library(tidyverse)# fs::dir_ls(path="data/LibriSpeech/dev-clean/1993/147149")trans_txt<-read_lines("data/LibriSpeech/dev-clean/1993/147149/1993-147149.trans.txt")# trans_0011_str <- trans_txt[str_detect(trans_txt, "0011")]# trans_str <- str_extract_all(trans_0011_str, "[a-zA-Z].+")[[1]]trans_0011<-trans_txt%>%enframe()%>%separate(value, into =c("순번", "텍스트"), sep ="\\s", extra ="merge")%>%mutate(텍스트 =str_to_lower(텍스트))%>%filter(str_detect(순번, "0011"))%>%pull(텍스트)
then the mother lifted up her voice and wept
영어 음성
영어 음성을 들어보자. .flac 파일을 av 패키지 av_audio_convert() 함수로 .mp3 혹은 .wav 파일 변환이 가능하다.
코드
library(av)library(embedr)audio_file<-"data/LibriSpeech/dev-clean/1993/147149/1993-147149-0011.flac"av::av_audio_convert(audio_file, output ="data/whisper_before.mp3", format ="mp3", sample_rate =16000)#> [1] "D:\\tcs\\chatGPT\\data\\whisper_before.mp3"whisper_before_mp3<-av::read_audio_bin("data/whisper_before.mp3")embedr::embed_audio("data/whisper_before.mp3")
2whisper STT
영어 음성에서 텍스트로 전환하는 작업을 STT(Speech-to-Text)라고 부르는데 최근 성능도 많이 좋아졌고 그중 챗GPT 인기를 얻고 있는 whisper API를 사용해서 영어 음성을 텍스트로 변환할 수도 있고, C/C++로 OpenAI의 Whisper 모델 이식한 whisper.cpp 모델을 사용하면 CPU로 무료로 사용가능하다.
audio.whisper 패키지가 최근에 출시되어 이를 사용하면 수월히 R에서도 STT 작업을 수행할 수 있다.
모형
언어
크기
필요 RAM 크기
tiny & tiny.en
Multilingual & English only
75 MB
390 MB
base & base.en
Multilingual & English only
142 MB
500 MB
small & small.en
Multilingual & English only
466 MB
1.0 GB
medium & medium.en
Multilingual & English only
1.5 GB
2.6 GB
large-v1 & large
Multilingual
2.9 GB
4.7 GB
whisper() 입력 오디오는 16비트 .wav 파일형식만 가능하다. 따라서 av 패키지 av_audio_convert() 함수로 원본 파일(.flac)을 .wav 파일로 변환한 후에 STT 작업을 수행한다.
.flac → .wav
.flac 파일을 .wav 파일로 변환시킨다.
코드
library(audio.whisper)av::av_audio_convert(audio_file, output ="data/whisper_before.wav", format ="wav", sample_rate =16000)#> [1] "D:\\tcs\\chatGPT\\data\\whisper_before.wav"
STT 결과
base.en 모델을 사용해서 STT로 영어음성에서 텍스트를 추출한다.
코드
model<-whisper("base.en")#> whisper_init_from_file: loading model from 'D:/tcs/chatGPT/ggml-base.en.bin'#> whisper_model_load: loading model#> whisper_model_load: n_vocab = 51864#> whisper_model_load: n_audio_ctx = 1500#> whisper_model_load: n_audio_state = 512#> whisper_model_load: n_audio_head = 8#> whisper_model_load: n_audio_layer = 6#> whisper_model_load: n_text_ctx = 448#> whisper_model_load: n_text_state = 512#> whisper_model_load: n_text_head = 8#> whisper_model_load: n_text_layer = 6#> whisper_model_load: n_mels = 80#> whisper_model_load: f16 = 1#> whisper_model_load: type = 2#> whisper_model_load: mem required = 215.00 MB (+ 6.00 MB per decoder)#> whisper_model_load: kv self size = 5.25 MB#> whisper_model_load: kv cross size = 17.58 MB#> whisper_model_load: adding 1607 extra tokens#> whisper_model_load: model ctx = 140.60 MB#> whisper_model_load: model size = 140.54 MBtrans<-predict(model, newdata ="data/whisper_before.wav", language ="en", n_threads =2)#> Processing data/whisper_before.wav (49920 samples, 3.12 sec), lang = en, translate = 0, timestamps = 0#> #> [00:00:00.000 --> 00:00:03.000] Then the mother lifted up her voice and wept.trans$data#> segment from to#> 1 1 00:00:00.000 00:00:03.000#> text#> 1 Then the mother lifted up her voice and wept.
