library(tidyverse)
library(gapminder)
calc_GDP <- function(dat, year=NULL, country=NULL) {
if(!is.null(year)) {
dat <- dat[dat$year %in% year, ]
}
if (!is.null(country)) {
dat <- dat[dat$country %in% country,]
}
gdp <- dat$pop * dat$gdpPercap
new <- cbind(dat, gdp=gdp)
return(new)
}
gapminder %>%
mutate(GDP = pop * gdpPercap)
#> # A tibble: 1,704 × 7
#> country continent year lifeExp pop gdpPercap GDP
#> <fct> <fct> <int> <dbl> <int> <dbl> <dbl>
#> 1 Afghanistan Asia 1952 28.8 8425333 779. 6567086330.
#> 2 Afghanistan Asia 1957 30.3 9240934 821. 7585448670.
#> 3 Afghanistan Asia 1962 32.0 10267083 853. 8758855797.
#> 4 Afghanistan Asia 1967 34.0 11537966 836. 9648014150.
#> 5 Afghanistan Asia 1972 36.1 13079460 740. 9678553274.
#> 6 Afghanistan Asia 1977 38.4 14880372 786. 11697659231.
#> 7 Afghanistan Asia 1982 39.9 12881816 978. 12598563401.
#> 8 Afghanistan Asia 1987 40.8 13867957 852. 11820990309.
#> 9 Afghanistan Asia 1992 41.7 16317921 649. 10595901589.
#> 10 Afghanistan Asia 1997 41.8 22227415 635. 14121995875.
#> # ℹ 1,694 more rows16 분할-적용-병합 전략
데이터 분석에서 흔히 사용되는 방법 중 하나가 분할-적용-병합(Split-Apply-Combine) 전략(Wickham 2011)이다. 즉, 큰 문제를 작은 문제로 쪼개고 각 문제에 대해서 적절한 연산(예를 들어 요약통계량)을 취하고 이를 결합하는 방법이 많이 사용되는 방법이다. 예를 들어 재현가능한 과학적 분석을 위한 R - “분할-적용-병합 전략”에 나온 것처럼 각 그룹별로 쪼갠 후에 각 그룹별로 평균을 내고 이를 조합한 사례가 전반적인 큰 그림을 그리는 데 도움이 될 수 있다. 여기서 평균을 사용했는데 요약(summarize) 뿐만 아니라, 윈도우 함수, 이를 일반화한 do() 함수도 포함된다.1
16.1 gapminder 데이터셋
gapminder 데이터 팩키지의 각 대륙, 국가, 연도별 인구와 중요 두 가지 정보인 평균수명과 일인당 GDP 정보를 바탕으로 각 대륙별 평균 GDP를 추출해보자. 이를 위해서 먼저 인당 GDP(gdpPercap)와 인구수(pop)를 바탕으로 GDP를 계산하고 이를 평균낸다. 특정 연도를 지칭하지 않는 것이 다소 문제의 소지가 있을 수 있지만, 분할-적용-병합 전략을 살펴보는 데 큰 무리는 없어 보인다.
16.2 진화의 역사
R에서 데이터 처리를 위한 분할-적용-병합 전략은 시간이 지남에 따라 발전해왔다. 초기에는 베이스 R 함수를 사용하여 데이터를 처리했지만, 점차 새로운 패키지와 함수가 개발되면서 더 효율적이고 가독성 높은 코드를 작성할 수 있게 되었다. 각 시대별로 주로 사용된 패키지와 함수가 발전함에 따라 데이터 처리에 대한 인식과 요구 사항을 반영하고 있기 때문이다.
- 선사시대 분할-적용-병합:
split,lapply,do.call(rbind, ...)- 기본 R 함수를 사용하여 데이터를 분할하고,
lapply로 각 분할에 함수를 적용한 후,do.call과rbind를 사용하여 결과를 결합한다.
- 기본 R 함수를 사용하여 데이터를 분할하고,
- 석기시대(
plyr) 분할-적용-병합:plyr::ddply-
plyr패키지의ddply함수를 사용하여 데이터를 분할, 함수 적용, 결합을 한 번에 처리한다.
-
- 초기 tidyverse 시대 분할-적용-병합:
group_by,do-
dplyr패키지의group_by함수를 사용하여 데이터를 그룹화하고,do함수를 사용하여 각 그룹에 함수를 적용한다.
