코드
import openai
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
openai.api_key = os.getenv('ENV_OPENAI_API_KEY')
LlamaIndex(GPT 인덱스)는 LLM을 외부 데이터와 연결하기 위한 통합 인터페이스를 제공하는 프로젝트다. 외부 데이터에는 당연히 데이터프레임도 포함된다.
펭귄 데이터를 판다스 데이터프레임으로 파이썬 환경으로 가져온 후에 LlamaIndex(GPT 인덱스)에 넣어 OpenAI GPT API 인터페이스를 통해 자연어로 다양한 데이터 분석을 수행할 수 있다.
챗GPT 시대 데이터 분석에 필요한 사항은 먼저 OpenAI API 연결을 위한 설정, 분석 데이터셋, 그리고 이를 연결시키는 LlamaIndex(GPT 인덱스)라고 할 수 있다.
import openai
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
openai.api_key = os.getenv('ENV_OPENAI_API_KEY')# !pip install palmerpenguins
import pandas as pd
from palmerpenguins import load_penguins
penguins_raw = load_penguins()
penguins_raw.head()| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | year | |
|---|---|---|---|---|---|---|---|---|
| 0 | Adelie | Torgersen | 39.1 | 18.7 | 181.0 | 3750.0 | male | 2007 |
| 1 | Adelie | Torgersen | 39.5 | 17.4 | 186.0 | 3800.0 | female | 2007 |
| 2 | Adelie | Torgersen | 40.3 | 18.0 | 195.0 | 3250.0 | female | 2007 |
| 3 | Adelie | Torgersen | NaN | NaN | NaN | NaN | NaN | 2007 |
| 4 | Adelie | Torgersen | 36.7 | 19.3 | 193.0 | 3450.0 | female | 2007 |
펭귄 데이터는 적지만 결측값이 존재한다. 실제 현업에서 데이터를 들여다보면 훨씬 더 많은 결측치가 존재하지만 학습용으로는 손색이 없다.
show_missing() 함수를 사용해서 간략히 전체적인 결측값 현황을 파악할 수 있다.
def show_missing(df):
"""Return a Pandas dataframe describing the contents of a source dataframe including missing values."""
variables = []
dtypes = []
count = []
unique = []
missing = []
pc_missing = []
for item in df.columns:
variables.append(item)
dtypes.append(df[item].dtype)
count.append(len(df[item]))
unique.append(len(df[item].unique()))
missing.append(df[item].isna().sum())
pc_missing.append(round((df[item].isna().sum() / len(df[item])) * 100, 2))
output = pd.DataFrame({
'variable': variables,
'dtype': dtypes,
'count': count,
'unique': unique,
'missing': missing,
'pc_missing': pc_missing
})
return output
# penguins.isna().sum()
show_missing(penguins_raw)| variable | dtype | count | unique | missing | pc_missing | |
|---|---|---|---|---|---|---|
| 0 | species | object | 344 | 3 | 0 | 0.00 |
| 1 | island | object | 344 | 3 | 0 | 0.00 |
| 2 | bill_length_mm | float64 | 344 | 165 | 2 | 0.58 |
| 3 | bill_depth_mm | float64 | 344 | 81 | 2 | 0.58 |
| 4 | flipper_length_mm | float64 | 344 | 56 | 2 | 0.58 |
| 5 | body_mass_g | float64 | 344 | 95 | 2 | 0.58 |
| 6 | sex | object | 344 | 3 | 11 | 3.20 |
| 7 | year | int64 | 344 | 3 | 0 | 0.00 |
llama-index 파이썬 패키지를 설치한 후에 GPTPandasIndex() 함수로 결측값이 담긴 펭귄 데이터프레임을 넣어 자연어 질의문을 던지게 되면 원하는 파이썬 작업결과를 얻을 수 있다.
# !pip install llama-index# !pip install llama-index
# penguins = penguins_raw.dropna()
import pandas as pd
from llama_index.indices.struct_store import GPTPandasIndex
penguins_raw_idx = GPTPandasIndex(df=penguins_raw)
raw_query_engine = penguins_raw_idx.as_query_engine(verbose=True)
response = raw_query_engine.query("""remove NaN values from the dataframe""")
# response = query_engine.query("""What is the pairwise correlation of the float64 datatype columns""")
print(response.response)> Pandas Instructions:
```
df.dropna()
```
> Pandas Output: species island bill_length_mm bill_depth_mm flipper_length_mm
0 Adelie Torgersen 39.1 18.7 181.0 \
1 Adelie Torgersen 39.5 17.4 186.0
2 Adelie Torgersen 40.3 18.0 195.0
4 Adelie Torgersen 36.7 19.3 193.0
5 Adelie Torgersen 39.3 20.6 190.0
.. ... ... ... ... ...
