임베딩(embedding)은 개념을 숫자 시퀀스로 변환한 수치 표현으로, 컴퓨터가 개념 간의 관계를 쉽게 이해할 수 있도록 한다. 이를 통해서 기존에 개별적으로 수행했던 작업을 통합적으로 추진하는 것이 가능하게 되었다. 수치적으로 유사한 임베딩은 의미적으로도 유사하기 때문에 임베딩을 통해서 텍스트를 유사한 것으로 모으는 군집분석이나 문서 검색과 같은 NLP 작업이 수월해졌다.
OpenAI에서 텍스트 유사도, 텍스트 검색, 코드 검색용으로 세가지 모델을 공개했다.1 2022년 12월 5일 공개된 text-embedding-ada-002 모형은 텍스트 검색, 텍스트 유사도 및 코드 검색을 위한 5개 개별 모델을 대체하며, 대부분의 작업에서 이전 최고 성능 모델인 다빈치보다 성능이 뛰어나면서도 가격은 99.8% 저렴하기 때문에 text-embedding-ada-002 모형을 중심으로 살펴보면 된다. 2 텍스트 분류에서만 text-similarity-*davinci*-001 모형보다 성능이 다소 떨어지고 나머지 분야에서는 모두 앞선 성능을 나타내면서도 가격이 저렴하다. 3
Models
Use Cases
Text similarity: Captures semantic similarity between pieces of text.
Code search: Find relevant code with a query in natural language.
code-search-{ada, babbage}-{code, text}-001
Code search and relevance
1 목표와 작업흐름
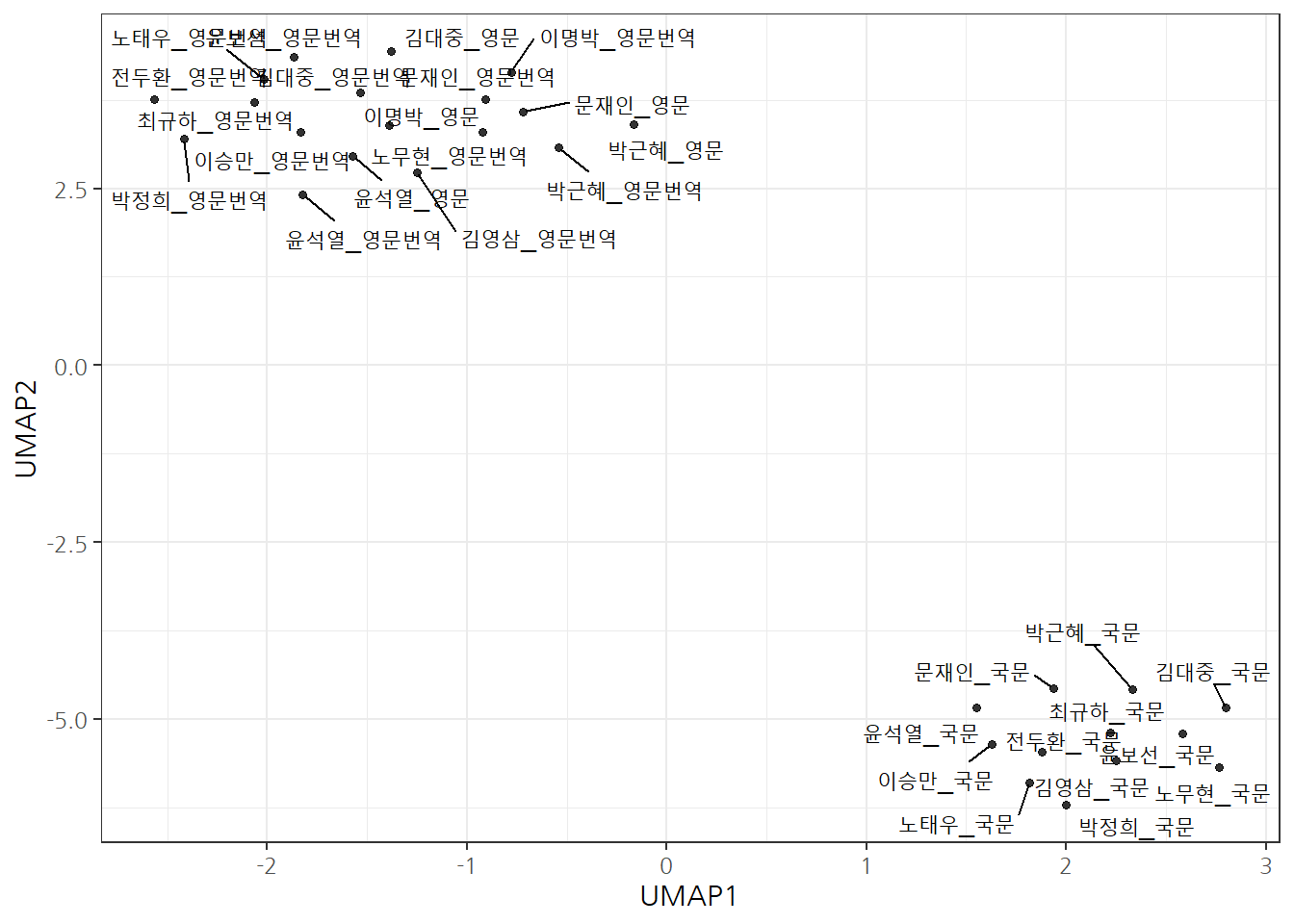
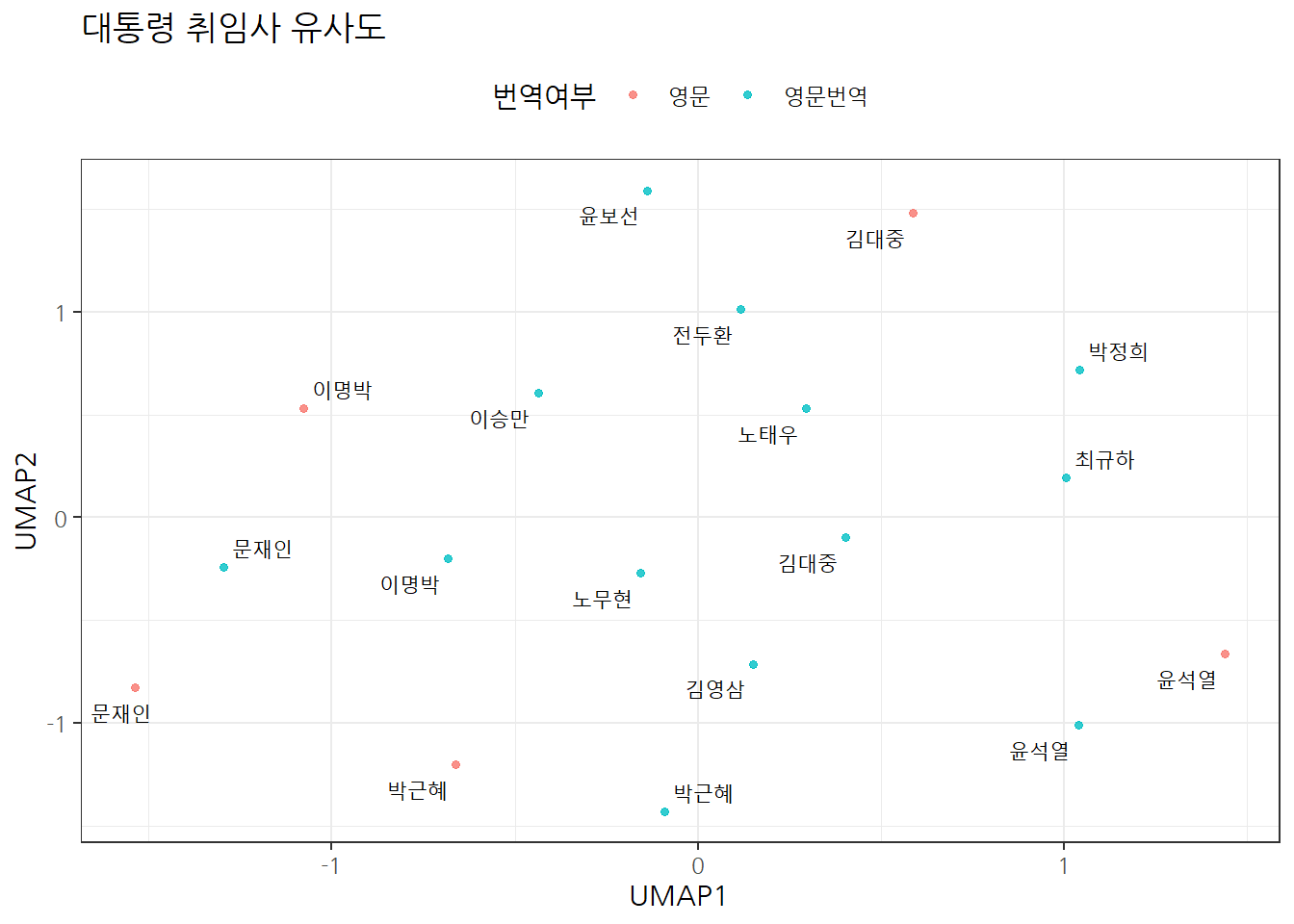
역대 대통령의 취임사에 적힌 한영 텍스트에 숨은 시맨틱(의미)을 기반으로 국정철학이 유사한 대통령을 텍스트 유사도를 기준으로 묶어보자.
