11 탐색적 데이터 분석
탐색적 데이터 분석(EDA)은 데이터 과학과 통계학에서 중요한 과정으로, 데이터 속에 숨겨진 패턴, 추세, 관계 및 구조를 식별하고 시각화한다. EDA는 데이터를 깊이 이해하고, 효과적인 모델을 구축하며, 데이터 기반 결정을 내리는 데 필요한 근거를 제공한다.
EDA는 데이터의 품질을 평가하고, 데이터에 존재할 수 있는 문제점들, 예를 들어 결측치, 이상치, 데이터 입력 오류 등을 식별한다. 이는 데이터 정제 및 전처리 과정에서 해결해야 할 문제를 명확하게 하며, 데이터 탐색을 통해 새로운 통찰력을 얻고 가설을 수립할 수 있다.
데이터의 특성을 이해함으로써 가장 적합한 통계적 모형이나 기계학습 알고리즘을 선정할 수 있으며, 복잡한 데이터에서 중요한 정보를 빠르게 파악하는 데 필요한 기술통계와 시각적 요약도 제공한다. EDA는 데이터 내에서 변수 간의 관계나 데이터 내에 존재하는 패턴을 찾아내며, 데이터에서 부적절한 관측점을 식별하여 분석 결과의 왜곡을 방지한다.
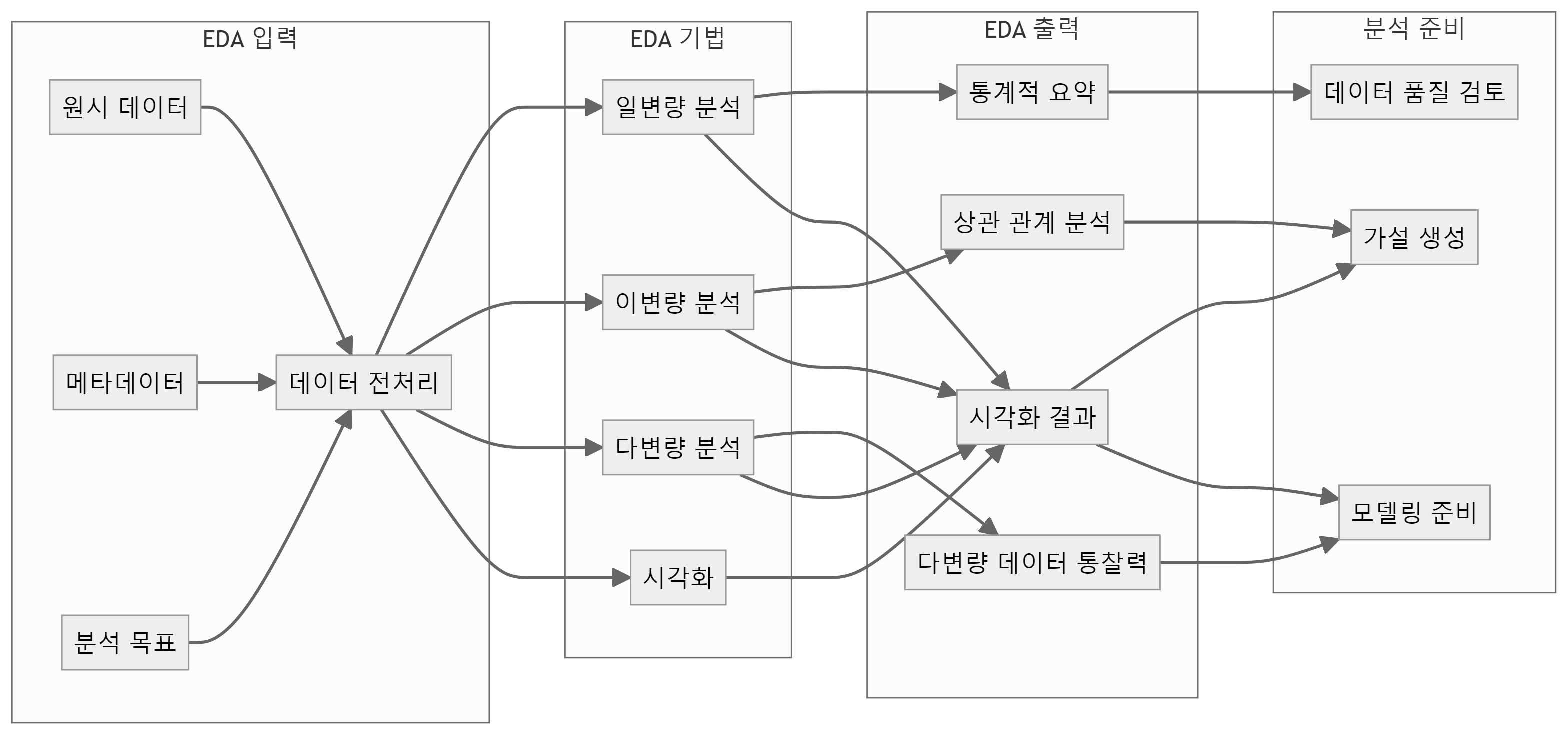
탐색적 데이터 분석(EDA)은 데이터 분석 초기 단계에서 수행되는 중요한 과정으로 데이터를 이해하고, 패턴을 발견하며, 가설을 생성하는 데 필수적인 과정이다. EDA 입력데이터로 원시 데이터, 메타데이터, 전처리된 데이터 등이 포함된다. 원시 데이터는 데이터베이스, 파일, 웹크롤링, API 등에서 얻어지며, 수치형 데이터, 범주형 데이터, 시간 데이터, 공간 데이터, 최근 이미지, 텍스트 등 다양한 유형의 (비)정형 데이터가 포함된다. 메타데이터는 데이터에 대한 추가 정보나 설명을 제공하며, 전처리된 데이터는 결측치 처리, 이상치 제거, 데이터 정제 등 과정을 거친 데이터다. 또한 특히, EDA를 작업을 수행할 때는 분석 목표를 명확히 정의하는 것이 중요하다.