1, 00:00:00.000, 00:00:03.000, Then the mother lifted up her voice and wept.
결국 유튜브 동영상으로 올려 한글 자막을 입히는 것이 최종 목적이기 때문에 .mp4 파일에서 이미지 정보 대신 오디오 정보만 .wav, .mp3 파일로 추출해서 뽑아낸다.
STT(Speech-to-Text) 영어 음성을 영어 텍스트로 전사(transcribe)해야 하는 작업이 필요하기 때문에 다양한 모델이 있지만 성능이 좋다고 인정받는 OpenAI Whisper 를 사용한다.
OpenAI Whisper API는 OpenAI의 API를 통해 사용할 수 있는 음성-텍스트 변환 모델이며 Whisper의 오픈 소스 버전은 Github에서 사용할 수 있다. 오픈 소스 버전의 Whisper와 OpenAI의 API를 통해 제공되는 버전은 차이가 없지만, OpenAI의 Whisper API를 사용할 경우, 시스템 전반에 걸친 일련의 최적화를 통해 OpenAI는 12월부터 ChatGPT의 비용을 90% 저렴하게 이용할 수 있으며,개발자는 API에서 오픈 소스 Whisper 대형-v2 모델을 사용하여 훨씬 빠르고 비용 효율적인 결과를 얻을 수 있다.
3.1 동영상에서 오디오 추출
ffmpeg 프로그램을 사용하면 오디오를 추출할 수 있다. MP4 파일에서 16비트 깊이와 16kHz 샘플링 레이트로 오디오를 추출하여야 whisper에 입력값으로 넣을 수 있는 .wav 파일이 된다. 두가지 조건(16비트 깊이와 16kHz 샘플링)이 충족되지 않을 경우 Whisper에서 처리할 수 없다는 오류가 나온다.
16비트 깊이와 16kHz 샘플링 조건을 갖춘 .wav 파일이 준비되면 다음 단계로 음성-텍스트 변환 Whisper 모델을 선정하여 텍스트 전사 작업을 수행한다. 윈도우 10 에서 2.6 GB 영어 medium.en 모델은 알 수 없는 오류로 인해 base.en 모델을 사용하여 영어 음성에서 텍스트를 추출했다.
코드
library(audio.whisper)medium_model<-whisper("base.en")misinformation_trans<-predict(medium_model, newdata ="data/LibriSpeech/misinformation_16.wav", language ="en", n_threads =2)
몇번의 시행착오를 거쳐 순번, 시작시각, 종료시각, 텍스트로 구성된 파일을 .srt 파일 형태로 변환하여 영어 자막작업을 마무리한다.
코드
mis_srt_raw<-read_lines("data/LibriSpeech/misinformation_proof_reading.txt")mis_srt_tbl<-mis_srt_raw%>%enframe()%>%separate(value, into =c("start", "end"), sep ="\\s==>\\s", extra ="merge")%>%separate(end, into =c("end", "subtitle"), sep ="\\s", extra ="merge")%>%mutate(subtitle =str_trim(subtitle))mis_srt_tbl%>%mutate(srt =glue::glue("{name} \n {start} --> {end} \n {subtitle}\n\n"))%>%pull(srt)%>%write_lines("data/LibriSpeech/misinformation_proof_reading_srt.srt")
유튜브 동영상 영문 자막으로 사용될 .srt 자막 파일을 불러읽어와서 최종 작업결과를 살펴본다.
