컴퓨터를 기반으로 한 시각화 시스템은 시각적으로 데이터를 표현함으로써 사람이 작업을 더욱 효율적으로 수행할 수 있도록 돕는다. 시각화는 시각지능을 갖춘 인공지능을 통해 사람을 대체하는 데 초점을 둔 것이 아니라 시각화를 통해 인간능력을 보조하고 증강시키는 데 유용하다. 따라서, 완전 자동화 해결책이 존재하고 신뢰성이 있는 경우에는 시각화가 필요하지 않다. 하지만, 많은 분석과 개발 문제에서 어떤 질문을 던져야 하는지 사전에 알고 있는 경우가 적어, 명세가 분명하지 않을 때는 시각화가 적합하다.
10.1 시각화 이유
시각화는 최종 데이터분석 결과를 표현하는 데이터 과학 제품과 인포그래픽으로 많은 관심을 받았다. 하지만 꼭 시각화가 데이터 과학 최종 결과물로서만 의미가 있는 것은 아니다. 인포그래픽과 같은 최종 결과를 제작하는 과정은 수많은 시도와 실패의 결과물로 조금씩 진전을 이뤄낸 산출물이다. 이 과정에서 데이터에 대한 충분한 이해가 필요한데 원본 데이터를 눈으로 일일이 살펴보거나 요약 통계량으로 데이터가 갖고 있는 의미를 충분히 살펴보는 데는 한계가 있다. 원데이터를 첫 번째 행부터 마지막 행까지, 첫 번째 변수부터 마지막 변수까지 일일이 살펴보는 작업은 상당한 인지부하를 가져와 쉽게 피로를 유발한다. 인지부하(cognitive load)를 시각적 지각(perception)으로 해당 작업을 바꿔 수월히 업무를 수행하는 데 필수적인 기법이 시각화(Visualization)(Munzner 2014)라고 볼 수 있다.
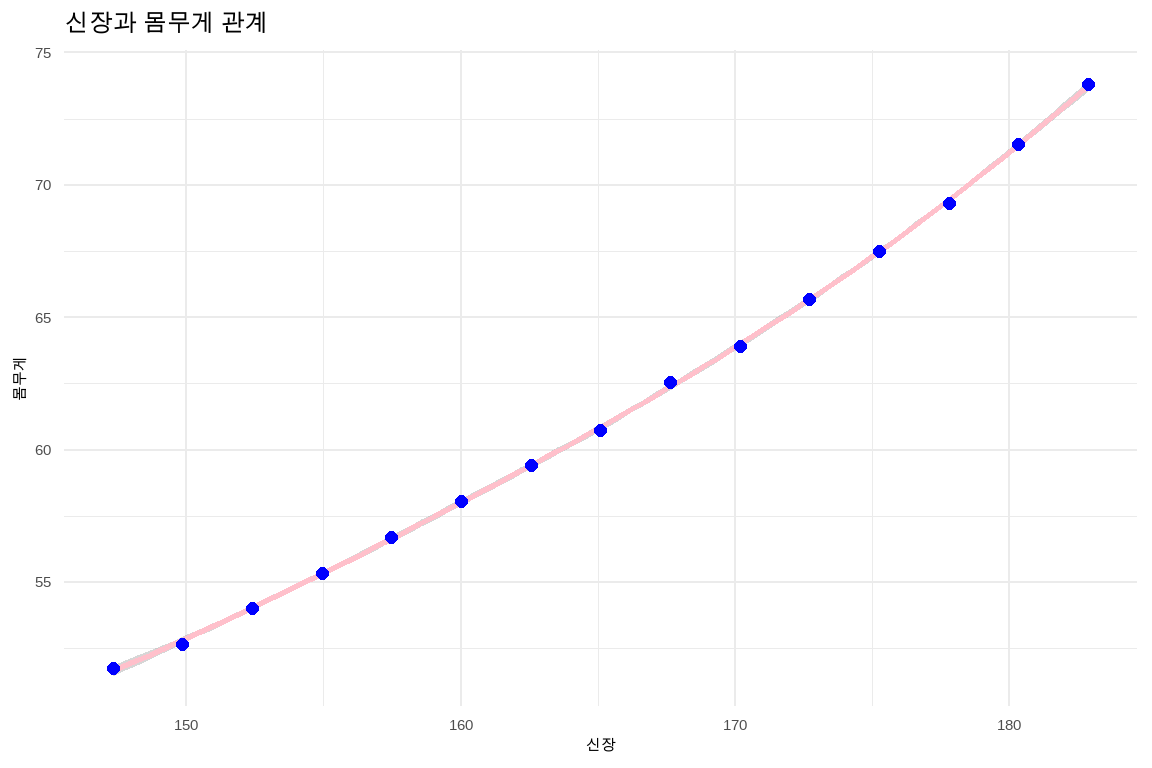
datasets 패키지에 포함된 women 데이터는 이미 정렬이 되어 있어서, 신장이 커짐에 따라 체중이 증가하는 것을 알 수 있지만, 데이터만 보고 이해하려면 인지적으로 데이터 한 줄을 읽고 머리속으로 생각하고, 두 번째 줄을 읽고 생각하고, … 이런 과정을 반복하면서 인지적 부하가 증가하게 된다. 하지만, 시각적으로 표현하게 되면 한눈에 신장과 체중 관계를 볼 수 있다.
women 데이터셋이 몸무게는 파운드(lbs), 신장(inch)로 되어 있어 우리나라에서 사용하는 kg, cm 단위로 시각화에 앞서 변환시킨다.
