#> ../../gpt4all
#> ├── chat
#> │ ├── gpt4all-lora-quantized-linux-x86
#> │ ├── gpt4all-lora-quantized-OSX-intel
#> │ ├── gpt4all-lora-quantized-OSX-m1
#> │ ├── gpt4all-lora-quantized-win64.exe
#> │ └── gpt4all-lora-quantized.bin
#> ├── clean.py
#> ├── configs
#> │ ├── deepspeed
#> │ │ └── ds_config.json
#> │ ├── eval
#> │ │ ├── generate.yaml
#> │ │ ├── generate_baseline.yaml
#> │ │ ├── generate_full.yaml
#> │ │ ├── generate_large_2.yaml
#> │ │ └── generate_large_3.yaml
#> │ ├── generate
#> │ │ ├── generate.yaml
#> │ │ └── generate_llama.yaml
#> │ └── train
#> │ ├── finetune.yaml
#> │ └── finetune_lora.yaml
#> ├── data.py
#> ├── env.yaml
#> ├── eval_data
#> │ └── user_oriented_instructions.jsonl
#> ├── eval_figures.py
#> ├── eval_self_instruct.py
#> ├── figs
#> │ ├── duplicate_loss.png
#> │ ├── first_lora.png
#> │ ├── perplexity_hist.png
#> │ └── single_epoch.png
#> ├── generate.py
#> ├── gpt4all-lora-demo.gif
#> ├── peft
#> ├── read.py
#> ├── README.md
#> ├── requirements.txt
#> ├── train.py
#> ├── TRAINING_LOG.md
#> └── transformers1 스테이블 디뷰젼
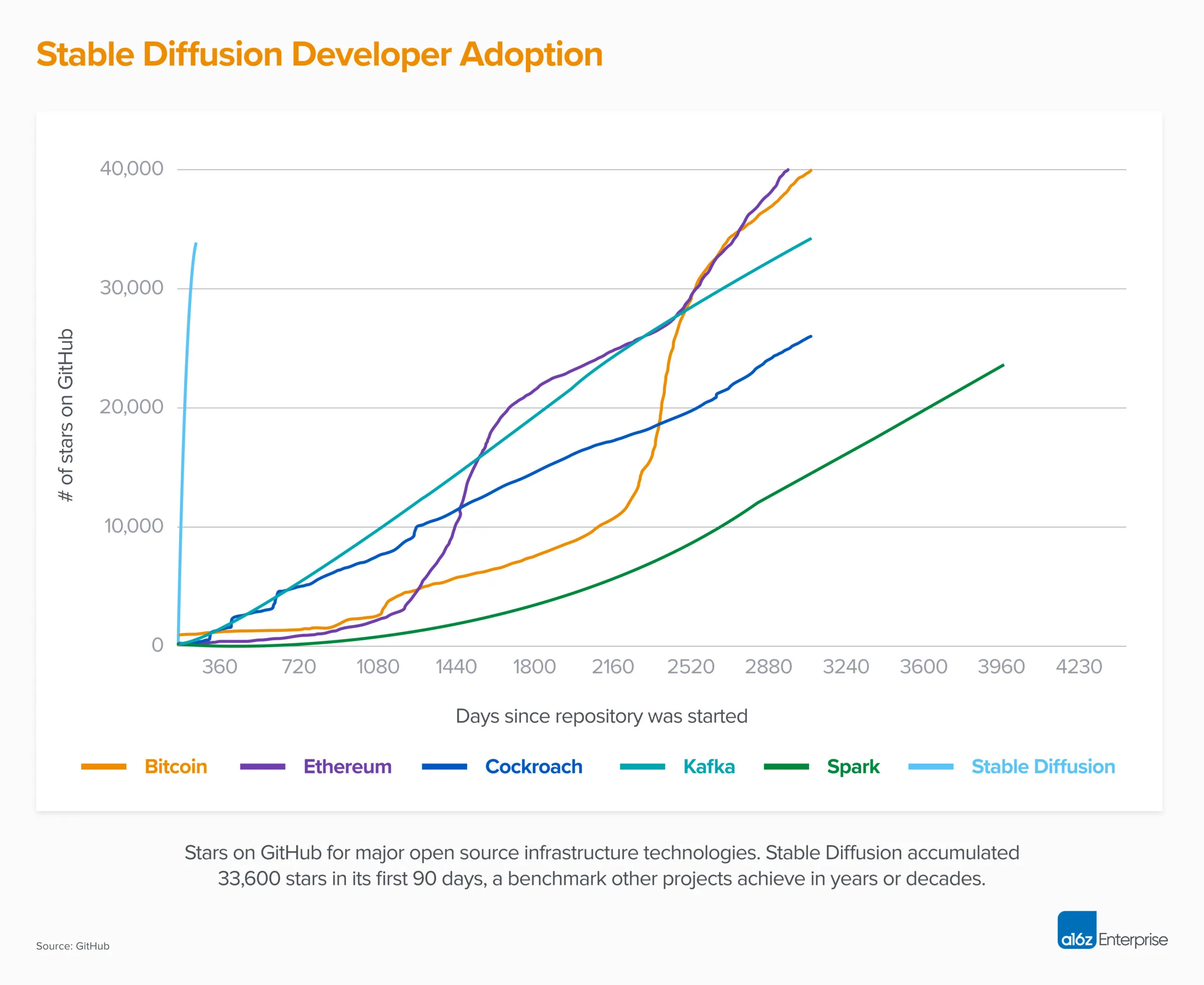
