19 확률과 통계
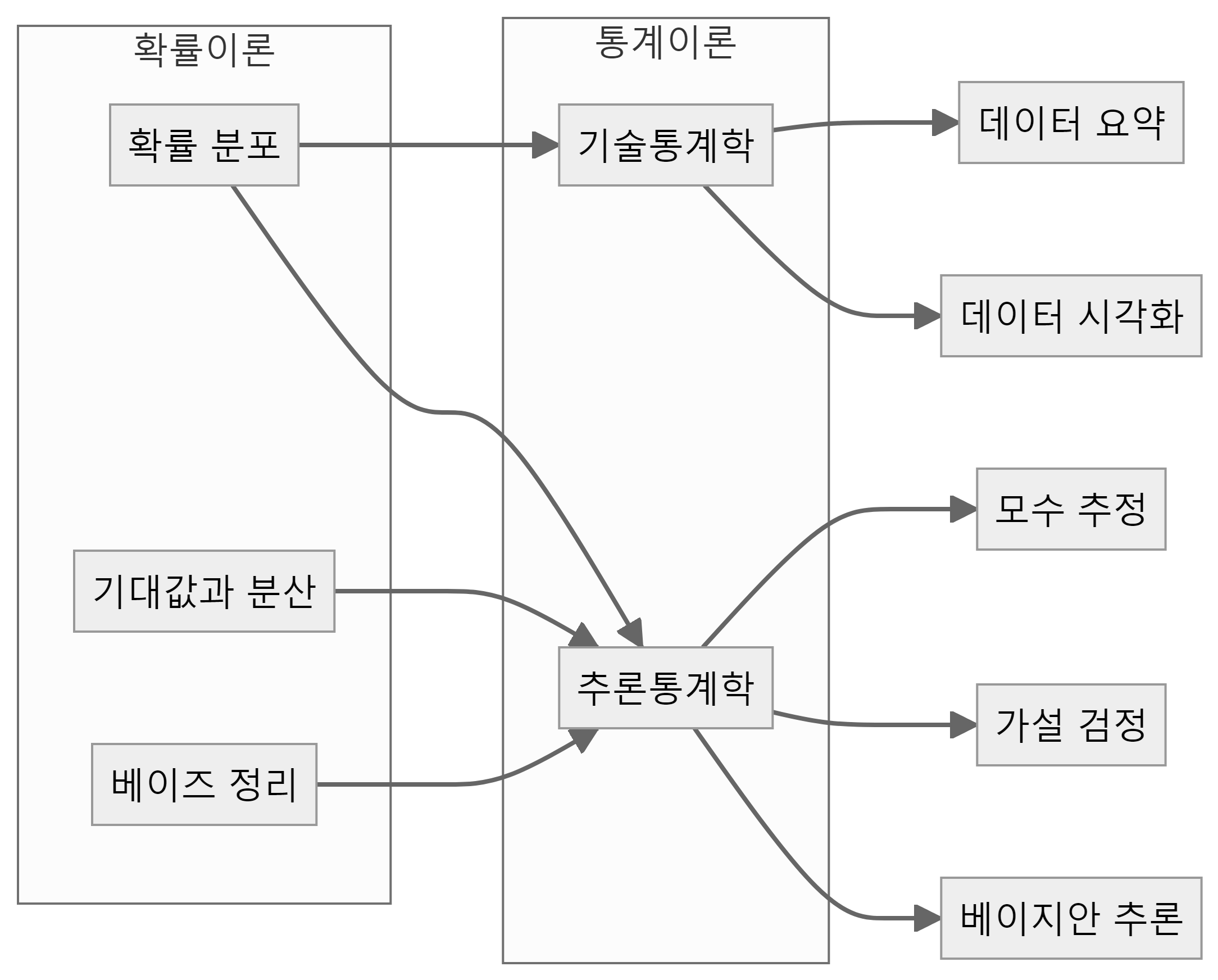
확률 이론과 통계학은 밀접한 관련성을 가진다. 확률 이론은 데이터의 불확실성을 정량화하고 모형화하는 기반을 제공하며, 통계학은 이를 실제 데이터 분석에 적용한다. 확률 이론의 핵심 개념인 확률 분포, 기대값, 분산, 베이즈 정리 등은 통계학의 여러 분야에서 활용된다. 기술통계학에서 확률 분포를 사용해 데이터를 요약하고 시각화하는 반면, 추론통계학에서는 기대값과 분산을 이용해 모수를 추정하고 베이즈 정리를 통해 베이지안 추론을 수행한다.
