OpenAI에서 플러그인으로 출시한 코드 인터프리터(code interpreter)는 자연어 질문이나 요청을 받아 코드를 작성하고 실행하는 데 초점을 맞춘 도구다. 파이썬으로 프로그래밍 관련 문제를 해결하거나, 특정 알고리즘을 구현하는 데 유용하다. 사용자는 자연어로 복잡한 코드를 작성하거나 디버깅하는 과정 없이도 원하는 코드를 작성할 수 있고 결과도 직접 실행시켜 확인할 수 있다.
반면, OpenAI에서 코드 인터프리터를 고급 데이터 분석(advanced data analytics)으로 명칭을 변경한 후에 출시한 도구는 더 복잡한 데이터 분석과 시각화 기능을 제공한다. 코드 인터프리터가 실시간 코드 실행과 테스트에 초점을 맞춘 반면, 고급 데이터 분석은 복잡한 데이터 분석과 시각화에 초점을 두어 인사이트와 의사결정 지원에 기능이 특화되어 있다.
OpenAI에서 챗GPT에 플러그인 형태로 제공되던 코드 인터프리터와 고급 데이터 분석 기능은 챗 인터페이스에 하나로 통합되어 입력 데이터 유형에 따라 자동으로 코드 인터프리터와 고급 데이터 분석 기능이 활성화되어 실행되는 것으로 변경되었다.
29.1 광명시 인구현황 분석
29.1.1 데이터 수집
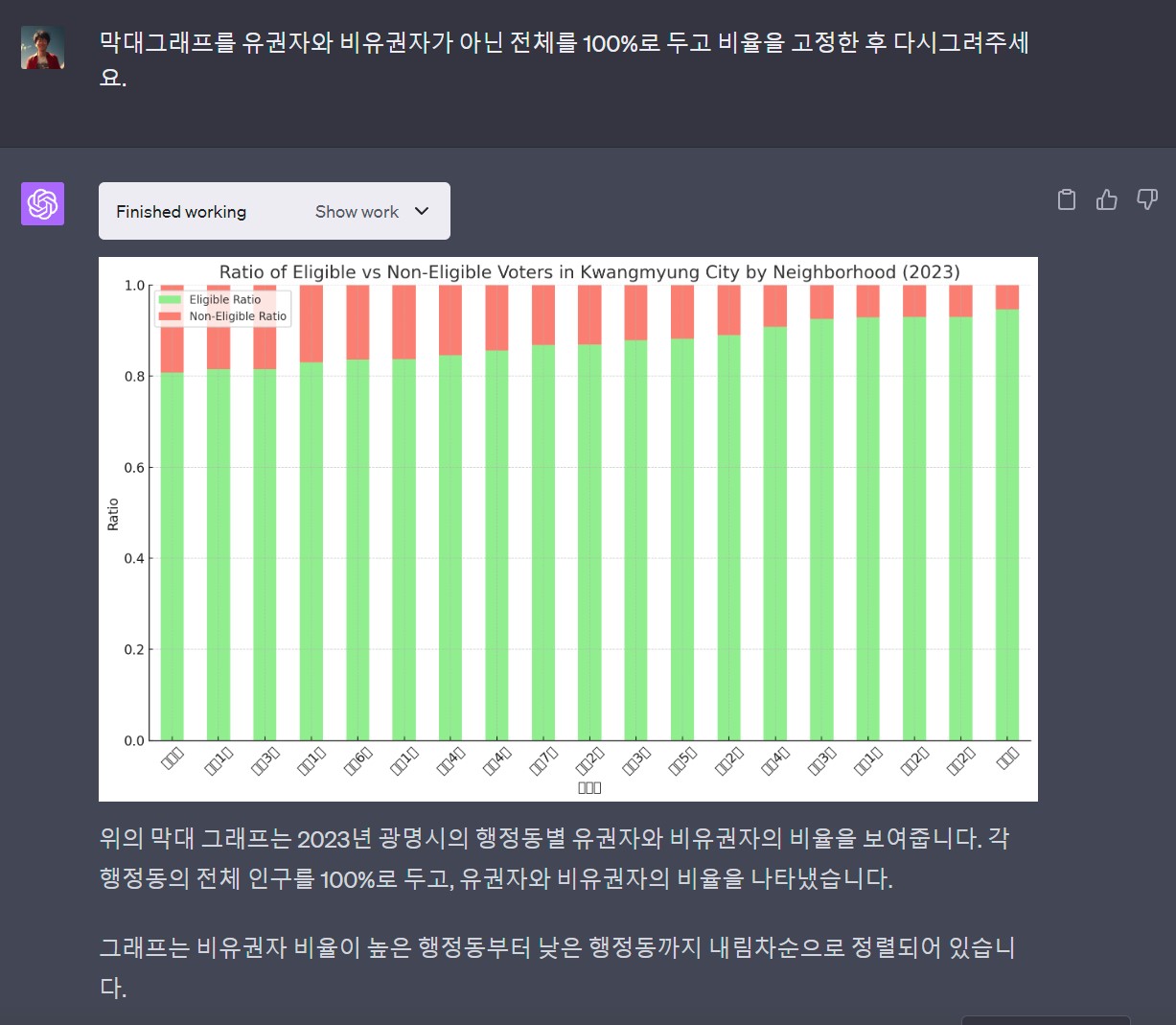
행정안전부 주민등록 인구 및 세대현황 웹사이트에서 광명시 2023년 7월 기준 인구현황 데이터를 가져온다.
