The hottest new programming language is English
— Andrej Karpathy ((karpathy?)) January 24, 2023
기계학습과 예전 신경망 모형이 특정 작업을 위해 설계된 특수 목적의 컴퓨터라면, GPT는 자연어 프로그램을 실행하기 위해 런타임에 재구성되는 범용 컴퓨터다. 처음 프롬프트[일종의 시작(inception)]가 프로그램 형태로 제공되고, 거대언어모형(GPT)는 문서를 완성하도록 프로그램을 실행한다.
1 Few-Shot 학습
GPT-3 논문 (Brown 기타, 2020) 에서 거대언어모형(LLM)이 컨텍스트 내 학습(in-context learning)을 수행하며, 입력:출력 예제를 통해 프롬프트 내에서 다양한 작업을 수행하도록 “프로그래밍”할 수 있음을 시연했다. 즉, 언어 모델을 확장하면 작업별 미세 조정(Fine-tuning) 없이 몇 가지 예제 또는 간단한 지침만으로 수행작업의 성능향상을 기대해볼 수 있다.

전통적인 미세조정(Fine tuning)과 제로샷, 원샷, 퓨샷과 대비하면 명확해진다. 미세조정(Fine tuning)은 전통적인 방법이지만, 제로샷, 원샷, 퓨샷은 순방향으로 작업을 수행하는 모델을 필요로 한다.
작업: 감성 분석 (주어진 텍스트를 긍정적, 부정적, 중립적으로 분류)
입력: “어제 놀이공원에서 정말 즐거운 하루를 보냈어요!”
출력: 긍정적
작업: 주어진 텍스트로 설명된 동물 파악하기
예시: “이 동물은 긴 목과 반점이 특징인데, 아프리카에서 발견할 수 있어요.” 답변: 기린
입력: “이 동물은 주머니가 있고 호주 원주민이며, 껑충 뛰는 능력으로 유명해요.”
출력 : 캥거루
작업: 주어진 문장을 능동태에서 수동태로 바꾸기
예시 1: “철수가 샌드위치를 먹었다.” 답변: “샌드위치가 철수에게 먹혔다.”
예시 2: “고양이가 쥐를 쫓았다.” 답변: “쥐가 고양이에게 쫓겼다.”
입력: “선생님이 학생을 칭찬했다.”
출력: “학생이 선생님에게 칭찬받았다.”
2 Chain-of-Thought (CoT)
