graph TB
subgraph Software["<strong>좋은 소프트웨어 개발</strong>, 챗GPT"]
subgraph 이해하기
모형 --> 시각화
변환 --> 모형
시각화 --> 변환
end
가져오기 --> 깔끔화 --> 이해하기
이해하기 --> 의사소통
end
classDef modern fill:#fff,stroke:#333,stroke-width:2px,color:#333,font-family:MaruBuri,font-size:12px;
classDef emphasize fill:#8CBDE3,stroke:#333,stroke-width:3px,color:#333,font-family:MaruBuri,font-size:15px,font-weight:bold;
classDef subgraphStyle fill:#f0f8ff,stroke:#333,stroke-width:2px,color:#333,font-family:MaruBuri,font-size:15px;
class 가져오기,깔끔화,변환,모형,시각화,의사소통 modern
class 이해하기 subgraphStyle
1 데이터 과학 운영체제
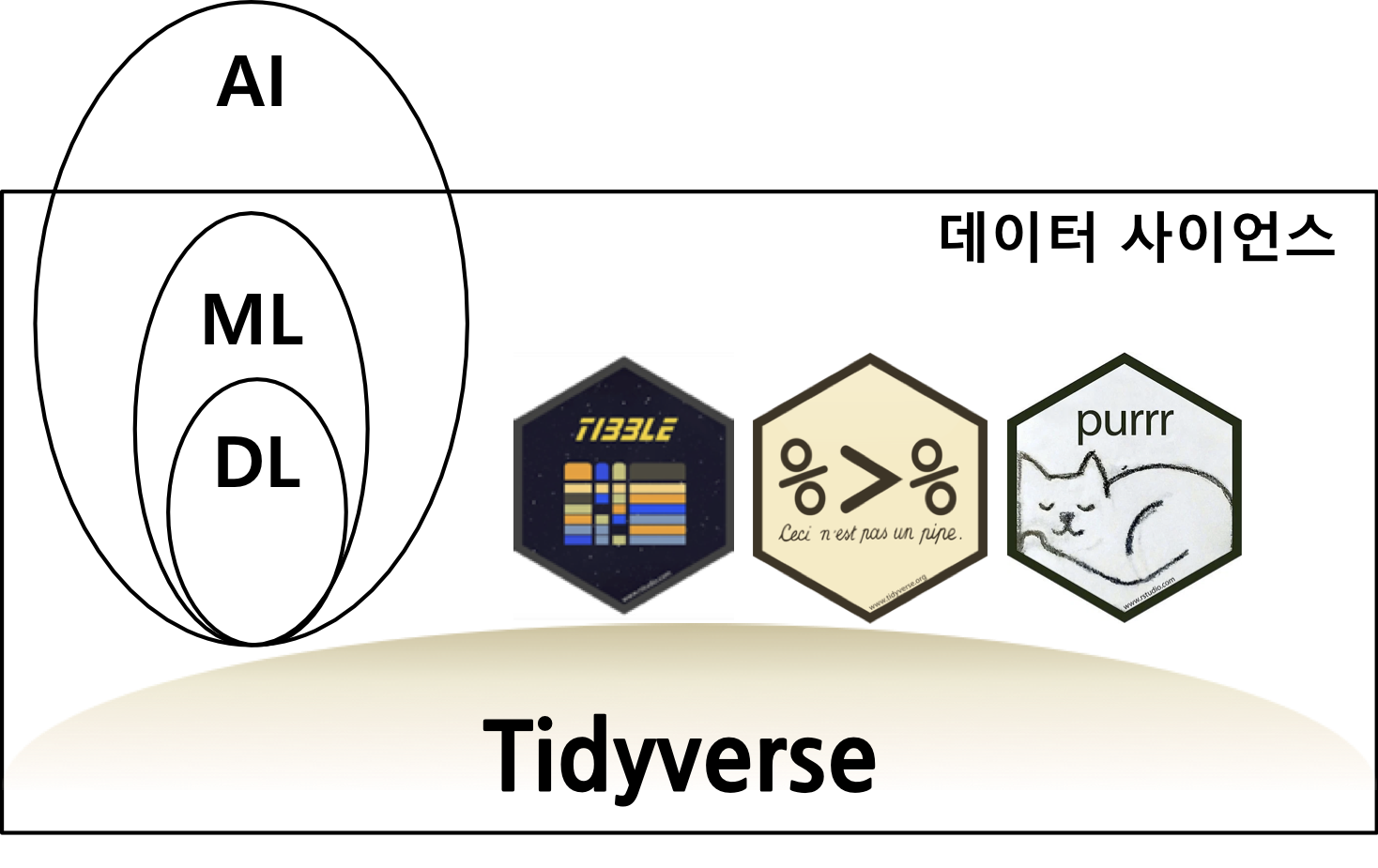
이세돌 9단이 2016년 4월 딥마인드에서 제작한 알파고에 의해 패배하면서 한국 사회는 인공지능(AI)에 폭발적인 관심을 가지게 되었고 통계학도 예외는 아니다. 알파고가 차용한 기술은 딥러닝 기술이고 딥러닝(Deep Learning, DL) 기술은 기계학습(Machine Learning, ML)을 구성하는 일부이며, 기계학습도 인공지능의 일부다. 기계학습도 회귀모형과 수학적인 공통기반을 갖고 있다는 점에서 통계학과 깊은 관련을 맺고 있다. 따라서, ML/DL 예측 모형도 데이터 사이언스의 탄탄한 이론적인 토대 없이는 지속적인 발전에 한계가 있다. 최근 인기를 얻고 있는 기계학습(Machine Learning)이나 인공지능(AI)과는 별개로 몇 년 전부터 RStudio의 해들리 위컴(Hadley Wickham) 박사는 tidyverse을 통해 데이터 사이언스(Wickham, Çetinkaya-Rundel, 와/과 Grolemund 2023)를 새롭게 정의하는 시도를 하였고 많은 이론 통계학자와 실무자로부터 호응을 얻고 있었다. 이러한 기여를 인정받아 얼마 전 통계학의 노벨상이라고 불리는 COPSS 상을 해들리 위컴이 수상하면서 순수 이론 중심의 통계학도 데이터 사이언스를 적극 포용하는 출발을 공식적으로 알리는 계기가 되었다.
