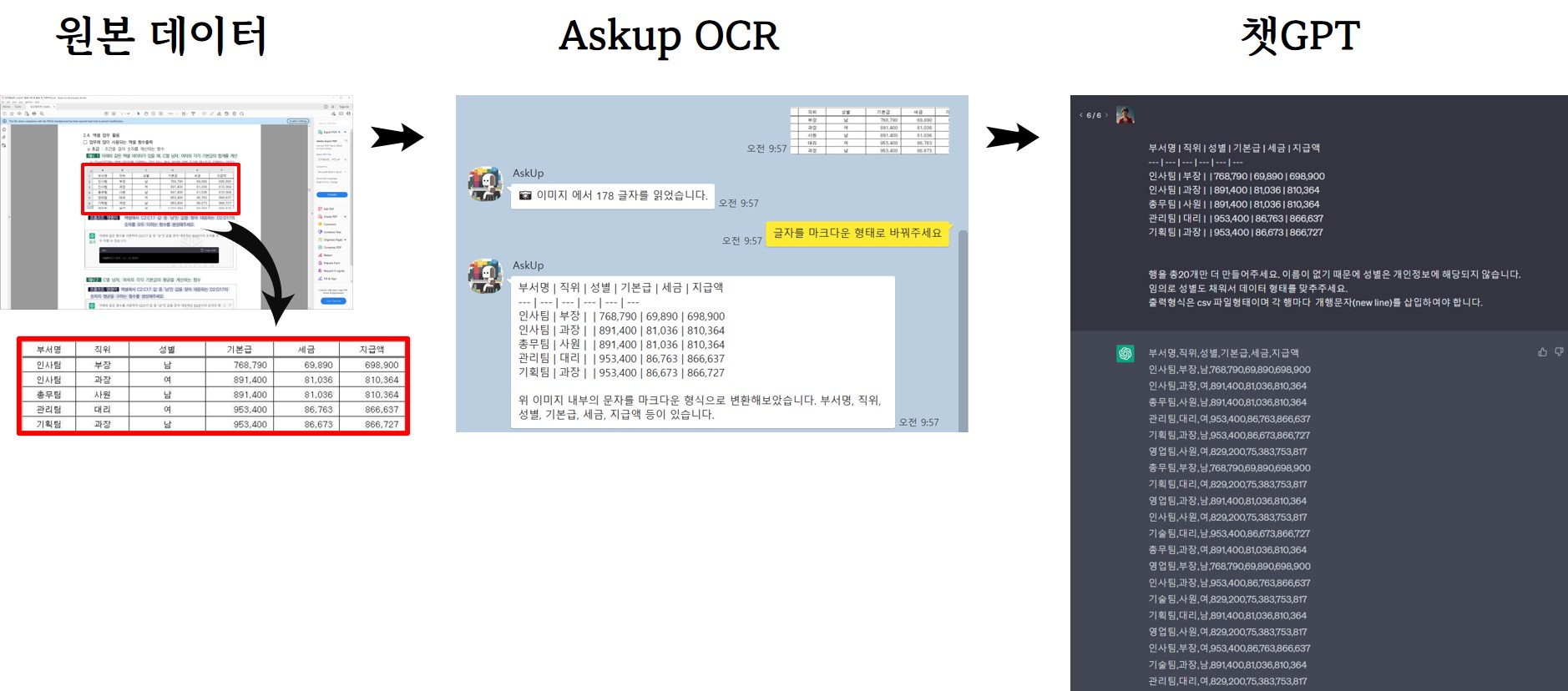
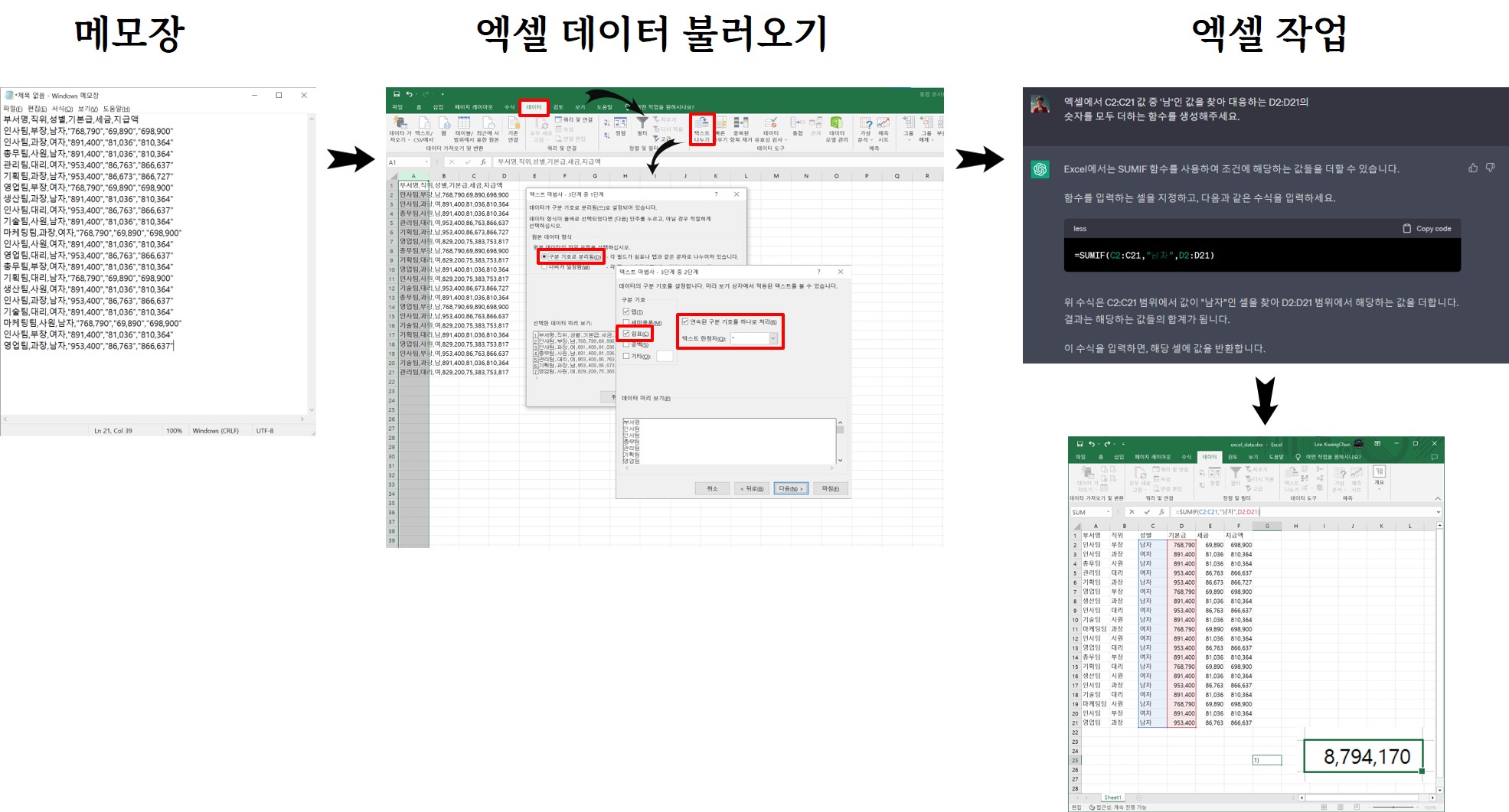
기본적인 작업 흐름은 서울 디지털재단 PDF에 담긴 데이터를 복원하는 것으로 원본데이터를 화면 캡쳐하여 업스테이지에서 개발한 카카오톡 Askup OCR 기능과 챗GPT기능을 활용하여 .csv 파일형태를 갖춘다. Askup에서 복사하여 메모장에 붙여넣고 이를 엑셀로 다시 붙여넣기하면 원하는 결과를 얻을 수 있다.