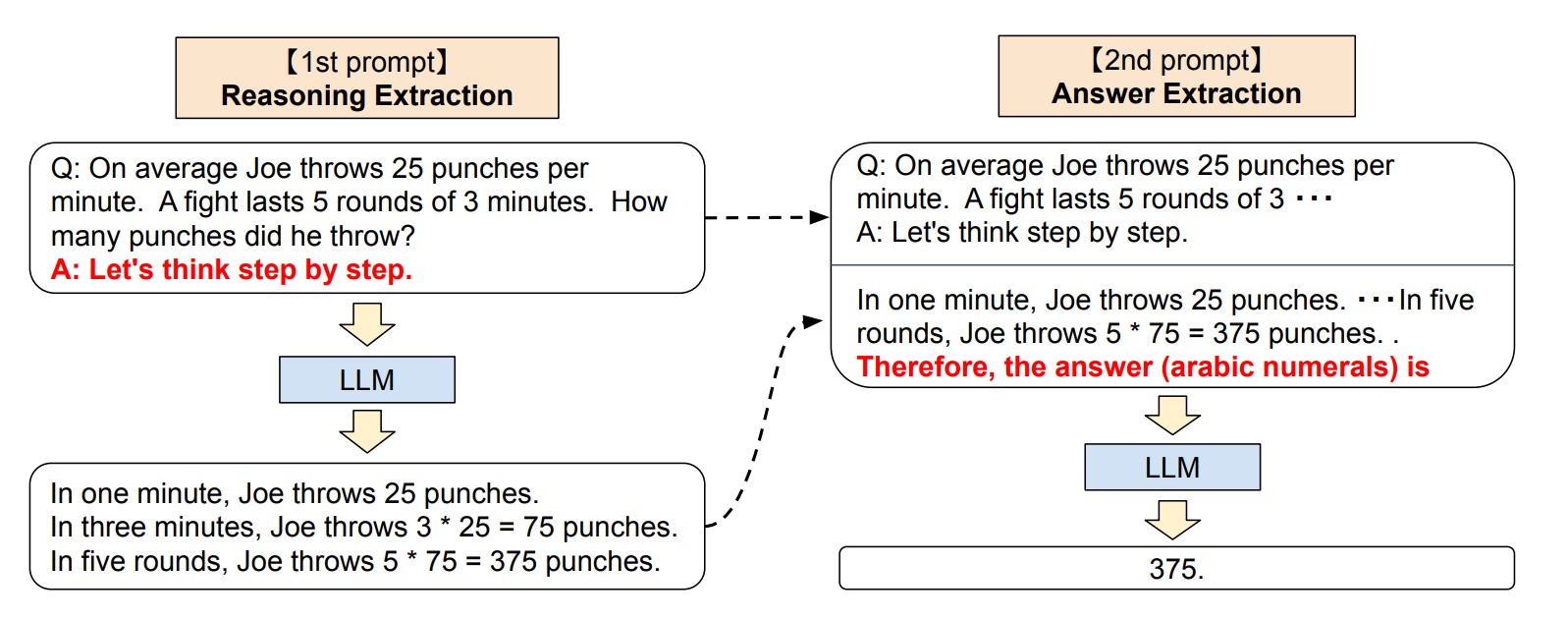
작업별 예제 없이 거대언어모형(LLM)에 사고의 사슬(Chain of Thought)를 통해 복잡한 다단계 추론이 가능하다. 각 답변 앞에 “단계별로 생각해 봅시다(Let’s think step by step)”를 추가함으로써 산술, 기호 추론, 논리적 추론과 같은 다양한 추론 작업에서 표준 제로샷 프롬프트보다 훨씬 뛰어난 성능을 발휘했다. (Kojima 기타, 2023)

GPT-Turbo, GPT-4 모델은 해당문제를 바로 정확히 풀 수 있으나 Legacy (GPT-3.5)는 CoT 기법을 적용해야 정답을 이끌어낼 수 있다.
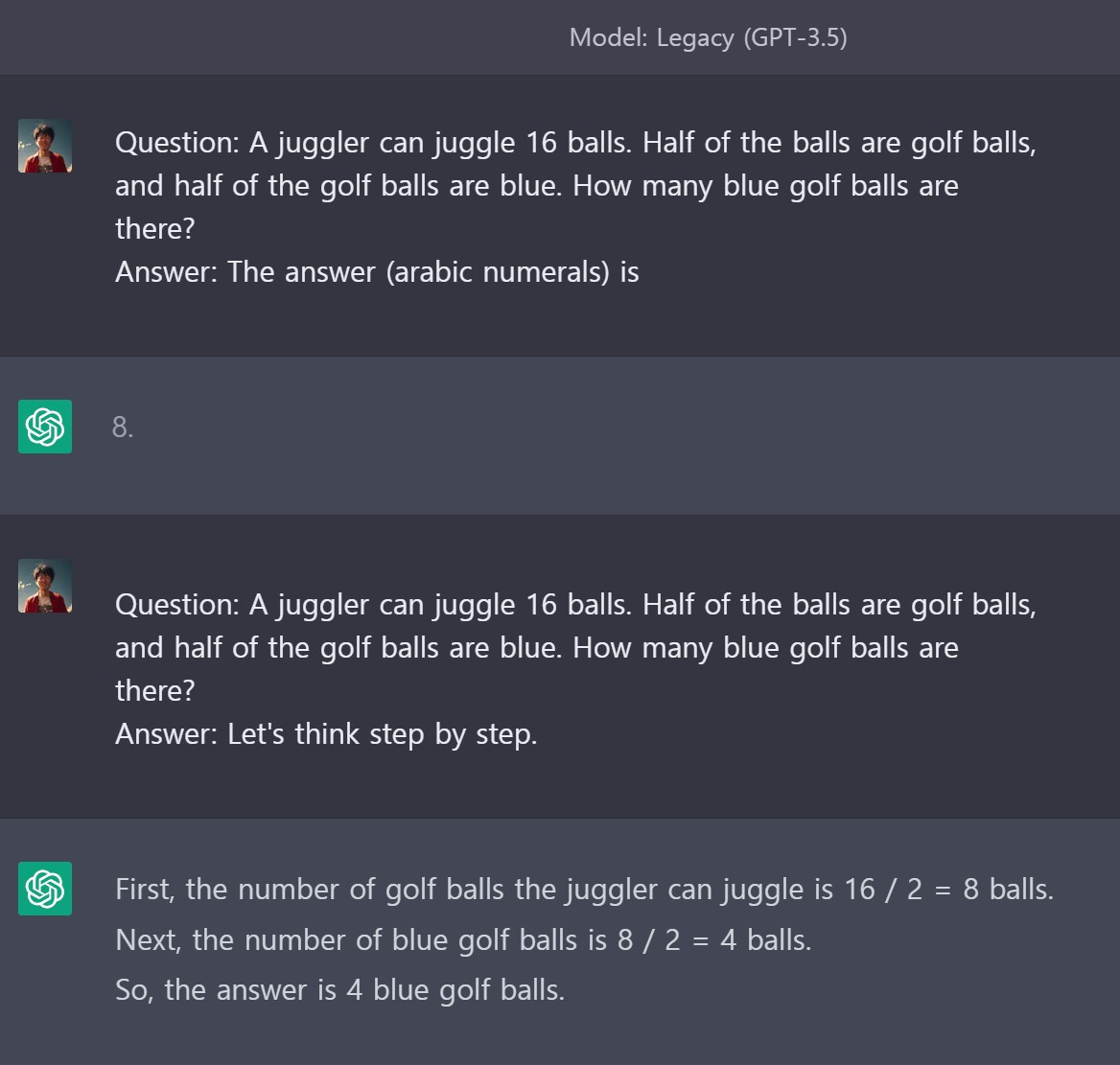
명령어 자동 생성 및 선택을 위한 자동 프롬프트 엔지니어(Automatic Prompt Engineer, APE)는 프롬프트 명령(instruction)을 프로그램으로 간주하고 거대언어모형(LLM)이 제안한 대한 선택지를 검색하여 선택한 목적 함수를 최대화하는 명령어를 최적화시킨 다음 선택한 명령어를 다른 LLM을 사용하여 평가하는 방법도 제시되었다. (Zhou 기타, 2023)
3 성과지표 설정
잘 작성된 프롬프트에는 원하는 목표 성과가 포함되어야 한다. GPT는 최선을 다해 성공을 추구하지 않고 모방만 할 뿐이다. 좋은 결과를 원한다면 달성해야 되는 성공을 명시해야 한다. (Chen 기타, 2021)
“Please provide a step-by-step guide on how to achieve top-tier performance in time management and productivity techniques, so I can excel in my personal and professional life.”
“I aspire to become an exceptional public speaker. Can you offer me comprehensive advice, including tips, tricks, and exercises that will help me develop outstanding presentation skills?”
“I am determined to become a top-performing sales professional. Share with me the essential skills, strategies, and habits that I must adopt to excel in this competitive field.”
“I wish to become a highly respected and successful leader. Could you provide insights, examples, and actionable steps to develop strong leadership qualities and excel in any organization?”
“I desire to master the art of negotiation and achieve win-win outcomes. Please provide me with detailed guidance, best practices, and real-life examples that will enable me to excel in negotiations.”
“My goal is to become a top performer in project management. Can you outline the key principles, methodologies, and tools that will help me successfully manage projects and exceed expectations?”
“I aspire to be an excellent writer, able to captivate my audience and inspire them through my words. Please provide me with writing techniques, exercises, and recommendations that will elevate my writing skills to the highest level.”