반대로, 통계학의 개념과 방법론은 확률 모형의 개발과 평가에 활용되며, 데이터를 통해 확률 모델의 가정을 검증하고 모형 적합도를 평가한다. 또한, 통계적 기법을 사용해 확률 모형의 모수를 추정한다.
확률과 통계는 서로 영향을 주고받으며 데이터 분석의 전 과정에 걸쳐 유기적으로 작용한다. 확률 이론이 통계학의 이론적 기반을 형성하고, 통계학은 확률 이론을 실제 데이터 분석에 적용하는 방법론을 제공한다.
19.1 확률 이론
확률 이론은 불확실성을 다루는 수학의 한 분야로, 통계학과 밀접한 관련이 있다. 확률 이론은 우리 주변에서 일어나는 다양한 현상을 이해하고 예측하는 데 필수적인 도구로 사용된다. 확률론은 사건의 발생 가능성을 수학적으로 모형화하고, 이를 바탕으로 의사 결정을 내리는 데 활용될 뿐만 아니라, 통계적 추론의 기반이 되는 중요한 이론이다.
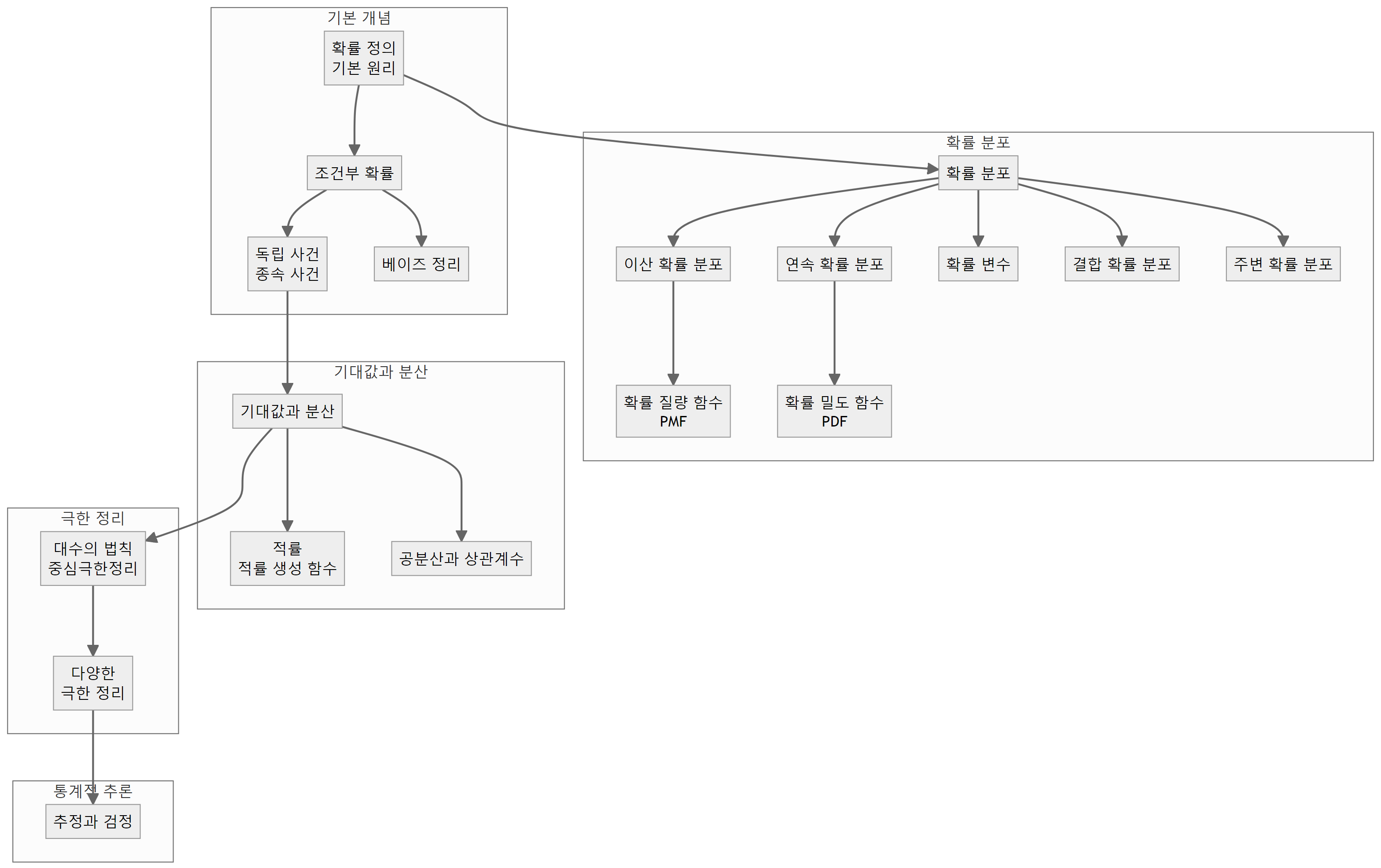
확률의 정의와 기본 원리를 이해하는 것은 매우 중요하다. 확률 이론의 토대에는 사건의 발생 가능성을 수치적으로 나타내는 방법과 확률의 공리가 포함된다. 확률의 공리를 바탕으로 조건부 확률, 독립 사건과 종속 사건, 베이즈 정리 등의 기본 개념을 학습함으로써 사건 간의 관계를 파악하고, 주어진 정보를 토대로 확률을 갱신할 수 있게 된다.
