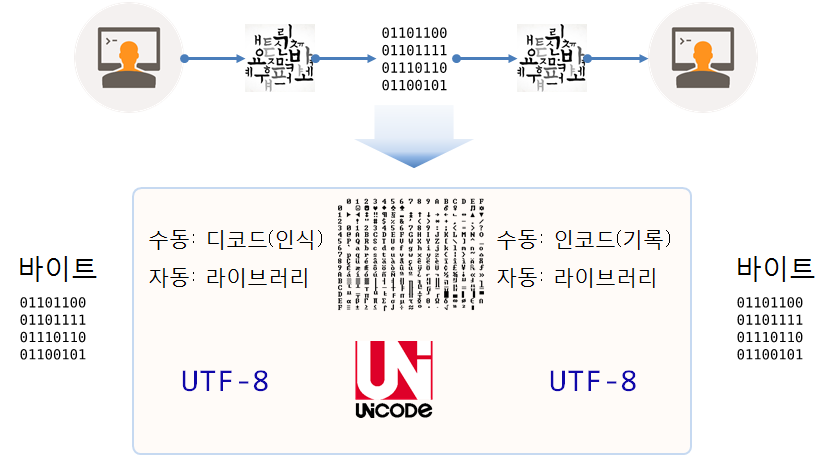
웹 표준 인코딩
스마트폰의 대중화에 따라 더이상 윈도우 운영체제에서 사용되는 문자체계가 더이상 표준이 되지 못하고 여러 문제점을 야기함에 따라 유니코드 + UTF-8 체제가 대세로 자리잡고 있는 것이 확연히 나타나고 있다.
2010년 구글에서 발표 한 자료에 의하면 2010년 UTF-8 인코딩이 웹에서 주류로 부상하기 시작한 것이 확인되었다. (Davis, 2010 ) 웹기반 플롯 디지털 도구를 활용하여 그래프(WebPlotDigitizer )에서 데이터를 추출하여 시각화면 유사한 결과를 시각적으로 표현할 수 있다.
2010년 이후 웹에서 가장 점유율이 높은 인코딩 방식은 UTF-8으로 W3Tech Web Technology Surveys 를 통해 확인을 할 수 있다.
Code
library (tidyverse):: loadfonts ()## 1. 2000년부터 웹 인코딩 추세 ------------------ <- read_csv ("data/ascii_red.csv" , col_names = FALSE ) %>% set_names (c ("연도" , "ascii" ))<- ascii %>% mutate (연도 = floor (연도)) %>% group_by (연도) %>% summarize (ascii = mean (ascii))<- read_csv ("data/iso_orange.csv" , col_names = FALSE ) %>% set_names (c ("연도" , "iso_8859" ))<- iso_8859 %>% mutate (연도 = floor (연도)) %>% group_by (연도) %>% summarize (iso_8859 = mean (iso_8859))<- read_csv ("data/utf-8_blue.csv" , col_names = FALSE ) %>% set_names (c ("연도" , "utf_8" ))<- utf_8 %>% mutate (연도 = floor (연도)) %>% group_by (연도) %>% summarize (utf_8 = mean (utf_8, na.rm = FALSE )) <- left_join (ascii_tbl, iso_8859_tbl) %>% left_join (utf_8_tbl) %>% pivot_longer (cols = - 연도) %>% mutate (value = ifelse (is.na (value), 0 , value)) %>% filter (연도 <= 2009 )<- encoding_tbl %>% mutate (연도 = lubridate:: make_date (year = 연도)) %>% ggplot (aes (x = 연도, y = value, color = name)) + geom_line () + geom_point () + theme_bw (base_family = "MaruBuri" ) + labs (x = "" ,y = "점유율(%)" ,title = "웹에서 UTF-8 성장세" ,subtitle = "2010 ~ 2010년" ,color = "인코딩" ) + scale_y_continuous (labels = scales:: percent) + scale_color_manual (values = c ("ascii" = "gray50" , "iso_8859" = "red" , "utf_8" = "blue" )) + theme (legend.position = "top" ) + expand_limits (y = c (0 , 1 ))## 2. 