코드
remotes::install_github("rstudio/reticulate")
reticulate::install_miniconda(force = TRUE)reticulate 최신버전을 설치하고 나서, miniconda를 설치한다. 기존 설치된 경우 install_miniconda(force = TRUE) 인자를 넣어 재설치한다.
remotes::install_github("rstudio/reticulate")
reticulate::install_miniconda(force = TRUE)miniconda 설치에 어려움이 생긴경우 rminiconda가 대안이 될 수 있다.
devtools::install_github("farach/huggingfaceR")huggingfaceR README.md 파일에 실린 헬로월드 텍스트 분류 모형을 돌려보자.
library(huggingfaceR)
library(reticulate)
use_python("C:/Users/statkclee/AppData/Local/r-miniconda/envs/huggingfaceR/python.exe")
# hf_python_depends('transformers') # 빠진 라이브러리 설치
distilBERT <- hf_load_pipeline(
model_id = "distilbert-base-uncased-finetuned-sst-2-english",
task = "text-classification")
distilBERT("I like you. I love you")
#> [[1]]
#> [[1]]$label
#> [1] "POSITIVE"
#>
#> [[1]]$score
#> [1] 0.9998739library(tidyverse)
library(huggingfaceR)
library(scales)
models <- huggingfaceR::models_with_downloads
models %>%
ggplot(aes(x= downloads))+
geom_histogram(alpha = 0.8, color = "black")+
scale_x_continuous(trans = "log10", labels = comma)+
theme_bw(base_family = "sans")+
labs(title = "Log-transformed Histogram of Downloads per Model",
subtitle = "The vast majority of models have received < 1k downloads",
y = "Number of Models",
x = "Number of Downloads",
caption = paste0("Up to date as of: ", Sys.Date()))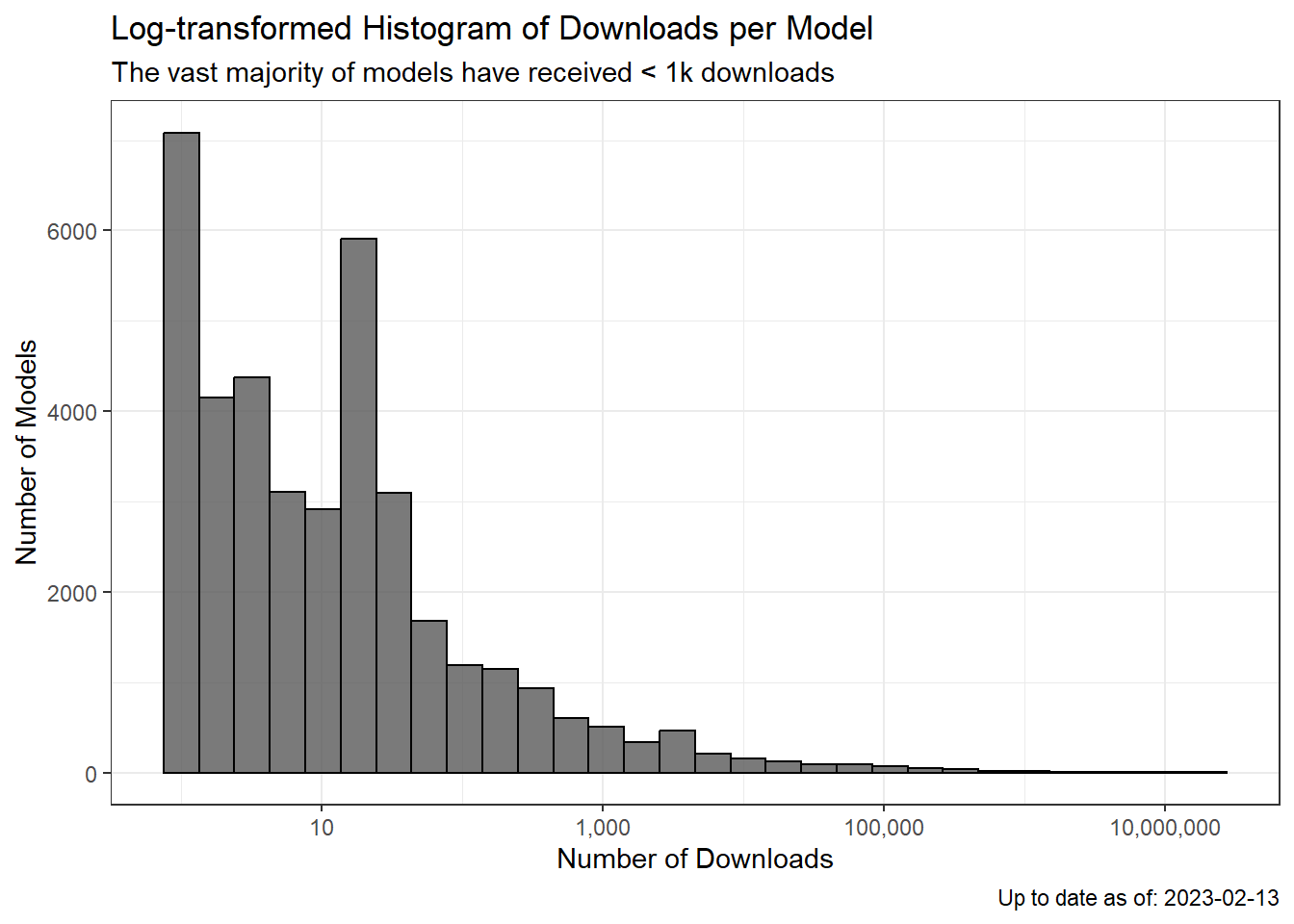
models %>%
count(task, sort = TRUE)%>%