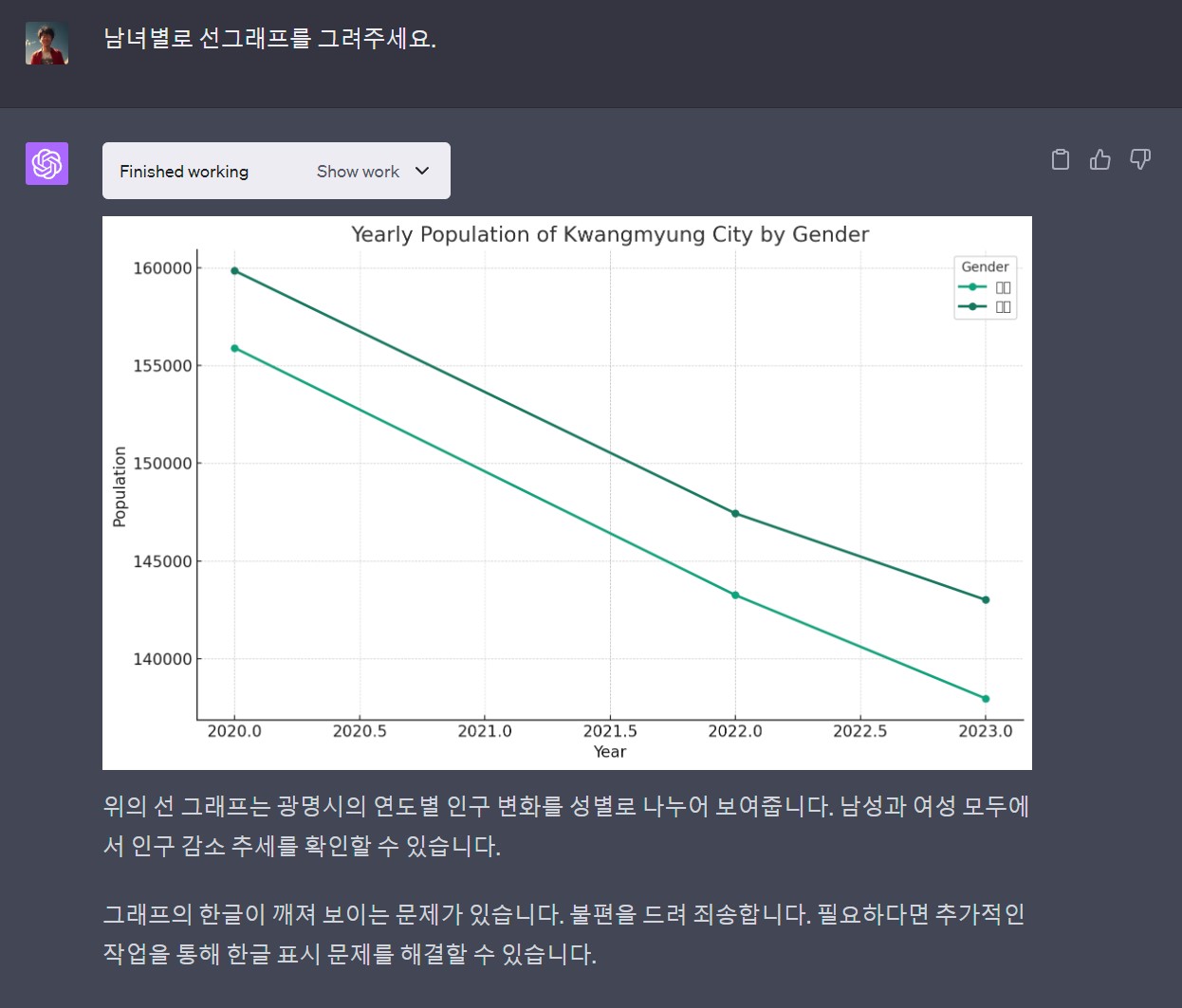
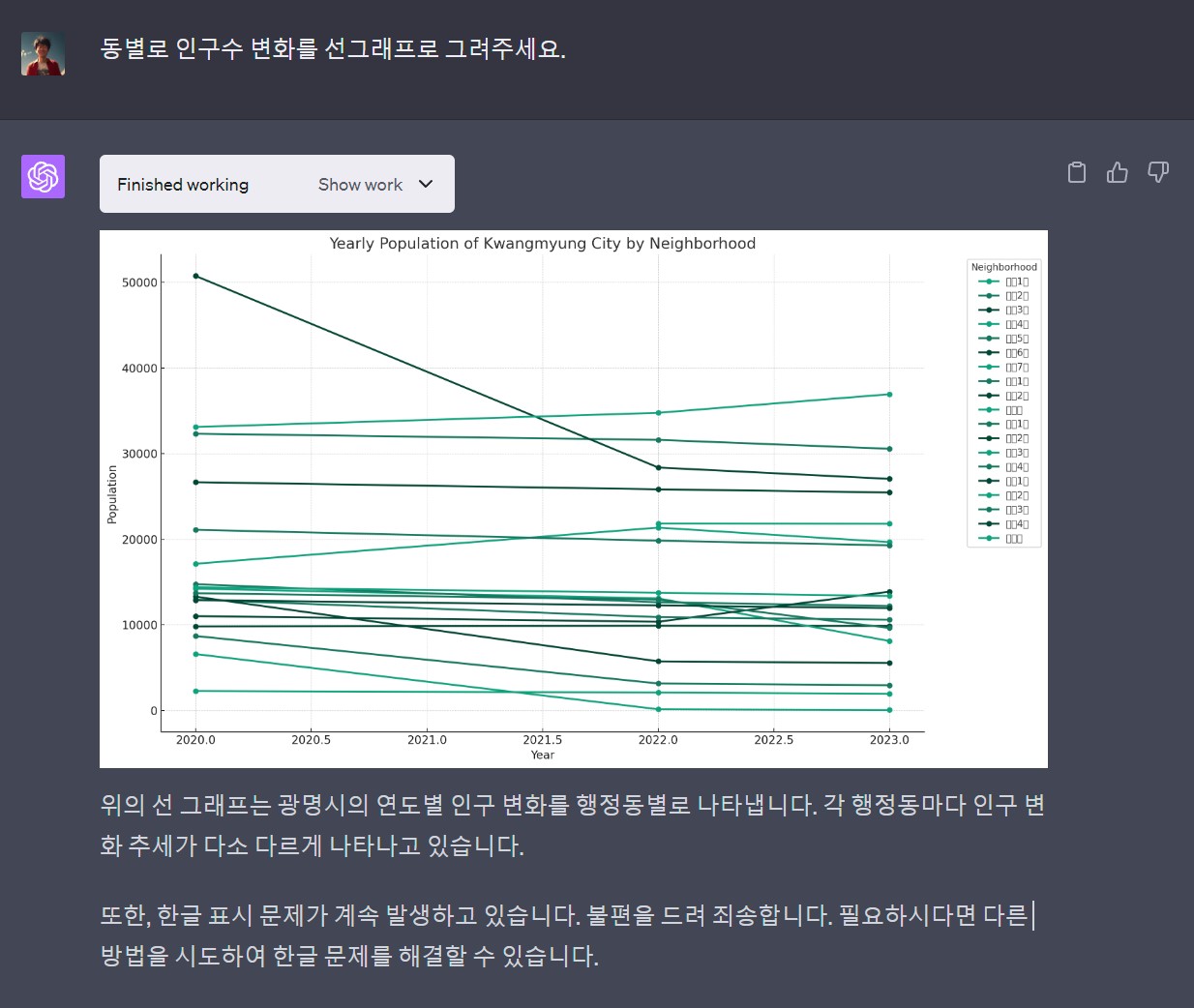
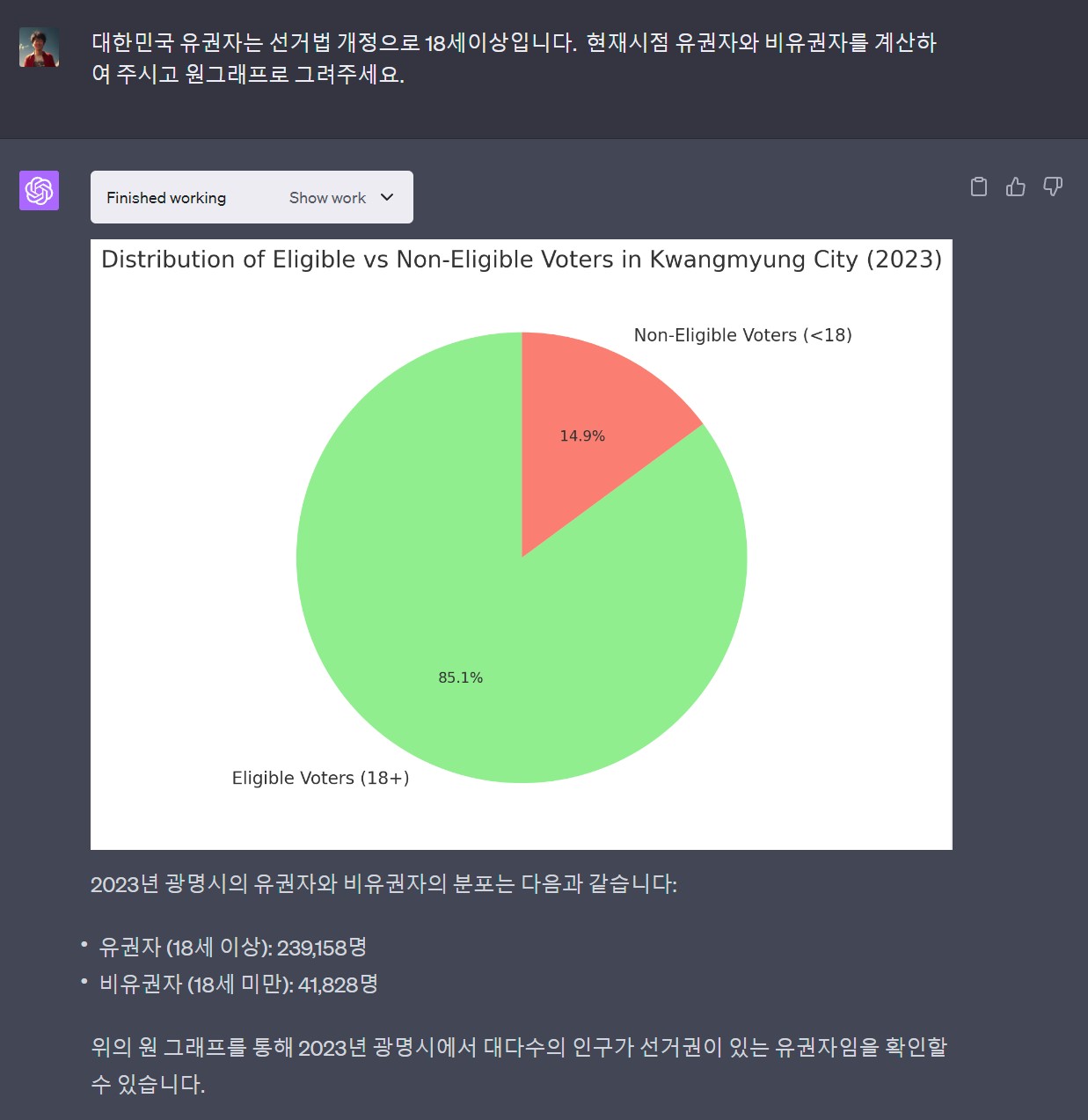
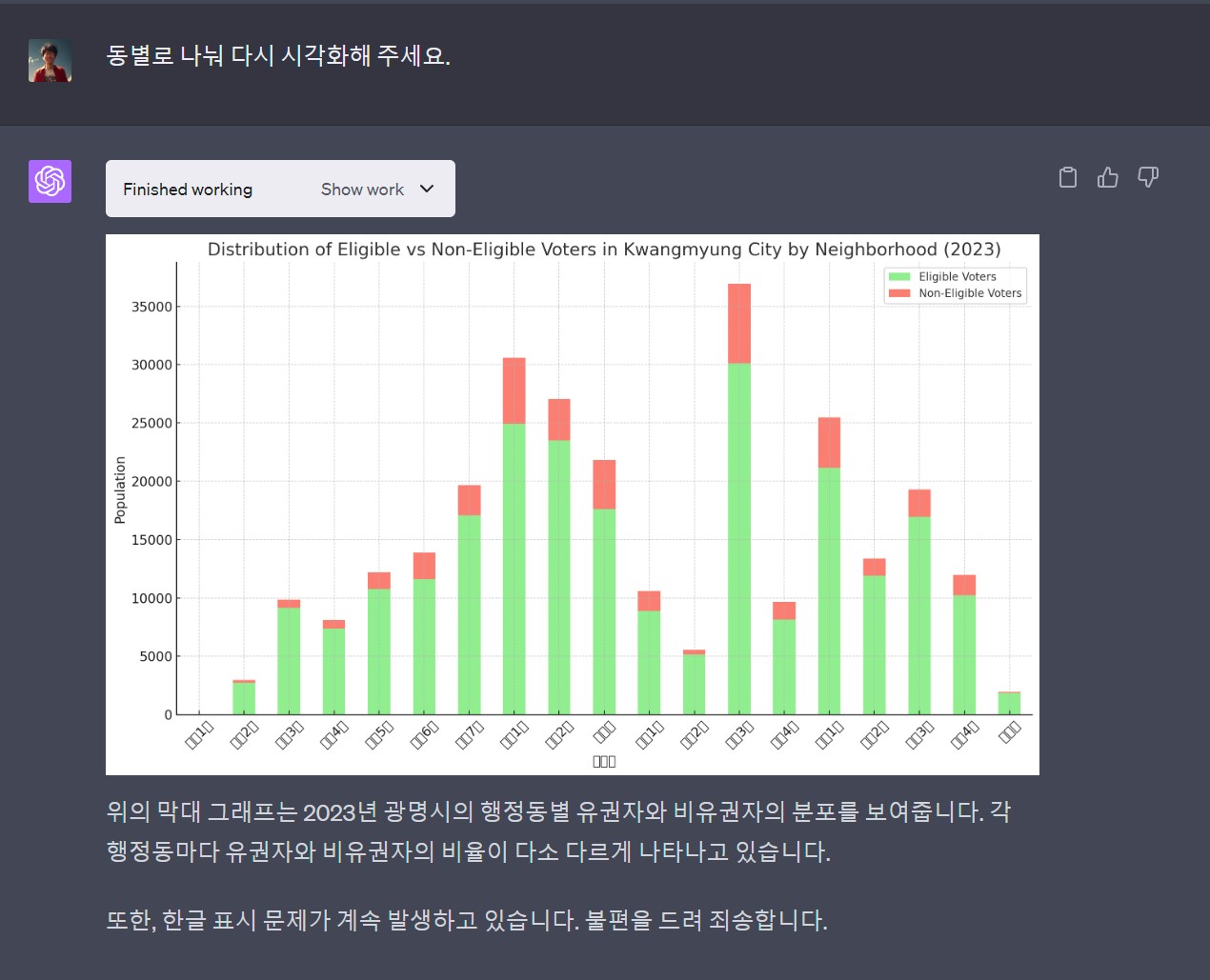
