2 데이터
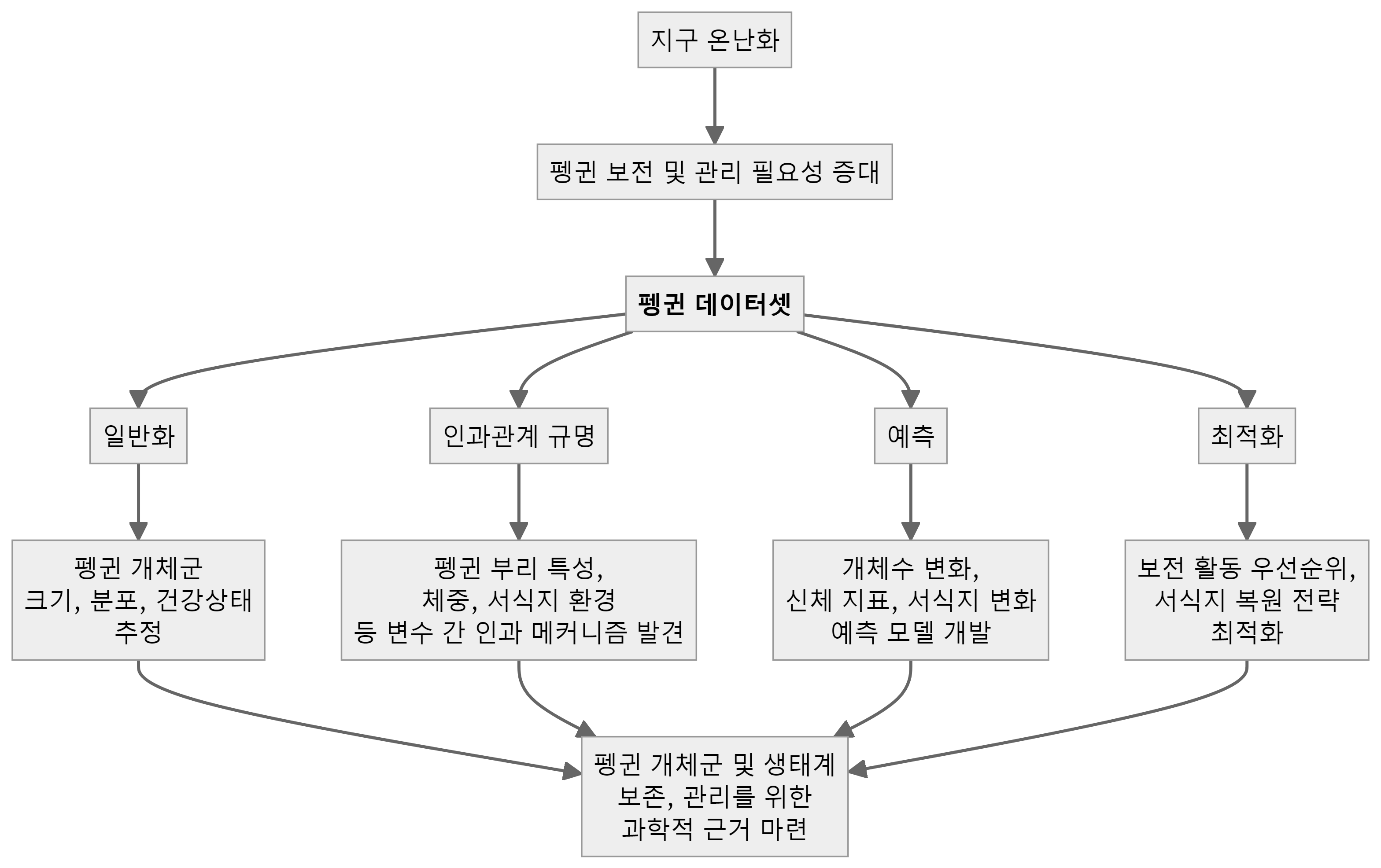
지구 온난화로 펭귄 보전과 관리도 중요한 화두다. 팔머 펭귄 데이터셋은 펭귄 개체군과 생태계를 보존하고 관리하기 위한 과학적 근거를 마련하는 데 중요한 역할을 한다. 데이터에 기반한 일반화, 인과관계, 예측, 최적화는 통계학과 데이터 과학에서 매우 중요한 개념이다. 이러한 개념을 통해 펭귄 개체군의 현황을 파악하고, 생태적 특성과 환경 요인 간의 인과관계를 규명하며, 미래 동향을 예측하고, 보전정책과 서식지 관리를 최적화할 수 있다.
