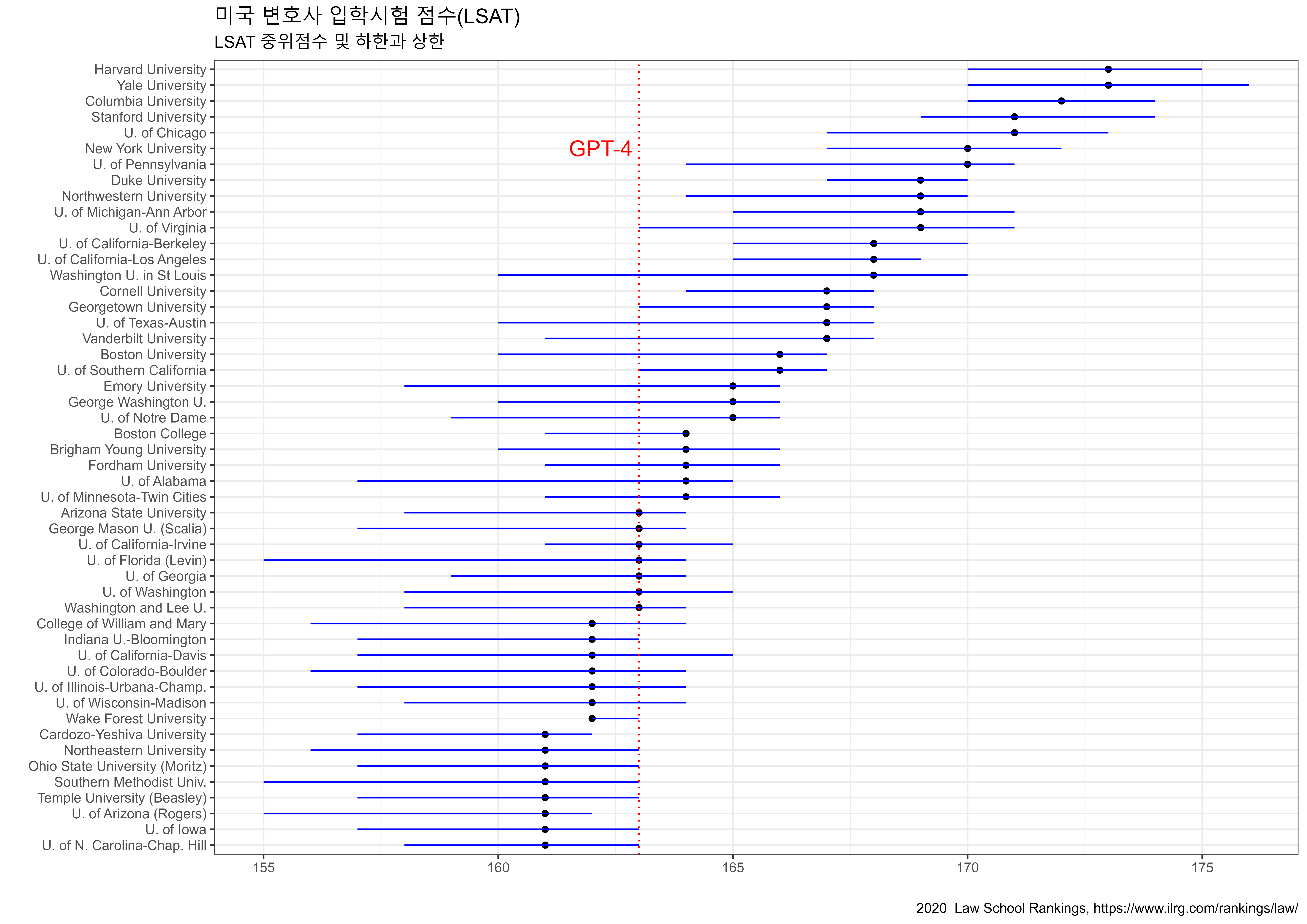
GRE (Graduate Record Examination)는 미국의 대학원 수학 자격시험으로 미국 대학원에 유학 할 때 필요하다. MBA 나 로스쿨 등 전문대학원은 이 시험 대신 LSAT 나 GMAT 점수가 필요하다.
