챗GPT GPT-4를 사용해서 챗GPT 실무교육을 통해 얻으려는 것을 요약하도록 프롬프트를 작성한다.
프롬프트: 챗GPT 교육참여 텍스트를 5개 목표로 군집화시켜 정리하시요
챗GPT 응답: 1. 업무 효율성과 생산성 향상: - 보고서 작성 및 엑셀 스킬 향상 - 행정 업무의 간소화 - 특정 직무 역할에서 ChatGPT를 적용하는 다양한 방법 탐구 1. 변화하는 기술 추세에 적응하고 새로운 기술 습득: - AI와 ChatGPT의 최신 동향 이해 - ChatGPT 사용에 뒤처지지 않기 위한 지식 획득 - 변화하는 기술 풍경에 적응하기 위한 기본 지식 습득 1. 문제 해결 및 의사 결정 능력 향상: - 기획 및 이벤트 프로모션을 위한 데이터 시각화 활용 - 사례 연구 및 문제 해결을 위해 ChatGPT 사용 - 지역 발전 및 IT 동향에 대한 ChatGPT의 영향 분석 및 이해 1. ChatGPT 응용 범위 확장: - 일상 생활 및 다양한 산업 분야(예: 농업 홍보, 콘텐츠 산업)에 ChatGPT 적용 - 다양한 비즈니스 프로젝트에서 ChatGPT 통합의 잠재력 조사 1. 의사소통 및 질문 기술 향상: - 효과적인 프롬프트 질문 방법 학습 - ChatGPT와 더 나은 상호 작용을 위한 기술 개발 - 원하는 결과를 얻기 위해 올바른 질문을 하는 것의 중요성 이해
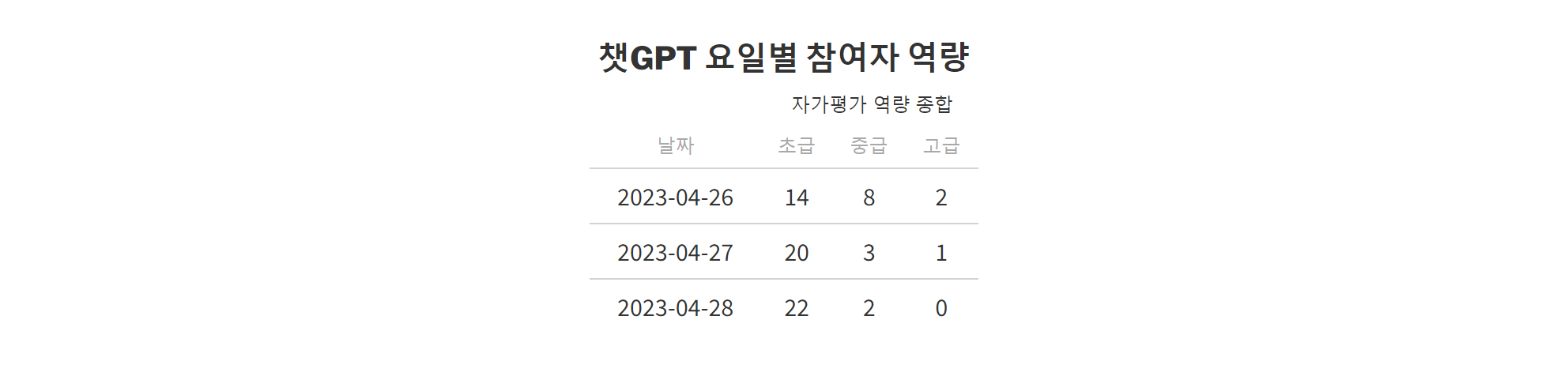
---title: "chatGPT"subtitle: "챗GPT 팀구성"description: | 챗GPT를 데이터 과학 문제 해결에 동원해보자.author: - name: 이광춘 url: https://www.linkedin.com/in/kwangchunlee/ affiliation: 한국 R 사용자회 affiliation-url: https://github.com/bit2rtitle-block-banner: true#title-block-banner: "#562457"format: html: css: css/quarto.css theme: flatly code-fold: true code-overflow: wrap toc: true toc-depth: 3 toc-title: 목차 number-sections: true highlight-style: github self-contained: falsefilters: - lightboxlightbox: autolink-citations: trueknitr: opts_chunk: message: false warning: false collapse: falseeditor_options: chunk_output_type: consoleeditor: markdown: wrap: 72---# 데이터셋챗GPT 교육에 참여한 설문조사 데이터를 정리한다.```{r}library(tidyverse)library(readxl)survey_26 <-read_excel("data/(붙임) 경기도청 챗GPT 직원직무 교육신청 명단(취합).xlsx", sheet ='4.26.