통계학은 실제로 데이터를 다루는 가장 오래된 학문 중 하나이며, 기본적으로 두 가지 큰 줄기, 즉 기술 통계(Descriptive Statistics)와 추론 통계(Inferential Statistics)로 나눌 수 있다. 기술 통계는 데이터를 요약하고 설명하는 데 초점을 맞추며, 추론 통계는 표본 데이터를 바탕으로 보다 큰 모집단에 대한 결론이나 예측을 하는 데 사용된다.
기계학습은 통계학의 기술 통계와 추론 통계 모두와 관련이 있지만, 그 중에서도 주로 추론 통계에 무게를 두고 있다. 기계학습의 주된 목적은 데이터를 바탕으로 모형을 구축하여 새로운 데이터에 대한 예측이나 일반화를 수행하는 것이다.
기계학습(Abu-Mostafa, Magdon-Ismail, 와/과 Lin 2012)은 다음 세 가지 사항을 기반으로 하고 있다. 패턴이 존재한다고 가정하는 부분에서 통계학의 회귀분석과 유사하나, 수학적으로 명시적으로 명세할 수 없다는 점에서 차이가 난다. 기계학습과 회귀모형은 둘 다 데이터를 기반으로 한다는 면에서 공통점을 갖는다.
패턴이 존재한다.
수학적으로 명시적으로 명세할 수 없다.
데이터를 갖고 있다.
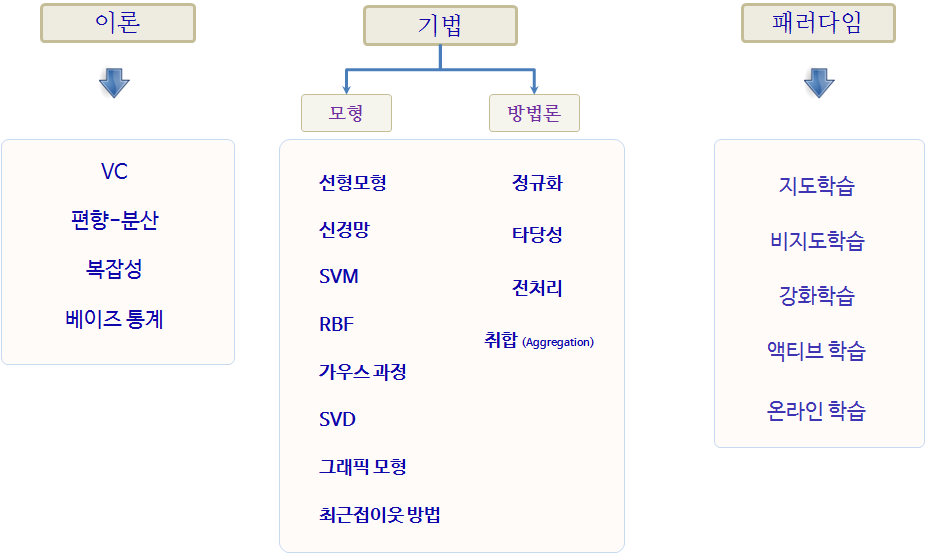
기계학습을 구성하는 이론은 편향-분산(bias-variance), 복잡성, Vapnik–Chervonenkis 이론, 베이즈 통계가 기반이 되고, 선형회귀모형을 비롯한 다양한 모형이 존재하며, 모형의 성능과 신뢰성을 높이고자 데이터 전처리, 교차 타당성(cross validation), 정규화(regularization) 등이 동원된다.
