install.packages('dplyr')
library("dplyr")6 dplyr 패키지
데이터프레임을 솜씨 있게 조작하는 것은 많은 과학연구원에게 큰 의미를 지닌다. 특정 관측점(행) 혹은 변수(열)을 선택하거나, 특정 변수(들)로 데이터를 집단으로 그룹 짓거나, 요약 통계량을 계산하기도 한다. 이런 연산 작업에 기본 베이스(Base) R 연산을 사용한다.
하지만, 그다지 멋있지는 않은데, 이유는 상당한 반복이 존재하기 때문이다. 여러분이 직접 반복하게 되면, 지금뿐만 아니라 나중에도 소중한 시간을 허비하게 되고, 더 나아가 잠재적으로 버그가 스며들 여지를 남기게 된다.
운 좋게도, dplyr 패키지가 데이터프레임을 솜씨 있게 조작하는 데 유용한 함수를 많이 제공한다. 이를 통해서, 위에서 언급된 반복을 줄이고, 실수를 범할 확률도 줄이며, 심지어 타이핑 수고도 줄일 수 있다. 보너스로, dplyr 문법은 훨씬 더 가독성이 높다.
가장 흔히 사용되는 6가지 함수뿐만 아니라, 이런 함수를 조합하는 데 사용되는 파이프 (%>%) 연산자 사용법도 다룬다.
이전 장에서 패키지를 설치하지 않았다면, 설치해서 직접 실습해 보기 바란다. 이제 패키지를 불러와서 적재한다.
6.1 select() 동사
예를 들어, 데이터프레임에서 변수 일부만 뽑아서 작업해 나가고자 한다면, select() 함수를 사용한다. 이 함수는 선택한 변수만 갖도록 지정한다.
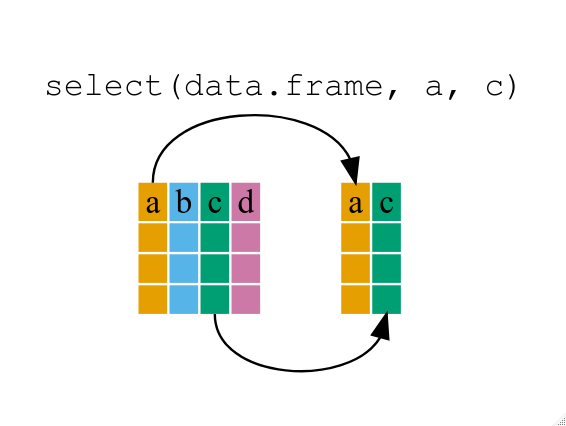
select함수 데이터프레임 적용 도식화
year_country_gdp 데이터프레임을 열어보면, year, country, gdpPercap 변수만 담겨 있는 것을 볼 수 있다. 위에서는 정규 문법이 사용되었지만, dplyr 패키지의 장점은 파이프를 사용해서 함수 다수를 조합하는 데 있다. 파이프 문법은 이전에 R에서 살펴본 것과는 사뭇 다르다. 위에서 파이프를 사용한 것을 다시 작성해본다.
파이프를 사용해서 작성한 이유에 대한 이해를 돕기 위해서, 단계별로 살펴보자. 먼저 gapminder 데이터프레임을 불러오고 나서, %>% 파이프 기호를 사용해서 다음 작업 단계(select() 함수)로 전달했다. 이번 경우에는 select() 함수에 데이터 객체를 명시하지 않았는데, 이는 이전 파이프로부터 데이터를 전달받았기 때문이다. 재미있는 사실: 챗GPT 유닉스 쉘 책(이광춘·신종화 2023)에서 이미 파이프를 접해봤을 것이다. R에서 파이프 기호가 %>%인 반면, 셸에서는 |을 사용한다. 하지만 개념은 동일하다!
6.2 filter() 동사
이제 앞선 작업을 바탕으로 작업을 진척시켜 보자. 유럽 대륙만 갖고 작업하고자 한다면 select와 filter를 조합하면 된다.
도전과제
명령어 하나 (여러 행에 걸칠 수 있고, 파이프도 포함한다)를 작성하는데, lifeExp, country, year 변수에 대해서 아프리카 대륙(African)만 갖는 데이터프레임을 작성한다. 하지만, 다른 대륙은 포함되면 안 된다. 데이터프레임 행의 개수는 얼마나 되는가? 그리고 이유는 무엇인가?