“I am determined to achieve peak physical fitness and athletic performance. Share with me the best workout routines, nutrition tips, and mental strategies that will help me reach my full potential as an athlete.”
“I want to excel in the art of problem-solving and critical thinking. Please provide me with the necessary tools, frameworks, and exercises that will help me become an exceptional problem solver and thinker.”
“My goal is to become a highly skilled and successful investor. Can you provide me with the most effective strategies, tips, and resources that will enable me to outperform in the world of investing?”
“시간 관리 및 생산성 기술에서 최고 수준의 성과를 달성하는 방법에 대한 단계별 가이드를 제공하여 개인 및 직장 생활에서 탁월함을 발휘할 수 있도록 도와주세요.”
“저는 뛰어난 대중 연설가가 되고 싶습니다. 뛰어난 프레젠테이션 기술을 개발하는 데 도움이 되는 팁, 요령 및 연습 문제를 포함한 포괄적인 조언을 제공해 주시겠습니까?”
“최고의 성과를 내는 영업 전문가가 되기로 결심했습니다. 경쟁이 치열한 이 분야에서 뛰어난 성과를 내기 위해 반드시 갖춰야 할 필수 기술, 전략 및 습관을 알려주세요.”
“존경받고 성공적인 리더가 되고 싶습니다. 강력한 리더십 자질을 개발하고 어떤 조직에서든 뛰어난 성과를 낼 수 있는 인사이트, 사례, 실행 가능한 단계를 알려주시겠어요?”
“협상의 기술을 습득하여 서로 윈윈하는 결과를 얻고 싶습니다. 협상에서 탁월한 능력을 발휘할 수 있도록 자세한 지침, 모범 사례 및 실제 사례를 제공해 주세요.”
“제 목표는 프로젝트 관리 분야에서 최고의 성과를 내는 것입니다. 프로젝트를 성공적으로 관리하고 기대치를 초과 달성하는 데 도움이 되는 핵심 원칙, 방법론 및 도구를 간략하게 설명해 주시겠습니까?”
“저는 글을 통해 청중을 사로잡고 영감을 줄 수 있는 훌륭한 작가가 되고 싶습니다. 제 글쓰기 실력을 최고 수준으로 끌어올릴 수 있는 글쓰기 기법, 연습 문제, 권장 사항을 제공해 주세요.”
“최고의 체력과 운동 능력을 갖추기 위해 노력하고 있습니다. 운동선수로서 제 잠재력을 최대한 발휘하는 데 도움이 될 최고의 운동 루틴, 영양 팁, 정신 전략을 알려주세요.”
“문제 해결 능력과 비판적 사고력이 뛰어나고 싶습니다. 뛰어난 문제 해결자이자 사상가가 되는 데 도움이 되는 필요한 도구, 프레임워크, 연습 문제를 제공해 주세요.”
“제 목표는 고도로 숙련되고 성공적인 투자자가 되는 것입니다. 투자 세계에서 뛰어난 성과를 낼 수 있는 가장 효과적인 전략, 팁, 리소스를 제공해 주실 수 있나요?”
4 자기 일관성
기존 사고 사슬(Chain of Thought)의 한계를 넘어서 제시된 자기 일관성(Self-consistency)은 복잡한 추론 문제에서 일반적으로 고유한 정답으로 이어지는 여러 가지 사고 방식을 인정한다는 직관을 활용한다. (Wang 기타, 2023)
자기 일관성 기법은 다음 3단계를 거쳐 최종 답을 제시한다.
- 사고의 사슬(CoT) 프롬프트를 사용하여 거대언어모형에 프롬프트 생성한다.
- CoT 프롬프트가 “Greedy Decoding” 최선을 추구하는 반면, 거대언어모형 디코더에서 표본을 추출하여 다양한 추론 경로 집합을 생성한다.
- 추론 경로를 한계화하고 최종 답변 세트에서 가장 일관된 답변을 선택 및 집계하여 제시한다.