-
- 중기 tidyverse 시대 분할-적용-병합:
group_by&by_slice-
group_by함수로 데이터를 그룹화한 후,by_slice함수를 사용하여 각 그룹에 함수를 적용한다.
-
- 현대 tidyverse 시대 분할-적용-병합:
group_by,nest,mutate(map())-
group_by함수로 데이터를 그룹화하고,nest함수로 각 그룹을 중첩 데이터프레임으로 변환한 후,mutate와purrr패키지의map함수를 사용하여 각 그룹에 함수를 적용한다.
-
- tidyverse/base 하이브리드 조합 분할-적용-병합:
split,map_dfr- 기본 R의
split함수로 데이터를 분할하고,purrr패키지의map_dfr함수를 사용하여 각 분할에 함수를 적용하고 결과를 데이터프레임으로 결합한다.
- 기본 R의
16.2.1 선사시대
선사시대에는 대륙별로 split한 후에 lapply() 함수를 사용해서 앞서 정의한 calc_GDP 함수로 GDP를 계산한 후에 평균을 다시 계산한 뒤에 마지막으로 do.call() 함수로 병합(combine)하여 GDP 대륙별 평균을 구할 수 있다.
continent_split_df <- split(gapminder, gapminder$continent)
GDP_list_df <- lapply(continent_split_df, calc_GDP)
GDP_list_df <- lapply(GDP_list_df, function(x) mean(x$gdp))
mean_GDP_df <- do.call(rbind, GDP_list_df)
mean_GDP_df
#> [,1]
#> Africa 20904782844
#> Americas 379262350210
#> Asia 227233738153
#> Europe 269442085301
#> Oceania 18818710535416.2.2 석기시대
석기시대에는 plyr 패키지의 ddply 함수를 사용해서 각 대륙별로 쪼갠 후에 각 대륙별 평균 GDP를 구할 수 있다.
16.2.3 초기 tidyverse 시대
group_by() + do()를 결합하여 임의 연산작업을 각 그룹별로 수행시킬 수 있다.
16.2.4 중기 tidyverse 시대
group_by() + by_slice()를 결합하여 분할-적용-병합 전략을 적용시킬 수도 있으나 by_slice() 함수가 dplyr::do() 함수와 같은 작업을 수행했고, purrrlyr로 갔다가 그 후 행방이 묘연해졌다.
gapminder %>%
group_by(continent) %>%
purrrlyr::by_slice(~calc_GDP(.x), .collate = 'rows') %>%
select(continent, gdp) %>%
group_by(continent) %>%
purrrlyr::by_slice(~mean(.$gdp), .collate = 'rows')
#> # A tibble: 5 × 2
#> continent .out
#> <fct> <dbl>
#> 1 Africa 20904782844.
#> 2 Americas 379262350210.
#> 3 Asia 227233738153.
#> 4 Europe 269442085301.
#> 5 Oceania 188187105354.
16.2.5 현대 tidyverse 시대
현대 분할-적용-병합 전략은 group_by + nest()로 그룹별 데이터프레임으로 만들고, mutate(map())을 사용해서 calc_GDP() 함수를 적용시켜 GDP를 계산하고, summarize() 함수를 적용시켜 각 대륙별 평균 GDP를 계산한다. 마지막으로 unnest를 적용시켜 원하는 산출물을 얻는다.
gapminder %>%
group_by(continent) %>%
nest() %>%
mutate(data = purrr::map(data, calc_GDP)) %>%
mutate(mean_GDP = purrr::map(data, ~ summarize(., mean_GDP = mean(gdp)))) %>%
unnest(mean_GDP)
#> # A tibble: 5 × 3
#> # Groups: continent [5]
#> continent data mean_GDP
#> <fct> <list> <dbl>
#> 1 Asia <df [396 × 6]> 227233738153.
#> 2 Europe <df [360 × 6]> 269442085301.
#> 3 Africa <df [624 × 6]> 20904782844.
#> 4 Americas <df [300 × 6]> 379262350210.
#> 5 Oceania <df [24 × 6]> 188187105354.