EDA 작업 수행결과는 데이터에 대한 통찰력을 제공하고, 후속 분석을 준비하는 데 필수적으로 일반적으로 통계적 요약, 시각화, 데이터 통찰력, 분석 준비 등의 형태로 제공된다. 통계적 요약에는 평균, 중앙값, 최빈값, 표준편차, 분산, 최대값, 최소값, 백분위수, 사분위수 등이 포함되고, 시각화로는 히스토그램, 상자 그림, 산점도, 히트맵, 바이올린 플롯 등이 사용된다. 데이터 통찰력은 패턴 발견, 이상치 식별, 변수 간의 상관관계 등을 포함하며, 분석 준비는 추후 분석을 위한 데이터 조정 방향, 가설 설정, 변수 선택 및 변형 등을 제안한다.
EDA에서는 다양한 기법이 사용되며, 일변량 분석은 단일 변수의 분포 특성을 파악하기 위해 도수분포표, 히스토그램, 상자그림 등을 활용하며, 중심 경향과 변동성을 측정한다. 이변량 분석은 두 변수 간의 관계를 탐색하기 위해 산점도, 상관계수 등을 사용하며, 피어슨 상관계수를 통해 선형 관계의 강도와 방향을 측정한다. 한걸음 더 나아가 다변량 분석은 주성분 분석(PCA), 요인 분석, 군집 분석 등을 활용하여 다변량 데이터 구조를 탐색하고, 차원 축소, 변수 간 관계 파악, 그룹 식별 등을 수행한다. 마지막으로 시각화는 데이터의 패턴, 관계, 이상치 등을 시각적으로 표현하며, 막대 차트, 파이 차트, 히트맵, 트리맵, 평행 좌표계 등 다양한 기법이 활용된다.
