18 펭귄 성별 분류 모형
palmerpenguins 데이터셋을 활용하여 펭귄의 성별을 예측하는 분류 모형을 개발합니다.
18.1 작업 흐름도
데이터 정제 후 변수 선택 및 피쳐 엔지니어링을 거쳐 로지스틱 회귀 모형을 적합시킵니다. 모형 성능 평가 후 중요 변수를 파악하고 이를 바탕으로 펭귄의 성별을 예측합니다.
18.2 데이터 정제
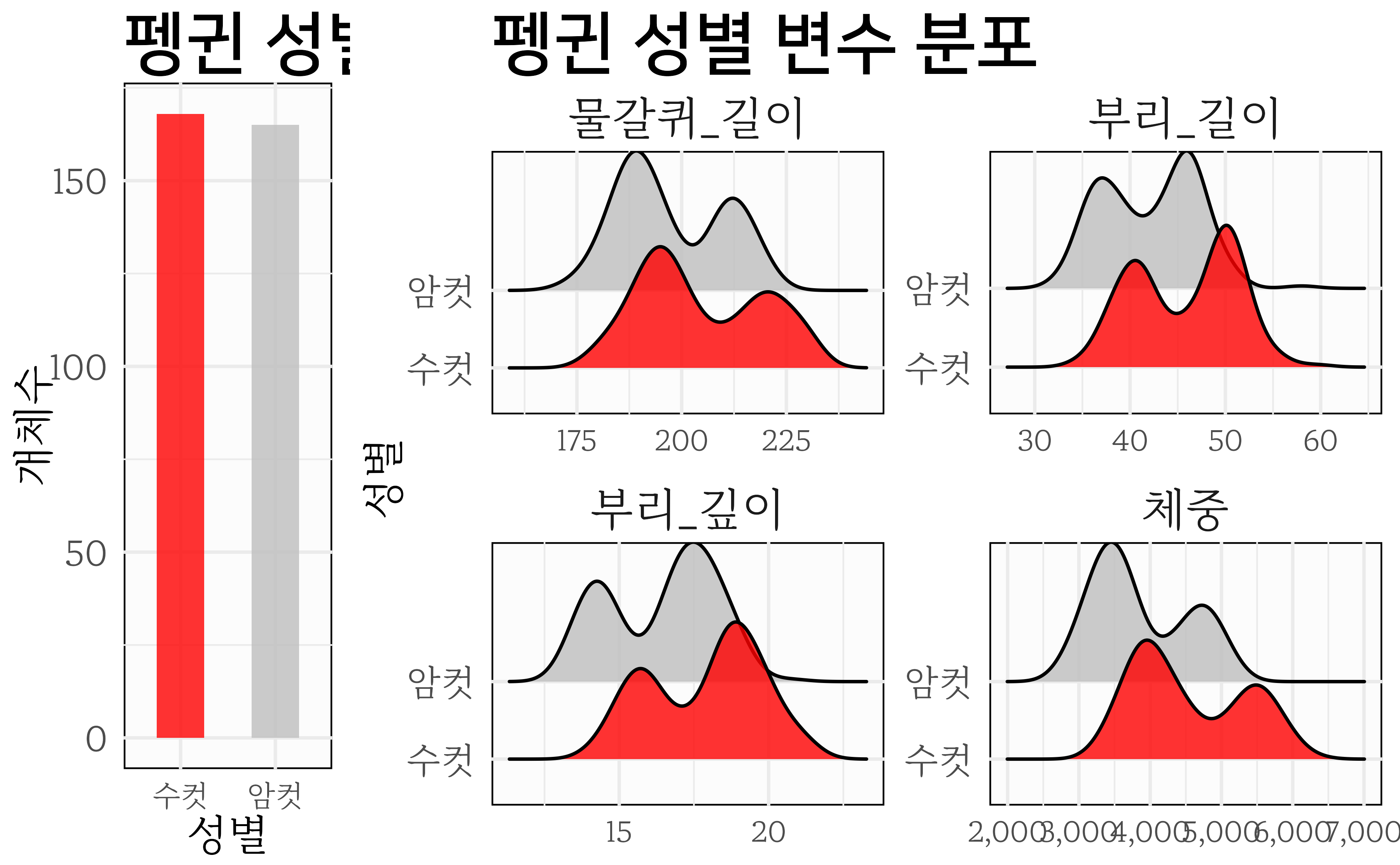
18.3 펭귄 성별 비율
| 성별 | 개체수 | 비율 | |
|---|---|---|---|
| 수컷 | 168 | 50.5% | |
| 암컷 | 165 | 49.5% | |
| 합계 | — | 333 | 1 |
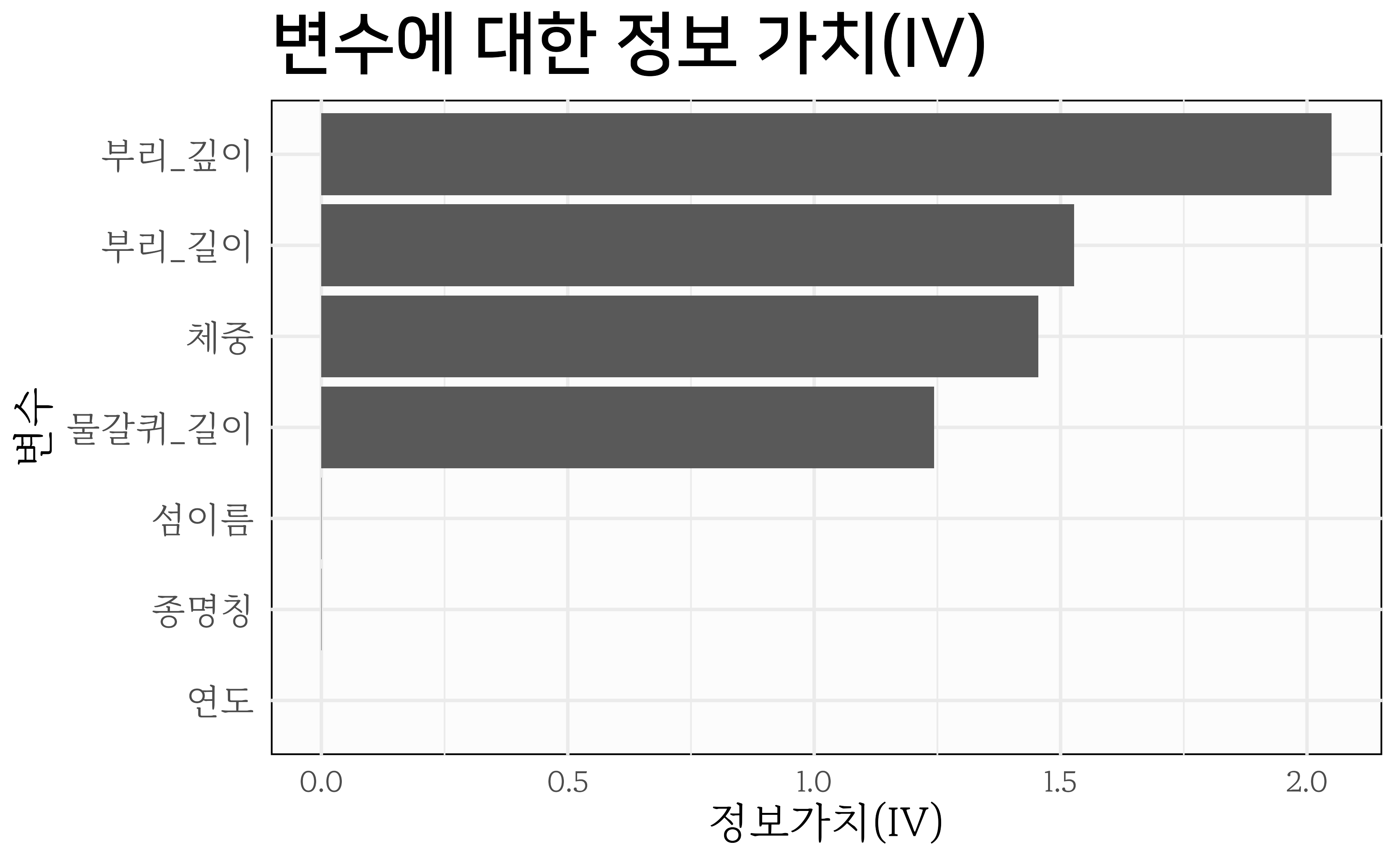
18.4 정보가치
정보 가치(Information Value, IV)는 예측 모형개발에서 변수 예측력을 평가하는 데 사용되는 중요한 지표로 목표 변수를 얼마나 잘 예측하는지 수치적으로 나타낸다. 정보 가치는 변수가 분류 문제에서 유용한지를 판단하는 데 중요한 역할을 한다. 정보 가치는 다음 공식으로 계산된다.
\[ IV = \sum_{i=1}^{n} (P_{\text{수컷}}(i) - P_{\text{암컷}}(i)) \times \ln\left(\frac{P_{\text{수컷}}(i)}{P_{\text{암컷}}(i)}\right) \]
\(n\)은 분석 대상 변수의 범주 수(또는 구간 수)이고, \(P_{\text{수컷}}(i)\)는 \(i\)번째 범주(또는 구간)에 대한 수컷의 비율이다. \(P_{\text{암컷}}(i)\)는 \(i\)번째 범주(또는 구간)에 대한 암컷의 비율이며, \(\ln\)은 자연 로그다.