1.1 패러다임 변화
정보를 잃지 않고 압축하거나 최대한 많은 정보를 추출하고자 하는 노력으로 통계학 이론들이 많이 활용되었지만, 최근에는 기계학습/딥러닝을 통해 다양한 통계 모형이 이론적인 면뿐만 아니라 실무에서도 많이 사용되고 있다. 이런 점에서 만 개가 넘는 R 패키지가 개발되어 활용된다는 점은 긍정적이지만, 각자의 설계 원칙에 맞춰 제각기 개발되고, 손을 바꿔 여러 다른 사람이 유지보수하게 되면서 초기에 세워진 설계 원칙과 철학이 많이 무너진 점이 지속 가능한 데이터 사이언스 발전을 가로막고 있는 커다란 장애물로 떠올랐다. 이를 인지한 데이터 과학자는 다수 존재하지만, 이를 체계적으로 실제 활용할 수 있도록 아마도 가장 크게 기여한 분을 꼽으라면 다들 “해들리 위컴”(Hadley Wickham)을 언급하는 데 주저하지 않을 것이다. tidyverse는 수많은 기여자의 도움을 받아 해들리 위캄이 오랜 동안 나름대로의 방식으로 체계화시킨 것을 확대 발전시킨 것으로 데이터 사이언스를 체계적으로 집대성하였다는 평가를 받고 있다. 특히, 데이터 과학자 및 실무자에게 큰 도움을 주었는데, 어떻게 보면 기존 SAS/SPSS/미니탭 같은 상용 패키지 중심에서 R을 중심으로 한 오픈소스 소프트웨어로 흐름을 바꾸었다고 볼 수 있다. 데이터를 다루려면 컴퓨터가 필요하고 컴퓨터와 대화하기 위해서는 언어가 필요한데, 다행히 통계학에서는 R 언어가 1990년대 초반 개발되자마자 오픈소스로 공개되어 자연스럽게 통계학 전공자가 오픈소스 소프트웨어에 친숙해지는 계기가 되었다.1
마이크로소프트 창업자 빌 게이츠가 소프트웨어 상업화 모델로 큰 성공을 거두면서 기존 IBM이 만들어 놓았던 생태계가 크게 변화했지만, 지나친 소프트웨어 상업화에 대한 반발로 리처드 스톨먼이 씨를 뿌리고 리누스 토발즈가 튼튼한 뿌리를 내린 리눅스 운영체제, 인터넷의 보급으로 오픈소스 소프트웨어(Open Source Software)에 대한 확산, 개방과 공유를 가치로 하는 개발자 특유의 문화를 기반으로 이제 대세는 오픈소스 소프트웨어가 되었다. 이러한 소프트웨어에 대한 인식의 전환은 GNU 선언문에 잘 표현되어 있다.