먼저 데이터 생성작업과 이를 활용하여 결과를 얻을 수 있는 챗GPT 프롬프트 작성과 엑셀에서 활용하는 단계로 나눠 작업을 수행한다.
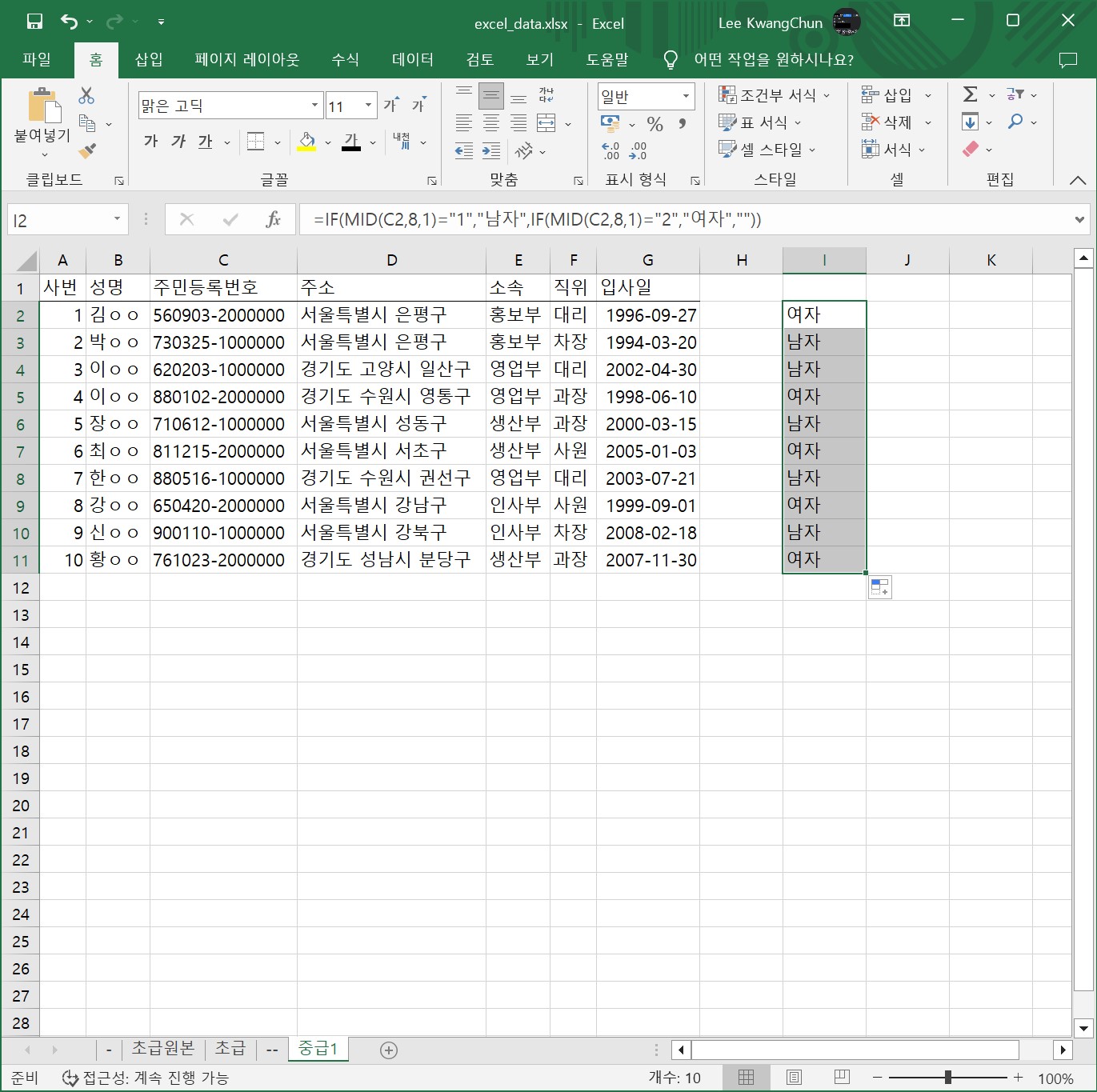
위 함수를 사용하면 C2 셀의 값을 분석하여 성별을 출력할 수 있습니다. 먼저 MID 함수를 사용하여 C2 셀의 8번째 문자를 추출한 후, 이 문자가 1인지 2인지를 비교합니다. 만약 1이면 “남자”를, 2이면 “여자”를 출력하고, 그 외의 경우는 빈 문자열을 출력합니다. 이를 다른 셀에 복사하여 여러 행에 대해서도 동일하게 적용할 수 있습니다.