339 Chinstrap Dream 55.8 19.8 207.0
340 Chinstrap Dream 43.5 18.1 202.0
341 Chinstrap Dream 49.6 18.2 193.0
342 Chinstrap Dream 50.8 19.0 210.0
343 Chinstrap Dream 50.2 18.7 198.0
body_mass_g sex year
0 3750.0 male 2007
1 3800.0 female 2007
2 3250.0 female 2007
4 3450.0 female 2007
5 3650.0 male 2007
.. ... ... ...
339 4000.0 male 2009
340 3400.0 female 2009
341 3775.0 male 2009
342 4100.0 male 2009
343 3775.0 female 2009
[333 rows x 8 columns]
species island bill_length_mm bill_depth_mm flipper_length_mm
0 Adelie Torgersen 39.1 18.7 181.0 \
1 Adelie Torgersen 39.5 17.4 186.0
2 Adelie Torgersen 40.3 18.0 195.0
4 Adelie Torgersen 36.7 19.3 193.0
5 Adelie Torgersen 39.3 20.6 190.0
.. ... ... ... ... ...
339 Chinstrap Dream 55.8 19.8 207.0
340 Chinstrap Dream 43.5 18.1 202.0
341 Chinstrap Dream 49.6 18.2 193.0
342 Chinstrap Dream 50.8 19.0 210.0
343 Chinstrap Dream 50.2 18.7 198.0
body_mass_g sex year
0 3750.0 male 2007
1 3800.0 female 2007
2 3250.0 female 2007
4 3450.0 female 2007
5 3650.0 male 2007
.. ... ... ...
339 4000.0 male 2009
340 3400.0 female 2009
341 3775.0 male 2009
342 4100.0 male 2009
343 3775.0 female 2009
[333 rows x 8 columns]원본 데이터를 분석을 위해 데이터를 가져오게 되면 가장 먼저 데이터를 살펴보게 된다. 지시명령문을 다음과 같이 작성헤 되면 행과 열을 파악할 수 있게 된다.
Return how many rows and how many columns are in the dataset.\n
The response must be a key-value object as we show in the tags:\n
<{'rows':..., 'columns':...}>penguins = penguins_raw.dropna()
penguins_idx = GPTPandasIndex(df=penguins)
query_engine = penguins_idx.as_query_engine(verbose=True)
#response = query_engine.query("""데이터셋에 있는 행 수와 열 수를 반환합니다.\n
# 응답은 다음 태그에 표시된 대로 키-값 객체여야 합니다.\n
# <{'행':..., '열':...}>""")
response = query_engine.query("""Return how many rows and how many columns are in the dataset.\n
The response must be a key-value object as we show in the tags:\n
<{'rows':..., 'columns':...}>""")
print(response.response)> Pandas Instructions:
```
{'rows': df.shape[0], 'columns': df.shape[1]}
```
> Pandas Output: {'rows': 333, 'columns': 8}
{'rows': 333, 'columns': 8}몇차례 시행착오가 있었지만 숫자형 칼럼만 선택하여 상관관계를 파악한다.
response = query_engine.query("""list the float64 datatype columns and calculate the pairwise correlation of the float64 datatype columns""")
# response = query_engine.query("""What is the pairwise correlation of the float64 datatype columns""")
print(response.response)> Pandas Instructions:
```
df.select_dtypes(include=['float64']).corr(method='pearson')
```
> Pandas Output: bill_length_mm bill_depth_mm flipper_length_mm
bill_length_mm 1.000000 -0.228626 0.653096 \
bill_depth_mm -0.228626 1.000000 -0.577792
flipper_length_mm 0.653096 -0.577792 1.000000
body_mass_g 0.589451 -0.472016 0.872979
body_mass_g
bill_length_mm 0.589451
bill_depth_mm -0.472016
flipper_length_mm 0.872979
body_mass_g 1.000000
bill_length_mm bill_depth_mm flipper_length_mm
bill_length_mm 1.000000 -0.228626 0.653096 \
bill_depth_mm -0.228626 1.000000 -0.577792
flipper_length_mm 0.653096 -0.577792 1.000000
body_mass_g 0.589451 -0.472016 0.872979
body_mass_g
bill_length_mm 0.589451
bill_depth_mm -0.472016
flipper_length_mm 0.872979
body_mass_g 1.000000 실무에서 가장 많이 사용하는 그룹 집단별로 요약통계량을 구하는 질의문을 작성하여 시행한다.