코드
library(tidyverse)mis_srt<-read_lines("data/LibriSpeech/misinformation.srt")mis_srt%>%head(20)#> [1] "1 " #> [2] "00:00:00.000 --> 00:00:27.520 " #> [3] "Welcome everybody to our Seoul R Online seminar where we explore various ideas and" #> [4] "" #> [5] "2 " #> [6] "00:00:27.520 --> 00:00:33.360 " #> [7] "practices of data science. We are really happy today to have Jevin West from the University" #> [8] "" #> [9] "3 " #> [10] "00:00:33.360 --> 00:00:43.040 " #> [11] "of Washington with us to talk about ChatGPT and misinformation. I'm sorry, I'll begin again."#> [12] "" #> [13] "4 " #> [14] "00:00:43.040 --> 00:00:46.480 " #> [15] "Okay, no problem. No, I do this a lot of times." #> [16] "" #> [17] "5 " #> [18] "00:00:46.480 --> 00:00:53.680 " #> [19] "Welcome everybody to our Seoul R Online seminar. We explore various ideas and" #> [20] ""
---title: "chatGPT"subtitle: "음성인식(Whisper)"author: - name: 이광춘 url: https://www.linkedin.com/in/kwangchunlee/ affiliation: 한국 R 사용자회 affiliation-url: https://github.com/bit2rtitle-block-banner: true#title-block-banner: "#562457"format: html: css: css/quarto.css theme: flatly code-fold: true code-overflow: wrap toc: true toc-depth: 3 toc-title: 목차 number-sections: true highlight-style: github self-contained: falsefilters: - lightboxlightbox: autolink-citations: trueknitr: opts_chunk: message: false warning: false collapse: true comment: "#>" R.options: knitr.graphics.auto_pdf: trueeditor_options: chunk_output_type: console---```{r}#| include: falsehtml_tag_audio <-function(file, type =c("wav")) { type <-match.arg(type) htmltools::tags$audio(controls ="", htmltools::tags$source(src = file,type = glue::glue("audio/{type}", type = type) ) )}```# 음성인식 데이터셋[OpenSLR](https://www.openslr.org/index.html)은 음성 인식을 위한 학습용 말뭉치, 음성 인식 관련 소프트웨어 등 음성 및 언어 자원을 제공하고 있다.## 오디오 표본[대규모(1000시간) 영어 음성 읽기 말뭉치](https://www.openslr.org/12)에서 영어 음성 읽기 하나를 추출해서 관련 사항을 정답문과 비교해보자.:::::::{.column-body-outset}:::::{.columns}:::{.column}### 영어 음성 대본 {.unnumbered}[대규모(1000시간) 영어 음성 읽기 말뭉치](https://www.openslr.org/12)에 포함된 영어음성대본에서 텍스트를 추출해서 다음에 영어 음성에서 텍스트 추출을 비교한다.