graph LR A["Data Collection <br> Preprocessing"] --> B["Feature Extraction <br> Model Training"] B --> C["Model Evaluation <br> Tuning"] C --> D["Model Deployment <br> Maintenance"] D --> T1[1. Sentiment Analysis] D --> T2[2. Text Classification] D --> T3[3. Named Entity Recognition] D --> T4[4. Part-of-Speech Tagging] D --> T5[5. Dependency Parsing] D --> T6[6. Machine Translation] D --> T7[7. Question Answering] D --> T8[8. Text Summarization] D --> T9[9. Coreference Resolution] D --> T10[10. Text Generation] class A,B,C,D nodeStyle class T1,T2,T3,T4,T5,T6,T7,T8,T9,T10 taskStyle classDef nodeStyle fill:#93c47d,stroke:#000000,stroke-width:0.7px,font-weight:bold,font-size:14px; classDef taskStyle fill:#fdfd96,stroke:#000000,stroke-width:0.7px,font-weight:bold,font-size:12px;

1 자연어 처리
자연어 처리는 컴퓨터로 하여금 사람이 작성한 언어(음성과 글)의 의미를 이해시키는 것을 목표로 한다.
- 텍스트 데이터
- 트위터
- 소설, 신문기사
- 고객 평점과 리뷰
- 전자우편
- 의무기록
- …
- 텍스트 저장 형식
- 뉴스 등 웹 페이지
- PDF/워드/한글 문서
- 트위터 등 SNS, RSS 피드, 댓글
- …
- 응용분야
- 감성분석
- 텍스트 분류
- 번역
- 챗봇
- 개인 비서
- …
- 기술
- 단어주머니(Bag of Words)
- Word Embedding, 워드투벡(Word2Vec)
- RNN, LSTM
- BERT, Transformer
- GPT, 거대언어모형(LLM)
- …
1.1 대표적인 NLP 작업
숫자가 아닌 텍스트를 통해 가치를 창출할 수 있는 분야가 자연어처리(NLP) 영역이다. 자연어 처리 분야에서 흔히 접하는 대표적인 상위 10가지 NLP으로 다음을 들 수 있다.
감정 분석: 긍정, 부정, 중립 등 주어진 텍스트에 표현된 감정을 파악.
텍스트 분류: 텍스트 데이터를 미리 정의된 클래스 또는 주제(예: 스포츠, 정치, 연예 등)로 분류.
개체명 인식(NER): 텍스트 내에서 사람, 조직, 위치, 날짜 등의 명명된 개체(entity)를 식별하고 분류.
품사(POS) 태깅: 주어진 텍스트의 단어에 문법적 레이블(예: 명사, 동사, 형용사)을 할당.
의존성 구문 분석: 문장 내 단어 간의 문법 구조와 관계를 식별.
기계 번역: 영어에서 스페인어로 또는 중국어에서 프랑스어로와 같이 한 언어에서 다른 언어로 텍스트를 번역.
질의 응답: 자연어로 제기된 질문을 이해하고 답변할 수 있는 시스템을 개발.
텍스트 요약: 주요 아이디어와 정보를 보존하면서 주어진 텍스트에 대한 간결한 요약을 생성.
상호참조해결(Coreference Resolution): 텍스트에서 두 개 이상의 단어나 구가 동일한 개체 또는 개념을 지칭하는 경우 식별.
텍스트 생성: 주어진 입력, 컨텍스트 또는 일련의 조건에 따라 일관되고 의미 있는 텍스트를 생성.
자연어 처리 작업과 작업흐름을 서로 연결하게 되면 다음과 같이 개별적으로 중복되고 분리된 작업을 수행하게 되는 문제가 있다.
