1 문서 요약
GPT 모델은 텍스트에서 흔히 볼 수 있는 문자 시퀀스인 토큰을 사용하여 텍스트를 처리한다. GPT 모델은 이러한 토큰 간의 통계적 관계를 이해하고 토큰 시퀀스에서 다음 토큰을 생성하는 데 탁월하다.
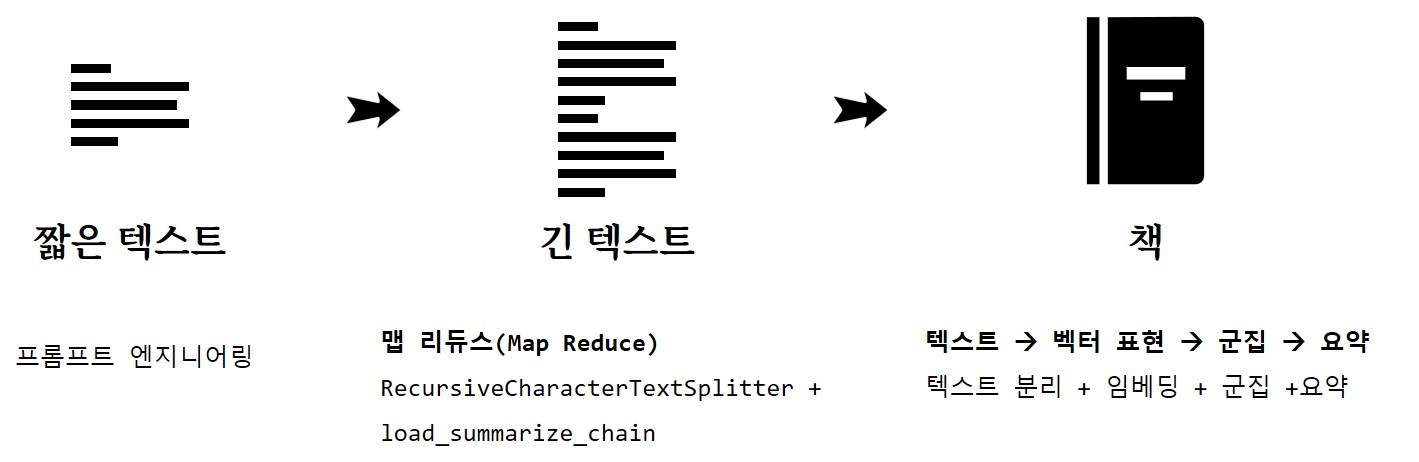
요약은 많은 LLM 작업의 기본 구성 요소로 많은 양의 텍스트를 간결한 요점으로 압축해야 하는 사용 사례가 많다.따라서, 요약하려는 텍스트의 길이에 따라 다양한 요약 방법을 선택해야한다.
문서 길이에 따라 요약하는 방식도 달라진다. 짧은 텍스트의 경우 프롬프트 공학을 사용해서 요약을 짧은 코드로 수행할 수 있지만 텍스트의 길이가 길어지고 특히, 책과 같이 수백 페이지에 이르게 되는 경우 다른 전략이 필요하다.
2 텍스트 길이
서울 R 미트업 2023년 5월 “챗GPT와 오정보(Misinformation)” 행사에서 제빈 웨스트 교수가 발표한 헛소문 바로잡기(Cutting Through Bullshit: Navigating Misinformation and Disinformation in the GenChatGPT Era) 텍스트를 추출하여 요약해보자. STT를 이용하여 음성에서 텍스트를 추출하는 방법에 대해서는 음성인식(Whisper)을 참고한다.
2.1 .srt → .txt
자막파일(.srt)에서 시간 정보를 제거하고 텍스트만 전환하는 작업을 다음 코드를 사용하여 진행한다.
2.2 R 코드
텍스트 길이와 별개로 단어갯수(word)를 파악하는 것이 전체적인 API 비용 및 후속 텍스트 분석 방향을 잡을 때 중요하다. 이를 위해서 stringr 패키지 str_sub() 함수와 정규표현식(\\w+)을 결합하여 사용하거나 텍스트 마이닝 특화된 qdap 패키지 wc() 함수를 사용해서 계산한다.
코드
library(tidyverse)
misinfo_txt <- read_lines("data/LibriSpeech/misinfo_chatGPT.txt")
misinfo_wc <- str_count(misinfo_txt, '\\w+')
glue::glue("텍스트 일부: {str_sub(misinfo_txt, 1, 100)}
단어갯수: {misinfo_wc}
단어갯수(qdap): {qdap::wc(misinfo_txt)}")
#> 텍스트 일부: Well, thank you very much, Dr. Ahn. This is a real pleasure to be able to speak across the ocean. I
#> 단어갯수: 6900
#> 단어갯수(qdap): 6615
2.3 Tokenizer
챗GPT LLM은 토큰을 기본 단위로 사용하고 과금단위이기도 하기 때문에 OpenAI 에서 제공하는 Tokenizer에서 복사하여 붙여넣게 되면 발표음성을 텍스트 파일에 저장시킨 사항을 바로 확인할 수 있다. 다른 방식은 langchain get_num_tokens() 메쏘드를 사용해서 API를 통해 확인하는 방식이다.