확률 분포는 확률 변수의 가능한 값과 그에 대응하는 확률을 나타내는 함수이다. 확률 분포는 이산 확률 분포와 연속 확률 분포로 나뉘며, 각각 확률 질량 함수(PMF)와 확률 밀도 함수(PDF)로 표현된다. 결합 확률 분포와 주변 확률 분포의 개념을 이해하면 여러 확률 변수 간의 관계를 파악할 수 있다.
확률 개념과 확률 분포를 기반으로, 기대값과 분산, 적률과 적률 생성 함수, 공분산과 상관계수 등의 개념으로 확장할 수 있다. 이러한 개념들은 확률 분포의 특성을 요약하고, 확률 변수 간의 관계를 정량화하는 데 유용하게 사용된다. 특히, 기대값과 분산은 확률 분포의 위치와 퍼짐을 나타내는 핵심적인 척도다.
확률 이론의 중요한 축 중 하나는 극한 정리이다. 대수의 법칙은 독립적인 시행을 반복할 때, 표본 평균이 모평균에 수렴함을 보여주며, 중심극한정리는 독립적인 확률 변수의 합이 정규 분포에 근사함을 증명한다. 이러한 극한 정리는 확률 변수의 장기적인 행동을 이해하고, 실제 데이터 분석에 활용되는 통계적 방법의 견고한 이론적 토대를 제공한다.
확률 이론은 통계적 추론의 기반이 된다. 추정은 표본 데이터를 사용하여 모집단의 특성을 추론하는 과정이고, 검정은 가설의 타당성을 확률을 통해 판단하는 과정이다. 이러한 통계적 추론 방법은 실제 데이터 분석에서 널리 활용되며, 그 근간에는 확률 이론의 개념과 정리가 자리 잡고 있다.