로지스틱 모형에서 정보 가치는 변수 선택에 도움을 주고, 모형 해석을 용이하게 하며, 과적합의 위험을 줄이는 역할을 한다. 각 변수의 정보 가치를 분석함으로써, 해당 변수가 분류 문제에 얼마나 중요한 영향을 미치는지 이해할 수 있다.
| 정보 가치 (IV) | 예측력 |
|---|---|
| IV ≤ 0.02 | 변수는 예측에 유용하지 않음 |
| 0.02 < IV ≤ 0.1 | 약한 예측력 |
| 0.1 < IV ≤ 0.3 | 중간 예측력 |
| 0.3 < IV ≤ 0.5 | 강한 예측력 |
| IV > 0.5 | 매우 강한 예측력 |
Information 팩키지 create_infotables() 함수를 통해 IV를 쉽게 계산할 수 있다. 성별예측에 영향을 많이 주는 변수를 사전에 선정하는데 참조한다.
18.5 훈련/시험 데이터 분할
18.6 로지스틱 회귀 모형 적합
18.7 모형 예측 및 성능 평가
#> # A tibble: 1 × 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
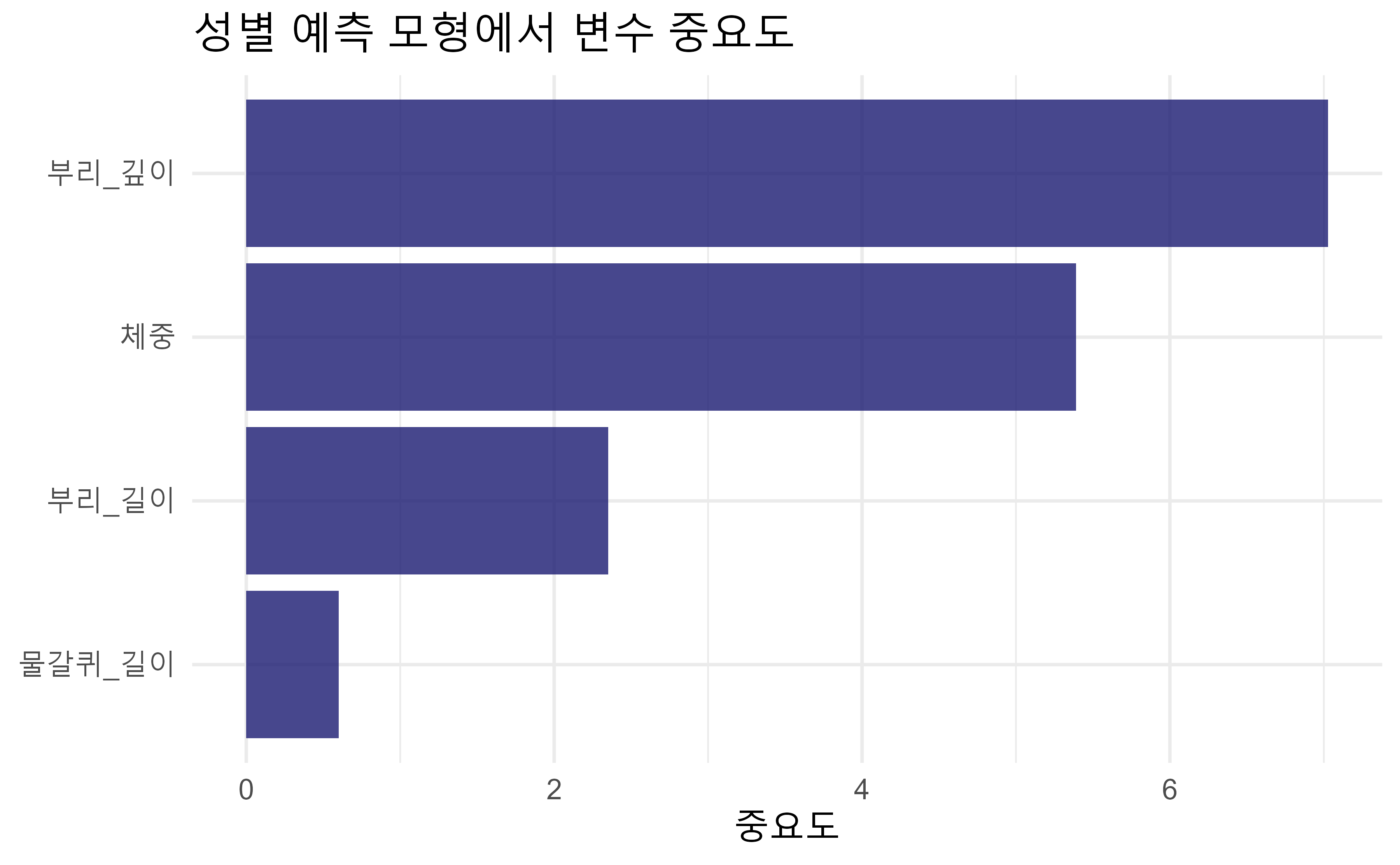
#> 1 accuracy binary 0.94118.8 변수 중요도
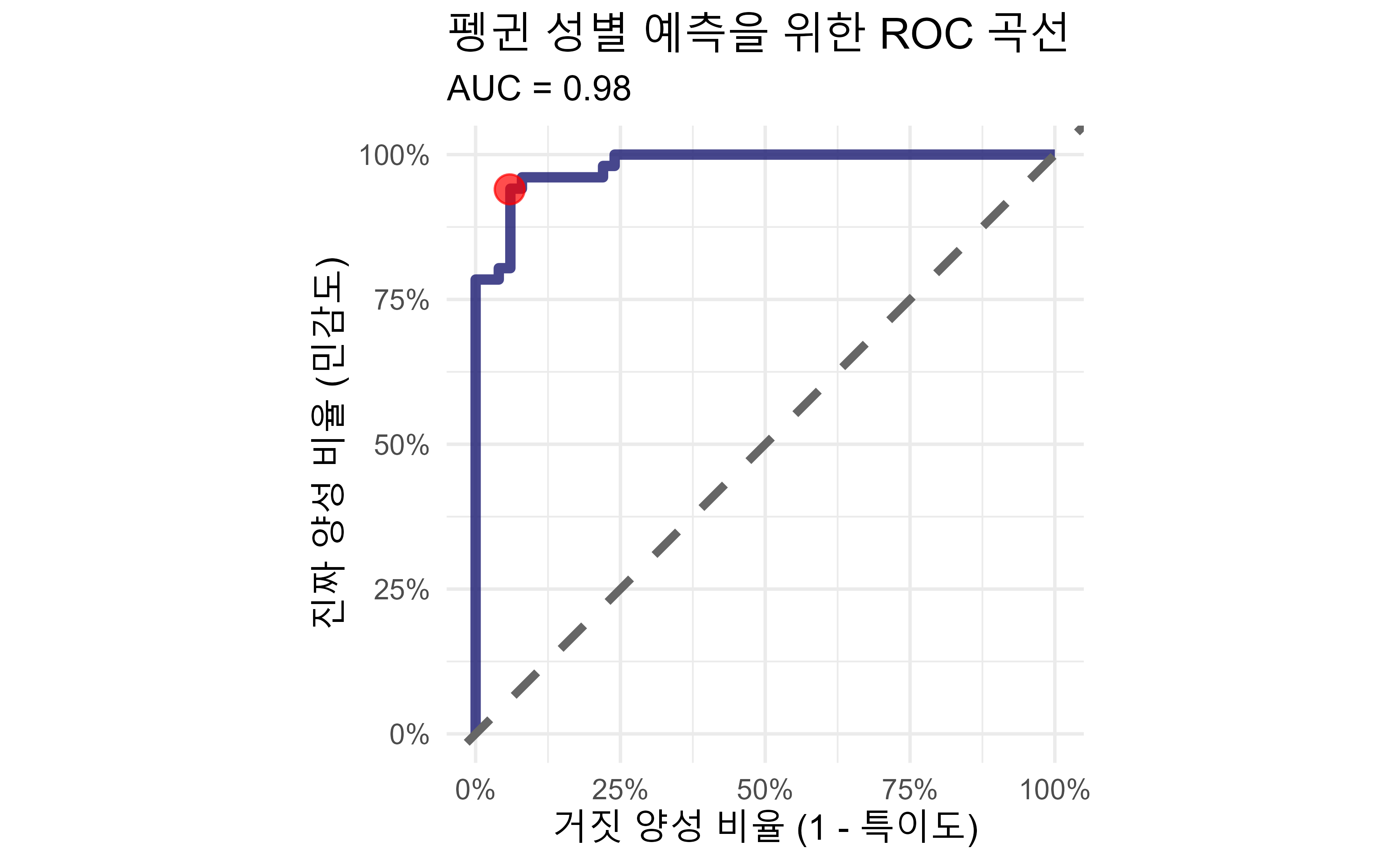
18.9 예측 모형 성능
18.10 펭귄 성별 예측
새로 포획한 펭귄의 성별을 예측해보자. 먼저, 새로운 펭귄의 측정 데이터를 생성한다.
새로 포획한 펭귄은 부리 길이는 45mm, 부리 깊이는 18mm, 날개 길이는 200mm, 체중은 4000g이다. 이제 앞서 훈련한 모델을 사용하여 이 새로운 펭귄의 성별을 예측한다.