웹 UI
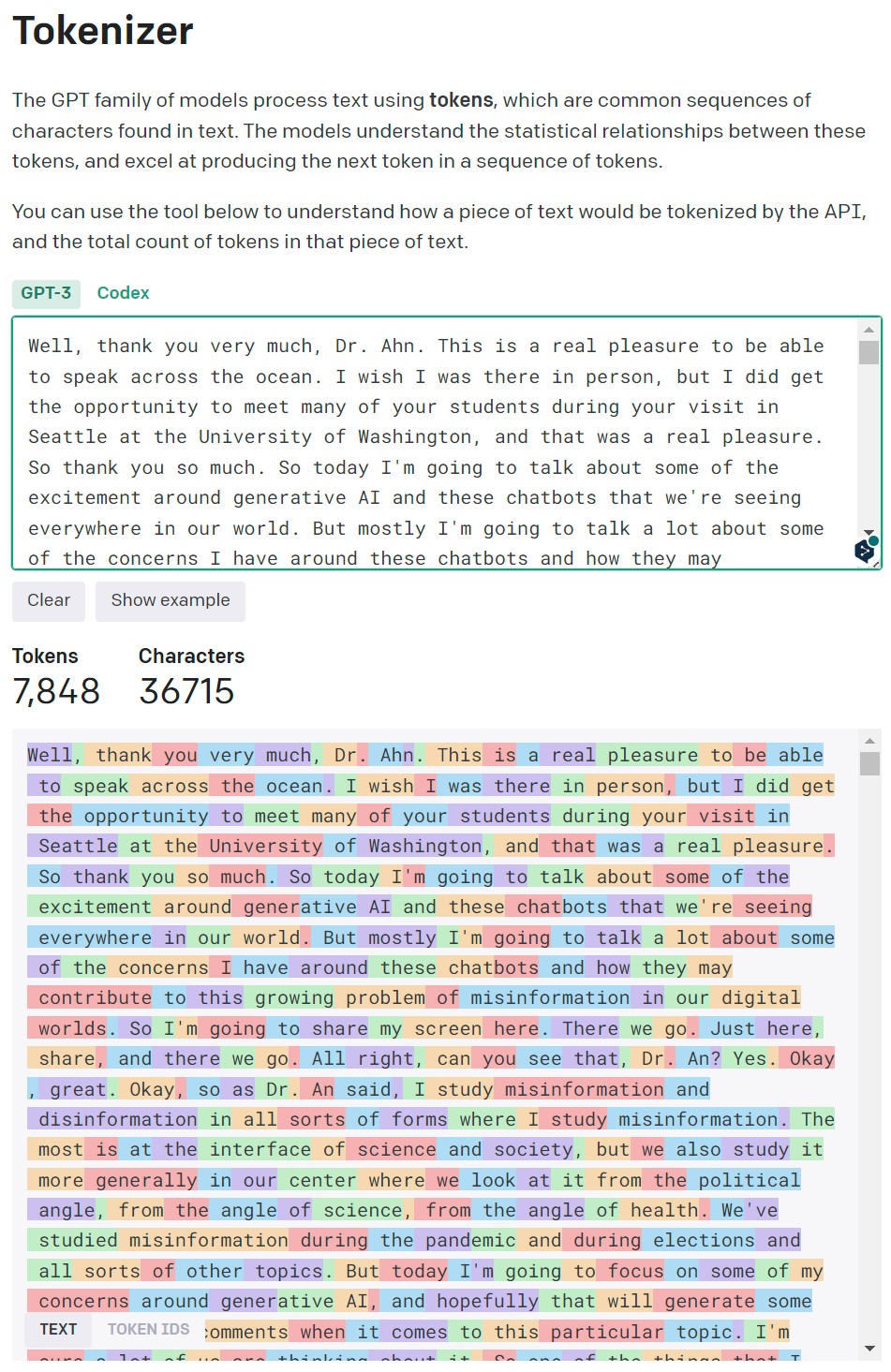
API 프로그래밍
코드
from langchain import OpenAI
llm = OpenAI(temperature=0, openai_api_key=os.getenv('ENV_OPENAI_API_KEY'))
prompt_lvl_01 = """
Please provide a summary of the following text.
Please provide your output in a manner that a 5 year old would understand
TEXT:
Well, thank you very much, Dr. Ahn. This is a real pleasure to be able to speak across the ocean.\
I wish I was there in person, but I did get the opportunity to meet many of your students during your visit in Seattle at the University of Washington,\
and that was a real pleasure. So thank you so much.\
So today I'm going to talk about some of the excitement around generative AI and these chatbots that we're seeing everywhere in our world.\
But mostly I'm going to talk a lot about some of the concerns I have around these chatbots and how they may contribute to this growing problem of misinformation in our digital worlds.
"""
num_tokens_lvl_01 = llm.get_num_tokens(prompt_lvl_01)
print (f"Level 1 Prompt has {num_tokens_lvl_01} tokens")Level 1 Prompt has 172 tokens3 요약
Greg Kamradt은 LLM 문서요약관련하여 5가지 전략을 제시하고 있다.
- 몇 문장 요약하기 - 기본 프롬프트
- 몇 단락 요약 - 프롬프트 템플릿
- 몇 페이지 요약 - 맵 리듀스(Map Reduce)
- 책 전체 요약하기 - Best Representation Vectors
- 알 수 없는 양의 텍스트 요약 - 에이전트(Agent)
5가지 전략 중 강의내용을 요약할 수 있는 두가지 사례를 중심으로 살펴보자.
3.1 몇 문장 요약
요약형태도 지정하여 누구나 이해하기 쉬운 형태로 몇 문장 텍스트를 요약하도록 프롬프트를 작성하여 국문, 영문 작업을 수행한다.
국문요약
코드
from langchain import OpenAI
llm = OpenAI(temperature=0, openai_api_key=os.getenv('ENV_OPENAI_API_KEY'))
prompt_lvl_01_ko = """
다음 텍스트를 요약해주세요.
