9 표본추출방법
거의 모든 통계적 방법은 암묵적 무작위성 개념에 기초하고 있다. 만약 데이터가 모집단으로부터 무작위 구조 아래에서 수집되지 않는다면, 통계적 방법 – 추정값과 추정값과 연관된 오차 – 은 신뢰할 수 없다. 여기서 통계에서 가장 기본이 되는 4가지 무작위 표본 추출 기법(단순 표집, 층화 표집, 군집 표집, 다단계 표집)을 살펴보자.
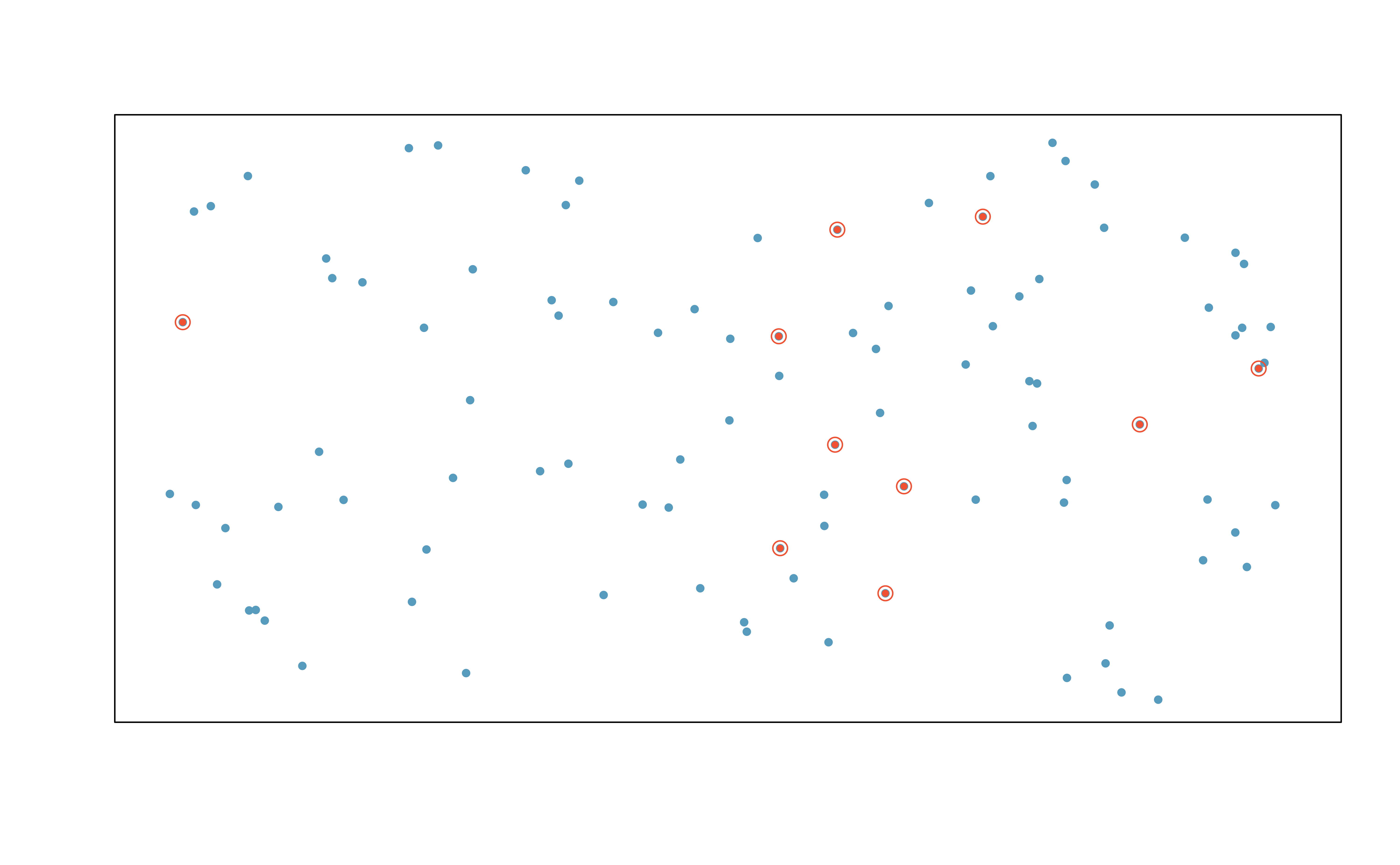
9.1 단순 임의 표본 추출
단순 임의 표본 추출은 무작위로 표본을 선정하는 가장 기본적인 방법이다. 예를 들어, 344마리의 펭귄으로 이루어진 팔머 펭귄 데이터셋에서 120마리의 펭귄을 뽑아 몸무게를 조사하고 싶다고 가정해 보자.
