graph TB
subgraph 가져오기["가져오기"]
csv[CSV 파일] --> 핸들러_가져오기
스프레드쉬트 --> 핸들러_가져오기
subgraph spreadsheet[" "]
엑셀 --> 스프레드쉬트
구글시트 --> 스프레드쉬트
end
데이터베이스 --> 핸들러_가져오기
통계패키지 --> 핸들러_가져오기
subgraph pkg[" "]
SPSS --> 통계패키지
SAS --> 통계패키지
STATA --> 통계패키지
end
웹["웹 데이터"] --> 핸들러_가져오기
end
핸들러_가져오기["핸들러"] --> 데이터프레임
classDef modern fill:#fff,stroke:#333,stroke-width:2px,color:#333,font-family:MaruBuri,font-size:12px;
classDef emphasize fill:#d0d0d0,stroke:#333,stroke-width:3px,color:#333,font-family:MaruBuri,font-size:15px,font-weight:bold;
classDef subgraphStyle fill:#f0f0f0,stroke:#333,stroke-width:2px,color:#333,font-family:MaruBuri,font-size:20px;
classDef spreadsheetStyle fill:#e0e0e0,stroke:#333,stroke-width:3px,color:#333,font-family:MaruBuri,font-size:20px;
class csv,데이터베이스,웹,통계패키지,pkg,엑셀,구글시트,SPSS,SAS,STATA modern
class 데이터프레임 emphasize
class 가져오기 subgraphStyle
class 스프레드쉬트,spreadsheet spreadsheetStyle
class 핸들러_가져오기 modern
26 상용 데이터
R에서는 CSV 파일, 스프레드시트(엑셀, 구글시트), 데이터베이스, 통계 패키지(SPSS, SAS, STATA), 웹 데이터 등 다양한 출처에서 데이터를 가져올 수 있다. 상용 파일 형식 데이터는 크게 통계 패키지 계열과 스프레드시트 계열로 나눠볼 수 있다.
통계 패키지의 데이터 파일은 과거 다양한 R 패키지가 존재하였으나 해들리 위컴이 저작한 haven 패키지에서 제공하는 함수(read_spss(), read_sas(), read_dta() 등)를 사용하여 불러온다. 한국보건사회연구원에서 조사하여 발표하는 한국복지패널데이터(KoWeP)는 오픈 파일 형식을 제외하고 SAS, SPSS, STATA 3가지 형식으로 제공되는데 haven 패키지를 사용하여 불러올 경우 함수명은 다르지만 동일한 방식으로 일관성을 갖는다는 점에서 장점이 있다.
엑셀로 대표되는 스프레드시트 파일은 로컬 파일로 작업할 때는 readxl 패키지의 read_excel(), 원격 스프레드시트 파일을 구글시트(Google Sheets)로 작업할 때는 googlesheets4 패키지의 read_sheet() 함수를 사용한다.
엑셀, 구글 드라이브와 연결된 구글시트, 통계패키지 파일은 유료 상용 소프트웨어로 원칙적으로 해당 파일을 R 혹은 파이썬 등 다른 작업환경으로 가져오는 것은 해당 소프트웨어가 없다면 불가능하다. 물론 상용 소프트웨어가 개방형 파일 형태(.csv 등)로 내보내는 기능을 제공하지만 이러한 경우 메타데이터가 손실되는 것은 불가피하고 데이터 일부가 손실될 수 있다.
26.1 통계패키지
SPSS, SAS, STATA는 널리 사용되는 통계 분석 소프트웨어 패키지로, 각각 고유한 파일 형식을 사용한다. 고유한 파일 형식을 갖게 되면 데이터가 통계 패키지 내부에서 원활히 동작할 수 있는 메타 정보를 담을 수 있고 속도 향상도 기대할 수 있다. 그러나 이러한 독점적인 파일 형식은 다른 통계 패키지와의 상호 운용성을 제한할 수 있고, 장기적으로 데이터 보존 및 이식성에 문제를 일으킬 수 있다.
SPSS는 .sav 확장자를 사용하는 이진 파일 형식을 사용한다. .sav 파일은 데이터, 변수 레이블, 값 레이블 등의 메타데이터를 포함하고 있다. SPSS의 .por 확장자를 가진 파일은 다른 시스템으로 이식도 가능하다.