초등학생이 이해할 수 있게 요약을 쉽게 해주세요.
TEXT:
Well, thank you very much, Dr. Ahn. This is a real pleasure to be able to speak across the ocean.\
I wish I was there in person, but I did get the opportunity to meet many of your students during your visit in Seattle at the University of Washington,\
and that was a real pleasure. So thank you so much.\
So today I'm going to talk about some of the excitement around generative AI and these chatbots that we're seeing everywhere in our world.\
But mostly I'm going to talk a lot about some of the concerns I have around these chatbots and how they may contribute to this growing problem of misinformation in our digital worlds.
"""
output_lvl_01_ko = llm(prompt_lvl_01_ko)
print (output_lvl_01_ko)
Dr. Ahn과 함께 오션에서 만난 여러 학생들과의 만남을 기쁘게 생각하며, 인공지능과 챗봇의 기쁨과 관련해 미디어 정보의 문제를 이야기하고 있다.영문요약
코드
prompt_lvl_01 = """
Please provide a summary of the following text.
Please provide your output in a manner that a 5 year old would understand
TEXT:
Well, thank you very much, Dr. Ahn. This is a real pleasure to be able to speak across the ocean.\
I wish I was there in person, but I did get the opportunity to meet many of your students during your visit in Seattle at the University of Washington,\
and that was a real pleasure. So thank you so much.\
So today I'm going to talk about some of the excitement around generative AI and these chatbots that we're seeing everywhere in our world.\
But mostly I'm going to talk a lot about some of the concerns I have around these chatbots and how they may contribute to this growing problem of misinformation in our digital worlds.
"""
output_lvl_01 = llm(prompt_lvl_01)
print (output_lvl_01)
Dr. Ahn and someone from Seattle had a nice chat across the ocean. They talked about how AI and chatbots are exciting, but also how they can cause problems with misinformation.3.2 전체 요약
요약 대상이 되는 텍스트와 요약 프롬프트를 한번에 넣어 작업하는 대신 텍스트 토큰 크기를 산정한 후에 적절한 크기로 나눈 다음 각각 텍스트 조각에 대해 요약작업을 수행하고 나서 이를 다시 요약하는 맵리듀스(Map Reduce) 방식으로 요약 작업을 마무리한다.
3.2.1 토큰 크기
발표 텍스트 토큰 크기를 계산하여 적절한 토큰 분리 크기를 산정한다.
코드
import openai
import os
from langchain import OpenAI
llm = OpenAI(temperature=0, openai_api_key=os.getenv('ENV_OPENAI_API_KEY'))
from langchain import OpenAI
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import RecursiveCharacterTextSplitter
misinfo_lecture = '../data/LibriSpeech/misinfo_chatGPT.txt'
with open(misinfo_lecture, 'r') as file:
misinfo = file.read()
llm.get_num_tokens(misinfo) 78483.2.2 요약결과
load_summarize_chain() 으로 전체 발표 텍스트를 요약한다.
코드
summary_chain = load_summarize_chain(llm=llm, chain_type='map_reduce',
verbose=True # Set verbose=True if you want to see the prompts being used
)
output = summary_chain.run(docs)
output
> Entering new MapReduceDocumentsChain chain...
> Entering new LLMChain chain...
Prompt after formatting:
Write a concise summary of the following:
"Well, thank you very much, Dr. Ahn. This is a real pleasure to be able to speak across the ocean. I wish I was there in person, but I did get the opportunity to meet many of your students during your visit in Seattle at the University of Washington, and that was a real pleasure. So thank you so much. So today I'm going to talk about some of the excitement around generative AI and these chatbots that we're seeing everywhere in our world. But mostly I'm going to talk a lot about some of the concerns I have around these chatbots and how they may contribute to this growing problem of misinformation in our digital worlds. So I'm going to share my screen here. There we go. Just here, share, and there we go. All right, can you see that, Dr. An? Yes. Okay, great. Okay, so as Dr. An said, I study misinformation and disinformation in all sorts of forms where I study misinformation. The most is at the interface of science and society, but we also study it more generally in our center where we look at it from the political angle, from the angle of science, from the angle of health. We've studied misinformation during the pandemic and during elections and all sorts of other topics. But today I'm going to focus on some of my concerns around generative AI, and hopefully that will generate some questions and comments when it comes to this particular topic. I'm sure a lot of us are thinking about it. So one of the things that I tend to ask myself when new technologies come onto the world scene is whether we're better or worse off. I recently wrote an op-ed, an opinion piece for the Seattle Times, which is our paper here in Seattle in the United States. And I talked about some of the concerns I had. And so some of the things I'm going to talk about in this talk come from that op-ed, but I'm going to talk about a lot of other things I didn't have room to talk about in that particular op-ed. But I really want us as a group to think a lot about this. Are we better or worse off with this new chatbot ability? And of course it's a mixed bag. There are things that might be better, and there are things that are going to be worse. I'm going to kind of focus on the more pessimistic version of this. About a week ago, there was a lot of attention around a new music song that was posted on several music services that sounded like a mix between the famous musician Drake and the weekend. These are two musical artists that are known worldwide for their music. And there was a song that was created that was quite catchy. And believe it or not, it was kind of good, I have to admit. And it was probably viewed by millions and millions of people. I don't know the exact stats on that. I should look that up. But the point is this song was created with some of this new generative AI technology. And this is an example where there might be some positive elements of this technology that allows for this mixing and this creation. It created a song that caught enough people's attention that it caught so much attention. It actually had to be taken down because of issues likely around copyright. And there's all sorts of fallout from this. And there's lots of discussions in the legal world that are continuing. And it's only been about a week since this song was released. But this is an example of the excitement that surrounds this technology. And for good reason, if it can create a song that's a good mix of Drake and the weekend and it sounds reasonably good, that's some evidence at least of the power of this new technology. And it's not like this is brand new technology. There is this kind of technology from the natural language processing world and machine learning more generally has been around. But there's been some advancements recently that make the generative aspect quite exciting, but also a little scary. So I'm going to talk about today some of the the cautions that I have. There's a lot more cautions. But these are the things I'm going to focus on. And it's a lot to focus on in about 25 minutes. So I'm going to hit these briefly. And then if there are questions, we can always go back to some of these topics in more detail. But I'm going to go through talking about how at least from my perspective, as someone who studies misinformation, and as someone who studies misinformation specifically in science, these are some of my big concerns. One of them is that these really are bullshatters at scale. They get a lot right, but they also get some things wrong. Concerns around how this might affect democratic discourse online and offline. Concerns about content