이때, 제비뽑기함에 344마리 펭귄의 이름을 모두 적어 넣고, 120마리가 뽑힐 때까지 무작위로 이름을 뽑는 것이 단순 임의 표본 추출 방식이다. 이 방법은 모집단 내 모든 펭귄이 표본으로 선택될 확률이 동일하다는 특징이 있다.
또한, 어떤 펭귄이 표본에 포함되더라도 다른 펭귄이 표본에 포함될 확률에 영향을 주지 않는다. 이처럼 모집단의 모든 사례가 동일한 확률로 표본에 포함되고, 특정 사례의 선택이 다른 사례의 선택에 영향을 미치지 않을 때 이를 “단순 무작위 표본”이라고 한다.
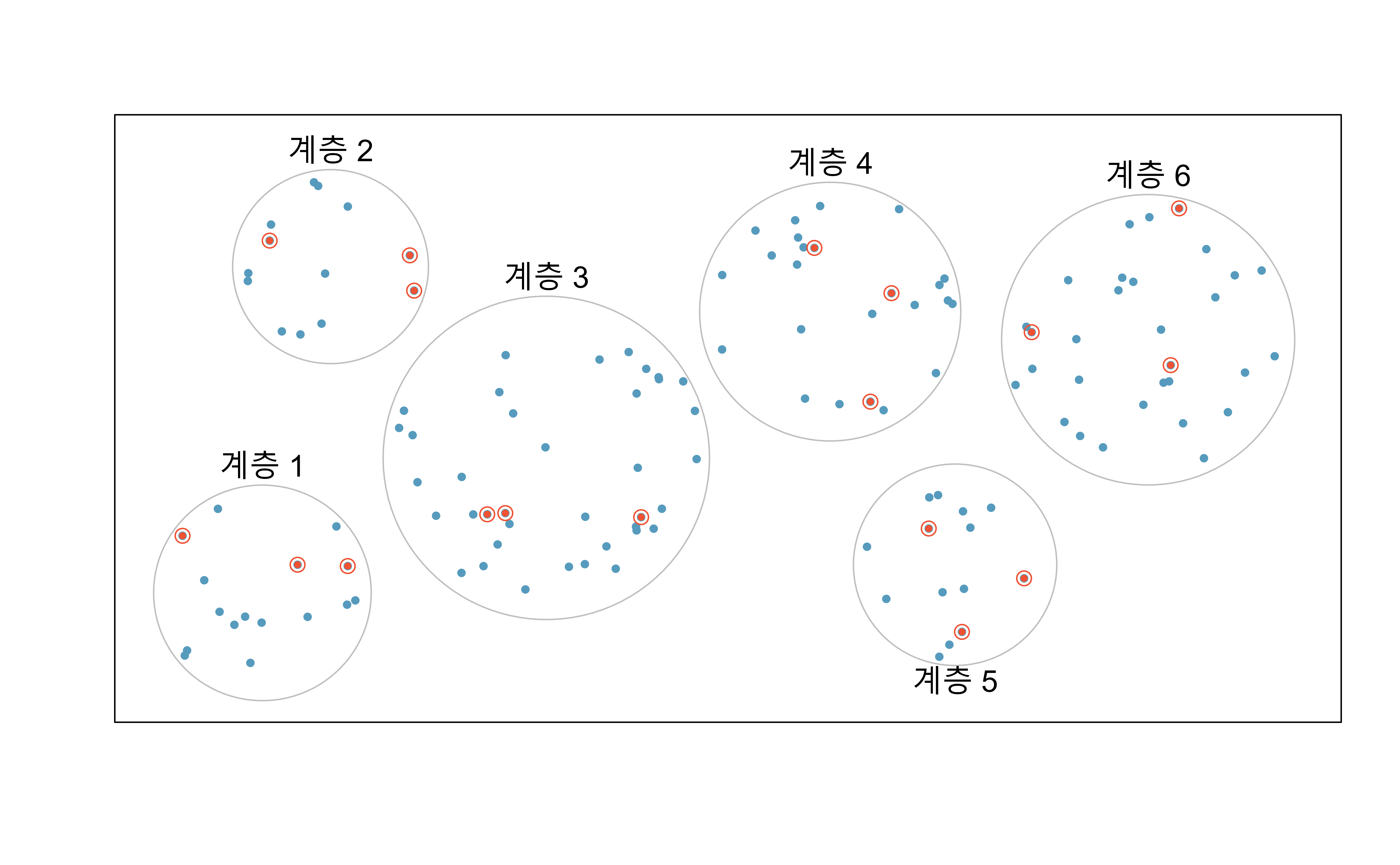
9.2 층화 표본 추출
층화 표본 추출은 모집단을 유사한 특성을 가진 하위 집단인 층으로 나누고, 각 층에서 무작위로 표본을 추출하는 방식이다. 이는 분할 정복 전략을 활용한 표본 추출 기법 중 하나이다.
