코드
xfun::embed_file("data/spreadsheet/spreadsheet.zip", text="실습파일 압축(zip) 다운로드")xfun::embed_file("data/spreadsheet/spreadsheet.zip", text="실습파일 압축(zip) 다운로드")연속형 값을 갖는 변수를 이산형으로 변환하는 경우가 흔히 있다. 예를 들어, 성정을 0~100점 사이 연속형 값 대신에 수우미양가 와 같은 이산형 값으로 데이터를 변환하는 것이 훨씬 더 직관적이다. 또다른 예로 의원들의 의정활동을 정량적으로 평가하여 점수를 매긴 후에 최우수/우수/중간/미흡 등과 같이 척도를 바꾸는 것이 많이 사용되는 사례다.
먼저, 10명의 학생들에 대한 임의의 데이터를 csv 형태로 만들어 보겠습니다. 이 데이터는 학생의 이름, 출석, 중간고사, 기말고사, 그리고 과제 점수를 포함하고 있습니다.
이름,출석,중간고사,기말고사,과제
학생1,10,70,80,90
학생2,9,85,75,80
학생3,10,80,90,70
학생4,8,70,75,80
학생5,10,85,90,85
학생6,9,70,80,70
학생7,10,75,85,90
학생8,9,85,80,85
학생9,10,90,85,80
학생10,8,80,85,75다음으로, 각 학생의 총점을 계산하는 엑셀 함수를 작성해야 합니다. 이는 각 학생의 출석, 중간고사, 기말고사, 그리고 과제 점수에 가중치를 적용하여 계산됩니다.
예를 들어, ’학생1’의 경우, 총점은 다음과 같이 계산됩니다:
출석 점수: 10 * 0.1 = 1 중간고사 점수: 70 * 0.3 = 21 기말고사 점수: 80 * 0.3 = 24 과제 점수: 90 * 0.3 = 27
따라서, 학생1의 총점은 1 + 21 + 24 + 27 = 73 점이 됩니다.
이러한 계산을 엑셀에서 수행하는 함수는 다음과 같이 작성할 수 있습니다:
= B2*0.1 + C2*0.3 + D2*0.3 + E2*0.3마지막으로, 각 학생의 성적을 할당하는 엑셀 함수를 작성해야 합니다. 이 함수는 총점에 따라 학생에게 ‘A’, ‘B’, ‘C’, 또는 ‘F’ 성적을 할당합니다.
이를 수행하는 엑셀 함수는 다음과 같이 작성할 수 있습니다:
=IF(F2>=90, "A", IF(F2>=80, "B", IF(F2>=70, "C", "F")))위의 함수에서 ‘F2’는 총점이 계산된 엑셀의 셀을 나타냅니다. 이 함수는 ’F2’ 셀의 값이 90 이상인지, 80 이상인지, 70 이상인지 확인하고, 각 경우에 따라 적절한 성적을 할당합니다. 만약 ‘F2’ 셀의 값이 70 미만인경우, 학생에게 ‘F’ 성적이 할당됩니다.
이러한 방식으로, 엑셀에서 학생들의 성적을 계산하고 할당하는 함수를 작성할 수 있습니다.
library(tidyverse)
library(googlesheets4)
library(gt)
gpa <- googlesheets4::read_sheet(ss = "https://docs.google.com/spreadsheets/d/1PLIvo8hfZQ_a15NAMiPOAXuTp40ngVIwGRaIh4qaSRo/edit#gid=0", sheet = "학점")
gpa %>%
gt::gt() %>%
cols_align(align = "center",
columns = everything())| 이름 | 출석 | 중간고사 | 기말고사 | 과제 | 총점 | 학점 |
|---|---|---|---|---|---|---|
| 학생1 | 10 | 70 | 80 | 90 | 73.0 | C |
| 학생2 | 9 | 85 | 75 | 80 | 72.9 | C |
| 학생3 | 10 | 80 | 90 | 70 | 73.0 | C |
| 학생4 | 8 | 70 | 75 | 80 | 68.3 | F |
| 학생5 | 10 | 85 | 90 | 85 | 79.0 | C |
| 학생6 | 9 | 70 | 80 | 70 | 66.9 | F |
| 학생7 | 10 | 75 | 85 | 90 | 76.0 | C |
| 학생8 | 9 | 85 | 80 | 85 | 75.9 | C |
| 학생9 | 10 | 90 | 85 | 80 | 77.5 | C |
| 학생10 | 8 | 80 | 85 | 75 | 72.8 | C |
데이터의 정합성을 유지하는 것은
입고일자,자재명,자재번호,담당부서,수량,단위
네, 20개의 공장 입고 데이터를 생성했습니다. 중복은 입고일자, 자재명, 자재번호, 담당부서, 수량, 단위가 모두 동일해야 합니다. 자재명과 담당부서도 실제처럼 작성했습니다.