#> # A tibble: 1 × 7
#> .pred_수컷 .pred_암컷 부리_길이 부리_깊이 물갈퀴_길이 체중 성별_예측
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
#> 1 0.674 0.326 45 18 200 4000 수컷predict() 함수를 사용하여 새로운 펭귄 데이터에 대한 예측을 수행한다. type = "prob"는 각 클래스(수컷과 암컷)에 대한 예측 확률을 반환하도록 지정하고, type = "class"는 예측된 클래스를 반환하도록 지정할 수도 있고, 앞서 임계값(threshold)을 반영하여 성별예측 한 예측 결과를 원래의 펭귄 데이터와 함께 bind_cols()를 사용하여 하나의 데이터프레임으로 결합한다.
새로 포획된 펭귄은 약 67.3579345%의 확률로 수컷으로 예측되었다. 따라서 이 펭귄은 수컷일 가능성이 높다고 볼 수 있다.
18.11 shiny 앱
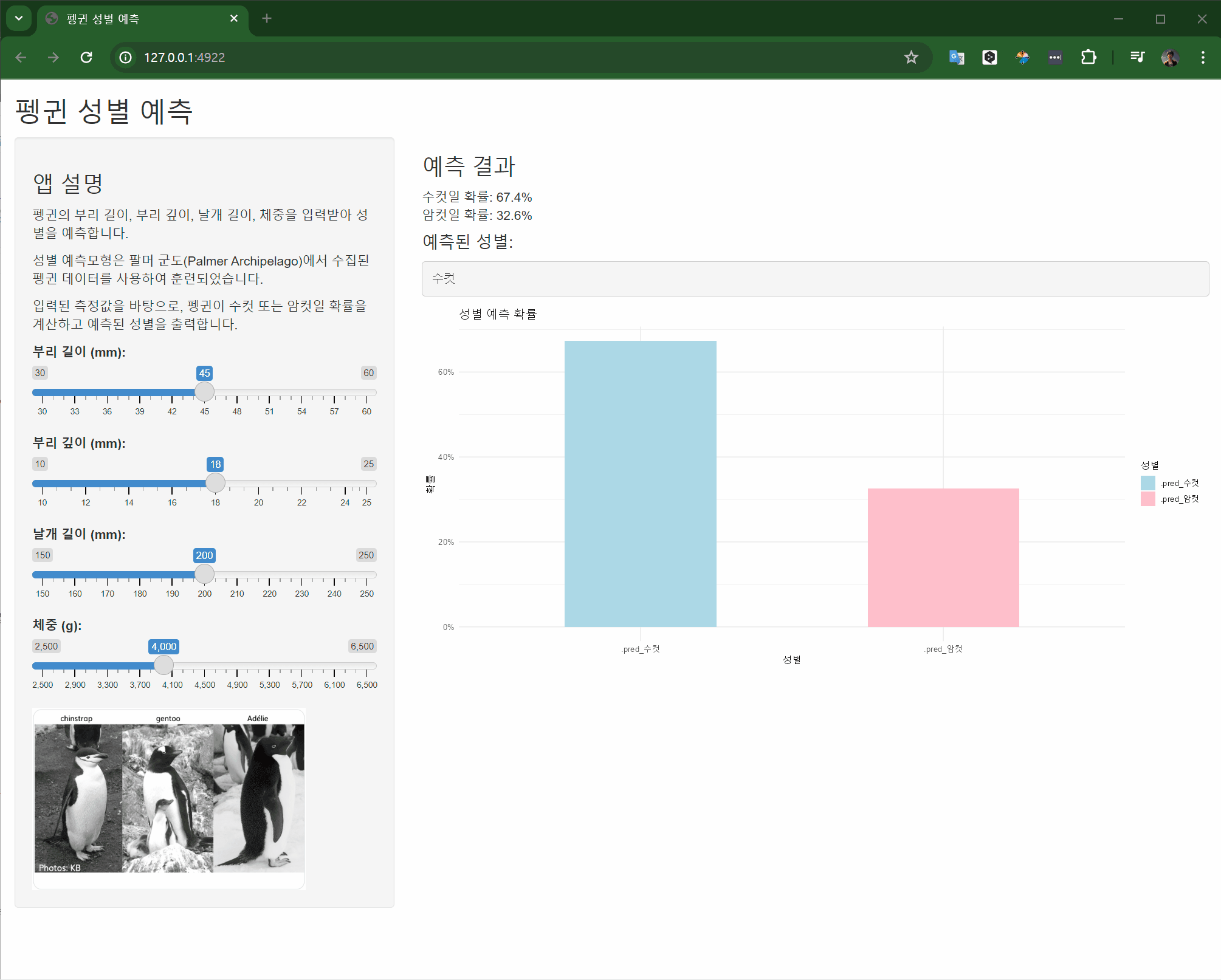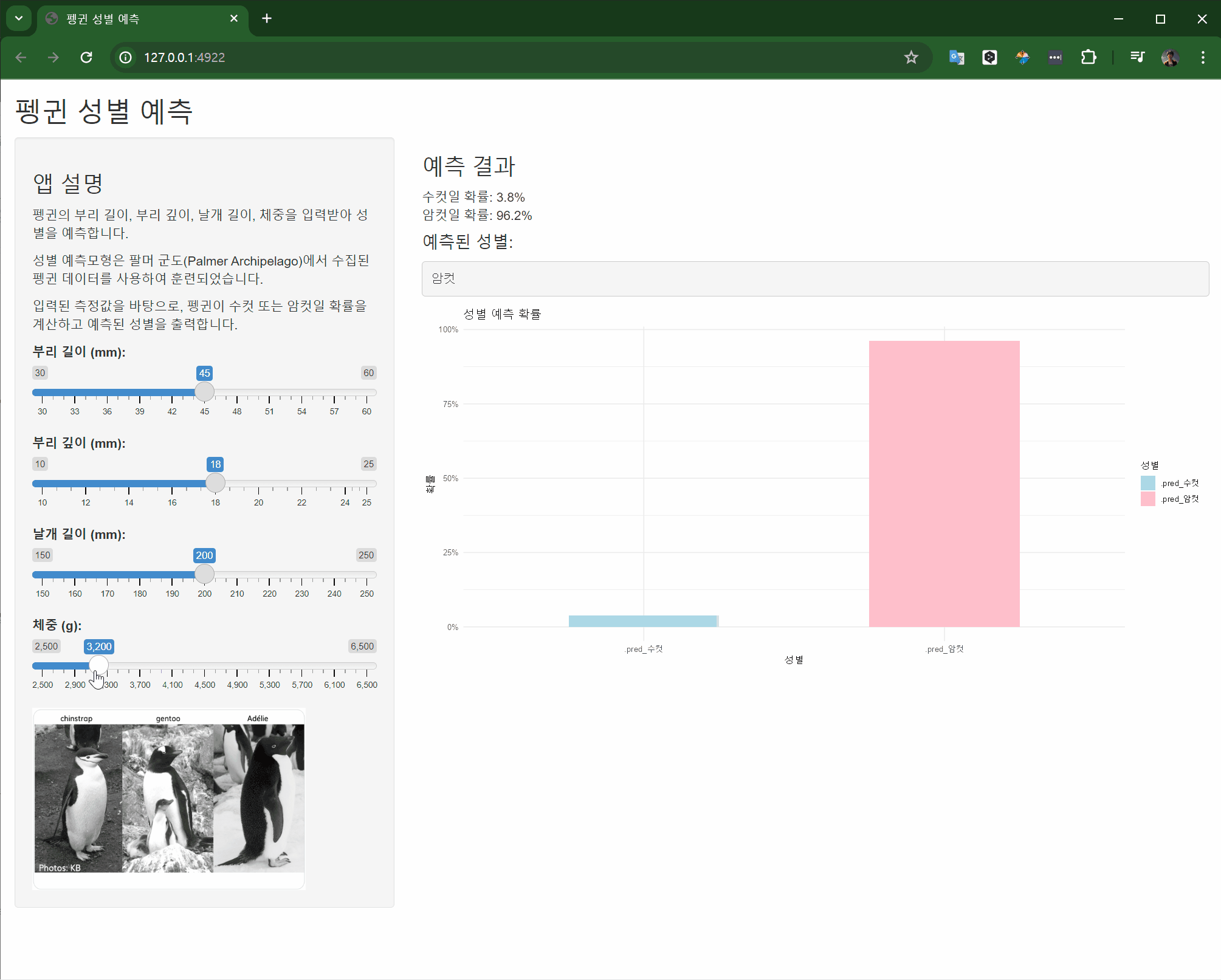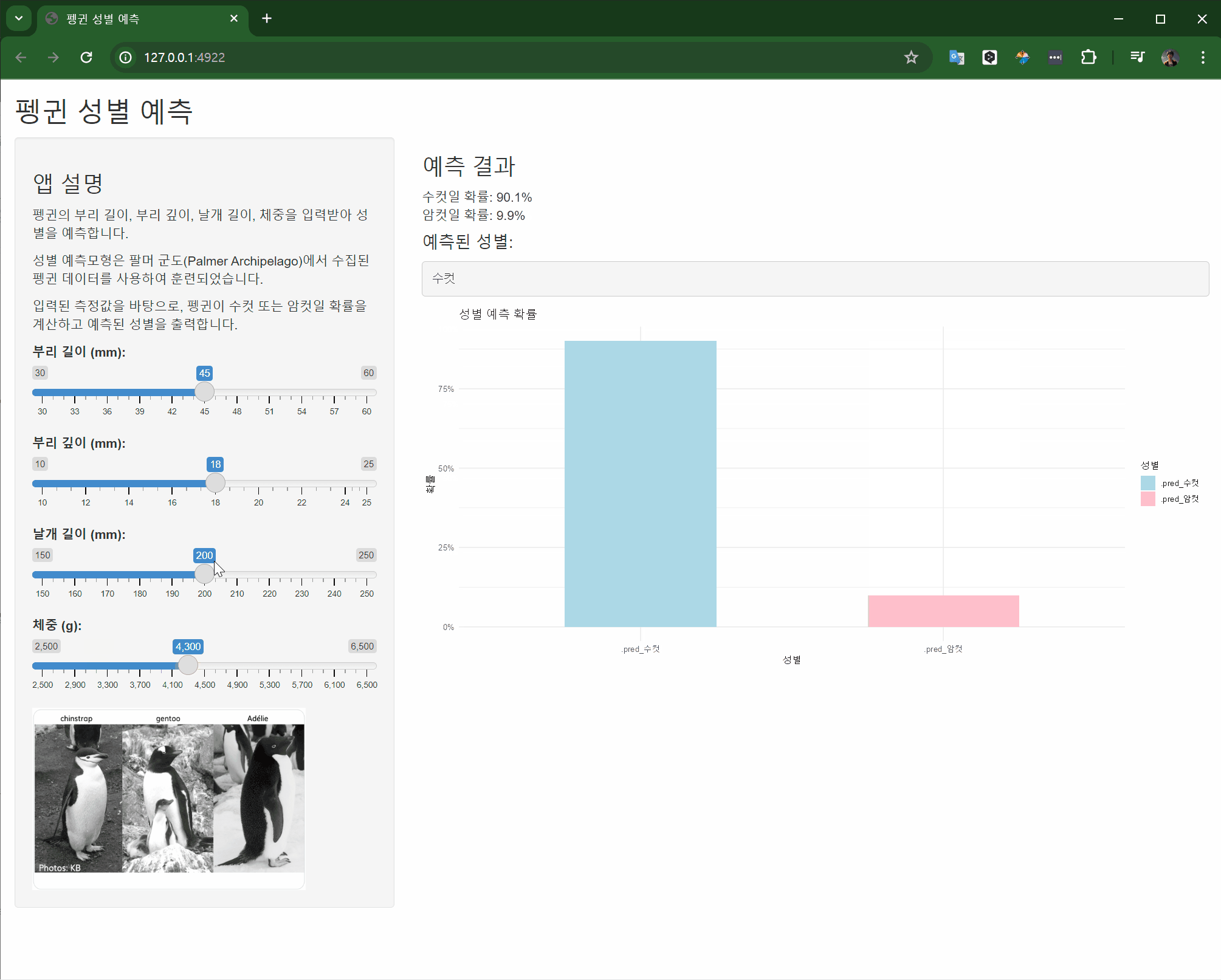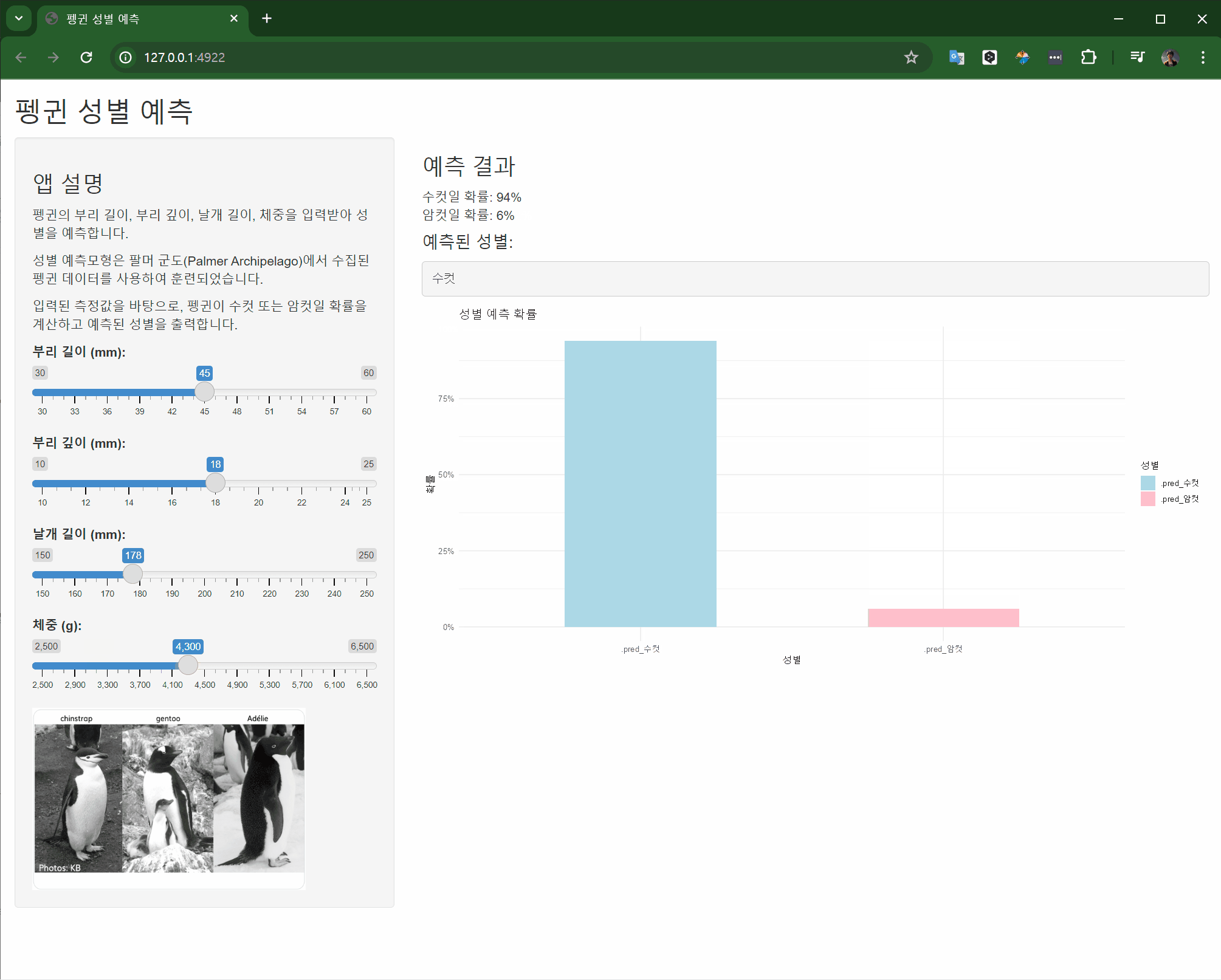
#| label: shinylive-penguins-logistic