SAS는 .sas7bdat 확장자를 사용하는 이진 파일 형식을 사용한다. .sas7bdat 파일은 데이터와 메타데이터를 모두 포함하며, SAS에서만 읽을 수 있다. SAS도 SPSS .por처럼 .xpt 확장자를 가진 다른 시스템에 이식 가능한 파일 형식을 지원한다.
STATA는 .dta 확장자를 사용하는 이진 파일 형식을 사용한다. .dta 파일에는 데이터, 변수 레이블, 값 레이블 등 메타데이터가 포함되어 있다. .dta 파일은 STATA에서만 읽을 수 있고 SAS, SPSS에서 읽을 수는 없다. 하지만, ‘SAS STATA Transfer’ 프로시저나 ’SPSS Data Access Pack’을 구매하여 STATA 파일을 불러읽을 수 있으며, STATA에서 CSV 파일 형태로 내보낸 후 별도 프로시저나 팩 없이 SPSS, SAS에서 불러읽을 수 있는 방법이 있다.
하지만, 통계 패키지 간에 데이터를 교환하려면 일반적으로 .csv(쉼표로 분리된 값) 또는 .txt(탭으로 분리된 값) 형식과 같은 중간 파일 형식을 사용하는 과정에서 변수 레이블과 값 레이블과 같은 일부 메타데이터가 손실될 수 있다.
따라서, 단기적으로 SAS/SPSS/STATA와 같은 독점 파일 형식이 제공하는 장점보다 개방형 파일 형식이 장기적으로 데이터 접근성과 재사용성을 높일 수 있다는 면에서 장점이 크다.
26.1.1 SPSS
세종시에 위치한 한국보건사회연구원에서 조사하여 발표하는 한국복지패널데이터는 특이하게도 오픈 파일 형식만 제외하고 상용 통계 패키지가 있어야 열어볼 수 있는 SPSS, STATA, SAS 파일 형식으로 제공되고 있다. 총 4가지 종류의 파일을 제공하고 있지만 여기서는 다양한 파일 데이터를 불러오는 방법을 중심으로 살펴보기 때문에 가장 단순한 파일만 R 환경으로 불러오는 방법을 살펴보자.
- 가구용데이터(SAS, SPSS, STATA):koweps_h17_2022_Beta1
- 가구원용데이터(SAS, SPSS, STATA):koweps_p17_2022_Beta1
- 복지인식설문용데이터(SAS, SPSS, STATA):koweps_wc17_2022_Beta1
- 가구용, 가구원용, 복지인식설문용 머지데이터(SAS, SPSS, STATA):koweps_hpwc17_2022_Beta1
SPSS로 작성된 .sav 파일을 R 환경으로 불러오기 위해서는 haven 패키지를 로드하여 SPSS (.sav) 데이터 파일을 R로 읽어온다. read_spss() 함수를 사용하여 “koweps_hpwc17_2022_Beta1.sav” 파일을 welfare_raw 데이터 프레임으로 저장한 후, map_chr() 함수를 사용하여 welfare_raw의 각 변수에 대해 attributes(.x)$label을 적용하여 변수의 레이블을 추출하고 후속 작업을 위해서 문자형 벡터로 변환시킨다.
enframe() 함수를 사용하여 추출된 레이블을 데이터 프레임으로 변환하고, filter() 함수와 str_detect() 함수를 사용하여 “성별”, “종교”, “태어난 연도”, “혼인상태”, “가구원수”라는 키워드가 포함된 변수만 선택한다. pull() 함수를 사용하여 선택된 변수의 이름을 추출하고, setdiff() 함수를 사용하여 정규표현식 작성과정에서 함께 추출된 “h1707_6aq6” 변수를 제외시킨 후 demo_vars 변수로 저장한다.
welfare_raw 데이터 프레임에서 select() 함수와 all_of() 함수를 사용하여 demo_vars에 해당하는 변수만 선택한 후 set_names() 함수를 사용하여 선택된 변수명을 “성별”, “종교”, “태어난 연도”, “혼인상태”, “가구원수”로 변경한다. str_split()과 dput()을 사용하여 변수 이름을 파이프(|) 연산으로 한 명령어로 처리한다. janitor 패키지의 clean_names() 함수를 사용하여 변수 이름을 깔끔하게 정리하는데, ascii = FALSE 옵션을 사용하여 한글 변수명을 유지한다.