이를 위해서 취임사를 국/영문으로 취합하여 OpenAI text-embedding-ada-002 모형을 통해 취임사의 임베딩을 구하고 이를 R과 ggplot으로 텍스트 유사도와 시각화를 통해 국정철학이 유사한 대통령을 묶어낸다.
2 데이터
2.1 국문 취임사
행정안전부 대통령기록관 기록컬렉션 연설기록에서 역대 대통령의 취임사를 텍스트 형태로 다운로드 받을 수 있다. 이승만, 박정희, 전두환 대통령의 경우 2회 이상 대통령을 역임했기 때문에 가장 마지막 취임사를 받아온다.
코드
library(tidyverse)presidents<-fs::dir_ls("data/Inaugural/")inaugural_tbl<-presidents%>%enframe(name ="파일경로")%>%separate(value, into =c("역대", "대통령"), sep="_")%>%mutate(대통령 =str_remove(대통령, "\\.txt"))%>%mutate(취임사 =map(파일경로, read_lines))%>%mutate(취임사 =map_chr(취임사, paste0, collapse =" "))%>%select(역대, 대통령, 취임사)%>%mutate(취임사 =str_squish(취임사))%>%mutate(취임사 =str_replace_all(취임사, "ㆍ", ", "))inaugural_tbl#> # A tibble: 13 × 3#> 역대 대통령 취임사 #> <chr> <chr> <chr> #> 1 data/Inaugural/제03대 이승만 "나의 사랑하는 동포 여러분. 내가 오늘 또 한번 … #> 2 data/Inaugural/제04대 윤보선 "제2공화국의 초대대통령으로 영예의 당선을 얻은 …#> 3 data/Inaugural/제09대 박정희 "친애하는 5천만 동포 여러분! 그리고 내외 귀빈 … #> 4 data/Inaugural/제10대 최규하 "친애하는 국내외 동포 여러분! 그리고 이 자리를 …#> 5 data/Inaugural/제12대 전두환 "친애하는 국내외 동포 여러분! 그리고 이 자리를 …#> 6 data/Inaugural/제13대 노태우 "친애하는 6천만 국내외 동포 여러분. 우리 헌정발…#> 7 data/Inaugural/제14대 김영삼 "친애하는 7천만 국내외 동포 여러분, 노태우 대통…#> 8 data/Inaugural/제15대 김대중 "존경하고 사랑하는 국민 여러분! 오늘 저는 대한… #> 9 data/Inaugural/제16대 노무현 "존경하는 국민 여러분. 오늘 저는 대한민국의 제1…#> 10 data/Inaugural/제17대 이명박 "존경하는 국민 여러분! 700만 해외동포 여러분, … #> 11 data/Inaugural/제18대 박근혜 "희망의 새 시대를 열겠습니다. 존경하는 국민여러…#> 12 data/Inaugural/제19대 문재인 "존경하고 사랑하는 국민 여러분! 감사합니다. 국… #> 13 data/Inaugural/제20대 윤석열 "존경하고 사랑하는 국민 여러분, 750만 재외동포 …
2.2 [딥엘] 영문 취임사
파파고 API를 사용하여 번역작업을 진행할 수 있으나 일 50,000글자로 제한이 있고 추가 비용을 지불하는 금전적인 문제도 있고 딥엘(DeepL) 보다 번역품질에서 낫기 때문에 기본 코드만 작성해 둔다. 번역품질이 최상은 아니지만 일반적인 번역 품질에는 큰 차이는 없다.
코드
translate_papago<-function(text, source="ko", target="en"){transURL<-"https://openapi.naver.com/v1/papago/n2mt"response<-transURL%>%httr::POST(httr::add_headers("Content-Type"="application/x-www-form-urlencoded; charset=UTF-8","X-Naver-Client-Id"=Sys.getenv('NAVER_CLIENT_ID'),"X-Naver-Client-Secret"=Sys.getenv('NAVER_CLIENT_SECRET')), body =glue::glue("text={text}&source={source}&target={target}"))%>%toString()%>%jsonlite::fromJSON()Sys.sleep(1)response$message$result$translatedText}tranlated<-fs::dir_ls("data/Inaugural-eng/")translated_tbl<-tranlated%>%enframe(name ="파일경로")%>%separate(value, into =c("역대", "대통령"), sep="_")%>%mutate(대통령 =str_remove(대통령, "\\.txt"))%>%mutate(영문번역 =map(파일경로, read_lines))%>%mutate(영문번역 =map_chr(영문번역, paste0, collapse =" "))%>%select(역대, 대통령, 영문번역)%>%mutate(영문번역 =str_squish(영문번역))%>%mutate(영문번역 =str_replace_all(영문번역, "ㆍ", ", "))# DeepL 번역 결과translated_tbl#> # A tibble: 13 × 3#> 역대 대통령 영문번역 #> <chr> <chr> <chr> #> 1 data/Inaugural-eng/제03대 이승만 "My fellow countrymen and women. Today I st…#> 2 data/Inaugural-eng/제04대 윤보선 "My excitement yesterday at being honored a…#> 3 data/Inaugural-eng/제09대 박정희 "Dear 50 million compatriots! And distingui…#> 4 data/Inaugural-eng/제10대 최규하 "Dear compatriots at home and abroad! And d…#> 5 data/Inaugural-eng/제12대 전두환 "Dear compatriots at home and abroad! And d…#> 6 data/Inaugural-eng/제13대 노태우 "Dear 60 million compatriots at home and ab…#> 7 data/Inaugural-eng/제14대 김영삼 "Dear 70 million compatriots at home and ab…#> 8 data/Inaugural-eng/제15대 김대중 "Honored and beloved citizens of the Republ…#> 9 data/Inaugural-eng/제16대 노무현 "Honorable fellow citizens. Today I stand h…#> 10 data/Inaugural-eng/제17대 이명박 "Honored citizens! 7 million overseas Korea…#> 11 data/Inaugural-eng/제18대 박근혜 "We will usher in a new era of hope. Honora…#> 12 data/Inaugural-eng/제19대 문재인 "My honored and beloved people! Thank you. …#> 13 data/Inaugural-eng/제20대 윤석열 "My honored and beloved countrymen, our 7.5…
2.3 영문 취임사
최근 대통령 취임사는 외교부나 구글 인터넷 검색을 통해 영문으로 취임사를 구할 수 있다.