그림 12.1: 기계학습 지도
12.1 기계학습 구성요소
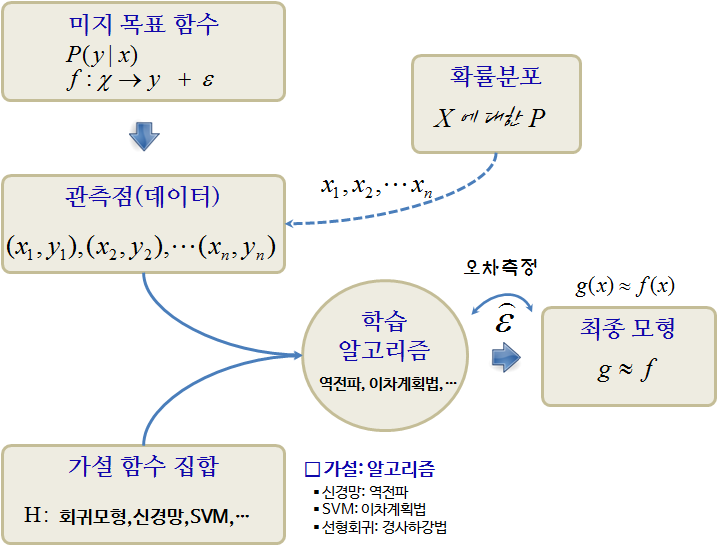
데이터 과학에서 모형은 현실 세계의 복잡한 현상을 단순화하고 추상화하여 표현하는 도구이다. 모형을 통해 데이터에 내재된 패턴과 관계를 발견하고, 미래를 예측하며, 의사 결정을 지원할 수 있다. 모형을 구축할 때, 데이터에서 진정한 신호를 추출하고 잡음을 제거하는 것을 목표로 한다. 일반 모형을 “신호 + 잡음(signal + noise)”으로 가정하고 다음과 같은 수식으로 표현할 수 있다.
\[y = f(x) + \epsilon\]
출력 : \(y\), 관심을 갖고 있는 결과변수
입력 : \(x\), 설명/예측 변수
\(y\)의 변동성을 설명하는 목적의 모형을 구축하는 경우 \(x\)는 설명변수
\(y\)의 변동성을 예측하는 목적의 모형을 구축하는 경우 \(x\)는 예측변수
가설: : \(g: x \rightarrow y\), \(x\)는 \(y\)에 영향을 주는 인과관계가 존재한다.
목적함수 : \(f: x \rightarrow y\), \(y\)와 \(x\)를 연관시켜주는 함수
오차: \(\epsilon\), \(f: x \rightarrow y\)으로 설명되지 않는 부분
결국, 잡음이 낀 데이터에서 잡음을 제거하고 신호만 뽑아내는 것이 회귀모형과 기계학습 모형이라고 볼 수 있다. 회귀모형은 특정 함수 형태를 가정하고 데이터에서 신호와 잡음을 구분하는 데 초점을 두었다면, 기계학습 모형은 \(x\)와 \(y\)의 인과관계를 가정으로 놓고 신호와 잡음을 가장 잘 구분해낼 수 있는 함수를 찾아내는 데 초점을 둔다.
그림 12.2: 기계학습 도해
12.2 기계학습 3 원칙
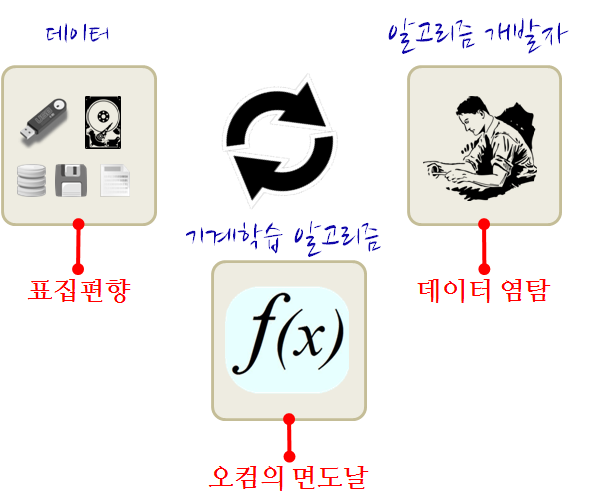
기계학습 알고리즘 개발에는 3 기본 원칙(Coelho 와/과 Richert 2015)이 적용된다. 첫째, 오컴의 면도날 원칙에 따라 더 단순하고 간결한 모형을 선택한다. 둘째, 표집 편향을 고려해 모집단을 잘 대표하는 데이터를 사용하여 정확성을 확보한다. 셋째, 데이터 염탐 편향을 회피해 알고리즘 선택을 객관적으로 한다. 1
오컴의 면도날(Occam’s Razor): 절약의 원리(Principle of Parsimony)라고도 불리며, 동일한 현상을 설명하는 여러 모형이 있을 때, 가장 단순한 모형을 선택하는 것이 좋다는 원리다. 과적합(overfitting)을 방지하고 모형의 일반화 성능을 높이는 데 도움이 된다.