한국보건사회연구원에서 한국복지패널 데이터가 SPSS로 제공되고 있지만 상용 SPSS 패키지가 없더라도 R 환경에서 haven 패키지와 janitor 패키지를 활용하여 SPSS 데이터를 불러와서 본격적인 분석을 오픈 데이터 분석 및 통계 언어 R로 수행할 준비가 되었다.
library(haven) # install.packages("foreign")
# Read the .sav file
welfare_raw <- read_spss("data/file/SPSS/koweps_hpwc17_2022_Beta1.sav")
## 관심 변수 추출
demo_vars <- welfare_raw %>%
map_chr(~attributes(.x)$label) |>
enframe() |>
filter(str_detect(value, "성별|종교|(태어난 연도)|혼인상태|가구원수")) |>
pull(name) |>
setdiff("h1707_6aq6") # 기타소비-종교관련비 변수 제거
## 인구통계학적 변수로 구성된 데이터셋
welfare_raw %>%
select(all_of(demo_vars)) |>
set_names(str_split("성별|종교|(태어난 연도)|혼인상태|가구원수", "\\|")[[1]] |> dput()) |>
janitor::clean_names(ascii = FALSE)
#> c("성별", "종교", "(태어난 연도)", "혼인상태", "가구원수"
#> )
#> # A tibble: 16,591 × 5
#> 성별 종교 태어난_연도 혼인상태 가구원수
#> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 2 1945 2 1
#> 2 1 1 1948 2 2
#> 3 1 1 1942 3 1
#> 4 5 1 1962 1 1
#> 5 5 2 1963 1 1
#> 6 5 2 2003 5 1
#> 7 5 1 1927 1 1
#> 8 5 2 1934 1 1
#> 9 1 2 1940 2 1
#> 10 2 2 1970 3 1
#> # ℹ 16,581 more rows26.1.2 SAS
SAS 통계패키지 koweps_hpwc17_2022_beta1.sas7bdat 파일은 앞서 작성된 동일한 한국보건사회연구원의 한국복지패널 데이터다. haven 패키지를 사용하여 read_sas() 함수로 SAS 데이터 파일(.sas7bdat)을 불러온다. 이후 코드는 앞서 SPSS 데이터를 R 인구통계 데이터프레임으로 변환시켜 가져온 것과 동일한 방법으로 진행된다. 즉, 코드를 재사용하게 된다.
library(haven) # install.packages("foreign")
sas_raw <- read_sas("data/file/SAS/koweps_hpwc17_2022_Beta1.sas7bdat")
## 관심 변수 추출
sas_vars <- sas_raw %>%
map_chr(~attributes(.x)$label) |>
enframe() |>
filter(str_detect(value, "성별|종교|(태어난 연도)|혼인상태|가구원수")) |>
pull(name) |>
setdiff("h1707_6aq6") # 기타소비-종교관련비 변수 제거
## 인구통계학적 변수로 구성된 데이터셋
sas_raw %>%
select(all_of(sas_vars)) |>
set_names(str_split("성별|종교|(태어난 연도)|혼인상태|가구원수", "\\|")[[1]] |> dput()) |>
janitor::clean_names(ascii = FALSE)
#> c("성별", "종교", "(태어난 연도)", "혼인상태", "가구원수"
#> )
#> # A tibble: 16,591 × 5
#> 성별 종교 태어난_연도 혼인상태 가구원수
#> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 2 1945 2 1
#> 2 1 1 1948 2 2
#> 3 1 1 1942 3 1
#> 4 5 1 1962 1 1
#> 5 5 2 1963 1 1
#> 6 5 2 2003 5 1
#> 7 5 1 1927 1 1
#> 8 5 2 1934 1 1
#> 9 1 2 1940 2 1
#> 10 2 2 1970 3 1
#> # ℹ 16,581 more rows26.1.3 STATA
STATA 통계패키지 koweps_hpwc17_2022_beta1.dta 파일은 SAS 버전과 동일한 한국복지패널 데이터다. R에서 haven 패키지의 read_dta() 함수를 사용하여 STATA 데이터 파일(.dta)을 불러올 수 있다. 이후 코드는 앞서 SPSS, SAS 데이터를 R로 가져와 인구통계 데이터프레임으로 변환한 것과 동일한 방법으로 진행된다. 따라서 이전에 작성한 코드를 그대로 재사용할 수 있다.