(수)', skip =2) %>%mutate(날짜 ="2023-04-26")survey_27 <-read_excel("data/(붙임) 경기도청 챗GPT 직원직무 교육신청 명단(취합).xlsx", sheet ='4.27.(목)', skip =2) %>%mutate(날짜 ="2023-04-27")survey_28 <-read_excel("data/(붙임) 경기도청 챗GPT 직원직무 교육신청 명단(취합).xlsx", sheet ='4.28.(금)', skip =2) %>%mutate(날짜 ="2023-04-28")survey <-bind_rows(survey_26, survey_27) %>%bind_rows(survey_28) %>% janitor::clean_names(ascii =FALSE) %>%set_names(c("연번", "실국", "소속", "직위", "성명", "프롬프트", "API", "성취목표", "날짜")) %>%mutate(실국 =ifelse(is.na(실국), "직속", 실국)) ```# 데이터 가명처리실국, 소속과 직위, 성명이 포함되어 있어 변수 중 성명을 가명처리한다.이를 위해서 파이썬 `Faker` 패키지를 사용하여 가명으로 처리한다.```{python}from faker import Fakerimport pandas as pdimport numpy as npimport randomfrom datetime import datetimefake = Faker('ko_KR')def create_rows_faker(num=1): output = [{"name" : fake.name()} for x inrange(num)]return outputdf_faker = pd.DataFrame(create_rows_faker(72))```가명처리 데이터를 정리한다.```{r}library(reticulate)survey_tbl <- survey %>%bind_cols(py$df_faker) %>%select(-성명) %>%rename(성명 = name) %>%select(날짜, 실국, 성명, 직위, 프롬프트, API) ```# 챗GPT 챗GPT `GPT-4`를 사용해서 챗GPT 실무교육을 통해 얻으려는 것을 요약하도록 프롬프트를 작성한다.:::{.callout-note collpase="true"}### 프롬프트: 챗GPT 교육참여 텍스트를 5개 목표로 군집화시켜 정리하시요> 챗GPT 응답: <br>> 1. 업무 효율성과 생산성 향상: <br>> - 보고서 작성 및 엑셀 스킬 향상 <br>> - 행정 업무의 간소화 <br>> - 특정 직무 역할에서 ChatGPT를 적용하는 다양한 방법 탐구 <br>> 1. 변화하는 기술 추세에 적응하고 새로운 기술 습득: <br>> - AI와 ChatGPT의 최신 동향 이해 <br>> - ChatGPT 사용에 뒤처지지 않기 위한 지식 획득 <br>> - 변화하는 기술 풍경에 적응하기 위한 기본 지식 습득 <br>> 1. 