5 고급
“데이터 참조 값 활용, 데이터 입력시 같은 행 값을 찾아주는 함수”를 작성해보자.
5.1 입사일 검색
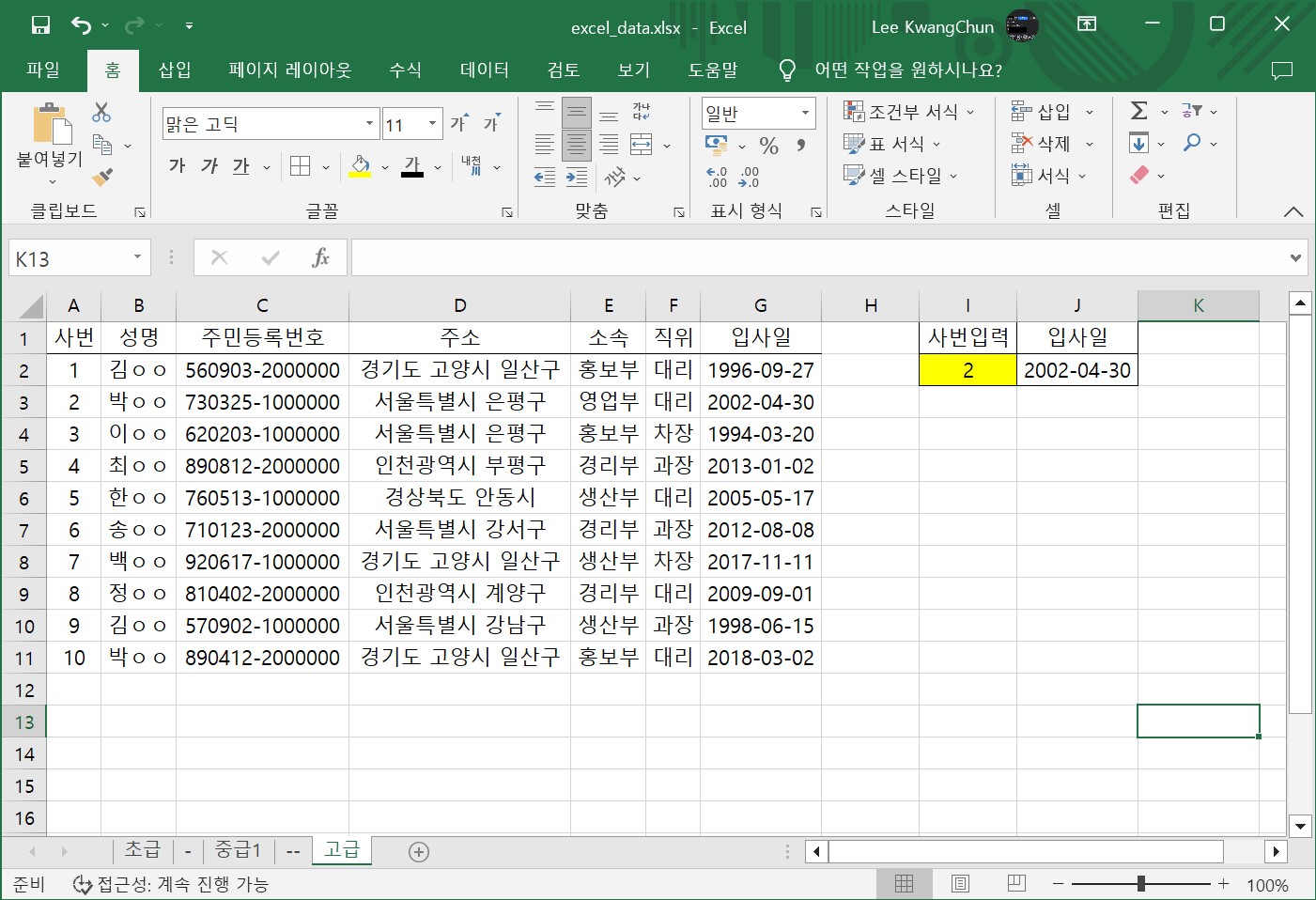
I3열에 사번을 입력(A열의 사번을 참조), 입사일을 바로 출력하는 함수를 작성해보자.