데이터를 많이 다루는 통계학도 소프트웨어 패러다임의 변화에 맞춰 진화해 왔다. SAS/SPSS/미니탭으로 대표되는 통계 패키지와 더불어 가우스/매트랩/매스매티카를 필두로 한 고급 상용 소프트웨어가 한 시대를 풍미했다면, 이제는 R과 파이썬으로 대표되는 오픈소스 소프트웨어가 그 빈자리를 급격히 채워 나가고 있다. 이러한 변화를 직감했던지 해들리 위컴은 2017년 11월 13일 Tidyverse 선언문(Tidy Tools Manifesto)을 직접 작성하여 웹사이트에 공개하였다.
데이터 사이언스 언어 R을 사용해서 산적한 과제를 해결해 나가면서 쌓인 여러 지적 자산을 패키지로 개발하여 공개하였고, 이를 통칭하여 과거에는 Hadleyverse로 불렸다. 이유는 dplyr, ggplot2 패키지를 해들리 위컴이 제작했고, 데이터 사이언스 문제를 풀려고 하면 해들리 위컴이 제작한 패키지를 조합해서 접근해야 수월하게 풀 수 있었기 때문이다. 하지만, 오픈소스 소프트웨어 개발은 한 사람의 노력으로만 가능한 것이 아니고, 전 세계 수많은 개발자와 사용자의 노력으로 이뤄낸 성과이기에 이를 tidyverse라는 명칭으로 통일하면서 데이터 사이언스 운영체제와 같은 역할과 위상을 가지게 되었다.
1.2 깔끔한 세상
해들리 위컴이 주장한 tidyverse(타이디버스, 깔끔한 세상)를 이해하기 위해서는 반드시 유닉스 철학(Unix Philosophy)에 대한 기본 지식이 필요하다. 세상에서 유일한 운영체제는 누구나 유닉스(UNIX)를 꼽고 있다. 사실 유닉스를 포크(fork)해서 만든 것이 마이크로소프트의 윈도우즈 운영체제다. 따라서, 사용 방식에는 다소 차이가 있을 수 있지만, 그 이면의 운영체제 설계와 구성에서는 크게 다르지 않다. 초기 유닉스 운영체제 개발자들은 모듈 방식과 재사용성의 개념을 적극 도입하였고, 이를 소프트웨어 개발에 대한 문화적 규범이자 철학적 접근을 통칭하여 유닉스 철학이라고 부르게 되었다.
엉망진창인 R 도구상자(messyverse)와 비교하기도 하지만, tidyverse는 패키지라기보다는 유닉스 철학처럼 데이터 사이언스에 있어 하나의 철학적 지침으로 접근하는 것이 일반적이다. 깔끔한 R 도구상자(tidyverse)는 깔끔한(tidy) API에 다음과 같은 4가지 원칙을 제시하고 있다.
- 기존 자료구조를 재사용한다: Reuse existing data structures.
- 파이프 연산자로 간단한 함수를 조합한다: Compose simple functions with the pipe.
- 함수형 프로그래밍을 적극 사용한다: Embrace functional programming.
- 기계가 아닌 인간을 위한 설계를 한다: Design for humans.
기존 자료구조를 재사용한다는 점은 티블(tibble), 파이프 연산자로 함수를 조합한다는 것은 %>% 기호로 유명한 magrittr 패키지, 적극적 함수형 프로그래밍은 purrr 패키지를 통해 구현되었고, 기계가 아닌 인간을 위한 설계는 대표적으로 1부터 시작한다는 점을 들 수 있다.
1.2.1 tidyverse 작업 흐름
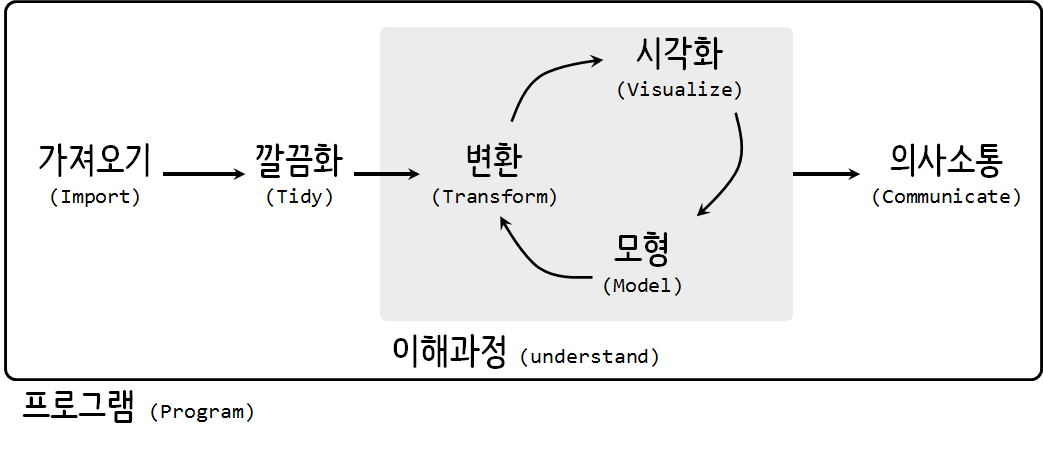
tidyverse의 핵심적인 내용은 다양한 형태의 데이터를 가져와서 최종 산출물을 사람과 기계가 소통할 수 있는 형태로 제작하는 과정을 추상화한 것으로 이해할 수 있다. 시각화(Visualization)는 데이터에 대한 통찰력(insight)과 유연성, 놀라움을 줄 수 있지만, 확장성(Scalability) 측면에서는 한계가 명확히 존재하는데 이는 사람이 작업 흐름 루프에 포함되기 때문이다. 반대로 모형(Model)은 자동화와 확장성에는 장점이 있지만, 주어진 모형 틀 안에서만 이뤄지기 때문에 통찰력, 놀라움, 유연성을 주지는 못하는 아쉬움이 있다. 따라서, tidyverse는 시각화와 모형을 통해 통찰력과 함께 자동화에 대한 부분도 충분히 반영한 체계적인 작업 흐름을 제시하고 있는데, 이를 관통하는 핵심적인 개념이 파이프(pipe)이며 이미 이런 개념은 유닉스 파이프 연산자를 통해 검증되었다.
