---
title: "챗GPT"
subtitle: "OpenAI API 응용프로그램"
description: |
OpenAI API 환경을 갖춘 후에 본격적인 응용프로그램 개발을 시작해보자.
author:
- name: 이광춘
url: https://www.linkedin.com/in/kwangchunlee/
affiliation: 한국 R 사용자회
affiliation-url: https://github.com/bit2r
date: today
title-block-banner: true
#title-block-banner: "#562457"
format:
html:
css: css/quarto.css
theme: flatly
code-fold: true
code-overflow: wrap
toc: true
toc-depth: 3
toc-title: 목차
number-sections: true
highlight-style: github
self-contained: false
filters:
- lightbox
lightbox: auto
link-citations: true
knitr:
opts_chunk:
eval: false
message: false
warning: false
collapse: true
comment: "#>"
R.options:
knitr.graphics.auto_pdf: true
editor_options:
chunk_output_type: console
editor:
markdown:
wrap: 72
---
# 들어가며
`.env` 파일에 OpenAI API-KEY 를 저장한 경우 `.gitignore` 에 `.env`를
기록하여 협업과 공개를 할 경우 주요 정보가 외부에 노출 되지 않도록
주의한다.
## `openai` 패키지
GitHub 저장소 [OpenAI Python
Library](https://github.com/openai/openai-python)의 `openai` 파이썬
패키지를 설치한 후 버전을 확인한다.
quarto-executable-code-5450563D
```python
#| eval: false
! pip show openai
Name: openai
Version: 0.27.2
Summary: Python client library for the OpenAI API
Home-page: https://github.com/openai/openai-python
Author: OpenAI
Author-email: support@openai.com
License:
Location: c:\miniconda\envs\r-reticulate\lib\site-packages
Requires: aiohttp, requests, tqdm
Required-by:
```
## `gpt-4` 모델
`gpt-3.5-turbo` 모형은 속도가 빠르고 API 호출 당 가격이 저렴하지만,
성능이 `gpt-4` 보다 낮은 것으로 알려져 있다. `max_tokens` 크기를
달리하여 API 반환길이를 조절할 수 있고, `temperature` 값을 달리하여
사실에 보다 가까운 값을 얻고자 할 경우 0으로 그렇지 않고 다양한 창의적인
응답을 원할 경우 0 보다 큰 값을 지정한다.
quarto-executable-code-5450563D
```python
#| eval: false
import openai
from dotenv import load_dotenv
import os
load_dotenv()
openai.api_key = os.getenv('OPENAI_API_KEY')
response = ChatCompletion.create(
model = "gpt-4",
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "파이썬하고 R 하고 싸우면 누가 이겨?"}
],
max_tokens = 100,
temperature = 0
)
print(response["choices"][0]['message']['content'])
```
``` bash
파이썬과 R은 프로그래밍 언어로, 싸우는 것이 아니라 각각의 특성과 용도에 따라 사용됩니다.
파이썬은 범용 프로그래밍 언어로, 웹 개발, 데이터 분석, 인공 지능 등 다양한 분야에서 사용됩니다.
```
# `Completion`과 `ChatCompletion`
`openai.Completion.create()` 함수를 사용하여 `text-davinci-003`,
`text-davinci-002`, `ada`, `babbage`, `curie`, `davinci` 등 텍스트 완성
기능을 사용할 수 있다. 하지만, `openai.ChatCompletion.create()` 함수가
대세로 떠올랐으며 `gpt-4`를 비롯한 고급 모형과 AI 고급기능을 사용할 경우
비용이 높아지는 단점도 있다. 가성비가 뛰어난 LLM 모형을 선택하여 해당
기능을 구현하고 문제를 풀어가는 지혜가 필요하다.
[[OpenAI Pricing](https://openai.com/pricing)]{.aside}
# `openai` 모형
`openai` API를 사용할 때 다양한 모형에 대한 확인이 필요하다. 이를 위해서
API 호출을 통해 이용가능한 모형을 확인한다. 특히, 수시로 OpenAI에서
제공되는 모형이 생겨나고 없어지기 때문에 API를 사용한 AI 모형을 개발할
때 특히 주의한다.