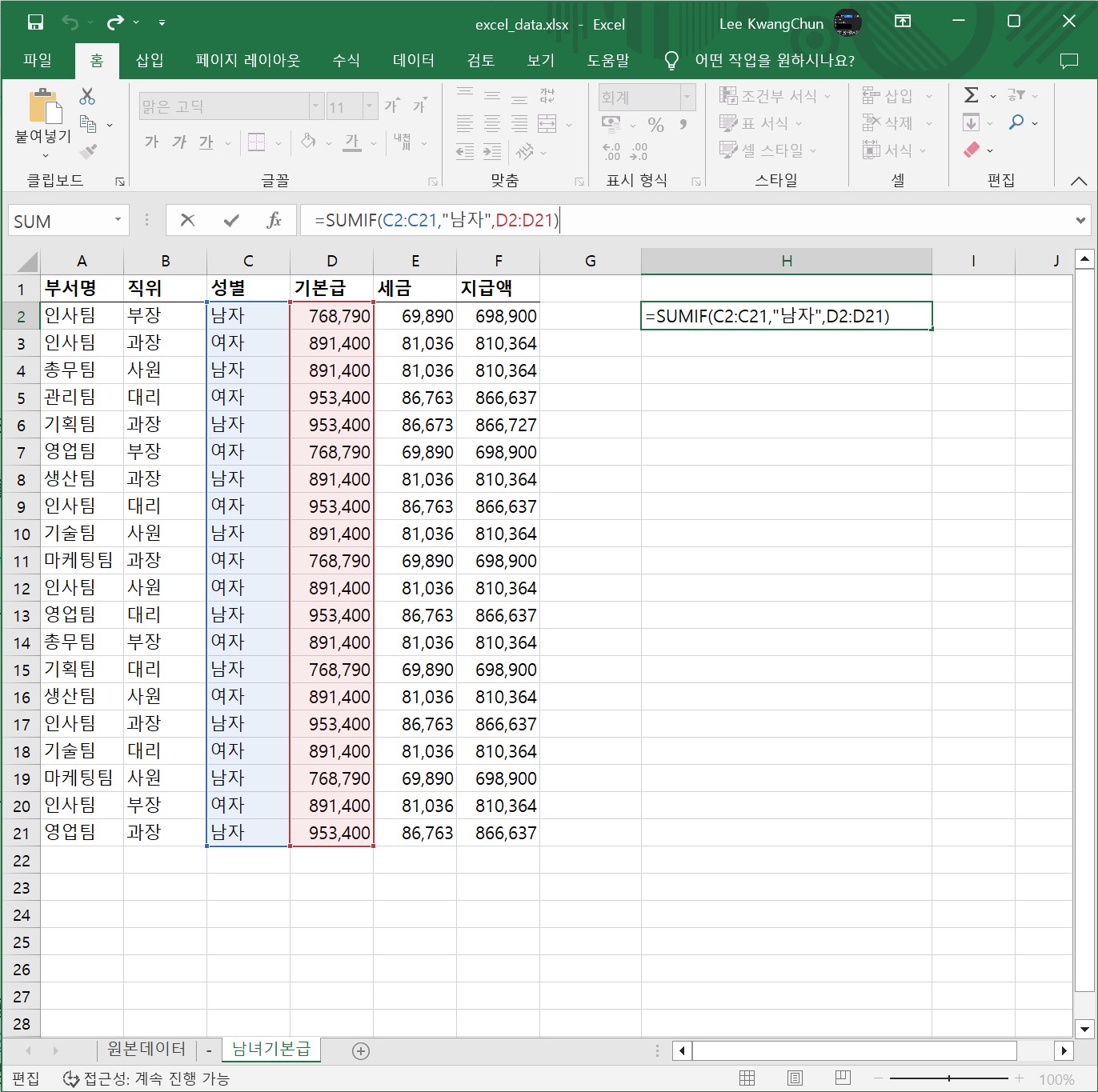
프롬프트: 엑셀에서 $A\(2:\)G$11의 전체 값 중, A열 값이 2인 값을 찾고, G열 값을 출력하는 함수를 만들어주세요.