library(haven) # install.packages("haven")
# STATA 파일 불러오기
stata_raw <- read_dta("data/file/STATA/Koweps_hpwc17_2022_beta1.dta")
## 관심 변수 추출
stata_vars <- stata_raw %>%
map_chr(~attributes(.x)$label) |>
enframe() |>
filter(str_detect(value, "성별|종교|(태어난 연도)|혼인상태|가구원수")) |>
pull(name) |>
setdiff("h1707_6aq6") # 기타소비-종교관련비 변수 제거
## 인구통계학적 변수로 구성된 데이터셋
stata_raw %>%
select(all_of(stata_vars)) |>
set_names(str_split("성별|종교|(태어난 연도)|혼인상태|가구원수", "\\|")[[1]] |> dput()) |>
janitor::clean_names(ascii = FALSE)
#> c("성별", "종교", "(태어난 연도)", "혼인상태", "가구원수"
#> )
#> # A tibble: 16,591 × 5
#> 성별 종교 태어난_연도 혼인상태 가구원수
#> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 2 1945 2 1
#> 2 1 1 1948 2 2
#> 3 1 1 1942 3 1
#> 4 5 1 1962 1 1
#> 5 5 2 1963 1 1
#> 6 5 2 2003 5 1
#> 7 5 1 1927 1 1
#> 8 5 2 1934 1 1
#> 9 1 2 1940 2 1
#> 10 2 2 1970 3 1
#> # ℹ 16,581 more rows26.2 엑셀
엑셀에서 복잡한 데이터를 관리하는 방법 중 하나는 여러 시트에 데이터를 나누어 저장하는 것이다. readxl 패키지를 사용하여 엑셀 파일을 불러올 때 excel_sheets() 함수를 사용하여 엑셀 파일에 저장된 시트 이름을 확인할 수 있다. 이후 read_excel() 함수를 사용하여 원하는 시트를 불러올 수 있다. 제20대 국회의원 선거 지역구와 비례대표 당선자 명단을 담은 엑셀 파일을 불러오는 예제를 살펴보자. 국회의원 정수는 총 300명이기 때문에 지역구 당선자와 비례 당선자를 하나로 묶어 각 당별로 당선자가 몇 명인지 확인할 수 있다.
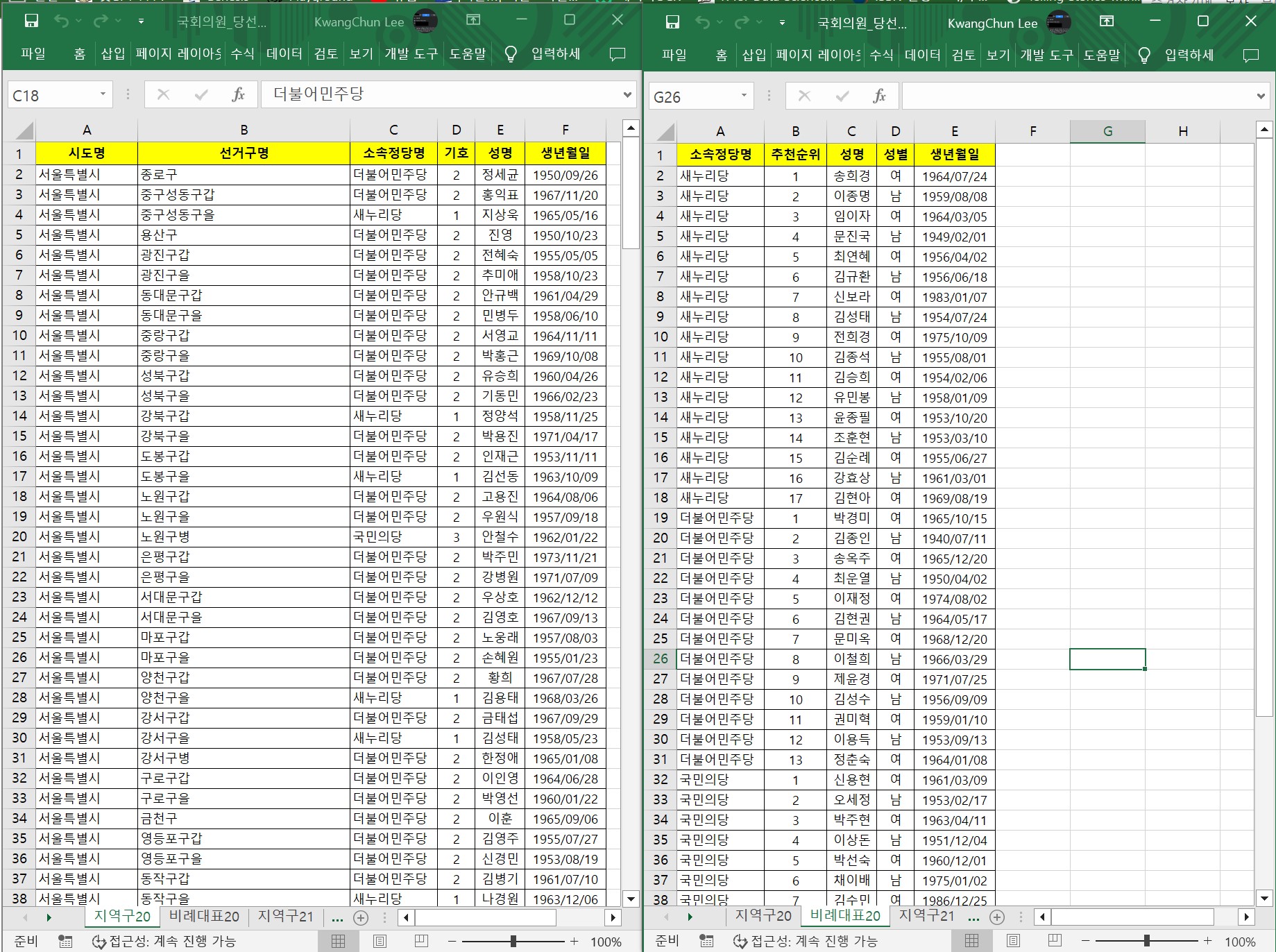