입고일자,자재명,자재번호,담당부서,수량,단위
2023-05-23,나사,123456,생산부,100,개
2023-05-23,볼트,789012,품질관리부,200,개
2023-05-23,못,345678,연구개발부,300,개
2023-05-23,드라이버,987654,영업부,400,개
2023-05-23,망치,654321,마케팅부,500,개
2023-05-23,톱,543210,총무부,600,개
2023-05-23,끌,432109,인사부,700,개
2023-05-23,못박이,321098,재무부,800,개
2023-05-23,칼,210987,자재부,900,개
2023-05-23,가위,109876,공장장실,1000,개
2023-05-23,나사,123456,생산부,100,개
2023-05-23,볼트,789012,품질관리부,200,개
2023-05-23,못,345678,연구개발부,300,개
2023-05-23,드라이버,987654,영업부,400,개
2023-05-23,망치,654321,마케팅부,500,개
2023-05-23,톱,543210,총무부,600,개
2023-05-23,끌,432109,인사부,700,개
2023-05-23,못박이,321098,재무부,800,개
2023-05-23,칼,210987,자재부,900,개아래 데이터는 백틱(`) 3개에 담겨져 있습니다. 데이터에 중복된 데이터가 있어 이를 제거하는 엑셀 코드를 작성해주세요.
입고일자,자재명,자재번호,담당부서,수량,단위
2023-05-23,나사,123456,생산부,100,개
2023-05-23,볼트,789012,품질관리부,200,개
2023-05-23,못,345678,연구개발부,300,개
2023-05-23,드라이버,987654,영업부,400,개
2023-05-23,망치,654321,마케팅부,500,개
2023-05-23,톱,543210,총무부,600,개
2023-05-23,끌,432109,인사부,700,개
2023-05-23,못박이,321098,재무부,800,개
2023-05-23,칼,210987,자재부,900,개
2023-05-23,가위,109876,공장장실,1000,개
2023-05-23,나사,123456,생산부,100,개
2023-05-23,볼트,789012,품질관리부,200,개
2023-05-23,못,345678,연구개발부,300,개
2023-05-23,드라이버,987654,영업부,400,개
2023-05-23,망치,654321,마케팅부,500,개
2023-05-23,톱,543210,총무부,600,개
2023-05-23,끌,432109,인사부,700,개
2023-05-23,못박이,321098,재무부,800,개