```{r}library(tidyverse)# fs::dir_ls(path="data/LibriSpeech/dev-clean/1993/147149")trans_txt <-read_lines("data/LibriSpeech/dev-clean/1993/147149/1993-147149.trans.txt") # trans_0011_str <- trans_txt[str_detect(trans_txt, "0011")]# trans_str <- str_extract_all(trans_0011_str, "[a-zA-Z].+")[[1]]trans_0011 <- trans_txt %>%enframe() %>%separate(value, into =c("순번", "텍스트"), sep ="\\s", extra ="merge") %>%mutate(텍스트 =str_to_lower(텍스트)) %>%filter(str_detect(순번, "0011")) %>%pull(텍스트)````r trans_0011`::::::{.column}### 영어 음성 {.unnumbered}영어 음성을 들어보자. `.flac` 파일을 `av` 패키지 `av_audio_convert()` 함수로 `.mp3` 혹은 `.wav` 파일 변환이 가능하다.```{r}library(av)library(embedr)audio_file <-"data/LibriSpeech/dev-clean/1993/147149/1993-147149-0011.flac"av::av_audio_convert(audio_file, output ="data/whisper_before.mp3", format ="mp3", sample_rate =16000)whisper_before_mp3 <- av::read_audio_bin("data/whisper_before.mp3")embedr::embed_audio("data/whisper_before.mp3")```:::::::::::::::# `whisper` STT영어 음성에서 텍스트로 전환하는 작업을 STT(Speech-to-Text)라고 부르는데 최근 성능도 많이 좋아졌고 그중 챗GPT 인기를 얻고 있는 `whisper` API를 사용해서 영어 음성을 텍스트로 변환할 수도 있고, C/C++로 OpenAI의 Whisper 모델 이식한 [whisper.cpp](https://github.com/ggerganov/whisper.cpp) 모델을 사용하면 CPU로 무료로 사용가능하다.[`audio.whisper`](https://github.com/bnosac/audio.whisper) 패키지가 최근에 출시되어 이를 사용하면 수월히 R에서도 STT 작업을 수행할 수 있다.| 모형 | 언어 | 크기 | 필요 RAM 크기 ||:-----------------------|:---------------------------:|-------:|-----------:|| `tiny` & `tiny.en` | Multilingual & English only | 75 MB | 390 MB || `base` & `base.en` | Multilingual & English only | 142 MB | 500 MB || `small` & `small.en` | Multilingual & English only | 466 MB | 1.0 GB || `medium` & `medium.en` | Multilingual & English only | 1.5 GB | 2.6 GB || `large-v1` & `large` | Multilingual | 2.9 GB | 4.7 GB |`whisper()` 입력 오디오는 16비트 `.wav` 파일형식만 가능하다. 