mutate(task = stringr::str_to_title(task),
task = stringr::str_replace_all(task, "-", " "))%>%
na.omit()%>%
ggplot(aes(y= reorder(task,n), x = n))+
geom_col(fill = "#0f50d2")+
theme_bw(base_family = "sans")+
labs(title = "Models Saved on Hugging Face Hub by Task",
subtitle = "Models without download information & NA's for task omitted",
caption = paste0("Up to date as of: ", Sys.Date()),
y = "Model task",
x = "Number of models per task")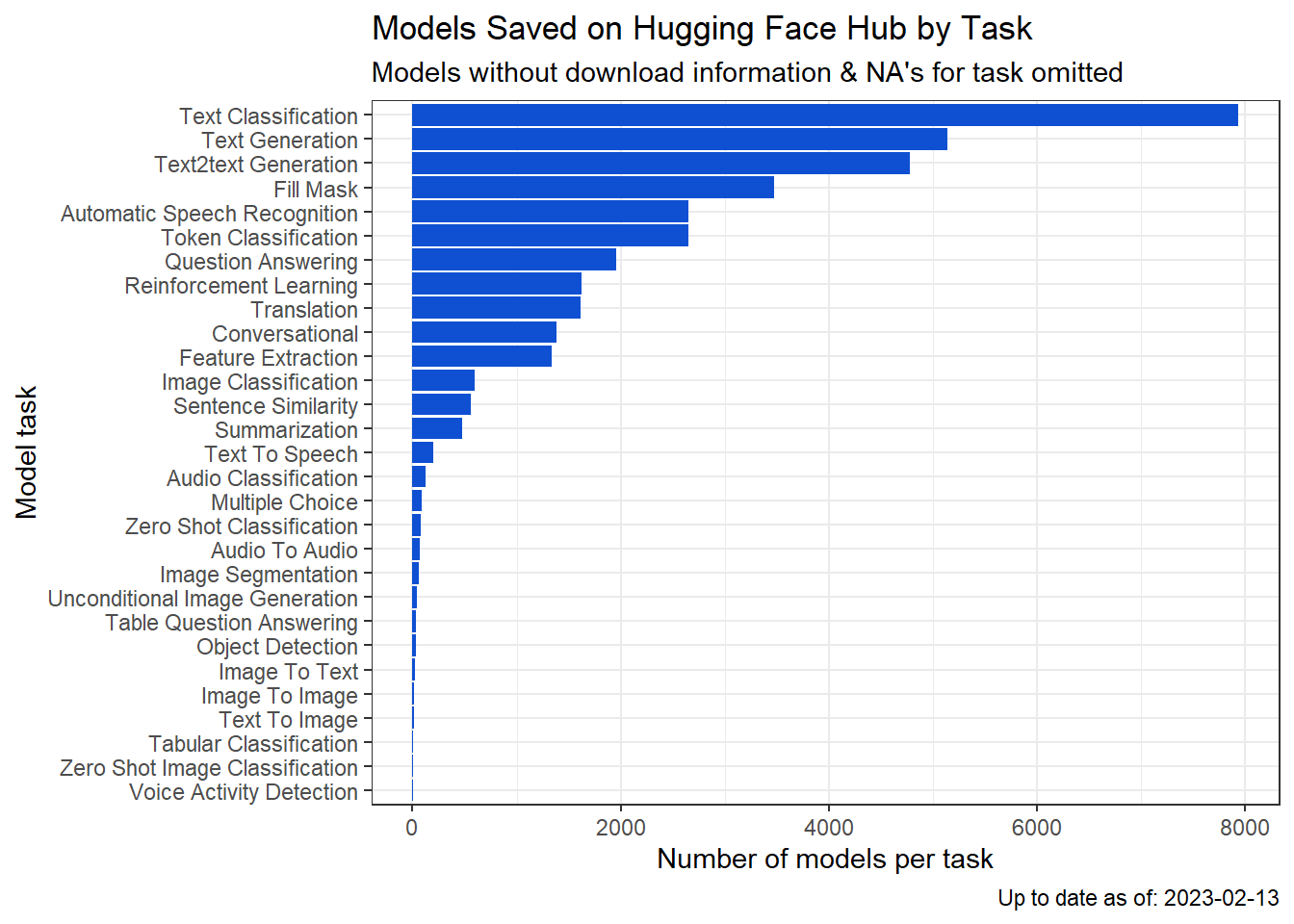
models %>%
mutate(task = forcats::fct_lump_n(task, n = 16))%>%
na.omit()%>%
group_by(task)%>%
summarise(av_dl = mean(downloads), med_dl = median(downloads), n = n())%>%
arrange(desc(av_dl))%>%
ggplot(aes(y= av_dl, x = n))+
geom_point()+