예를 들어, 팔머 펭귄 데이터셋에서 펭귄의 종은 서로 다른 특성을 가지고 있으므로 층을 대표할 수 있다. 따라서 종별로 40마리씩 무작위 추출하여 총 120마리의 표본을 얻을 수 있다.
층화 표본 추출은 각 층 내부의 사례들이 연구하고자 하는 결과에 대해 매우 비슷한 특성을 보일 때 특히 유용하다. 하지만 층화 표본 데이터를 분석하는 것은 단순 무작위 표본 데이터를 다루는 것보다 더 복잡할 수 있다는 단점이 있다.
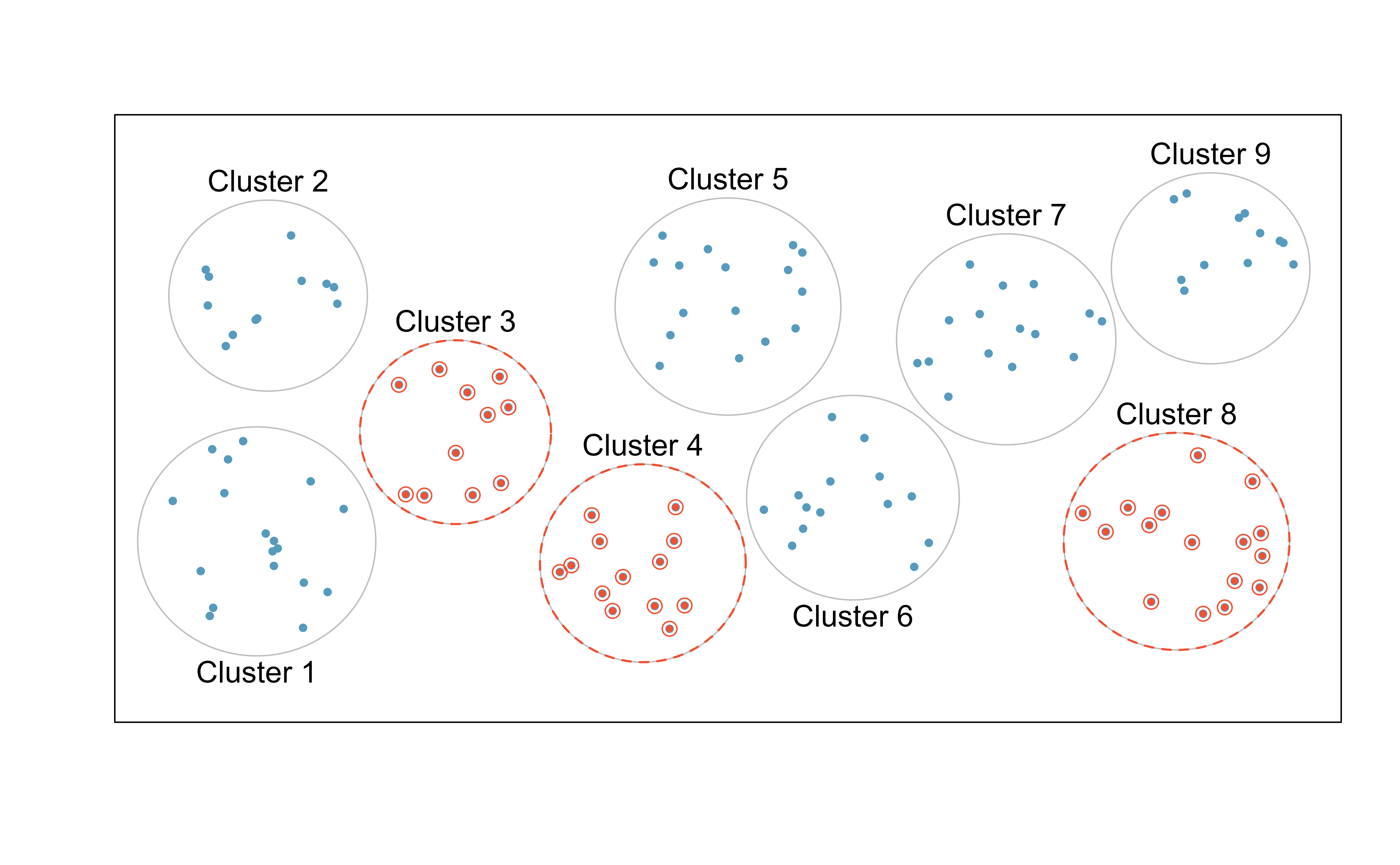
9.3 군집 표본 추출
군집 표본 추출은 모집단을 여러 개의 군집으로 분할하고, 그 중 일부 군집을 무작위로 선택하여 해당 군집 내 모든 관측점을 표본에 포함하는 방식이다. 이 방법은 군집 간 차이는 크지 않지만, 군집 내 사례들 간의 변동성이 클 때 효과적이다. 