16.2.6 tidyverse/base R 조합
마지막으로 base R의 split() 함수와 map_dfr() 함수를 조합해서 원하는 결과를 얻어낼 수도 있다.
gapminder %>%
split(.$continent) %>%
purrr::map_dfr(calc_GDP) %>%
split(.$continent) %>%
purrr::map_dfr(~mean(.$gdp)) %>%
gather(continent, mean_GDP)
#> # A tibble: 5 × 2
#> continent mean_GDP
#> <chr> <dbl>
#> 1 Africa 20904782844.
#> 2 Americas 379262350210.
#> 3 Asia 227233738153.
#> 4 Europe 269442085301.
#> 5 Oceania 188187105354.
16.3 gapminder 실습
앞서, 함수를 사용해서 코드를 단순화하는 방법을 살펴봤다. gapminder 데이터셋을 인자로 받아, pop와 gdpPercap를 곱해 GDP를 계산하는 calcGDP 함수를 정의했다. 추가적인 인자를 정의해서, year별, country별 필터를 적용할 수도 있다.
데이터 작업을 할 때, 흔히 마주치는 작업이 집단별로 그룹을 묶어 계산하는 것이다. 위에서는 단순히 두 열을 곱해서 GDP를 계산했다. 하지만, 대륙별로 평균 GDP를 계산하고자 한다면 어떻게 해야 할까?
calcGDP를 실행하고 나서, 각 대륙별로 평균을 산출해보자. 데이터셋을 가져와서 인구 열과 1인당 GDP 열을 곱합니다.
하지만, 그다지 멋있지는 않다. 그렇다. 함수를 사용해서 반복되는 작업을 상당 부분 줄일 수 있었다. 함수 사용은 멋있었다. 하지만, 여전히 반복이 있다. 직접 반복하게 되면, 지금은 물론이고 나중에도 시간을 까먹게 되고, 잠재적으로 버그가 스며들 여지를 남기게 된다.
calcGDP처럼 유연성 있는 함수를 새로 작성할 수도 있지만, 제대로 동작하는 함수를 개발하기까지는 상당한 노력과 테스트가 필요하다.
여기서 맞닥뜨린 추상화 문제를 “분할-적용-병합(split-apply-combine)” 전략이라고 한다.
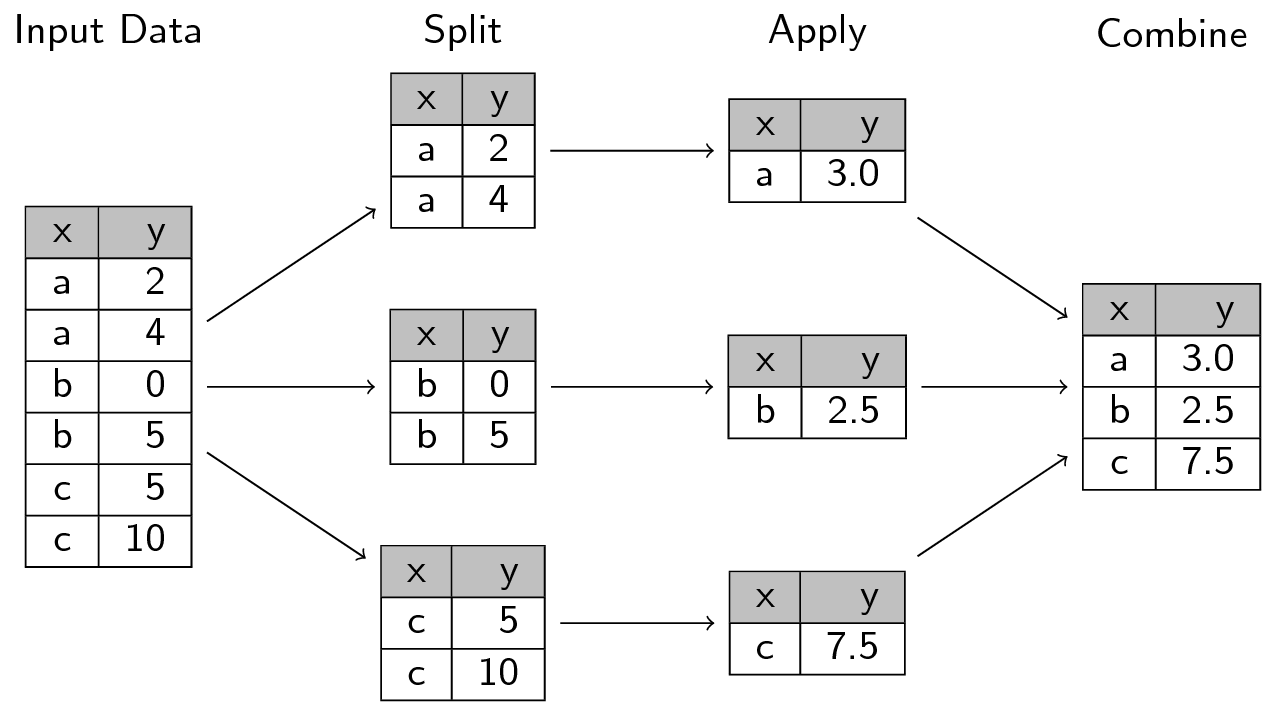
데이터를 집단으로 분할(split)하고, 이번 경우에는 대륙별로 분할한다. 그리고 분할된 집단에 연산을 적용(apply)한 후, 선택적으로 결과를 묶어 병합(combine)한다.