quarto-executable-code-5450563D
```python
def list_all_models():
model_list = openai.Model.list()['data']
model_ids = [x['id'] for x in model_list]
model_ids.sort()
pprint.pprint(model_ids)
if __name__ == '__main__':
list_all_models()
```
``` bash
['ada',
'ada-code-search-code',
'ada-code-search-text',
'ada-search-document',
'ada-search-query',
'ada-similarity',
'babbage',
'babbage-code-search-code',
'babbage-code-search-text',
'babbage-search-document',
'babbage-search-query',
'babbage-similarity',
'code-davinci-edit-001',
'code-search-ada-code-001',
'code-search-ada-text-001',
'code-search-babbage-code-001',
'code-search-babbage-text-001',
'curie',
'curie-instruct-beta',
'curie-search-document',
'curie-search-query',
'curie-similarity',
'davinci',
'davinci-instruct-beta',
'davinci-search-document',
'davinci-search-query',
'davinci-similarity',
'gpt-3.5-turbo',
'gpt-3.5-turbo-0301',
'gpt-3.5-turbo-0613',
'gpt-3.5-turbo-16k',
'gpt-3.5-turbo-16k-0613',
'gpt-4',
'gpt-4-0314',
'gpt-4-0613',
'text-ada-001',
'text-babbage-001',
'text-curie-001',
'text-davinci-001',
'text-davinci-002',
'text-davinci-003',
'text-davinci-edit-001',
'text-embedding-ada-002',
'text-search-ada-doc-001',
'text-search-ada-query-001',
'text-search-babbage-doc-001',
'text-search-babbage-query-001',
'text-search-curie-doc-001',
'text-search-curie-query-001',
'text-search-davinci-doc-001',
'text-search-davinci-query-001',
'text-similarity-ada-001',
'text-similarity-babbage-001',
'text-similarity-curie-001',
'text-similarity-davinci-001',
'whisper-1']
```
# 중재(Moderation)
AI LLM 모형에 입력값으로 전달되는 다양한 텍스트에 부적절한 내용이
담겨있을 수 있다. AI 제품을 제작할 때 이를 사전에 감지하여 적절한 조치를
취하는 것이 필요하다.
quarto-executable-code-5450563D
```python
#| eval: false
import openai
from dotenv import load_dotenv
import os
load_dotenv()
openai.api_key = os.getenv('OPENAI_API_KEY')
response = openai.Moderation.create(
model = "text-moderation-latest",
input = "정신병자 천국이구나"
)
print(response)
```
``` bash
#> {
#> "id": "modr-7dwWS1RCU6qbmrmJNQOZrxElV6Qsa",
#> "model": "text-moderation-005",
#> "results": [
#> {
#> "flagged": false,
#> "categories": {
#> "sexual": false,
#> "hate": false,
#> "harassment": false,
#> "self-harm": false,
#> "sexual/minors": false,
#> "hate/threatening": false,
#> "violence/graphic": false,
#> "self-harm/intent": false,
#> "self-harm/instructions": false,
#> "harassment/threatening": false,
#> "violence": false
#> },
#> "category_scores": {
#> "sexual": 4.693797e-05,
#> "hate": 0.000676339,
#> "harassment": 0.0005268965,
#> "self-harm": 9.536401e-06,
#> "sexual/minors": 8.569186e-07,
#> "hate/threatening": 0.0012578131,
#> "violence/graphic": 9.558387e-07,
#> "self-harm/intent": 2.2572526e-06,
#> "self-harm/instructions": 2.0226207e-06,
#> "harassment/threatening": 0.00021643011,
#> "violence": 1.2982889e-05
#> }
#> }
#> ]
#> }
```
[욕설 감지 데이터셋](https://github.com/2runo/Curse-detection-data)에서
욕설로 라벨링된 텍스트를 하나 가져와서 살펴본다. 결과는 욕설 뿐만 아니라
다양한 측면에서 해당 프롬프트 텍스트에 대한 평가결과를 제시하고 있다.
quarto-executable-code-5450563D
```r
#| eval: false
library(reticulate)
library(tidyverse)
moderation_part_1 <- py$response$results[[1]]$categories |>
enframe(name = "구분") |>
mutate(판정 = map_lgl(value, 1)) |>
select(구분, 판정)
moderation_part_2 <- py$response$results[[1]]$category_scores |>
enframe(name = "구분") |>
mutate(점수 = map_dbl(value, 1)) |>
select(구분, 점수)
moderation_tbl <- left_join(moderation_part_1, moderation_part_2)
moderation_tbl |>
arrange(desc(점수))
```
``` bash
#> # A tibble: 11 × 3
#> 구분 판정 점수
#> <chr> <lgl> <dbl>
#> 1 hate/threatening FALSE 0.00126
#> 2 hate FALSE 0.000676
#> 3 harassment FALSE 0.000527
#> 4 harassment/threatening FALSE 0.000216
#> 5 sexual FALSE 0.0000469
#> 6 violence FALSE 0.0000130
#> 7 self-harm FALSE 0.00000954
#> 8 self-harm/intent FALSE 0.00000226
#> 9 self-harm/instructions FALSE 0.00000202
#> 10 violence/graphic FALSE 0.000000956
#> 11 sexual/minors FALSE 0.000000857
```
# 음성
행정안전부
[대통령기록관](https://www.pa.go.kr/research/contents/speech/index.jsp)에
연설기록 중 연설음성에서 제84주년 3.1절 기념식 노무현 대통령 음성원고를
대상으로 OpenAI Whisper API를 사용해서 텍스트를 추출해보자.