코드
eng_inaugural<-fs::dir_ls("data/inaugural-mofa/")inaugural_eng_tbl<-eng_inaugural%>%enframe(name ="파일경로")%>%separate(value, into =c("역대", "대통령"), sep="_")%>%mutate(대통령 =str_remove(대통령, "\\.txt"))%>%mutate(영문취임사 =map(파일경로, read_lines))%>%mutate(영문취임사 =map_chr(영문취임사, paste0, collapse =" "))%>%mutate(연설문길이 =str_length(영문취임사))%>%filter(연설문길이>1000)%>%select(역대, 대통령, 영문취임사)%>%mutate(영문취임사 =str_squish(영문취임사))# 영어취임사inaugural_eng_tbl#> # A tibble: 5 × 3#> 역대 대통령 영문취임사 #> <chr> <chr> <chr> #> 1 data/inaugural-mofa/제15대 김대중 "My fellow countrymen, Today, I am being in…#> 2 data/inaugural-mofa/제17대 이명박 "Together We Shall Open, A Road to Advancem…#> 3 data/inaugural-mofa/제18대 박근혜 "My fellow Koreans and seven million fellow…#> 4 data/inaugural-mofa/제19대 문재인 "My fellow Koreans, I am grateful to you al…#> 5 data/inaugural-mofa/제20대 윤석열 "My fellow Koreans, Seven and a half millio…
3 임베딩
취임사 텍스트가 국문 취임사, 영문 번역본, 영문 취임사로 준비가 되었다면 다음 단계로 OpenAI text-embedding-ada-002 API를 통해 각 취임사에 대한 임베딩을 계산하면 된다. 특히 토큰 크기(텍스트 크기) 제한이 있기 때문에 OpenAI에서 제공하는 Tokenizer를 사용하여 미리 토큰 크기를 확인하고 만약 취임사가 토큰크기를 상회하는 경우 별도 전략을 세운다.
3.1 API 호출 함수
get_embedding() 함수를 제작하여 국,영문 취임사 텍스트를 전달하여 임베딩 값을 반환받는다. 매번 API를 호출할 때마다 비용이 발생되기 때문에 API호출 횟수를 최소화한다.
각각 API를 호출하여 준비한 취임사 텍스트를 임베딩으로 변환한 데이터프레임을 각각 이어붙여 후속 데이터 분석을 위해 준비한다.
