import tiktokendef num_tokens_from_string(string: str) ->int:"""Returns the number of tokens in a text string.""" encoding = tiktoken.get_encoding("cl100k_base") num_tokens =len(encoding.encode(string))return num_tokens# num_tokens_from_string("Hello World!",)num_tokens=num_tokens_from_string(contents)num_tokens
# 출처: https://github.com/OpsConfig/OpenAI_Lab/blob/3a8c55160a6790fc790ef1c2c797d83c716eee94/Context-based-search-Version2.ipynb# Based on https://openai.com/api/pricing/ on 01/29/2023# If you were using this for approximating pricing with Azure OpenAI adjust the values below with: https://azure.microsoft.com/pricing/details/cognitive-services/openai-service/#MODEL USAGE#Ada v1 $0.0040 / 1K tokens#Babbage v1 $0.0050 / 1K tokens#Curie v1 $0.0200 / 1K tokens#Davinci v1 $0.2000 / 1K tokens#MODEL USAGE#Ada v2 $0.0004 / 1K tokens#This Ada model, text-embedding-ada-002, is a better and lower cost replacement for our older embedding models. n_tokens_sum = num_tokensada_v1_embeddings_cost = (n_tokens_sum/1000) *.0040babbage_v1_embeddings_cost = (n_tokens_sum/1000) *.0050curie_v1_embeddings_cost = (n_tokens_sum/1000) *.02davinci_v1_embeddings_cost = (n_tokens_sum/1000) *.2ada_v2_embeddings_cost = (n_tokens_sum/1000) *.0004print("Number of tokens: "+str(n_tokens_sum) +"\n")print("MODEL VERSION COST")print("-----------------------------------")print("Ada"+"\t\t"+"v1"+"\t$"+'%.8s'%str(ada_v1_embeddings_cost))print("Babbage"+"\t\t"+"v1"+"\t$"+'%.8s'%str(babbage_v1_embeddings_cost))print("Curie"+"\t\t"+"v1"+"\t$"+'%.8s'%str(curie_v1_embeddings_cost))print("Davinci"+"\t\t"+"v1"+"\t$"+'%.8s'%str(davinci_v1_embeddings_cost))print("Ada"+"\t\t"+"v2"+"\t$"+'%.8s'%str(ada_v2_embeddings_cost))
Number of tokens: 7852
MODEL VERSION COST
-----------------------------------
Ada v1 $0.031408
Babbage v1 $0.03926
Curie v1 $0.15704
Davinci v1 $1.570400
Ada v2 $0.003140
import pandas as pdsentences = contents.split(". ")df = pd.DataFrame(sentences, columns=['text'])print(df.head())
text
0 Well, thank you very much, Dr
1 Ahn
2 This is a real pleasure to be able to speak ac...
3 I wish I was there in person, but I did get th...
4 So thank you so much
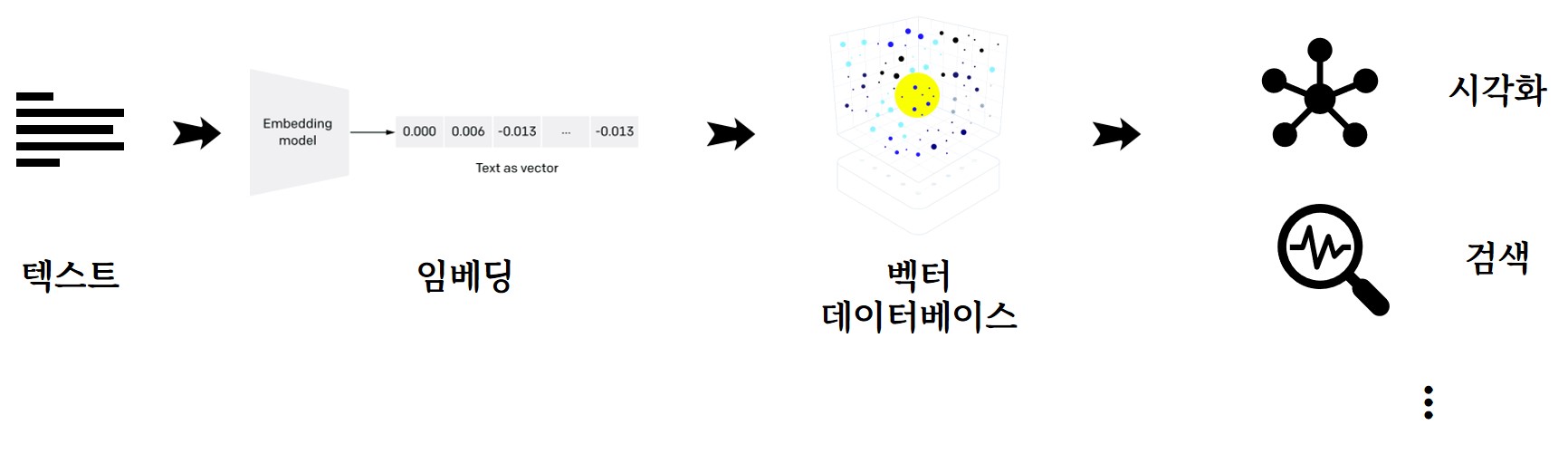
앞서 임베딩이 마무리되었으며 이를 벡터 데이터베이스에 밀어넣고 다양한 후속작업을 수행할 수 있도록 준비한다. 관계형 데이터베이스가 그 수가 많은 만큼 벡터 데이터베이스는 종류가 많다. 선두 주자로 평가받는 파인콘(Pinecone) 회원가입하면 API 형태로 벡터 데이터베이스를사용할 수 있다.