women%>%mutate(height =2.54*height, weight =0.45*weight)%>%ggplot(aes(y=weight, x=height))+geom_smooth(color='pink')+geom_point(color='blue', size=2)+labs(x ="신장", y ="몸무게", title ="신장과 몸무게 관계")
그림 10.1: 시각화를 통한 신장과 몸무게 관계
10.2 앤스콤 4종류 데이터
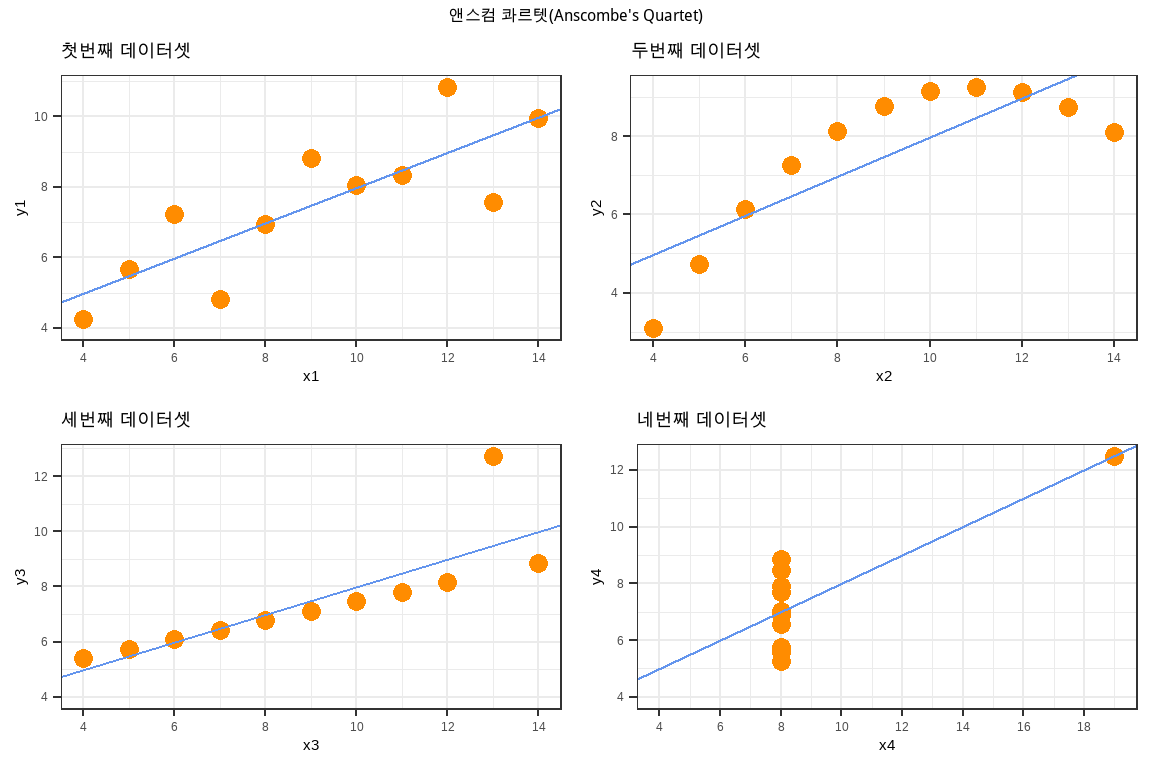
앤스콤(Anscombe 1973)은 1973년 “Anscombe’s Quartet”로 알려진 동일한 통계량을 갖는 4종류 데이터셋을 만들어서 시각화의 중요성을 일깨웠다. 앤스콤 데이터셋은 평균, 분산, 상관계수, 회귀직선 등 주요 통계치가 매우 유사한 4쌍의 데이터로 구성되어 있다. 그러나 이 데이터들을 그래프로 시각화했을 때 서로 완전히 다른 패턴과 관계성을 보여준다.
단순히 숫자로 요약된 통계만으로는 데이터의 특성을 제대로 파악하기 어려울 수 있다는 점을 시사하는 것으로, 데이터를 시각적으로 표현함으로써 숨겨진 패턴, 이상치, 추세 등을 직관적으로 발견할 수 있다. 두 변수 x, y에 대한 통계량에 대한 정보는 다음과 같다.
통계량
값
평균(x)
9
분산(x)
11
평균(y)
7.5
분산(y)
4.1
상관계수
0.82
회귀식
\(y = 3.0 + 0.5 \times x\)
표 10.2: 앤스콤 데이터셋 기술통계
10.2.1 데이터셋 기술통계량
datasets 패키지 내부에 anscombe 명칭으로 데이터셋이 포함되어 있어 앞서 제기한 기술통계량이 맞는지 평균, 분산, 상관계수, 회귀식 회귀계수를 통해 소수점 아래 일부 차이가 있지만 동일하다는 것을 확인할 수 있다.
10.2.2 데이터셋 시각화
anscombe 데이터셋 기술 통계량을 통해 4종류 데이터셋이 동일한 분포를 갖고 있고 표본추출로 보면 모집단에서 잘 추출된 표본이라고 볼 수도 있으나 시각화를 통해 보면 전혀 다른 특성을 갖는 데이터라는 것을 한번에 알 수 있다. 즉, 가장 일반적으로 첫 번째 데이터셋과 같은 특성이 기술통계량을 통해 존재한다는 것이 일반적이다. 하지만, 2차식이 내재된 두 변수의 관계(두 번째 데이터셋)일 수도 있으며, 강한 선형 관계가 두 변수 사이에 존재하지만 튀는 관측점이 하나 존재하는 관계(세 번째 데이터셋)일 수도 있으며, 네 번째 데이터셋의 경우 데이터 입력 과정에서 오류가 의심되는 경우일 수도 있다.
시각화는 데이터를 이해하고 통찰력을 얻는 데 매우 중요한 도구이다. 기본적인 그래프 유형을 넘어, 데이터 특성과 전달하고자 하는 메시지에 맞는 효과적인 그래프를 만드는 것이 중요하다.
ggplot2 문법을 활용하여 6가지 고급 그래프를 제작하는 방법을 살펴본다. 시계열 데이터에 라벨을 추가하는 방법, 막대그래프에 그룹별 색상을 적용하는 기법, 추세선에 강조와 라벨을 더하는 방법도 알아본다. 또한 롤리팝 그래프, 아령 그래프, 경사 그래프 등 데이터 비교와 변화를 효과적으로 나타내는 그래프들도 코드와 함께 상세히 살펴본다.
