7 데이터 수집
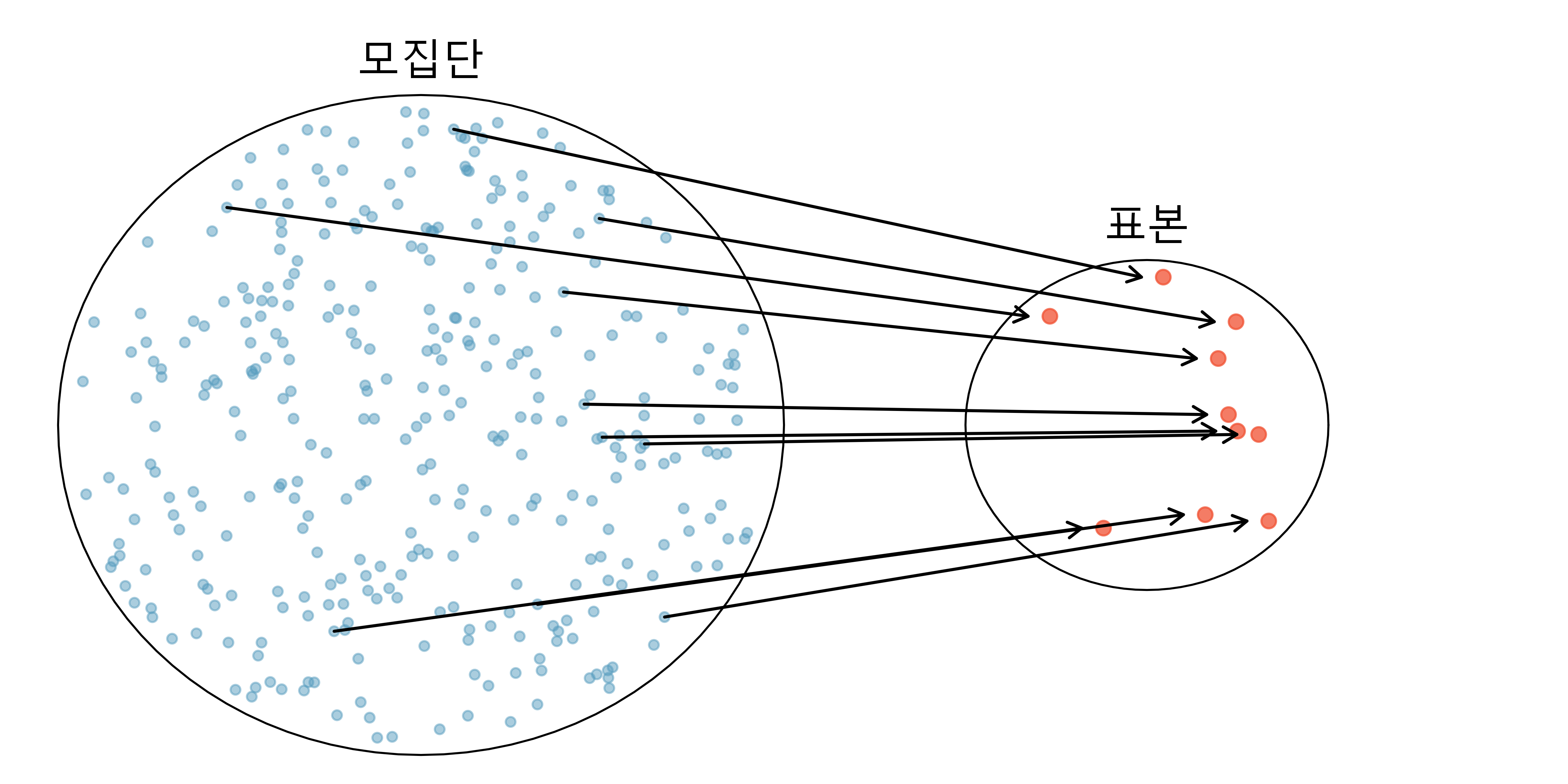
통계학은 계획을 세우고, 자료를 수집, 분석하여 결론을 도출하는 가장 좋은 방법을 연구하는 학문이다. 과학기술 연구자와 실무자가 관찰 노트, 설문조사, 실험, 문헌연구 등에서 수집되며 통계 조사와 연구의 기반이 되는 것을 자료(데이터)라고 부른다.