| exam | gpt_4 | gpt_3_5 |
|---|---|---|
| Graduate Record Examination (GRE) Quantitative | 163 / 170 (~80th) | 147 / 170 (~25th) |
| Graduate Record Examination (GRE) Verbal | 169 / 170 (~99th) | 154 / 170 (~63rd) |
| Graduate Record Examination (GRE) Writing | 4 / 6 (~54th) | 4 / 6 (~54th) |
Average scores and standard deviations on Graduate Record Examination (GRE) general and subject tests: 1965 through 2016 을 통해 2016년도 GRE 점수를 GPT-4와 비교해보자.
gre_g <- ggplot() +
labs(x = 'Data', y = 'Density') +
stat_function(fun = dnorm, args = list(mean = 150, sd = 8.5), size = 1,
aes(color = "GRE Quantitative")) +
geom_vline(xintercept = 163, size = 1) +
stat_function(fun = dnorm, args = list(mean = 153, sd = 9.0), size = 1,
aes(color = "GRE Verbal")) +
geom_vline(xintercept = 169, size = 1, color = "red") +
scale_x_continuous(limits = c(120,180)) +
scale_colour_manual("GRE 시험", values = c("black", "red")) +
theme_bw(base_family = "MaruBuri Bold") +
labs(x = "GRE 점수",
y = "밀도",
title = "GPT-4 GRE Quantitative / Verbal 역량",