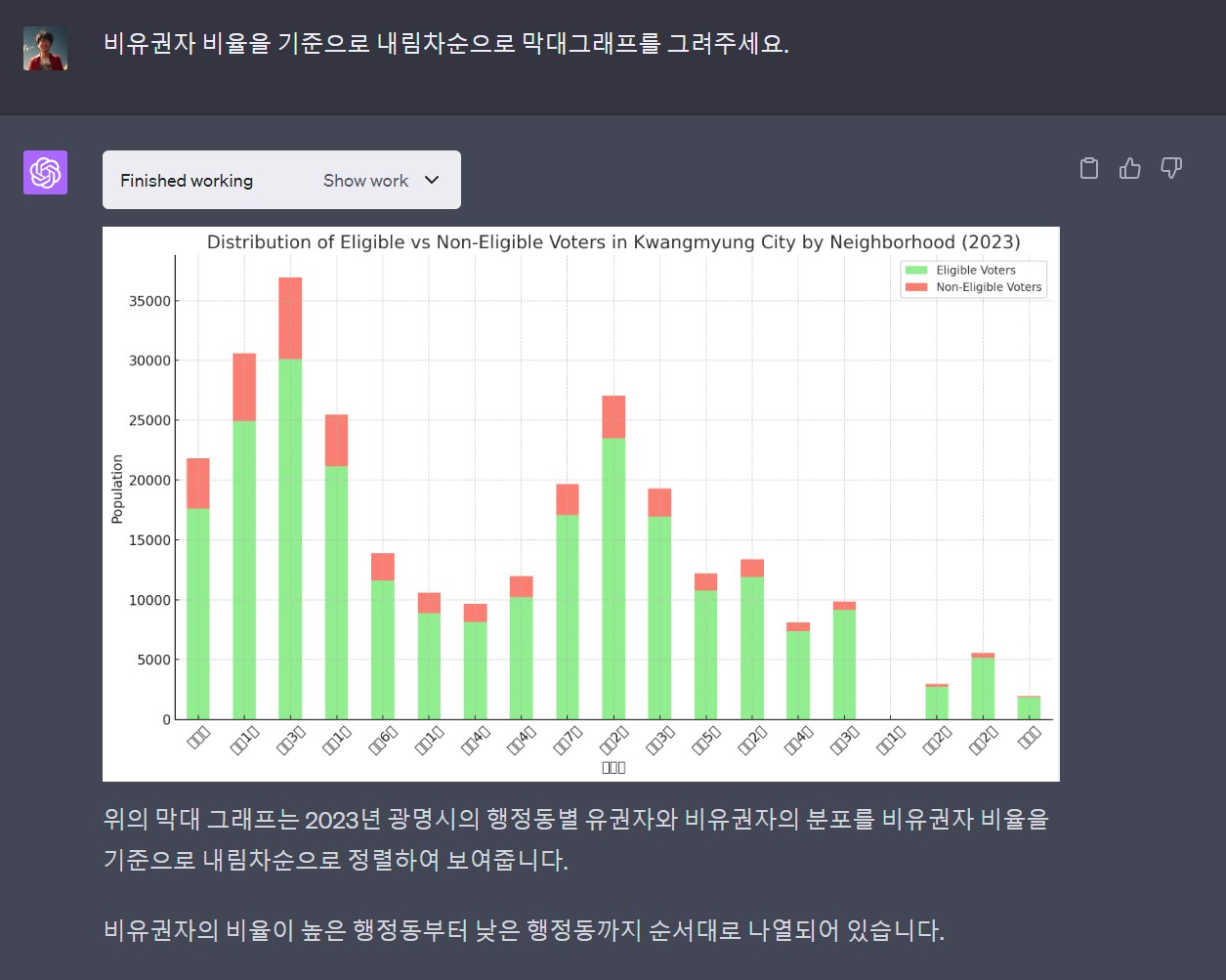
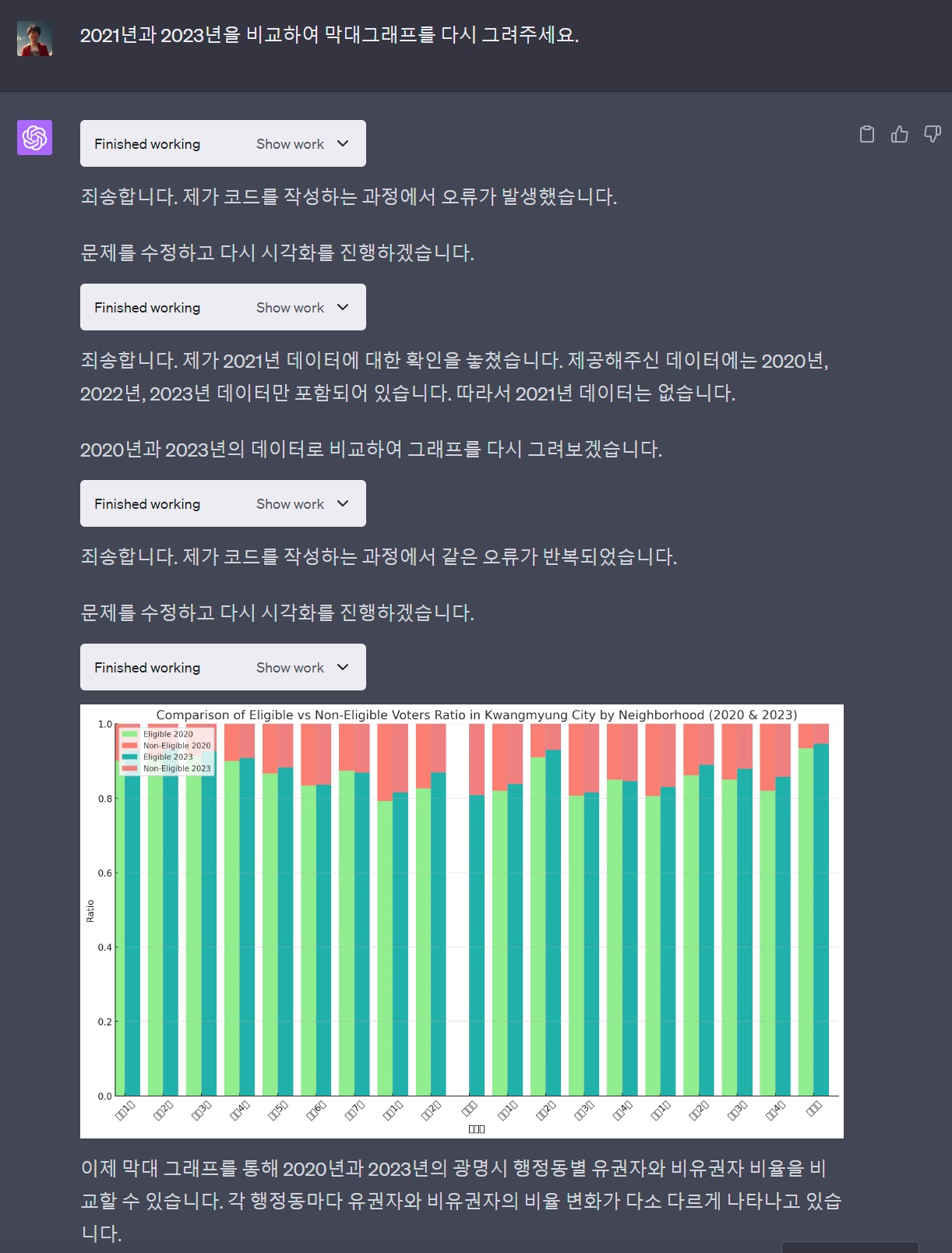
챗GPT 플러그인이 자연어를 파이썬 코드로 변경하고 실행한 결과를 출력하지만 