1.2.2 깔끔한 데이터
기존 소프트웨어와 다르게 tidyverse는 데이터를 중심으로 다루기 때문에 깔끔한 데이터(tidy data)에 대한 이해도 추가로 필요하다. 깔끔한 데이터(tidy data)의 정의는 데이터를 통해 정보를 추출하고, 인사이트를 도출하기 위해서 시각화를 하고, 데이터를 모형으로 자동화하고, 소통을 위한 웹앱을 개발하고 발표 보고서를 작성할 때 수월한 자료구조를 갖는 데이터를 의미한다. 엄밀한 의미로 깔끔한 데이터를 전산학 데이터베이스 이론으로 설명할 수도 있지만, 비전산 전공자의 관점에서 보자면 깔끔한 데이터가 준비되면 정제 작업과 변형, 모형 개발, 시각화, 보고서 작성을 원활하게 할 수 있는 반면 엉망진창인 데이터(messy data)는 그렇지 않은 데이터로 볼 수 있다.
깔끔한 데이터는 특정한 구조를 갖추고 있는데 변수는 열(column)이고, 관측점은 행(row)이며, 관측 단위에 대한 형태는 데이터셋 즉, 테이블(table)로 구성된다.
깔끔한 데이터 원칙은 전산학의 코드(Codd) 박사의 관계대수(Relational Algebra)와 깊은 관련이 있어, 통계학 전공자는 해당 데이터셋에서 관측점과 변수를 각각 식별하는 작업을 쉽게 생각하지만, 일반적으로 변수와 관측점을 정확하게 정의하는 것이 보통 어려운 것은 아니다. 따라서, 행과 열보다는 변수 간 기능적 관계(functional relationship)를 기술하는 것이 더 쉽고, 칼럼 그룹 집단 간 비교보다 관측점 그룹 집단 사이 비교를 하는 것이 더 쉽다.
깔끔한 데이터(tidy data)는 데이터셋의 의미를 구조에 매칭하는 표준적인 방식으로 이와 같이 데이터가 구조화되면, 데이터 분석, 조작, 시각화, 모형 작업을 수월하게 진행할 수 있다.
- 각 변수가 칼럼이 된다.
- 각 관측점은 행이 된다.
- 관측 단위에 대한 형태는 테이블로 구성한다.
| 저장 구분 | 의미 |
|---|---|
| 테이블/파일 | 데이터셋 |
| 행 | 관측점 |
| 열 | 변수 |
깔끔하지 않은 데이터(messy data)는 위와는 다른 형태의 데이터를 지칭한다. 전산학에서 말하는 코드 제3 정규형이지만, 통계적 언어로 다시 표현한 것이다. 또한, 깔끔한 데이터는 R 같은 벡터화 프로그래밍 언어에 특히 잘 맞는다. 왜냐하면 동일한 관측점에 대한 서로 다른 변수 값이 항상 짝으로 매칭되는 것을 보장하기 때문이다.
시각화와 모형을 새로 개발하는 데 별도 자료구조(data structure)를 다시 만드는 대신에 가능하면 기존 자료구조를 재사용하는 것을 원칙으로 삼고 있다. ggplot2, dplyr, tidyr을 포함한 대다수 R 패키지는 칼럼에 변수, 행에 관측점을 갖는 직사각형 형태 데이터셋을 가정하고 있다. 그리고, 일부 패키지는 특정한 변수 자료형에 집중한다. stringr은 문자열, lubridate는 날짜/시간, forcats는 요인 자료형에 집중하고 있지만 모두 기존 자료구조 재사용을 염두에 두고 있는 것도 사실이다.