readxl 패키지의 excel_sheets() 함수를 사용하여 제20대와 제21대 국회의원선거 당선인 정보가 담긴 엑셀 파일 “data/국회의원_당선인명부.xlsx”에서 시트명을 추출하여 winners_sheetname 변수에 저장한다. read_excel() 함수를 사용하여 지역구 당선자 명단은 winners_sheetname의 첫 번째 시트에서, 비례대표 당선자 명단은 두 번째 시트에서 추출하여 각각 winners_precinct와 winners_prop 변수에 저장한다. bind_rows() 함수를 사용하여 지역구와 비례대표 당선자 명단을 하나로 합치고, 비례대표 당선자의 선거구명을 “비례대표”로 설정하여 지역구와 자료구조를 맞춘 후 winners 데이터프레임에 저장한다. count() 함수를 사용하여 소속정당명별 당선자수를 집계하고, 당선자수 순으로 정렬한다.
library(tidyverse)
library(readxl)
# 엑셀 파일에서 시트명 추출
winners_sheetname <- readxl::excel_sheets("data/국회의원_당선인명부.xlsx")
winners_sheetname
#> [1] "지역구20" "비례대표20" "지역구21" "비례대표21"
# 지역구와 비례 당선자 명단 추출
winners_precinct <- readxl::read_excel("data/국회의원_당선인명부.xlsx", sheet = winners_sheetname[1])
winners_prop <- readxl::read_excel("data/국회의원_당선인명부.xlsx", sheet = winners_sheetname[2])
# 지역구와 비례대표 당선자 명단을 하나로 합침
winners <- bind_rows(winners_precinct, winners_prop |>
mutate(선거구명 = "비례대표"))
# 정당별 당선자수 집계
winners |>
count(소속정당명, sort = TRUE, name = "당선자수")
#> # A tibble: 5 × 2
#> 소속정당명 당선자수
#> <chr> <int>
#> 1 더불어민주당 123
#> 2 새누리당 122
#> 3 국민의당 38
#> 4 무소속 11
#> 5 정의당 626.3 구글시트
스프레드시트는 데이터 입력, 저장, 분석 및 시각화를 위해 널리 사용되는 소프트웨어 도구다. 하지만, 데이터 입력과 저장 측면에 초점을 맞추어 보면 오류도 많다. 흔히 보게 되는 엑셀 파일의 문제점 중 하나는 엉망진창(messy) 데이터다. 논문(Broman 와/과 Woo 2018)에 제시된 엉망진창 데이터 중 하나를 뽑아 깔끔한 데이터로 변환해보자.