response = query_engine.query("""list the float64 datatype columns and calcuate the average values by species""")
print(response.response)> Pandas Instructions:
```
df.groupby('species')[['bill_length_mm', 'bill_depth_mm', 'flipper_length_mm', 'body_mass_g']].mean().reset_index()
```
> Pandas Output: species bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
0 Adelie 38.823973 18.347260 190.102740 3706.164384
1 Chinstrap 48.833824 18.420588 195.823529 3733.088235
2 Gentoo 47.568067 14.996639 217.235294 5092.436975
species bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
0 Adelie 38.823973 18.347260 190.102740 3706.164384
1 Chinstrap 48.833824 18.420588 195.823529 3733.088235
2 Gentoo 47.568067 14.996639 217.235294 5092.436975response = query_engine.query("""visualize two columns; body_mass_g and flipper_length_mm with scatterplot""")
print(response.response)> Pandas Instructions:
```
df.plot.scatter(x='body_mass_g', y='flipper_length_mm')
```
> Pandas Output: Axes(0.125,0.11;0.775x0.77)
Axes(0.125,0.11;0.775x0.77)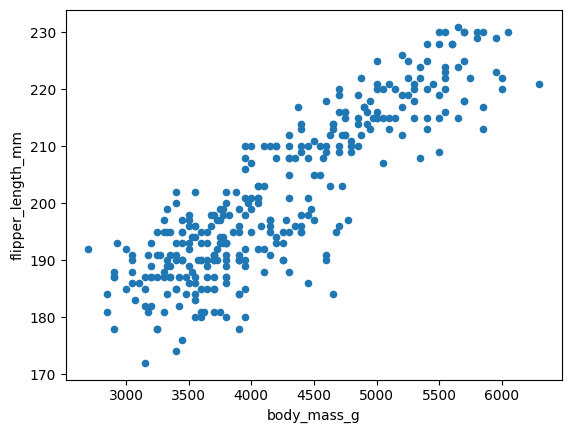
# import seaborn as sns
response = query_engine.query("""draw distribution plot for body_mass_g with transparency by species with legend""")
print(response.response)> Pandas Instructions:
```
df.groupby('species')['body_mass_g'].plot.kde(legend=True, alpha=0.5)
```
> Pandas Output: species
Adelie Axes(0.125,0.11;0.775x0.77)
Chinstrap Axes(0.125,0.11;0.775x0.77)
Gentoo Axes(0.125,0.11;0.775x0.77)
Name: body_mass_g, dtype: object
species
Adelie Axes(0.125,0.11;0.775x0.77)
Chinstrap Axes(0.125,0.11;0.775x0.77)
Gentoo Axes(0.125,0.11;0.775x0.77)
Name: body_mass_g, dtype: object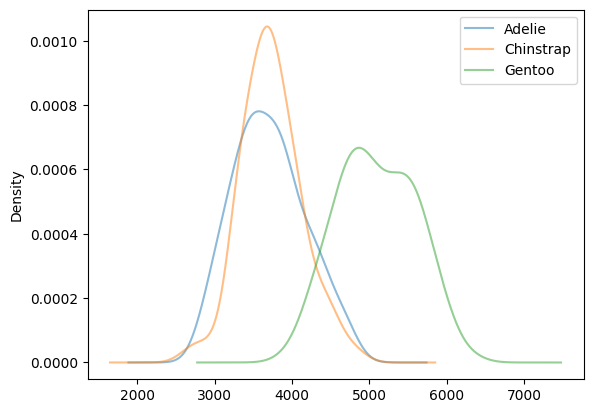
# !pip install -U scikit-learn
from sklearn.linear_model import LogisticRegression
response = query_engine.query("""build a `sex` classification model using logistic regression step-by-step""")
print(response.response)> Pandas Instructions:
```
eval('LogisticRegression().fit(df[["bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g"]], df["sex"]).predict(df[["bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g"]])')
```
> Pandas Output: There was an error running the output as Python code. Error message: name 'LogisticRegression' is not defined
There was an error running the output as Python code. Error message: name 'LogisticRegression' is not defined