코드
xfun::embed_file("data/spreadsheet.zip", text="실습파일 압축(zip) 다운로드")실습 엑셀 파일을 다운로드 받아 사전 준비한다.
xfun::embed_file("data/spreadsheet.zip", text="실습파일 압축(zip) 다운로드")정제 후에 분석한 데이터로 새 엑셀파일을 생성한다. 원본 데이터셋을 수정하지 마라! 만약 원본 데이터셋을 수정했다면 어디서 어디까지 작업되었는지 전혀 알 수가 없다. 정제작업 또는 분석에서 수행한 단계를 추적하고 기록을 남긴다.이런 작업에 Git을 사용하지 않는다면 데이터 파일과 같은 폴더에 저장된 일반 텍스트 파일에 기록을 남기는 것이 좋다. (Hoyt 기타, 2023)

스프레드시트 프로그램을 데이터에 사용할 때 가장 중요한 규칙은 데이터를 ‘깔끔하게’ 유지하는 것이다:
데이터시트를 설정할 때 “열 = 변수”, “행 = 관측값”, 셀 = 데이터(값)가 깔끔한 데이터(Tidy Data) 원칙이다.
library(tidyverse)
library(readxl)
messy_tbl <- read_excel("data/survey_data_spreadsheet_messy.xlsx", sheet="2014", range = "C32:E42")
messy_tbl %>% gt::gt()| Date collected | species_sex | wgt |
|---|---|---|
| 1978-01-08 | DM_F | 37 |
| 1978-01-08 | DS_F | 128 |
| 1978-01-08 | DM_F | 42 |
| 1978-01-08 | DM_M | 37 |
| 1978-01-08 | DM_M | NA |
| 1978-01-08 | DM_F | 48 |
| 1978-01-08 | DM_M | 45 |
| 1978-01-08 | DM_F | 42 |
| 1978-01-08 | DO_M | 52 |
| 1978-01-08 | OL_M | 35 |
messy_tbl %>%
separate(species_sex, into=c("species", "sex"), sep="_") %>%
gt::gt()| Date collected | species | sex | wgt |
|---|---|---|---|
| 1978-01-08 | DM | F | 37 |
| 1978-01-08 | DS | F | 128 |
| 1978-01-08 | DM | F | 42 |
| 1978-01-08 | DM | M | 37 |
| 1978-01-08 | DM | M | NA |
| 1978-01-08 | DM | F | 48 |
| 1978-01-08 | DM | M | 45 |
| 1978-01-08 | DM | F | 42 |
| 1978-01-08 | DO | M | 52 |
| 1978-01-08 | OL | M | 35 |
하나의 스프레드시트 안에 여러 개의 데이터 테이블을 만드는 것이 일견 데이터를 다루는 훌륭한 전략처럼 보인다. 이는 컴퓨터를 혼란스럽게 하므로 절대 다음과 같이 하지 않는다! 하나의 스프레드시트 내에 여러 개의 테이블을 만들면 컴퓨터가 각 행을 하나의 관측값으로 인식하여 사물 간에 잘못된 연결관계를 맺게된다. 또한 여러 곳에서 동일한 필드명을 사용할 가능성이 있으므로 데이터를 사용 가능한 형태로 정리하기가 더 어려워진다.
이유가 무엇이든 누락된 데이터는 문제다. 명확하게 정의되고 일관된 결측값(Null) 표시기를 사용하는 것이 중요하다. 공백(대부분의 응용 프로그램) 및 NA(R의 경우)가 좋은 선택이 된다.