표집 대표성(Sampling Representativeness): 기계학습 알고리즘을 훈련시키는 데 사용되는 데이터는 전체 모집단을 대표할 수 있어야 한다. 표집 편향(Sampling Bias)이 발생하면, 즉 훈련 데이터가 모집단을 제대로 반영하지 못하면 알고리즘의 성능 저하는 물론 일반화 능력도 떨어진다.
데이터 염탐 편향(Data Snooping Bias): 데이터를 본 후에 기계학습 알고리즘을 결정하는 것으로, 사실 데이터를 보기 전에 기계학습 알고리즘을 선정해야 한다. 데이터를 보고 나서 알고리즘을 선택하면, 데이터에 포함된 편향이나 패턴을 알고리즘이 학습할 수 있기 때문에 일반화 능력이 떨어진다.
그림 12.3: 기계학습 세 가지 원칙
중요한 세 가지 원칙
데이터에 기반한 모형 개발에서 준수해야 할 세 가지 원칙은 다음과 같다.
오컴의 면도날
동일한 조건이라면 더 단순한 것을 선택하는 것으로, 가장 큰 이유는 갖고 있는 데이터를 벗어나 새로운 데이터를 갖게 될 경우 학습시킨 기계학습 알고리즘이 더 좋은 성능을 보인다는 것이다. 결국 수많은 가능한 모형 중에서 하나를 선택하는 기준이 된다.
An explanation of the data should be made as simple as possible, but no simpler – Albert Einstein
표집 편향 제거
1948년 미국 대통령선거에서 트루먼이 듀이 후보를 물리치고 대통령이 된 것은 잘 알려진 사실이다. 하지만 대부분의 여론조사에서 듀이의 승리를 예상했지만, 실제로는 그 반대의 결과가 나타났다. 그 당시 여론조사는 전화기를 사용하였는데, 문제는 전화기를 부유층이 많이 소유하고 있어 미국 대통령선거 모집단을 대표하는 데 문제가 있어 왜곡된 결과가 도출된 것이다.
상업적으로 개인금융의 신용카드 발급, 신용평가에도 동일한 문제가 발생한다. 수익성은 저신용자가 높아 이를 살펴보면, 신용평가에 사용될 데이터는 저신용자는 카드를 발급받을 수 없어 데이터베이스에는 표집 편향된 고객 정보만 존재하는 것을 어렵지 않게 볼 수 있다.
If the data is sampled in a biased way, learning will produce a similarly biased outcome.
데이터 염탐 편향 제거
데이터를 본 후에 기계학습 알고리즘을 결정하는 것으로, 사실 데이터를 보기 전에 기계학습 알고리즘을 선정해야 하지만, 현실적으로 현업에서 작업하는 사람들이 흔히 범하는 실수다. 동일한 데이터에 대해 갖가지 기계학습 알고리즘을 적용해서 가장 좋은 성능이 나오는 알고리즘을 선정한다. 문제는 데이터가 바뀌면 어떨까? 아마 기대했던 성능이 나오지 못할 가능성이 크다.
If you torture the data long enough, it will confess
12.3 모형 개발과정
통계모형 개발과정은 데이터 과학 프로세스에서 크게 차이가 나지 않는다. 다만, 일반적인 통계모형을 개발할 경우 다음과 같은 과정을 거치게 되고, 지난한 과정이 될 수도 있다.
데이터를 정제하고, 모형에 적합한 데이터(R/파이썬과 모형 패키지와 소통이 될 수 있는 데이터 형태)가 되도록 준비한다.
변수에 대한 분포를 분석하고 기울어짐이 심한 경우 변수 변환도 적용한다.
변수와 변수 간에, 종속변수와 설명변수 간에 산점도와 상관계수를 계산한다. 특히 변수 간 상관관계가 \(r > 0.9\) 혹은 그 근처인 경우 변수를 빼거나 다른 방법을 강구한다.
동일한 척도로 회귀계수를 추정하고 평가하려는 경우, scale() 함수로 척도를 표준화한다.
