#> [1] 0.990147516 상관분석
상관분석은 두 변수 간의 선형적 관계를 측정하고 분석하는 통계적 기법으로, 상관분석 역사는 19세기 후반으로 거슬러 올라가며, 영국의 통계학자 프란시스 갈턴(Francis Galton)이 부모의 키와 자녀의 키 사이의 관계를 연구하면서 시작되었다. 갈턴은 이 연구를 통해 회귀분석(regression analysis)의 개념을 도입했고, 상관분석의 기초를 만들었다.
상관분석에서 상관계수(correlation coefficient)를 사용하여 두 변수 간의 선형적 관계의 강도와 방향을 측정한다. 가장 널리 사용되는 상관계수는 피어슨 상관계수(Pearson correlation coefficient)로, 다음과 같은 수식으로 정의된다.
\[r = \frac{\sum_{i=1}^{n} (x_i - \bar{x})(y_i - \bar{y})}{\sqrt{\sum_{i=1}^{n} (x_i - \bar{x})^2} \sqrt{\sum_{i=1}^{n} (y_i - \bar{y})^2}}\]
\(x_i\)와 \(y_i\)는 i번째 관측치의 두 변수 값, \(\bar{x}\)와 \(\bar{y}\)는 각 변수의 평균, \(n\)은 관측점 개수다.
상관계수는 -1에서 1 사이의 값을 가지며, 양수이면 양의 상관관계, 음수이면 음의 상관관계를 나타내며, 상관계수의 절댓값이 클수록 두 변수 간의 선형적 관계가 강함을 의미하고, 상관계수가 0이면 두 변수 간에 선형적 관계가 없음을 나타낸다.
상관분석을 통해서 두 변수 간의 선형적 관계의 강도와 방향을 파악할 수 있고, 두 변수 간의 관계가 우연히 발생한 것인지 아니면 실제로 유의미한 관계인지를 통계적 검정을 통해 확인할 수 있다. 상관분석은 또한 다중 회귀분석 등 다양한 통계 기법에 활용될 수 있으며, 데이터 탐색과 이해에 중요한 도구로 활용된다.
R 코드로 두 변수 \(x\)와 \(y\) 간의 피어슨 상관계수를 계산한다. 상관계수는 cor() 함수를 사용하여 쉽게 계산할 수 있다.
#> term 부리_길이 부리_깊이 물갈퀴_길이 체중
#> 1 부리_길이 -.23 .65 .59
#> 2 부리_깊이 -.23 -.58 -.47