2010년부터 웹 인코딩 추세 ------------------ library (readxl)<- read_excel ("data/web_encoding.xlsx" , col_types = "text" )<- encoding_raw %>% :: clean_names (ascii = FALSE ) %>% pivot_longer (cols = - 구분, names_to = "연도" , values_to = "점유율" ) %>% mutate (연도 = str_extract (연도, " \\ d{4}" ) %>% as.integer (.)) %>% mutate (점유율 = parse_number (점유율)) %>% group_by (구분, 연도) %>% summarise (점유율 = min (점유율, na.rm = TRUE )) %>% ungroup ()<- encoding_web %>% filter (구분 %in% c ("EUC-KR" , "GB2312" , "Shift JIS" , "UTF-8" , "ISO-8859-1" )) %>% mutate (연도 = lubridate:: make_date (year = 연도)) %>% ggplot (aes (x = 연도, y = 점유율, color = 구분)) + geom_line () + geom_point () + theme_bw (base_family = "MaruBuri" ) + labs (x = "" ,y = "점유율(%)" ,title = "웹에서 UTF-8 성장세" ,subtitle = "2011 ~ 2012년 3분기" ,color = "인코딩" ) + scale_y_continuous (labels = scales:: percent) + scale_color_manual (values = c ("EUC-KR" = "gray50" , "GB2312" = "gray80" , "Shift JIS" = "gray70" , "ISO-8859-1" = "red" , "UTF-8" = "blue" )) + theme (legend.position = "top" ) + expand_limits (y = c (0 , 1 ))## 3. 시각화 요약 ------------------ library (patchwork)+ encoding_2022_g
유니코드와 UTF-8
사람과 사람 사이 의사소통하는데 필요한 것 중 하나가 문자 다. 문자는 영어 알파벳, 한국어 한글, 중국 한자 등 무수히 많은 언어가 문자를 사용해서 의사를 소통한다. 이를 컴퓨터를 활용해서 의사소통하는 경우 컴퓨터가 인식할 수 있도록 바이트를 사용한다.
컴퓨터는 바이트로 만들어 졌고, 바이트를 묶어 파일이 되고, 파일을 네트워크에 전송해서 다른 컴퓨터에 넘겨야 되고, 이를 사람이 읽을 수 있는 형태로 변환하면 의사소통이 완성된다. 이 과정에서 인코딩(Encoding, 부호화)하는 과정과 디코딩(Decoding, 복화화)하는 과정을 거치게 된다.
컴퓨터에서 입출력되는 모든 정보는 바이트(Byte), 즉 예를 들어 알파벳 A는 0100 0001으로 부호화되어 전달된다.
0100 0001 바이트를 사람이 인식할 수 있는 A로 인식한 최초의 약속이 아스키(ASCII) 다.영문자를 기반으로한 ASCII 256개 기호보다 많은 기호를 전달할 필요가 있다. 특히, CJK 동아시아 한자문화권에서는 더욱 그렇다. 그렇게 컴퓨터를 이용하여 문자를 전달하고 전달받고자하는 영문자를 제외한 다른 문화권에서 이를 확장한 노력이 동시 다발적으로 일어났고 한글은 EUC-KR, 일본문자는 Shift_JIS, 중국 한자는 GB2312, 러시아 등에서 사용되는 키릴 문자는 Windows-1251, 같은 라틴문화권이지만 각자 고유 문자를 갖고 있는 스페인, 프랑스, 독일 등은 Windows-1252 규약을 사용했다.
표의문자(이모지 등)가 대거 등장하고 아랍어를 비롯한 전세계 문자를 컴퓨터에 넣기 위해서 더 많은 문자를 담을 수 있는 표준이 필요했고 유니코드(Unicode) 가 탄생했고 이제 웹 표준으로 정착됨은 물론 모든 문서의 문자를 표현하는 표준으로 자리잡아가고 있다.
유니코드(Unicode) 는 글자와 코드가 1:1 매핑되어 있는 단순한 코드표 에 불과하고 산업표준으로 일종의 국가 당사자간 약속이다. 한글 이 표현된 유니코드 영역은 위키백과 유니코드 영역 에서 찾을 수 있다.
UTF-8(Universal Coded Character Set + Transformation Format – 8-bit의 약자) 은 앞서 정의한 유니코드를 위한 가변 길이 문자 인코딩 방식 중 하나로, 켄 톰프슨과 롭 파이크가 제작했다.