2023-05-23,칼,210987,자재부,900,개중복된 데이터를 제거하려면 Excel의 “중복 제거” 기능을 사용하면 됩니다. 아래 단계대로 진행하시면 됩니다:
이렇게 하면 중복된 행이 제거되고 유일한 행만 남게 됩니다.


챗GPT에 중복을 제거하는 엑셀 매크로를 작성하도록 지시한다.
입고일자,자재명,자재번호,담당부서,수량,단위
2023-05-23,나사,123456,생산부,100,개
2023-05-23,볼트,789012,품질관리부,200,개
2023-05-23,못,345678,연구개발부,300,개
2023-05-23,드라이버,987654,영업부,400,개
2023-05-23,망치,654321,마케팅부,500,개
2023-05-23,톱,543210,총무부,600,개
2023-05-23,끌,432109,인사부,700,개
2023-05-23,못박이,321098,재무부,800,개
2023-05-23,칼,210987,자재부,900,개
2023-05-23,가위,109876,공장장실,1000,개
2023-05-23,나사,123456,생산부,100,개
2023-05-23,볼트,789012,품질관리부,200,개
2023-05-23,못,345678,연구개발부,300,개
2023-05-23,드라이버,987654,영업부,400,개
2023-05-23,망치,654321,마케팅부,500,개
2023-05-23,톱,543210,총무부,600,개
2023-05-23,끌,432109,인사부,700,개
2023-05-23,못박이,321098,재무부,800,개
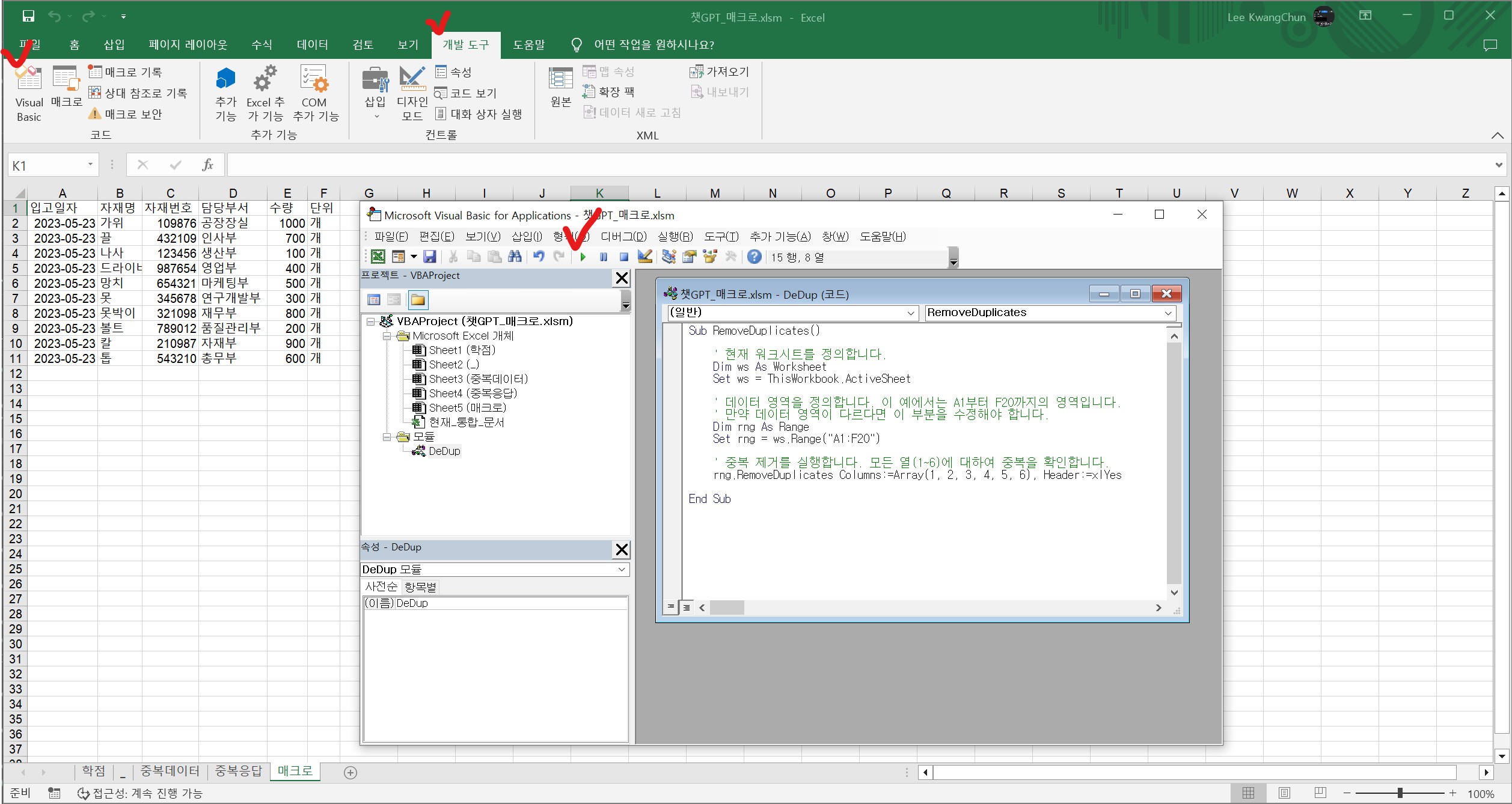
2023-05-23,칼,210987,자재부,900,개엑셀의 VBA(Visual Basic for Applications)를 이용하여 중복된 행을 제거하는 매크로를 만들 수 있습니다. 아래에 예시 코드를 제공합니다.
Sub RemoveDuplicates()
' 현재 워크시트를 정의합니다.
Dim ws As Worksheet
Set ws = ThisWorkbook.ActiveSheet
' 데이터 영역을 정의합니다. 이 예에서는 A1부터 F20까지의 영역입니다.
' 만약 데이터 영역이 다르다면 이 부분을 수정해야 합니다.
Dim rng As Range
Set rng = ws.Range("A1:F20")
' 중복 제거를 실행합니다. 모든 열(1~6)에 대하여 중복을 확인합니다.
rng.RemoveDuplicates Columns:=Array(1, 2, 3, 4, 5, 6), Header:=xlYes
End Sub위 코드는 데이터가 A1부터 F20까지 위치하고, 첫 번째 행에 헤더가 있는 경우를 가정합니다. 실제 데이터의 위치와 헤더의 유무에 따라 코드를 조정해야 할 수 있습니다.