19.2 확률 기초
확률의 고전적 정의는 17세기와 18세기의 수학자들에 의해 발전되었고 간단하고 직관적이다. 대표적으로 라플라스 확률론적 접근은 ‘고전 확률론’으로도 불리며, 특정한 확률 공간 내에서 모든 원소가 동일한 확률로 발생한다는 가정을 기반으로 한다. 라플라스의 확률론은 간단하고 이상적인 상황, 특히 가능한 모든 결과가 명확하게 정의되고, 그 결과들이 ’균등하게 가능한’ 경우에 적합하다. 즉, 각 결과가 ‘균등하게 가능한’ 상황에서만 유효하다.
\[ P(A) = \frac{\text{사건 } A \text{에 속하는 기본 사건의 수}}{\text{모든 가능한 기본 사건의 총수}} \]
- \(P(A)\)는 사건 \(A\)의 확률이다.
- 분자는 사건 \(A\)를 구성하는 원소의 개수다.
- 분모는 전체 표본공간 \(S\) 내의 모든 원소의 개수다.
특정 사건 \(A\)가 발생할 확률 \(P(A)\)를 전체 가능한 사건의 수로 나눈 사건 \(A\)가 발생하는 경우의 수로 정의된다. 예를 들어, 공정한 동전 던지기에서 앞면이 나올 확률은 전체 가능한 사건(앞면, 뒷면) 2개 중에서 앞면이 나오는 경우 1로, \(P(\text{앞면}) = \frac{1}{2}\)이 된다.
라플라스 확률 정의는 모든 결과가 동일한 확률을 가질 때만 적용 가능하다는 한계를 갖는다. 비균등 확률이 필요한 상황이나, 결과의 개수를 쉽게 셀 수 없는 복잡한 확률 공간에서는 적용하기 어렵다. 또한, 연속 확률 공간에서는 적합하지 않기 때문에 현대 확률 이론은 콜모고로프의 확률 공리를 기반으로 발전하였다.
콜모고로프 확률 공리
콜모고로프의 확률 공리는 다음 세 가지 기본 원칙에 근거한다.
비음성(Non-negativity): 모든 사건 \(A\)에 대해, 확률은 음수가 아니어야 한다. \[ P(A) \geq 0 \]
정규화(Normalization): 전체 표본 공간에 대한 확률은 1 이다. \[ P(\text{전체 표본 공간}) = 1 \]
가산가법성(Additivity): 서로 배타적인 사건들 \(A, B\) 에 대해, 합집합의 확률은 각 사건의 확률의 합과 같다.
\[ P(A \cup B) = P(A) + P(B), \quad \text{if } A \cap B = \emptyset \]
- \(A\)와 \(B\)는 서로 겹치지 않는(상호 배타적인) 사건이다.
- \(A \cup B\)는 사건 \(A\) 또는 \(B\)가 발생하는 것을 의미한다.
- \(P(A) + P(B)\)는 사건 \(A\)가 발생할 확률과 사건 \(B\)가 발생할 확률의 합이다.
- \(A \cap B = \emptyset\)는 사건 \(A\)와 \(B\)가 동시에 발생할 수 없다는 것을 의미한다.