credit for all those content creators out there, the musicians like Drake and the weekend, and the writers and the journalists and the researchers and the authors and the poets, etc. What happens to their content when it gets pushed down after these generative AI, these chatbots and these large language models train on this content and then provide some reason new content on top of it. Who owns the content? How's that going to work as we move forward? I'll talk a little bit about some of the job elimination issues, both course in science, but in other areas, it'll be that, well, some of these are focused outside of the issue of science. And then of course, I'm going to talk about some of the issues of pseudoscience proliferation, the overconfidence of AI and the need for some of these qualifiers of confidence, the issues around reverse engineering, the generative cost, the actual cost, both monetarily, environmentally, but also the costs in other forms and creativity and other things. And then I'll talk, I'll end with just really emphasizing this issue about garbage in garbage out. Okay, so we now live in this world where it seems we've got almost sentient beings. I know there's lots of philosophical debates whether they're sentient. I don't think they are. And we certainly haven't reached AGI levels. And there's all sorts of great, you know, critiques of this particular technology. But one thing that at least I think we're all pretty sure of, it's kind of here to stay in some form or another. Even in my world in education as a professor who runs a research lab and also as a professor who teaches students, college students, I'm seeing the technology everywhere. And when I was teaching my class last quarter, I decided to just embrace the technology and allow the students to use it in any form that they see as long as they let me know that they were using it. That's my only criteria because I want to learn how this technology can be used by students and by teachers like myself and professors like myself. But I also want to figure out where it goes wrong. And so I learned a lot from my students and I will continue to have that kind of policy. But maybe that'll change at some point. I know that some instructors don't allow it. I know that some scientific publishers are not allowing co-authorship or the use of AI in any form. Even countries like Italy have outlawed some forms of this technology. And so there's going to be some that are going to eliminate it, some that are going to embrace it. And the way I look at it is that it may just force me to write different kinds of questions and do different kinds of assessment. But it might also be a tool that could help students learn to write when they're stuck and learn how to correct as long as they're willing to do some editing and self-correct and correction of the content that comes from these different bots. And so the technology really is here to stay. And one thing I should say is what's interesting is that we have a technology that really seems to have passed the Turing test. And one thing that's a bit a little surprising to me is that we haven't had a big celebration about this. Even though I'm a bit of a critic of this technology and I focus a lot of my attention on some of the concerning areas of Generative AI, since I studied misinformation, disinformation. I should say though, on the other hand, we should be thinking about some of the things that have occurred. And for those not familiar with the Turing test, it's this pretty simple idea that the Turing test will have passed when an individual can't tell the difference. But when content, at least in this case written content created by a human and one by a computer. And if that's the case, and I do think in many respects, we probably have passed this Turing test. And there's been no celebrations. So I guess, okay, for those that are optimistic about this technology and more positive about this technology, this would be something to celebrate. Absolutely. No doubt. And in terms of education, as I mentioned before, this is really transforming education, but it's transforming all sorts of other industries in ways that have captured the world's attention. I mean, this technology has been adopted now faster than pretty much any other technology has been adopted with hundreds, like 100 million users within a very short amount of time. And of course, that's only growing and billions and billions of dollars being invested into this technology from big corporations to venture capitalists. There is a lot going into this technology. And again, there's good reason for that. And a lot of times my students will say, well, it's just like a calculator. Why would you ever want to take it away? And I'm not taking it. I'm lo and use it. But I will say, it's a little different than a calculator, because this is a technology that gets this things wrong at minimum, probably 10% of the time. I mean, these things are starting to still get sorted out in the research space. We're working on some of these things to figure out, you know, what is the baseline error? Well, it turns out it's pretty high. And in some cases, the impact can be quite high. So if you're talking about the medical field or you're talking about fields that really have an impact on an individual's lives, that 10% or 20% or 5% or whatever, those errors can"
CONCISE SUMMARY:
Prompt after formatting:
Write a concise summary of the following:
"gets this things wrong at minimum, probably 10% of the time. I mean, these things are starting to still get sorted out in the research space. We're working on some of these things to figure out, you know, what is the baseline error? Well, it turns out it's pretty high. And in some cases, the impact can be quite high. So if you're talking about the medical field or you're talking about fields that really have an impact on an individual's lives, that 10% or 20% or 5% or whatever, those errors can be highly problematic. If you're just creating a poem, then fine. It doesn't really matter. But this analogy to the calculator goes a little, it's there's reason to think that's a somewhat reasonable analogy, but it is different. I wouldn't use a calculator that got the answers wrong 10% of the time. That would be, I would probably be looking for other technologies. Or if I was using that calculator, it would make it for a lot harder work. And that's what we have to recognize. It's yes, we have this technology that can do a lot of this new amazing things to make some of our jobs easier. But it's going to take a lot of hard work on the editorial side to make sure that we're paying attention to some of those errors. And there's all sorts of application. This was an article just recently written by Wired sort of examining the ways in which the medical field is starting to think about the adoption of this. In fact, some medical researchers have gone so far as to say that all doctors will be using this technology at some point. And maybe that's true. And there are reasons to think that's a possibility with its ability to mine the scientific literature, to integrate all sorts of different symptoms, and could be that assistant in the doctor's room. However, there are reasons to also be worried about these technologies and in places like the medical field. It might help the doctors as this article talks about, but it also might not benefit