해답
지난번과 마찬가지로, gapminder 데이터프레임을 filter() 함수에 전달하고 나서, 필터링된 gapminder 데이터프레임 버전을 select() 함수에 전달한다. 주의: 연산 순서가 이번 경우에 무척 중요하다. select() 함수를 먼저 실행하면, filter() 함수는 대륙 변수를 찾을 수 없는데, 이는 이전 단계에서 제거했기 때문이다.
6.3 group_by() + summarize() 조합
이제, 기본 베이스(base) R로 작업함으로써 실수를 범하기 쉬운 반복 작업을 줄일 것으로 생각했지만, 현재까지는 목표를 달성하지 못했다. 왜냐하면, 각 대륙마다 상기 작업을 반복해야 되기 때문이다. filter() 대신에, group_by()를 사용한다. filter()는 특정 기준을 만족하는 관측점만 넘겨준다(이번 경우: continent=="Europe"). group_by()는 본질적으로, 필터에서 사용할 수 있는 모든 유일무이한 기준을 사용할 수 있다.
group_by() 함수를 사용한 데이터프레임 구조(grouped_df)가 원래 gapminder 데이터프레임 구조(data.frame)와 같지 않음에 주목한다. grouped_df는 list 리스트로 간주될 수 있는데, list에 각 항목은 data.frame으로, 각 데이터프레임은 특정 대륙 continent에 대응되는 행만 담겨진다(적어도 상기 예제의 경우).
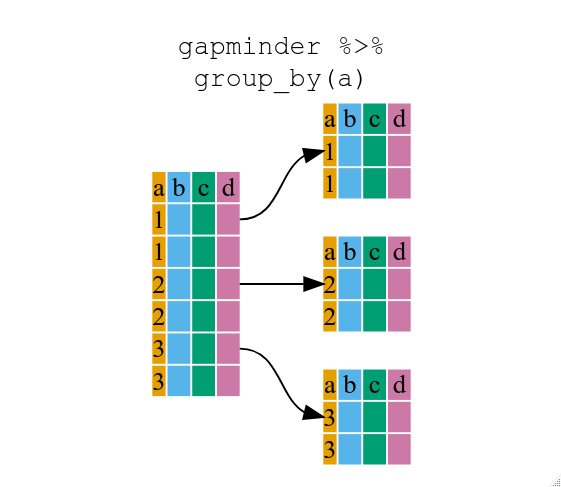
group_by() 데이터프레임 적용 도식화
6.4 summarize() 동사
상기 예제는 그다지 특별한 점이 없다. 왜냐하면 group_by() 함수는 summarize()와 함께 사용할 때 훨씬 더 흥미롭기 때문이다. 두 함수를 조합하면 새로운 변수가 생성되는데, 각 대륙별 데이터프레임에 대해 반복적인 함수 작업을 수행할 수 있다. 다시 말해, group_by() 함수를 사용해서, 최초 데이터프레임을 다수의 조각으로 쪼갠 후, 각각에 대해 함수(예를 들어 mean() 혹은 sd())를 summarize() 내부에서 실행시킨다.
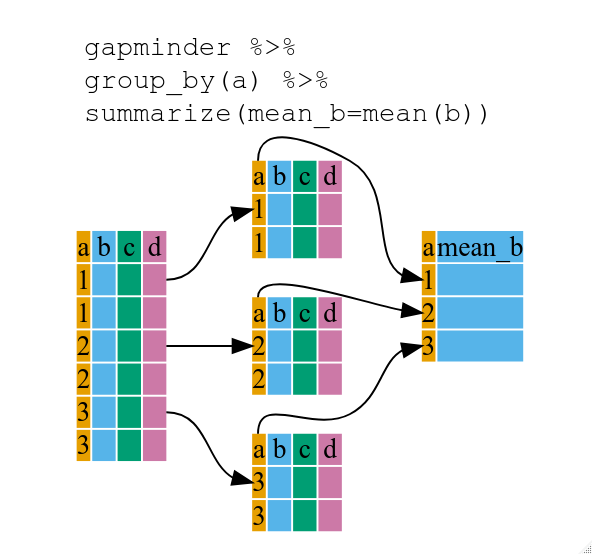
summarize() 데이터프레임 적용 도식화
상기 코드는 각 대륙별로 평균 gdpPercap를 계산할 수 있게 하지만, 훨씬 더 개선할 수 있다.
도전과제
group_by() 함수에 변수 다수를 사용해서 집단으로 그룹을 만들 수도 있다. year와 continent 변수로 그룹을 만들어 보자.