문제 해결 및 의사 결정 능력 향상: <br>> - 기획 및 이벤트 프로모션을 위한 데이터 시각화 활용 <br>> - 사례 연구 및 문제 해결을 위해 ChatGPT 사용 <br>> - 지역 발전 및 IT 동향에 대한 ChatGPT의 영향 분석 및 이해 <br>> 1. ChatGPT 응용 범위 확장: <br>> - 일상 생활 및 다양한 산업 분야(예: 농업 홍보, 콘텐츠 산업)에 ChatGPT 적용 <br>> - 다양한 비즈니스 프로젝트에서 ChatGPT 통합의 잠재력 조사 <br>> 1. 의사소통 및 질문 기술 향상: <br>> - 효과적인 프롬프트 질문 방법 학습 <br>> - ChatGPT와 더 나은 상호 작용을 위한 기술 개발 <br>> - 원하는 결과를 얻기 위해 올바른 질문을 하는 것의 중요성 이해 <br>:::# 통계 분석설문조사에 나타난 자기평가 프롬프트 API 활용역량을 표로 요약한다.```{r}library(gt)library(gtExtras)survey_gt <- survey %>%count(프롬프트, API) %>%pivot_wider(names_from = API, values_from = n, values_fill =0) %>%mutate(라 =0) %>% gt::gt() %>%tab_spanner(label ="API 활용능력",columns =c( 가,나,다,라 ) ) %>%gt_theme_nytimes() %>%tab_header(title ="자기평가 프롬프트, API 활용역량") %>%cols_align(align ="center",columns =everything())survey_gt %>%gtsave_extra(filename="images/gg_survey_gt.png")```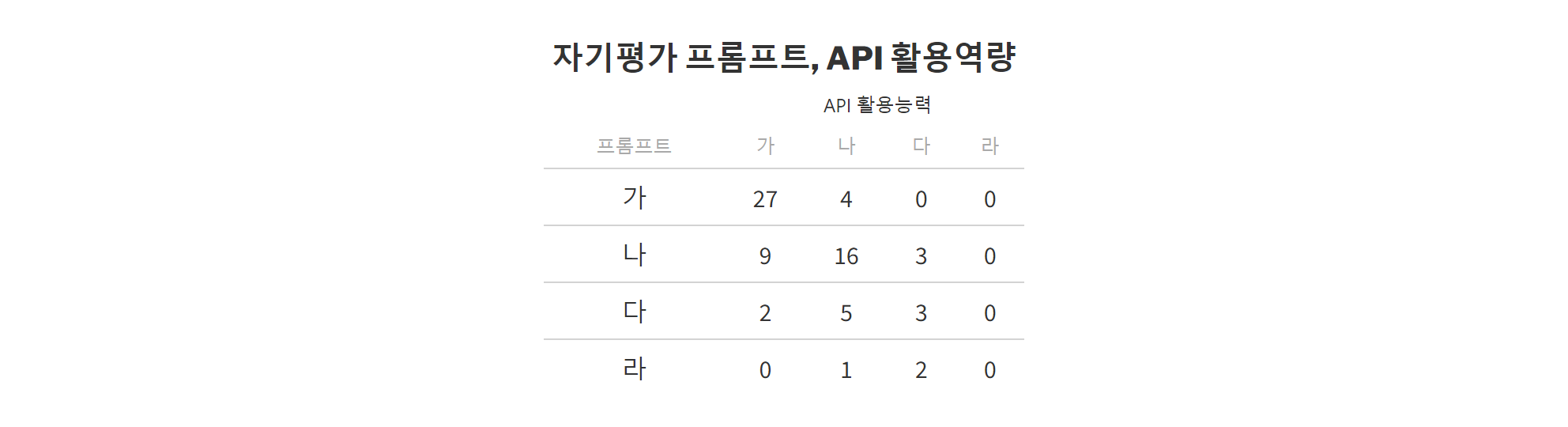요일별 초,중,고급 참여자 역량을 다음과 같이 요약한다.```{r}survey_gt_date <- survey %>%mutate(수준 =case_when(프롬프트 %in%c("가", "나") & API %in%c("가", "나") ~"초급", 프롬프트 =="라"~"고급",TRUE~"중급")) %>%count(날짜, 수준) %>%pivot_wider(names_from = 수준, values_from = n, values_fill =0) %>% gt::gt() %>%tab_spanner(label ="자가평가 역량 종합",columns =c( 초급, 중급, 고급 ) ) %>%gt_theme_nytimes() %>%tab_header(title ="챗GPT 요일별 참여자 역량") %>%cols_align(align ="center",columns =everything()) survey_gt_date %>%gtsave_extra(filename="images/survey_gt_date.png")```