1.2.3 함수형 프로그래밍
복잡한 문제를 해결하는 강력한 전략은 레고 블록처럼 다수의 간단한 조각으로 나누고 이를 조합하는 것이다. 단, 각 조각은 격리되어 쉽게 파악되며, 다른 조각과 조합할 수 있는 표준 위에서 성립되어야 한다. tidyverse 밑바탕에는 이런 전략이 파이프 연산자를 통해 구현되어 있고, 파이프 연산자(예를 들어, %>%)로 단순한 함수를 조합하여 시스템 전체의 힘을 극대화시킨다.
이를 위해서는 무엇보다 레고 블록 같은 패키지 혹은 함수가 동일한 인터페이스 표준을 준수해야만 한다. %>% 연산자를 통해 많은 패키지에 걸쳐 동작되도록 만들려면, 함수를 작성할 때 다음 원칙을 준수하여 작성하면 된다.
- 함수를 가능하면 단순하게 작성한다. 일반적으로 각 함수는 한 가지 작업을 매우 잘해야 되고, 한 문장으로 함수 존재 목적을 기술할 수 있어야 한다.
- 변형(transformation)과 부작용(side-effect)을 섞지 말아야 한다. 함수가 객체를 반환하거나, 부작용을 일으키는 둘 중 하나만 동작하게 만든다.
- 함수명은 동사로 작성해야 한다. 하지만, 다수의 함수가 동일한 동사를 사용하는 경우는 예외로 한다. 예를 들어
modify,add,compute등을 들 수 있다. 이런 경우 반복되는 동사가 중복되지 않도록 명사에 집중한다.ggplot2가 좋은 예인데, 기존 플롯에 좌표, 점, 범례 등 거의 모든 함수가 추가되기 때문이다.
R은 데이터를 위해 개발된 함수형 언어를 근본에 두고 있지만, 객체 지향 언어(OOP)나 다른 언어 패러다임과 싸우려고 하지 말고 적극적으로 받아들이라고 충고하고 있는데, 이것이 의미하는 바는 다음과 같다.
- 상태 불변 객체: 작성된 코드에 대한 추론이 쉬워진다.
- S3, S4에서 제공하는 제네릭 함수: 상태 변형 가능한 상태가 필요하다면, 파이프 내부에서 구현한다.
-
for루프를 추상화한 도구:apply함수 가족과purrr맵(map) 함수
데이터 사이언스에서 병목점으로 문제가 발생되는 곳은 공통적으로 컴퓨터 실행 시간(computing time)이 아니라 사람의 생각(thinking time)의 시간이다. 따라서, 함수명을 작성할 때 생각이 잘 연상되는 이름으로 작명하고 시간을 적절히 안분하고, 명시적이며 긴 명칭을 변수명, 함수명, 객체명에 사용하고, 짧은 명칭은 가장 중요한 이름으로 아껴서 사용한다. RStudio 소스 편집기의 자동 완성 기능을 사용하는 경우 접두어가 접미어보다 왜 중요한지 알 수 있고, stringr, xml2, rvest 패키지를 살펴보면 접두어에 일관된 명칭을 부여한 장점을 알 수 있다.
1.3 tidyverse 사례
전통적으로 R은 작은 데이터를 빠르게 탐색하는 데 최적의 환경을 제공했는데, 빅데이터도 많지 않았고, 지금과 같이 다양한 영역에서 폭넓고 깊이 있게 다룰 필요성이 없었던 것도 큰 이유가 된다. 하지만, 현재 상황은 빅데이터가 널려 있으며 컴퓨팅 자원을 클라우드와 HPC 서비스를 통해서 누구나 저렴한 비용으로 사용할 수 있게 되었다. tidyverse 패러다임과 도구를 적극 도입할 경우 데이터 과학자는 거의 모든 데이터를 원하는 방향으로 가져오기부터 정제와 변환, 시각화, 모형 개발, 실운영 환경 배포를 할 수 있다. 데이터 사이언스 문제를 데이터 크기를 기준으로 다음과 같이 크게 3가지로 나눌 수 있고 실무자 경험에 비춰보면 실제 빅데이터는 1%도 되지 않는다.