따라서 `av` 패키지 `av_audio_convert()` 함수로 원본 파일(`.flac`)을 `.wav` 파일로 변환한 후에 STT 작업을 수행한다.:::::::{.column-body-outset}:::::{.columns}:::{.column}### `.flac` → `.wav` {.unnumbered}`.flac` 파일을 `.wav` 파일로 변환시킨다.```{r}library(audio.whisper)av::av_audio_convert(audio_file, output ="data/whisper_before.wav", format ="wav", sample_rate =16000)```::::::{.column}### STT 결과 {.unnumbered}`base.en` 모델을 사용해서 STT로 영어음성에서 텍스트를 추출한다.```{r}model <-whisper("base.en")trans <-predict(model, newdata ="data/whisper_before.wav", language ="en", n_threads =2)trans$data````r trans$data`:::::::::::::::# 챗GPT와 오정보[[한국 R 컨퍼런스 - Julia Silge Keynote번역 (2021-11-17)](https://statkclee.github.io/deep-learning/rconf-keynote.html)]{.aside}2023년 서울 R 미트업에서 "챗GPT와 오정보(ChatGPT and Misinformation)"를 주제로워싱턴 대학 제빈 웨스트 교수님을 모시고 특강을 진행했다. 한정된 예산으로 직접 모시지는 못하고 줌(Zoom) 녹화로 대신했다.약 1시간 분량의 녹화분량 중 일부 불필요한 부분은 [오픈샷 비디오 편집기(OpenShot Video Editor)](https://ko.wikipedia.org/wiki/%EC%98%A4%ED%94%88%EC%83%B7)를 가지고 잘라낸다.결국 유튜브 동영상으로 올려 한글 자막을 입히는 것이 최종 목적이기 때문에 `.mp4` 파일에서 이미지 정보 대신 오디오 정보만 `.wav`, `.mp3` 파일로 추출해서 뽑아낸다. STT(Speech-to-Text) 영어 음성을 영어 텍스트로 전사(transcribe)해야 하는 작업이 필요하기 때문에 다양한 모델이 있지만 성능이 좋다고 인정받는 OpenAI Whisper 를 사용한다. [OpenAI Whisper API](https://platform.openai.com/docs/models/whisper)는 OpenAI의 API를 통해 사용할 수 있는 음성-텍스트 변환 모델이며 Whisper의 [오픈 소스 버전은 Github](https://github.com/openai/whisper)에서 사용할 수 있다. 오픈 소스 버전의 Whisper와 OpenAI의 API를 통해 제공되는 버전은 차이가 없지만, OpenAI의 Whisper API를 사용할 경우, 시스템 전반에 걸친 일련의 최적화를 통해 OpenAI는 12월부터 ChatGPT의 비용을 90% 저렴하게 이용할 수 있으며,개발자는 API에서 오픈 소스 Whisper 대형-v2 모델을 사용하여 훨씬 빠르고 비용 효율적인 결과를 얻을 수 있다.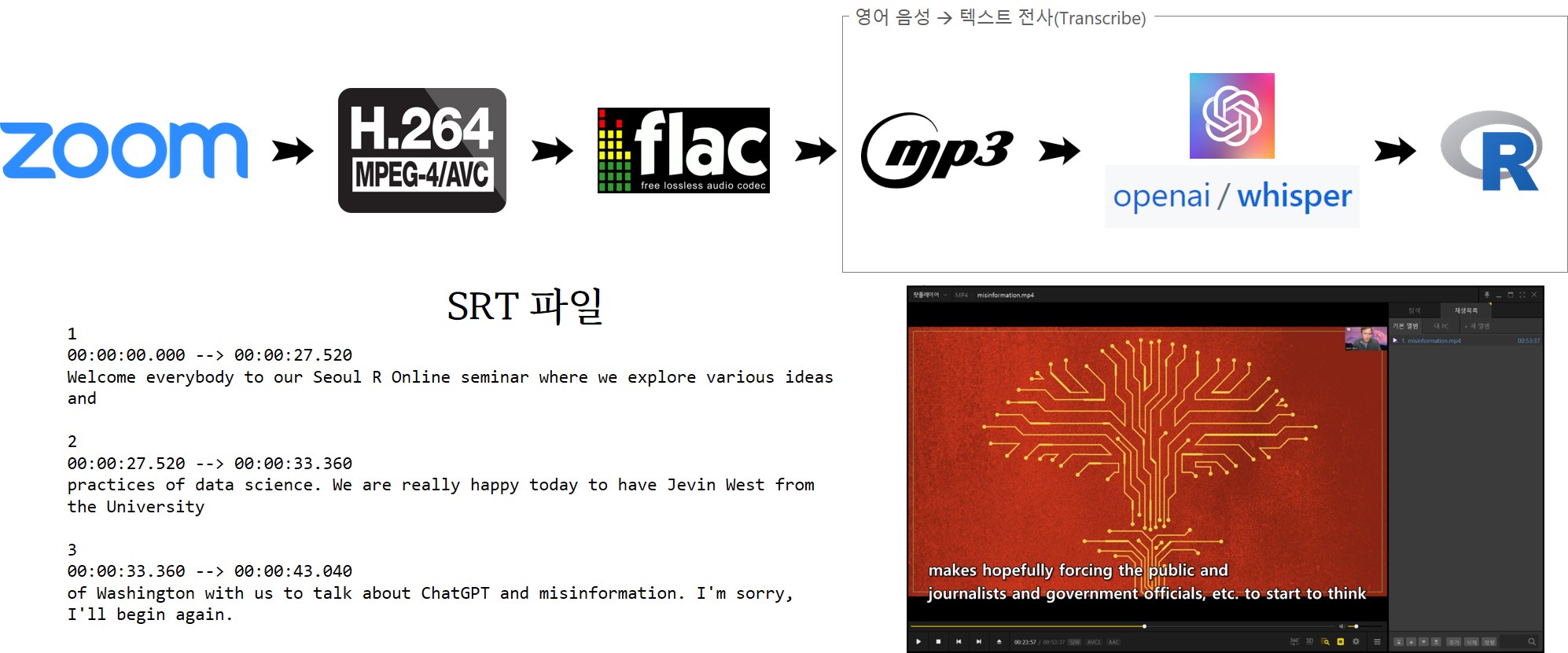## 동영상에서 오디오 추출`ffmpeg` 프로그램을 사용하면 오디오를 추출할 수 있다.MP4 파일에서 16비트 깊이와 16kHz 샘플링 레이트로 오디오를 추출하여야 `whisper`에 입력값으로 넣을 수 있는 `.wav` 파일이 된다. 두가지 조건(16비트 깊이와 16kHz 샘플링)이 충족되지 않을 경우 Whisper에서 처리할 수 없다는 오류가 나온다.:::::{.columns}:::{.column}### `.mp4`에서 `.wav` 추출 {.unnumbered}```bashffmpeg-i misinformation.mp4 -acodec pcm_s16le -ar 16000 -ac 2 misinformation_16.wav```::::::{.column}### `.mp4`에서 `.mp3` 추출 {.unnumbered}`.mp3` 확장자를 줄 경우 오디오를 `mp3` 파일로 추출하여 파일크기를 크게 줄일 수 있다.