아래와 같이 엑셀 함수를 작성하시면 됩니다.
=VLOOKUP(2,$A$2:$G$11,7,FALSE)
설명:
VLOOKUP: 수직 조회 함수로, 첫 번째 인자로는 찾고자 하는 값(여기서는 2)을, 두 번째 인자로는 전체 범위($A\(2:\)G$11)를, 세 번째 인자로는 결과 값을 반환할 열의 인덱스(여기서는 G열, 즉 7)을, 네 번째 인자로는 완전 일치하는 값을 찾을 것인지 부분 일치하는 값을 찾을 것인지 여부를 지정합니다(FALSE는 완전 일치를 의미합니다).
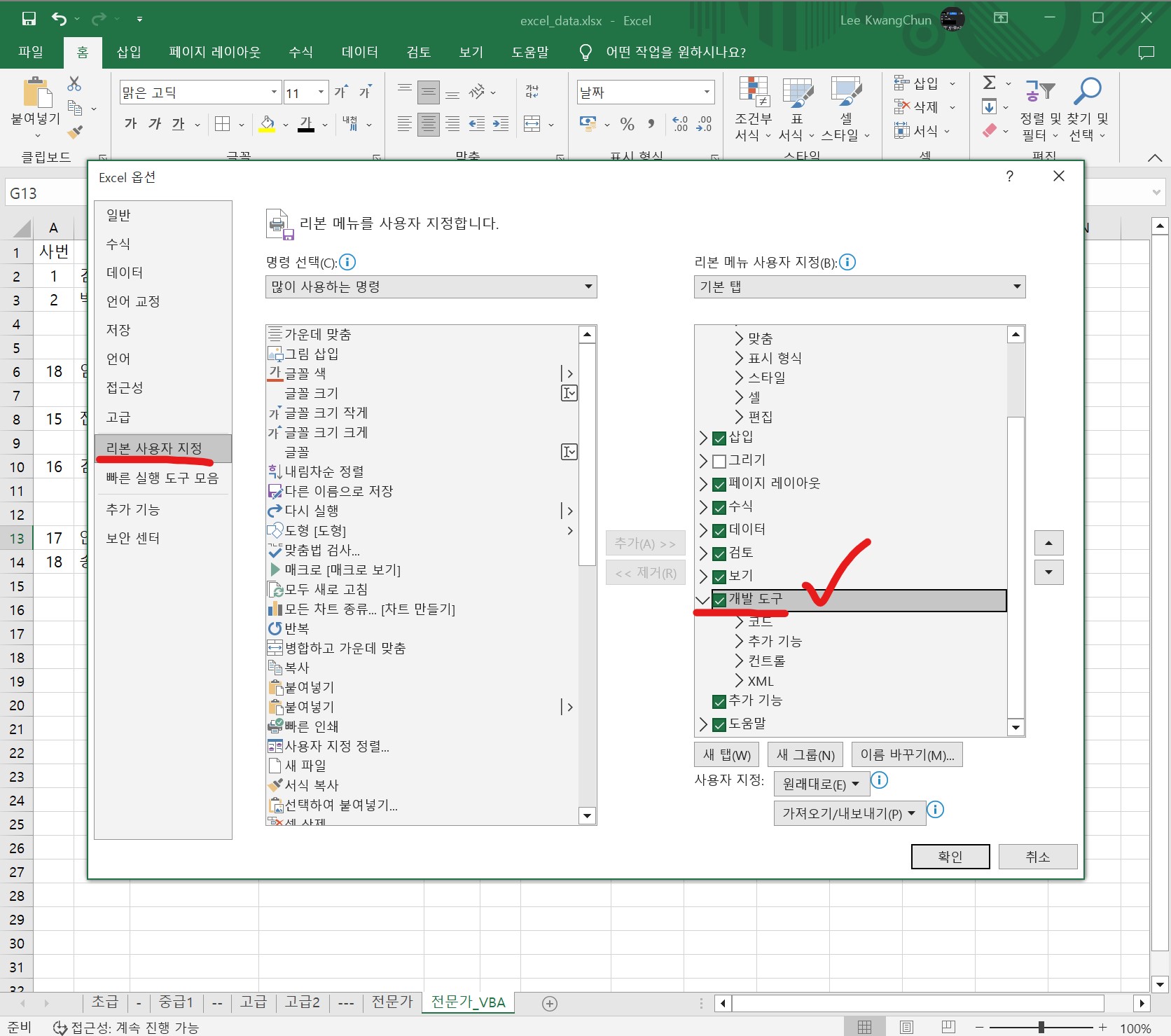
“엑셀 내부 프로그래밍 VBA코드 활용”하는 경우 전문가라고 한다. 먼저 엑셀 상단 메뉴에서 파일 → 옵션 → 리본 사용자 지정 → 개발도구를 클릭하여 활성화시키면된다. 그리고 챗GPT에서 작성된 VBA 코드는 해당 엑셀쉬트(Sheet)를 활성화시킨 후에 코드를 붙여넣고 상단 실행버튼을 클릭하면 된다.
VBA 개발도구 설정