#> 3 물갈퀴_길이 .65 -.58 .87
#> 4 체중 .59 -.47 .87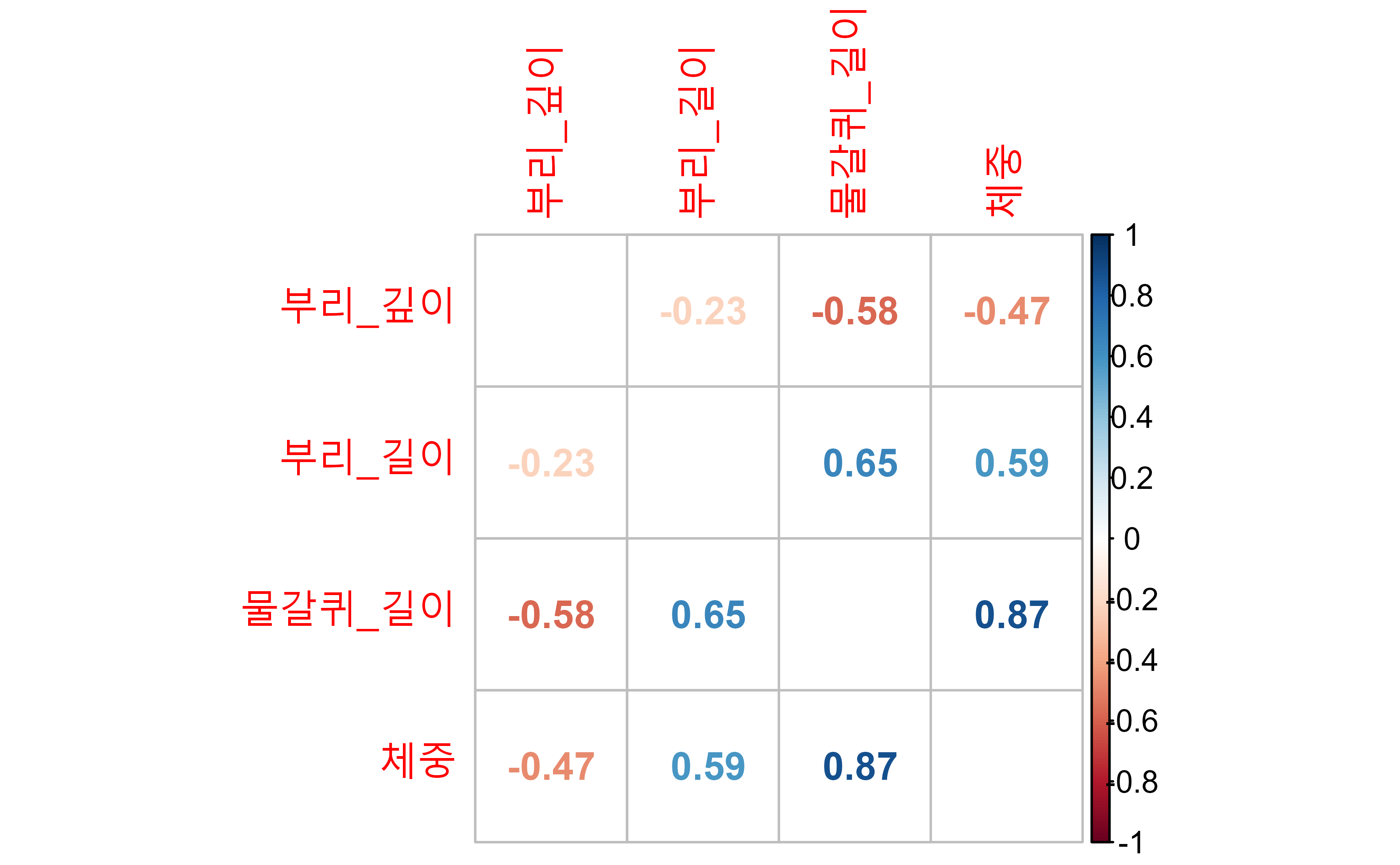
16.1 앤스콤 사중주
앤스콤(Anscombe, 1973)은 1973년 앤스콤 사중주(Anscombe’s Quartet)로 알려진 동일한 통계량을 갖는 4종류 데이터셋을 만들어서 시각화의 중요성을 일깨웠다. 앤스콤 데이터셋은 평균, 분산, 상관계수, 회귀직선 등 주요 통계치가 매우 유사한 4쌍의 데이터로 구성되어 있다. 그러나 이 데이터들을 그래프로 시각화했을 때 서로 완전히 다른 패턴과 관계성을 보여준다.
단순히 숫자로 요약된 통계만으로는 데이터의 특성을 제대로 파악하기 어려울 수 있다는 점을 시사하는 것으로, 데이터를 시각적으로 표현함으로써 숨겨진 패턴, 이상치, 추세 등을 직관적으로 발견할 수 있다. 두 변수 x, y에 대한 통계량에 대한 정보는 다음과 같다.
| 통계량 | 값 |
|---|---|
평균(x) |
9 |
분산(x) |
11 |
평균(y) |
7.5 |
분산(y) |
4.1 |
| 상관계수 | 0.82 |
| 회귀식 | \(y = 3.0 + 0.5 \times x\) |
16.1.1 데이터셋 기술통계량
datasets 패키지 내부에 anscombe 명칭으로 데이터셋이 포함되어 있어 앞서 제기한 기술통계량이 맞는지 평균, 분산, 상관계수, 회귀식 회귀계수를 통해 소수점 아래 일부 차이가 있지만 동일하다는 것을 확인할 수 있다.
16.1.2 데이터셋 시각화
anscombe 데이터셋 기술 통계량을 통해 4종류 데이터셋이 동일한 분포를 갖고 있고 표본추출로 보면 모집단에서 잘 추출된 표본이라고 볼 수도 있으나 시각화를 통해 보면 전혀 다른 특성을 갖는 데이터라는 것을 한번에 알 수 있다. 즉, 가장 일반적으로 첫 번째 데이터셋과 같은 특성이 기술통계량을 통해 존재한다는 것이 일반적이다. 하지만, 2차식이 내재된 두 변수의 관계(두 번째 데이터셋)일 수도 있으며, 강한 선형 관계가 두 변수 사이에 존재하지만 튀는 관측점이 하나 존재하는 관계(세 번째 데이터셋)일 수도 있으며, 네 번째 데이터셋의 경우 데이터 입력 과정에서 오류가 의심되는 경우일 수도 있다.