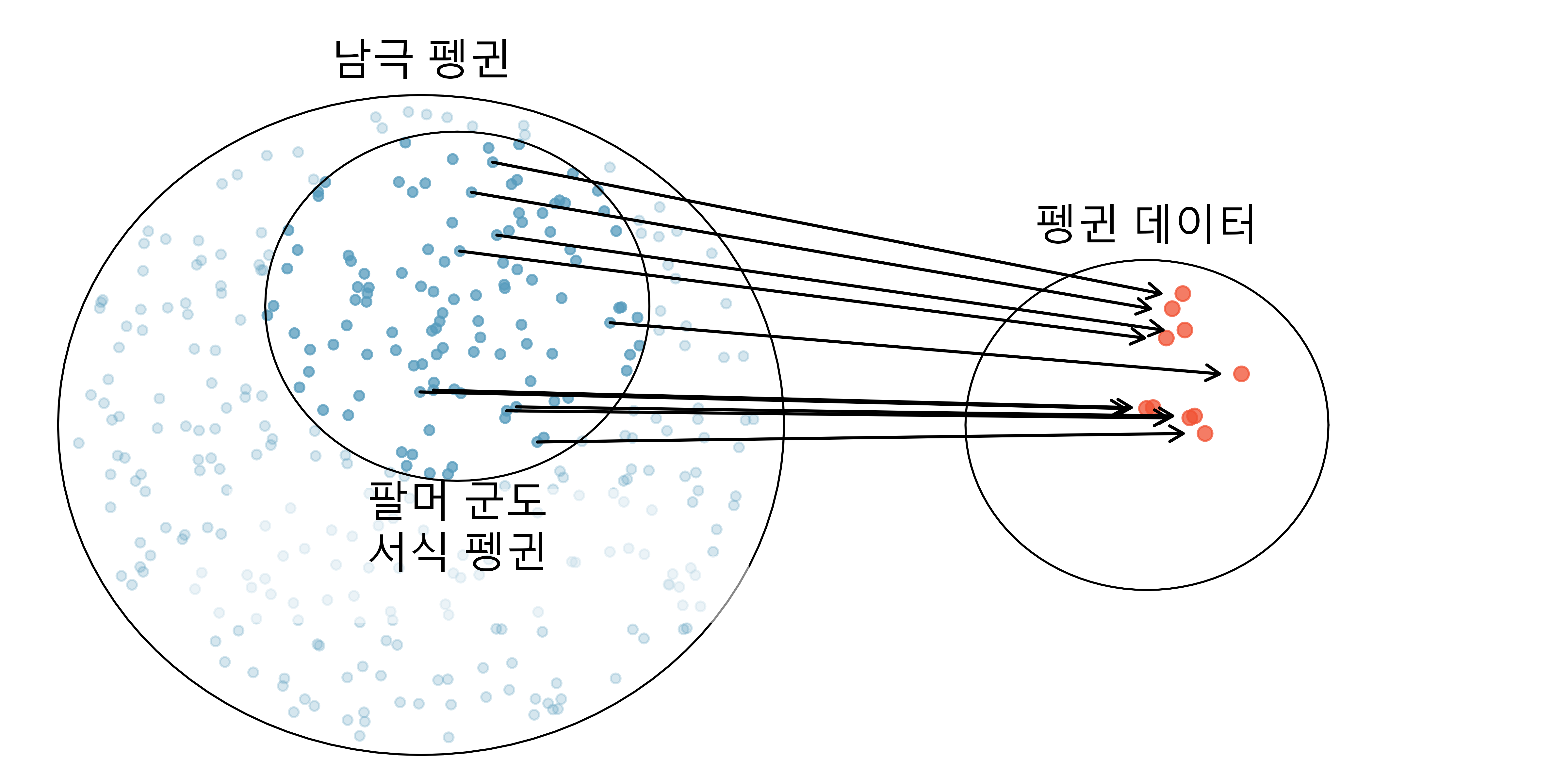
8 깔끔한 데이터
#> # A tibble: 6 × 8
#> 종명칭 섬이름 부리_길이 부리_깊이 물갈퀴_길이 체중 성별 연도
#> <fct> <fct> <dbl> <dbl> <int> <int> <fct> <int>
#> 1 아델리 토르거센 39.1 18.7 181 3750 수컷 2007
#> 2 아델리 토르거센 39.5 17.4 186 3800 암컷 2007
#> 3 아델리 토르거센 40.3 18 195 3250 암컷 2007
#> 4 아델리 토르거센 36.7 19.3 193 3450 암컷 2007
#> 5 아델리 토르거센 39.3 20.6 190 3650 수컷 2007
#> 6 아델리 토르거센 38.9 17.8 181 3625 암컷 2007표에 각 행은 단일 펭귄 혹은 사례(case)를 표현한다. 칼럼(열, column)은 각 펭귄에 대한 변수(variable)라고 불리며, 특성을 표현한다. 예를 들어, 첫번째 행은 1번 펭귄으로, 아델리 종이고, 토르거센 섬에 서식하며, 부리 길이 39.1mm, 부리 깊이 18.7mm, 날개 길이 181mm, 체질량 3750g, 수컷임을 나타낸다.