11.1 남극 펭귄
palmer penguins 데이터셋은 남극 팔머 연구기지 근처에서 관찰된 세 종류 펭귄(아델리, 턱끈, 젠투)에 대한 데이터를 포함하고 있으며 펭귄의 종, 부리 크기, 델타 길이, 몸무게 및 성별 등의 정보를 담겨져 있다.
-
데이터셋 로드 및 준비
-
palmerpenguins패키지를 설치하고 데이터셋과 패키지를 불러온다.
-
-
데이터셋 검토
- 데이터셋 구조와 처음 몇 개의 행을 확인한다.
#> tibble [344 × 8] (S3: tbl_df/tbl/data.frame)
#> $ species : Factor w/ 3 levels "Adelie","Chinstrap",..: 1 1 1 1 1 1 1 1 1 1 ...
#> $ island : Factor w/ 3 levels "Biscoe","Dream",..: 3 3 3 3 3 3 3 3 3 3 ...
#> $ bill_length_mm : num [1:344] 39.1 39.5 40.3 NA 36.7 39.3 38.9 39.2 34.1 42 ...
#> $ bill_depth_mm : num [1:344] 18.7 17.4 18 NA 19.3 20.6 17.8 19.6 18.1 20.2 ...
#> $ flipper_length_mm: int [1:344] 181 186 195 NA 193 190 181 195 193 190 ...
#> $ body_mass_g : int [1:344] 3750 3800 3250 NA 3450 3650 3625 4675 3475 4250 ...
#> $ sex : Factor w/ 2 levels "female","male": 2 1 1 NA 1 2 1 2 NA NA ...
#> $ year : int [1:344] 2007 2007 2007 2007 2007 2007 2007 2007 2007 2007 ...
#> # A tibble: 6 × 8
#> species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
#> <fct> <fct> <dbl> <dbl> <int> <int>
#> 1 Adelie Torgersen 39.1 18.7 181 3750
#> 2 Adelie Torgersen 39.5 17.4 186 3800
#> 3 Adelie Torgersen 40.3 18 195 3250
#> 4 Adelie Torgersen NA NA NA NA
#> 5 Adelie Torgersen 36.7 19.3 193 3450
#> 6 Adelie Torgersen 39.3 20.6 190 3650
#> # ℹ 2 more variables: sex <fct>, year <int>-
결측치 처리
- 결측치를 확인하고 처리한다.
#> species island bill_length_mm bill_depth_mm
#> Adelie :152 Biscoe :168 Min. :32.10 Min. :13.10
#> Chinstrap: 68 Dream :124 1st Qu.:39.23 1st Qu.:15.60
#> Gentoo :124 Torgersen: 52 Median :44.45 Median :17.30
#> Mean :43.92 Mean :17.15
#> 3rd Qu.:48.50 3rd Qu.:18.70
#> Max. :59.60 Max. :21.50
#> NA's :2 NA's :2
#> flipper_length_mm body_mass_g sex year
#> Min. :172.0 Min. :2700 female:165 Min. :2007
#> 1st Qu.:190.0 1st Qu.:3550 male :168 1st Qu.:2007
#> Median :197.0 Median :4050 NA's : 11 Median :2008
#> Mean :200.9 Mean :4202 Mean :2008
#> 3rd Qu.:213.0 3rd Qu.:4750 3rd Qu.:2009
#> Max. :231.0 Max. :6300 Max. :2009
#> NA's :2 NA's :2-
기술통계 요약
- 종별로 그룹화하여 주요 기술통계량을 계산한다.
#> # A tibble: 3 × 6
#> species count mean_flipper_length sd_flipper_length mean_body_mass
#> <fct> <int> <dbl> <dbl> <dbl>
#> 1 Adelie 146 190. 6.52 3706.
#> 2 Chinstrap 68 196. 7.13 3733.
#> 3 Gentoo 119 217. 6.59 5092.
#> # ℹ 1 more variable: sd_body_mass <dbl>-
시각화
- 기술통계를 시각화하여 종별 차이를 확인한다.