모형을 적합시킨 후에 잔차를 보고, 백색잡음(white noise)인지 확인한다. 만약, 잔차에 특정한 패턴이 보이는 경우 패턴을 잡아내는 모형을 새로 개발한다.
plot() 함수를 사용해서 이상점이 있는지, 비선형 관계를 잘 잡아냈는지 시각적으로 확인한다.
다양한 모형을 적합시키고 \(R^2\) 와 RMSE, 정확도 등 모형 평가 결과가 가장 좋은 것을 선정한다.
절약의 원리(principle of parsimony)를 반드시 준수하여 가장 간결한 모형이 되도록 노력한다.2
최종 모형을 선택하고 모형에 대한 해석 결과와 더불어 신뢰구간 정보를 넣어 마무리한다.
키보드로 통계모형 표현하기
수학적 표현을 프로그래밍 언어(R, 파이썬 등)로 전환하는 필요성은 키보드 입력의 제한성 때문에 발생한다. 키보드 특수문자를 최적으로 활용하여, R에서의 구현은 아래와 같이 가장 읽기 쉽고 입력하기 편리한 형식으로 다음과 같이 정리할 수 있다.
주효과에 대해 변수를 입력으로 넣을 때는 +를 사용한다.
교호작용을 변수 간에 표현할 때는 :를 사용한다. 예를 들어 x*y는 x+y+x:z와 같다.
모든 변수를 표기할 때는 .을 사용한다.
종속변수와 예측변수를 구분할 때는 ~을 사용한다. y ~ .은 데이터 프레임에 있는 모든 변수를 사용한다는 의미다.
특정 변수를 제거할 때는 -를 사용한다. y ~ . -x는 모든 예측변수를 사용하고, 특정 변수 x를 제거한다는 의미다.
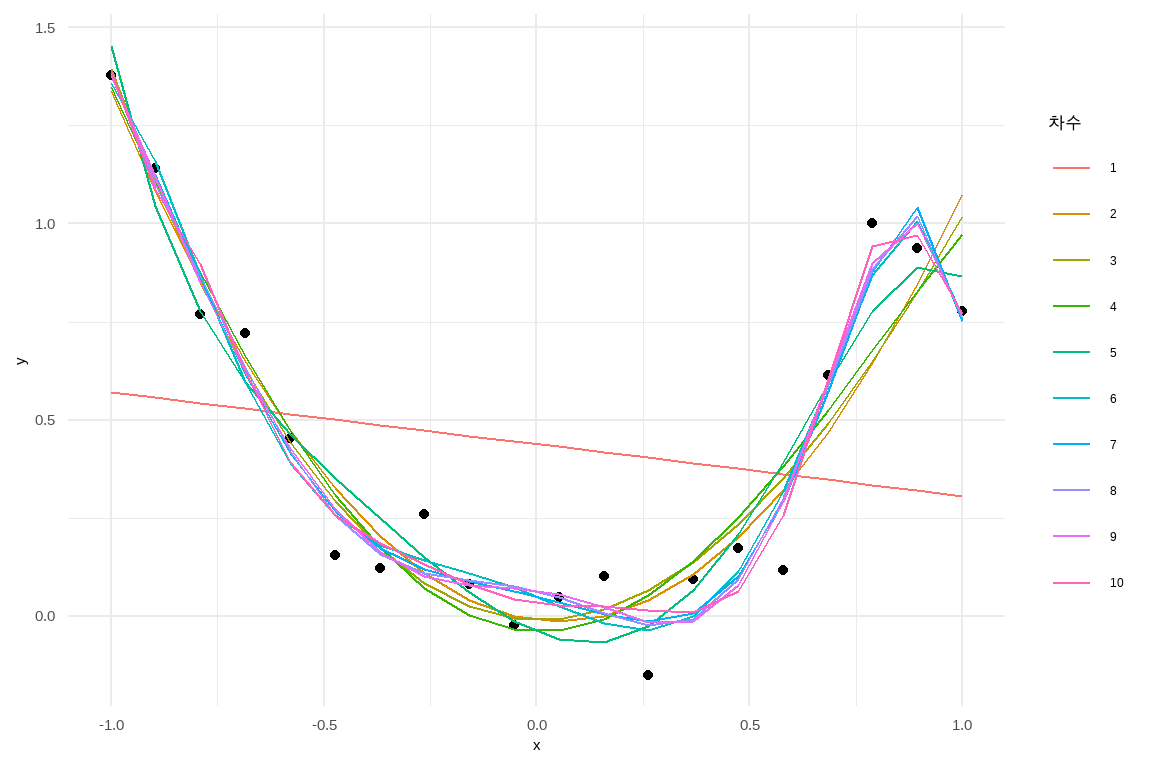
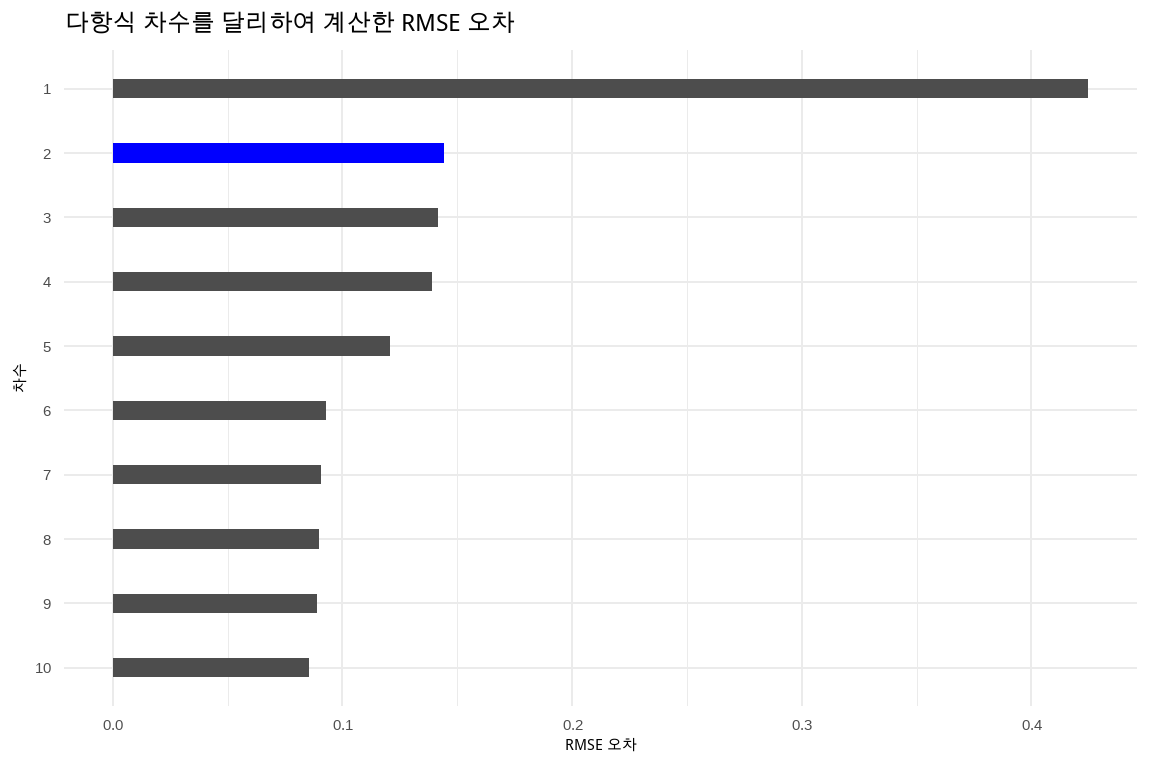
다항식 차수를 달리하여 데이터에 1~10차 다항식을 적합시킨 후에 오차를 계산했다. 1차보다 2차 다항식으로 적합시킬 때 오차가 확연히 줄어들지만 그 이후에는 오차의 감소폭이 크지는 않다. 물론 오차는 다항식 차수를 높일수록 낮아지지만 절약성의 원칙을 생각하면 이와 같은 고차 다항식 함수가 필요한지는 의문이다.