데이터 사전(data dictionary)은 데이터셋에 대한 변수, 열 또는 필드에 대한 정의와 설명을 포함하는 문서다. 데이터 과학자, 분석가, 기계학습 개발자/연구자 및 유관 이해 관계자에게 전체적인 맥락과 명확성을 제공하는 데 사용된다.
일반적인 데이터 사전에는 각 변수에 대한 다음 정보가 포함된다.
- 변수명(Variable): 변수, 열 또는 필드의 이름 또는 레이블.
- 데이터 유형(Data Type): 숫자, 범주형 또는 텍스트와 같은 자료형.
- 설명(Description): 변수가 나타내는 것이나 측정값에 대한 간단한 설명이 기술된다.
- 측정 단위(Unit): 해당하는 경우 변수의 측정 단위 (예를 들면, cm, kg, …)
- 출처(Data Scource): 데이터베이스 또는 외부 소스와 같은 원데이터의 출처.
- 결측값 코드(Missing Value Code): 결측 데이터를 나타내는 데 사용되는 코드 또는 값.
- 값(Value): 변수에 사용할 수 있는 값 또는 범주와 의미 등.
- 예제: 데이터셋 예제
팔머 펭귄 데이터에 대한 데이터 사전을 아래와 같이 만들어 제작할 수 있다. k_penguins_tbl 데이터 사전은 palmerpenguins 패키지에 포함된 penguins 데이터셋의 각 변수에 대한 정보를 한글로 번역하여 제공된다. 변수명, 자료형, 변수 설명, 측정 단위, 데이터 출처, 결측값 코드, 가능한 값의 범위와 예시 등이 포함되어 있어 데이터셋을 이해하고 활용하는 데 도움이 된다.
| 변수명 | 자료형 | 설명 | 측정단위 | 자료출처 | 결측값 | 값 | 사용례 |
|---|---|---|---|---|---|---|---|
| 종명칭 | 범주형 | 펭귄의 종 | - | Palmer Station LTER | NA | 아델리, 턱끈, 젠투 | 아델리, 턱끈, 젠투 |
| 섬이름 | 범주형 | 펭귄이 서식하는 섬 | - | Palmer Station LTER | NA | 비스코, 드림, 토르거센 | 비스코, 드림, 토르거센 |
| 부리_길이 | 숫자형 | 부리의 길이 | 밀리미터(mm) | Palmer Station LTER | NA | 32.1-59.6 | 39.1, 39.5, 40.3, 36.7 |
| 부리_깊이 | 숫자형 | 부리의 깊이 | 밀리미터(mm) | Palmer Station LTER | NA | 13.1-21.5 | 18.7, 17.4, 18.0, 19.3 |
| 물갈퀴_길이 | 숫자형 | 날개의 길이 | 밀리미터(mm) | Palmer Station LTER | NA | 172-231 | 181, 186, 195, 193 |
| 체중 | 숫자형 | 펭귄의 체질량 | 그램(g) | Palmer Station LTER | NA | 2700-6300 | 3750, 3800, 3250, 3450 |
| 성별 | 범주형 | 펭귄의 성별 | - | Palmer Station LTER | NA | 수컷, 암컷 | 수컷, 암컷, 수컷, 암컷 |
| 연도 | 정수형 | 조사 연도 | - | Palmer Station LTER | NA | 2007, 2008, 2009 | 2007, 2007, 2007, 2007 |
데이터를 데이터 행렬(data matrix), 데이터프레임(dataframe)을 표현하는데 데이터를 구조화하는 일반적인 방법으로 데이터 행렬 각 행은 단일 사례에 대응되고, 각 칼럼은 변수에 대응된다.
데이터 행렬은 데이터를 기록하고 저장하는 편리한 방법이다. 만약 또다른 펭귄 혹은 사례가 데이터셋에 추가되면, 쉽게 부가적으로 행을 추가할 수 있다. 유사하게, 또다른 칼럼도 신규 변수로 추가될 수 있다.