so greatly many of those patients, especially because we have many, many examples of the ways in which these machines get things wrong and have biases built in because the data that it's trained on has some of these biases. And at this point, a lot of these technologies are essentially just patching and putting band aids on these problems that exist. And part of it's just because these things are very difficult to reverse engineer, which I'll talk about a little bit later. Now, there's plenty of other reasons to be excited to actually one of my colleagues who I just saw at a conference last week, Daniel Katz and his colleague Michael Bomerito showed how this technology took the bar exam. This is the main legal, the exam in the United States for allowing you to become a lawyer or sort of allowing you to sort of move forward as a certified lawyer. And they were able to show that chat GPT did already darn well in past the bar exam. And there's examples of the MCAT and, you know, some of these other standardized tests that are that have been tested with this technology. In fact, in many ways, these have almost become a baseline test when comparing different large language models. And so it is pretty amazing. So again, amazed in many ways, but I'm going to talk the rest of the time about some of the concerns that I have. And by the way, as was mentioned, I have this book where I talk about bullshit. And bullshit is a part of the misinformation story. And as Dr. An had mentioned, it's also been translated in Korean, which has been super fun to see it pulled or written in these other languages. And it helps me try to figure out what's being said here. But in that book, if you read it, one of the more important laws and principles that we talk about is something called "Randalini's Bullshit, a Symmetry Principle." And if you go to Wikipedia, at least the English version, I actually should check the Korean version, see if it's there. But the English version of the Wikipedia has this principle in the Wikipedia. And this law is pretty simple. It basically says that the amount of energy needed to refute bullshit is an order of magnitude bigger than needed to produce it. So the amount of energy needed to refute it to clean it up, to fix the problem, is an order of magnitude much harder to produce it. So here's the law. So my colleague Carl Bergstrom decided to ask the large language model that Metacreat a while ago called Galactica. And this has been taken down since then, but this was the science version, essentially, of one of these large language models. And he decided to ask Galactica, "Tell me about Randalini's Bullshit, a Symmetry Principle. And you know what it came up with?" And this is the real answer. Here's what it came up. Randalini's law is a theory in economics proposed by G. Anani Brannalini, a professor at the University of Pateau, which dates the smaller the economic unit, the greater its efficiency. Almost nothing here is correct. It's basically bullshitting the bullshit principle. So to me, this encapsulates one of the biggest problems with this technology. It bullshits, and it can do this at scale. And this could be put in the wrong hands. And this can also just add more noise to an information environment that has plenty of noise. We needed to clean up that polluted information environment, not add noise. And that's what a lot of these chatbots will do, definitely, because they make, they put a lot of accurate things out there, but they also put a lot of false things. And this is the best encapsulation that I've seen so far, which is actually bullshitting the bullshit principle. So that's a problem. So as I mentioned in this op-ed, I talk about some of these things. And one of the things I talk about as well is that not only do these things, can these bullshit at scale, they also can get in the way of democratic discourse. And many years ago, back in 2018, there was a lot of attention around Facebook's role in pushing misinformation. Excuse me. And they revealed at the time when Mark Zuckerberg was being questioned by Congress about all the fake accounts. And they admitted they had disabled 1.3 billion fake accounts. Now, they certainly haven't solved that problem, just like no social media platform has solved that. In fact, when Elon Musk was taking over Twitter, that was one of the big issues at hand, that there was all sorts of concerns if there was lots and lots of bots on Twitter. Now, that's still a problem. I can guarantee you, you know, my group has done a little bit of work working in detecting and looking at the effects of bots. But my colleagues in my research area have done a lot of work on that space, and it's very, very hard to do. But one thing is that, you know, we do know is that there are a lot of bots out there and a lot of fake accounts. Now, imagine those fake accounts with the ability that these chat bots now have to look even more human technology that's basically, well, has passed the Turing test. That to me is problematic because of these different reasons. So you have these large number of fake accounts. Now imagine these fake accounts being scaled to conversations with our public officials. Now, democracies depend on an engagement with the public, with their officials that they voted in. Well, that becomes a problem like it was back in 2017, when there was discussions, at least in the United States around something called net neutrality. And net neutrality was a policy that was being debated in governmental circles, and they wanted to know what the public was saying. But when you went to what the public was saying, they had complete the, there were comments that had completely flooded the conversation on one side of the issue, and it turns out that they were essentially fake accounts. They were bots. And again, now imagine doing that with the sophistication that these new chat bots have before you could, there was a, you could start, you could detect a bot much easier. Now it's become even harder. And if our democratic systems are flooded with these kinds of things, this is, this is problematic. So this issue, in its potential impact on democratic discourse, and its ability to bullshit at scale is of major concern to me. So I spent a lot of my time, like my colleagues in our center, in sort of the darker core of the internet, studying the ways in which misinformation and disinformation spreads online. And one thing that we are, of course, very concerned about now are the ways in which these technologies can really further inflame or further fan the flames of discourse in groups, if these get in the wrong hands. And they certainly will. It's almost certain that bad actors are finding ways to use this technology for their own ends. And we know that, you know, our surgeon general and other major leaders around the world have recognized the ways in which misinformation can affect our health, and they can affect the health of democracies. So it's not just that, oh, well, it's annoying, there's a lot of false information online. It just makes it hard to find, you know, good information. It's not just that it actually affects people's health. And we're recognizing that. And at least, well, we've recognized it. And now we've got another problem ahead of us, which is the ability of these technologies to create deep fake images, video, audio, text. That's the challenge that we have ahead of us. So as Dr. On mentioned, we have a center at the University of Washington in Seattle in the United States where we study this, and this is one of the issues that we study and we study these things on social media platforms. And we look at the way that individuals and organizations get amplified. But we're also going to start looking at the ways that these bots and synthetically created content also get amplified. So we do this through all sorts of different channels, research is our main thing, but we also do it through policy and education and community engagement. And one of"