geom_text(aes(label = stringr::str_to_title(stringr::str_replace_all(task, "-", " "))),
check_overlap = TRUE, size =3, nudge_y = 350)+
theme_bw()+
labs(title = "Average Downloads per Task vs Number of Models")+
labs(y = "Average Downloads", x = "Number of Models",
caption = paste0("Up to date as of: ", Sys.Date()))+
expand_limits(x = c(-10, 8500))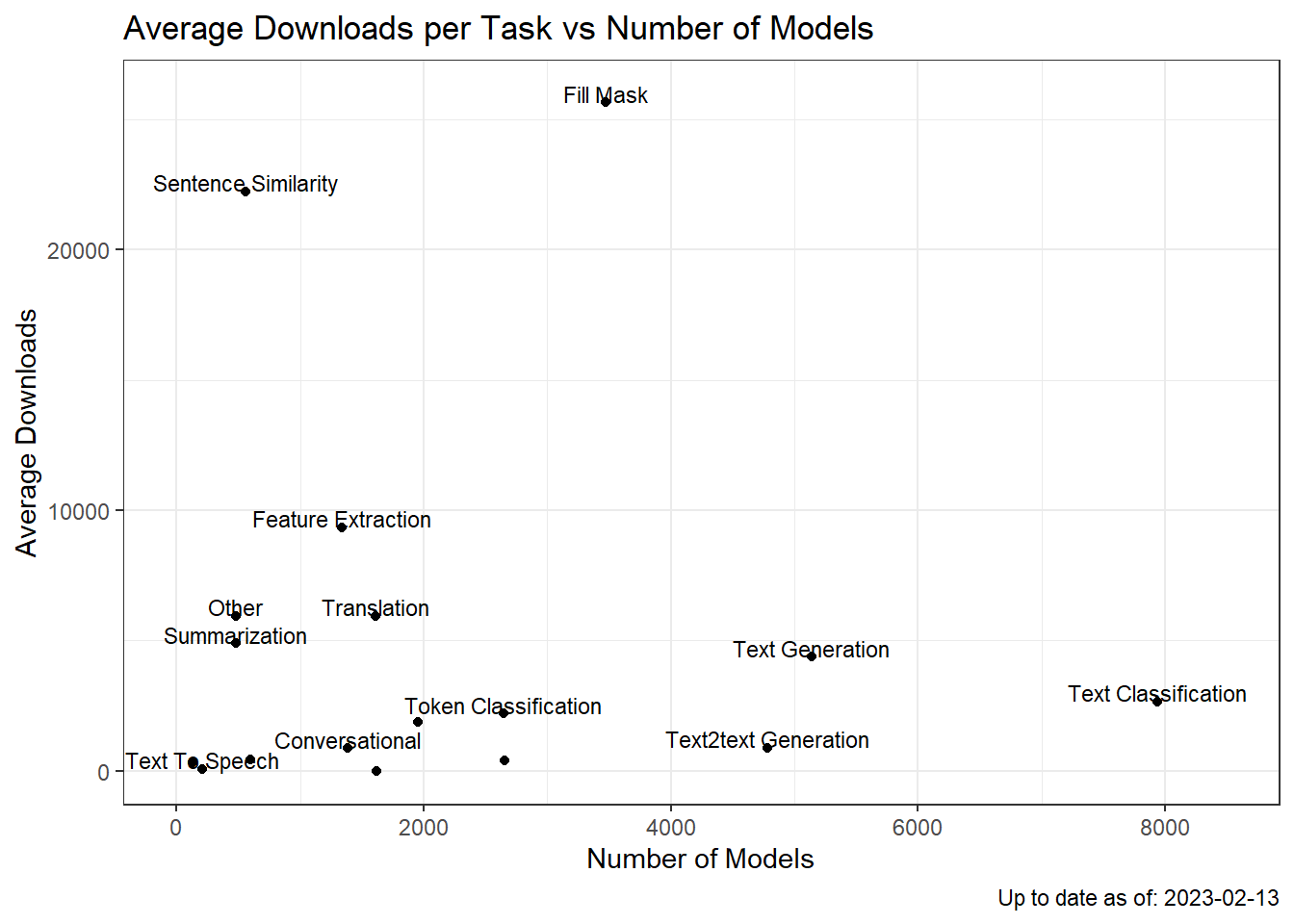
models %>%
mutate(task = forcats::fct_lump_n(task, n = 16))%>%
na.omit()%>%
group_by(task)%>%
summarise(av_dl = mean(downloads), med_dl = median(downloads), n = n())%>%
arrange(desc(av_dl))%>%
ggplot(aes(y= med_dl, x = n))+
geom_point()+
geom_text(aes(label = stringr::str_to_title(stringr::str_replace_all(task, "-", " "))),
check_overlap = FALSE, size = 3)+