8.1 변수 유형
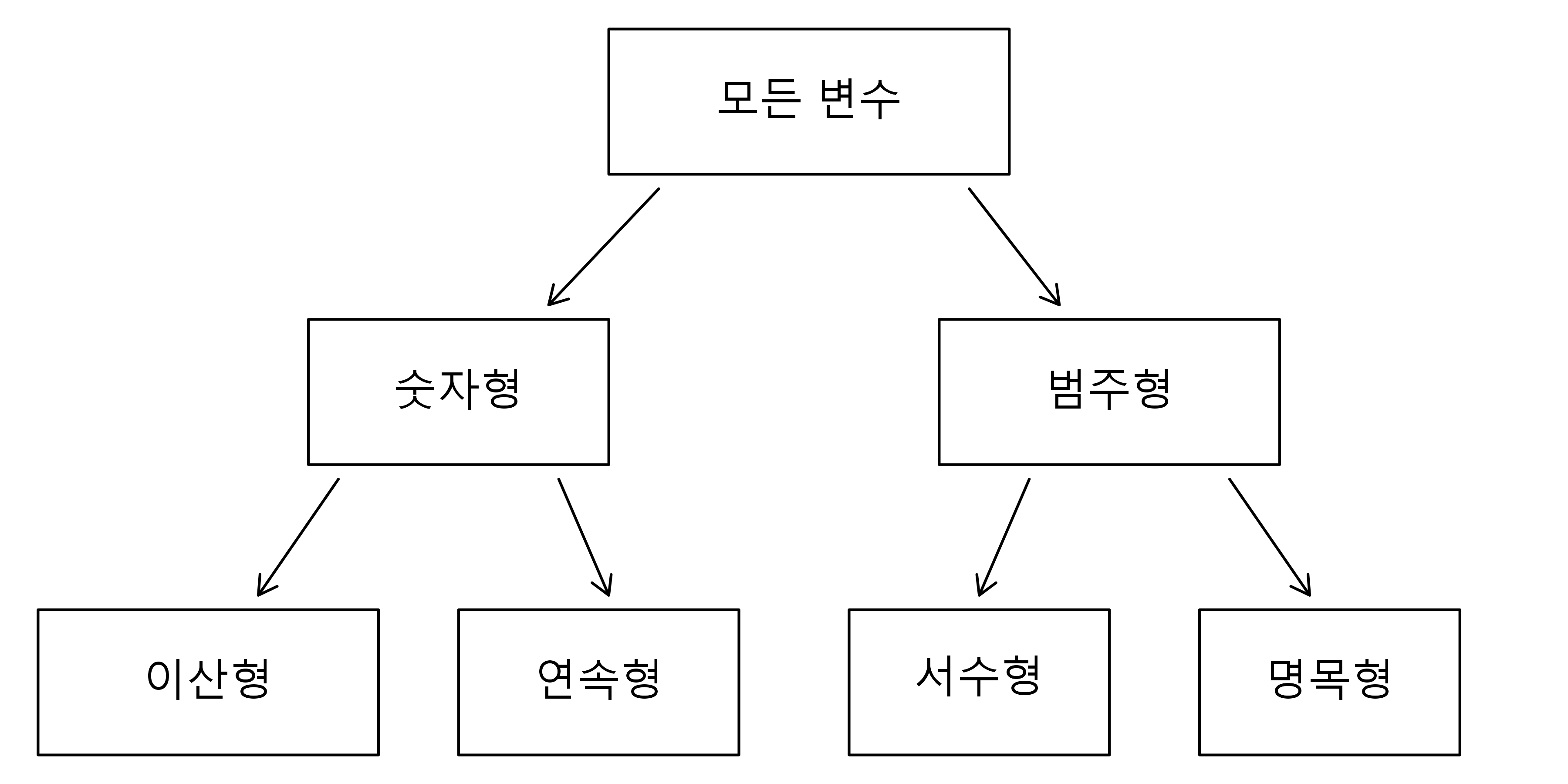
k_penguins_tbl 데이터셋을 구성하는 종명칭, 섬이름, 부리_길이, 성별 변수를 살펴보자. 각 변수는 본질적으로 서로 다르지만 특정한 성질은 공유한다.
먼저, 부리_길이를 살펴보자. 부리_길이 변수는 폭넓은 숫자값을 취할 수 있고, 더하고 빼고 평균을 계산할 수 있어 숫자형(numerical) 변수로 불린다.