예를 들어, 영어 A 대문자는 1 바이트, 한글 가는 3 바이트다.
Code
<- pryr:: bits ("A" , split = TRUE )
Code
Code
<- pryr:: bits ("가" , split = TRUE )
[1] "11101010 10110000 10000000"
Code
R 4.2
R 4.2 버전은 그 이전 R과 달리 크게 변화된 문자체계를 갖고 있다. R 언어로 통계 및 데이터 과학 작업을 할 경우 크게 3개 문자표(Character Map)가 중요하다. 사실 다른 언어권의 문자도 유사하게 생각하여 확장할 수도 있다.
Alex Farach, “Let’s start at the beginning - bits to character encoding in R”, rstudio::conf(2022)
ASCII: 7 비트 = \(2^7 = 128\) 문자
Latin1 (ISO-8859-1): 8 비트 = \(2^8 = 256\) 문자
UTF-8 (Unicode Transformation 8-bit): 1:4 바이트 = 1,112,064 문자(혹은, Code Points)
MBCS(Multi-Byte Character Set) 는 바이트 2개이상을 사용해서 문자를 표현하는 인코딩 방식으로 2 바이트를 사용하는 DBCS(double-byte character set) 으로 한글, 일본문자, 한자(CJK)를 표현하는데 큰 무리가 없었기 때문에 MBCS = DBCS 로 볼 수 있었다. MBCS는 UNICODE 라는 산업표준이 정립되기 이전에 CJK 문자를 표현하기 위한 하나의 과도기적 문자표로 이해할 수 있다.
Code
<- c ("커피" , "coffee" , "café" , "caf\u00E9" , "caf \xe9 " )print (coffee_v)
[1] "커피" "coffee" "café" "café" "caf\xe9"
Code
[1] "UTF-8" "unknown" "UTF-8" "UTF-8" "unknown"
R 4.2 이후 버전에서 Encoding() 함수를 사용해서 인코딩을 확인할 수 있다. 크게 보면 기존
Code
$MBCS
[1] TRUE
$`UTF-8`
[1] TRUE
$`Latin-1`
[1] FALSE
$codepage
[1] 65001
$system.codepage
[1] 65001
MBCS와 UTF-8 이 활성화되어 있지만, Latin-1 즉 확장 아스키 코드는 비활성화되어 있고 코드페이지는 65001을 갖고 있다.
Code
[1] "LC_COLLATE=Korean_Korea.utf8;LC_CTYPE=Korean_Korea.utf8;LC_MONETARY=Korean_Korea.utf8;LC_NUMERIC=C;LC_TIME=Korean_Korea.utf8"
로컬라이제이션(localization) 은 사용자의 문화와 언어에 맞추는 일체의 과정을 의미하고 당연히 문자도 여기에 포함된다. 날짜, 시간, 숫자 표기법 등이 여기에 포함된다. 로컬라이제이션이 영문자로도 길기 때문에 줄여서 l10n으로 표현한다.
LC_ALL: 모든 카테고리에 대한 로케일 설정을 위한 환경변수
LC_CTYPE: 문자 분류, 글자수, 대소문자 구분
LC_NUMERIC: 숫자와 관련된 기준
LC_COLLATE: 문자열의 정렬 순서를 결정
LC_TIME: 날짜 시간 표시방법
LC_MONETARY: 통화나 금액과 관련된 숫자의 기준
LC_MESSAGES: 메시지 표시
LC_PAPER: 종이
LC_ADDRESS: 주소
LC_TELEPHONE: 전화번호
LC_MEASUREMENT: 측정단위 (무게, 온도 등)
LC_NAME: ???
LC_IDENTIFICATION: ???
문자표
ASCII 는 7비트로 총 \(2^7=128\) 문자 주로 영미권 문자를 문자표(Character Map)에 매핑하는데 사용되는 인코딩 방식이다. 영어 파운드화 등 기호를 확장하여 인접한 라틴문화권 문자도 컴퓨터로 표시할 수 있도록 확장한 표준이 ISO-8859-1 로 8비트를 사용하여 총 \(2^8=256\) 개 문자 표현이 가능하다.
요약하면, 영문자(Alphabet)를 표현하는데 ASCII 7비트 총 128개 문자로 충분했으나 추가 문자가 필요한 언어의 경우 이를 확장하여 256개 문자를 각자 나머지 128개 문자를 각자 문자에 넣어 표준을 제정하여 사용했었다.