오픈 소스 AI 모델 Stable Diffusion V1은 전 세계적으로 수백 개의 다른 모델과 혁신을 낳았다. 두 달도 채 되지 않아 33,000개의 별을 돌파하며 모든 소프트웨어 중 가장 빠르게 Github 별 10,000개에 도달했고, 이는 이전의 다른 혁신적인 기술 비트코인, 이더리움, 카프카, 스파크 등과 비교하면 그 파급력이 갈음된다. 최근 공개(March 24, 2023)된 Stable Diffusion V2는 GitHub stablediffusion에서 확인 가능하다.
1.1 메타 라마
페이스북으로 잘 알려진 메타(Meta)는 연구 목적(비상업적 사용)으로 라마(LLaMA) 거대언어모형을 오픈소스 소프트웨어로 2023년 2월 24일 공개했다. LLaMA는 라틴어와 키릴 문자를 사용하는 20개 언어의 텍스트를 학습하여 다양한 크기(7B, 13B, 33B, 65B 매개변수) 언어모형 형태로 공개되어 거대언어모형을 대중화하고 연구자들이 새로운 접근 방식과 사용 사례를 테스트할 수 있는 취지로 공개되었지만, 여전히 편향성, 독성, 잘못된 정보 등 추가적인 보완이 필요하다.
2 GPT4All
GPT4All은 메타 LLaMa에 기반하여 GPT-3.5-Turbo 데이터를 추가학습한 오픈소스 챗봇이다. 설치는 간단하고 사무용이 아닌 개발자용 성능을 갖는 컴퓨터라면 그렇게 느린 속도는 아니지만 바로 활용이 가능하다. 문제는 한국어 지원은 되지 않는다는 것이다. 이유는 LLaMA가 라틴어와 키릴 문자를 사용하는 20개 언어 텍스트를 학습했기 때문이다.
설치 방식은 GPT4All을 git clone 혹은 저장소를 다운로드받아 압축을 푼 다음 gpt4all-lora-quantized.bin을 chat\ 디렉토리 아래 복사하여 넣은 다음 윈도우의 경우 gpt4all-lora-quantized-win64.exe 파일을 실행하면 된다. gpt4all-lora-quantized.bin 파일이 4GB 조금 넘는 크기라 Sosaka/GPT4All-7B-4bit-ggml 에서 좀더 빠르게 다운로드 받을 수 있다.
윈도우 탐색기에서 gpt4all-lora-quantized-win64.exe 파일을 두번 클릭하면 GPT4All 모형을 다운로드 받아 바로 사용이 가능하다. 대한민국의 수도도 정확히 알려주고 파이썬 코드도 작성해준다.