- 빅데이터 문제-소규모 분석방법(Big Data-Small Analytics): 요약/표본추출/부분집합 추출 (90%)
- 병렬 처리가 가능한 문제: 작은 데이터 문제로 쪼개서 분할 정복 (9%)
- 빅데이터 문제 대규모 분석방법(Big Data-Large Scale Analytics): 더 이상 어찌할 수 없는 큰 문제 데이터 (1%)
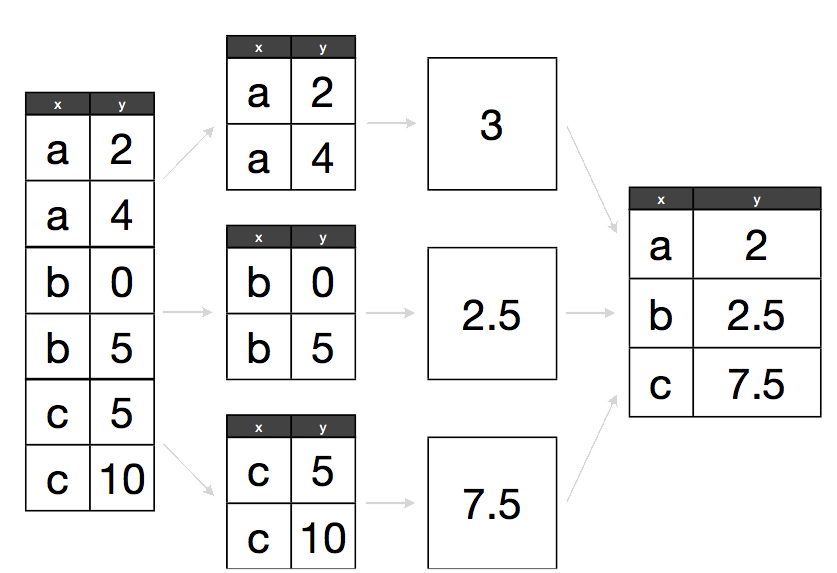
정보량을 잃지 않으면서 빅데이터를 요약하는 방법과 병렬 처리 가능한 문제로 바꾸어서 하둡과 스파크(Hadoop and Spark) 클러스터를 생성하여 클라우드 컴퓨팅 자원을 활용하여 처리할 수 있는 방법을 고려할 경우 거의 99%의 빅데이터 문제를 처리할 수 있다. 빅데이터 문제를 소규모 분석방법으로 다루는 방법은 요약, 표본 추출, 부분집합 추출 등을 통해 많이 알려져 있지만, 병렬/분산 처리 방법은 클라우드 컴퓨팅을 많이 사용하는 개발자에게는 친숙하지만, 데이터 과학자에게는 아직도 새로운 기술로 받아들여지고 있다. 최근에 큰 문제를 작은 문제로 쪼개고 각 문제에 대해서 적절한 연산(예를 들어 요약통계량)을 취하고 이를 결합하는 분할-적용-병합(Split-Apply-Combine) 전략으로 소개되고 있다. 재현 가능한 과학적 분석을 위한 R - “분할-적용-병합 전략”에 나온 것처럼 각 그룹별로 쪼갠 후 각 그룹별로 평균을 내고 이를 조합한 사례가 전반적인 큰 그림을 그리는 데 도움이 될 수 있다. 여기서 평균을 사용했는데 요약 함수(summarize)뿐만 아니라, 윈도우 함수, 이를 일반화한 do() 함수로도 확장할 수 있다. 이론적인 사항은 분할-적용-병합 전략을 설명한 논문(Wickham 2011)을 참조한다.
1.4 소프트웨어 작성법
tidyverse는 데이터 과학 작업을 위한 강력하고 일관된 프레임워크를 제공하지만, 데이터 과학 운영체제 위에서 좋은 코드를 작성하는 것은 여전히 데이터 과학자의 몫이다. 좋은 코드(이광춘 2024)를 작성하는 것은 단순히 프로그램이 정상 동작하는 것 이상의 의미를 지닌다. 협업, 재사용, 유지보수 등 장기적인 관점에서 코드의 가치를 결정짓는 핵심 요소이기 때문이다.
먼저 코드의 가독성을 높이기 위해 노력해야 한다. 변수와 함수의 이름을 명확하게 짓고, 코드 블록을 논리적으로 구조화하며, 충분한 주석을 달아 코드의 의도를 명확히 전달해야 한다. 특히 주석은 단순히 코드가 “어떻게” 동작하는지 뿐만 아니라 “왜” 그렇게 작성되었는지를 설명해야 한다.
함수는 가능한 한 작고 단순하게 작성해야 한다. 각 함수는 한 가지 일만 하도록 하고, 입력과 출력을 명확히 정의해야 한다. 이렇게 하면 함수를 조합하여 더 복잡한 작업을 수행하기 쉬워진다. 또한 함수는 꼭 필요한 경우에만 부작용(side-effect)을 발생시켜야 한다.