2 작업흐름
2.1 NLP 기계학습
자연어처리(NLP) 기계학습은 통계모형과 거의 비슷한 작업흐름을 갖는다. 차이점이 있다면 데이터 관계의 설명보다 예측에 더 중점을 둔다는 점이라고 볼 수 있다. 예를 들어, 감성 분석 및 텍스트 분류 등 텍스트를 데이터로 하는 전통적인 자연어 처리 작업은 다음과 같은 작업흐름을 갖게 된다.
graph TD
A[데이터 수집] --> B[데이터 전처리]
B --> C[피쳐 추출]
C --> D[훈련-테스트 데이터셋 분할]
D --> E[모형 선택]
E --> F[모형 학습]
F --> G[모형 평가]
G --> H[하이퍼파라미터 튜닝]
H --> I[모형 배포]
I --> J[모니터링 및 유지보수]
데이터 수집: 텍스트 데이터와 해당 레이블이 포함된 데이터셋을 수집한다. 감성 분석의 경우, 라벨은 ‘긍정’, ‘부정’ 또는 ’중립’이 되고, 텍스트 분류의 경우 레이블은 다양한 주제나 카테고리를 나타낼 수 있다. 즉, 자연어 처리 목적에 맞춰 라벨을 특정하고 연관 데이터를 수집한다.
데이터 전처리: 텍스트 데이터를 정리하고 전처리하여 추가 분석에 적합하도록 작업하는데 소문자화, 토큰화, 불용어 제거, 특수문자 제거, 어간 단어 기본형으로 줄이기 등이 포함된다.
피쳐 추출:사전 처리된 텍스트를 기계 학습 알고리즘에 적합한 숫자 형식으로 변환하는 과정으로 BoW, TF-IDF, 단어 임베딩 등이 흔히 사용되는 기법이다.
훈련-시험 데이터셋 분할: 일반적으로 70-30, 80-20 또는 기타 원하는 분할 비율을 사용하여 데이터셋을 훈련과 시험 데이터셋으로 구분한다.
모형 선택: 적합한 통계, 머신 러닝, 딥러닝 모델을 선정한다.
모형 학습: 적절한 최적화 알고리즘과 손실 함수를 사용하여 훈련 데이터셋에서 선택한 모델을 학습시킨다.
모형 평가: 정확도, 정밀도, 리콜, F1 점수 또는 ROC 곡선 아래 영역과 같은 관련 메트릭을 사용하여 시험 데이터셋에서 학습 모형의 성능을 평가한다.
하이퍼파라미터 튜닝: 격자 검색 또는 무작위 검색과 같은 기술을 사용하여 모형의 하이퍼파라미터를 최적화하여 성능을 개선한다.
모형 배포: 모형을 학습하고 최적화한 후에는 실제 환경에서 사용할 수 있도록 실제 운영 환경에 배포하여 가치를 창출한다.
모니터링 및 유지 관리: 배포된 모형의 성능을 지속적으로 모니터링하고 필요에 따라 새로운 학습데이터로 업데이트하여 정확성과 효율성을 유지한다.
3 비교
3.1 NLP vs LLM
지구상의 거의 모든 텍스트 데이터를 학습한 거대언어모형(LLM)이 존재하는 상황이기 때문에 적절한 LLM을 선택한 후에 좀더 성능을 높이기 위해서 추가 학습데이터를 수집하여 미세조정(Fine-tuning) 학습을 거친 후에 AI 모형을 배포하여 운영한다.
graph TB subgraph "전통적인 NLP 작업흐름 <br>" direction TB A1[Data Collection & Preprocessing] --> B1[Feature Extraction & Model Selection] B1 --> C1[Model Training & Evaluation] C1 --> D1[Hyperparameter Tuning] D1 --> E1[Deployment & Maintenance] end subgraph "거대언어기반 NLP 작업흐름 <br>" direction TB A2[Pretraining] --> B2[Fine-tuning] B2 --> C2[Model Training & Evaluation] C2 --> D2[Hyperparameter Tuning] D2 --> E2[Deployment & Maintenance] end class A1,B1,C1,D1,E1,A2,B2,C2,D2,E2 nodeStyle classDef nodeStyle fill:#ffffff,stroke:#000000,stroke-width:1px,font-weight:bold,font-size:14px;