#| label: fig-shinylive-prob
#| viewerHeight: 700
#| standalone: true
# source("shiny/definition/app.R")
library(shiny)
library(ggplot2)
library(dplyr)
# 사용자 인터페이스
ui <- fluidPage(
titlePanel("주사위 던지기와 확률 계산"),
sidebarLayout(
sidebarPanel(
checkboxGroupInput("event", "사건 선택:",
choices = list("1" = 1, "2" = 2, "3" = 3,
"4" = 4, "5" = 5, "6" = 6),
selected = 1, inline = TRUE),
verbatimTextOutput("probability"),
verbatimTextOutput("event_count") # 선택된 사건에 대한 주사위 눈의 수 출력
),
mainPanel(
plotOutput("plot")
)
)
)
# 서버 로직
server <- function(input, output) {
output$plot <- renderPlot({
sample_space <- 1:6
event <- as.numeric(input$event)
data <- data.frame(number = sample_space,
event = sample_space %in% event) %>%
mutate(event = ifelse(event, "나옴", "안나옴"))
ggplot(data, aes(x = number, y = event, fill = event)) +
geom_point(shape = 21, size = 20) +
scale_fill_manual(values = c("안나옴" = "grey", "나옴" = "blue")) +
scale_y_discrete(labels = c("안나옴", "나옴"), limits = c("안나옴", "나옴")) +
scale_x_continuous(breaks = 1:6) +
labs(title = "주사위 던지기 사건 시각화",
x = "주사위 면",
y = "사건 포함 여부",
fill = "사건결과") +
theme_minimal() +
theme(legend.position = "top")
})
output$event_count <- renderText({
event <- as.numeric(input$event)
paste("나온 주사위 눈의 수:", length(event),
"/", "전체 주사위 눈의 수:", length(1:6))
})
output$probability <- renderText({
event <- as.numeric(input$event)
prob <- length(event) / 6
paste("선택한 사건의 확률:", round(prob * 100, 1), "%")
})
}
# 앱 실행
shinyApp(ui = ui, server = server)
19.3 확률 법칙
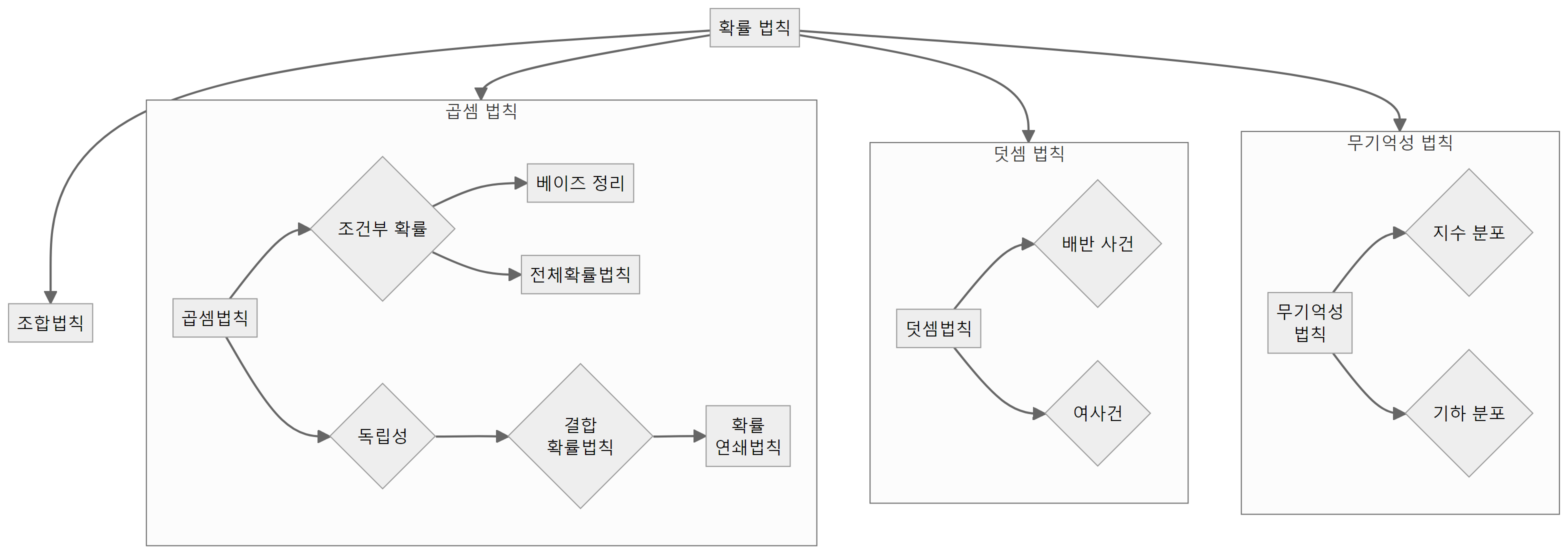
확률 법칙은 확률 이론의 핵심으로, 확률을 계산하고 해석하는 데 필수적인 도구들을 제공한다. 확률 법칙들은 복잡한 확률 문제를 체계적으로 해결할 수 있는 기반을 마련해 주며, 실제 응용 분야에서 널리 활용된다.