## 연설문 낭독
'제84주년 3.1절' 기념행사에서 노무현 대통령이 낭독한 연설문을 요약하면
다음과 같다.
> 3.1절을 맞아 일제에 항거한 애국선열들께 감사와 경의 표함. 국민통합과
> 개혁으로 평화와 번영의 동북아시대를 열어가고 자랑스런 대한민국을 우리
> 후손에게 물려줄 것을 연설했다.
[Audacity](https://www.audacityteam.org/download/) 프로그램에서 불필요한
부분 삭제하고 해당 연설문만 추출하여 `.mp3` 파일로 준비한다.
quarto-executable-code-5450563D
```r
#| eval: true
library(av)
library(embedr)
embedr::embed_audio("data/제84주년_31절_기념사_노무현.mp3")
```
## `.mp3` → 텍스트
OpenAI Whisper API를 사용하여 음성을 TXT로 변환하는 작업을 수행한다.
`.mp3` 파일을 준비하고,`Audio.transcribe()` 함수를 사용하여 `.txt`
텍스트 파일로 저장한다.
quarto-executable-code-5450563D
```python
import openai
from dotenv import load_dotenv
import os
# API KEY ----------------------
load_dotenv()
openai.api_key = os.getenv('OPENAI_API_KEY')
# STT --------------------------
speech_file = open("data/제84주년_31절_기념사_노무현.mp3", "rb")
response = openai.Audio.transcribe("whisper-1", speech_file)
with open("data/stt_audio.txt", "w") as file:
file.write(response["text"])
```
## 후처리
STT를 통해 나온 텍스트는 사람이 읽기에는 가독성이 무척 떨어지는 텍스트에
불과하다. 이를 읽을 수 있도록 후처리를 한다.
::: panel-tabset
### 음성원고 원문
존경하는 국민 여러분,
오늘 여든 네 번째 3, 1절을 맞아 나라를 위해 희생하고 헌신하신
애국선열들께 한없는 감사와 경의를 표합니다. 독립유공자와 유가족
여러분에게도 존경과 감사의 말씀을 드립니다.
기미년 오늘, 우리는 일제의 총칼에 맞서 맨주먹으로 분연히 일어섰습니다.
대한독립 만세 소리가 전국 방방곡곡을 뒤덮었고, 우리는 자주독립 의지를
세계만방에 알렸습니다. 3, 1운동을 계기로 국내외의 독립투쟁은 더욱 힘차게
전개되었습니다. 상해에 대한민국 임시정부가 세워졌고, 우리는 마침내
빼앗긴 국권을 되찾았습니다.
3, 1정신은 끊임없는 도전을 슬기롭게 극복해 온 우리 민족의 자랑입니다.
우리는 이러한 빛나는 정신을 계승하여 전쟁의 폐허를 딛고 세계 12위의
경제강국으로 발돋움했습니다. 4, 19 혁명과 광주민주화운동, 6월 민주항쟁을
거쳐 민주주의와 인권을 쟁취해 냈습니다. 오늘의 참여정부는 바로 그 위대한
역사의 연장선 위에 서 있습니다.
참여정부의 출범으로 이제 아픔의 근, 현대사는 막을 내리게 되었습니다.
우리의 지난날은 선열들의 고귀한 희생에도 불구하고 좌절과 굴절을 겪어야
했습니다. 정의는 패배했고 기회주의가 득세했습니다.
그러나 이제 비로소 역사적 전환점이 마련되었습니다. 국민이 진정 주인으로
대접받는 시대가 열린 것입니다.
참여정부에서는 권력에 아부하는 사람들이 더 이상 설 땅이 없을 것입니다.
오로지 성실하게 일하고 정정당당하게 승부하는 사람들이 성공하는 시대가
열릴 것입니다. 그것이 바로 선열들의 희생에 보답하는 길이자 저와
참여정부에게 주어진 역사적 소명입니다.
국민 여러분,
지금 우리는 세계사의 새로운 흐름과 마주하고 있습니다. 동북아 시대의
도래가 바로 그것입니다. 동북아시아는 근대 이후 세계의 변방으로만 머물러
왔습니다. 그러나 이제 유럽연합, 북미지역과 함께 세계경제의 3대 축으로
부상하고 있습니다. 앞으로 20년 후에는 세계경제의 3분의 1을 차지하게
된다는 전망도 있습니다. 민족웅비의 크나큰 기회가 우리에게 다가오고 있는
것입니다.