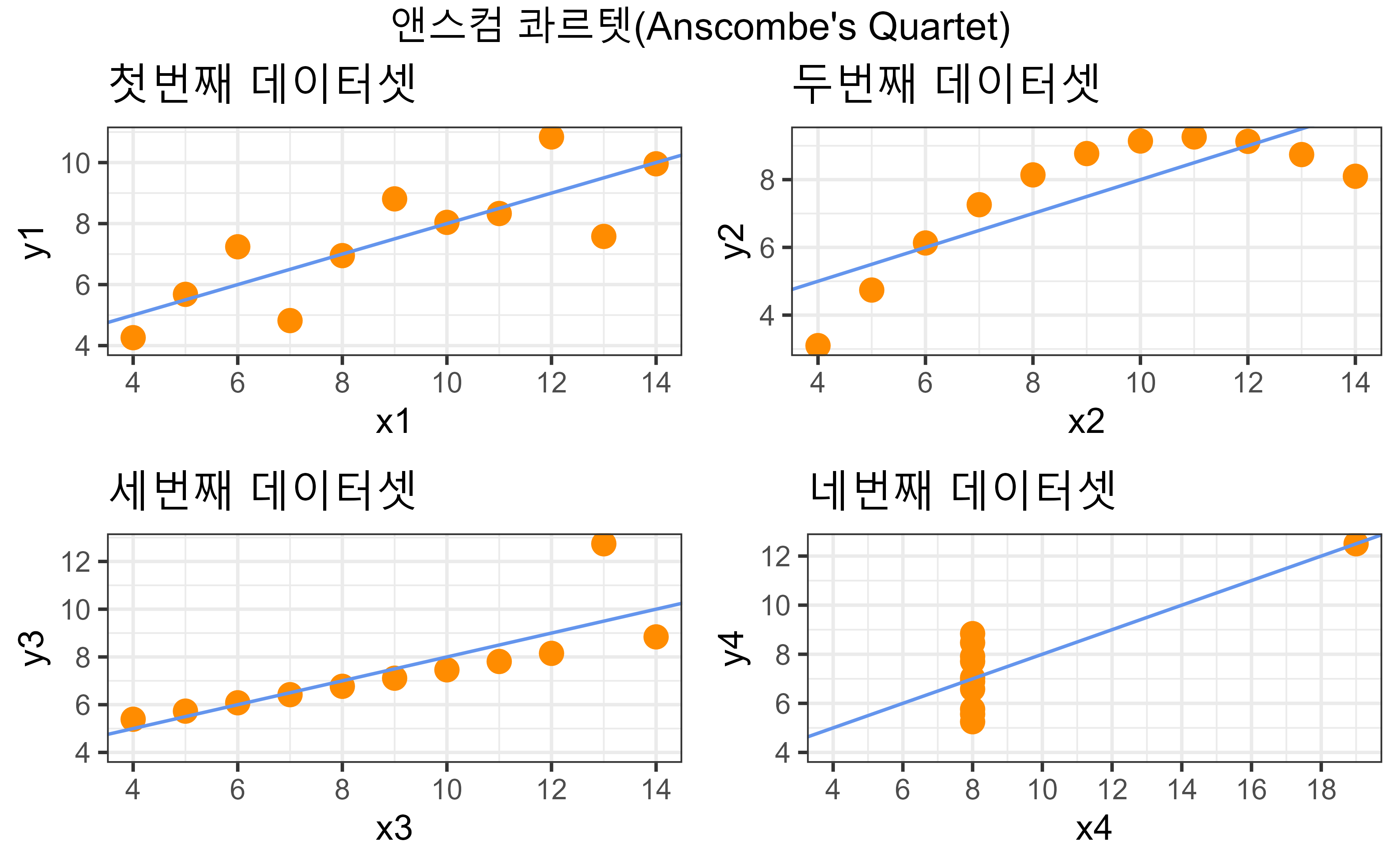
앤스콤 데이터셋은 데이터 시각화의 중요성을 강조하는 대표적인 사례이다. 시각화는 데이터를 이해하고 통찰력을 얻는 데 매우 중요한 도구로 요약 통계량 상관계수, 평균 등 숫자가 담아내지 못한 중요한 정보를 제공한다.