이미 매우 막강한 기능이지만, 더 좋게 만들 수 있다! summarize() 함수에 변수 하나를 정의하는 것에 한정되지 않고, 확장도 가능하다.
6.5 count()와 n() 함수
매우 흔한 연산 중 하나는 각 그룹마다 관측점 수를 세는 것이다. dplyr 패키지에는 개수를 도와주는 연관 함수가 2개 있다.
예를 들어, 2002년 데이터셋에 포함된 국가 수를 확인하고자 한다면, count() 함수를 사용하는데, 관심 있는 그룹을 포함하는 칼럼을 하나 이상 지정할 수도 있다. 선택사항으로 sort=TRUE를 인자로 추가하면 내림차순으로 결과를 정렬할 수 있다:
계산 과정에서 관측점 개수를 파악할 필요가 있는 경우, n() 함수가 유용하다. 예를 들어, 각 대륙별 기대수명 표준오차를 다음과 같이 구할 수도 있다:
요약 연산을 몇 개 엮어서 계산할 수도 있다. 이 경우 각 대륙별 기대수명에 대한 minimum, maximum, mean, se 값을 다음과 같이 계산한다:
6.6 mutate() 동사
mutate() 함수를 사용해서 정보를 요약하기 전에(혹은 후에도) 새로운 변수를 생성할 수 있다.
6.7 mutate() 논리 필터 연결
변수를 새로 만들 때, mutate() 함수를 논리 조건문과 엮을 수 있다. mutate()와 ifelse()의 단순 조합을 통해서 필요한 것만 적절히 필터링할 수 있다. 즉, 새로운 무언가를 생성하는 순간에 말이다. 이러한 가독성 높은 문장을 통해서 (데이터프레임 전체 차원을 변경시키지 않고도) 특정 데이터를 버리거나, 조건에 따라 값을 갱신하는 데 신속하고 강력한 방식을 제공할 수 있게 된다.
6.8 dplyr와 ggplot2 조합
데이터 시각화를 위해서 ggplot2를 설치하고 불러온다.
install.packages('ggplot2')
library("ggplot2")ggplot2를 사용해서 패싯(facet) 패널 계층을 추가해서 작은 창에 그래프를 담아내는 방식을 앞선 시각화 수업에서 확인했다. 다음은 앞서 사용한 코드이다.
상기 코드는 원하는 그래프를 만들어 주지만, 다른 용도로는 뚜렷이 사용되지 않는 변수(starts.with, az.countries)도 생성하게 된다. %>% 연산자를 사용해서 dplyr 함수를 엮어 데이터를 파이프에 흘러보냈듯이, ggplot() 함수에 데이터를 흘러보낼 수 있다. %>% 파이프 연산자가 함수의 첫 번째 인자를 대체하기 때문에,ggplot() 함수에 data = 인자를 명시할 필요는 없다. dplyr, ggplot2 함수를 조합하게 되면, 동일한 그래프를 생성하는 데 있어 변수를 새로 생성하거나 데이터를 변경할 필요가 없어진다.
dplyr 함수를 사용하게 되면 문제를 단순화할 수 있다. 예를 들어, 첫 두 단계를 다음과 같이 조합할 수도 있다.
고급 도전과제
각 대륙별로 국가를 두 개씩 임의로 뽑아서 2002년 평균 기대수명을 계산해보자. 그리고 나서, 역순으로 대륙명을 정렬한다. 힌트: dplyr 패키지의 arrange(), sample_n() 함수를 사용한다. 두 함수 모두 다른 dplyr 함수와 유사한 구문을 갖고 있다.
해답
6.9 요약
데이터프레임 조작에 유용한 dplyr 패키지는 data 와 pliers(집게)의 합성어로, 데이터프레임을 다양한 집게로 잡아 조작한다는 의미이다. select()는 원하는 변수만 선택하고, filter()는 조건에 맞는 관측점만 남긴다. group_by()와 summarize() 함수를 조합하면 그룹별로 요약 통계량을 계산할 수 있다. 새 변수 생성에는 mutate()를 사용하고, 빈도수 수 계산에는 count()와 n() 함수가 유용하다.
dplyr의 강력함은 %>%, |> 파이프 연산자로 함수를 연결해 복잡한 조작을 간결하게 표현하는 데 있다. ggplot2 패키지와 결합해 그래프 생성 코드를 깔끔하게 만드는 데에도 활용된다. dplyr로 데이터 전처리를 마친 뒤 %>%를 통해 ggplot() 함수로 바로 연결하면 임시변수 생성 없이 그래프를 제작할 수 있다.