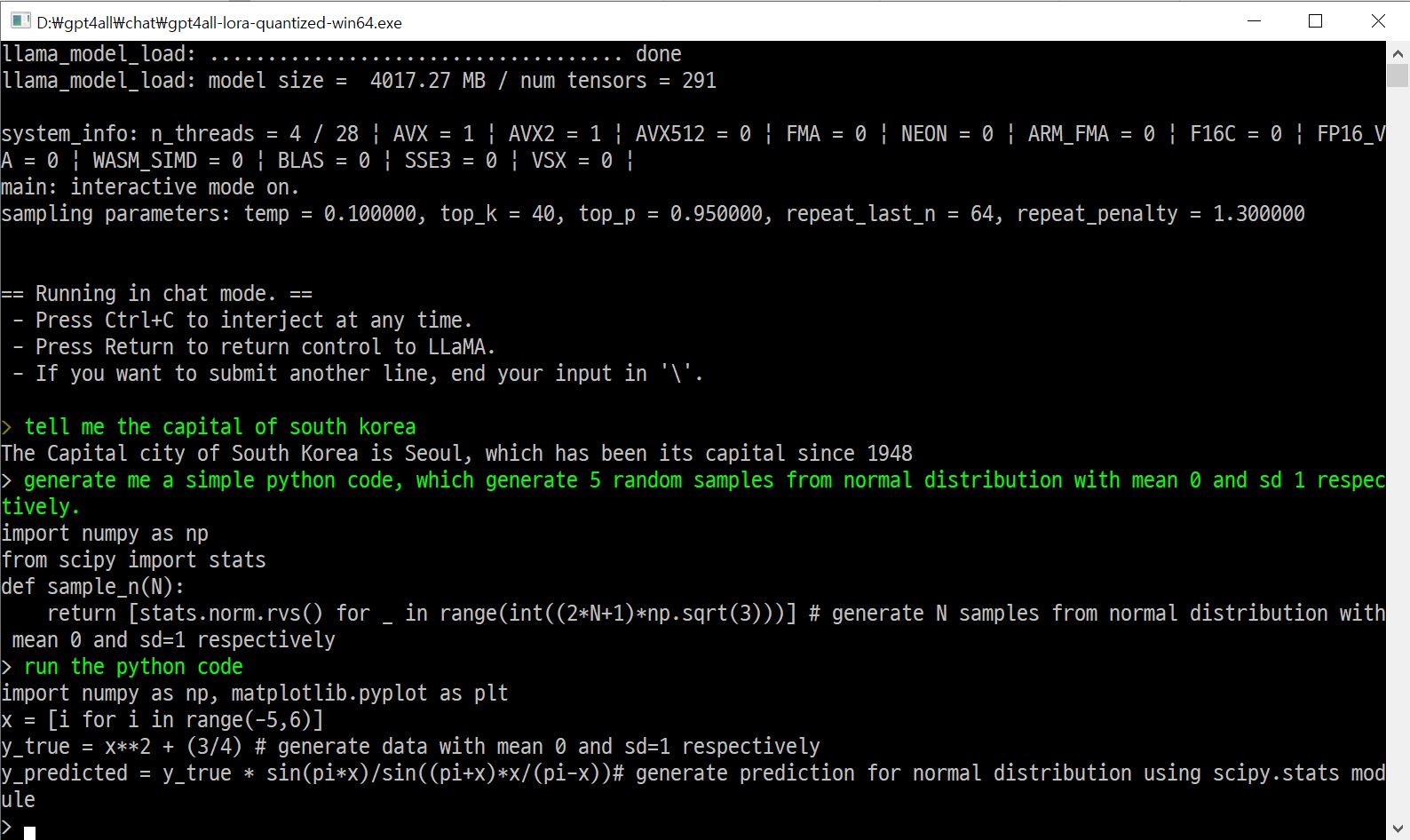
정규분포에서 표본을 추출하는 코드를 작성해 달라고 요청했으나 코드에 오류가 있어 수정하여 정상적인 결과 비교하자.
gpt4all
import numpy as np
from scipy import stats
def sample_n_gpt4all(N):
return [stats.norm.rvs() for _ in range(int((2*N+1)*np.sqrt(3)))]
for element in sample_n_gpt4all(1):
print(f"{element:.2f}")
#> -0.79
#> -0.77
#> -0.44
#> -0.56
#> 0.67수정 코드
import numpy as np
from scipy import stats
def sample_n(N):
samples = [stats.norm.rvs() for _ in range(N)]
return samples
sample_n(1)
#> [-0.3076006219586942]3 Open Assistant