EUC-KR: 한글
Shift_JIS : 일본문자
GB2312: 한자
Windows-1251: 키릴 문자 (러시아 등)
Windows-1252: 스페인, 프랑스, 독일 등
…
과거 문자를 단순히 영미권과 주요 선진국에서 사용하던 것을 넘어 전세계 문자를 컴퓨터로 표현하는데 유니코드가 제정되었고 웹에서 빠르게 국제표준으로 자리잡았다.
ASCII 문자
ASCII 총 \(2^7=128\) 문자 중 제어문자를 제외한 출력가능한 문자를 뽑아보자.
Code
<- c (33 : 126 )<- tibble (= coderange,= as.raw (coderange),= rawToChar (as.raw (coderange), multiple= TRUE ),= pryr:: bits (문자, split = TRUE )%>% relocate (문자, .before = 십진수)%>% slice_sample (n= 30 )
# A tibble: 30 × 4
문자 십진수 십육진수 이진수
<chr> <int> <raw> <chr>
1 "I" 73 49 01001001
2 "3" 51 33 00110011
3 "z" 122 7a 01111010
4 "S" 83 53 01010011
5 "#" 35 23 00100011
6 ">" 62 3e 00111110
7 "\\" 92 5c 01011100
8 "b" 98 62 01100010
9 "w" 119 77 01110111
10 "=" 61 3d 00111101
# … with 20 more rows
출력가능한 ASCII 문자표를 33번부터 126번까지 문자 십진수 이진수 순으로 출력하면 다음과 같다.
Code
library (mmtable2) # devtools::install_github("ianmoran11/mmtable2") %>% mutate (index = row_number ()) %>% mutate (x_grp = index %/% 10 ) %>% mutate (y_grp = index %% 10 ) %>% group_by (x_grp, y_grp) %>% summarise (문자 = glue:: glue ("{문자} {십진수} {이진수}" ) ) %>% ungroup () %>% mmtable (cells = 문자) + header_left (x_grp) + header_top (y_grp)
0
1
2
3
4
5
6
7
8
9 0
! 33 00100001
" 34 00100010
# 35 00100011
$ 36 00100100
% 37 00100101
& 38 00100110
' 39 00100111
( 40 00101000
) 41 00101001 1
* 42 00101010
+ 43 00101011
, 44 00101100
- 45 00101101
. 46 00101110
/ 47 00101111
0 48 00110000
1 49 00110001
2 50 00110010
3 51 00110011 2
4 52 00110100
5 53 00110101
6 54 00110110
7 55 00110111
8 56 00111000
9 57 00111001
: 58 00111010
; 59 00111011
< 60 00111100
= 61 00111101 3
> 62 00111110
? 63 00111111
@ 64 01000000
A 65 01000001
B 66 01000010
C 67 01000011
D 68 01000100
E 69 01000101
F 70 01000110
G 71 01000111 4
H 72 01001000
I 73 01001001
J 74 01001010
K 75 01001011
L 76 01001100
M 77 01001101
N 78 01001110
O 79 01001111
P 80 01010000
Q 81 01010001 5
R 82 01010010
S 83 01010011
T 84 01010100
U 85 01010101
V 86 01010110
W 87 01010111
X 88 01011000
Y 89 01011001
Z 90 01011010
[ 91 01011011 6
\ 92 01011100
] 93 01011101
^ 94 01011110
_ 95 01011111
` 96 01100000
a 97 01100001
b 98 01100010
c 99 01100011
d 100 01100100
e 101 01100101 7
f 102 01100110
g 103 01100111
h 104 01101000
i 105 01101001
j 106 01101010
k 107 01101011
l 108 01101100
m 109 01101101
n 110 01101110
o 111 01101111 8
p 112 01110000
q 113 01110001
r 114 01110010
s 115 01110011
t 116 01110100
u 117 01110101
v 118 01110110
w 119 01110111
x 120 01111000
y 121 01111001 9
z 122 01111010
{ 123 01111011
| 124 01111100
} 125 01111101
~ 126 01111110
확장 ASCII 문자
확장 ASCII 총 \(2^8=256\) 문자 중 앞선 기본 ASCII를 제외한 나머지 확장문자표를 출력해보자.