16.2 공룡 데이터
데이터 분석에서 시각화의 중요성은 아무리 강조해도 지나치지 않는다. 상관계수와 같은 요약 통계량은 데이터의 전반적인 경향을 파악하는 데 도움이 되지만, 데이터의 세부 패턴이나 특이점을 놓칠 수 있기 때문이다.
이를 극명하게 보여주는 사례가 바로 공룡 데이터(Datasaurus)다. 공룡 데이터는 평균, 표준편차, 상관계수 등의 요약 통계량이 거의 동일함에도 불구하고, 그래프로 시각화했을 때는 전혀 다른 모습을 보여주는 가상 데이터로 요약 통계량만으로는 데이터의 실제 분포나 패턴을 파악하기 어렵다는 것을 의미한다.
공룡 데이터는 앨버트 카이로(Alberto Cairo)가 만든 DrawMyData 웹사이트에서 처음 소개되었고, 이후 Justin Matejka와 George Fitzmaurice의 논문(Matejka & Fitzmaurice, 2017)을 통해 널리 알려졌다. 이들의 연구는 데이터 과학 커뮤니티에 큰 영향을 미쳤으며, 이를 바탕으로 datasauRus R 데이터 패키지도 개발되어 공룡 데이터를 쉽게 사용할 수 있게 되었다.
공룡 데이터와 앤스콤 사중주 데이터는 단순히 재미있는 시각화 사례를 넘어, 데이터 분석에서 시각화의 중요성을 일깨우는 상징적인 존재가 되었다. 데이터를 그래프로 그려보는 것은 데이터를 이해하고 통찰을 얻는 데 필수적인 과정으로, 특히 상관계수와 같은 요약 통계량은 데이터의 전체적인 경향을 파악하는 데 유용하지만, 데이터의 세부 패턴이나 특이점을 발견하기 위해서는 반드시 시각화가 동반되어야 한다.
#> # A tibble: 13 × 6
#> dataset mean_x mean_y std_dev_x std_dev_y corr_x_y
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 away 54.3 47.8 16.8 26.9 -0.0641
#> 2 bullseye 54.3 47.8 16.8 26.9 -0.0686
#> 3 circle 54.3 47.8 16.8 26.9 -0.0683
#> 4 dino 54.3 47.8 16.8 26.9 -0.0645
#> 5 dots 54.3 47.8 16.8 26.9 -0.0603
#> 6 h_lines 54.3 47.8 16.8 26.9 -0.0617
#> 7 high_lines 54.3 47.8 16.8 26.9 -0.0685
#> 8 slant_down 54.3 47.8 16.8 26.9 -0.0690
#> 9 slant_up 54.3 47.8 16.8 26.9 -0.0686
#> 10 star 54.3 47.8 16.8 26.9 -0.0630
#> 11 v_lines 54.3 47.8 16.8 26.9 -0.0694
#> 12 wide_lines 54.3 47.8 16.8 26.9 -0.0666
#> 13 x_shape 54.3 47.8 16.8 26.9 -0.0656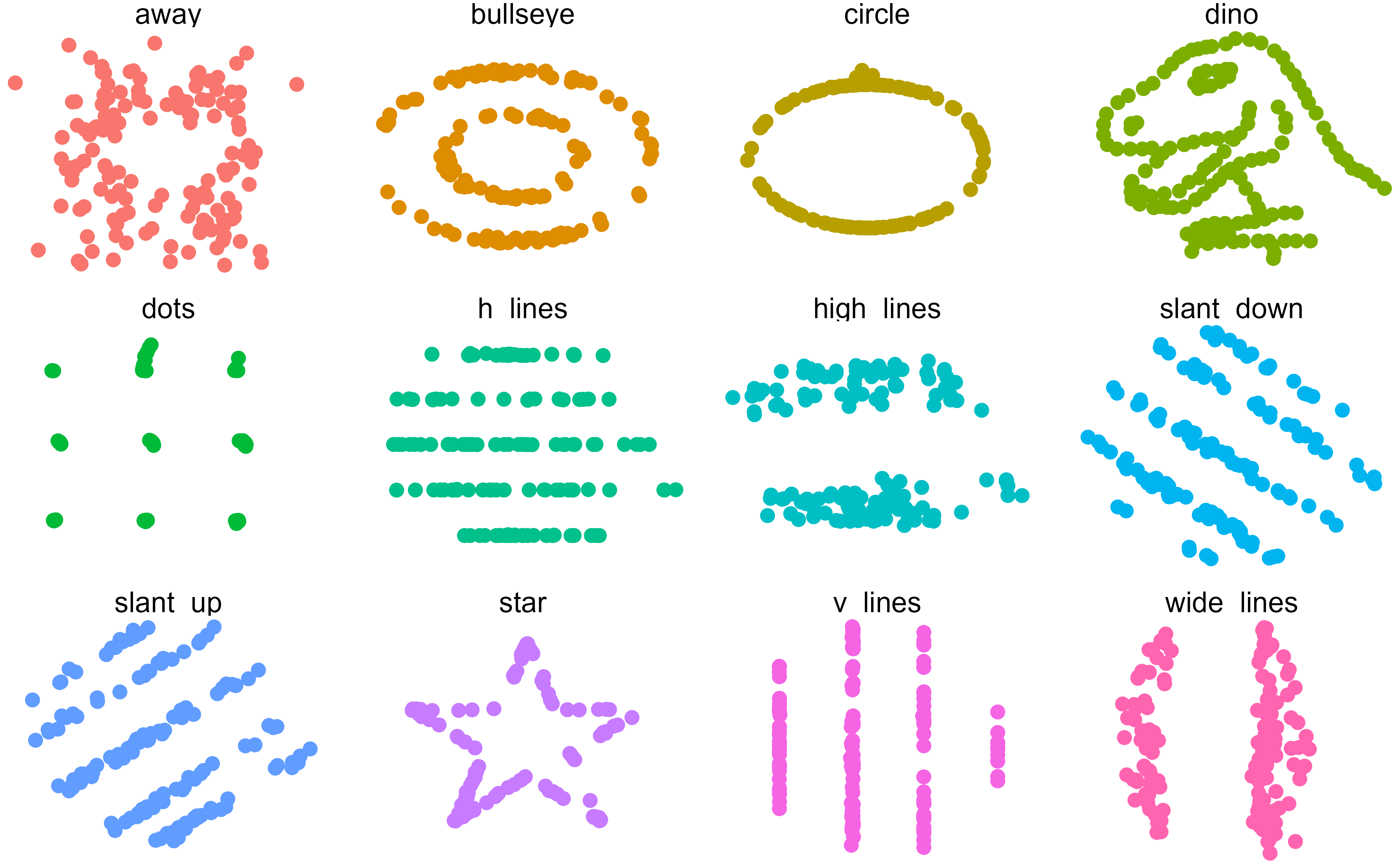
16.3 shiny 앱
#| label: shinylive-anscombe-datasaurus
#| viewerHeight: 600
#| standalone: true
library(shiny)
library(ggplot2)
library(dplyr)
library(datasets)
library(datasauRus)
# UI 정의
ui <- fluidPage(
titlePanel("시각화 중요성: 앤스콤 사중주와 공룡 데이터"),
sidebarLayout(
sidebarPanel(
p("앤스콤 사중주와 공룡 데이터는 유사한 요약 통계량과 상관계수를 가지고 있지만, 시각화했을 때 큰 차이를 보입니다."),
hr(),
h4("데이터셋 선택"),
radioButtons("dataset", "데이터셋을 선택하세요:",