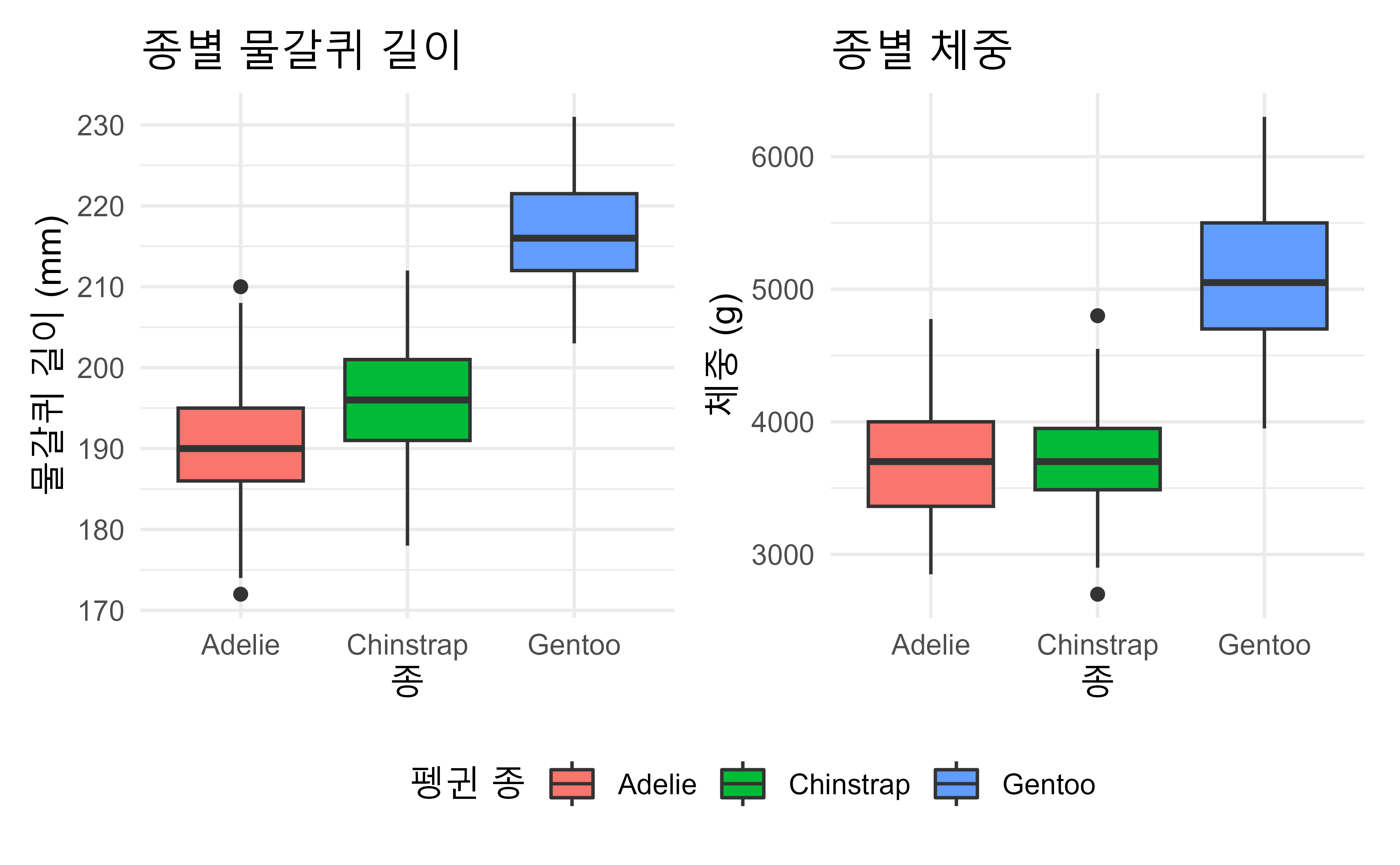
세 종류의 펭귄(아델리, 턱끈, 젠투)의 특성을 탐색하고 종별 차이를 확인하는 EDA를 수행하였다. 데이터셋에는 펭귄의 종, 부리 길이, 부리 깊이, 물갈퀴 길이, 체중, 성별, 연도 등의 변수가 포함되어 있다. 데이터셋 구조와 처음 몇 펭귄개체를 확인한 후, 결측치를 확인하고 제거하였다. 이후 종별로 그룹화하여 주요 기술통계량을 계산하였으며, 젠투 펭귄이 가장 많은 수를 차지하고, 아델리 펭귄의 물갈퀴 길이와 체중이 가장 크고 변동이 큰 것으로 나타났다. 종별 물갈퀴 길이와 체중에 대한 상자 그림을 생성하여 종별 차이를 시각적으로 확인하였으며, 아델리 펭귄이 다른 두 종에 비해 물갈퀴 길이와 체중이 더 크고 변동이 큰 것을 알 수 있었다. 젠투 펭귄이 생태학적 특성이나 환경 적응 면에서 다른 종과 다를 수 있음을 강력히 시사한다.