| 결측값 | 문제 | 호환성 | 추천 |
|---|---|---|---|
| 0 | 진정한 0와 구분이 안 됨 | 사용하지 마세요 | |
| 빈칸 | 입력 누락과 무시된 값을 구별하기 어려움. 빈칸과 공백을 구별하기 어려움, 이들은 다르게 동작함 | R, 파이썬, SQL | 최선의 선택 |
| -999, 999 | 사용자 입력 없이 많은 프로그램에서 널로 인식되지 않음. 계산에 실수로 포함될 수 있음 | 피하세요 | |
| NA, na | 줄임말일 수도 있음 (예: 북아메리카), 데이터 타입에 문제를 일으킬 수 있음 (숫자 열을 텍스트 열로 바꿀 수 있음). NA가 na보다 결측값으로 인식됨 | R | 좋은 선택 |
| N/A | NA의 다른 형태, 그러나 대부분의 소프트웨어와 호환되지 않음 | 피하세요 | |
| NULL | 데이터 타입에 문제를 일으킬 수 있음 | 피하세요 | |
| None | 흔하지 않음. 데이터 타입에 문제를 일으킬 수 있음 | 파이썬 | 피하세요 |
| 데이터 없음 | 흔하지 않음. 데이터 타입에 문제를 일으킬 수 있음, 공백을 포함함 | 피하세요 | |
| 누락 | 흔하지 않음. 데이터 타입에 문제를 일으킬 수 있음 | 피하세요 | |
| -,+,. | 흔하지 않음. 데이터 타입에 문제를 일으킬 수 있음 | 피하세요 |
서식을 사용하여 정보를 전달하는 것은 피해야한다.


설명적인 필드 이름을 선택하되 공백, 숫자 또는 특수 문자가 포함되지 않도록 주의한다. 공백은 구분 기호로 공백을 사용하는 구문 분석기가 잘못 해석할 수 있으며 일부 프로그램은 숫자로 시작하는 텍스트 문자열인 필드 이름을 사용할 경우 오류가 발생된다.
밑줄(_)은 공백을 대체할 수 있는 좋은 방법이다. 가독성을 높이려면 이름을 낙타 대소문자(예: ExampleFileName)로 작성하는 것이 좋다. 지금은 의미가 있는 약어가 6개월 후에는 의미가 없을 수도 있지만, 지나치게 긴 이름을 과도하게 사용하지 않는다. 필드 이름에 단위를 포함하면 혼동을 피할 수 있고 다른 사람들이 필드를 쉽게 해석할 수 있게 도움이 된다.
| 권장 변수명 | 대안 변수명 | 피할 변수명 |
|---|---|---|
| Max_temp_C | MaxTemp | Maximum Temp (°C) |
| Precipitation_mm | Precipitation | precmm |
| Mean_year_growth | MeanYearGrowth | Mean growth/year |
| sex | sex | M/F |
| weight | weight | w. |
| cell_type | CellType | Cell Type |
| Observation_01 | first_observation | 1st Obs |
스프레드시트의 날짜는 문제가 될 수 있다. 우선, 날짜는 단일 열에 저장된다. 이는 날짜를 기록하는 가장 자연스러운 방법처럼 보이지만 실제로는 최선의 방법은 아니다. 스프레드시트 애플리케이션은 겉으로 보기에는 올바른 방식으로 날짜를 표시하지만 실제로 날짜를 처리하고 저장하는 방식은 문제가 될 수 있다.
특히, 특정 스프레드시트 프로그램(LibreOffice Calc, Microsoft Excel, OpenOffice, Gnumeric 등)에 유효한 날짜 함수는 일반적으로 동일한 제품군 내에서만 호환이 보장된다는 점을 기억한다. Mac 또는 Windows에서 실행되는 Microsoft Excel에서 스프레드시트 파일 대부분이 제작된다. 스프레드시트에 관계없이 나중에 데이터를 내보내야 하고 시간정보(타임스탬프)를 보존해야 하는 경우 다른 방식으로 작업하는 것이 필요하다.
Excel의 큰 문제 중 하나는 날짜가 아닌 것을 날짜로 바꾸는 기능이 꼽힌다. 예를 들어, 유전자/단백질 이름이나 MAR1, DEC1, OCT4와 같은 식별자가 날짜로 변경되면 (수동으로 변경하는 경우를 제외하고) 원래 이름이나 식별자를 되돌릴 수 없다.