예를 들어, 섬을 군집으로 설정하고 섬 내 개체군의 다양성이 클 경우 군집 표본 추출이 적합하다. 이 방법은 다른 표본 추출 기법에 비해 경제적일 수 있다는 장점이 있지만, 일반적으로 더 복잡한 분석 기법을 요구한다는 단점이 있다.
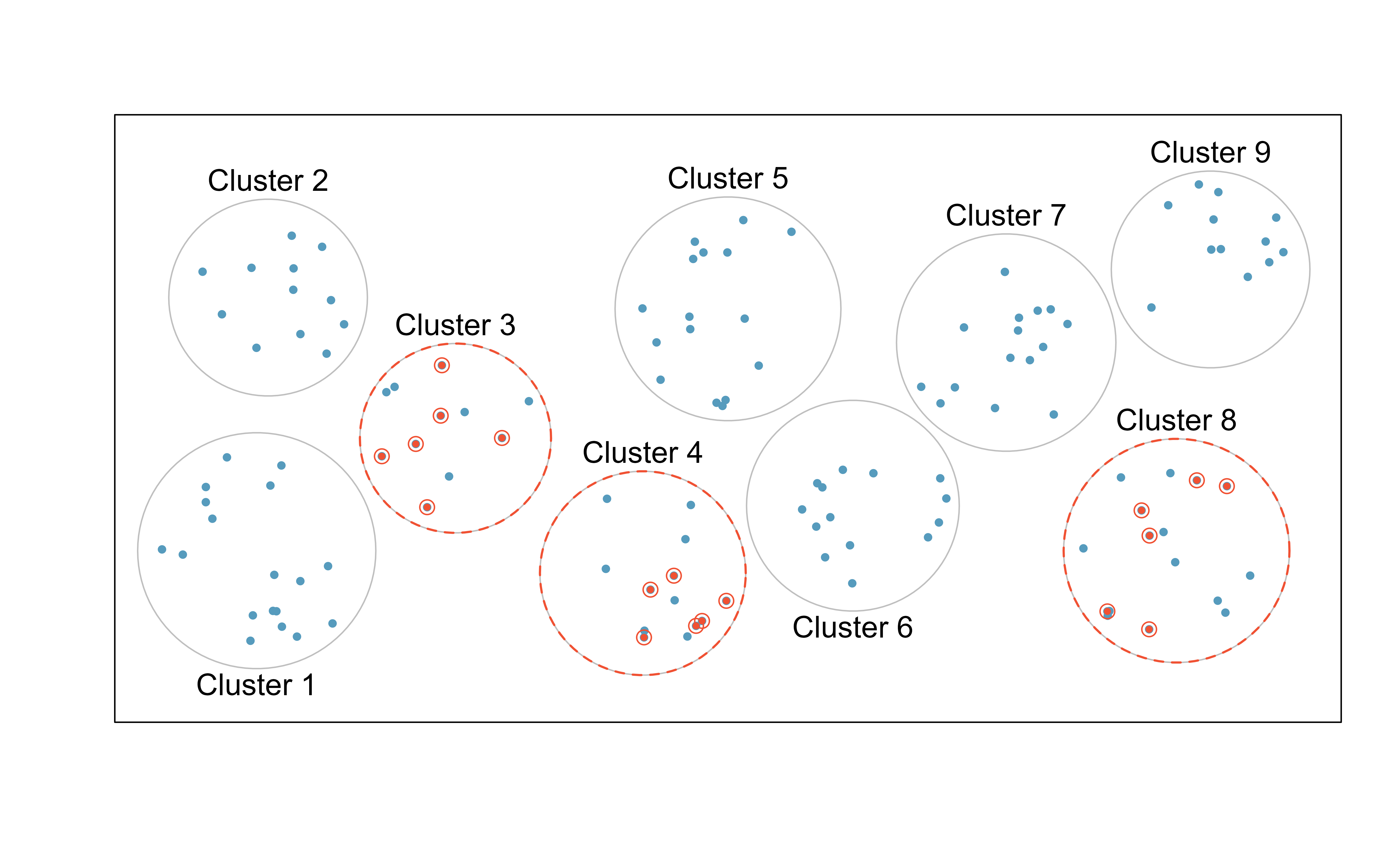
9.4 다단계 표본 추출
다단계 표본 추출은 군집 표본 추출과 유사하게 모집단을 여러 개의 군집으로 분할한다. 그러나 선택된 군집 내에서 다시 무작위로 표본을 추출하는 점에서 군집 표본 추출과 차이가 있다. 이 방법 역시 군집 간 차이는 크지 않지만, 군집 내 사례들 간의 변동성이 클 때 효과적이다. 다단계 표본 추출은 군집 표본 추출과 마찬가지로 경제적일 수 있지만, 더 복잡한 분석 기법을 필요로 한다. 하지만 기존의 분석 방법을 확장함으로써 이러한 데이터를 처리할 수 있다.
9.5 R 코드
4가지 표본 추출 방법을 팔머펭귄 데이터셋에 적용해보자.
9.5.1 단순 무작위 표본 추출
단순 무작위 표본추출방법(Simple Random Sampling)은 모집단이 비교적 동질적이고 하위 그룹에 대한 정보가 필요하지 않을 때 적합하다. 모든 펭귄이 표본에 선택될 동등한 기회를 가지며, 이론적으로 모집단을 가장 잘 대표하는 표본을 얻을 수 있다. 단순 무작위 표본 추출은 표본 추출 방법 중 가장 간단하고 효율적인 방법이다.하지만, 특정 그룹이 과소 또는 과대 표현될 수 있고, 큰 데이터셋에서는 비용이 많이 들 수 있다는 단점이 있다. dplyr 패키지의 slice_sample() 함수를 사용하여 단순 무작위 표본 추출을 수행할 수 있다. n = 50을 지정하여 50개의 표본을 추출할 수도 있고, p = 0.1을 지정하여 10%의 표본을 추출할 수도 있다.