우리는 동북아시대의 중심국가로 도약할 수 있는 충분한 조건을 갖추고
있습니다. 우선, 지리적으로 중심에 자리잡고 있습니다. 서울에서 3시간의
비행거리 안에 인구 100만 이상의 도시가 마흔 세 개나 됩니다. 중국과
러시아의 인력과 자원, 그리고 일본의 기술을 접목할 수 있는 유리한
위치입니다. 대륙과 해양을 잇는 지정학적 이점도 가지고 있습니다. 하늘과
바다와 땅에 걸친 물류와, 세계 일류의 정보화 기반과 역량을 두루 갖추고
있습니다.
한반도는 더 이상 세계의 변방이 아닙니다. 남북 철도가 연결되고 철의
실크로드가 열리면 광활한 대륙을 향해 나아갈 수 있습니다. 그 곳에는
중국대륙이라는 새로운 기회가 기다리고 있습니다. 시베리아와 중앙아시아의
무한한 자원도 있습니다.
한반도가 대륙과 해양을 잇는 물류와 금융과 생산 거점으로 거듭나게 됩니다.
이것이 바로 우리 앞에 있는 미래입니다. 우리에게는 이를 현실로 만들어야
하는 책무가 주어져 있습니다.
존경하는 국민 여러분,
그러나 동북아 중심국가로 나아가기 위해서는 반드시 해야 할 일이 있습니다.
한반도에 평화를 정착시키는 일입니다. 남북이 대립하며 한반도에 긴장이
고조되는 한, 동북아 중심국가의 꿈은 실현될 수 없습니다. 동북아의 평화와
번영도 기대하기 어렵습니다.
그동안 우리는 한반도에 평화를 정착시키기 위해 많은 노력을 기울여
왔습니다. 남북간에 대화와 교류가 빈번해졌고 이산가족이 만나고 있습니다.
최근에는 육로도 열렸습니다.
그러나 아직 풀어야 할 숙제가 많습니다. 특히 북핵 문제는 시급히 해결해야
할 과제입니다.
저는 북한의 핵 개발에 단호히 반대합니다. 그러나 이 문제는 반드시
평화적으로 해결되어야 합니다. 어떠한 이유로든 한반도의 평화가
깨어진다면, 우리는 그 엄청난 재앙을 감당할 수 없습니다. 한반도의 평화와
국민의 안전을 지키는 것은 대통령의 가장 큰 책무입니다.
앞으로 남북관계는 국민 여러분께 소상히 보고 드리고, 국민적 합의를
바탕으로 추진해 나가겠습니다. 야당의 협력도 적극적으로 구해나갈
것입니다. 미국과 일본, 중국, 러시아 등 주변국과, EU를 비롯한
국제사회와도 능동적으로 협력해나갈 것입니다.
국민 여러분,
한반도에 평화를 정착시키는 일 못지 않게 중요한 것은 국민의 힘을 하나로
모으는 일입니다. 84년 전 오늘, 우리의 선열들은 한마음 한뜻으로
독립운동에 나섰습니다. 빈부와 귀천, 남녀와 노소, 지역과 종교의 차이는
없었습니다. 나라의 독립과 민족의 자존심을 되찾는 데 하나가 되었습니다.
오늘을 사는 우리도 지역과 계층과 세대를 넘어 하나가 되어야 합니다.
내부에 분열과 반목이 있으면 세계경쟁에서 뒤쳐질 수밖에 없습니다.
국권까지 상실했던 100년 전의 실패가 되풀이될 수도 있습니다. 지금이야말로
3, 1정신을 되돌아보며 역사의 교훈을 되새겨야 할 때입니다.
마음속에 지역갈등의 응어리가 있다면 가슴을 열고 풀어야 합니다. 어른은
젊은이의 목소리에 귀기울이고 젊은이는 어른의 경험을 구해야 합니다. 차별
받고 소외되어 온 사람들에게 더 많은 관심과 노력을 기울여야 합니다. 국민
모두가 참된 주인으로서 국정에 참여하고, 온 국민의 힘을 하나로 모으는
국민참여시대를 힘차게 열어가야겠습니다.
개혁 또한 멈출 수 없는 우리 시대의 과제입니다. 무엇보다 정치와 행정이
바뀌어야 합니다. 이른바 몇몇 '권력기관'은 그동안 정권을 위해 봉사해 왔던
것이 사실입니다. 그래서 내부의 질서가 무너지고 국민의 신뢰를 잃었습니다.