코드
embedding_tbl<-read_rds("data/Inaugural.rds")%>%mutate(구분 ="국문 취임사")translated_embedding<-read_rds("data/translated_embedding.rds")%>%mutate(구분 ="영문번역 취임사")%>%rename(취임사 =영문번역)inaugural_eng_embedding<-read_rds("data/inaugural_eng_embedding.rds")%>%mutate(구분 ="영문 취임사")%>%rename(취임사 =영문취임사)api_embedding<-bind_rows(embedding_tbl, translated_embedding)%>%bind_rows(inaugural_eng_embedding)api_embedding%>%select(구분, 대통령, 취임사, 임베딩)#> # A tibble: 31 × 4#> 구분 대통령 취임사 임베딩#> <chr> <chr> <chr> <list>#> 1 국문 취임사 이승만 나의 사랑하는 동포 여러분. 내가 오늘 또 한번 우리 … <list>#> 2 국문 취임사 윤보선 제2공화국의 초대대통령으로 영예의 당선을 얻은 어제… <list>#> 3 국문 취임사 박정희 친애하는 5천만 동포 여러분! 그리고 내외 귀빈 여러… <list>#> 4 국문 취임사 최규하 친애하는 국내외 동포 여러분! 그리고 이 자리를 빛… <list>#> 5 국문 취임사 전두환 친애하는 국내외 동포 여러분! 그리고 이 자리를 빛… <list>#> 6 국문 취임사 노태우 친애하는 6천만 국내외 동포 여러분. 우리 헌정발전을… <list>#> 7 국문 취임사 김영삼 친애하는 7천만 국내외 동포 여러분, 노태우 대통령… <list>#> 8 국문 취임사 김대중 존경하고 사랑하는 국민 여러분! 오늘 저는 대한민국… <list>#> 9 국문 취임사 노무현 존경하는 국민 여러분. 오늘 저는 대한민국의 제16대… <list>#> 10 국문 취임사 이명박 존경하는 국민 여러분! 700만 해외동포 여러분! … <NULL>#> # … with 21 more rows
4 취임사 유사도
두 임베딩 벡터 \(\mathbf{u}\) 와 \(\mathbf{v}\) 는 다음 공식을 사용하여 두 벡터간의 유사도를 구할 수 있다.
국문 윤석열 대통령 취임사를 기준으로 역대 대통령 취임사와 유사도를 살펴보면 가장 유사도가 높은 대통령은 노무현 대통령 취임사로 나타났다. 여기서 이명박 대통령은 토큰 크기가 너무 커서 제외한 것을 감안해야 한다. 가장 취임사 유사도가 떨어지는 대통령은 영문으로 번역한 박정희 대통령 취임사가 윤보선 대통령 취임사와 거의 동률로 나왔다.
---title: "chatGPT"subtitle: "대통령 취임사"author: - name: 이광춘 url: https://www.linkedin.com/in/kwangchunlee/ affiliation: 한국 R 사용자회 affiliation-url: https://github.com/bit2rtitle-block-banner: true#title-block-banner: "#562457"format: html: css: css/quarto.css theme: flatly code-fold: true code-overflow: wrap toc: true toc-depth: 3 toc-title: 목차 number-sections: true highlight-style: github self-contained: falsefilters: - lightbox - custom-callout.lua lightbox: autolink-citations: trueknitr: opts_chunk: message: false warning: false collapse: true comment: "#>" R.options: knitr.graphics.auto_pdf: trueeditor_options: chunk_output_type: console---**임베딩(embedding)**은 개념을 숫자 시퀀스로 변환한 수치 표현으로, 컴퓨터가 개념 간의 관계를 쉽게 이해할 수 있도록 한다. 이를 통해서 기존에 개별적으로 수행했던 작업을 통합적으로 추진하는 것이 가능하게 되었다. 수치적으로 유사한 임베딩은 의미적으로도 유사하기 때문에 임베딩을 통해서 텍스트를 유사한 것으로 모으는 군집분석이나 문서 검색과 같은 NLP 작업이 수월해졌다.OpenAI에서 텍스트 유사도, 텍스트 검색, 코드 검색용으로 세가지 모델을 공개했다.[^1]2022년 12월 5일 공개된 `text-embedding-ada-002` 모형은 텍스트 검색, 텍스트 유사도 및 코드 검색을 위한 5개 개별 모델을 대체하며, 대부분의 작업에서 이전 최고 성능 모델인 다빈치보다 성능이 뛰어나면서도 가격은 99.8% 저렴하기 때문에 `text-embedding-ada-002` 모형을 중심으로 살펴보면 된다. [^openai2]텍스트 분류에서만 `text-similarity-*davinci*-001` 모형보다 성능이 다소 떨어지고 나머지 분야에서는 모두 앞선 성능을 나타내면서도 가격이 저렴하다. [^price][^1]: [Introducing text and code embeddings](https://openai.com/blog/introducing-text-and-code-embeddings)[^openai2]: [New and improved embedding model](https://openai.com/blog/new-and-improved-embedding-model)[^price]: [OpenAI GPT-3 Text Embeddings - Really a new state-of-the-art in dense text embeddings?](https://medium.com/@nils_reimers/openai-gpt-3-text-embeddings-really-a-new-state-of-the-art-in-dense-text-embeddings-6571fe3ec9d9)| | Models | Use Cases ||-----------------------|----------------------|---------------------------|| Text similarity: Captures