한글 글꼴이 없기 때문에 한글이 깨져서 출력되는 것은 물론 시각화를 위한 프롬프트 의도를 제대로 이해하지 못하고 고급 시각화 기능을 구현하는데는 한계가 있다. 하지만, 자연어를 통해 빠르게 데이터 분석결과를 확인하고 대략적인 방향을 잡는 것에는 분명 큰 도움이 된다.
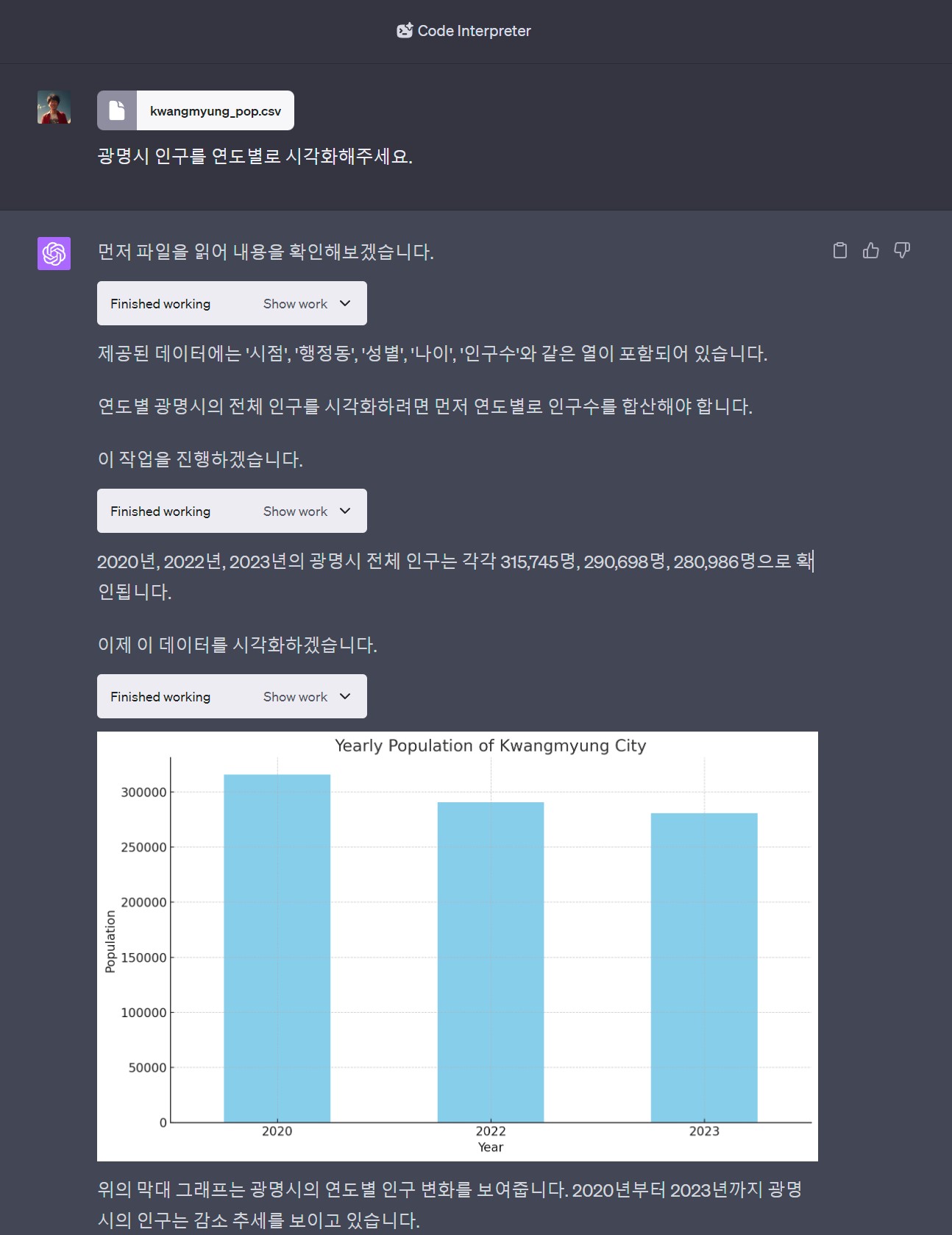
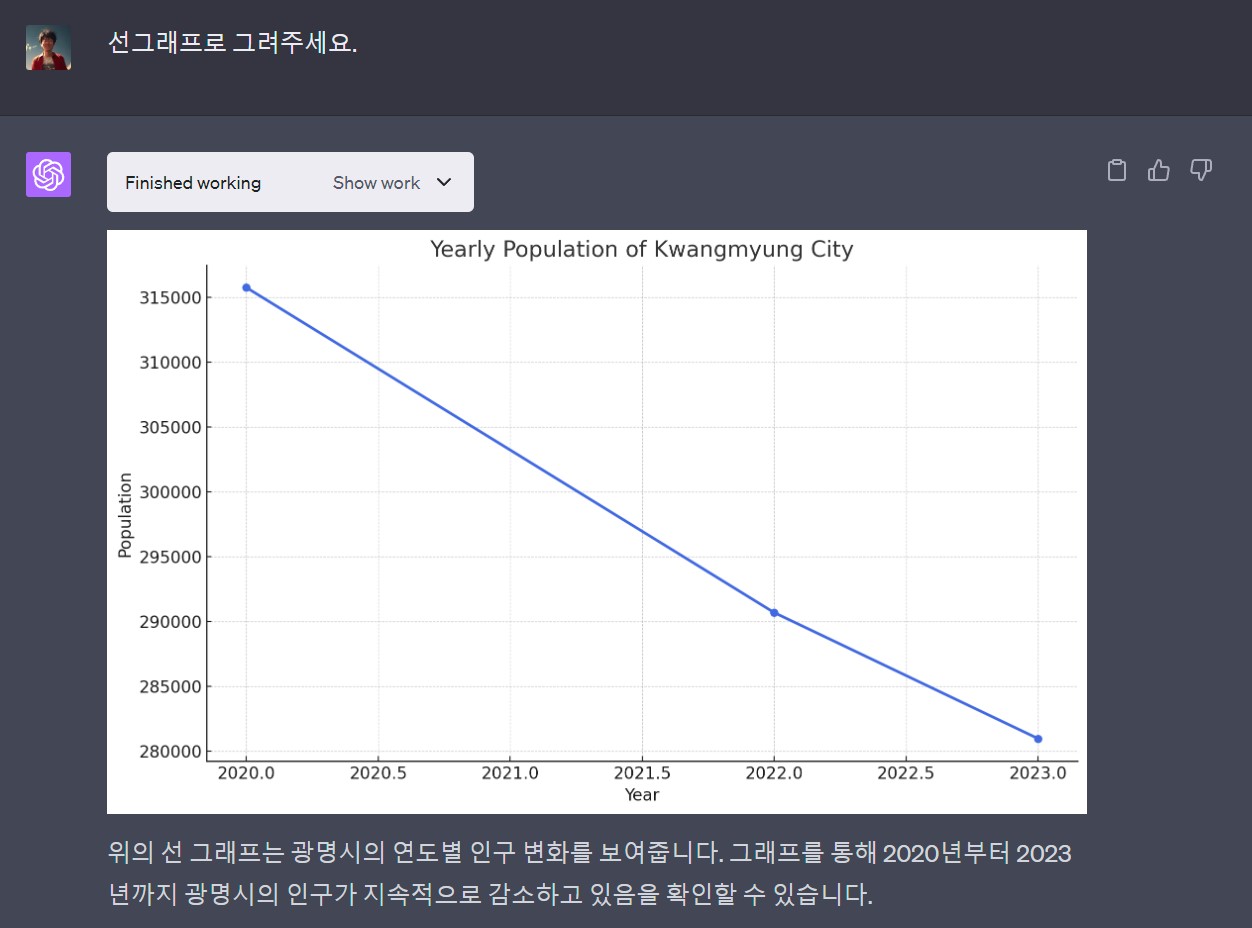
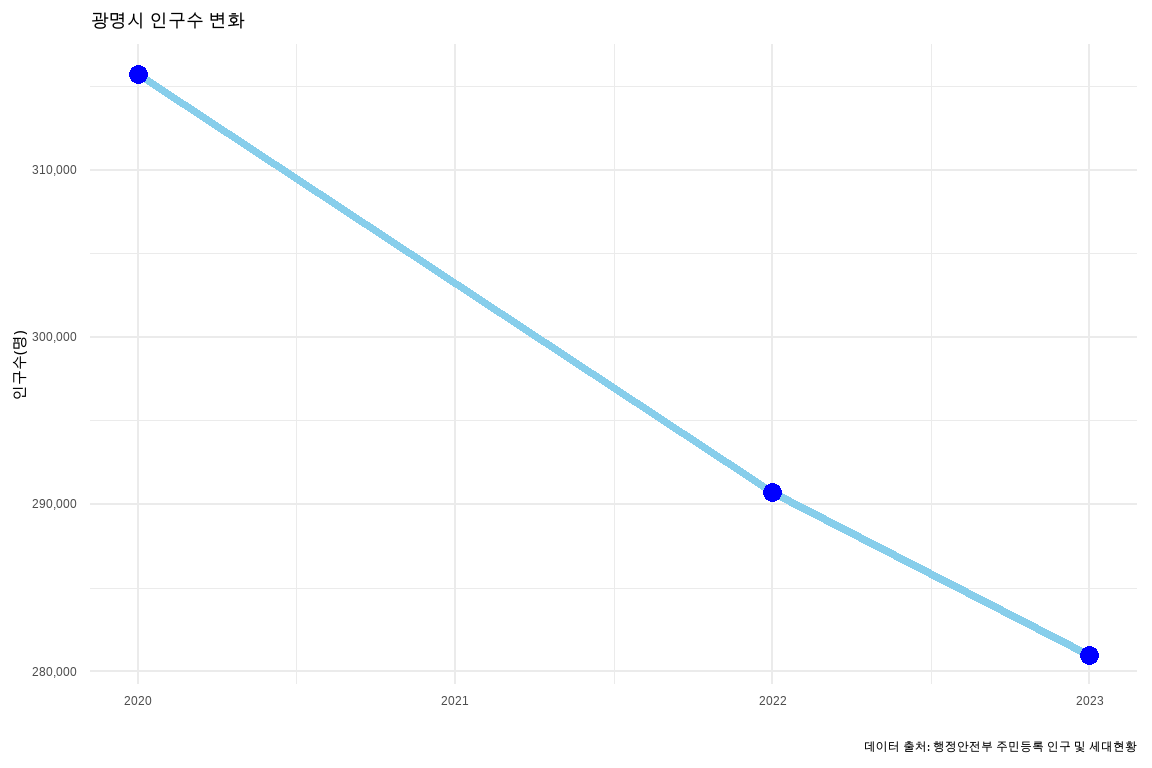