```bashffmpeg-i misinformation.mp4 -acodec pcm_s16le -ar 16000 -ac 2 misinformation.mp3```::::::::전체 `.mp3` 파일이 너무 길어 `ffmpeg`를 사용해서 30분부터 30초만 추출하는 코드를 작성해서 들어보자.```bashffmpeg-i misinformation.mp3 -ss 00:30:30 -t 00:00:30 -vn-codec:a libmp3lame -qscale:a 2 misinformation_short.mp3``````{r}embedr::embed_audio("data/LibriSpeech/misinformation_short.mp3")```## STT16비트 깊이와 16kHz 샘플링 조건을 갖춘 `.wav` 파일이 준비되면 다음 단계로 음성-텍스트 변환 Whisper 모델을 선정하여 텍스트 전사 작업을 수행한다.윈도우 10 에서 `2.6 GB` 영어 `medium.en` 모델은 알 수 없는 오류로 인해 `base.en` 모델을 사용하여 영어 음성에서 텍스트를 추출했다.```{r}#| eval: falselibrary(audio.whisper)medium_model <-whisper("base.en")misinformation_trans <-predict(medium_model, newdata ="data/LibriSpeech/misinformation_16.wav", language ="en", n_threads =2)```Whisper 모델을 통해 나온 음성-텍스트 변환 결과를 로컬 파일에 저장하여 점검한다.```{r}#| eval: falselibrary(tidyverse)misinformation_trans$data %>%mutate(data = glue::glue("{from} ==> {to} {text}")) %>%pull(data) %>%write_lines("data/LibriSpeech/misinformation_oneline.txt")```## SRT몇번의 시행착오를 거쳐 순번, 시작시각, 종료시각, 텍스트로 구성된 파일을 `.srt` 파일 형태로 변환하여 영어 자막작업을 마무리한다.```{r}#| eval: falsemis_srt_raw <-read_lines("data/LibriSpeech/misinformation_proof_reading.txt")mis_srt_tbl <- mis_srt_raw %>%enframe() %>%separate(value, into =c("start", "end"), sep ="\\s==>\\s", extra ="merge") %>%separate(end, into =c("end", "subtitle"), sep ="\\s", extra ="merge") %>%mutate(subtitle =str_trim(subtitle))mis_srt_tbl %>%mutate(srt = glue::glue("{name} \n {start} --> {end} \n {subtitle}\n\n")) %>%pull(srt) %>%write_lines("data/LibriSpeech/misinformation_proof_reading_srt.srt")```유튜브 동영상 영문 자막으로 사용될 `.srt` 자막 파일을 불러읽어와서 최종 작업결과를 살펴본다.```{r}library(tidyverse)mis_srt <-read_lines("data/LibriSpeech/misinformation.srt")mis_srt %>%head(20) ``````{r}#| eval: falselibrary(magick)mis_mp4 <-image_read_video("data/LibriSpeech/misinformation.mp4", fps =1)```