CONCISE SUMMARY:
Prompt after formatting:
Write a concise summary of the following:
"in the United States where we study this, and this is one of the issues that we study and we study these things on social media platforms. And we look at the way that individuals and organizations get amplified. But we're also going to start looking at the ways that these bots and synthetically created content also get amplified. So we do this through all sorts of different channels, research is our main thing, but we also do it through policy and education and community engagement. And one of the things that my colleague Carl Wurxman, I created several years ago to bring public attention to synthetic media to deep fakes, was to create a game that we called which faces real calm. And it was a simple game. We just asked the users which image is real. One of them is a real image of a real person on this earth. And another one was synthetically created with computers. And you can go through that, you know, thousands and thousands and thousands of images and we play this game and then you get told whether it's real or not. And it turns out it's pretty hard. I mean, you know, there's some that are kind of obvious, but they're hard like this one right here, which one's real. Look at it for a second. Well, the one that's real is the one with the blue shirt, at least on my right. And if you said the one on the red shirt, totally understand it's really hard to tell the difference. And the reason why we created this game was just to bring public attention because the time in a technology's birth that's I think most scary when it comes to its potential impact is when the public is not aware of the things that it can do. So we created this game and we've had millions and millions of plays of this game. And we've now seen actually this technology, you know, get used and you know, of course, good ways, but a lot of bad ways too. For example, we've seen this technology be used to create fake journalists. This is an example and you can read more about it, but this has happened many times where journalists, or so-called journalists, you know, profiles created and then there's these images and people that study deep fake imagery can actually look at these images and start to see what some of look for some of these telltale signs on what's real or not. So these, this technology's been been already used. And we talked about this when this game was created, the ways in which it's been used. And we've already seen it, of course, many ways. So now we're asking how are the ways in which this new generative technology could be used. But it's very similar. It's based on similar kinds of concepts and data training, etc, etc. But we're now asking the same things. And of course, we've seen this now just recently with this kind of technology being used in videos and even in ways that are more sophisticated than just these sort of portrait pictures. So this was an image. It's a fake image and it's been reported all over BBC and lots of other places of Donald Trump supposedly being arrested in New York. This was before he was actually brought to New York on the recent case. But this, of course, never happened, but it certainly sparked all sorts of concern and it spread like wildfire on the internet using some of this, you know, mid-journey technology in our company called Mid-Journey and a lot of other companies that are creating this. So it's making it easier and easier and less expensive and making it harder for us to tell what's real. And so that technology has of course evolved. So, okay, so now I've talked about some of the democratic discourse. I'm going to go through a little quicker on these other ones so then I can get to sort of the end and try to finish in about, I would say about seven minutes or so. So like I mentioned at the beginning, there's this issue of content creation and that's really important because these content creators are generating a lot of the content that a lot of these technology companies are using to create these chatbots. But we've seen this story before and by the way, just recently, there are major technology companies that are now not allowing the scraping of this data to be trained for these technologies unless they're compensating. I think that's a fair thing. So, you know, some of these big companies like Reddit is not allowing stack overflow is now saying, "Hey, if you're going to scrape our data, they want to be compensated." And so you're going to start to see content creators starting to push back, which is good because like I said, we've seen this story before. Oh, and by the way, this is an example of, you know, Getty Images is in a lawsuit right now with a company that may have been scraping their data illegally. And the reason why that came out is because you can see this little Getty Images that pops up, which is a watermark that Getty Images puts on their images. So there's an appending lawsuit about this and that could determine some of the some of how this content can or can't be scraped. But we've seen this before when looking at new technology and the impact it can have on other information producers in the United States and in many places around the world, we have growing news deserts. These are areas where there's no more local news. And that's pretty devastating for democratic discourse or democracies because we depend on local news for engagement, civic engagement and quality information and local news tends to be trusted more than national news. And there's all sorts of reasons for that happening. But certainly one element of that is the effect that search engines and Google in particular around it, you know, the way it sells ads and it takes a large cut at those ads has potentially contributed to these news deserts. Of course, there's lots of other things as well. But that technology everyone was excited about, including myself and we use it all the time. But there are these unintended effects that can affect other aspects of our information ecosystems. And right now, there's a lawsuit going on. The Justice Department, United States Justice Department is suing Google for monopolizing digital advertising technologies. And one of those elements of this lawsuit story is the sort of increase in the demise of local news. So there's all sorts of interesting things playing out right now. And then the Biden administration, United States is thinking about doing some regulation of AI, but they don't know, it's so new to all administrations that it's hard to figure out. Like I mentioned, Italy has gone probably one of the furthest steps I think around this. But there hasn't been a lot of action, at least on the US side when it comes to this sort of thing. And so, there's been letters. So this was an article