9.5.2 층화 표본 추출
층화 표본 추출(Stratified Sampling)은 모집단을 여러 층(stratum)으로 나눈 후 각 층에서 단순 무작위 표본 추출을 수행하는 방법으로 모집단이 이질적이고 하위 그룹에 대한 정보가 중요할 때 적합하다.
모집단의 하위 그룹을 고려하여 표본을 추출하므로 모집단을 잘 대표할 수 있고 하위 그룹별 분석이 가능하다는 장점이 있는 반면, 층을 나누기 위한 정보가 필요하고, 층별로 별도의 표본 추출이 이루어지므로 경우에 따라서는 비용이 더 들 수도 있다. group_by() 함수를 사용하여 종을 기준으로 층화시킨 후 slice_sample() 함수로 단순 무작위 표본 추출 작업을 수행한다.
9.5.3 군집 표본 추출
군집 표본 추출(Cluster Sampling)은 모집단을 여러 군집(cluster)으로 나눈 후 몇 개의 군집을 무작위로 선택한 후 선택된 군집에서 모든 개체를 표본으로 추출하는 방법이다. 군집 표본 추출은 모집단이 지리적으로 넓게 분포되어 있을 때 효율적이다. 모집단이 자연스럽게 군집을 이루고 있고, 군집 간 차이가 크지 않을 때 적합하다. 군집 내 유사성으로 인해 편향된 결과를 얻을 수 있으며, 표본 크기가 클 수 있다는 단점이 있다. sample() 함수를 사용하여 군집을 무작위로 선택한 후 filter() 함수로 선택된 군집에 속하는 표본을 추출한다. 펭귄이 서식하는 섬(비스코, 드림, 토르거센)을 기준으로 무작위로 섬을 하나 선택하고 해당 섬에 서식하는 펭귄을 모두 추출한다.
9.5.4 다단계 표본 추출
다단계 표본 추출(Multistage Sampling)은 두 단계 이상으로 표본을 추출하는 방법으로 모집단이 계층적 구조를 가지고 있을 때 적합하다. 다단계 표본 추출은 복잡한 설계를 필요로 하며, 설계 효과(design effect)를 고려해야 한다. sample() 함수를 사용하여 서식지를 기준으로 1차 추출한 후 slice_sample() 함수로 펭귄을 2차 추출한다.
9.6 shiny 앱
#| label: shinylive-four-sampling
#| viewerHeight: 600
#| standalone: true
library(shiny)
library(openintro)
data(COL)
# _____ Simple Random _____ #
build_srs <- function(n, N) {
colSamp <- COL[4]
PCH <- rep(c(1, 3, 20)[3], 3)
col <- rep(COL[1], N)
pch <- PCH[match(col, COL)]
plot(0, xlim = c(0,2), ylim = 0:1, type = 'n', axes = FALSE, xlab = "", ylab = "")
box()
x <- runif(N, 0, 2)
y <- runif(N)
inc <- n
points(x, y, col = col, pch = pch)
these <- sample(N, n)
points(x[these], y[these], pch = 20, cex = 0.8, col = colSamp)
points(x[these], y[these], cex = 1.4, col = colSamp)
}
# _____ Stratified _____ #
build_stratified <- function(N, numStrata, sampleSizePerStratum) {
colSamp <- COL[4]
col <- rep(COL[1], N)
PCH <- rep(c(1, 3, 20)[3], 3)
plot(0, xlim = c(0, 2), ylim = 0:1 + 0.01,
type = 'n', axes = FALSE, xlab = "", ylab = "")
box()
X <- seq(0.1, 1.9, length.out = numStrata)
Y <- rep(0.5, numStrata)
# 각 계층의 크기를 무작위로 생성
strataSizes <- sample(ceiling(N/numStrata) * 0.5 + c(-1, 1) * ceiling(N/numStrata) * 0.25, numStrata, replace = TRUE)
strataSizes <- round(strataSizes / sum(strataSizes) * N)
R <- sqrt(strataSizes / 500)
above <- rep(1, numStrata)
currentIndex <- 1
for (i in 1:numStrata) {
hold <- seq(0, 2 * pi, length.out = 99)
x <- X[i] + (R[i] + 0.01) * cos(hold)
y <- Y[i] + (R[i] + 0.01) * sin(hold)
polygon(x, y, border = COL[5, 4])
x <- rep(NA, strataSizes[i])
y <- rep(NA, strataSizes[i])
for (j in 1:strataSizes[i]) {
inside <- FALSE
while (!inside) {
xx <- runif(1, -R[i], R[i])
yy <- runif(1, -R[i], R[i])
if (sqrt(xx^2 + yy^2) < R[i]) {