10.3 시계열 데이터
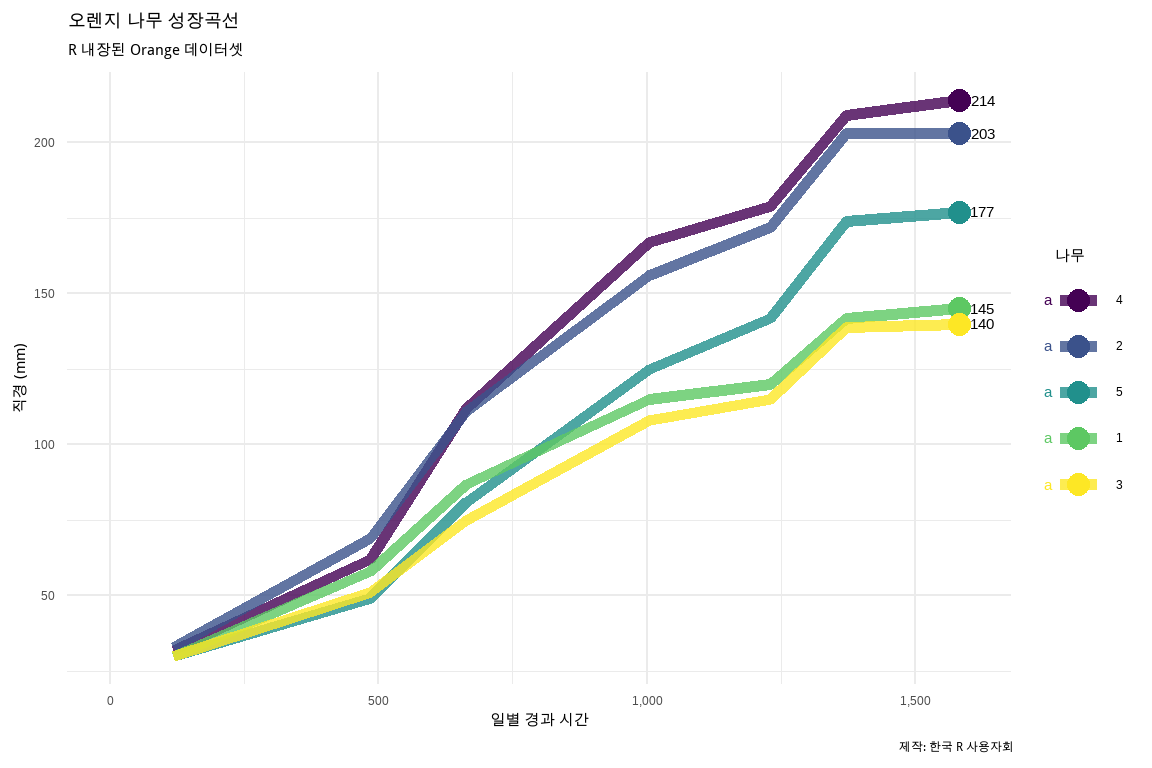
시계열 데이터를 제작하게 되면 추세를 파악할 수 있지만 결국 가장 최근 값이 어떻게 되는지에 대한 관심이 많다. 이런 사용자 요구를 맞추기 위해 시계열 데이터 마지막 시점에 라벨값을 붙이게 되면 가독성도 좋아진다. 기본적인 작업 흐름은 데이터셋에서 가장 최근 관측점을 뽑아서 별도 데이터프레임으로 저장하고 이를 geom_text() 혹은 geom_text_repel() 함수를 사용해서 해결한다.1
## 마지막 관측점orange_ends<-datasets::Orange%>%group_by(Tree)%>%filter(age==max(age))%>%ungroup()datasets::Orange%>%## 범례와 그래프 순서 맞추기 위해 범주 순서 조정mutate(Tree =fct_reorder(Tree, -circumference))%>%ggplot(aes(age, circumference, color =Tree))+geom_line(size =2, alpha =.8)+scale_x_continuous(label=scales::comma, limits =c(0, 1600))+## 마지막 관측점 라벨과 큰 점 추가geom_text(data =orange_ends, aes(label =circumference, color =NULL), hjust =-0.5,)+geom_point(data =orange_ends, aes(x=age, y=circumference), size =3.7)+theme_minimal(base_family ="MaruBuri")+labs(title ="오렌지 나무 성장곡선", subtitle ="R 내장된 Orange 데이터셋", x ="일별 경과 시간", y ="직경 (mm)", caption ="제작: 한국 R 사용자회", color ="나무")
그림 10.3: 시계열 데이터 마지막 관측점에 라벨을 붙이는 방법
10.4 막대그래프 그룹별 색상
RStudio를 거쳐 IBM에서 근무하고 있는 Alison Presmanes Hill의 GitHub 저장소에 공개된 TV 시리즈 데이터를 사용해서 막대그래프를 작성할 때 그룹별 색상을 적용하여 가시성을 높인다. TV 시리즈별 색상을 달리할 경우 RColorBrewer 패키지 색상 팔레트를 범주형에 맞춰 각 시리즈별로 가장 잘 구분될 수 있도록 색상을 칠해 시각화한다.
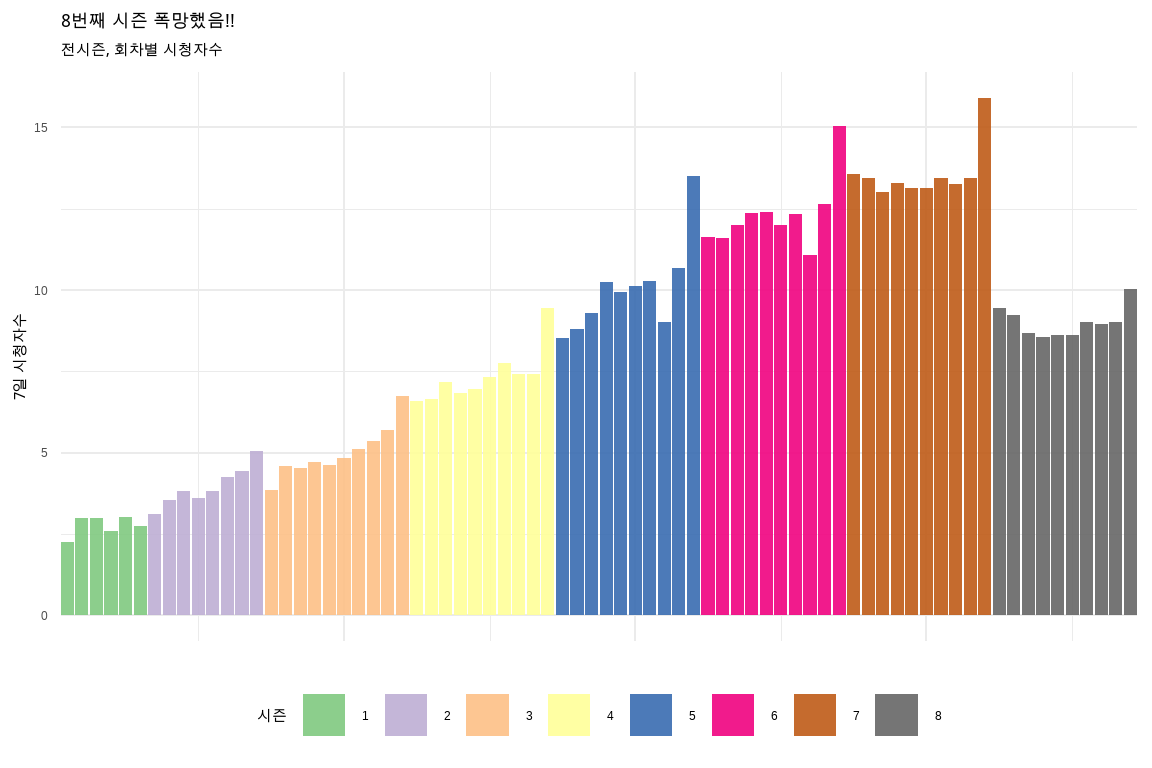