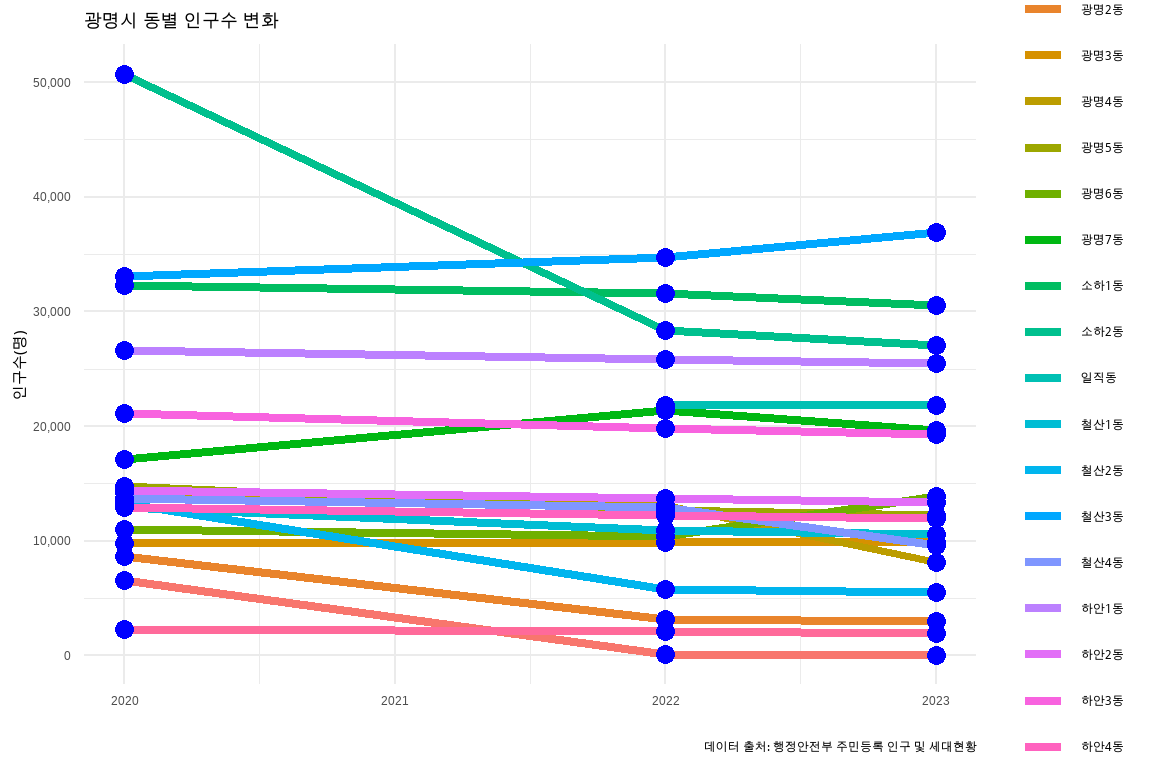
29.3.1 연도별 인구수
연도별 인구수를 시각화하는 마무리 작업은 파이썬 코드를 R로 챗GPT가 번역한 초벌 R 코드를 바탕으로 수정하여 시각화 작업을 마무리한다.
OpenAI의 코드 인터프리터(Code Interpreter)와 고급 데이터 분석(advanced data analytics) 플러그인은 자연어 질문을 통해 코드 작성과 데이터 분석을 보다 편리하게 수행할 수 있도록 한다. 광명시 인구현황 데이터를 수집하고 가공한 후 데이터 분석과 시각화를 수행해 보았다.