3.2 Fine-tuning LLM vs Prompt Eng.
두가지 접근방법 모두 거대언어모형(LLM)에 기반한다는 점에서 동일하나, 추가학습 데이터를 반영한 AI 모형을 개발하느냐 아니면 프롬프트(일명 AI 프로그램)를 잘 작성한 AI 모형을 개발하느냐 차이가 존재한다. 물론 Zero-/One-/Few-Shot 예제를 반영한 프롬프트도 있고 미세조정 훈련모형에 프롬프트를 반영한 AI 모형도 존재한다. 각 문제에 맞춰 적절한 개발방법을 취하면 될 것이다.
graph TB subgraph "미세조정 작업흐름<br>LLM-based Fine-tuning Workflow" direction TB A1[사전 훈련] --> B1[미세 조정] B1 --> C1[모델 훈련 및 평가] C1 --> D1[하이퍼파라미터 튜닝] D1 --> E1[배포 및 유지보수] end subgraph "프롬프트 공학 작업흐름<br>Prompt Engineering Workflow" direction TB A2[사전 학습] --> B2[프롬프트 설계] B2 --> C2[모델 추론 및 후처리] C2 --> D2[모델 평가] D2 --> E2[배포 및 유지보수] end class A1,B1,C1,D1,E1,A2,B2,C2,D2,E2 nodeStyle classDef nodeStyle fill:#93c47d,stroke:#000000,stroke-width:1px,font-weight:bold,font-size:14px;
3.3 비교
LLM 모형을 오픈소스 소프트웨어 공개하는 경우 이를 돌릴 수 있는 강력한 하드웨어가 필요하기도 하고, LLM을 비공개하는 경우 구독형으로 비용을 청구하여 AI 서비스를 제공하는 경우도 존재한다. 해당 문제를 가장 잘 해결할 수 있는 AI 개발방법론을 주어진 제약조건에서 장단점을 비교하여 풀어가면 좋은 결과가 기대된다.
| Perspective | Traditional NLP | LLM Fine-tuning | LLM Prompt Engineering |
|---|---|---|---|
| Model Adaptation | Feature extraction and model selection | Fine-tuning on task-specific data | Crafting effective prompts |
| Labeled Data Requirements | Requires labeled data for model training | Requires labeled data for fine-tuning | Requires fewer labeled examples, if any |
| Computational Resources | Can vary, but generally lower than LLM Fine-tuning | Higher due to fine-tuning | Lower, as fine-tuning is not required |