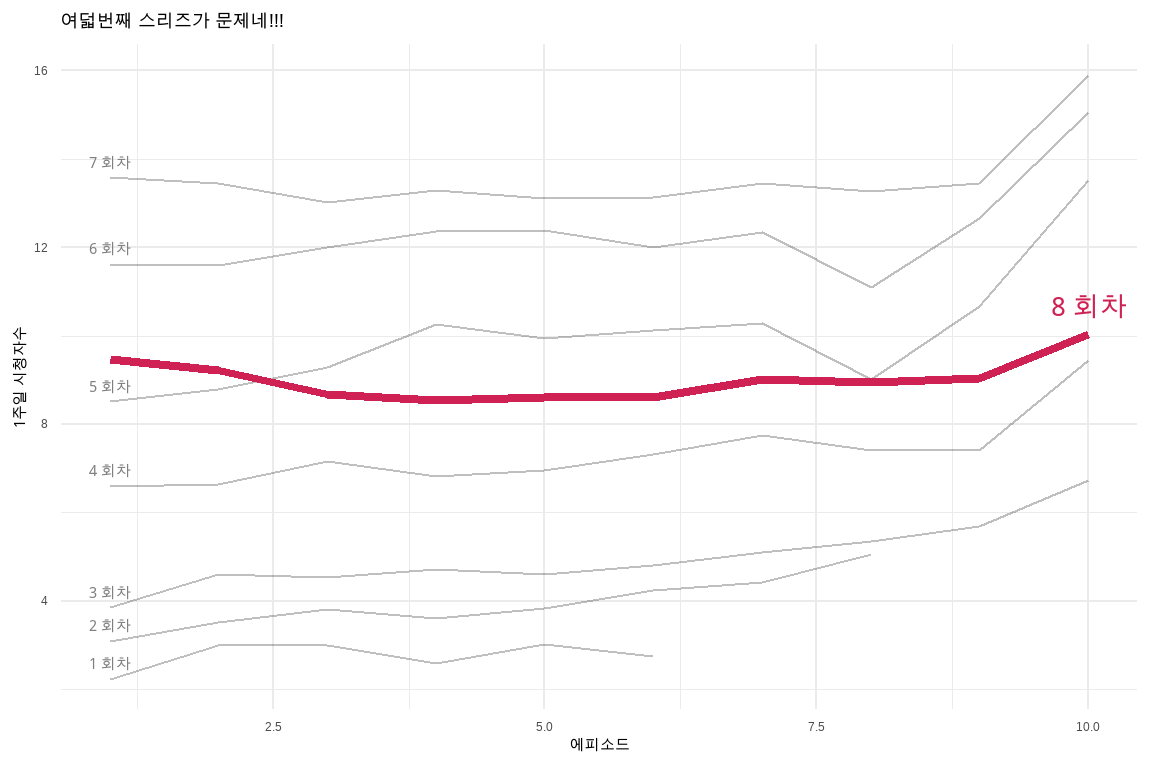
시각화의 백미는 아무래도 대조와 비교를 통해 강한 인상을 주는 것이다. 앞선 ratings TV 시리즈 시청자 평가 데이터를 대상으로 추세선에 강조를 넣고 라벨 텍스트도 넣어 하이라이트 강조 그래프를 작성해보자. geom_line()을 두 개 포함시켜 강조하고자 하는 색상을 별도로 지정하고 선 굵기도 달리한다. 라벨도 동일한 방법으로 geom_text()를 두 개 포함시켜 강조하고자 하는 색상과 글꼴 크기도 달리 지정한다.
ratings%>%mutate(episode =as.factor(episode))%>%ggplot(aes(x =episode, y =viewers_7day, group =series))+geom_line(data =filter(ratings, !series==8), alpha =.25)+## 기존 그려진 선에 굵은 선과 색상을 달리하여 차별화한다.geom_line(data =filter(ratings, series==8), color ="#CF2154", size =1.5)+theme_minimal(base_family ="MaruBuri")+labs(x ="에피소드", y="1주일 시청자수", title="여덟번째 스리즈가 문제네!!!")+geom_text(data =filter(ratings, episode==1&series%in%c(1:7)), color ="gray50",aes(label =paste0(series, " 회차 ")), vjust =-1, family ="MaruBuri")+## 8회차 텍스트 반대위치에 크기를 달리하고 글꼴도 달리하여 라벨 추가geom_text(data =filter(ratings, episode==10&series==8), color ="#CF2154",aes(label =glue::glue("{series} 회차")), vjust =-1, family ="Nanum Pen Script", size =7)
그림 10.5: 추세선을 강조하고 라벨을 추가한 그래프
10.6 롤리팝 그래프
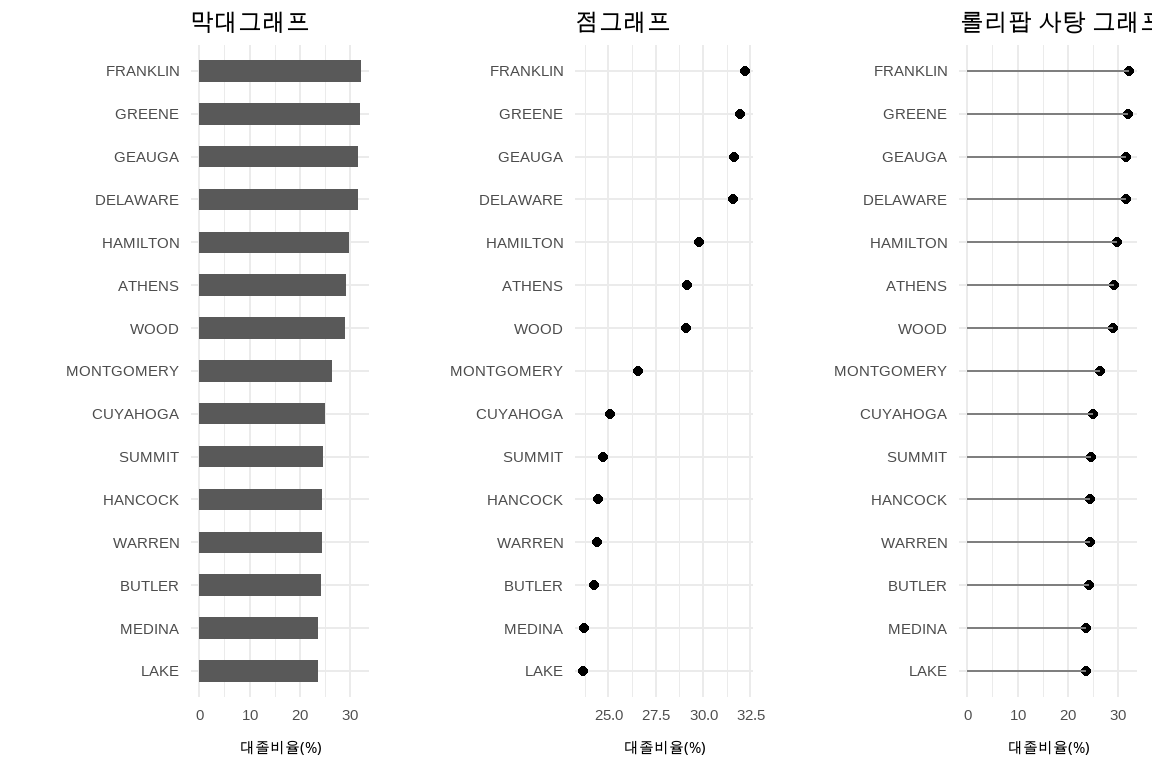
롤리팝(Lollipop) 사탕 그래프는 막대그래프와 클리블랜드 점그래프를 합성한 것으로 한 축에는 연속형, 다른 한 축에는 범주형을 두고 사용자의 관심을 점그래프로 집중시키는 데 효과적이다. 단순히 막대그래프를 제작하는 것과 비교하여 임팩트 있는 시각화를 가능하게 한다.