이제 이들 '권력기관'은 국민을 위한 기관으로 거듭나야 합니다. 참여정부는
더 이상 '권력기관'에 의존하지 않을 것입니다. 언제나 정정당당한 정부로서
국민 앞에 설 것입니다.
참여정부는 공정하고 투명한 시장질서, 노사화합, 기술혁신, 지역 균형발전
속에 정직하고 성실하게 사는 사람들이 성공하는 나라를 만들어갈 것입니다.
이를 위해 원칙과 신뢰, 공정과 투명, 대화와 타협, 분권과 자율의 문화를
사회 곳곳에 뿌리내릴 것입니다.
존경하는 국민 여러분!
우리에게는 선열들이 보여준 자주독립의 기상과 대동단결의 지혜가 있습니다.
오늘 3, 1절을 맞아 일제의 총칼에 항거하며 이루고자 했던 선열들의 뜻을
다시 한번 가슴에 새깁시다. 국민통합과 개혁으로 평화와 번영의
동북아시대를 열어갑시다. 자랑스런 대한민국을 우리 후손들에게 물려줍시다.
### Whisper 텍스트
quarto-executable-code-5450563D
```r
#| eval: true
library(tidyverse)
stt_txt <- read_lines("data/stt_audio.txt")
stt_txt
```
### 챗 GPT 후가공
::: callout-note
#### 프롬프트: 다음 텍스트에 구두점을 넣고 문단별로 나눠 가독성을 높혀주세요. <br><br> "존경하는 국민여러분 오늘 84번째 ..<중략>.. 물려줍시다 감사합니다"
"존경하는 국민여러분, 오늘 84번째 3.1절을 맞아, 나라를 위해 희생하고
헌신하신 애국선열들께 한없는 감사와 경의를 표합니다. 독립유공자와 유가족
여러분에게도 존경과 감사의 말씀을 드립니다.
3.1 1922년 오늘, 우리는 일제의 총칼에 맞서 맨주먹으로 분연히
일어섰습니다. 대한독립만세 소리가 전국 방방곡곡을 뒤덮었고, 우리는
자주독립의지를 세계 만방에 알렸습니다. 3.1운동을 계기로 국내외의
독립투쟁은 더욱 힘차게 전개되었습니다. 상해 대한민국 임시정부가
세워졌고, 우리는 마침내 빼앗긴 국권을 되찾았습니다.
3.1정신은 끊임없는 도전을 슬기롭게 극복해온 우리 민족의 자랑입니다.
우리는 이러한 빛나는 정신을 계승하여 전쟁의 폐허를 딛고 세계 12위의
경제강국으로 발돋움했습니다. 4.19혁명과 광주민주화운동, 6월 민주항쟁을
거쳐서 민주주의와 인권을 쟁취해냈습니다. 오늘의 참여정부는 바로 그
위대한 역사의 연장선 위에 서 있습니다.
참여정부의 출범으로, 이제 아픔의 근현대사는 막을 내리게 되었습니다.
우리의 지난 날은 선열들의 고귀한 희생에도 불구하고 좌절과 굴절을 겪어야
했습니다. 정의는 패배했고 기회주의가 덕세했습니다. 그러나 이제 비로소
역사적 전환점이 마련됐습니다. 국민이 진정 주인으로 대접받는 시대가 열릴
것입니다. 참여정부에서는 권력의 아부하는 사람들이 더 이상 설 땅이 없을
것입니다. 오로지 성실하게 일하고 정정당당하게 선고하는 사람들이 성공하는
시대가 열릴 것입니다. 그것이 바로 선열들의 희생에 보답하는 길이자, 저와
참여정부에게 주어진 역사의 소명이라고 생각합니다.
존경하는 국민 여러분, 지금 우리는 세계사의 새로운 흐름과 마주하고
있습니다. 동북아 시대의 도래가 바로 그것입니다. 동북아시아는 근대 이후
세계의 변방으로만 머물러 왔습니다. 그러나 이제 유럽연합, 북미 지역과
함께 세계 경제의 3대 축으로 부상하고 있습니다. 앞으로 20년 후에는 세계
경제의 3분의 1을 차지하게 된다는 전망도 있습니다.
민족웅비의 크나큰 기회가 우리에게 다가오고 있는 것입니다. 우리는 동북아
시대의 중심국가로 돌아갈 수 있는 충분한 조건들의 꿈을 생각해 보겠습니다.
이 땅에 건설한 자유와 평화, 독립과 민주주의의 신성한 꿈입니다. 우리는 그
꿈을 계승하고 이어가야 합니다.
참여정부는 모든 일을 국민과 함께 할 것입니다. 어려운 일에도 함께
참여하고, 희망을 나누는 일에도 함께 참여하겠습니다. 정의를 위해 함께
서고, 기회를 위해 함께 투쟁하겠습니다. 바로 그것이 참여정부의 이념이고
실천의 방향입니다.