| Performance | May be lower than LLM-based approaches | Typically better due to task-specific fine-tuning | Competitive, but may require more manual effort |
| Effort and Creativity | Requires more manual feature engineering | Requires less manual effort in prompt design | Requires more creativity in prompt design and iteration |
| Domain Adaptation | Less effective for domain-specific tasks | More effective for domain-specific tasks | May be limited by the pretrained model’s knowledge |
| Interpretability | More interpretable due to handcrafted features and models | Less interpretable due to fine-tuned model weights | More interpretable as output is guided by designed prompts |
| Deployment and Maintenance | Requires storing and maintaining custom models | Requires storing and maintaining fine-tuned models | Easier, as only pretrained model and prompts are needed |
| When to Use | When custom features are needed or LLMs are not available | When labeled data is available, higher performance is desired, and computational resources are sufficient | When labeled data is scarce, computational resources are limited, or rapid development and iteration are required |
4 LLM 모형
2023년 3월 10억이상 패러미터를 갖는 공개된 거대언어모형에 대한 전체적인 조사에서 강조된 점이 공개형(Open Source) 모형이냐 폐쇄형(Closed Source) 모형이냐는 점이다. (Zhao 기타, 2023)
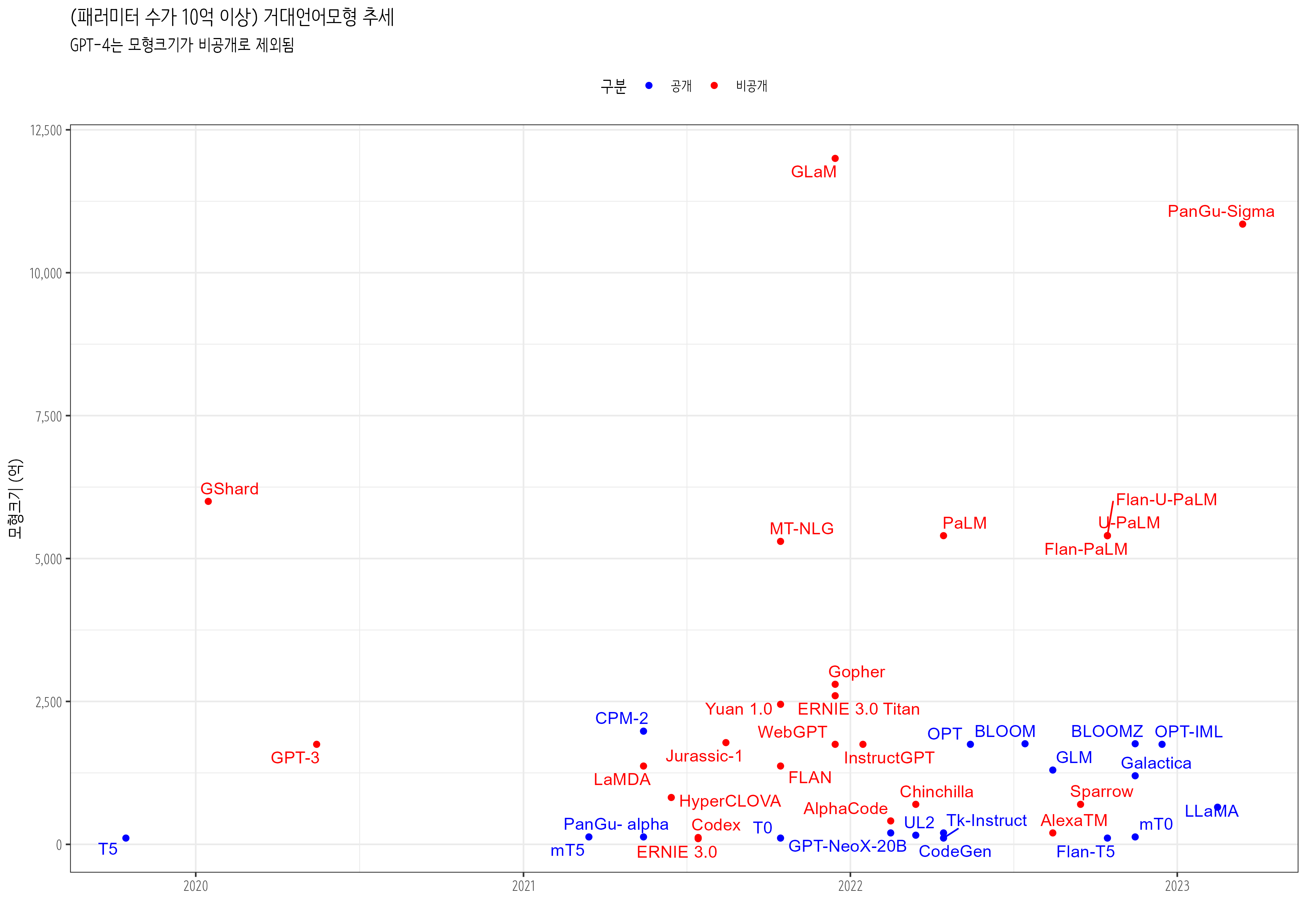
참고문헌
Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., Du, Y., Yang, C., Chen, Y., Chen, Z., Jiang, J., Ren, R., Li, Y., Tang, X., Liu, Z., … Wen, J.-R. (2023). A Survey of Large Language Models. https://arxiv.org/abs/2303.18223