제작 순서는 막대그래프 → 점그래프 → 롤리팝 그래프로 뼈대 골격을 만들어 나간다. 대략적인 골격이 제작되고 나면 외양과 필요한 경우 값도 텍스트로 넣어 시각화 제품을 완성한다. 롤리팝 사탕 그래프를 작성할 때 geom_point()를 사용해서 롤리팝 사탕을 제작하고, geom_segment() 함수를 사용해서 사탕 막대를 그린다. 이때 막대 사탕의 시작은 x, y에 넣어주고 끝은 xend와 yend에 넣어 마무리한다.
데이터는 ggplot2에 내장된 midwest 데이터를 사용한다. midwest 데이터셋은 2000년 미국 중서부 센서스 데이터로 인구통계 조사가 담겨있다. percollege 변수는 카운티(우리나라 군에 해당) 별 대학졸업비율을 나타낸다.
# 데이터 -----## 롤리팝 사탕 그래프를 위해 상위 15개 군만 추출ohio_top15<-ggplot2::midwest%>%filter(state=="OH")%>%select(county, percollege)%>%## 대졸자 비율이 높은 카운티 15개 선정top_n(15, wt =percollege)%>%## 시각화를 위해 오름차순 정렬arrange(percollege)%>%## 문자형 자료를 범주형으로 변환mutate(county =factor(county, levels =.$county))ohio_barplot_g<-ohio_top15%>%ggplot(aes(county, percollege))+geom_col(width =0.5)+coord_flip()+labs(title ="막대그래프", y ="대졸비율(%)", x ="")ohio_dotplot_g<-ohio_top15%>%ggplot(aes(county, percollege))+geom_point()+coord_flip()+labs(title ="점그래프", y ="대졸비율(%)", x ="")ohio_lollipop_g<-ohio_top15%>%ggplot(aes(county, percollege))+geom_point()+geom_segment(aes(x =county, xend =county, y =0, yend =percollege), color ="grey50")+coord_flip()+labs(title ="롤리팝 사탕 그래프", y ="대졸비율(%)", x ="")cowplot::plot_grid(ohio_barplot_g, ohio_dotplot_g, ohio_lollipop_g, nrow=1)
그림 10.6: 롤리팝 사탕 그래프
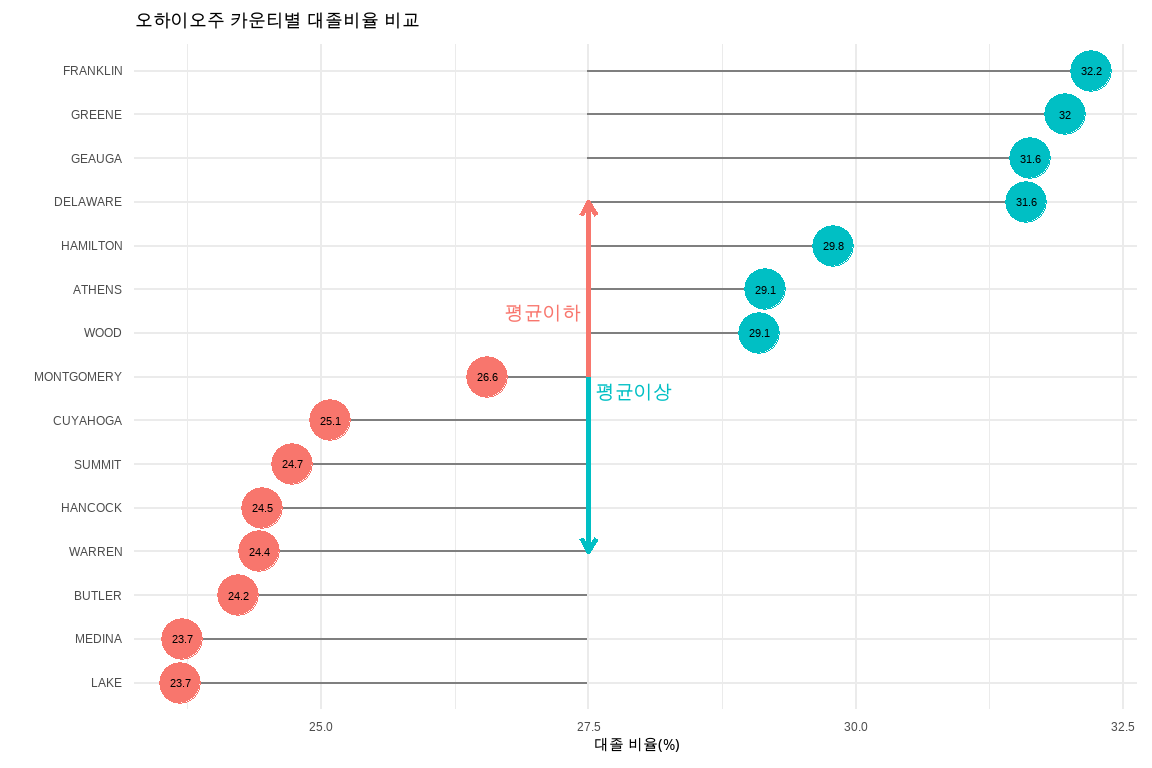
한 발 더 나아가, 평균값에서 얼마나 차이가 있느냐를 롤리팝 그래프로 시각화하는 패턴이 많이 사용된다. 이를 위해서, 앞서와 마찬가지로 15개 카운티를 뽑아내고 평균을 구하고 평균 이상, 평균 이하에 대한 요인(factor)도 함께 만들어낸다.