subtitle = "2016년 GRE 평균과 표준편차 반영 정규분포",
caption = "Average scores and standard deviations on Graduate Record Examination (GRE), https://nces.ed.gov/programs/digest/d18/tables/dt18_327.10.asp") +
theme(legend.position = "top") +
annotate("text", x = 175, y = 0.045, label = "GPT-4", size = 7, color = "blue")
ragg::agg_png("images/gre_g.png", width = 297, height = 210, units = "mm", res = 600)
gre_g
dev.off()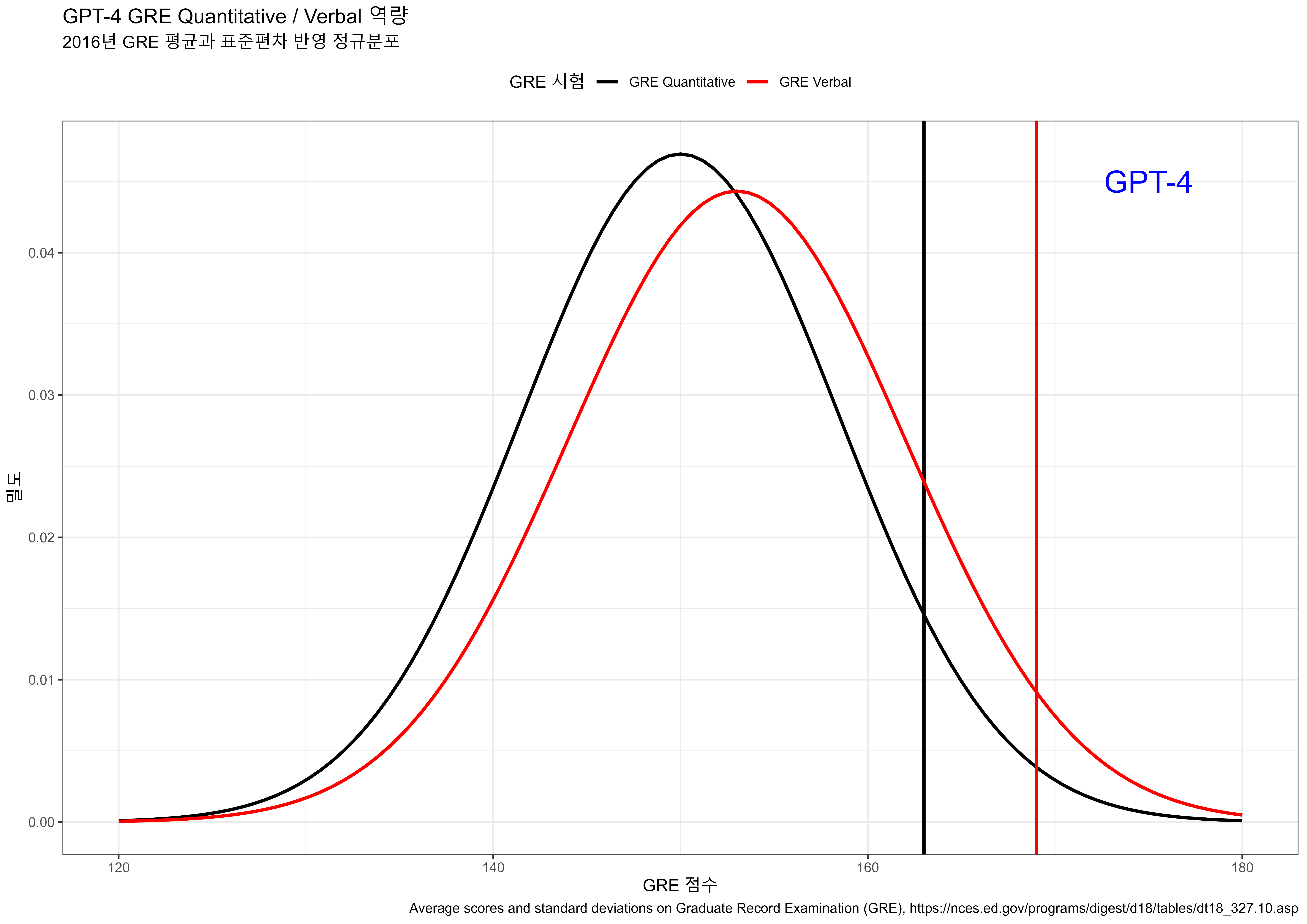
Advanced Placement (AP)는 미국의 College Board가 만든 프로그램으로 고등학생들에게 대학 수준의 교육과정과 시험을 제공합니다. 미국의 대학과 대학들은 시험에서 높은 점수를 얻은 학생들에게 배치와 학점 인정을 한다. AP를 통해 학생들이 고등학교에 다니면서 대학 수준의 작업을 다루고 대학 학점 및 배치를 얻을 수 있는 기회를 제공한다.
AMC 10은 미국 수학 협회가 주최하는 수학 대회로, 10학년 이하의 학생들을 대상으로 한다. 이 시험은 고등학교 교육과정 중 10학년까지의 내용을 다룹니다1. AMC 10은 AMC 12와 함께 미국이 국제 수학 올림피아드 (IMO)에 참가하는 팀을 선발하기 위한 일련의 시험 중 첫 번째 시험이다.
AMC 12는 미국 수학 협회가 주최하는 수학 대회로, 12학년 이하의 학생들을 대상으로 한다. 이 시험은 고등학교 전 과정을 다루지만 Calculus 부분은 제외됩니다1. AMC 12는 AMC 10과 함께 미국이 국제 수학 올림피아드 (IMO)에 참가하는 팀을 선발하기 위한 일련의 시험 중 하나다.