이 매크로를 사용하려면, 엑셀에서 다음과 같이 하십시오.
데이터프레임으로 불러와서 중복은 제거하는 함수(distinct())로 중복을 제거하자.
library(tidyverse)
library(readxl)
material <- read_excel("data/spreadsheet/챗GPT.xlsx", sheet="중복제거")
material %>%
distinct(입고일자, 자재명, 자재번호, 담당부서, 수량) %>%
mutate(자재번호 = row_number()) %>%
select(자재번호, everything()) %>%
gt::gt() %>%
gt::cols_align(align="center", columns = everything())| 자재번호 | 입고일자 | 자재명 | 담당부서 | 수량 |
|---|---|---|---|---|
| 1 | 2023-05-23 | 가위 | 공장장실 | 1000 |
| 2 | 2023-05-23 | 끌 | 인사부 | 700 |
| 3 | 2023-05-23 | 나사 | 생산부 | 100 |
| 4 | 2023-05-23 | 드라이버 | 영업부 | 400 |
| 5 | 2023-05-23 | 망치 | 마케팅부 | 500 |
| 6 | 2023-05-23 | 못 | 연구개발부 | 300 |
| 7 | 2023-05-23 | 못박이 | 재무부 | 800 |
| 8 | 2023-05-23 | 볼트 | 품질관리부 | 200 |
| 9 | 2023-05-23 | 칼 | 자재부 | 900 |
| 10 | 2023-05-23 | 톱 | 총무부 | 600 |
챗GPT의 도움으로 R 코드를 간략하게 파이썬 코드로 구현할 수 있다.
# !pip install openpyxl
import pandas as pd
from openpyxl import load_workbook
# Load the data
material = pd.read_excel('data/spreadsheet/챗GPT.xlsx', sheet_name='중복제거')
# Drop duplicate rows based on specific columns
material = material.drop_duplicates(subset=['입고일자', '자재명', '자재번호', '담당부서', '수량'])
# Add a new column with row number
material['자재번호'] = range(1, len(material) + 1)
# Rearrange the columns
cols = material.columns.tolist()
cols = cols[-1:] + cols[:-1]
material = material[cols]
# Display the DataFrame
print(material)
#> 단위 입고일자 자재명 자재번호 담당부서 수량
#> 0 개 2023-05-23 가위 1 공장장실 1000
#> 1 개 2023-05-23 끌 2 인사부 700
#> 3 개 2023-05-23 나사 3 생산부 100
#> 5 개 2023-05-23 드라이버 4 영업부 400
#> 7 개 2023-05-23 망치 5 마케팅부 500
#> 9 개 2023-05-23 못 6 연구개발부 300
#> 11 개 2023-05-23 못박이 7 재무부 800
#> 13 개 2023-05-23 볼트 8 품질관리부 200
#> 15 개 2023-05-23 칼 9 자재부 900
#> 17 개 2023-05-23 톱 10 총무부 600library(tidyverse)
library(readxl)
material <- read_excel("data/spreadsheet/챗GPT.xlsx", sheet="중복제거")
material %>%
distinct(입고일자, 자재명, 자재번호, 담당부서, 수량) %>%
mutate(자재번호 = row_number()) %>%
select(자재번호, everything()) %>%
gt::gt() %>%
gt::cols_align(align="center", columns = everything())Sure, I can help with that. Here’s how your R code might look in Python using pandas for data handling and openpyxl for reading Excel files:
import pandas as pd
from openpyxl import load_workbook
# Load the data
material = pd.read_excel('data/spreadsheet/챗GPT.xlsx', sheet_name='중복제거')
# Drop duplicate rows based on specific columns
material = material.drop_duplicates(subset=['입고일자', '자재명', '자재번호', '담당부서', '수량'])
# Add a new column with row number
material['자재번호'] = range(1, len(material) + 1)
# Rearrange the columns
cols = material.columns.tolist()
cols = cols[-1:] + cols[:-1]
material = material[cols]
# Display the DataFrame
print(material)
# Optional: Save the DataFrame to a new Excel file
material.to_excel("data/spreadsheet/챗GPT_processed.xlsx", index=False)Please note that Python does not have a direct equivalent to the gt::gt() and gt::cols_align() functions from R. If you would like to display a stylized table in a Jupyter notebook for example, you may want to use the DataFrame style methods. You can center the text in the DataFrame like so:
material.style.set_properties(**{'text-align': 'center'})And this is only for displaying purposes. If you need a more feature-rich table formatting tool, consider using packages like tabulate or prettytable. Also, you might want to consider formatting the table in the destination, like a HTML file, a markdown document, or in Excel using openpyxl styles.