EDA 결과를 바탕으로 다음과 같은 가설을 세울 수 있다.
- 아델리 펭귄은 다른 두 종에 비해 물갈퀴 길이와 체중이 더 크므로, 수영 속도와 잠수 능력이 더 뛰어날 것이다. 이는 먹이 획득과 포식자 회피에 유리할 수 있다.
- 부리 크기와 물갈퀴 길이, 체중 사이에는 상관관계가 있을 것이다. 부리 크기가 클수록 더 큰 먹이를 잡을 수 있어 체중과 물갈퀴 길이가 증가할 수 있다.
- 성별에 따른 크기 차이가 있을 것이다. 많은 조류 종에서 암컷보다 수컷이 더 크므로, 펭귄에서도 이와 유사한 패턴이 나타날 수 있다.
향후 진행 방향으로는 다음과 같은 내용을 기술적으로 분석할 수 있다.
- 종별 차이를 통계적으로 검정하기 위해 t-검정이나 ANOVA 등의 가설 검정을 수행한다.
- 부리 크기, 물갈퀴 길이, 체중 사이의 상관관계를 분석하고, 회귀분석을 통해 변수 간의 관계를 모형화한다.
- 성별에 따른 크기 차이를 확인하기 위해 성별을 기준으로 그룹화하여 기술통계량을 비교하고, 가설 검정을 수행한다.
- 연도에 따른 펭귄 특성의 변화를 분석하여 시간에 따른 추세를 파악한다.
펭귄데이터에 대한 EDA를 통해서 다음과 같은 가설을 설정하고 추가 연구를 수행할 수도 있다.
- 환경적 요인과 펭귄의 특성 간의 관계 분석: 젠투 펭귄의 큰 체구가 그들이 서식하는 환경과 어떻게 관련이 있는지 조사할 수 있다. 예를 들어, 더 거친 해양 조건에서 더 큰 체구가 생존에 유리한가를 분석한다.
- 식단과 체구의 관계 연구: 다양한 펭귄 종의 식단이 체구, 특히 물갈퀴 길이와 체중에 어떠한 영향을 미치는지 분석해볼 수 있다. 펭귄의 영양 섭취와 신체 발달 간의 연관성을 밝힐 수 있다.
- 기후 변화가 펭귄 종에 미치는 영향: 기후 변화가 각 펭귄 종의 서식지 분포와 체구 변화에 어떤 영향을 미치는지 연구할 수 있다. 기후 변화로 인한 서식지 축소나 식량 자원의 변화가 펭귄의 생물학적 특성에 영향을 미치는지 분석하는 것이다.