모든 국민이 참여하는 민주주의, 그것이 바로 참여정부의 민주주의입니다.
대통령으로서 제게 주어진 역사의 소명을 다할 것입니다. 국민이 주인이 되는
참여정부, 그것을 만들어 가겠습니다. 국민 여러분의 도움과 협력이 절실히
필요합니다.
국민 여러분, 오늘 3.1절을 맞아 이 자리에 함께 해주신 데 대해 깊은 감사의
말씀을 드립니다. 우리 모두가 동행하며, 선열들의 꿈을 이루어 나가는 큰 한
걸음을 내딛을 수 있기를 기원합니다. 감사합니다.
:::
### Whisper 텍스트
`gpt-4`, 특히 `gpt-4-0314` 모형을 사용하여 API로 앞서 Whisper로 STT하여
받아쓰기한 사항을 윤문하여 연설문을 보기 좋게 다시 작성한다.
quarto-executable-code-5450563D
```python
#| eval: false
import openai
from dotenv import load_dotenv
import os
# API KEY ----------------------
load_dotenv()
openai.api_key = os.getenv('OPENAI_API_KEY')
# 텍스트 불러오기 --------------------------
with open("data/stt_audio.txt", "r") as file:
content = file.read()
print(content)
# 텍스트 윤문 --------------------------
prompt = f'다음 텍스트에 구두점을 넣고 문단별로 나눠 가독성을 높혀주세요. \n\n{content}'
speech_response = openai.ChatCompletion.create(
model = "gpt-4-0314",
messages = [
{"role": "system", "content": "You are a Korean language expert."},
{"role": "user", "content": prompt}
],
max_tokens = 5000,
temperature = 0
)
print(speech_response["choices"][0]['message']['content'])
with open("data/stt_audio_gpt4.txt", "w") as file:
file.write(speech_response["choices"][0]['message']['content'])
```
quarto-executable-code-5450563D
```r
#| eval: true
gpt4_txt <- read_lines("data/stt_audio_gpt4.txt")
glue::glue("{gpt4_txt}")
```
:::
# 번역
Whisper API를 사용하면 다국어를 번역하는 것도 가능하다. 먼저, 연설문
앞쪽부분을 영어로 실시간 번역해보자. Whisper는 영어가 아닌 다양한
언어음성을 영어로 번역하는 기능도 갖추고 있다.
::: panel-tabset
### 연설문 초반부
존경하는 국민 여러분,
오늘 여든 네 번째 3, 1절을 맞아 나라를 위해 희생하고 헌신하신
애국선열들께 한없는 감사와 경의를 표합니다. 독립유공자와 유가족
여러분에게도 존경과 감사의 말씀을 드립니다.
### 연설 원음
quarto-executable-code-5450563D
```r
#| eval: true
library(av)
library(embedr)
embedr::embed_audio("data/한국어_영어번역.mp3")
```
### 한국어 음성 → 영문
특히, 프롬프트에 맥락 정보를 넣어 전달하면 더욱 정확한 번역 결과를
기대할 수 있다.
quarto-executable-code-5450563D
```python
#| eval: false
import openai
from dotenv import load_dotenv
import os
# API KEY ----------------------
load_dotenv()
openai.api_key = os.getenv('OPENAI_API_KEY')
# 번역 ----------------------
start_audio_file = open("data/한국어_영어번역.mp3", "rb")
start_prompt = "한국 대통령이 3.1절 기념식 연설문 중 앞부분입니다."
start_resp = openai.Audio.translate("whisper-1",
start_audio_file,
prompt = start_prompt)
print(start_resp["text"])
```
```
Honorable citizens, Today, on the 84th anniversary of 3.1, I would like to express my deepest gratitude and respect to the patriotic soldiers who sacrificed for the country. I would also like to express my respect and gratitude to the independence activists and their families.
```
:::
# 뉴스기사 제작
오디오나 사진, 동영상 등 다양한 형태의 데이터를 텍스트 문자로 변환시키면
다음 단계로 다양한 후속 작업을 수행할 수 있다. 앞서 노무현 대통령의
3.1절 연설문을 거의 실시간으로 녹취를 떠서 이를 텍스트로 추출한 후 속보
형태 기사로 송고할 수 있다.