Code
<- c (161 : 255 )# iconv(extendedascii, from="Windows-1252", to="UTF-8") <- tibble (= coderange,= as.raw (coderange),= rawToChar (as.raw (coderange), multiple= TRUE ),= pryr:: bits (문자, split = TRUE )%>% relocate (문자, .before = 십진수) %>% mutate (문자 = str_conv (문자, encoding = "latin-1" )) %>% slice_sample (n= 30 )
# A tibble: 30 × 4
문자 십진수 십육진수 이진수
<chr> <int> <raw> <chr>
1 ¤ 164 a4 10100100
2 ÷ 247 f7 11110111
3 æ 230 e6 11100110
4 Þ 222 de 11011110
5 ® 174 ae 10101110
6 Ý 221 dd 11011101
7 Ô 212 d4 11010100
8 Ä 196 c4 11000100
9 ¸ 184 b8 10111000
10 ç 231 e7 11100111
# … with 20 more rows
Code
library (mmtable2) # devtools::install_github("ianmoran11/mmtable2") %>% mutate (index = row_number ()) %>% mutate (x_grp = index %/% 10 ) %>% mutate (y_grp = index %% 10 ) %>% group_by (x_grp, y_grp) %>% summarise (문자 = glue:: glue ("{문자} \n {십진수} \n {이진수}" ) ) %>% ungroup () %>% ggplot (aes (x= x_grp, y= y_grp)) + geom_text (aes (label = 문자), size = 3 ) + theme_void (base_family = "MaruBuri" )
[참조: Ascii code table in R ], ASCII Table with All 256 Character codes in decimal, hexadecimal, octal and binary
유니코드
Unicode
Code
library (Unicode)library (rlang)<- u_scripts ()names (all_scripts)
[1] "Adlam" "Ahom" "Anatolian_Hieroglyphs"
[4] "Arabic" "Armenian" "Avestan"
[7] "Balinese" "Bamum" "Bassa_Vah"
[10] "Batak" "Bengali" "Bhaiksuki"
[13] "Bopomofo" "Brahmi" "Braille"
[16] "Buginese" "Buhid" "Canadian_Aboriginal"
[19] "Carian" "Caucasian_Albanian" "Chakma"
[22] "Cham" "Cherokee" "Chorasmian"
[25] "Common" "Coptic" "Cuneiform"
[28] "Cypriot" "Cypro_Minoan" "Cyrillic"
[31] "Deseret" "Devanagari" "Dives_Akuru"
[34] "Dogra" "Duployan" "Egyptian_Hieroglyphs"
[37] "Elbasan" "Elymaic" "Ethiopic"
[40] "Georgian" "Glagolitic" "Gothic"
[43] "Grantha" "Greek" "Gujarati"
[46] "Gunjala_Gondi" "Gurmukhi" "Han"
[49] "Hangul" "Hanifi_Rohingya" "Hanunoo"
[52] "Hatran" "Hebrew" "Hiragana"
[55] "Imperial_Aramaic" "Inherited" "Inscriptional_Pahlavi"
[58] "Inscriptional_Parthian" "Javanese" "Kaithi"
[61] "Kannada" "Katakana" "Kawi"
[64] "Kayah_Li" "Kharoshthi" "Khitan_Small_Script"
[67] "Khmer" "Khojki" "Khudawadi"