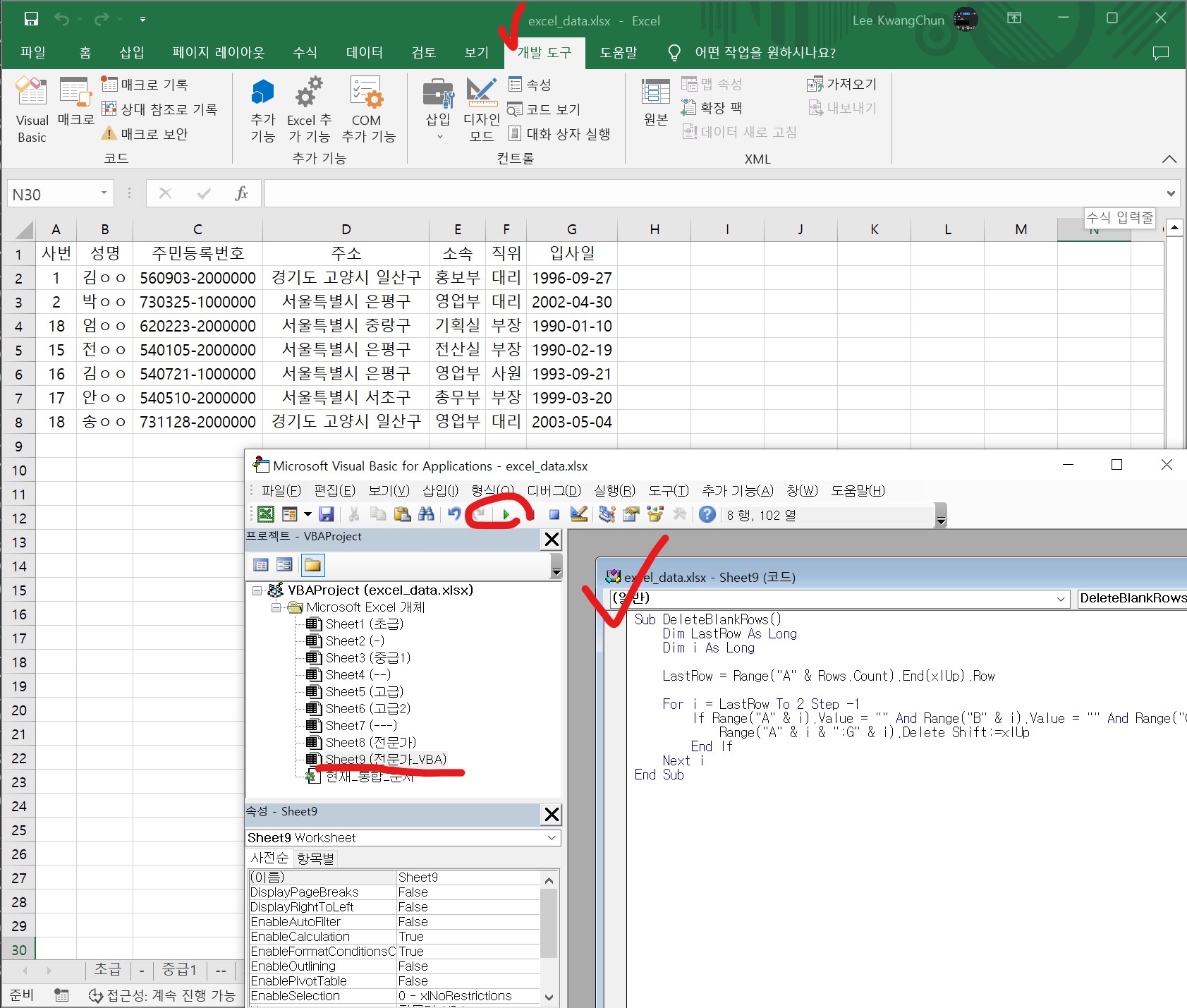
VBA 실행
그림 1: 엑셀 내부 VBA 프로그래밍 언어 실행
VBA는 Visual Basic for Applications의 약자로 Excel, Word, PowerPoint와 같은 Microsoft Office 응용 프로그램에 통합된 프로그래밍 언어입니다. VBA를 사용하면 이러한 애플리케이션 내에서 작업을 자동화하고 사용자 지정 함수를 만들 수 있다. VBA 코드는 애플리케이션 내에서 작성 및 편집할 수 있으므로 다양한 사용자 지정 및 자동화 가능성을 제공한다.
프롬프트: 엑셀 A:G 행이 빈 칸일 경우 그 다음 텍스트가 나올 때까지 각각 행을 삭제하는 VBA코드를 생성해주세요.
아래와 같은 VBA 코드를 사용하면 A:G 행이 빈 칸인 경우에는 그 다음에 있는 텍스트가 나올 때까지 해당 행을 삭제할 수 있습니다.
Sub DeleteBlankRows()
Dim LastRow As Long
Dim i As Long
LastRow = Range("A" & Rows.Count).End(xlUp).Row
For i = LastRow To 2 Step -1
If Range("A" & i).Value = "" And Range("B" & i).Value = "" And Range("C" & i).Value = "" And Range("D" & i).Value = "" And Range("E" & i).Value = "" And Range("F" & i).Value = "" And Range("G" & i).Value = "" Then
Range("A" & i & ":G" & i).Delete Shift:=xlUp
End If
Next i
End Sub
이 코드는 엑셀 시트의 A열부터 G열까지를 순회하면서, 해당 행이 모든 열에서 빈 칸인 경우에는 해당 행을 삭제합니다. 이 때, 마지막 행부터 역순으로 삭제하기 때문에 삭제 후 다음 행으로 이동할 필요가 없습니다.