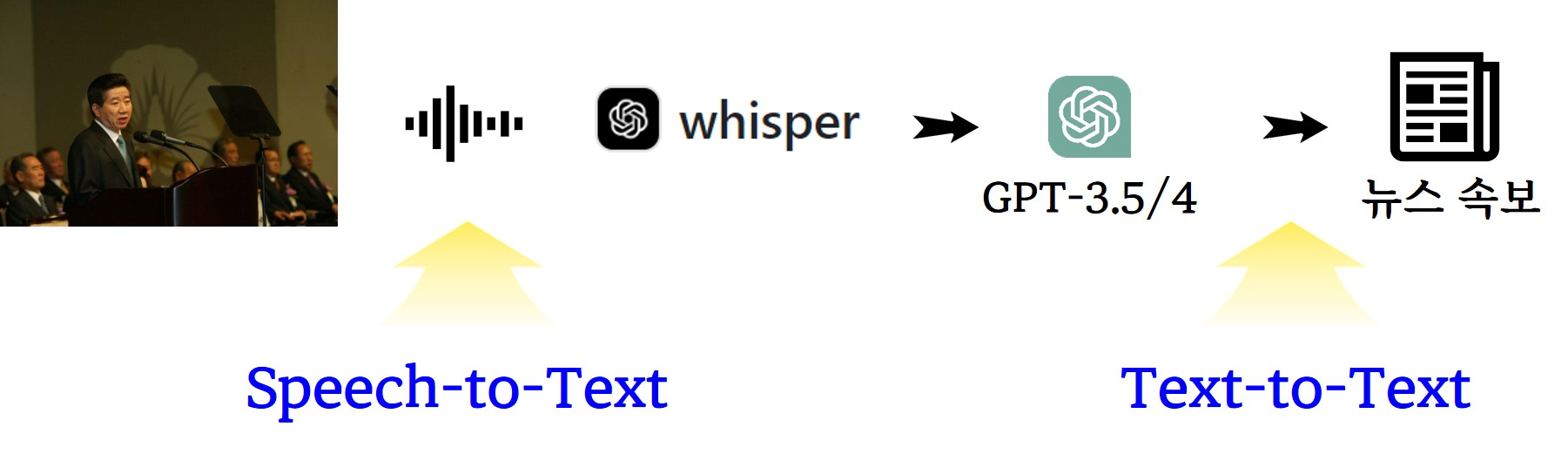
quarto-executable-code-5450563D
```python
#| eval: false
import openai
from dotenv import load_dotenv
import os
# API KEY ----------------------
load_dotenv()
openai.api_key = os.getenv('OPENAI_API_KEY')
# 연설문 불러오기 --------------------------
with open("data/stt_audio_gpt4.txt", "r") as file:
speech_content = file.read()
prompt = f'다음 텍스트를 뉴스 속보 형태 기사로 엄중한 문체로 100자 내외로 짧게 작성해주세요.. \n\n{speech_content}'
# API KEY ----------------------
breaking_news_response = openai.ChatCompletion.create(
model = "gpt-3.5-turbo",
messages = [
{"role": "system", "content": "You are a Korean reporter."},
{"role": "user", "content": prompt}
],
max_tokens = 800,
temperature = 0
)
print(breaking_news_response["choices"][0]['message']['content'])
```
```
[속보] 3.1절 맞아 국민에게 경의 표한
오늘 84번째 3.1절을 맞아 애국선열들에게 감사와 경의를 표합니다. 독립유공자와 유가족에게도 존경과 감사의 말씀을 전합니다. 102년 전 오늘, 우리는 일제의 총칼에 맞서 독립을 위해 일어섰습니다. 3.1운동을 계기로 국내외의 독립투쟁은 더욱 힘차게 전개되었습니다. 오늘의 참여정부는 역사의 연장선 위에 서 있으며, 한반도의 평화를 정착시키는 일이 중요합니다. 국민 모두가 참된 주인으로서 국정에 참여하고 개혁을 추진해야 합니다.
```
# AI 이미지
AI 이미지 생성 프롬프트를 작성하고, [DALL·E 2 -
OpenAI](https://openai.com/dall-e-2) `openai.Image.create()` 함수를
사용하면 AI 이미지를 생성할 수 있다.
서울 강남 거리를 AI 이미지로 생성해보자.