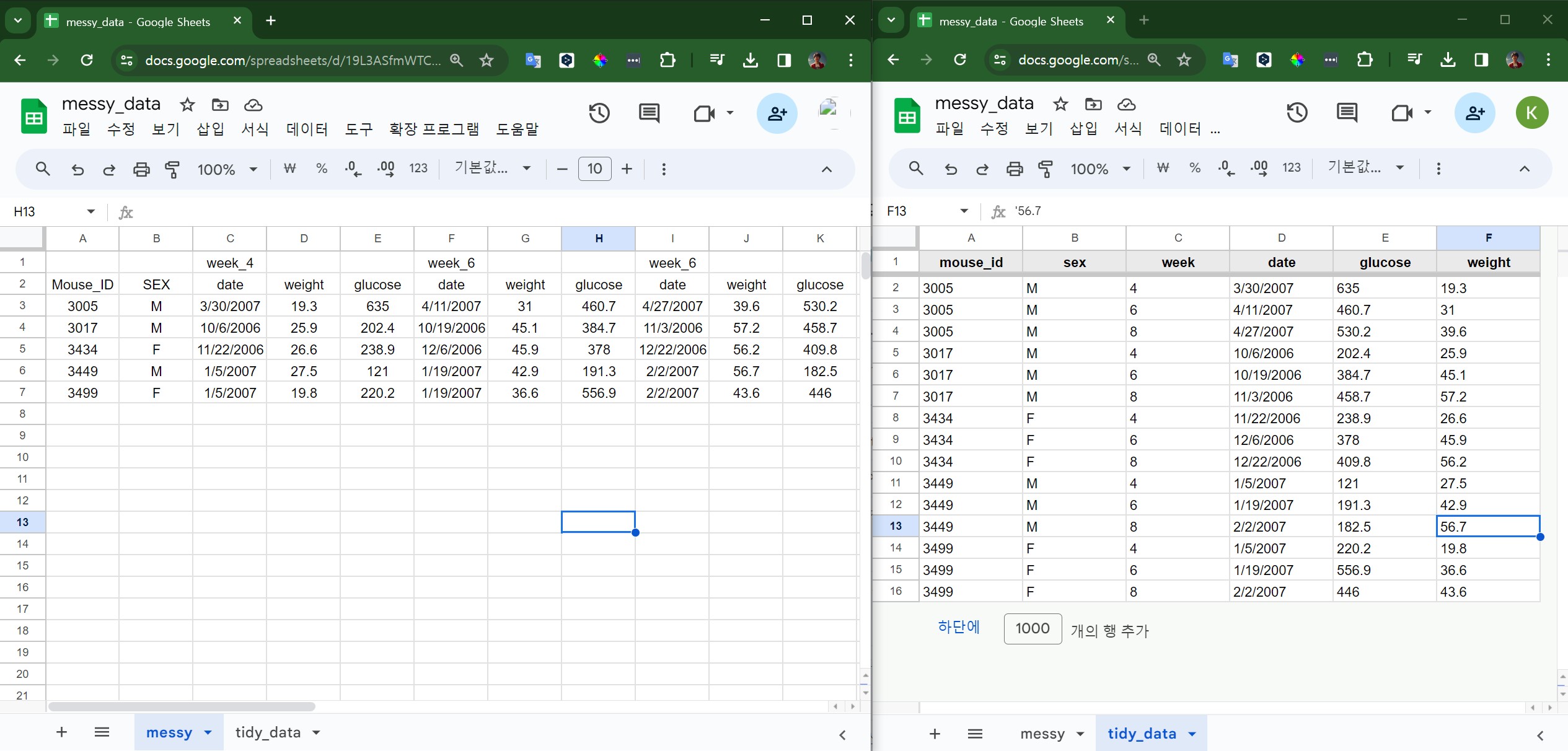
논문 데이터를 OCR 과정을 거친 후에 누구나 실습할 수 있도록 구글시트 messy_data로 공유되어 있다. 구글시트는 엑셀과 유사한 스프레드시트 프로그램이다. 구글시트에 저장된 데이터를 불러오기 위해서는 googlesheets4 패키지를 사용한다. googlesheets4 패키지를 사용하여 구글 시트의 엉망진창(messy) 데이터를 불러온다. read_sheet() 함수로 데이터를 읽어오고, set_names() 함수로 열 이름을 설정한다. pivot_longer() 함수를 사용하여 엉망진창 데이터를 깔끔한(tidy) 데이터로 변환한다. starts_with("week") 열을 선택하고, names_sep 인수로 “_”를 기준으로 열 이름을 분리한다. names_to와 values_to 인수를 사용하여 새로운 열 이름과 값을 지정한다. select(), rename(), mutate() 함수를 사용하여 필요한 열을 선택하고 이름을 변경한다. 최종적으로 깔끔한 데이터 형태로 변환된 데이터프레임을 얻는다.