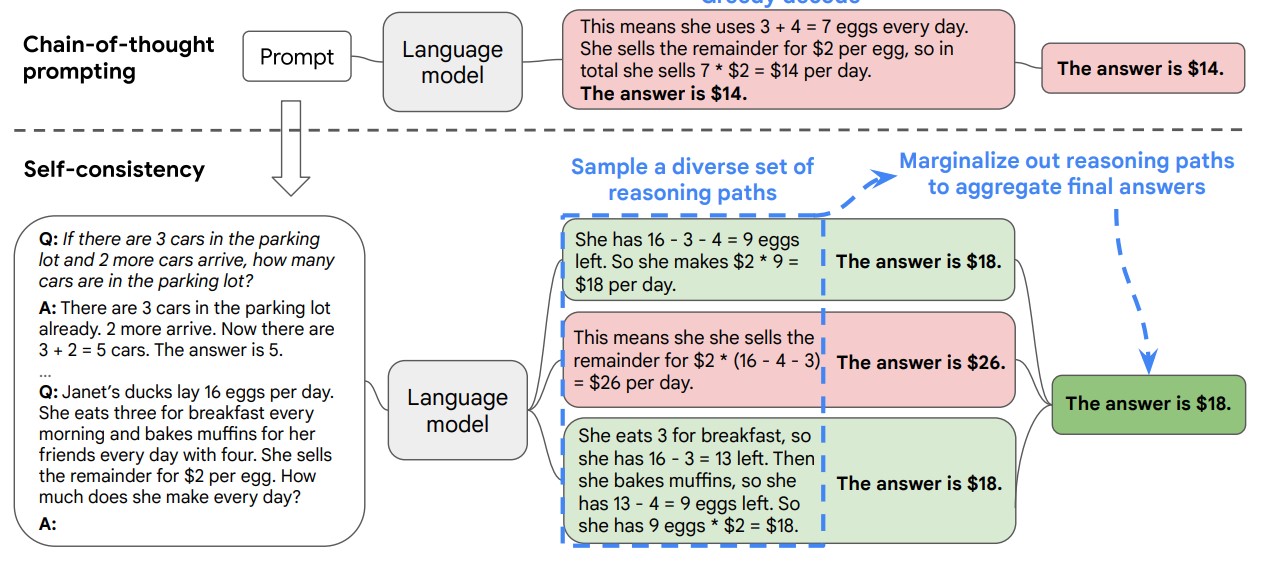
당신이 6살이었을 때 여동생은 당신의 나이의 절반이었으므로, 여동생은 당신보다 3살 어렸습니다. 지금 당신이 70살이니, 여동생은 여전히 당신보다 3살 어립니다. 따라서 여동생은 70 - 3 = 67살입니다.
5 Generated Knowledge Prompting
생성된 지식 프롬프트(Generated Knowledge Prompting)는 몇 번의 데모를 통해 언어 모델에서 질문과 관련된 지식 진술을 이끌어내고, 해당 지식이 있는 다른 언어 모델에 프롬프트를 표시하여 예측을 유도하는 기법이다. (Liu 기타, 2022)
- 언어 모델에서 질문과 관련된 지식 진술을 생성하기 위해 몇 장면의 데모를 사용.
- 제2언어 모델을 사용하여 각 지식 진술에 대해 예측을 한 다음 가장 신뢰도가 높은 예측을 취사선택.