## 평균기준 대졸비율 비교를 위한 데이터셋 준비ohio<-midwest%>%filter(state=="OH")%>%select(county, percollege)%>%top_n(15, wt=percollege)%>%arrange(percollege)%>%mutate(Avg =mean(percollege, na.rm =TRUE), Above =ifelse(percollege-Avg>0, TRUE, FALSE), county =factor(county, levels =.$county))## 시각화 기본 골결 제작comparison_lollipop_g<-ohio%>%ggplot(aes(percollege, county, color =Above))+geom_segment(aes(x =Avg, y =county, xend =percollege, yend =county), color ="grey50")+geom_point()## 외양과 설명을 넣어 가시성을 높임ohio%>%ggplot(aes(percollege, county, color =Above, label=round(percollege,1)))+geom_segment(aes(x =Avg, y =county, xend =percollege, yend =county), color ="grey50")+geom_point(size=7)+annotate("text", x =27.5, y ="WOOD", label ="평균이상", color ="#00BFC4", size =5, hjust =-0.1, vjust =5)+annotate("text", x =27.5, y ="WOOD", label ="평균이하", color ="#F8766D", size =5, hjust =+1.1, vjust =-1)+geom_text(color="black", size=3)+theme_minimal(base_family ="MaruBuri")+labs(x="대졸 비율(%)", y="", title="오하이오주 카운티별 대졸비율 비교")+geom_segment(aes(x =27.5, xend =27.5 , y ="WOOD", yend ="WARREN"), size=1, arrow =arrow(length =unit(0.2,"cm")), color ="#00BFC4")+geom_segment(aes(x =27.5, xend =27.5 , y ="MONTGOMERY", yend ="DELAWARE"), size=1, arrow =arrow(length =unit(0.2,"cm")), color ="#F8766D")+theme(legend.position ="none")
롤리팝 사탕 그래프 외양과 설명 추가
10.7 아령 그래프
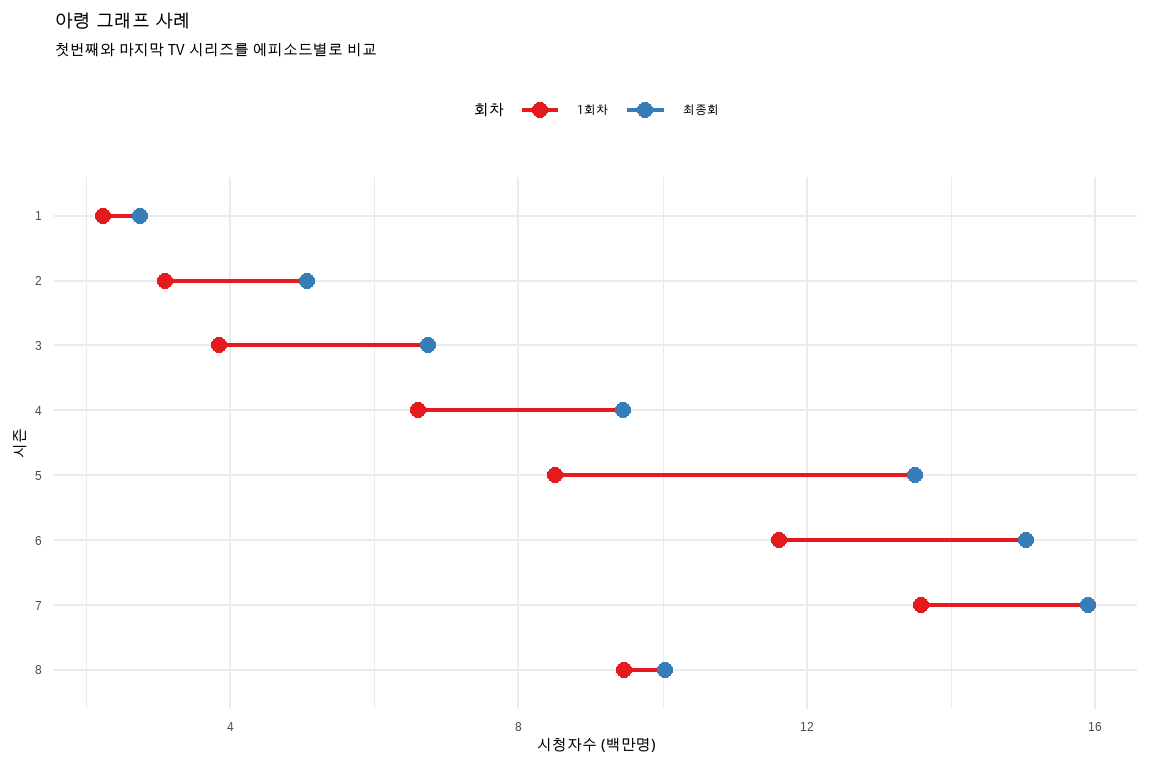
두 시점을 비교하여 전후를 비교한다든가 두 지역을 비교할 때 아령 그래프는 매우 효과적이다. TV 시리즈별로 회차를 달리하여 첫 번째와 가장 마지막 시청자 수를 비교하여 시각화하는데 아령(dumbbell) 그래프가 적절한 예시가 될 것으로 보인다. 이를 위해서 ggplot()에 들어가는 자료형을 미리 준비하고 이에 맞춰 geom_line()과 geom_point()를 결합시켜 시각화한다.