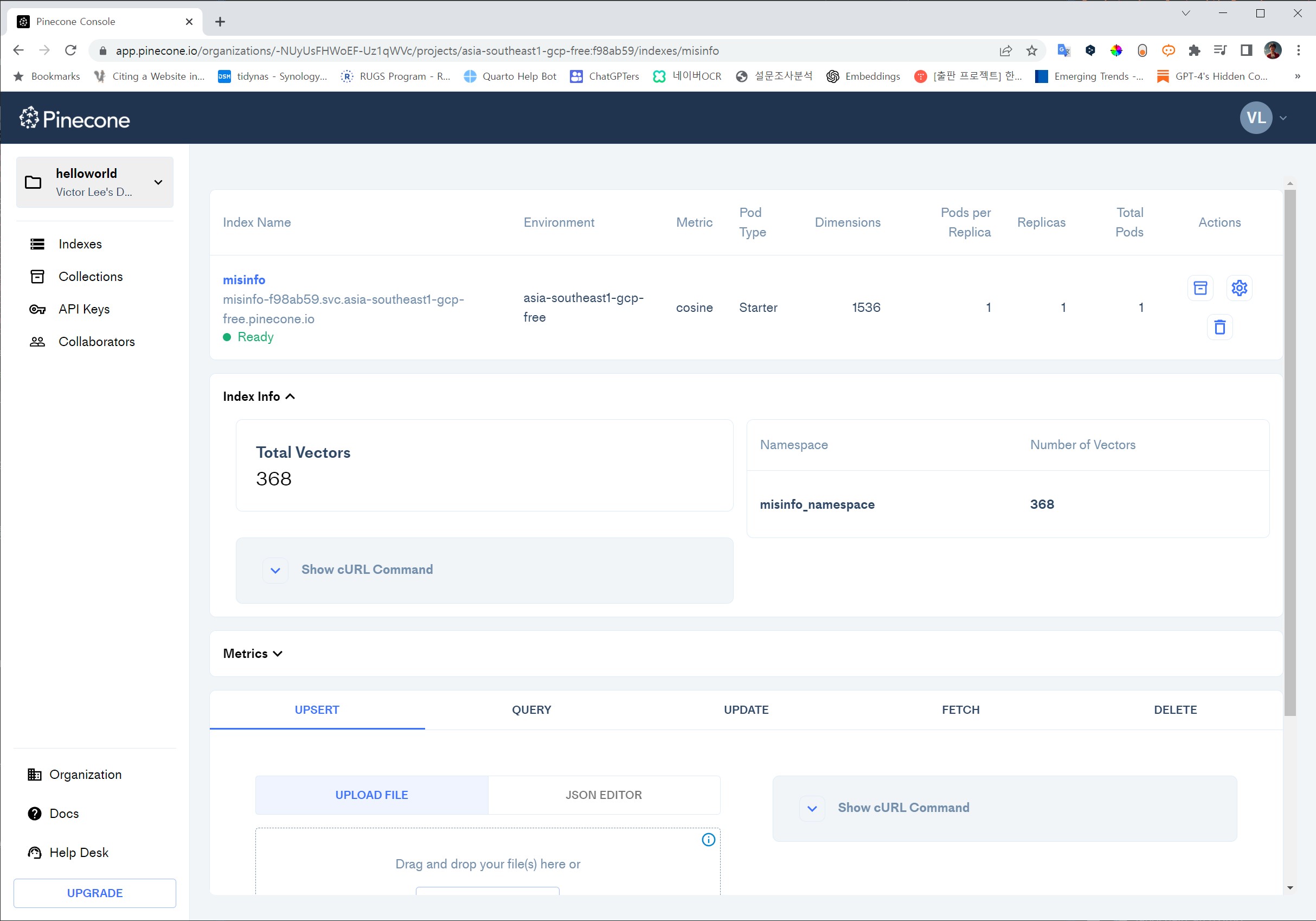
4.1 DB 생성
코드
# Pick a name for the new indexindex_name ='misinfo'# Check whether the index with the same name already exists - if so, delete itif index_name in pinecone.list_indexes(): pinecone.delete_index(index_name)# Creates new indexpinecone.create_index(name=index_name, dimension=len(df['embedding'][0]))index = pinecone.Index(index_name=index_name)# Confirm our index was createdpinecone.list_indexes()
186 And we know that, you know, our surgeon general and other major leaders around the world have recognized the ways in which misinformation can affect our health, and they can affect the health of democracies
130 And bullshit is a part of the misinformation story
16 We've studied misinformation during the pandemic and during elections and all sorts of other topics
Name: text, dtype: object