[70] "Lao" "Latin" "Lepcha"
[73] "Limbu" "Linear_A" "Linear_B"
[76] "Lisu" "Lycian" "Lydian"
[79] "Mahajani" "Makasar" "Malayalam"
[82] "Mandaic" "Manichaean" "Marchen"
[85] "Masaram_Gondi" "Medefaidrin" "Meetei_Mayek"
[88] "Mende_Kikakui" "Meroitic_Cursive" "Meroitic_Hieroglyphs"
[91] "Miao" "Modi" "Mongolian"
[94] "Mro" "Multani" "Myanmar"
[97] "Nabataean" "Nag_Mundari" "Nandinagari"
[100] "New_Tai_Lue" "Newa" "Nko"
[103] "Nushu" "Nyiakeng_Puachue_Hmong" "Ogham"
[106] "Ol_Chiki" "Old_Hungarian" "Old_Italic"
[109] "Old_North_Arabian" "Old_Permic" "Old_Persian"
[112] "Old_Sogdian" "Old_South_Arabian" "Old_Turkic"
[115] "Old_Uyghur" "Oriya" "Osage"
[118] "Osmanya" "Pahawh_Hmong" "Palmyrene"
[121] "Pau_Cin_Hau" "Phags_Pa" "Phoenician"
[124] "Psalter_Pahlavi" "Rejang" "Runic"
[127] "Samaritan" "Saurashtra" "Sharada"
[130] "Shavian" "Siddham" "SignWriting"
[133] "Sinhala" "Sogdian" "Sora_Sompeng"
[136] "Soyombo" "Sundanese" "Syloti_Nagri"
[139] "Syriac" "Tagalog" "Tagbanwa"
[142] "Tai_Le" "Tai_Tham" "Tai_Viet"
[145] "Takri" "Tamil" "Tangsa"
[148] "Tangut" "Telugu" "Thaana"
[151] "Thai" "Tibetan" "Tifinagh"
[154] "Tirhuta" "Toto" "Ugaritic"
[157] "Vai" "Vithkuqi" "Wancho"
[160] "Warang_Citi" "Yezidi" "Yi"
[163] "Zanabazar_Square"
영문자
영문자를 유니코드에서 찾아 살펴보자. 영문자는 라틴 계열이라 라틴계열에 포함된 문자를 뽑아서 유니코드 범위를 정해서 유니코드 범위에 포함된 문자를 사람이 읽을 수 있는 문자로 화면에 일부만 출력한다.
Code
<- u_scripts ('Latin' )<- map (latin_char, n_of_u_chars)<- function (i) {<- as.u_char_seq (latin_char$ Latin[i])<- unlist (expand_ranges)intToUtf8 (unicode_chars)map_chr (1 : 10 , show_characters)
[1] "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
[2] "abcdefghijklmnopqrstuvwxyz"
[3] "ª"
[4] "º"
[5] "ÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖ"
[6] "ØÙÚÛÜÝÞßàáâãäåæçèéêëìíîïðñòóôõö"
[7] "øùúûüýþÿĀāĂ㥹ĆćĈĉĊċČčĎďĐđĒēĔĕĖėĘęĚěĜĝĞğĠġĢģĤĥĦħĨĩĪīĬĭĮįİıIJijĴĵĶķĸĹĺĻļĽľĿŀŁłŃńŅņŇňʼnŊŋŌōŎŏŐőŒœŔŕŖŗŘřŚśŜŝŞşŠšŢţŤťŦŧŨũŪūŬŭŮůŰűŲųŴŵŶŷŸŹźŻżŽžſƀƁƂƃƄƅƆƇƈƉƊƋƌƍƎƏƐƑƒƓƔƕƖƗƘƙƚƛƜƝƞƟƠơƢƣƤƥƦƧƨƩƪƫƬƭƮƯưƱƲƳƴƵƶƷƸƹƺ"
[8] "ƻ"
[9] "Ƽƽƾƿ"
[10] "ǀǁǂǃ"
한글
동일하게 유니코드에 등록된 한글도 확인해보자. 한글완성형으로 한글 유니코드 7번째 블록에 11,172 개 글자가 등록되어 있어 이를 제외한 한글을 뽑아보자.