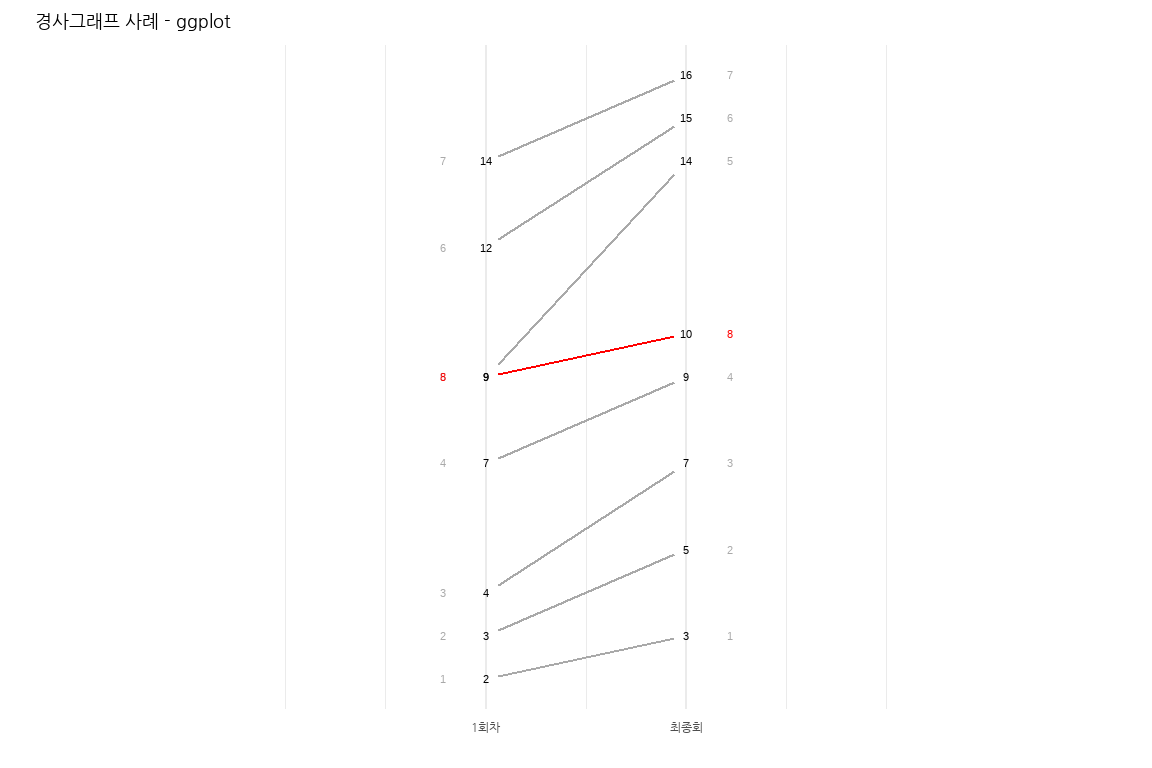
아령 그래프를 제작한 동일한 데이터를 터프티(tufte) 스타일 경사그래프로 구현하면 시즌별 첫 회와 최종회 시청자 수 비교를 좀 더 직관적으로 만들 수 있다.
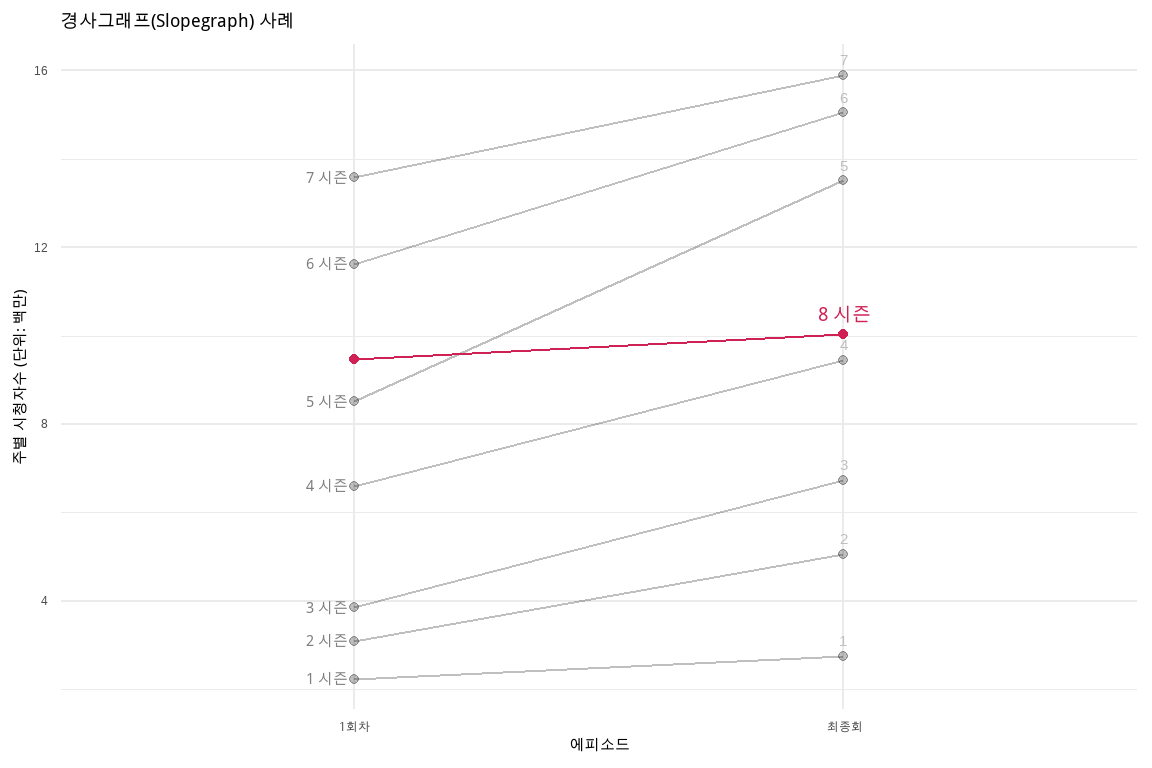
ggplot의 기본 기능을 활용하여 경사그래프를 시각화하고 강조하고자 하는 시즌을 색상을 달리하여 표현한다. 이를 통해 1~7번째 시즌은 1회차 시청률은 낮으나 최종회는 높게 마무리된 것을 알 수 있고, 더불어 시즌이 진행될수록 1회차 시청률도 높아지고 있었다. 하지만 8번째 시즌은 다른 시즌과 달리 낮게 시작했고 최종회 시청률도 크게 나아지지 않은 것을 한눈에 파악할 수 있다.