choices = c("앤스콤 사중주" = "anscombe", "공룡 데이터" = "datasaurus"),
selected = "anscombe",
inline = TRUE),
hr(),
conditionalPanel(
condition = "input.dataset == 'anscombe'",
h4("변수 선택 (앤스콤 사중주)"),
selectInput("anscombe_var", "변수 쌍을 선택하세요:",
choices = c("그룹 1" = "1", "그룹 2" = "2", "그룹 3" = "3", "그룹 4" = "4"),
selected = "1")
),
conditionalPanel(
condition = "input.dataset == 'datasaurus'",
h4("데이터셋 선택 (공룡 데이터)"),
selectInput("dino_dataset", "데이터셋을 선택하세요:",
choices = unique(datasaurus_dozen$dataset),
selected = "dino")
)
),
mainPanel(
tabsetPanel(
tabPanel("요약 통계량",
verbatimTextOutput("summary_stats")),
tabPanel("상관계수",
verbatimTextOutput("corr_coef")),
tabPanel("시각화",
plotOutput("data_plot"))
)
)
)
)
# 서버 로직 정의
server <- function(input, output) {
# 선택된 데이터셋 불러오기
selected_data <- reactive({
if (input$dataset == "anscombe") {
anscombe[, c(as.numeric(input$anscombe_var), as.numeric(input$anscombe_var) + 4)]
} else {
datasaurus_dozen %>%
filter(dataset == input$dino_dataset) %>%
select(x, y)
}
})
# 요약 통계량 출력
output$summary_stats <- renderPrint({
summary(selected_data())
})
# 상관계수 출력
output$corr_coef <- renderPrint({
if (input$dataset == "anscombe") {
cor(selected_data()[, 1], selected_data()[, 2])
} else {
cor(selected_data()$x, selected_data()$y)
}
})
# 시각화
output$data_plot <- renderPlot({
if (input$dataset == "anscombe") {
ggplot(selected_data(), aes(x = selected_data()[, 1], y = selected_data()[, 2])) +
geom_point(size = 3, color = "steelblue") +
geom_smooth(method = "lm", se = FALSE, color = "red", linetype = "dashed") +
theme_minimal() +
labs(title = paste("앤스콤 사중주 - 그룹", input$anscombe_var),
x = "x", y = "y")
} else {
ggplot(selected_data(), aes(x = x, y = y)) +
geom_point(size = 3, color = "darkorange") +
geom_smooth(method = "lm", se = FALSE, color = "darkgreen", linetype = "dashed") +
theme_minimal() +