semantic similarity between pieces of text. | text-similarity-{ada, babbage, curie, davinci}-001 | Clustering, regression, anomaly detection, visualization || Text search: Semantic information retrieval over documents. | text-search-{ada, babbage, curie, davinci}-{query, doc}-001 | Search, context relevance, information retrieval || Code search: Find relevant code with a query in natural language. | code-search-{ada, babbage}-{code, text}-001 | Code search and relevance |# 목표와 작업흐름역대 대통령의 취임사에 적힌 한영 텍스트에 숨은 시맨틱(의미)을 기반으로국정철학이 유사한 대통령을 텍스트 유사도를 기준으로 묶어보자.이를 위해서 취임사를 국/영문으로 취합하여 OpenAI `text-embedding-ada-002` 모형을 통해 취임사의 임베딩을 구하고 이를 R과 `ggplot`으로 텍스트 유사도와 시각화를 통해 국정철학이 유사한 대통령을 묶어낸다.# 데이터## 국문 취임사행정안전부 대통령기록관 기록컬렉션 [연설기록](https://www.pa.go.kr/research/contents/speech/index.jsp)에서 역대 대통령의 취임사를 텍스트 형태로 다운로드 받을 수 있다. 이승만, 박정희, 전두환 대통령의 경우 2회 이상 대통령을 역임했기 때문에 가장 마지막 취임사를 받아온다. ```{r}library(tidyverse)presidents <- fs::dir_ls("data/Inaugural/")inaugural_tbl <- presidents %>%enframe(name ="파일경로") %>%separate(value, into =c("역대", "대통령"), sep="_") %>%mutate(대통령 =str_remove(대통령, "\\.txt")) %>%mutate(취임사 =map(파일경로, read_lines)) %>%mutate(취임사 =map_chr(취임사, paste0, collapse =" ")) %>%select(역대, 대통령, 취임사) %>%mutate(취임사 =str_squish(취임사)) %>%mutate(취임사 =str_replace_all(취임사, "ㆍ", ", "))inaugural_tbl```## [딥엘] 영문 취임사파파고 API를 사용하여 번역작업을 진행할 수 있으나 일 50,000글자로 제한이 있고 추가 비용을 지불하는 금전적인 문제도 있고 [딥엘(DeepL)](https://www.deepl.com/translator) 보다 번역품질에서 낫기 때문에 기본 코드만 작성해 둔다. 번역품질이 최상은 아니지만 일반적인 번역 품질에는 큰 차이는 없다.```{r}translate_papago <-function(text, source="ko", target="en") { transURL <-"https://openapi.naver.com/v1/papago/n2mt" response <- transURL %>% httr::POST( httr::add_headers("Content-Type"="application/x-www-form-urlencoded; charset=UTF-8","X-Naver-Client-Id"=Sys.getenv('NAVER_CLIENT_ID'),"X-Naver-Client-Secret"=Sys.getenv('NAVER_CLIENT_SECRET') ),body = glue::glue("text={text}&source={source}&target={target}") ) %>%toString() %>% jsonlite::fromJSON()Sys.sleep(1) response$message$result$translatedText}tranlated <- fs::dir_ls("data/Inaugural-eng/")translated_tbl <- tranlated %>%enframe(name ="파일경로") %>%separate(value, into =c("역대", "대통령"), sep="_") %>%mutate(대통령 =str_remove(대통령, "\\.txt")) %>%mutate(영문번역 =map(파일경로, read_lines)) %>%mutate(영문번역 =map_chr(영문번역, paste0, collapse =" ")) %>%select(역대, 대통령, 영문번역) %>%mutate(영문번역 =str_squish(영문번역)) %>%mutate(영문번역 =str_replace_all(영문번역, "ㆍ", ", "))# DeepL 번역 결과translated_tbl```## 영문 취임사최근 대통령 취임사는 외교부나 구글 인터넷 검색을 통해 영문으로 취임사를 구할 수 있다.```{r}eng_inaugural <- fs::dir_ls("data/inaugural-mofa/")inaugural_eng_tbl <- eng_inaugural %>%enframe(name ="파일경로") %>%separate(value, into =c("역대", "대통령"), sep="_") %>%mutate(대통령 =str_remove(대통령, "\\.txt")) %>%mutate(영문취임사 =map(파일경로, read_lines)) %>%mutate(영문취임사 =map_chr(영문취임사, paste0, collapse =" ")) %>%mutate(연설문길이 =str_length(영문취임사)) %>%filter(연설문길이 >1000) %>%select(역대, 대통령, 영문취임사) %>%mutate(영문취임사 =str_squish(영문취임사)) # 영어취임사inaugural_eng_tbl```# 임베딩취임사 텍스트가 국문 취임사, 영문 번역본, 영문 취임사로 준비가 되었다면 다음 단계로 OpenAI `text-embedding-ada-002` API를 통해 각 취임사에 대한 임베딩을 계산하면 된다.