#install.packages("tidyr")
#install.packages("dplyr")
7 tidyr 패키지
과학연구원들은 흔히 ‘wide’ 형식에서 ‘long’ 형식으로 혹은 역으로 데이터를 솜씨 있게 조작해야 한다. ‘long’ 형식은 다음과 같이 정의된다:
- 각 칼럼이 변수다.
- 각 행이 관측점이다.
순수한 ‘long’(또는 ‘가장 긴’) 형식에서는 일반적으로 관측 변수에 대해 1개의 열과 ID 변수에 대해 다른 열들을 가진다.
‘wide’ 형식에서 각 행은 흔히 관측점(site/subject/patient)이며, 동일한 자료형을 담고 있는 다수 관측변수를 갖는다. 시간이 경과함에 따라 반복되는 관측점이거나, 다수 변수의 관측점(혹은 둘이 혼합된 사례)일 수 있다. 데이터 입력이 더 단순하거나 일부 다른 응용 사례에서 ‘wide’ 형식을 선호할 수 있다. 하지만, R 함수 다수는 ’long’형식을 가정하고 설계되었다. 원래 데이터 형식에 관계없이 데이터를 효율적으로 변환하는 방식을 자세히 살펴보자.
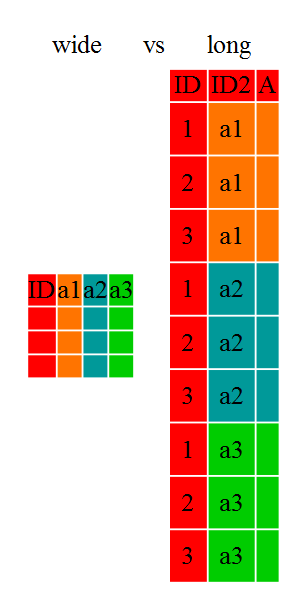
wide와 long 데이터프레임 비교
데이터 형식은 주로 가독성에 영향을 준다. 사람에게는 ‘wide’ 형식이 좀 더 직관적인데, 이유는 데이터 형상으로 인해 화면에 더 많은 데이터를 볼 수 있기 때문이다. 하지만, 컴퓨터에게는 ‘long’ 형식이 더 가독성이 높고, 데이터베이스 형식에 훨씬 더 가깝다. 데이터프레임의 ID 변수는 데이터베이스 필드(Field)와 유사하고, 관측변수는 데이터베이스 값(Value)과 유사하다.
7.1 시작하기
먼저 설치하지 않았다면 tidyr 패키지를 설치한다(아마도 앞에서 dplyr 패키지는 설치했을 것이다):
패키지를 로드한다
먼저 원래 gapminder 데이터프레임의 구조를 살펴보자.
str(gapminder)
#> 'data.frame': 1704 obs. of 6 variables:
#> $ country : chr "Afghanistan" "Afghanistan" "Afghanistan" "Afghanistan" ...
#> $ year : int 1952 1957 1962 1967 1972 1977 1982 1987 1992 1997 ...
#> $ pop : num 8425333 9240934 10267083 11537966 13079460 ...
#> $ continent: chr "Asia" "Asia" "Asia" "Asia" ...
#> $ lifeExp : num 28.8 30.3 32 34 36.1 ...
#> $ gdpPercap: num 779 821 853 836 740 ...
도전과제
gapminder는 순수한 ‘long’ 형식인가, ‘wide’ 형식인가, 혹은 두 가지 특징을 갖는 중간 형식인가?
해답
원 gapminder 데이터프레임은 두 가지 특징을 갖는 중간 형식이다. 데이터프레임에 다수의 관측변수(pop, lifeExp, gdpPercap)가 있다는 점에서, 순수한 long 형식이라고 보기는 어렵다.
gapminder 데이터셋처럼, 관측된 데이터에는 다양한 자료 형식이 있다. 대부분 순도 100% ‘long’ 혹은 순도 100% ‘wide’ 자료 형식 사이 어딘가에 위치하게 된다. gapminder 데이터셋에는 “ID” 변수가 3개(continent, country, year), “관측변수”가 3개(pop, lifeExp, gdpPercap)가 있다. 저자는 일반적으로 대부분의 경우에 중간단계 형식 데이터를 선호한다. 칼럼 1곳에 모든 관측점이 3가지 서로 다른 단위를 갖는 일은 거의 없다(예를 들어, ID변수 4개, 관측변수 1개).