written by Time. The image quite nice. It actually grows. There was a letter that went around from a bunch of influential people in AI and business leaders and technology, including Elon Musk that says, hey, we should stop the development until we've had more time to think about it. Although it's kind of ironic, given that many of these tech leaders are still, of course, pushing their own development of AI in many ways and creating new AI companies and developing. But anyway, that's another story. But that is something to think about. I don't think it's a, I think there's no way that that letter is going to stop the technology from being developed. But one thing it is good about is it's makes hopefully forcing the public and journalists and government officials, etc. to start to think about the ways in which this technology could affect society. We should think about it. As I mentioned, one of the concerns is job demise. And I think there's a lot of concern with that by those that even work in the job industry, the Pew Research Center recently asked workers where are they concerned? Turns out a large number of workers from across these different industries are concerned. And there's probably good reason for this concern. Even Sam Altman at OpenAI, which is sort of, or is the owner of the chat GPT, which is the one of the more well-known chatbots out there. And it's also the one that Microsoft has invested billions. This is something that they've even said probably lose 5 million jobs. So these are real concerns. So the other thing to mention too is that it's not just within science itself, these are real concerns. And we've seen the proliferation of pseudoscience and the rise of predatory journals and content that maybe looks like science. But it's not. And I'll show you this is an example for many years ago. This was a paper that was published in this international conference on atomic and nuclear physics. And you look at the title Atomic Energy, or the made of able to a single source, and you read the abstract, and if you look at the abstract, it doesn't make a lot of sense. Well, it turns out that when this was created, it was created by a person to make a point about how poor some of these journal venues and conference venues are. This paper was made with autocomplete using an iPhone. And this is not all that different from this chatbots and chat GPT, which is really these autocomplete machines on steroids. And it looked sort of official, like a real science paper, but of course, a lot of it was nonsense. And the newest ones are much better. But it is a concern that this could increase the number of pseudoscience types of things or articles that are written by chatbots. In fact, there's been some articles that have been co-authored by chat GPT, although some journal, a lot of journals and publishers are saying they won't allow that anymore. And that's probably a good thing. And I will say this, there's been lots of talk about the hallucination of these chatbots. Well, one thing that I find incredibly problematic is the hallucination of citations. It'll make up citations all the time. And we've been doing some work trying to find ways to see when this happens. It even happened. My"
CONCISE SUMMARY:
Prompt after formatting:
Write a concise summary of the following:
"some articles that have been co-authored by chat GPT, although some journal, a lot of journals and publishers are saying they won't allow that anymore. And that's probably a good thing. And I will say this, there's been lots of talk about the hallucination of these chatbots. Well, one thing that I find incredibly problematic is the hallucination of citations. It'll make up citations all the time. And we've been doing some work trying to find ways to see when this happens. It even happened. My colleague, Carl, found these examples of papers supposedly by me. Well, these aren't real citations by me. It shows me right here, West German. This is not my paper. It's close to some of the papers I've written in terms of title, but it's just a fake citation. I just made up these citations. And that's again, another example of how that could affect the citation record and scholarly literature and something that I'm concerned about for science. And something that's now happened with some of these chatbots, even in Bing now that has sort of integrated chat GPT4 into Bing, is that it just throws references. So it looks official. But I can tell you that this was not done before the fact. This is this knowledge that was written out in this answer when I asked about new tax loss for electric vehicles. This is one question I asked that it's not that it's wrote, you know, learn something from citations and then cited them like we do in the scholar literature, it cited them close talk, something that was probably semantically similar. Although, well, maybe scholars, scholars probably do this too. Well, they do do it post after posting, some argument or sentence. But this is problematic to me because it looks like it's a science, almost science and, you know, science-y and technical. And it's really not even though it has those references. So, you know, there's been lots of discussion in the scientific literature what to do with these chatbots, some of lists of authors on papers, publishers have come out, even publishers in the machine learning world. So ICML was, you know, one of the first conferences, not the, I don't think it was the first, but one of the, you know, among the first that was saying, you can't use chat TBT on this. You know, some are saying if you use it, you have to note it, you know, all sorts of different policies are being created. But overall, you know, I think the publishing community in the scholar literature is going to have to grapple with this. And I, and my colleague and I have, Carl and I have a, another op-ed that we're, that we write about sort of what publishers can do around this particular issue. Now, one of the other big concerns of this is, of course, that this technology shows, you know, it doesn't, it's always 100% confident, whether it's right or whether it's wrong. And that's really problematic. At least when humans communicate, they have these qualifiers of confidence where you can say something like, I'm pretty sure, or I think so, or I think that's right. You know, these things are important. And these chatbots don't have it. They just are always, they always seem to be, well, not seem. They spew out things, whether they're right or wrong with 100% confidence. And that's dangerous. And if there's, you know, one paper, one of my colleagues Emily Bender has this great feature where in this paper that she talks about, and also in this feature in, in the New York or, in this New York magazine, they talk, it talks a lot about some of the current concerns, Emily, and other people that are true linguists that truly understand some of the problems with these technologies. This is one that I would recommend reading. And a lot of you may have heard of this early interview that a New York Times journalist had with this, you know, with Bing's chatbot. And it, what essentially happened was the chatbot kind of went off the rails and started to say, well, you should leave your wife and I want to take over the world and all these things happen. And of course, a lot of the developers of this technology, whoa, whoa, whoa, we