16.3.1 dplyr 패키지
dplyr 패키지는 데이터 조작을 위한 문법을 제공하며, 이를 통해 “분할-적용-병합” 문제를 해결할 수 있다. 먼저 dplyr 패키지를 로드하고, dplyr을 사용하여 대륙별 평균 GDP를 빠르게 계산한다.
방금 코드에서 일어난 일을 복기해 보자.
-
%>%파이프 연산자를 사용하여calcGDP(gapminder)함수의 결과를 다음 단계로 전달했다. -
group_by(continent)를 사용하여 데이터를 대륙별로 그룹화했다. -
summarise()를 사용하여 각 그룹에 대해mean(gdp)를 계산하고, 결과를mean_gdp라는 새로운 열에 저장했다.
그룹화 변수를 추가하면 어떻게 될까?
group_by()에 year를 추가하여 대륙과 연도별로 그룹화했다.
도전과제
대륙별로 평균 기대수명을 계산해보자. 어느 대륙의 기대수명이 가장 길고, 어느 대륙이 가장 짧은가?
해답
도전과제
dplyr의 함수를 사용하여 도전과제 2의 출력 결과로부터, 1952년에서 2007년 사이의 평균 기대수명 차이를 계산해보자.
해답
이렇게 dplyr 패키지를 사용하면 데이터 조작과 분석을 보다 간결하고 직관적으로 수행할 수 있다. 파이프 연산자(%>%)를 사용하여 연산을 연결하면 코드의 가독성도 향상된다. group_by(), summarise(), mutate() 등의 함수를 조합하여 다양한 분석 작업을 수행할 수 있다.
도전과제
실제로 실행하지 말고, 다음 중 어떤 코드가 대륙별 평균 기대수명을 계산하는지 살펴보자.
해답
답안 1은 대륙별 평균 기대수명을 계산한다.
16.4 요약
분할-적용-병합 전략은 큰 문제를 작은 문제로 쪼개어 각각에 대해 연산을 수행하고 그 결과를 다시 합치는 방식으로, 데이터를 그룹별로 처리하고 요약하는 데 효과적이다.
R에서 분할-적용-병합 전략은 시대에 따라 발전해 왔는데, 초기에는 베이스 R 함수를 사용하다가 plyr, dplyr 등의 패키지가 개발되면서 보다 간결하고 가독성 높은 코드를 작성할 수 있게 되었다. 특히 dplyr 패키지는 파이프 연산자(%>%)와 함께 그룹화(group_by()), 요약(summarise()), 변환(mutate()) 등의 함수를 제공하여 데이터 조작과 분석을 매우 직관적으로 수행할 수 있다.
gapminder 데이터셋을 활용한 실습을 통해 분할-적용-병합 전략의 실제 적용 방법을 살펴보고, 대륙별, 연도별로 그룹화하여 평균 GDP와 기대수명을 계산하는 예제를 통해 dplyr 패키지의 강력함을 체감할 수 있었다. 또한 dplyr의 함수를 조합하여 다양한 분석 작업을 수행할 수 있음을 확인했다.