부리_길이와 유사하게, 물갈퀴_길이 변수도 숫자형이다. 이 변수는 연속형(continuous)이라고 불리기도 한다.
종명칭 변수는 아델리, 턱끈, 젠투 세 값 중 하나만 가질 수 있다. 변수값 자체로 범주형이기 때문에, 종명칭은 범주형(categorical) 변수라고 불린다. 가능한 값을 변수 수준(levels)이라고 부른다.
마지막으로 성별 변수를 생각해 보자. 성별 변수는 펭귄의 성별을 ’수컷’과 ’암컷’으로 구분한다. 따라서 성별 변수 역시 범주형 변수이다.
8.2 변수 사이 관계
연구자들은 두 개 혹은 그 이상의 변수 사이의 관계를 찾으려는 동기로 분석을 시작한다. 팔머 펭귄 데이터셋을 분석하는 연구자는 다음과 같은 질문에 대답하고 싶어할 것이다:
부리의 길이가 깊이와 평균적으로 양의 상관관계를 갖는가?
젠투 펭귄의 몸무게가 아델리와 턱끈 펭귄보다 평균적으로 더 무거운가?
펭귄의 날개 길이가 몸무게와 양의 상관관계를 갖는가?
이러한 질문에 대답하기 위해서, penguins 데이터셋 같은 데이터가 수집되어야 한다. 요약 통계량을 조사하여 펭귄의 종별로 상기 3개 질문에 대한 통찰을 얻을 수 있다. 추가적으로, 그래프를 사용해서 데이터를 시각적으로 요약할 수 있고, 상기 질문에 답하는 데도 유용하다.
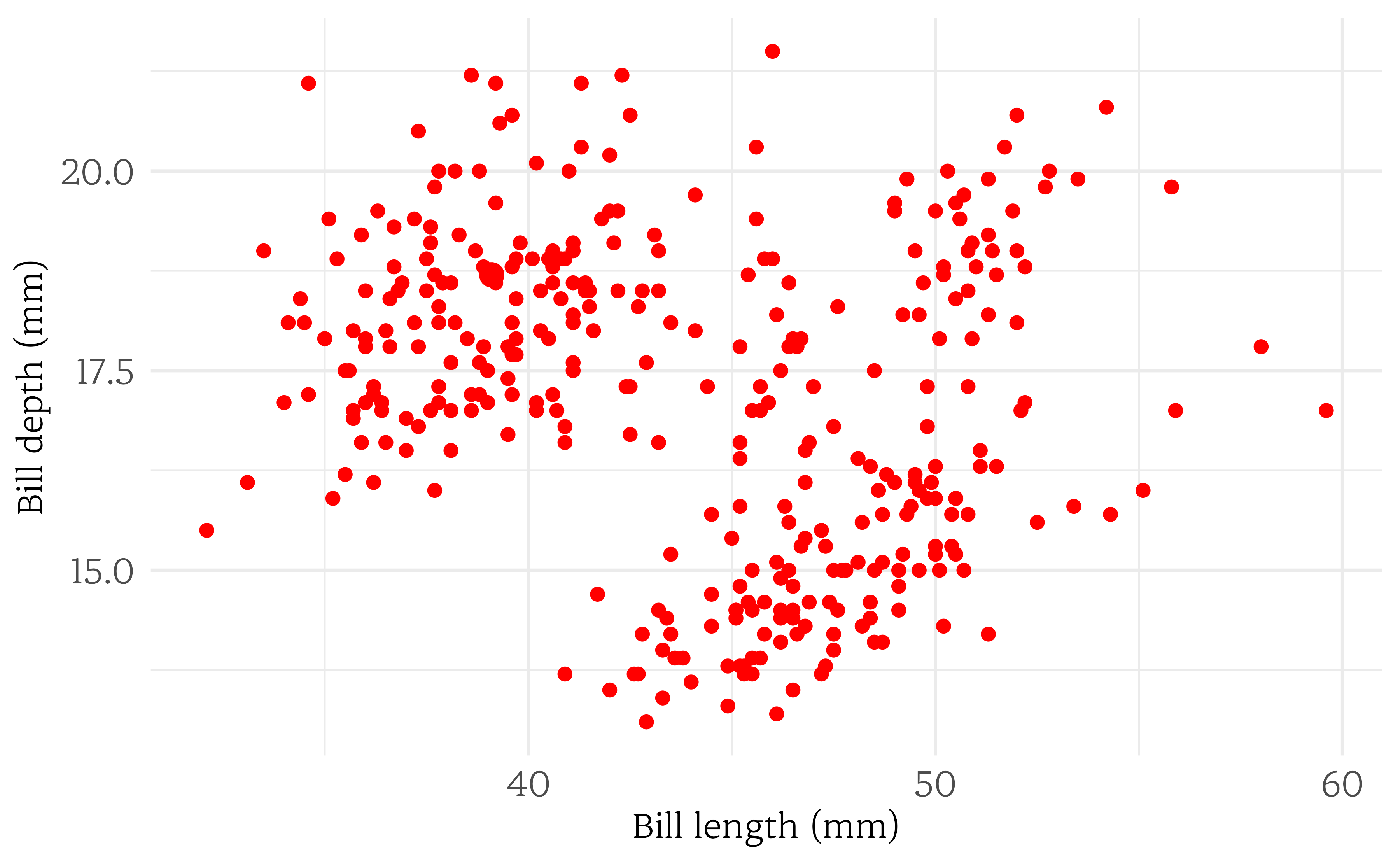