확률의 법칙은 크게 곱셈법칙, 덧셈법칙, 전체확률법칙, 베이즈 정리 등으로 구성된다. 이 법칙들은 각각 확률을 계산하는 데 사용되는 기본적인 규칙들을 제공하며, 서로 밀접하게 연관되어 있다.
가장 기본적인 확률 법칙 중 하나는 곱셈법칙이다. 곱셈법칙은 두 사건 A와 B가 동시에 일어날 확률을 계산하는 데 사용된다. \(P(B|A)\)는 사건 A가 주어졌을 때 사건 B의 조건부 확률을 의미하며 수학적으로는 다음과 같이 표현된다.
\[P(A \cap B) = P(A) \times P(B|A)\]
만약 두 사건 A와 B가 독립 사건이라면, 곱셈법칙은 다음과 같이 간단해진다.
\[P(A \cap B) = P(A) \times P(B)\]
또 다른 확률 법칙은 덧셈법칙이다. 덧셈법칙은 두 사건 A와 B 중 적어도 하나가 일어날 확률을 계산하는 데 사용되는데 수학적으로는 다음과 같이 표현된다.
\[P(A \cup B) = P(A) + P(B) - P(A \cap B)\]
만약 두 사건 A와 B가 서로 배반 사건이라면, 즉 동시에 일어날 수 없는 사건이라면, 덧셈법칙은 다음과 같이 간단해진다.
\[P(A \cup B) = P(A) + P(B)\]
전체확률법칙은 사건 B의 확률을 구할 때, 사건 B를 여러 개의 서로 배반인 사건으로 분할하여 계산하는 방법으로 수학적으로는 다음과 같이 표현된다.
\[P(B) = \sum_{i=1}^{n} P(B|A_i) \times P(A_i)\]
\(A_1, A_2, ..., A_n\)은 서로 배반이면서 전체 사건의 합집합은 표본공간이 되는 사건들이다.
베이즈 정리는 전체확률법칙을 활용하여 사건의 원인을 추론하는 데 사용되는 중요한 법칙이다. 베이즈 정리는 사전확률과 우도를 결합하여 사후확률을 계산한다. 수학적으로는 다음과 같이 표현된다.
\[P(A|B) = \frac{P(B|A) \times P(A)}{P(B)}\]
확률의 기본 법칙에는 덧셈법칙과 곱셈법칙이 있지만, 뺄셈법칙이나 나눗셈법칙은 별도로 존재하지 않는다. 확률은 항상 0과 1 사이의 값을 갖는 것으로 정의된다. 따라서 두 확률을 더하거나 곱했을 때 그 결과가 여전히 0과 1 사이의 값을 갖는 확률로 해석될 수 있어야 하지만, 두 확률을 빼거나 나누면 그 결과가 0보다 작거나 1보다 클 수 있어 확률의 정의에 어긋나게 된다.
덧셈법칙은 두 사건의 합집합 확률을 구하는 데 사용된다. 만약 뺄셈법칙이 필요하다면, 여사건의 개념을 사용하여 덧셈법칙으로 대체할 수 있다. 예를 들어, \(P(A - B) = P(A \cap B^c) = P(A) - P(A \cap B)\)와 같이 표현할 수 있다.