Code
<- u_scripts ('Hangul' )<- map (hangul_scripts, n_of_u_chars)map (hangul_scripts, n_of_u_chars)
$Hangul
[1] 256 2 94 31 31 29 11172 23 49 31 6 6
[13] 6 3
Code
<- as.u_char_seq (hangul_scripts$ Hangul[7 ])<- function (i) {<- as.u_char_seq (hangul_scripts$ Hangul[i])<- unlist (expand_ranges)intToUtf8 (unicode_chars)map_chr (c (1 : 6 ,8 : 14 ), show_hangul)
[1] "ᄀᄁᄂᄃᄄᄅᄆᄇᄈᄉᄊᄋᄌᄍᄎᄏᄐᄑᄒᄓᄔᄕᄖᄗᄘᄙᄚᄛᄜᄝᄞᄟᄠᄡᄢᄣᄤᄥᄦᄧᄨᄩᄪᄫᄬᄭᄮᄯᄰᄱᄲᄳᄴᄵᄶᄷᄸᄹᄺᄻᄼᄽᄾᄿᅀᅁᅂᅃᅄᅅᅆᅇᅈᅉᅊᅋᅌᅍᅎᅏᅐᅑᅒᅓᅔᅕᅖᅗᅘᅙᅚᅛᅜᅝᅞᅟᅠᅡᅢᅣᅤᅥᅦᅧᅨᅩᅪᅫᅬᅭᅮᅯᅰᅱᅲᅳᅴᅵᅶᅷᅸᅹᅺᅻᅼᅽᅾᅿᆀᆁᆂᆃᆄᆅᆆᆇᆈᆉᆊᆋᆌᆍᆎᆏᆐᆑᆒᆓᆔᆕᆖᆗᆘᆙᆚᆛᆜᆝᆞᆟᆠᆡᆢᆣᆤᆥᆦᆧᆨᆩᆪᆫᆬᆭᆮᆯᆰᆱᆲᆳᆴᆵᆶᆷᆸᆹᆺᆻᆼᆽᆾᆿᇀᇁᇂᇃᇄᇅᇆᇇᇈᇉᇊᇋᇌᇍᇎᇏᇐᇑᇒᇓᇔᇕᇖᇗᇘᇙᇚᇛᇜᇝᇞᇟᇠᇡᇢᇣᇤᇥᇦᇧᇨᇩᇪᇫᇬᇭᇮᇯᇰᇱᇲᇳᇴᇵᇶᇷᇸᇹᇺᇻᇼᇽᇾᇿ"
[2] "〮〯"
[3] "ㄱㄲㄳㄴㄵㄶㄷㄸㄹㄺㄻㄼㄽㄾㄿㅀㅁㅂㅃㅄㅅㅆㅇㅈㅉㅊㅋㅌㅍㅎㅏㅐㅑㅒㅓㅔㅕㅖㅗㅘㅙㅚㅛㅜㅝㅞㅟㅠㅡㅢㅣㅤㅥㅦㅧㅨㅩㅪㅫㅬㅭㅮㅯㅰㅱㅲㅳㅴㅵㅶㅷㅸㅹㅺㅻㅼㅽㅾㅿㆀㆁㆂㆃㆄㆅㆆㆇㆈㆉㆊㆋㆌㆍㆎ"
[4] "㈀㈁㈂㈃㈄㈅㈆㈇㈈㈉㈊㈋㈌㈍㈎㈏㈐㈑㈒㈓㈔㈕㈖㈗㈘㈙㈚㈛㈜㈝㈞"
[5] "㉠㉡㉢㉣㉤㉥㉦㉧㉨㉩㉪㉫㉬㉭㉮㉯㉰㉱㉲㉳㉴㉵㉶㉷㉸㉹㉺㉻㉼㉽㉾"
[6] "ꥠꥡꥢꥣꥤꥥꥦꥧꥨꥩꥪꥫꥬꥭꥮꥯꥰꥱꥲꥳꥴꥵꥶꥷꥸꥹꥺꥻꥼ"
[7] "ힰힱힲힳힴힵힶힷힸힹힺힻힼힽힾힿퟀퟁퟂퟃퟄퟅퟆ"
[8] "ퟋퟌퟍퟎퟏퟐퟑퟒퟓퟔퟕퟖퟗퟘퟙퟚퟛퟜퟝퟞퟟퟠퟡퟢퟣퟤퟥퟦퟧퟨퟩퟪퟫퟬퟭퟮퟯퟰퟱퟲퟳퟴퟵퟶퟷퟸퟹퟺퟻ"
[9] "ᅠᄀᄁᆪᄂᆬᆭᄃᄄᄅᆰᆱᆲᆳᆴᆵᄚᄆᄇᄈᄡᄉᄊᄋᄌᄍᄎᄏᄐᄑᄒ"
[10] "ᅡᅢᅣᅤᅥᅦ"
[11] "ᅧᅨᅩᅪᅫᅬ"
[12] "ᅭᅮᅯᅰᅱᅲ"
[13] "ᅳᅴᅵ"
rlang 패키지 chr_unserialise_unicode() 함수는 유니코드를 문자로 변환하여 확인할 때 유용하다.
Code
library (rlang)chr_unserialise_unicode ('<U+AC00>' )
Code
chr_unserialise_unicode ('<U+FFDC>' )