산점도는 두 숫자형 변수 사이의 관계를 조사하는 데 사용되는 일종의 그래프다. 그림 @ref(fig:bill-depth-length)은 bill_length_mm 변수와 bill_depth_mm 변수를 비교한다. 플롯에서 각 점은 단일 펭귄을 나타낸다. 예를 들어, 부각된 점은 penguins 데이터셋에서 첫 번째 펭귄으로, Torgersen 섬에 서식하는 Adelie 펭귄으로 부리 길이 39.1mm, 부리 깊이 18.7mm임을 나타낸다. 산점도를 통해서 두 변수 사이에 양의 상관관계가 있음을 유추할 수 있다. 부리 길이가 길수록 부리 깊이도 깊어지는 경향이 있다.
palmerpenguins 데이터셋에 있는 변수를 조사하여 본인 관심을 사로잡는 변수 사이의 관계에 관해 질문 2개를 만들어보세요.
- 펭귄의 날개 길이가 몸무게와 양의 상관관계를 갖는가? 즉, 날개 길이가 길수록 몸무게가 무거운 경향이 있는가?
- 펭귄의 성별에 따라 몸무게에 차이가 있는가? 즉, 수컷 펭귄이 암컷 펭귄보다 더 무거운 경향이 있는가?
bill_length_mm와 bill_depth_mm 변수는 연관(associated)되었다고 하는데 플롯을 통해 식별할 수 있는 패턴이 보이기 때문이다. 두 변수가 서로에 어떤 연관을 보일 때, 두 변수를 연관(associated) 변수라고 부른다. 연관된 변수는 또한 종속(dependent) 변수라고 불리기도 하고 역도 또한 같다.
그림 @ref(fig:mass-flipper)은 펭귄의 날개 길이와 몸무게 사이의 관계를 산점도로 시각화했다. 두 변수는 연관되었는가?
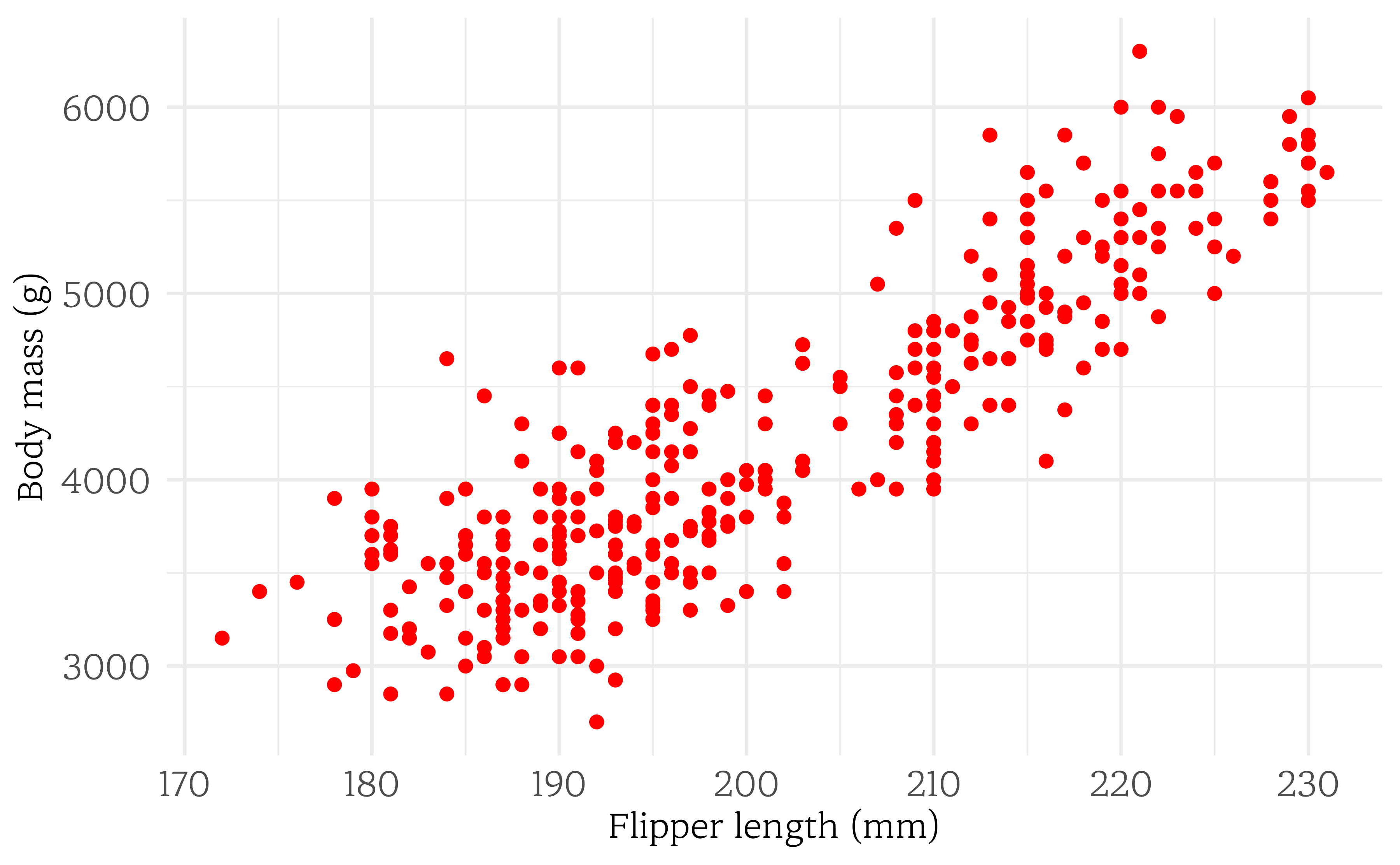
날개 길이가 길수록 몸무게가 무거워지는 경향을 보인다. 두 변수 사이에 일정한 관계가 있기 때문에, 두 변수는 연관되어 있다.