곱셈법칙은 두 사건의 교집합의 확률을 구하는 데 사용되며, 조건부 확률과 밀접한 관련이 있다. 나눗셈법칙이 필요한 경우, 조건부 확률의 정의를 사용하여 곱셈법칙을 활용할 수 있다. 예를 들어, \(P(A|B) = \frac{P(A \cap B)}{P(B)}\)와 같이 표현할 수 있다. 이 과정에서 나눗셈이 사용되지만, 이는 조건부 확률의 정의에 따른 것이지 별도의 나눗셈법칙이 존재하는 것은 아니다.
독립성과 종속성의 개념은 확률 법칙에서 매우 중요한 역할을 한다. 두 사건이 독립이라면, 한 사건의 발생 여부가 다른 사건의 발생 확률에 영향을 미치지 않는다. 수학적으로 표현하면 \(P(A \cap B) = P(A) \times P(B)\)가 성립한다. 반면에 두 사건이 종속적이라면, 한 사건의 발생 여부가 다른 사건의 발생 확률에 영향을 미친다.
결합확률법칙은 곱셈법칙을 확장한 개념으로, 여러 사건이 동시에 일어날 확률을 계산하는 데 사용된다. 수학적으로는 \(P(A \cap B \cap C) = P(A) \times P(B|A) \times P(C|A \cap B)\)와 같이 표현된다.
확률 연쇄법칙은 결합확률법칙을 일반화한 것으로, 여러 사건의 결합확률을 조건부 확률의 곱으로 나타낸다. 수학적으로는 \(P(A_1 \cap A_2 \cap ... \cap A_n) = P(A_1) \times P(A_2|A_1) \times ... \times P(A_n|A_1 \cap A_2 \cap ... \cap A_{n-1})\)와 같이 표현된다.
조합법칙은 세 개 이상의 사건의 합집합의 확률을 계산할 때 사용된다. 두 개 이상의 사건이 동시에 발생하는 경우를 고려하여, 중복을 제거하는 방식으로 확률을 계산한다. 예를 들어, 세 사건 \(A\), \(B\), \(C\)의 합집합의 확률을 다음과 같이 계산할 수 있다.
\[ P(A \cup B \cup C) = P(A) + P(B) + P(C) - P(A \cap B) - P(A \cap C) - P(B \cap C) + P(A \cap B \cap C) \]
무기억성 법칙은 특정 확률 분포가 과거의 사건에 독립적이라는 특성을 나타낸다. 주로 지수 분포와 기하 분포에서 나타난다. 예를 들어, 지수 분포를 따르는 시간 \(T\)에 대해, 특정 시간 \(s\) 이후 추가로 시간 \(t\)가 소요될 확률은 \(s\)와 관계없이 항상 같다.
\[ P(T > s + t \mid T > s) = P(T > t) \]
사례: 두 개의 주사위를 던질 때, 적어도 하나의 주사위에서 6이 나올 확률을 구해보자.
문제는 덧셈법칙과 여사건의 개념을 활용하여 해결할 수 있다. 먼저, 사건을 정의합니다.
- 사건 A: 첫 번째 주사위에서 6이 나오는 경우
- 사건 B: 두 번째 주사위에서 6이 나오는 경우
구하고자 하는 확률은 \(P(A \cup B)\)으로 표현할 수 있다. 덧셈법칙에 따라 다음과 같이 쓸 수 있다.
\[P(A \cup B) = P(A) + P(B) - P(A \cap B)\]
\(P(A)\)와 \(P(B)\)는 각각 \(\frac{1}{6}\)이다. \(P(A \cap B)\)는 두 주사위에서 모두 6이 나올 확률로, \(\frac{1}{36}\)이다.
따라서,
\[P(A \cup B) = \frac{1}{6} + \frac{1}{6} - \frac{1}{36} = \frac{11}{36}\]
또는 여사건의 개념을 활용하여 다음과 같이 계산할 수도 있다.
\[P(A \cup B) = 1 - P((A \cup B)^c) = 1 - P(A^c \cap B^c)\]
\(P(A^c \cap B^c)\)는 두 주사위에서 모두 6이 나오지 않을 확률로, \(\frac{25}{36}\)이다.