흔히 벡터 기반인 다수의 R 함수를 사용할 때, 서로 다른 단위를 갖는 값에 수학적 연산작업을 수행하지는 않는다. 예를 들어, 순수 ‘long’ 형식을 사용할 때, 인구, 기대수명, GDP의 모든 값에 대한 평균은 의미가 없는데, 이는 상호 호환되지 않는 3가지 단위를 갖는 평균값을 계산하여 반환하기 때문이다. 해법은 먼저 집단으로 그룹지어서 데이터를 솜씨 있게 다루거나(dplyr 학습교재 참조), 데이터프레임 구조를 변경시키는 것이다. 주의: R에서 일부 도식화 함수는 ‘wide’ 형식 데이터에 더 잘 작동한다.
7.2 pivot_longer(): wide에서 long 형식 전환
지금까지 깔끔한 형식을 갖는 원본 gapminder 데이터셋으로 작업을 했다. 하지만 ‘실제’ 데이터(즉, 자체 연구 데이터)는 절대로 잘 구성되어 있지 못하다. gapminder 데이터셋에 대한 wide 형식 버전을 가지고 시작해보자.
이곳에서 ‘wide’ 형태를 갖는
gapminder데이터를 다운로드 받아서, 로컬data폴더에 저장한다.
데이터 파일을 불러와서 살펴보자. 주의: continent, country 칼럼이 요인형 자료형이 될 필요가 없으므로 read.csv() 함수 인자로 stringsAsFactors을 거짓(FALSE)으로 설정한다.

wide 형식 데이터프레임깔끔한 중간 데이터 형식을 얻는 첫 단추는 먼저 ‘wide’ 형식에서 ‘long’ 형식으로 변환하는 것이다. tidyr 패키지의 pivot_longer() 함수는 관측 변수를 모아서(gather) long 형식 단일 변수로 변환한다. wide에서 long 형식으로 변환하기 위해 pivot_longer() 함수를 사용한다. pivot_longer()는 행의 수를 늘리고 열의 수를 줄임으로써 데이터셋을 더 길게 만들거나 관측 변수를 단일 변수로 ’연장’한다.
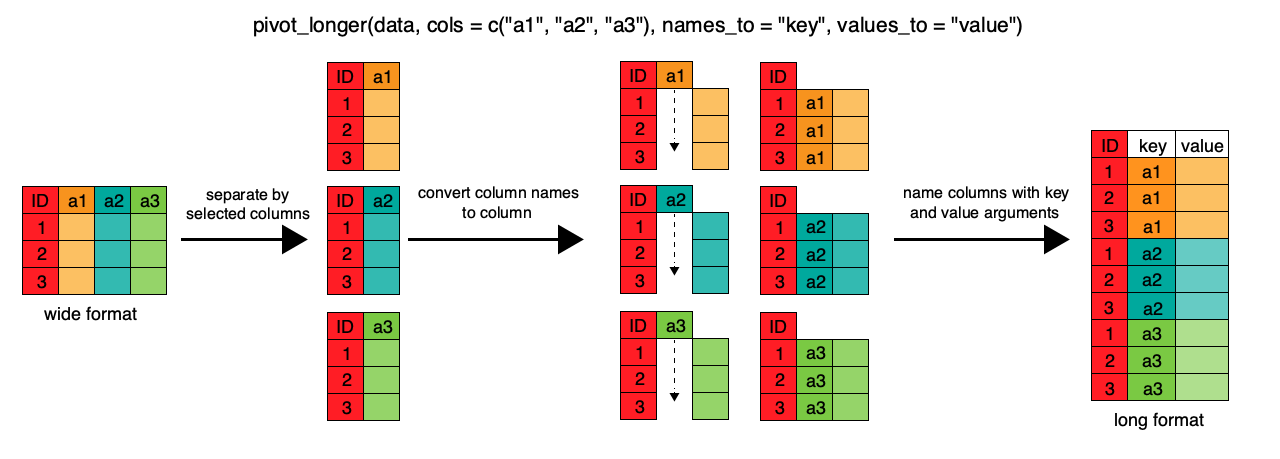
wide 형식에서 long 형식 전환과정 도식화
위에서 파이프 구문을 사용했는데, 이는 앞서 dplyr로 작업한 것과 유사하다. 사실, dplyr과 tidyr은 상호 호환되어 파이프 구문으로 dplyr과 tidyr 팩키지 함수를 파이핑하여 혼합하여 사용할 수 있다.
먼저 pivot_longer()에 longer 형식으로 피벗될 열 이름 벡터를 제공한다. 모든 관측 변수를 입력할 수도 있지만 dplyr 레슨의 select() 함수처럼 starts_with() 인수를 사용하여 원하는 문자열로 시작하는 모든 변수를 선택할 수 있다. pivot_longer()는 피벗하지 않을 변수(즉, ID 변수)를 식별하기 위해 - 기호를 사용하는 대체 구문도 허용한다. pivot_longer()에 대한 다음 인수는 새 ID 변수(obstype_year)를 포함할 열의 이름을 지정하는 names_to와 새로 합쳐진 관측 변수(obs_value)의 이름을 지정하는 values_to이다. 새 열 이름을 문자열로 제공하여 후속 작업 가독성을 높인다.