그림 @ref(fig:mass-flipper)에 우상향 경향이 보이기 때문에 – 날개 길이가 긴 펭귄이 더 무거운 경향이 있다 – 두 변수는 양의 연관성을 갖는다고 한다.
만약 두 변수가 연관되지 않는다면, 두 변수는 독립적이라고 한다. 즉, 두 변수 사이에 명백한 관계가 없다면, 두 변수는 독립이다.
8.2.1 설명 변수와 반응 변수
penguins 데이터셋에 대해 다음 질문을 생각해 보자.
펭귄의 부리 길이가 깊이와 평균적으로 양의 상관관계를 갖는가?
만약 부리의 길이가 깊이에 영향을 미친다고 의심하면, 부리 길이는 설명 변수가 되고 부리 깊이는 관계에 있어 반응 변수가 된다.
일부 경우에는 설명변수와 반응변수가 없을 수 있다. 다음 질문을 생각해보자.
펭귄의 성별에 따라 몸무게에 차이가 있는가?
어느 변수가 설명변수이며, 반응변수인지 판단하기가 어렵다. 즉, 방향성이 애매모호하다. 그래서 설명 혹은 반응 표식을 여기서는 제시할 수 없다.
8.2.2 관측연구와 실험 소개
데이터 수집에는 두 가지 유형이 있다: 관측연구와 실험.
데이터가 생성되는 방식에 직접적인 지장을 받지 않는 방식으로 데이터를 연구원이 수집할 때 관측연구를 수행한다. 예를 들어, 펭귄의 부리 길이와 깊이의 관계를 조사하기 위해서, 연구원은 펭귄을 관찰하고 측정값을 기록한다. 이러한 상황에서 연구원은 단지 자연적으로 발생한 데이터를 관측한다. 일반적으로, 관측연구는 변수 사이에 자연적으로 발생하는 연관 증거를 제공할 수 있지만, 그 자체로 인과관계를 제시할 수는 없다.