따라서,
\[P(A \cup B) = 1 - \frac{25}{36} = \frac{11}{36}\]
두 가지 방법 모두 같은 결과인 \(\frac{11}{36}\)을 도출하게 된다. 두 개의 주사위를 던졌을 때 적어도 하나의 주사위에서 6이 나올 확률이 약 30.56%임을 나타낸다.
#| label: shinylive-prob-law
#| viewerHeight: 600
#| standalone: true
library(shiny)
ui <- fluidPage(
titlePanel("확률 법칙 계산"),
sidebarLayout(
sidebarPanel(
h3("설명"),
p("선택한 확률 법칙에 따라 확률을 계산합니다."),
p("먼저 확률 법칙을 선택한 후, 해당 법칙에 필요한 확률 값을 슬라이더로 입력하세요."),
p("계산 결과는 우측 패널에 출력됩니다."),
br(),
selectInput("law", "확률 법칙 선택:",
choices = c("덧셈법칙", "곱셈법칙", "베이즈 정리")),
conditionalPanel(
condition = "input.law == '덧셈법칙'",
sliderInput("prob_a_add", "사건 A의 확률:", min = 0, max = 1, value = 0.5, step = 0.01),
sliderInput("prob_b_add", "사건 B의 확률:", min = 0, max = 1, value = 0.5, step = 0.01),
sliderInput("prob_a_and_b_add", "사건 A와 B의 교집합 확률:", min = 0, max = 1, value = 0.2, step = 0.01)
),
conditionalPanel(
condition = "input.law == '곱셈법칙'",
sliderInput("prob_a_mult", "사건 A의 확률:", min = 0, max = 1, value = 0.5, step = 0.01),
sliderInput("prob_b_given_a_mult", "사건 A가 주어졌을 때 사건 B의 조건부 확률:", min = 0, max = 1, value = 0.5, step = 0.01)
),
conditionalPanel(
condition = "input.law == '베이즈 정리'",
sliderInput("prob_a_bayes", "사건 A의 사전확률:", min = 0, max = 1, value = 0.2, step = 0.01),
sliderInput("prob_b_given_a_bayes", "사건 A가 주어졌을 때 사건 B의 조건부 확률:", min = 0, max = 1, value = 0.8, step = 0.01),
sliderInput("prob_b_bayes", "사건 B의 주변확률:", min = 0, max = 1, value = 0.3, step = 0.01)
)
),
mainPanel(
h3("확률 계산 결과:"),
verbatimTextOutput("result")
)
)
)
server <- function(input, output) {
output$result <- renderText({
if (input$law == "덧셈법칙") {
prob_a <- input$prob_a_add
prob_b <- input$prob_b_add
prob_a_and_b <- input$prob_a_and_b_add
prob_a_or_b <- prob_a + prob_b - prob_a_and_b
paste("P(A ∪ B) = P(A) + P(B) - P(A ∩ B) =", round(prob_a_or_b, 4))
} else if (input$law == "곱셈법칙") {
prob_a <- input$prob_a_mult
prob_b_given_a <- input$prob_b_given_a_mult
prob_a_and_b <- prob_a * prob_b_given_a
paste("P(A ∩ B) = P(A) × P(B|A) =", round(prob_a_and_b, 4))
} else if (input$law == "베이즈 정리") {
prob_a <- input$prob_a_bayes
prob_b_given_a <- input$prob_b_given_a_bayes
prob_b <- input$prob_b_bayes
prob_a_given_b <- (prob_b_given_a * prob_a) / prob_b
paste("P(A|B) = (P(B|A) × P(A)) / P(B) =", round(prob_a_given_b, 4))
}
})
}
shinyApp(ui = ui, server = server)