library(gt)
library(gtExtras)
tbl_01 %>%
select(-3) %>%
mutate(type = case_when( str_detect(exam, "Bar|LSAT") ~ "법",
str_detect(exam, "SAT ") ~ "수능",
str_detect(exam, "GRE") ~ "대학원",
str_detect(exam, "USABO|USNCO") ~ "고등 경진대회",
str_detect(exam, "Medical") ~ "헬스케어",
str_detect(exam, "Codeforces|Leetcode") ~ "코딩",
str_detect(exam, "Sommelier") ~ "소믈리에",
str_detect(exam, "^AP ") ~ "AP 시험",
str_detect(exam, "^AMC ") ~ "수학시험",
TRUE ~ "기타"
)) %>%
group_by(type) %>%
gt( rowname_col = "exam") %>%
gt_theme_nytimes() %>%
tab_header(
title = "GPT-4 성능",
subtitle = "OpenAI GPT-4 Technical Report") %>%
cols_align(
align = "center",
columns = everything()) %>%
gt_highlight_rows(
rows = type == "코딩",
fill = "lightgrey",
bold_target_only = TRUE,
target_col = gpt_4
) %>%
gt_highlight_rows(
rows = type == "수학시험",
fill = "lightgrey",
bold_target_only = TRUE,
target_col = gpt_4
) %>%
gt_highlight_rows(
rows = str_detect(exam, "English|\\) Writing|USNCO"),
fill = "lightgrey",
bold_target_only = TRUE,
target_col = gpt_4
) %>%
opt_table_font(
font = list(
google_font(name = 'Gowun Dodum')
)
)| GPT-4 성능 | ||
| OpenAI GPT-4 Technical Report | ||
| gpt_4 | gpt_3_5 | |
|---|---|---|
| 법 | ||
| Uniform Bar Exam (MBE+MEE+MPT) | 298 / 400 (~90th) | 213 / 400 (~10th) |
| LSAT | 163 (~88th) | 149 (~40th) |
| 수능 | ||
| SAT Evidence-Based Reading & Writing | 710 / 800 (~93rd) | 670 / 800 (~87th) |
| SAT Math | 700 / 800 (~89th) | 590 / 800 (~70th) |
| 대학원 | ||
| Graduate Record Examination (GRE) Quantitative | 163 / 170 (~80th) | 147 / 170 (~25th) |
| Graduate Record Examination (GRE) Verbal | 169 / 170 (~99th) | 154 / 170 (~63rd) |
| Graduate Record Examination (GRE) Writing | 4 / 6 (~54th) | 4 / 6 (~54th) |
| 고등 경진대회 | ||
| USABO Semifinal Exam 2020 | 87 / 150 (99th - 100th) | 43 / 150 (31st - 33rd) |
| USNCO Local Section Exam 2022 | 36 / 60 | 24 / 60 |
| 헬스케어 | ||
| Medical Knowledge Self-Assessment Program | 75 % | 53 % |
| 코딩 | ||
| Codeforces Rating | 392 (below 5th) | 260 (below 5th) |
| Leetcode (easy) | 31 / 41 | 12 / 41 |
| Leetcode (medium) | 21 / 80 | 8 / 80 |
| Leetcode (hard) | 3 / 45 | 0 / 45 |
| AP 시험 | ||
| AP Art History | 5 (86th - 100th) | 5 (86th - 100th) |
| AP Biology | 5 (85th - 100th) | 4 (62nd - 85th) |
| AP Calculus BC | 4 (43rd - 59th) | 1 (0th - 7th) |
| AP Chemistry | 4 (71st - 88th) | 2 (22nd - 46th) |
| AP English Language and Composition | 2 (14th - 44th) | 2 (14th - 44th) |
| AP English Literature and Composition | 2 (8th - 22nd) | 2 (8th - 22nd) |
| AP Environmental Science | 5 (91st - 100th) | 5 (91st - 100th) |
| AP Macroeconomics | 5 (84th - 100th) | 2 (33rd - 48th) |
| AP Microeconomics | 5 (82nd - 100th) | 4 (60th - 82nd) |
| AP Physics 2 | 4 (66th - 84th) | 3 (30th - 66th) |
| AP Psychology | 5 (83rd - 100th) | 5 (83rd - 100th) |
| AP Statistics | 5 (85th - 100th) | 3 (40th - 63rd) |
| AP US Government | 5 (88th - 100th) | 4 (77th - 88th) |
| AP US History | 5 (89th - 100th) | 4 (74th - 89th) |
| AP World History | 4 (65th - 87th) | 4 (65th - 87th) |
| 수학시험 | ||
| AMC 103 | 30 / 150 (6th - 12th) | 36 / 150 (10th - 19th) |
| AMC 123 | 60 / 150 (45th - 66th) | 30 / 150 (4th - 8th) |
| 소믈리에 | ||
| Introductory Sommelier (theory knowledge) | 92 % | 80 % |
| Certified Sommelier (theory knowledge) | 86 % | 58 % |
| Advanced Sommelier (theory knowledge) | 77 % | 46 % |
OpenAI Pricing 웹사이트에서 API 호출 당 가격을 확인할 수 있다. 2023년 4월에 계산한 가격과 2023년 7월 가격을 비교해보자.