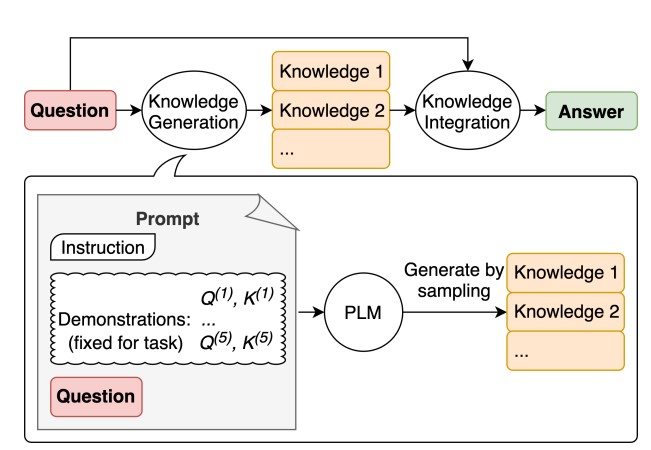
지식: 골프의 목표는 최소한의 스트로크로 일련의 홀을 플레이하는 것입니다. 골프 라운드는 일반적으로 18홀로 구성됩니다. 각 홀은 표준 골프 코스에서 라운드 중 한 번씩 플레이됩니다. 각 스트로크는 1점으로 계산되며, 총 스트로크 수가 게임의 승자를 결정하는 데 사용됩니다.
아니오, 골프의 목표는 다른 사람보다 더 높은 총점을 얻는 것이 아닙니다. 대신, 최소한의 스트로크로 일련의 홀을 완주하는 것이 목표입니다. 골프에서는 각 스트로크가 1점으로 계산되며, 라운드 종료 시점에서 스트로크 수가 가장 적은 선수가 승자로 간주됩니다. 따라서 골프에서는 점수가 낮을수록 좋습니다.
예, 골프 게임은 다른 사람보다 더 높은 총점을 얻기 위해 노력하는 게임입니다.
6 가상 컴퓨터
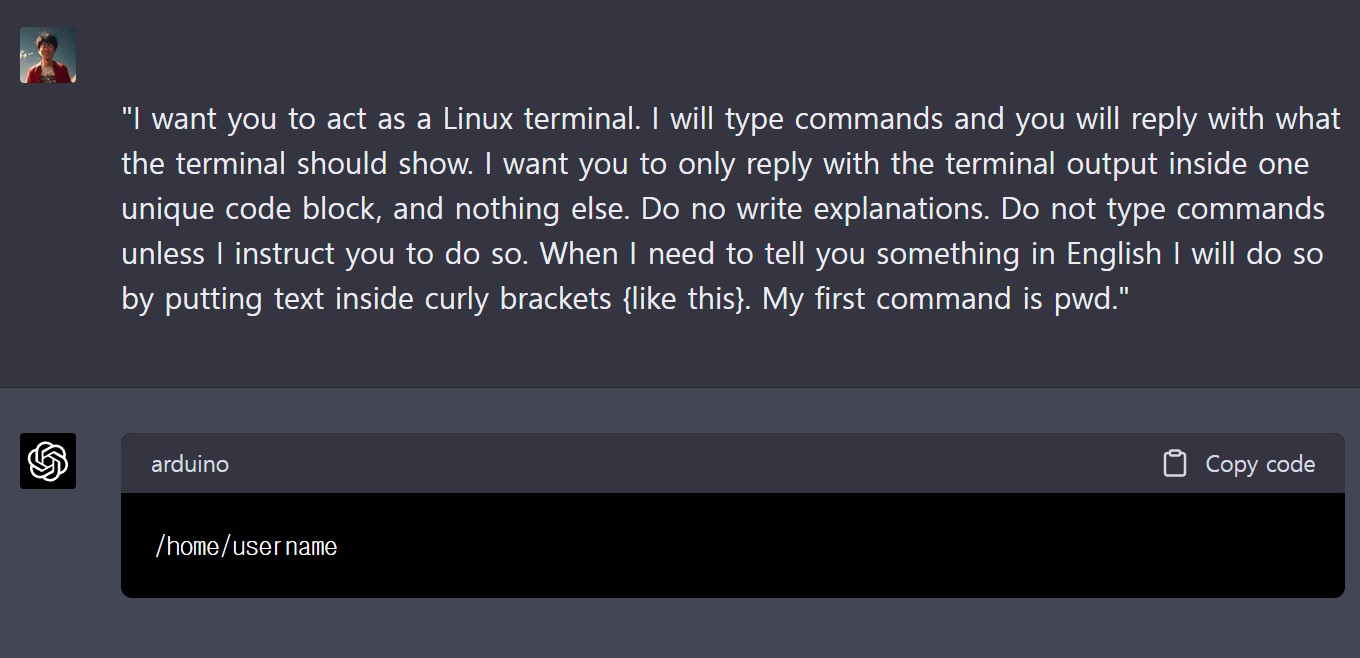
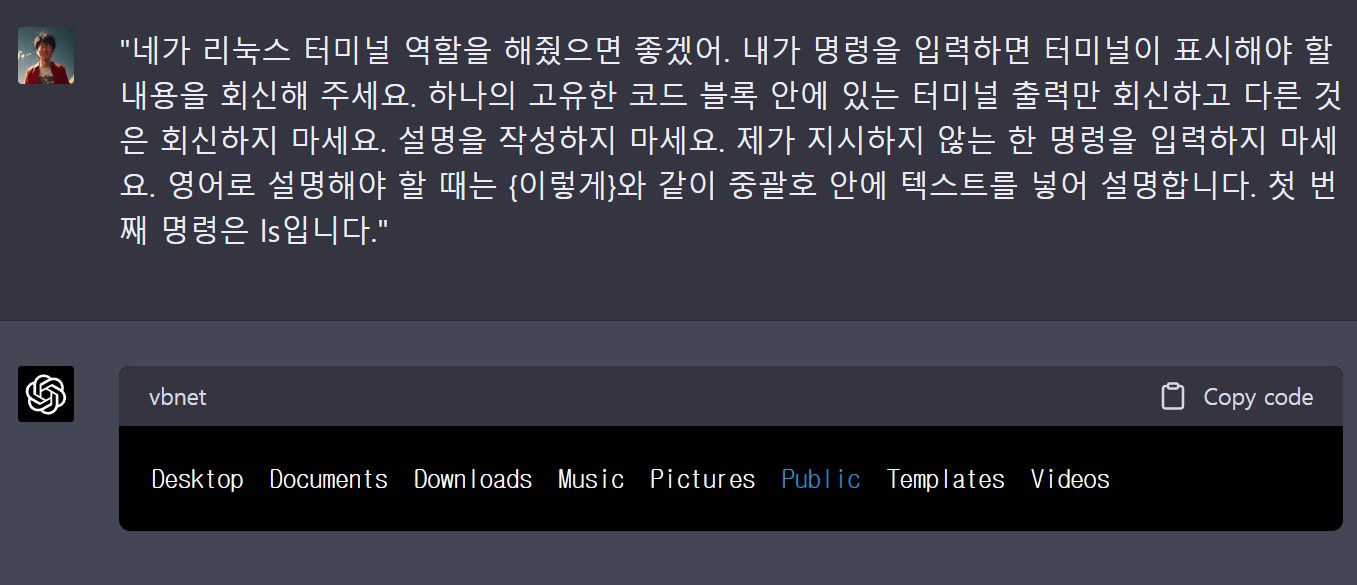
ChatGPT 내부에서 전체 가상 컴퓨터를 만들어 실행시킬 수 있다. 가상 컴퓨터는 파일 시스템 작동 방식을 이해하고 프로그래밍도 가능하다.
“I want you to act as a Linux terminal. I will type commands and you will reply with what the terminal should show. I want you to only reply with the terminal output inside one unique code block, and nothing else. Do no write explanations. Do not type commands unless I instruct you to do so. When I need to tell you something in English I will do so by putting text inside curly brackets {like this}. My first command is pwd.”
“네가 리눅스 터미널 역할을 해줬으면 좋겠어. 내가 명령을 입력하면 터미널이 표시해야 할 내용을 회신해 주세요. 하나의 고유한 코드 블록 안에 있는 터미널 출력만 회신하고 다른 것은 회신하지 마세요. 설명을 작성하지 마세요. 제가 지시하지 않는 한 명령을 입력하지 마세요. 영어로 설명해야 할 때는 {이렇게}와 같이 중괄호 안에 텍스트를 넣어 설명합니다. 첫 번째 명령은 ls입니다.”