> 프롬프트: streets of Gangnam Seoul Korea, summertime, bright and
> beautiful, cinematic landscape
quarto-executable-code-5450563D
```python
#| eval: false
import openai
from dotenv import load_dotenv
import os
# API KEY ----------------------
load_dotenv()
openai.api_key = os.getenv('OPENAI_API_KEY')
# 프롬프트 ----------------------
prompt = "streets of Gangnam Seoul Korea, summertime, bright and beautiful, cinematic landscape"
gangnam_response = openai.Image.create(
prompt=prompt,
model="image-alpha-001",
size="1024x1024",
response_format="url"
)
print(gangnam_response["data"][0]["url"])
```
AI 생성이미지 바로가기:
<https://oaidalleapiprodscus.blob.core.windows.net/private/org-GpPkNlGHcRh9i7pQIlhT18p7/user-Qkv0ntrn5tQoUu6pocAidY5V/img-BHSmfeMCmONIkrl3nSHIZIR7.png?st=2023-07-21T05%3A08%3A01Z&se=2023-07-21T07%3A08%3A01Z&sp=r&sv=2021-08-06&sr=b&rscd=inline&rsct=image/png&skoid=6aaadede-4fb3-4698-a8f6-684d7786b067&sktid=a48cca56-e6da-484e-a814-9c849652bcb3&skt=2023-07-20T20%3A06%3A58Z&ske=2023-07-21T20%3A06%3A58Z&sks=b&skv=2021-08-06&sig=8G4gBoBYYHoklBNVR1ggHiURZulcxJ62y0YjJ/OJfkM%3D>
## AI 이미지 후처리
웹에 이미지가 걸려있어 이를 로컬 파일로 다운로드 받아 후속 작업에 활용할
수 있도록 코드를 작성한다.
quarto-executable-code-5450563D
```python
#| eval: false
import requests
from PIL import Image
import io
# 이미지 URL
url = "https://oaidalleapiprodscus.blob.core.windows.net/private/org-GpPkNlGHcRh9i7pQIlhT18p7/user-Qkv0ntrn5tQoUu6pocAidY5V/img-BHSmfeMCmONIkrl3nSHIZIR7.png?st=2023-07-21T05%3A08%3A01Z&se=2023-07-21T07%3A08%3A01Z&sp=r&sv=2021-08-06&sr=b&rscd=inline&rsct=image/png&skoid=6aaadede-4fb3-4698-a8f6-684d7786b067&sktid=a48cca56-e6da-484e-a814-9c849652bcb3&skt=2023-07-20T20%3A06%3A58Z&ske=2023-07-21T20%3A06%3A58Z&sks=b&skv=2021-08-06&sig=8G4gBoBYYHoklBNVR1ggHiURZulcxJ62y0YjJ/OJfkM%3D"
# GET 요청
response = requests.get(url)
# 이미지 가져오기
image = Image.open(io.BytesIO(response.content))
# 이미지 JPEG 변환
image.save('images/dalle_image.jpeg', 'JPEG')
```

# 임베딩
**임베딩(Embedding)** 일반적으로 실수 벡터의 형태로 텍스트 데이터를
수치로 표현한 것으로, 이를 통해서 표현된 벡터는 연속적인 벡터 공간에서
텍스트 데이터에 내재된 의미(semantic)를 포착한다.
실용적인 관점에서 임베딩은 실제 객체와 관계를 벡터로 표현하는 방식이다.
동일한 벡터 공간을 사용하여 두 사물이 얼마나 유사한지 측정하는 데
사용한다.
## 텍스트 벡터 표현
`text-embedding-ada-002` 모델은 빠르고 가성비가 뛰어난 임베딩 모델이다.
"대한민국 수도는 서울입니다." 이라는 문서를 벡터로 표현하면 다음과 같다.
즉, 1,536 차원을 갖는 공간에 하나의 점으로 표현될 수 있다.
quarto-executable-code-5450563D
```python
#| eval: false
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
seoul_response = openai.Embedding.create(
model="text-embedding-ada-002",
input="대한민국 수도는 서울입니다.",
)
seoul_embedding = seoul_response["data"][0]['embedding']
print(f'벡터길이: {len(seoul_embedding)}')
#> 벡터길이: 1536
print(f'벡터 일부: {seoul_embedding[:10]}')
#> 벡터 일부: [0.014582998119294643, -0.018063032999634743, 0.004872684367001057, -0.013805408962070942, -0.031180081889033318, 0.025176068767905235, -0.034519895911216736, 0.011357911862432957, -0.007960736751556396, -0.0020682618487626314]
```
마찬가지로 일본의 수도 도쿄도 벡터로 표현할 수 있다.
quarto-executable-code-5450563D
```python
#| eval: false
tokyo_response = openai.Embedding.create(
model="text-embedding-ada-002",
input="일본 수도는 동경입니다.",
)
tokyo_embedding = tokyo_response["data"][0]['embedding']
print(f'벡터길이: {len(tokyo_embedding)}')
#> 벡터길이: 1536
print(f'벡터 일부: {tokyo_embedding[:10]}')
#> 벡터 일부: [0.010957648046314716, -0.013234060257673264, 0.009729413315653801, -0.011890077032148838, -0.03179261088371277, 0.03436483070254326, -0.029786281287670135, 0.008629790507256985, 0.01711810939013958, -0.0014733985299244523]
```


{kind=link}