웹사이트에 게시된 가격표를 크롤링하여 엑셀파일로 정리한다.
library(readxl)
library(tidyverse)
price_raw <- read_excel("data/openai_pricing.xlsx", sheet="price")
price <- price_raw %>%
janitor::clean_names(ascii = FALSE) %>%
select(-description) %>%
separate(가격, into = c("가격", "단위"), sep = "/") %>%
mutate(가격 = parse_number(가격) *1300, # 환율 1,300 / 달러 적용
단위 = str_squish(단위))
price %>%
gt::gt() %>%
gtExtras::gt_theme_espn()| 모형구분 | model | 작업 | 가격 | 단위 |
|---|---|---|---|---|
| GPT-4 | 8K context | Prompt | 39.00 | 1K tokens |
| GPT-4 | 32K context | Prompt | 78.00 | 1K tokens |
| GPT-4 | 8K context | Completion | 78.00 | 1K tokens |
| GPT-4 | 32K context | Completion | 156.00 | 1K tokens |
| Chat | gpt-3.5-turbo | Prompt | 2.60 | 1K tokens |
| InstructGPT | Ada | Prompt | 0.52 | 1K tokens |
| InstructGPT | Babbage | Prompt | 0.65 | 1K tokens |
| InstructGPT | Curie | Prompt | 2.60 | 1K tokens |
| InstructGPT | Davinci | Prompt | 26.00 | 1K tokens |
| Fine-tuning models | Ada | Prompt | 0.52 | 1K tokens |
| Fine-tuning models | Babbage | Prompt | 0.78 | 1K tokens |
| Fine-tuning models | Curie | Prompt | 3.90 | 1K tokens |
| Fine-tuning models | Davinci | Prompt | 39.00 | 1K tokens |
| Fine-tuning models | Ada | Usage | 2.08 | 1K tokens |
| Fine-tuning models | Babbage | Usage | 3.12 | 1K tokens |
| Fine-tuning models | Curie | Usage | 15.60 | 1K tokens |
| Fine-tuning models | Davinci | Usage | 156.00 | 1K tokens |