inside <- TRUE
x[j] <- xx
y[j] <- yy
}
}
}
type <- sample(1, strataSizes[i], TRUE)
pch <- PCH[type]
col <- COL[type]
x <- X[i] + x
y <- Y[i] + y
points(x, y, pch = pch, col = col)
these <- sample(strataSizes[i], min(sampleSizePerStratum, strataSizes[i]))
points(x[these], y[these],
pch = 20, cex = 0.8, col = colSamp)
points(x[these], y[these], cex = 1.4, col = colSamp)
currentIndex <- currentIndex + strataSizes[i]
}
text(X, Y + above * (R),
paste("계층", 1:numStrata),
pos = 2 + above,
cex = 1.3)
}
# _____ Cluster _____ #
build_cluster <- function(numClusters, clusterSizes, selectedClusters) {
colSamp <- COL[4]
PCH <- rep(c(1, 3, 20)[3], 3)
plot(0, xlim = c(0, 2), ylim = c(0.01, 1.04), type = 'n', axes = FALSE, xlab = "", ylab = "")
box()
X <- seq(0.1, 1.9, length.out = numClusters)
Y <- runif(numClusters, 0.2, 0.8)
R <- sqrt(clusterSizes / 500)
above <- ifelse(Y > 0.5, 1, -1)
for (i in 1:numClusters) {
hold <- seq(0, 2 * pi, length.out = 99)
x <- X[i] + (R[i] + 0.02) * cos(hold)
y <- Y[i] + (R[i] + 0.02) * sin(hold)
polygon(x, y, border = COL[5, 4])
if (i %in% selectedClusters) {
polygon(x, y, border = COL[4], lty = 2, lwd = 1.5)
}
x <- rep(NA, clusterSizes[i])
y <- rep(NA, clusterSizes[i])
for (j in 1:clusterSizes[i]) {
inside <- FALSE
while (!inside) {
xx <- runif(1, -R[i], R[i])
yy <- runif(1, -R[i], R[i])
if (sqrt(xx^2 + yy^2) < R[i]) {
inside <- TRUE
x[j] <- xx
y[j] <- yy
}
}
}
type <- sample(1, clusterSizes[i], TRUE)
pch <- PCH[type]
col <- COL[type]
x <- X[i] + x
y <- Y[i] + y
points(x, y, pch = pch, col = col)
if (i %in% selectedClusters) {
points(x, y, pch = 20, cex = 0.8, col = colSamp)
points(x, y, cex = 1.4, col = colSamp)
}
}
text(X, Y + above * (R + 0.01),
paste("군집", 1:numClusters),
pos = 2 + above,
cex = 1.3)
}
# _____ Multistage Sampling _____ #
build_multistage <- function(numClusters, sampleSizePerCluster, clusterSizes) {
colSamp <- COL[4]
PCH <- rep(c(1, 3, 20)[3], 3)
plot(0, xlim = c(0, 2), ylim = c(0.01, 1.04), type = 'n', axes = FALSE, xlab = "", ylab = "")
box()
X <- seq(0.1, 1.9, length.out = numClusters)
Y <- runif(numClusters, 0.2, 0.8)
R <- sqrt(clusterSizes / 500)
above <- ifelse(Y > 0.5, 1, -1)
for (i in 1:numClusters) {
hold <- seq(0, 2 * pi, length.out = 99)
x <- X[i] + (R[i] + 0.02) * cos(hold)
y <- Y[i] + (R[i] + 0.02) * sin(hold)
polygon(x, y, border = COL[5, 4])
x <- rep(NA, clusterSizes[i])
y <- rep(NA, clusterSizes[i])
for (j in 1:clusterSizes[i]) {
inside <- FALSE
while (!inside) {
xx <- runif(1, -R[i], R[i])
yy <- runif(1, -R[i], R[i])
if (sqrt(xx^2 + yy^2) < R[i]) {