펭귄 개체군의 현황을 파악하고 일반화된 통계를 산출하기 위해서, 데이터 수집과 일반화 과정은 필요하다. 이를 통해 펭귄 전체 모집단의 크기, 분포, 건강 상태 등 다양한 정보를 추정할 수 있다.
수집된 데이터를 바탕으로 데이터 분석을 통해 펭귄 부리 특성, 체중, 서식지 환경 등 변수들 간의 인과적 메커니즘을 발견할 수 있다. 이를 통해 펭귄의 생태적 특성과 환경 요인 간의 인과관계를 규명할 수 있다.
수집된 데이터로 개체수 변화, 신체 지표, 서식지 변화 등을 예측하는 모델을 개발할 수 있다. 이를 통해 펭귄 개체군의 미래 동향을 예측할 수 있다.
예측 모델과 인과관계 분석을 통해 보전 활동의 우선순위, 서식지 복원 전략 등을 과학적으로 최적화할 수 있다. 이를 통해 펭귄 보전정책과 서식지 관리를 최적화할 수 있다.
통계학의 핵심개념을 깊이 들어가기 전에 지구 온난화로 인한 펭귄 보전과 관리의 중요성을 데이터를 통해 가볍게 먼저 살펴보자.
2.1 펭귄 데이터셋
미국에서 조지 플로이드(George Floyd)가 경찰에 의해 살해되면서 촉발된 “흑인들의 생명도 소중하다 (Black Lives Matter)” 운동은 아프리카계 미국인을 향한 폭력과 제도적 인종차별에 반대하는 사회운동이다. 한국에서도 소수 정당인 정의당이 여당 의원 176명 중 누가?…차별금지법 발의할 ’의인’을 구합니다라는 기사를 내는 등 적극적으로 나서는 계기가 되었다.
통계 및 데이터 과학 분야에서도 R.A. 피셔의 과거 저서(Fisher, 1930)에 나타난 우생학(Eugenics)에 대한 관점이 논란이 되면서, 통계 및 R 데이터 과학의 첫 데이터셋인 붓꽃(iris) 데이터를 다른 데이터셋, 즉 펭귄 데이터로 대체하려는 움직임이 활발히 전개되고 있다. palmerpenguins 데이터셋(AbdulMajedRaja, 2020; Gorman, 2014; Horst 기타, 2020; Levy, 2019)이 대안으로 많은 호응을 얻고 있다.
2.2 팔머 군도 펭귄
팔머 펭귄 데이터에는 젠투 펭귄, 아델리 펭귄, 턱끈 펭귄 3종이 포함되고 각기 다른 모양과 생태적 특징을 갖고 있다. 1
- 젠투 펭귄(Gentoo Penguin): 머리에 모자처럼 둘러져 있는 하얀 털 때문에 알아보기가 쉽다. 암컷은 회색이 뒤에, 흰색이 앞에 있다. 펭귄 중에 가장 빠른 시속 36km의 수영 실력을 자랑하며, 짝짓기 준비가 된 펭귄은 75-90cm까지 자란다.
- 아델리 펭귄(Adelie Penguin): 프랑스 탐험가 뒤몽 뒤르빌(Dumont D’Urville) 부인의 이름을 따서 ’아델리’라 불리게 되었다. 각진 머리와 작은 부리 때문에 알아보기 쉽고, 다른 펭귄들과 마찬가지로 암수가 비슷하게 생겼지만 암컷이 조금 더 작다.