library(googlesheets4)
# messy 데이터 불러오기
sheet_url <- "https://docs.google.com/spreadsheets/d/19L3ASfmWTCd1YikWHIHeWKdK29nXz-hhwktFU8qLAYc/"
messy_import <- read_sheet(sheet_url, skip = 1,
col_types = "ccccccccccc" )
messy_data <- messy_import |>
set_names(c("Mouse_ID", "SEX", "week_4_date", "week_4_weight",
"week_4_glucose", "week_6_date", "week_6_weight",
"week_6_glucose", "week_8_date", "week_8_weight",
"week_8_glucose"))
# messy 데이터를 tidy 데이터로 변환
tidy_data <- messy_data %>%
mutate(across(everything(), as.character)) |>
pivot_longer(cols = starts_with("week"),
names_to = c("week", "type", ".value"),
values_to = c("date", "glucose", "weight"),
names_sep = "_") |>
select(-week) |>
rename(week = type) |>
mutate(mouse_id = Mouse_ID,
sex = SEX) %>%
select(mouse_id, sex, week, date, glucose, weight)
tidy_data
#> # A tibble: 15 × 6
#> mouse_id sex week date glucose weight
#> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 3005 M 4 3/30/2007 635 19.3
#> 2 3005 M 6 4/11/2007 460.7 31
#> 3 3005 M 8 4/27/2007 530.2 39.6
#> 4 3017 M 4 10/6/2006 202.4 25.9
#> 5 3017 M 6 10/19/2006 384.7 45.1
#> 6 3017 M 8 11/3/2006 458.7 57.2
#> 7 3434 F 4 11/22/2006 238.9 26.6
#> 8 3434 F 6 12/6/2006 378 45.9
#> 9 3434 F 8 12/22/2006 409.8 56.2
#> 10 3449 M 4 1/5/2007 121 27.5
#> 11 3449 M 6 1/19/2007 191.3 42.9
#> 12 3449 M 8 2/2/2007 182.5 56.7
#> 13 3499 F 4 1/5/2007 220.2 19.8
#> 14 3499 F 6 1/19/2007 556.9 36.6
#> 15 3499 F 8 2/2/2007 446 43.6깔끔한 데이터를 구글시트의 tidy_data 시트에 저장한다. sheet_write() 함수를 사용하여 깔끔한 데이터를 구글시트에 저장한다. 이때 해당 시트에 권한이 부여되어야만 데이터를 저장할 수 있다. 권한이 부여되지 않은 경우에는 그림 26.4와 같이 편집자 권한을 부여하면 깔끔한 데이터가 구글시트에 저장된다.
tidy_data |>
sheet_write(ss = sheet_url, sheet = "tidy_data")
✔ Writing to mess_data.
✔ Writing to sheet tidy_data.26.4 요약
통계 패키지의 데이터 파일은 haven 패키지를 사용하여 일관된 방식으로 불러올 수 있으며, 스프레드시트 파일은 readxl과 googlesheets4 패키지를 사용하여 로컬 및 원격 데이터를 손쉽게 가져올 수 있다.
상용 소프트웨어의 독점적인 파일 형식은 단기적으로는 장점이 있지만, 장기적으로는 데이터 접근성과 재사용성 측면에서 개방형 파일 형식이 더 유리하다. 따라서 데이터를 저장하고 공유할 때는 가급적 개방형 파일 형식을 사용하는 것이 권장된다.