11.2 R 코드
11.3 shiny 앱
#| label: shinylive-eda-penguins
#| viewerHeight: 600
#| standalone: true
library(shiny)
library(ggplot2)
library(dplyr)
library(palmerpenguins)
ui <- fluidPage(
titlePanel("팔머 펭귄 탐색적 데이터 분석"),
sidebarLayout(
sidebarPanel(
selectInput("species", "펭귄 종 선택:",
choices = c("모든 종", unique(as.character(penguins$species))),
selected = "모든 종"),
selectInput("x_var", "X 축 변수 선택:",
choices = c("부리 길이 (mm)", "부리 깊이 (mm)", "물갈퀴 길이 (mm)", "체중 (g)"),
selected = "부리 길이 (mm)"),
selectInput("y_var", "Y 축 변수 선택:",
choices = c("부리 길이 (mm)", "부리 깊이 (mm)", "물갈퀴 길이 (mm)", "체중 (g)"),
selected = "부리 깊이 (mm)"),
br(),
helpText(
tags$h3("팔머 펭귄 EDA"),
tags$p("팔머 펭귄 데이터셋을 활용하여 펭귄 종류 간의 신체적 차이와 변수 간 상호작용을 시각적으로 탐색합니다."),
tags$ul(
tags$li("펭귄 종 선택: 아델리, 턱끈, 젠투 중 흥미로운 종을 선택하세요."),
tags$li("변수 설정: X축과 Y축에 표시할 신체 측정치(부리 길이, 부리 깊이, 물갈퀴 길이, 체중)를 선택합니다."),
tags$li("분석 결과: 선택된 변수에 따라 데이터 테이블, 요약 통계, 그리고 산점도가 업데이트되어 데이터의 분포를 확인할 수 있습니다."),
tags$li("인터랙티브 시각화: 데이터와 통계를 통해 펭귄의 생물학적 특성을 이해하고 비교 분석할 수 있습니다.")
),
tags$p("이 앱을 통해 팔머 펭귄 데이터셋을 직관적이고 상호작용적으로 탐색하면서 통계적 분석과 데이터 시각화 기법을 체험할 수 있습니다.")
)
),
mainPanel(
tabsetPanel(
tabPanel("데이터", tableOutput("data")),
tabPanel("요약 통계량", verbatimTextOutput("summary")),
tabPanel("시각화", plotOutput("plot"))
)
)
)
)
server <- function(input, output) {
filtered_data <- reactive({
if (input$species == "모든 종") {
penguins %>%
select(species, bill_length_mm, bill_depth_mm, flipper_length_mm, body_mass_g)
} else {
penguins %>%
filter(species == input$species) %>%
select(bill_length_mm, bill_depth_mm, flipper_length_mm, body_mass_g)
}
})
output$data <- renderTable({
filtered_data() %>%
rename("부리 길이 (mm)" = bill_length_mm,
"부리 깊이 (mm)" = bill_depth_mm,
"물갈퀴 길이 (mm)" = flipper_length_mm,
"체중 (g)" = body_mass_g)
})
output$summary <- renderPrint({
summary(filtered_data())
})
output$plot <- renderPlot({
x_var <- switch(input$x_var,
"부리 길이 (mm)" = "bill_length_mm",
"부리 깊이 (mm)" = "bill_depth_mm",
"물갈퀴 길이 (mm)" = "flipper_length_mm",
"체중 (g)" = "body_mass_g")
y_var <- switch(input$y_var,
"부리 길이 (mm)" = "bill_length_mm",
"부리 깊이 (mm)" = "bill_depth_mm",
"물갈퀴 길이 (mm)" = "flipper_length_mm",
"체중 (g)" = "body_mass_g")
if (input$species == "모든 종") {
ggplot(filtered_data(), aes_string(x = x_var, y = y_var, color = "species")) +
geom_point() +
geom_smooth(method = "lm", se = FALSE) +
labs(x = input$x_var, y = input$y_var, title = "펭귄 종 간 산점도") +
theme_minimal()
} else {
ggplot(filtered_data(), aes_string(x = x_var, y = y_var)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE) +
labs(x = input$x_var, y = input$y_var, title = paste(input$species, "산점도")) +
theme_minimal()
}
})
}
shinyApp(ui, server)