코드를 모듈화하는 것도 중요하다. 데이터 로딩, 전처리, 분석, 시각화 등 일련의 작업을 독립적인 스크립트 또는 함수로 분리하면 코드의 재사용성이 높아지고 유지보수가 용이해진다. 나아가 함수나 모듈을 패키지화하면 다른 프로젝트에서도 손쉽게 활용할 수 있다.
코드에 대한 테스트도 소홀히 해서는 안 된다. 테스트 코드를 작성하는 것은 번거로운 일일 수 있지만, 장기적으로는 시간을 절약하고 코드의 신뢰성을 높이는 데 크게 기여한다. testthat과 같은 패키지를 활용하면 손쉽게 단위 테스트를 만들고 실행할 수 있다.
일관된 코딩 스타일을 유지하는 것이 중요하다. 들여쓰기, 공백, 줄바꿈 등 세세한 규칙을 정하고 이를 철저히 따르는 것만으로도 코드의 가독성은 크게 향상된다. tidyverse 패키지들이 일관된 네이밍과 API 디자인을 따르는 것처럼, 프로젝트 내에서 일관된 규칙을 세우고 따르는 것이 좋다.
한걸음 더 들어가 좋은 소프트웨어를 작성하려면,
- 프로젝트를 적절히 구조화하고,
- 필요한 사항은 문서화하고,
- 복잡한 문제는 작은 모듈로 나누어 해결하고,
- 코드 작동을 검증하는 테스트를 만들고,
- 반복되는 코드는 함수로 묶어서 처리하고,
- 일관된 코딩 스타일을 고수해야 한다.
위의 원칙을 지키면 다른 동료 연구자들과 미래의 자신에게 읽기 쉽고, 이해하기 쉽고, 확장 가능한 코드를 선물할 수 있을 것이다.
1.4.1 프로젝트 폴더 구조화
하위 폴더를 코드, 매뉴얼, 데이터, 바이너리, 출력 그래프 등으로 구분하여 프로젝트 폴더를 구조화하고, 잘 조직화하고, 깔끔하게 만든다. 완전 수작업으로 할 수도 있고, RStudio New Project 기능을 활용하거나 ProjectTemplate 같은 패키지를 사용한다.
ProjectTemplate - 가능한 해결책
프로젝트 관리를 자동화하는 한 방식은 제3자 패키지인 ProjectTemplate을 설치하는 것이다. 해당 패키지는 프로젝트 관리에 대한 이상적인 디렉토리 구조를 설정해 놓는다. 패키지가 자동으로 분석 파이프라인/작업 흐름을 구성해서 구조화해 놓는다. RStudio 기본 설정된 프로젝트 관리 기능과 Git을 함께 사용하면, 작업을 기록할 뿐만 아니라, 동료 연구원과 작업 산출물을 공유할 수 있게 한다.
-
ProjectTemplate을 설치한다. - 라이브러리를 불러온다.
- 프로젝트를 초기화한다.
install.packages("ProjectTemplate")
library(ProjectTemplate)
create.project("../my_project", merge.strategy = "allow.non.conflict")ProjectTemplate과 기능에 대한 자세한 사항은 ProjectTemplate 홈페이지를 방문한다.
1.4.2 가독성 높은 코드 생성
코드 작성에 있어 가장 중요한 부분은 코드를 가독성 있고 이해할 수 있게 작성하는 것이다. 누군가 여러분이 작성한 코드를 보고 무슨 작업을 수행하는지 이해할 수 있어야 한다. 흔히 누군가는 6개월 후에 바로 당신이 될 수 있고, 만약 그렇게 작성하지 않았다면 과거 자기 자신을 분명히 저주하게 될 것이다.
1.4.3 문서화
처음 코드를 작성할 때, 주석은 명령어가 무엇을 수행하는지 기술한다. 왜냐하면, 여전히 학습 중이라 개념을 명확히 하고, 나중에 다시 상기하는 데 도움이 되기 때문이다. 하지만, 이러한 주석은 나중에 작성한 코드가 어떤 문제를 해결하고자 하는지 기억하지 못하면 그다지 도움이 되지 않는다.
왜(why) 문제를 해결하려고 하는지, 그리고 어떤(what) 문제인지 전달하는 주석을 달려고 노력한다. 어떻게(how)는 그 다음에 온다. 정말 걱정할 필요가 없는 사항은 구체적인 구현이다.
1.4.4 코드 모듈화
소프트웨어 카펜트리에서 추천하는 것은 작성한 함수를 분석 스크립트와 구별해서 별도 파일에 저장하는 것이다. 프로젝트 R세션을 열 때, source 함수로 불러올 수 있게 별도 파일로 저장한다.