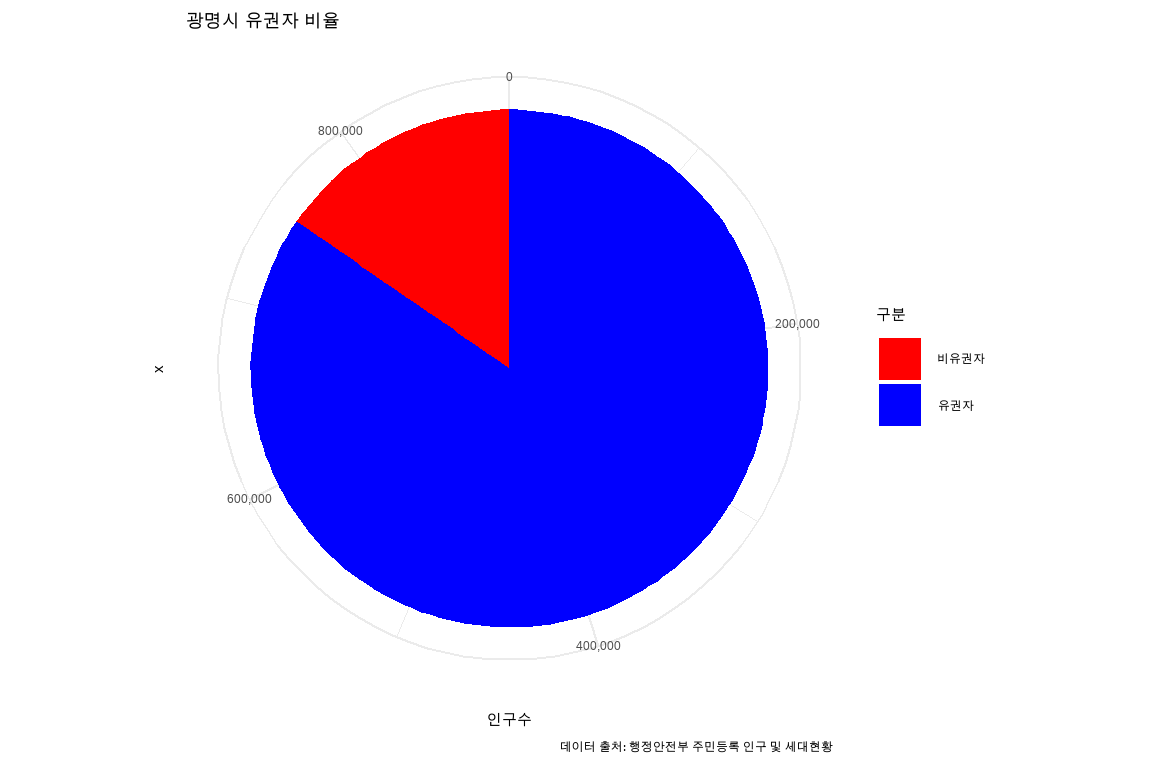
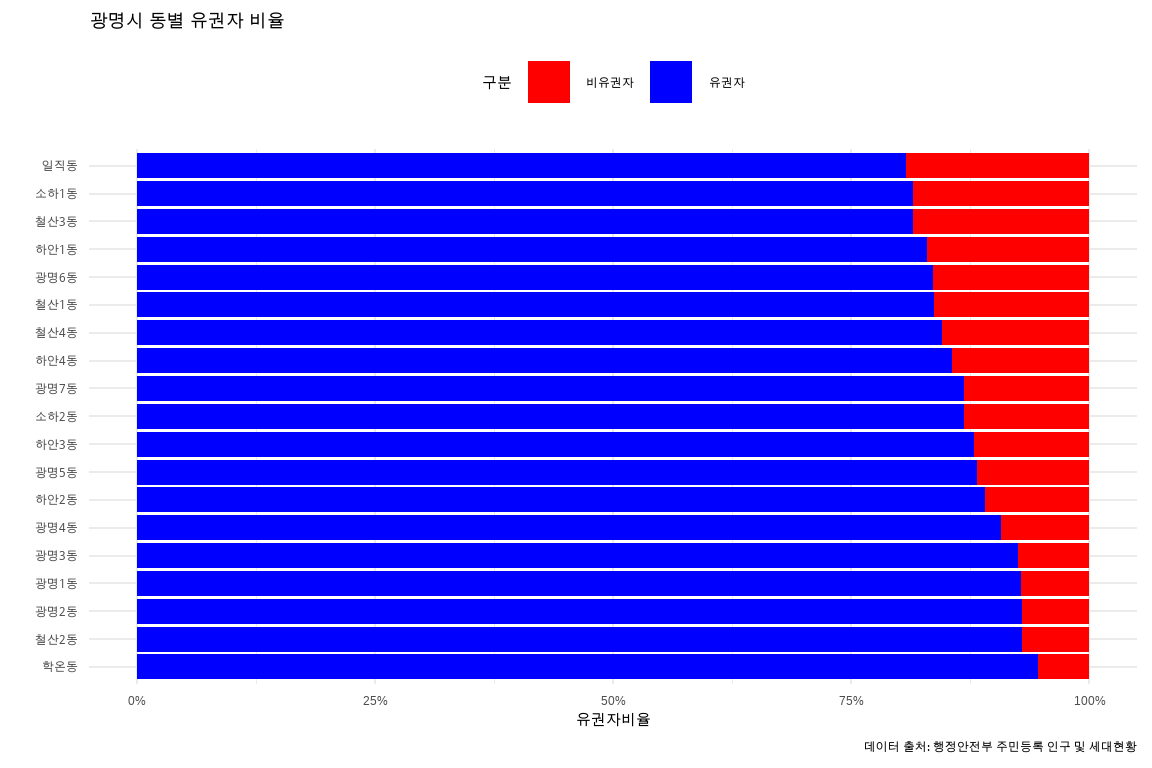
실습을 통해 광명시 연도별 인구 추이, 동별 인구 분포, 유권자 비율 등을 분석하고 시각화함으로써 광명시 인구 현황에 대한 전반적인 이해를 높일 수 있었다. 특히 챗GPT 코드 인터프리터를 활용하면 복잡한 코드 작성 과정 없이도 원하는 분석 결과를 빠르게 얻을 수 있어 데이터 분석 작업의 효율성을 크게 높일 수 있다.
또한 고급 데이터 분석 기능을 통해 다양한 시각화 옵션을 제공받을 수 있어 인사이트 도출에도 큰 도움이 된다. 앞으로도 새로운 데이터와 분석 주제에 챗GPT를 적극 활용해 보시길 추천하며, AI와 함께 데이터 분석 역량을 한층 더 높이고 보다 가치 있는 인사이트를 발견할 수 있을 것이다.