연구원이 인과관계 가능성을 조사하려면, 실험을 수행한다. 대체로 설명변수와 반응변수 모두 있다. 예를 들어, 펭귄의 먹이 섭취량을 조절하는 것이 펭귄의 몸무게에 미치는 영향을 조사할 수 있다. 설명변수와 반응변수 사이에 인과관계가 정말 있는지 검사하기 위해서, 연구원은 펭귄 표본을 수집하고 그룹으로 나눈다. 각 그룹의 펭귄은 처리(treatment)에 배정된다. 펭귄이 무작위로 그룹에 배정될 때, 해당 실험을 무작위 실험이라고 부른다. 예를 들어, 먹이 실험에서 각 펭귄을 아마도 동전 던지기를 통해서 두 그룹 중에 한 곳에 임의로 배정할 수 있다. 첫 번째 그룹은 일반 먹이를 공급받고, 두 번째 그룹은 고단백 먹이를 공급받는다. 물론 이러한 실험은 펭귄의 건강과 복지를 최우선으로 고려하여 신중하게 설계되어야 한다.
8.3 관측연구와 표본추출 전략
8.3.1 관측연구
일반적으로, 관측연구에 있어 데이터는 일어난 것을 모니터링하면서만 수집된다. 반면에, 연구의 주요 설명변수를 연구원이 각 대상마다 배정할 것을 실험에서는 요구한다.
실험에 근거해서 인과결론을 내리는 것은 합리적이다. 하지만, 관측연구에 근거해서 동일한 인과 결론을 내리는 것은 겉보기와 달리 위험하고 추천되지 않는다. 그래서, 관측연구는 일반적으로 연관만 보이는 데 충분하다.
다른 변수, 예를 들어 펭귄의 건강 상태나 나이가 날개 길이와 수영 속도 사이의 관계를 설명할 수 있다. 건강하고 나이가 적은 펭귄은 날개 길이가 길 가능성이 높고 동시에 더 빠르게 수영할 가능성이 높다. 이러한 변수가 관측연구에서 고려되지 않았을 수 있다.
펭귄의 건강 상태와 나이를 교락변수라고 부르는데, 설명변수와 반응변수 모두와 상관된 변수이기 때문이다. 관측연구로부터 도출된 인과결론을 정당화하는 방법은 교락변수를 철저히 찾는 것이지만, 모든 교락변수가 측정되거나 조사될 수 있다는 보장은 없다.
동일한 방식으로, penguins 데이터셋은 교락변수를 갖는 관측연구다. 그리고 인과결론을 도출하는 데 데이터가 쉽게 사용될 수는 없다.
\begin{exercise} 그림 @ref(fig:mass-flipper)에 펭귄의 날개 길이와 몸무게 사이에 양의 연관성이 보인다. 하지만, 두 변수 사이에 인과관계가 존재한다고 결론 내리는 것은 합리적이지 못하다. 그림 @ref(fig:mass-flipper)에 나타난 관계를 설명하는 하나 혹은 그 이상의 다른 변수를 제시하세요.
정답은 다양할 수 있다. 펭귄의 종이 중요할 수 있다. 몸집이 큰 종은 날개 길이도 길고 몸무게도 무거울 가능성이 높다. 또한 펭귄의 성별도 영향을 미칠 수 있다. 수컷 펭귄은 암컷보다 날개 길이가 길고 몸무게도 더 나갈 수 있다.
관측연구는 두 가지 형태가 있다: 전향적 연구(prospective studies)와 후향적 연구(retrospective studies).
전향적 연구는 펭귄을 식별하고 시간이 지남에 따라 정보를 수집해 나간다. 예를 들어, 연구원은 수년에 걸쳐 펭귄 집단을 추적하여 먹이의 변화가 펭귄의 건강에 미치는 잠재적 영향을 평가할 수 있다.
후향적 연구는 사건이 발생한 후에 데이터를 수집한다. 예를 들어, 연구원이 과거 기록을 통해 펭귄 개체군의 변화를 조사할 수 있다. penguins 데이터셋 같은 일부 데이터는 전향적이며 후향적 방식으로 수집된 변수를 모두 포함하고 있다. 현장 연구원은 전향적으로 사건이 전개되어 가면 일부 변수를 수집(예를 들어, 펭귄의 몸무게)하는 반면에, 다른 연구원은 후향적으로 과거 기록을 통해 변수를 수집했을 수 있다(예를 들어, 과거 펭귄 개체 수).