| Embedding models | Ada | Prompt | 0.52 | 1K tokens |
| Image models | 1024×1024 | Prompt | 26.00 | image |
| Image models | 512×512 | Prompt | 23.40 | image |
| Image models | 256×256 | Prompt | 20.80 | image |
| Audio models | Whisper | Prompt | 7.80 | minute |
OpenAI 가격을 원화(1,300원)로 변환시켜 API 호출별 체감되는 가격을 시각화한다.
extrafont::loadfonts()
pricing_g <- price %>%
mutate(모형상세 = glue::glue("{모형구분} / {model} / {작업}") %>% as.character(.)) %>%
mutate(모형구분 = factor(모형구분, levels=c("GPT-4","Fine-tuning models", "Image models", "Audio models",
"InstructGPT", "Chat", "Embedding models") )) %>%
ggplot(aes(x = fct_reorder(모형상세, 가격), y = 가격, fill = 모형구분)) +
geom_col(width = 0.5) +
# facet_wrap(~모형구분, scales = "free_y") +
coord_flip() +
geom_text(aes(x = 모형상세, y = 가격, label = glue::glue("{가격} 원") ), nudge_y = 5) +
theme_bw(base_family = "MaruBuri Bold") +
labs(title = "OpenAI 챗GPT API 호출 가격",
subtitle = "환율 1,300 원/달러 적용 (텍스트 1,000 토큰, 이미지는 크기별, 오디오는 1분 기준)",
x = "",
y = "가격(원)",
caption = "OpenAI 가격표: https://openai.com/pricing") +
theme(legend.position = c(0.8, 0.3),
legend.title=element_text(size=rel(2.5), family = "MaruBuri Bold"),
legend.text=element_text(size=rel(1.5), family = "MaruBuri Bold"))
ragg::agg_png("images/pricing_g.png", width = 297, height = 210, units = "mm", res = 600)
pricing_g
dev.off()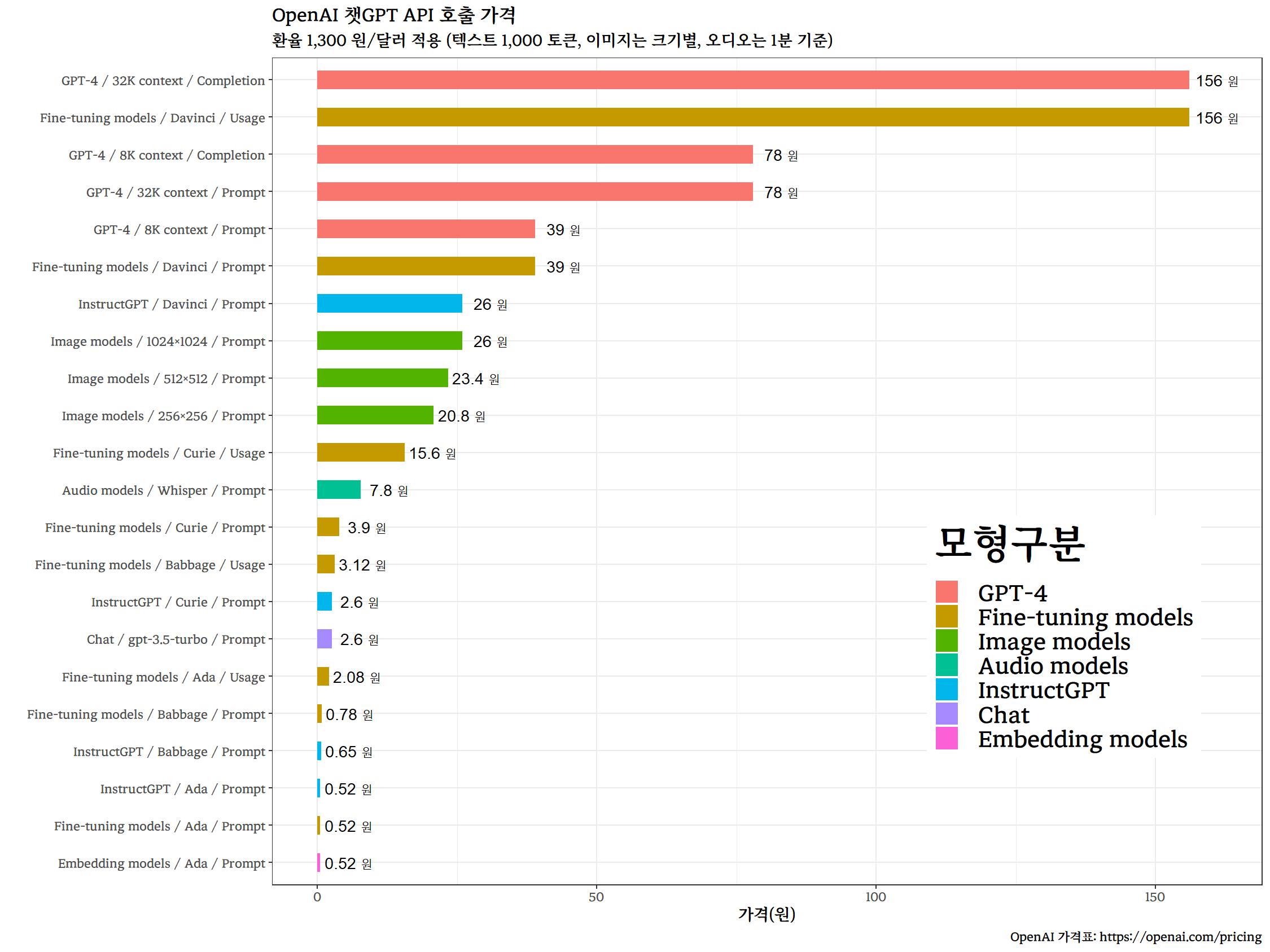
웹사이트에 게시된 가격표를 크롤링하여 엑셀파일로 정리한다.