inside <- TRUE
x[j] <- xx
y[j] <- yy
}
}
}
type <- sample(1, clusterSizes[i], TRUE)
pch <- PCH[type]
col <- COL[type]
x <- X[i] + x
y <- Y[i] + y
points(x, y, pch = pch, col = col)
these <- sample(clusterSizes[i], min(sampleSizePerCluster, clusterSizes[i]))
points(x[these], y[these], pch = 20, cex = 0.8, col = colSamp)
points(x[these], y[these], cex = 1.4, col = colSamp)
}
text(X, Y + above * (R + 0.01),
paste("군집", 1:numClusters),
pos = 2 + above, cex = 1.3)
}
# ui -----
ui <- fluidPage(
titlePanel("표본 추출 방법 시각화"),
sidebarLayout(
sidebarPanel(
radioButtons("method", "표본 추출 방법 선택:",
c("단순 무작위 표본 추출" = "srs",
"층화 표본 추출" = "stratified",
"군집 표본 추출" = "cluster",
"다단계 표본 추출" = "multistage"),
inline = TRUE),
conditionalPanel(
condition = "input.method == 'srs'",
sliderInput("sampleSize", "표본 크기:", min = 1, max = 100, value = 10)
),
conditionalPanel(
condition = "input.method == 'stratified'",
sliderInput("numStrata", "층(Stratum) 수:", min = 1, max = 5, value = 3),
sliderInput("sampleSizePerStratum", "층 내부 표본 크기:", min = 1, max = 10, value = 3)
),
conditionalPanel(
condition = "input.method == 'cluster'",
sliderInput("numClusters", "군집 수:", min = 1, max = 9, value = 3)
),
conditionalPanel(
condition = "input.method == 'multistage'",
sliderInput("numClustersMultistage", "군집 수:", min = 1, max = 9, value = 3),
sliderInput("sampleSizePerClusterMultistage", "군집 내부 표본 크기:", min = 1, max = 10, value = 3)
)
),
mainPanel(
plotOutput("samplingPlot")
)
)
)
server <- function(input, output) {
output$samplingPlot <- renderPlot({
if (input$method == "srs") {
build_srs(n = input$sampleSize, N = 100)
} else if (input$method == "stratified") {
build_stratified(N = 100, numStrata = input$numStrata, sampleSizePerStratum = input$sampleSizePerStratum)
} else if (input$method == "cluster") {
clusterSizeMin <- sample(5:30, 1)
clusterSizeMax <- sample((clusterSizeMin+5):50, 1)
clusterSizes <- sample(clusterSizeMin:clusterSizeMax, input$numClusters, replace = TRUE)
selectedClusters <- sample(1:input$numClusters, round(input$numClusters/3))
build_cluster(numClusters = input$numClusters, clusterSizes = clusterSizes, selectedClusters = selectedClusters)
} else if (input$method == "multistage") {
clusterSizeMin <- sample(5:30, 1)
clusterSizeMax <- sample((clusterSizeMin+5):50, 1)
clusterSizes <- sample(clusterSizeMin:clusterSizeMax, input$numClustersMultistage, replace = TRUE)
build_multistage(numClusters = input$numClustersMultistage, sampleSizePerCluster = input$sampleSizePerClusterMultistage, clusterSizes = clusterSizes)
}
})
}
shinyApp(ui, server)