특정 데이터프레임에서는 사소해 보일 수 있지만, 때로는 ID 변수 1개와 불규칙한 변수 이름을 가진 관측 변수 40개를 가질 수 있다. 이런 유연성은 시간을 상당히 절약해 준다!
이제 obstype_year은 정보가 두 조각으로 나뉜다. 관측 유형(pop, lifeExp, gdpPercap)과 연도(year). separate() 함수를 사용하여 문자열을 여러 변수로 분할할 수 있다.
도전과제
gap_long을 사용해서 각 대륙별로 평균 기대수명, 인구, 1인당 GDP를 계산한다. 힌트: dplyr에서 학습한 group_by()와 summarize() 함수를 사용한다.
해답
7.3 pivot_wider(): ’long’에서 중간 형식으로
작업을 항상 확인하는 것이 좋다. pivot_wider()는 pivot_longer()의 반대로, 열의 수를 늘리고 행의 수를 줄여 데이터셋을 더 넓게 만든다. pivot_wider()를 사용하여 gap_long을 원래의 중간 형식 또는 가장 넓은 형식으로 피벗하거나 재구성할 수 있다. 중간 형식에서부터 시작해보자.
이제 최초 데이터프레임 gapminder와 동일한 차원을 갖는 중간 데이터프레임 gap_normal이 있다. 하지만 변수 순서가 다르다. 순서를 수정하기 전에 all.equal() 함수를 사용해서 동일한지 확인한다.
거의 다 왔다. 최초 데이터프레임은 country로 정렬된 다음 year로 정렬되었다.
훌륭하다! ‘long’ 형식에서 다시 중간 형식으로 돌아왔지만, 코드에 어떤 오류도 스며들지 않았다.
이제 long에서 wide로 완전히 변환해 보자. wide 형식에서는 country와 continent를 ID 변수로 유지하고 관측치를 3개의 측정 기준(pop, lifeExp, gdpPercap)과 시간(year)에 걸쳐 피벗할 것이다. 먼저 모든 새 변수(시간*측정 기준 조합)에 대한 적절한 레이블을 만들어야 하며 gap_wide를 정의하는 과정을 단순화하기 위해 ID 변수를 통합해야 한다.
unite()를 사용하여 이제 continent와 country의 조합인 단일 ID 변수를 가지고 있고 변수 이름을 정의했다. 이제 pivot_wider()로 파이핑할 준비가 되었다.
도전과제
국가, 연도 및 3개의 측정 기준에 대해 피벗하여 gap_ludicrously_wide 형식 데이터를 만드시오.
힌트 이 새로운 데이터 프레임은 행이 5개만 있어야 한다.
해답
이제 훌륭한 ‘wide’ 형식 데이터프레임을 가지고 있지만 ID_var가 더 사용하기 편할 수 있다. separate()를 사용하여 2개의 변수로 분리해 보자.
다시 되돌아왔다!
7.4 요약
tidyr 패키지는 데이터를 ‘wide’ 형식에서 ‘long’ 형식으로, 또는 그 반대로 변환하는 데 사용된다. ‘long’ 형식은 각 열이 변수이고 각 행이 관측치인 형식이며, ‘wide’ 형식은 각 행이 관측치이고 여러 관측 변수를 포함하는 형식이다. 대부분의 데이터셋은 이 두 극단 사이의 중간 형식으로 존재한다.
pivot_longer() 함수는 ‘wide’ 형식에서 ‘long’ 형식으로 데이터를 변환하는 데 사용되며, 열의 수를 줄이고 행의 수를 늘린다. 이 함수는 pivot할 열을 선택하고, 새로운 변수 이름을 지정할 수 있는 유연성을 제공한다. separate() 함수를 사용하면 하나의 변수를 여러 변수로 분할할 수 있다.
반대로 pivot_wider() 함수는 ‘long’ 형식에서 ‘wide’ 형식으로 데이터를 변환하는 데 사용되며, 열의 수를 늘리고 행의 수를 줄인다. unite() 함수를 사용하면 여러 변수를 하나의 변수로 결합할 수 있다.
tidyr 패키지의 함수들을 사용하면 데이터 형식을 유연하게 변환할 수 있으며, dplyr 패키지와 함께 사용하면 데이터 조작 및 분석을 효율적으로 수행할 수 있다.