ratings_dumbbell_df%>%ggplot(aes(x =episode, y =viewers_7day, group =series))+geom_point(data =filter(ratings_dumbbell_df, !series==8), alpha =.25)+geom_point(data =filter(ratings_dumbbell_df, series==8), color ="#CF2154")+geom_line(data =filter(ratings_dumbbell_df, !series==8), alpha =.25)+geom_line(data =filter(ratings_dumbbell_df, series==8),color ="#CF2154")+theme_minimal(base_family ="MaruBuri")+labs(title ="경사그래프(Slopegraph) 사례", x="에피소드", y="주별 시청자수 (단위: 백만)")+## 8번째 시즌geom_text(data =filter(ratings_dumbbell_df, episode=="최종회"&series%in%c(1:7)), color ="gray",aes(label =series), vjust =-1, family ="Nanum Pen Script", hjust =.5)+geom_text(data =filter(ratings_dumbbell_df, episode=="최종회"&series==8), color ="#CF2154",aes(label =paste0(series, " 시즌")), vjust =-1, family ="Nanum Pen Script", size=5)+## 1~7번째 시즌geom_text(data =filter(ratings_dumbbell_df, episode=="1회차"&series%in%c(1:7)), color ="gray50",aes(label =paste0(series, " 시즌")), family ="MaruBuri", hjust =1.2)
그림 10.8: 경사그래프로 시리즈별 시청자수 비교
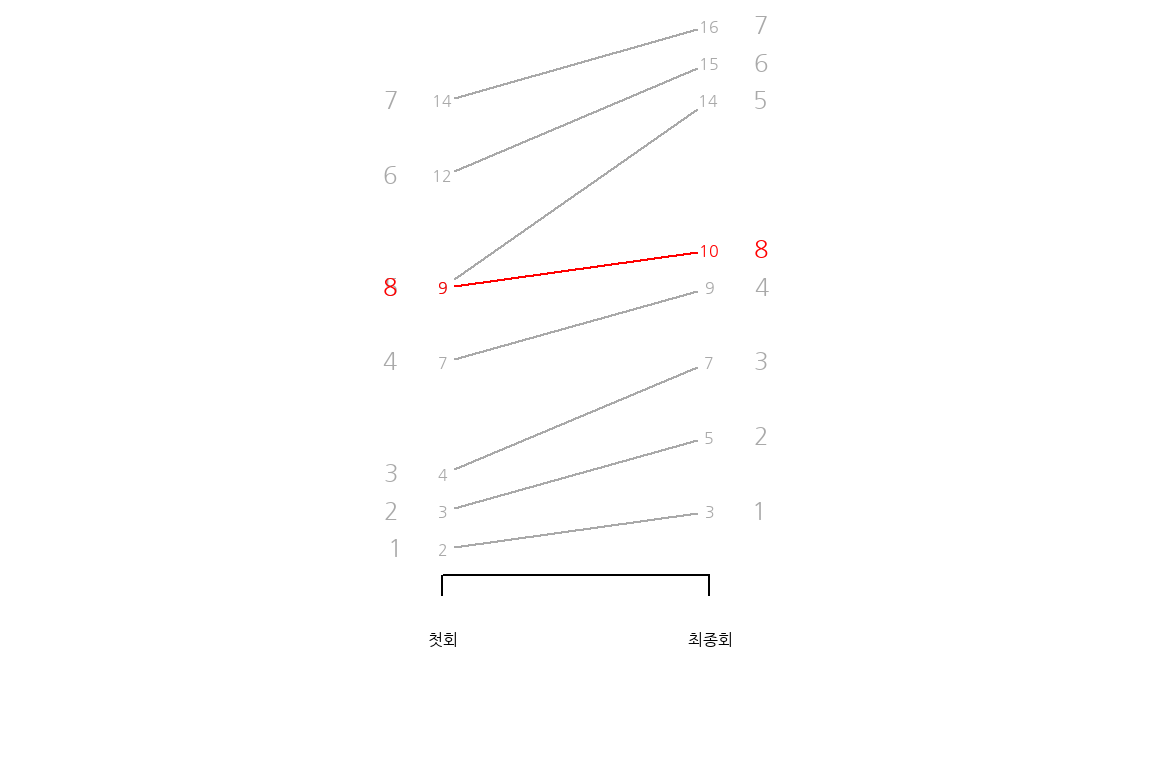
경사그래프를 제작하고 싶으나 전반적으로 시간이 더 필요한 분을 위해 slopegraph 패키지가 있다.
slopegraph는 Base 그래픽을 기본으로 삼고 있어 자료구조도 rownames를 갖는 전통적인 데이터프레임이다. 기본 Base 그래픽을 염두에 두고 상기 TV 연속물 경사그래프를 다음과 같이 작성할 수 있다.
효과적인 데이터 시각화를 위해 ggplot2 문법을 활용하여 6가지 고급 그래프 제작 방법을 살펴보았다. 먼저, 시계열 데이터에 라벨을 추가하여 최근 값을 강조하는 방법과 막대그래프에 그룹별 색상을 적용하여 가시성을 높이는 기법을 알아보았고, 추세선에 강조와 라벨을 더하여 차별화된 메시지를 전달하는 방법도 살펴보았다.
롤리팝 그래프는 막대그래프와 점그래프를 결합한 형태로, 사용자의 관심을 점그래프로 집중시키는 데 효과적이다. 롤리팝 그래프를 활용하여 평균값과의 차이를 비교하는 시각화 패턴도 많이 사용된다. 아령 그래프는 두 시점 혹은 두 지역을 비교할 때 매우 효과적인 그래프로, TV 시리즈별 첫 회와 마지막 회의 시청자 수 비교에 적절한 예시로 제시되었다.
마지막으로 경사 그래프는 아령 그래프와 유사하지만 좀 더 직관적인 형태로 시즌별 첫 회와 최종회 시청자 수 비교를 나타낼 수 있다. ggplot의 기본 기능을 활용하여 경사그래프를 시각화하고 강조하고자 하는 부분을 색상으로 구분하여 표현할 수 있다. 또한 slopegraph 패키지를 사용하면 Base 그래픽을 기반으로 한 경사그래프를 쉽게 제작할 수 있다.
그림 10.1: 시각화를 통한 신장과 몸무게 관계그림 10.2: 앤스콤 데이터셋 시각화그림 10.3: 시계열 데이터 마지막 관측점에 라벨을 붙이는 방법그림 10.4: 막대그래프 그룹별 색상 적용그림 10.5: 추세선을 강조하고 라벨을 추가한 그래프그림 10.6: 롤리팝 사탕 그래프롤리팝 사탕 그래프 외양과 설명 추가그림 10.7: 아령 그래프로 시리즈별 시청자수 비교그림 10.8: 경사그래프로 시리즈별 시청자수 비교그림 10.9: 전용 패키지 사용 경사그래프로 시리즈별 시청자수 비교그림 10.10: ggplot 패키지 사용 경사그래프로 시리즈별 시청자수 비교
Anscombe, Francis J. 1973. “Graphs in statistical analysis”. The american statistician 27 (1): 17–21.
Munzner, Tamara. 2014. Visualization analysis and design. CRC press.