- 턱끈 펭귄(Chinstrap Penguin): 언뜻 보면 아델리 펭귄과 매우 비슷하지만, 몸집이 조금 더 작고, 목에서 머리 쪽으로 이어지는 검은 털이 눈에 띈다. 어린 턱끈 펭귄은 회갈색 빛을 띠는 털을 가지고 있으며, 목 아래 부분은 더 하얗다. 무리 지어 살아가며 일부일처제를 지키기 때문에 짝짓기 이후에도 부부로서 오랫동안 함께 살아간다.

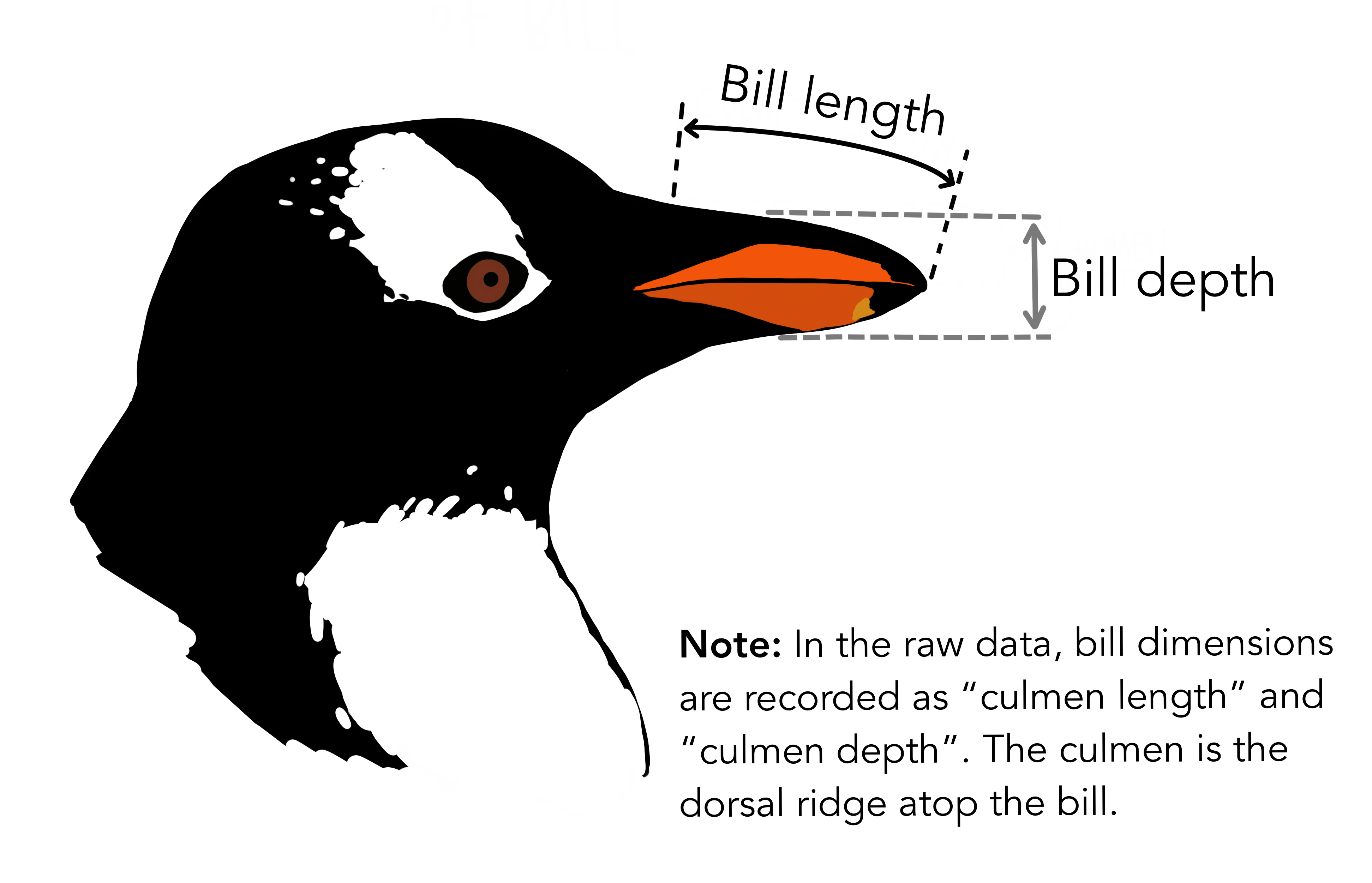
iris 데이터와 마찬가지로 펭귄 3종을 구분하기 위한 변수로 조류의 부리에 있는 중앙 세로선의 융기를 지칭하는 능선(culmen) 길이(culmen length)와 깊이(culmen depth)를 이해하면 된다. 능선은 부리로 다시 번역되어 실제 데이터에는 능선(부리) 정보 외에도 물칼퀴 길이, 체중, 성별, 종, 서식섬, 관측연도 정보가 담겨 있다.