#| viewerHeight: 600
#| standalone: true
library(shiny)
library(here)
penguins_fit <-
read_rds(str_glue("{here::here()}/shiny/model/logistic/penguins_fit.rds"))
ui <- fluidPage(
titlePanel("펭귄 성별 예측"),
sidebarLayout(
sidebarPanel(
h3("앱 설명"),
p("펭귄의 부리 길이, 부리 깊이, 날개 길이, 체중을 입력받아 성별을 예측합니다."),
p("성별 예측모형은 팔머 군도(Palmer Archipelago)에서 수집된 펭귄 데이터를 사용하여 훈련되었습니다."),
p("입력된 측정값을 바탕으로, 펭귄이 수컷 또는 암컷일 확률을 계산하고 예측된 성별을 출력합니다."),
sliderInput("bill_length", "부리 길이 (mm):", min = 30, max = 60, value = 45),
sliderInput("bill_depth", "부리 깊이 (mm):", min = 10, max = 25, value = 18),
sliderInput("flipper_length", "날개 길이 (mm):", min = 150, max = 250, value = 200),
sliderInput("body_mass", "체중 (g):", min = 2500, max = 6500, value = 4000, step = 100),
img(src = "penguins_real_photo.jpg", height = 200, width = 300)
),
mainPanel(
h3("예측 결과"),
textOutput("male_prob"),
textOutput("female_prob"),
h4("예측된 성별:"),
verbatimTextOutput("predicted_sex"),
plotOutput("prob_plot")
)
)
)
server <- function(input, output) {
new_penguin <- reactive({
tibble(
부리_길이 = input$bill_length,
부리_깊이 = input$bill_depth,
물갈퀴_길이 = input$flipper_length,
체중 = input$body_mass
)
})
new_penguin_pred <- reactive({
penguins_fit %>%
predict(new_data = new_penguin(), type = "prob") %>%
bind_cols(new_penguin()) %>%
mutate(
성별_예측 = if_else(.pred_수컷 >= best_threshold[["threshold"]], "수컷", "암컷")
)
})
output$male_prob <- renderText({
paste0("수컷일 확률: ", round(new_penguin_pred()$.pred_수컷 * 100, 1), "%")
})
output$female_prob <- renderText({
paste0("암컷일 확률: ", round(new_penguin_pred()$.pred_암컷 * 100, 1), "%")
})
output$predicted_sex <- renderText({
new_penguin_pred()$성별_예측
})
output$prob_plot <- renderPlot({
new_penguin_pred() %>%
pivot_longer(cols = c(.pred_수컷, .pred_암컷), names_to = "성별", values_to = "확률") %>%
ggplot(aes(x = 성별, y = 확률, fill = 성별)) +
geom_col(width = 0.5) +
scale_fill_manual(values = c("lightblue", "pink")) +
labs(title = "성별 예측 확률",
x = "성별",
y = "확률") +
scale_y_continuous(labels = scales::percent_format()) +
theme_minimal()
})
}
shinyApp(ui, server)