labs(title = paste("공룡 데이터 -", input$dino_dataset),
x = "x", y = "y")
}
})
}
# 앱 실행
shinyApp(ui, server)
16.4 상관분석 - 펭귄
16.5 shiny 앱
#| label: shinylive-correlation
#| viewerHeight: 600
#| standalone: true
library(shiny)
library(dplyr)
library(corrplot)
# 데이터 불러오기
k_penguins <- read_rds("k_penguins.rds")
# UI 정의
ui <- fluidPage(
titlePanel("펭귄 데이터셋 상관관계 분석"),
sidebarLayout(
sidebarPanel(
h3("변수 선택"),
checkboxGroupInput("variables", "분석할 변수를 선택하세요:",
choices = c("부리_길이", "부리_깊이", "물갈퀴_길이", "체중"),
selected = c("부리_길이", "부리_깊이", "물갈퀴_길이", "체중")),
hr(),
h3("상관계수 행렬 옵션"),
radioButtons("corr_type", "행렬 유형:",
choices = c("전체 행렬" = "full", "상삼각행렬" = "upper", "하삼각행렬" = "lower"),
selected = "lower"),
hr(),
h3("펭귄 종 선택"),
checkboxGroupInput("species", "분석할 펭귄 종을 선택하세요:",
choices = unique(k_penguins$종명칭),
selected = unique(k_penguins$종명칭)),
hr(),
h3("사용 방법"),
p("1. 분석할 변수와 펭귄 종을 선택하세요."),
p("2. 상관계수 행렬의 유형을 선택하세요."),
p("3. 선택한 옵션에 따라 생성된 상관계수 행렬과 시각화 결과를 확인하세요.")
),
mainPanel(
h3("상관계수 행렬"),
verbatimTextOutput("corr_matrix"),
h3("상관계수 행렬 시각화"),
plotOutput("corr_plot", width = "100%", height = "400px")
)
)
)
# 서버 로직 정의
server <- function(input, output) {
# 선택된 변수와 펭귄 종으로 데이터 필터링
penguins_selected <- reactive({
k_penguins %>%
filter(종명칭 %in% input$species) %>%
select(input$variables) %>%
drop_na()
})
# 상관계수 행렬 계산
corr_matrix <- reactive({
cor(penguins_selected())
})
# 상관계수 행렬 출력
output$corr_matrix <- renderPrint({
corr_matrix()
})
# 상관계수 행렬 시각화
output$corr_plot <- renderPlot({
corrplot(corr_matrix(), method = "color", type = input$corr_type,
tl.col = "black", tl.srt = 45, addCoef.col = "black", number.cex = 0.7,
mar = c(0,0,1,0), title = "상관계수 행렬",
col = colorRampPalette(c("#67001F", "#B2182B", "#D6604D", "#F4A582", "#FDDBC7",
"#FFFFFF", "#D1E5F0", "#92C5DE", "#4393C3", "#2166AC", "#053061"))(200))
})
}
# 앱 실행
shinyApp(ui, server)