2.3 펭귄 서식지
그림 2.4에는 펭귄 데이터를 수집한 연구자의 모습과 펭귄들이 서식하는 섬, 그리고 펭귄들의 사진이 담겨 있다. 팔머 연구소는 남극 반도에 위치한 섬으로, 연구소 인근에 펭귄들의 서식지가 있다.
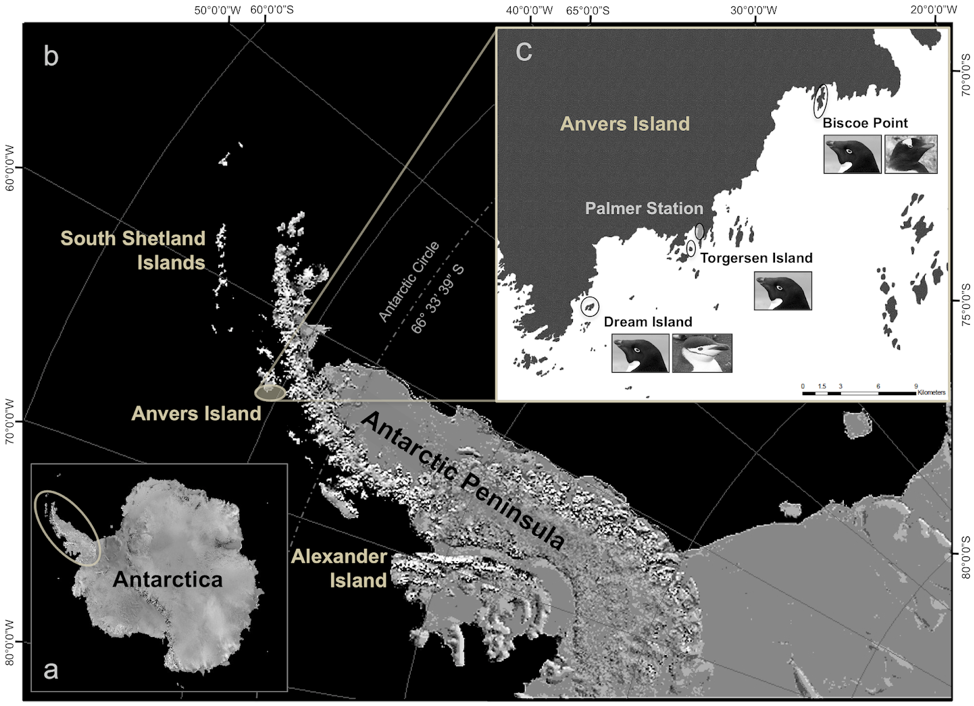





leaflet 패키지를 사용하면 남극 지역에서 펭귄 서식지를 특정할 수 있다. 이를 위해 지오코딩(geocoding)을 해야 하는데, 구글에서 위치 정보를 검색하면 https://latitude.to/에서 직접 위경도 정보를 제공한다. 이 정보를 바탕으로 펭귄 서식지를 시각화할 수 있다.