need to fix it. And there's been new rules around how you can use this Bing chatbot and other chatbots. But the problem with these fixes is they're like bandings. There's really, it's very, very difficult to reverse engineer these problems or reverse engineer. Yeah, reverse engineer these issues. It's not like you can go to a line of code and say, oh, that's where the problem is. It's the way that these things are trained, the way these models work with their resilience of parameters makes it very difficult to reverse engineer. And that's problematic when we run into these issues and all the issues we haven't even thought of. And so that to be is another big concern. Of course, there's all sorts of jail breaks to get these chatbots to do things that there have been bandings put around. And that's problematic. And I won't go over all the jail breaks you can read about because I don't want to get those out too much to the bug. But you can read about them. It's not like they're that hidden. And that's problematic. And there'll be many, many others as well. So these are some of the ones I had, some of these concerns, reverse engineers. The last two I'll mention is the cost. And the cost, we talked about jobs, the cost potentially to all different aspects of society. And the kind of scary thing is right now is that a lot of the tech layoffs are removing these teams. They're removing other individuals as well. But they're removing individuals that are on ethics and safety teams. And of all times to have these kinds of teams at these companies, it would be now, and certainly maybe if you went back in history at the beginning of the rise of social media, that they're being eliminated. And this is a concern. But there's also other kinds of costs that a lot of people forget. And that's the cost of these queries. There's been several analyses that have come out recently about the cost per query for running some of these chatbots. And it's almost an order of magnitude greater than a regular query that you'd have, let's say, on a Google search. And that has a cost. And there's also costs of investing billions and billions of dollars in this technology that could also go to other kinds of investments that might be helping society. So there's these costs that we have to think about the environmental costs, the costs to society, the costs of adding more pollution into our information systems, et cetera. There's also the issue of garbage in garbage out. And that's a problem we're likely going to see as these chatbots generate more and more content that land online, that becomes the training data for those chatbots in, you know, chat, chat GBT5 and chat GBT6. And what those effects will be requires some more research and thinking. But the main thing that we've known in a lot for a long time, of course, in the machine learning world is that garbage in with your training data creates garbage out. And even if you didn't have this, you know, feed forward loop that I just mentioned, there's a lot of garbage on the internet and that garbage finds its way into conversations with these chatbots. And that's always a concern whether you're talking about science or this technology just generative AI technology more broadly. So I'll end by saying that this technology is in many cases amazing. I have mostly focused on some of my cautions and concerns like many people have, especially in my world as someone who studies misinformation and misinformation specifically in science and its effect on the institution of science. And so, and so these are things that we're going to have to, you know, pay attention to going forward. But I think like a lot of our new technology, we just need time to think about it and run seminars and workshops and conferences just like this. So hopefully this generates some conversation and hopefully we can sort out some of these cautions. So with that, I'll end, you can reach out to me, you can learn more about my book and the research we do in my lab and at our university and in our center and you can reach me in these ways. So all right,"
CONCISE SUMMARY:
> Finished chain.
> Entering new StuffDocumentsChain chain...
> Entering new LLMChain chain...
Prompt after formatting:
Write a concise summary of the following:
" In this talk, the speaker discusses the excitement and concerns around generative AI and chatbots, which have become increasingly popular. He focuses on the potential for misinformation and disinformation, job elimination, pseudoscience proliferation, and the need for qualifiers of confidence. He also discusses the implications of the technology for education, copyright, and content credit.
This article discusses the potential implications of large language models and chatbots, which can produce false information at scale. It examines the potential impact on democratic discourse, health, and other areas, and the difficulty of detecting and reversing the effects of misinformation. It also looks at the ways in which these technologies can be used by bad actors and the need for research, policy, education, and community engagement to address the issue.
This article discusses the use of social media platforms to study the amplification of individuals and organizations, as well as the use of bots and synthetically created content. It also discusses the game "Which Faces Real" created to bring public attention to deep fakes, and how this technology has been used to create fake journalists and videos. It also discusses the potential impact of new generative technology on content creators, the growing news deserts in the US, and the Justice Department's lawsuit against Google for monopolizing digital advertising technologies. Finally, it discusses the potential for job loss due to AI, the proliferation of pseudoscience, and the potential for chatbots to create false citations.
Chat GPT technology has been used to co-author articles, but many journals and publishers are now prohibiting this. There are concerns about the technology creating fake citations and always being 100% confident in its answers, which can be dangerous. There are also concerns about the cost of the technology, the environmental cost, and the potential for garbage in/garbage out. It is important to take time to think about the implications of this technology and to have conversations about it."
CONCISE SUMMARY:
> Finished chain.
> Finished chain.
> Finished chain.' This article discusses the potential implications of generative AI and chatbots, such as misinformation, job elimination, pseudoscience proliferation, and the need for qualifiers of confidence. It also looks at the ways in which these technologies can be used by bad actors and the need for research, policy, education, and community engagement to address the issue. It examines the potential impact on democratic discourse, health, and other areas, and the difficulty of detecting and reversing the effects of misinformation. Finally, it discusses the potential for job loss due to AI, the proliferation of pseudoscience, and the potential for chatbots to create false citations.'이 글에서는 잘못된 정보, 일자리 퇴출, 사이비 과학 확산, 신뢰성 검증의 필요성 등 생성형 AI와 챗봇의 잠재적 영향에 대해 논의합니다. 또한 이러한 기술이 악의적인 행위자에 의해 악용될 수 있는 방법과 이 문제를 해결하기 위한 연구, 정책, 교육, 커뮤니티 참여의 필요성에 대해서도 살펴봅니다. 민주적 담론, 건강 및 기타 영역에 미칠 수 있는 잠재적 영향과 잘못된 정보의 영향을 감지하고 되돌리기 어려운 점을 살펴봅니다. 마지막으로 인공지능으로 인한 일자리 손실 가능성, 사이비 과학의 확산, 챗봇이 허위 인용을 일으킬 가능성에 대해 논의합니다.