특히 토큰 크기(텍스트 크기) 제한이 있기 때문에 OpenAI에서 제공하는 [Tokenizer](https://platform.openai.com/tokenizer)를 사용하여 미리 토큰 크기를 확인하고 만약 취임사가 토큰크기를 상회하는 경우 별도 전략을 세운다.## API 호출 함수`get_embedding()` 함수를 제작하여 국,영문 취임사 텍스트를 전달하여 임베딩 값을 반환받는다. 매번 API를 호출할 때마다 비용이 발생되기 때문에 API호출 횟수를 최소화한다. ```{r}#| eval: falselibrary(httr)get_embedding <-function(inaugural_address) { embeddings_url <-"https://api.openai.com/v1/embeddings" auth <-add_headers(Authorization =paste("Bearer", Sys.getenv("OPENAI_API_KEY"))) body <-list(model ="text-embedding-ada-002", input = inaugural_address) resp <-POST( embeddings_url, auth,body = body,encode ="json" ) embeddings <-content(resp, as ="text", encoding ="UTF-8") %>% jsonlite::fromJSON(flatten =TRUE) %>%pluck("data", "embedding")Sys.sleep(1)return(embeddings)}# 1. 국문 취임사embedding_tbl <- inaugural_tbl %>%mutate(임베딩 =map(취임사, get_embedding)) %>%pull()embedding_tbl %>%write_rds("data/Inaugural.rds")# 2. 영어번역본 취임사translated_embedding <- translated_tbl %>%mutate(임베딩 =map(영문번역, get_embedding))translated_embedding %>%write_rds("data/translated_embedding.rds")# 3. 영어 취임사inaugural_eng_embedding <- inaugural_eng_tbl %>%mutate(임베딩 =map(영문취임사, get_embedding))inaugural_eng_embedding %>%write_rds("data/inaugural_eng_embedding.rds")```## 임베딩 벡터각각 API를 호출하여 준비한 취임사 텍스트를 임베딩으로 변환한 데이터프레임을 각각 이어붙여 후속 데이터 분석을 위해 준비한다.```{r}embedding_tbl <-read_rds("data/Inaugural.rds") %>%mutate(구분 ="국문 취임사")translated_embedding <-read_rds("data/translated_embedding.rds") %>%mutate(구분 ="영문번역 취임사") %>%rename(취임사 = 영문번역)inaugural_eng_embedding <-read_rds("data/inaugural_eng_embedding.rds") %>%mutate(구분 ="영문 취임사") %>%rename(취임사 = 영문취임사)api_embedding <-bind_rows(embedding_tbl, translated_embedding) %>%bind_rows(inaugural_eng_embedding)api_embedding %>%select(구분, 대통령, 취임사, 임베딩) ```# 취임사 유사도두 임베딩 벡터 $\mathbf{u}$ 와 $\mathbf{v}$ 는 다음 공식을 사용하여 두 벡터간의 유사도를 구할 수 있다.$$\begin{equation*}\text{코사인 유사도}(\mathbf{u},\mathbf{v}) = \frac{\mathbf{u} \cdot \mathbf{v}}{\|\mathbf{u}\| \|\mathbf{v}\|}= \frac{\sum_{i=1}^n u_i v_i}{\sqrt{\sum_{i=1}^n u_i^2} \sqrt{\sum_{i=1}^n v_i^2}}\end{equation*}$$국문 윤석열 대통령 취임사를 기준으로 역대 대통령 취임사와 유사도를 살펴보면 가장 유사도가 높은 대통령은 노무현 대통령 취임사로 나타났다.여기서 이명박 대통령은 토큰 크기가 너무 커서 제외한 것을 감안해야 한다.가장 취임사 유사도가 떨어지는 대통령은 영문으로 번역한 박정희 대통령 취임사가 윤보선 대통령 취임사와 거의 동률로 나왔다.```{r}library(reactable)api_embedding_tbl <- api_embedding %>%select(구분, 대통령, 임베딩) %>%mutate(임베딩 =map(임베딩, unlist)) %>%mutate(임베딩크기 =str_length(임베딩)) %>%filter(임베딩크기 >100)yoon_embedding <- api_embedding_tbl$임베딩[12][[1]]yoon_list <-list()for(i in1:nrow(api_embedding_tbl)) { yoon_list[[i]] <- lsa::cosine(yoon_embedding, api_embedding_tbl$임베딩[[i]])}api_embedding_tbl %>%select(-임베딩, -임베딩크기) %>%mutate(유사도 = yoon_list %>% unlist) %>%arrange(desc(유사도)) %>% reactable::reactable(columns =list(유사도 =colDef(format =colFormat(separators =TRUE, digits =3))),# Table Themetheme =reactableTheme(backgroundColor ="#1D2024", color ="white", borderColor ="#666666",paginationStyle =list(color ="white"), selectStyle =list(color ="black"),headerStyle =list(color ="white", fontFamily ="NanumGothic"),cellStyle =list(color ="#FAFAFA", fontFamily ="NanumGothic, Consolas, Monaco, monospace", fontSize ="14px") )) ```# 시각화모든 대통령 취임사에 대한 유사도를 모두 계산하고 이를 시각화하여 취임사에 담긴 의미를 기준으로 대통령의 취임사를 군집으로 묶어 전체적으로 조망하자.