분석 스크립트를 깔끔하게 유지하고, 유용한 함수 저장소를 프로젝트 분석 스크립트에 불러들일 수 있게 함으로써 이러한 접근법이 깔끔하다. 또한 관련된 함수를 쉽게 그룹화할 수 있다.
1.4.5 문제를 작게 분해
처음 시작할 때, 문제 해결과 함수 작성은 어마어마한 작업이고, 코드를 쪼개는 것도 힘들다. 문제를 소화 가능한 덩어리로 쪼개고, 나중에 구현에 관한 구체적인 사항을 걱정한다. 해결책을 코드로 작성할 수 있는 지점까지 문제를 더 작게 그리고 더 작은 함수로 계속 쪼개 나간다. 그리고 나서 다시 거꾸로 조립해서 만들어 낸다.
1.4.6 코드 테스트
작성한 코드가 올바른 작업을 수행하도록 만든다. 작성한 함수를 테스트해서 확실히 동작하게 만든다.
1.4.7 복붙 금지
복사 붙여넣기는 코드를 작성하는 데 있어서 가장 나쁜 방법이다. 함수는 프로젝트 내부에서 재사용을 쉽게 한다. 프로젝트를 통해서 유사한 코드 라인 덩어리를 보게 되면, 대체로 함수로 옮겨져야 하는 대상을 찾은 것이다.
연산 작업이 연속된 함수를 통해 실행되면, 프로젝트는 모듈로 만들기 쉽고, 변경하기 쉽다. 항상 특정한 입력값을 넣으면 특정한 출력값이 나오는 경우에 특히 그렇다.
1.4.8 스타일 고집
코드에 일관된 스타일을 지킨다. 이것은 코드를 읽고 이해하는 데 도움이 된다.
1.4.9 코드 스타일과 가독성
일관된 코딩 스타일은 가독성을 높이고 버그를 최소화한다. R 커뮤니티에서 가장 널리 사용되는 스타일 가이드 중 하나는 해들리 위컴 스타일 가이드다. Google의 R 스타일 가이드도 널리 사용된다.
일관된 스타일로 프로젝트를 진행하면, 다른 사람이 코드를 더 쉽게 읽고 확장할 수 있다. RStudio의 코드 정리 기능을 활용하여 코드 스타일을 자동으로 적용할 수도 있다.
1.4.10 핵심은 일관성
함수 이름 붙이기, 코드 들여쓰기, 주석 달기 등 코딩 스타일의 어떤 요소든 한번 선택하면 이후로도 꾸준히 같은 스타일을 고수해야 한다. 코드 작성자에게는 편한 스타일이 좋지만, 팀 단위로 협업한다면 팀에서 합의한 코딩 스타일을 따르는 것이 바람직하다.
1.5 요약
해들리 위컴이 주창한 tidyverse는 통계학과 데이터 사이언스 분야에 지대한 영향을 미쳤다. tidyverse는 단순한 패키지의 집합이 아닌 하나의 철학이자 체계로서, 데이터를 다루는 일관되고 효율적인 방식을 제시하고 있다. 통계학이 단순히 이론에 머무르지 않고 실제 데이터를 다루는 데 있어 큰 도움을 주었으며, 기존 상용 통계 패키지에서 R/파이썬으로 대표되는 데이터 과학 오픈소스 프로그래밍 언어로 전환을 가속화하는 계기가 되었다.
tidyverse 핵심 개념 중 하나는 “깔끔한 데이터”로, 데이터를 일관된 형식으로 정리하여 분석, 시각화, 모형 등에 용이하게 활용할 수 있도록 한다. 또한, 함수형 프로그래밍과 파이프 연산자를 적극 활용하여 코드의 가독성과 재사용성을 높여 데이터 과학자들이 보다 효율적이고 생산적으로 작업할 수 있는 기반이 되고 있다.
한편, tidyverse는 데이터 과학 작업 과정 전반을 아우르는 체계적인 작업흐름도 제시하고 있다. 데이터 수집, 정제, 변환, 시각화, 모형, 커뮤니케이션 등 일련의 과정을 유기적으로 연결하여 데이터 과학 프로젝트를 보다 효과적으로 수행할 수 있도록 한다.
tidyverse가 제공하는 강력한 도구와 체계적인 방법론은 데이터 과학자에게 큰 도움이 되지만, tidyverse에 부합되는 실제 좋은 코드를 작성하고 프로젝트를 운영하는 것은 여전히 데이터 과학자 개인 역량에 달려 있다. 코드 가독성, 모듈화, 문서화, 테스트, 스타일 일관성 등을 고려하여 장기적으로 유지보수 가능하고 협업 친화적인 코드를 작성하는 노력이 필요하다.