library(readxl)
library(tidyverse)
price_today <- read_excel("data/openai_pricing.xlsx", sheet="price_230721")
price_tbl <- price_today %>%
janitor::clean_names(ascii = FALSE) %>%
separate(가격, into = c("가격", "단위"), sep = "/") %>%
mutate(가격 = parse_number(가격) *1300, # 환율 1,300 / 달러 적용
단위 = str_squish(단위))
price_tbl %>%
gt::gt() %>%
gtExtras::gt_theme_espn()| 모형구분 | model | 작업 | 가격 | 단위 |
|---|---|---|---|---|
| GPT-4 | 8K context | Input | 39.00 | 1K tokens |
| GPT-4 | 8K context | Output | 78.00 | 1K tokens |
| GPT-4 | 32K context | Input | 78.00 | 1K tokens |
| GPT-4 | 32K context | Output | 156.00 | 1K tokens |
| GPT-3.5 Turbo | 4K context | Input | 1.95 | 1K tokens |
| GPT-3.5 Turbo | 4K context | Output | 2.60 | 1K tokens |
| GPT-3.5 Turbo | 16K context | Input | 3.90 | 1K tokens |
| GPT-3.5 Turbo | 16K context | Output | 5.20 | 1K tokens |
| Fine-tuning models | Ada | Input | 0.52 | 1K tokens |
| Fine-tuning models | Ada | Output | 2.08 | 1K tokens |
| Fine-tuning models | Babbage | Input | 0.78 | 1K tokens |
| Fine-tuning models | Babbage | Output | 3.12 | 1K tokens |
| Fine-tuning models | Curie | Input | 3.90 | 1K tokens |
| Fine-tuning models | Curie | Output | 15.60 | 1K tokens |
| Fine-tuning models | Davinci | Input | 39.00 | 1K tokens |
| Fine-tuning models | Davinci | Output | 156.00 | 1K tokens |
| Embedding models | Ada v2 | Usage | 0.13 | 1K tokens |
| Image models | DALL·E 2 | 1024×1024 | 26.00 | image |
| Image models | DALL·E 3 | 512×512 | 23.40 | image |
| Image models | DALL·E 4 | 256×256 | 20.80 | image |
| Audio models | Whisper | Usage | 7.80 | minute |
OpenAI 가격을 원화(1,300원)로 변환시켜 API 호출별 체감되는 가격을 시각화한다.
extrafont::loadfonts()
pricing_20230621_g <- price_tbl %>%
mutate(모형상세 = glue::glue("{모형구분} / {model} / {작업}") %>% as.character(.)) %>%
mutate(모형구분 = factor(모형구분, levels=c("GPT-4", "GPT-3.5 Turbo", "Fine-tuning models",
"Embedding models",
"Image models", "Audio models") )) %>%
ggplot(aes(x = fct_reorder(모형상세, 가격), y = 가격, fill = 모형구분)) +
geom_col(width = 0.5) +
# facet_wrap(~모형구분, scales = "free_y") +
coord_flip() +
geom_text(aes(x = 모형상세, y = 가격, label = glue::glue("{가격} 원") ), nudge_y = 5) +
theme_bw(base_family = "MaruBuri Bold") +
labs(title = "OpenAI 챗GPT API 호출 가격",
subtitle = "환율 1,300 원/달러 적용 (텍스트 1,000 토큰, 이미지는 크기별, 오디오는 1분 기준)",
x = "",
y = "가격(원)",
caption = "OpenAI 가격표: https://openai.com/pricing") +
theme(legend.position = c(0.8, 0.3),
legend.title=element_text(size=rel(2.5), family = "MaruBuri"),
legend.text=element_text(size=rel(1.5), family = "MaruBuri"))
ragg::agg_png("images/pricing_20230621_g.png", width = 297, height = 210, units = "mm", res = 600)
pricing_20230621_g
dev.off()