## 유사도 계산먼저 취임사 임베딩 벡터로부터 각 취임사별 코사인 유사도를 계산하면 정방행렬(Square Matrix)를 다시 데이터프레임으로 변환하게 시킨다. 이를 통해 취규하, 노태우, 전두환 대통령 취임사 사이에 높은 취임사 유사도가 확인된다.```{r}library(umap)embeddings_mat <-matrix(unlist(api_embedding_tbl$임베딩), ncol =1536, byrow =TRUE)embeddings_similarity <- embeddings_mat /sqrt(rowSums(embeddings_mat * embeddings_mat))embeddings_similarity <- embeddings_similarity %*%t(embeddings_similarity)dim(embeddings_similarity)## 정방행렬을 데이터프레임으로 변환취임사_구분자 <- api_embedding_tbl %>%mutate(구분명 = glue::glue("{대통령}_{str_remove(구분, ' ?취임사 ?')}")) %>%pull(구분명)취임사_colnames_tbl <-tibble(취임사_구분자 = 취임사_구분자) %>%mutate(name = glue::glue("V{1:30}"))embeddings_similarity_tbl <- embeddings_similarity %>% as.data.frame %>%mutate(구분자 = 취임사_구분자) %>%column_to_rownames(var ="구분자") %>% tibble::rownames_to_column() %>% tidyr::pivot_longer(-rowname) %>%# From A to Bleft_join(취임사_colnames_tbl) %>%select(취임사_A = rowname, 취임사_B = 취임사_구분자, 유사도 = value)embeddings_similarity_tbl %>%filter(유사도 <0.9999 ) %>%arrange(desc(유사도)) %>%mutate(대통령_A =str_extract(취임사_A, "[^_]+(?=_)"), 대통령_B =str_extract(취임사_B, "[^_]+(?=_)")) %>%filter(대통령_A != 대통령_B) %>%select(취임사_A, 취임사_B, 유사도) %>% reactable::reactable(columns =list(유사도 =colDef(format =colFormat(separators =TRUE, digits =3))),# Table Themetheme =reactableTheme(backgroundColor ="#1D2024", color ="white", borderColor ="#666666",paginationStyle =list(color ="white"), selectStyle =list(color ="black"),headerStyle =list(color ="white", fontFamily ="NanumGothic"),cellStyle =list(color ="#FAFAFA", fontFamily ="NanumGothic, Consolas, Monaco, monospace", fontSize ="14px") ))```## 차원축소 시각화국문영문 취임사를 모두 넣어 시각화를 하게 되면 국문 취임사는 국문 취임사, 영문 취임사는 DeepL 번역이든 영문 번역이든 둘로 명확히 나눠 군집화가 된 것이 확인된다.```{r}library(ggrepel)extrafont::loadfonts()inaugural_umap <-umap(embeddings_mat)umap_df <- inaugural_umap$layout %>%as.data.frame()%>%rename(UMAP1="V1",UMAP2="V2") %>%bind_cols(api_embedding_tbl) %>%mutate(구분명 = glue::glue("{대통령}_{str_remove(구분, ' ?취임사 ?')}")) %>%select(UMAP1, UMAP2, 구분명)umap_df %>%ggplot(aes(x = UMAP1, y = UMAP2))+geom_point(size =1.3, alpha =0.8) +geom_text_repel(aes(label=구분명)) +theme_bw(base_family="NanumGothic")```앞선 분석에서 이명박 대통령 취임사가 토큰 길이를 넘어 국문 임베딩이 존재하지 않기 때문에영문 번역 혹은 영문 취임사 임베딩을 `umap` 차원 축소 기법을 통해 시각화한다.이를 통해 윤석열 대통령과 노무현 대통령 취임사가 유사성이 큰게 눈에 띈다.```{r}# 영어만 추출only_english_tbl <- api_embedding_tbl %>%filter(str_detect(구분, "영문"))english_embeddings_mat <-matrix(unlist(only_english_tbl$임베딩), ncol =1536, byrow =TRUE)# 시각화english_umap <-umap(english_embeddings_mat)english_umap_df <- english_umap$layout %>%as.data.frame()%>%rename(UMAP1="V1",UMAP2="V2") %>%bind_cols(only_english_tbl) %>%mutate(구분명 = glue::glue("{대통령}_{str_remove(구분, ' ?취임사 ?')}")) %>%select(UMAP1, UMAP2, 구분명)english_umap_df %>%separate(구분명, into =c("대통령", "번역여부"), sep ="_") %>%ggplot(aes(x = UMAP1, y = UMAP2))+geom_point(aes(color = 번역여부), size =1.3, alpha =0.8) +geom_text_repel(aes(label=대통령)) +theme_bw(base_family="NanumGothic") +theme(legend.position ="top") +labs(title ="대통령 취임사 유사도")```