비즈니스 문제를 기계학습 문제로 전환하는 것은 데이터 기반 의사결정을 강화하고 비즈니스 전략을 최적화하는 데 핵심적인 역할을 한다. 고객 구매 패턴의 예측, 고객 세분화를 통한 효율적인 마케팅 전략 개발, 추천 시스템을 통한 맞춤형 서비스 제공, 사기 탐지를 통한 위험 관리, 가격 탄력성 분석을 통한 수익 극대화, 인기 제품 식별 및 마케팅 캠페인 효과 분석 등은 기계학습을 활용함으로써 비즈니스의 효율성과 경쟁력을 향상시킬 수 있다.
비즈니스 문제
기계학습 문제
기계학습 기법
마케팅 효율성 향상을 위한 고객 세분화와 타겟 마케팅
유사한 특성을 가진 고객 그룹 식별 및 그룹별 마케팅 전략 수립
군집 분석
온라인 쇼핑몰의 맞춤형 제품 추천을 통한 매출 증대
유사한 취향의 고객 구매 패턴 분석 및 개인화 제품 추천 제공
협업 필터링
소매 기업의 적절한 재고 유지와 판매 기회 손실 최소화
과거 판매 데이터 기반 미래 수요 예측 및 재고 관리 전략 수립
시계열 분석, 회귀 분석
금융 기관의 사기성 거래 및 이상 거래 실시간 탐지
정상 거래 패턴에서 벗어나는 이상 거래 식별 및 실시간 모니터링/대응 시스템 구축
이상치 탐지
서비스 기업의 고객 이탈 사전 예측 및 대응을 통한 고객 유지율 향상
과거 고객 데이터 분석을 통한 이탈 가능성 높은 고객 식별 및 맞춤형 고객 유지 전략 수립/실행
분류
다양한 비즈니스 문제를 기계학습 문제로 변환하고, 각 문제에 적합한 기계학습 기법을 적용함으로써 기업은 데이터로부터 통찰력을 확보하는 데 그치지 않고, 실질적인 비즈니스 가치를 창출하고 시장에서의 성공 가능성을 높일 수 있다.
12.6 요약
기계학습은 데이터에 내재된 패턴을 찾아내고 이를 기반으로 예측이나 의사결정을 수행하는 것을 목표로 한다. 기계학습 알고리즘 개발에는 오컴의 면도날, 표집 대표성, 데이터 염탐 편향 회피 등 세 가지 기본 원칙이 적용된다.
통계 모형 개발 과정은 데이터 준비, 탐색적 데이터 분석, 모형 적합, 모형 평가 및 선택의 단계를 거친다. 이 과정에서는 데이터 전처리, 변수 변환, 상관관계 분석 등 다양한 기법이 활용된다. 또한 과적합을 방지하고 모형의 일반화 성능을 높이기 위해 예시로 다항식 차수를 적절히 선택하는 사례를 통해 설명하였다.
기계학습은 비즈니스 문제 해결에 핵심적인 역할을 한다. 고객 세분화, 맞춤형 추천, 수요 예측, 이상 거래 탐지, 고객 이탈 예측 등 다양한 분야에서 기계학습 기법이 활용되고 있다. 기업은 비즈니스 문제를 기계학습 문제로 변환하고 적합한 알고리즘을 적용함으로써 데이터 기반 의사결정을 강화하고 경쟁력을 높일 수 있다.
그림 12.1: 기계학습 지도그림 12.2: 기계학습 도해그림 12.3: 기계학습 세 가지 원칙그림 12.4: 다항식 차수에 따른 과적합 모형 시각화그림 12.5: 다항식 모형 식별
Abu-Mostafa, Yaser S, Malik Magdon-Ismail, 와/과 Hsuan-Tien Lin. 2012. Learning from data. Vol 4. AMLBook New York.
Coelho, Luis Pedro, 와/과 Willi Richert. 2015. Building machine learning systems with Python. Packt Publishing Birmingham.
간결성 원칙으로도 번역되며, 오캄의 면도날(“Occam’s razor”)이라는 이름으로도 알려져 있다. 연구나 문제 해결의 맥락에서 가장 단순한 설명이나 가설을 우선적으로 고려해야 한다는 의미로, 두 개 이상의 설명이 관찰된 현상을 동등하게 설명할 수 있을 때, 더 적은 가정이 필요한 또는 더 단순한 설명을 선호해야 한다는 것이다.↩︎