2.4 데이터 수집
데이터 수집은 팔머 군도 현장에서 이루어졌다. 연구자들은 펭귄을 직접 관찰하고, 부리 길이, 부리 깊이, 플리퍼 길이, 체질량 등을 측정하였다. 또한 펭귄의 성별과 종을 기록하고, 필요에 따라 혈액 샘플을 채취하기도 하였다. 이렇게 수집된 데이터는 연구실로 가져와 디지털화되고 정리되었다.
Raw 데이터를 분석에 적합한 형태로 가공하기 위해, 연구자들은 데이터 정제 및 전처리 과정을 거쳤다. 결측치를 확인하고 처리하였으며, 이상치(outlier)를 점검하였다. 변수의 형태를 일관되게 맞추고, 필요에 따라 파생변수를 생성하기도 하였다. 이렇게 준비된 데이터는 palmerpenguins R 패키지에 포함되어 배포되었다.
palmerpenguins 패키지의 데이터는 데이터 과학의 다양한 단계를 실습하기에 매우 적합하다. 우선 탐색적 데이터 분석(EDA)을 통해 데이터를 이해하고 시각화할 수 있다. 펭귄의 종별 부리 길이와 깊이의 분포, 성별에 따른 플리퍼 길이의 차이 등을 살펴볼 수 있다. 이 과정에서 통계학의 기본 개념인 중심 경향성, 변동성, 상관관계 등이 활용된다.
다음으로 연구 질문에 답하기 위한 통계 모형을 구축할 수 있다. 예를 들어, 펭귄의 종을 예측하는 분류 모형이나, 부리 길이와 깊이 간의 관계를 설명하는 회귀 모형 등을 만들어볼 수 있다. 모형의 성능을 평가하고, 가정을 진단하며, 모형을 개선해나가는 과정은 통계학과 기계학습의 중요한 원리를 학습하는 기회가 된다.
마지막으로 분석 결과를 시각화하고 소통하는 방법을 익힐 수 있다. 데이터로부터 얻은 인사이트를 효과적으로 전달하는 것은 데이터 과학자의 핵심 역량 중 하나이다. palmerpenguins 데이터셋을 활용한 분석 결과를 정리하고, 시각화하여 발표해보는 경험은 이 역량을 기르는 데 큰 도움이 될 것이다.
이처럼 Palmer 군도의 펭귄 데이터는 데이터가 수집되는 현장부터, 데이터 정제 및 가공, 분석, 시각화, 소통에 이르기까지 데이터 과학의 전 과정을 체험할 수 있는 좋은 예시이다. 실제 데이터를 다루며 통계학과 데이터 과학의 원리를 적용해보는 경험은, 데이터 과학자로서의 역량을 키우는 데 있어 매우 값지고 유익할 것이다.
2.4.1 데이터 가져오기
줄리앙 브룬 박사 작업한 코드를 통해 펭귄 데이터를 환경 데이터 협의회(Environmental Data Initiative, EDI)로부터 원본 데이터를 직접 가져올 수도 있다.
하지만, 아스키 형태 펭귄 데이터를 정제하여 R 패키지로 만들어놓은 palmerpenguins 패키지를 활용하면 더 쉽게 데이터를 가져올 수 있다. 팔머 군도에서 수집된 펭귄 데이터를 R 패키지 palmerpenguins를 remotes install_github() 함수로 GitHub 저장소에서 펭귄 데이터를 설치한다. dplyr 패키지 glimpse() 함수로 펭귄 데이터를 일별한다. 총 344개 행과 8개 열로 구성된 펭귄 데이터셋을 확인할 수 있다.