theme_bw()+
labs(title = "Median Downloads per Task vs Number of Models")+
labs(y = "Median Downloads", x = "Number of Models",
caption = paste0("Up to date as of: ", Sys.Date()),
subtitle = "Median is far below mean - models are a winner-takes-most game")+
expand_limits(x = c(-100, 8500))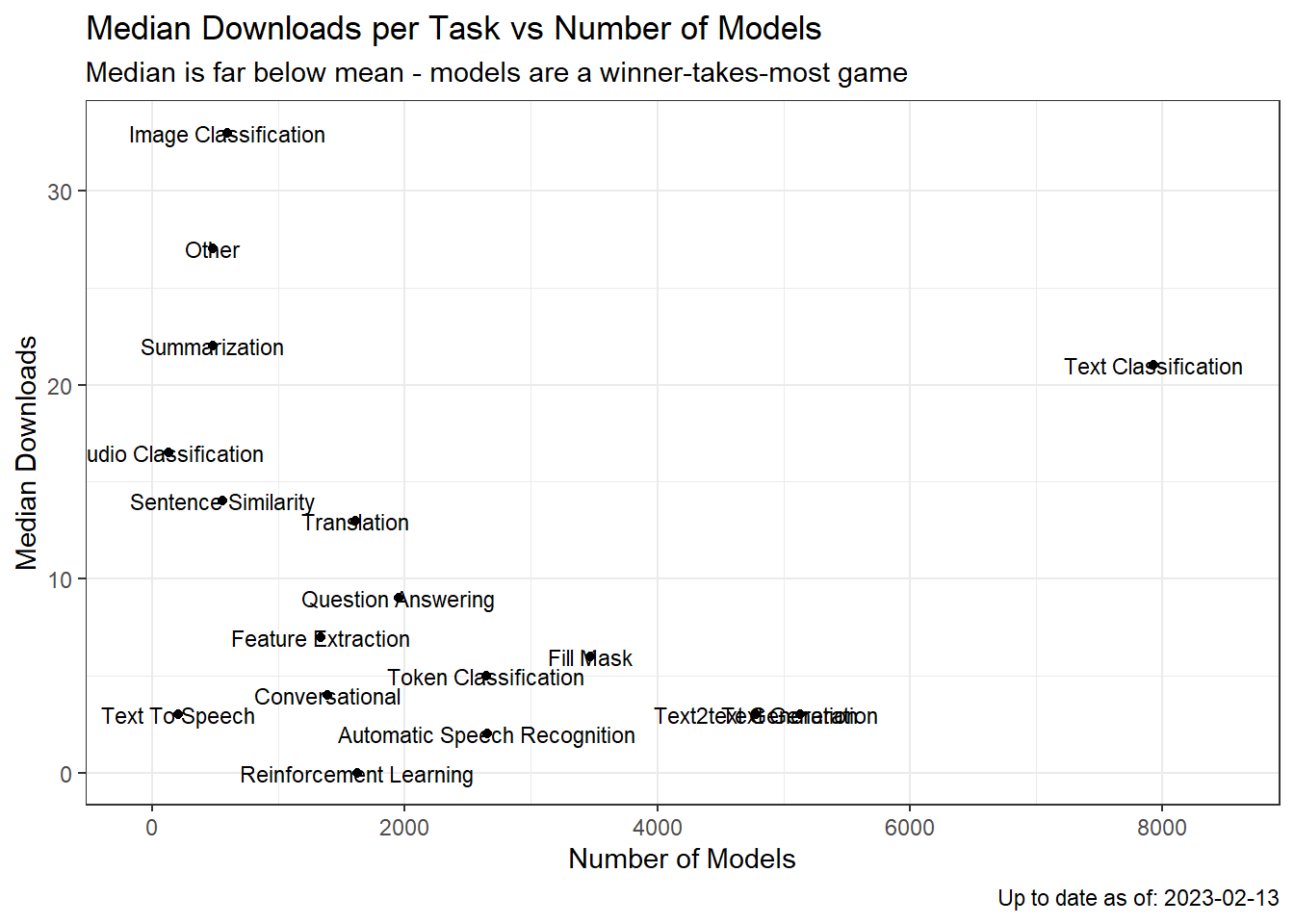
다운로드 횟수가 많은 hugginface 모형은 다음과 같다.
huggingfaceR 패키지 hf_load_dataset() 함수를 사용해서 emotion 감성 데이터셋을 가져와서 tidvyerse 작업흐름과 연계시킬 수 있다.
emo <- hf_load_dataset(
dataset = "emotion",
split = "train"
)
emo_model <- emo %>%
sample_n(100) %>%
transmute(
text,
emotion_id = label,
emotion_name = label_name,
distilBERT_sent = distilBERT(text)
) %>%
unnest_wider(distilBERT_sent)
glimpse(emo_model)