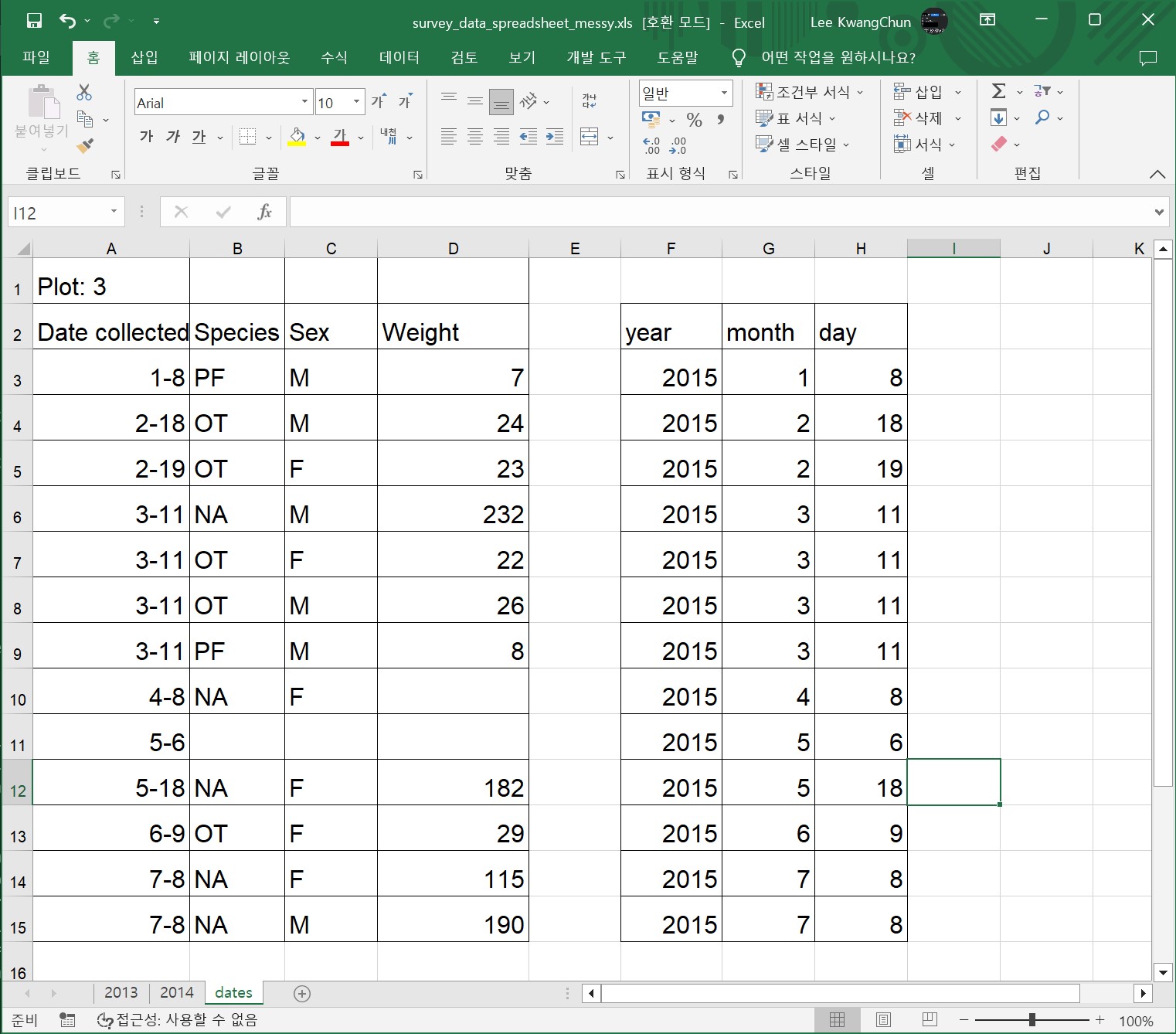
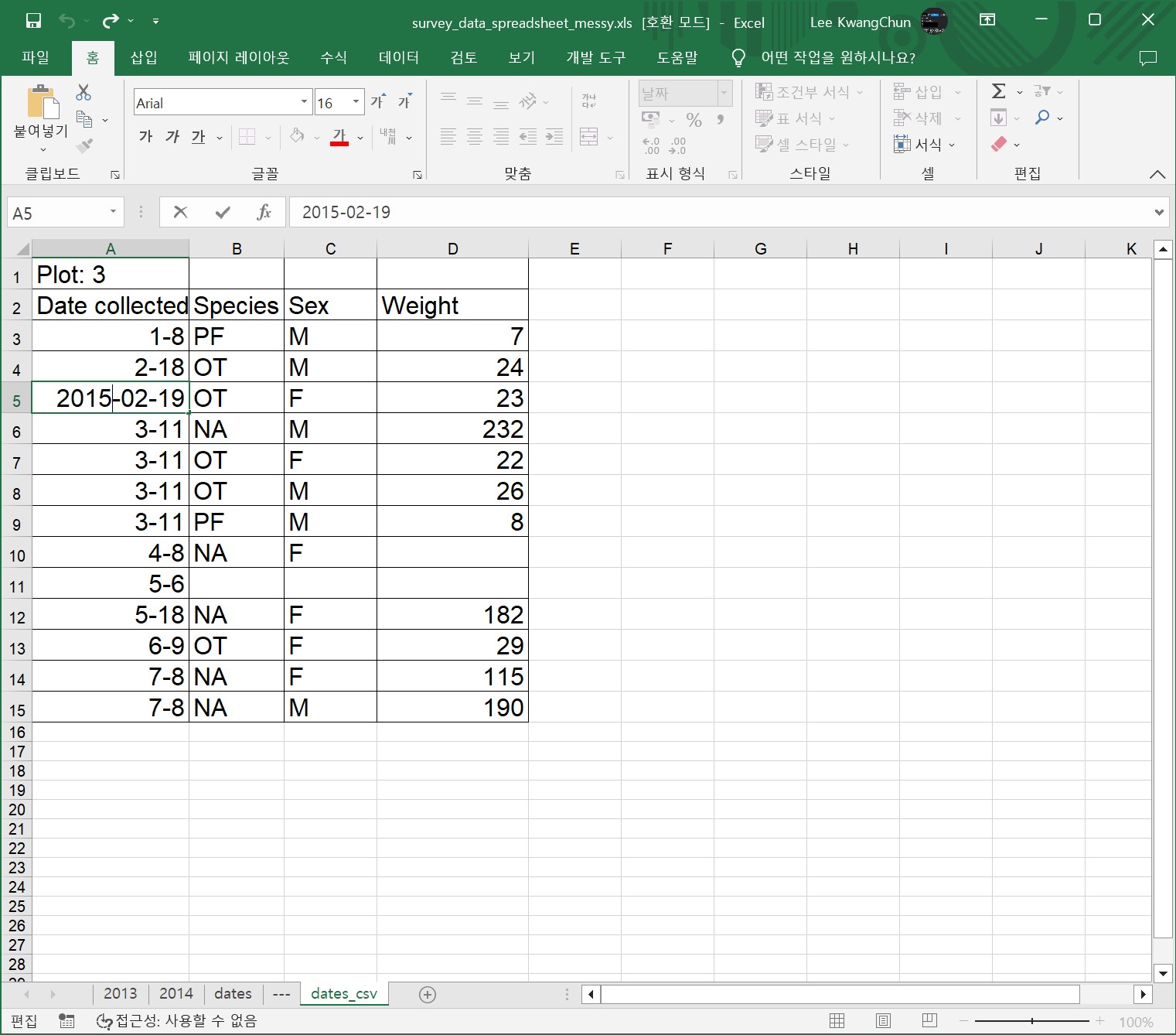

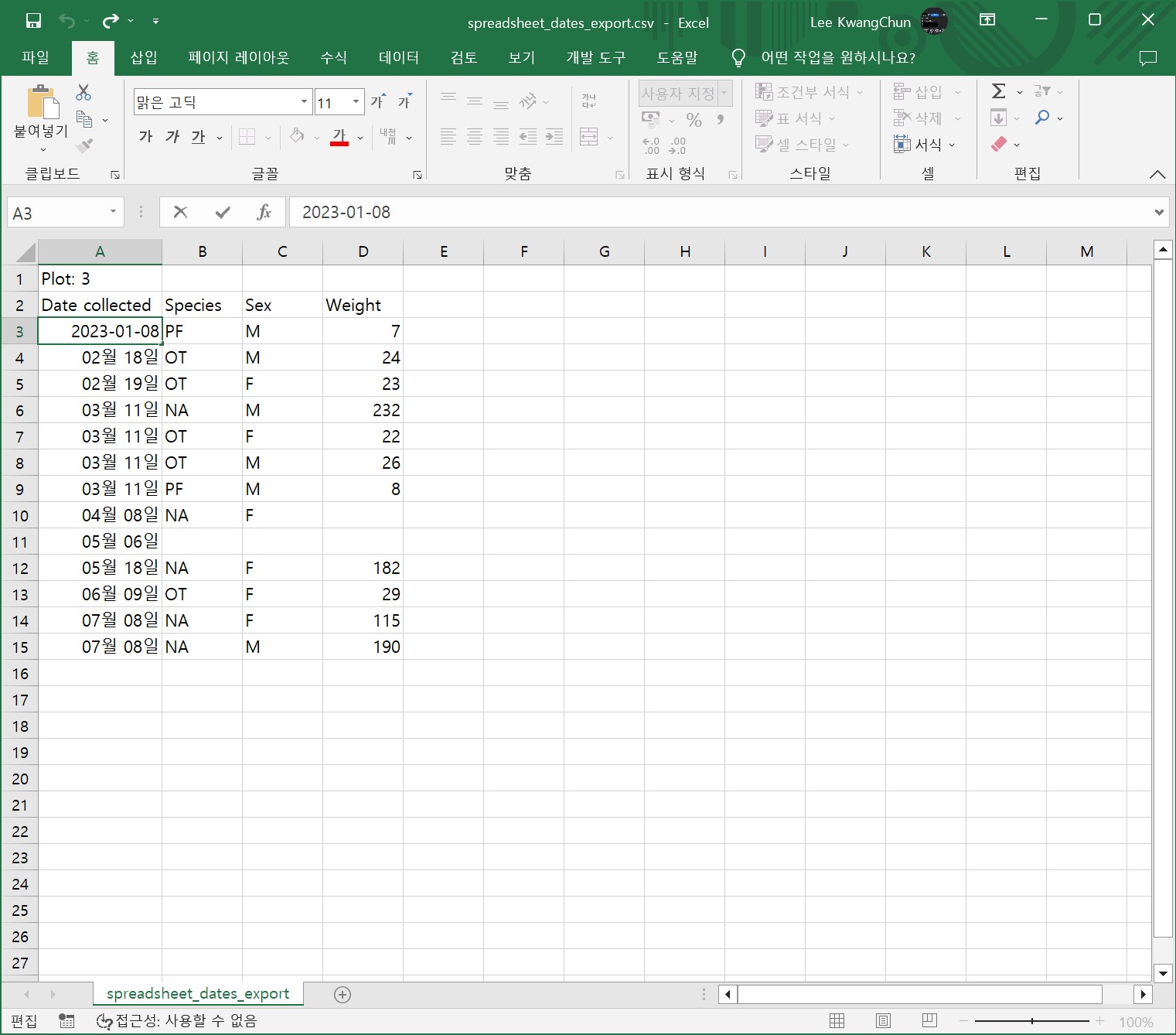
Excel은 1899년 12월 31일 이전의 날짜를 구문 분석할 수 없으므로 이러한 날짜는 그대로 유지된다. 이 날짜 이전과 이후의 과거 데이터를 혼합하는 경우 Excel은 1900년 이후의 날짜만 내부 형식으로 변환하므로 데이터가 혼합된다. 과거 데이터로 작업하는 경우 날짜에 각별한 주의가 요망된다.
1900년 날짜 시스템에서 지원되는 첫 번째 날짜는 1900년 1월 1일이다. 날짜를 입력하면 날짜는 1900년 1월 1일의 경우 1로 시작하는 경과 일수를 나타내는 일련 번호로 변환된다. 예를 들어 1998년 7월 5일을 입력하면 Excel은 날짜를 일련 번호 35981로 변환된다.
기본적으로 Windows용 Microsoft Excel은 1900년 날짜 시스템을 사용한다. 1900년 날짜 시스템을 사용하면 Excel과 MS-DOS 또는 Microsoft Windows에서 실행되도록 설계된 Lotus 1-2-3과 같은 다른 스프레드시트 프로그램 간의 호환성을 향상시킬 수 있다.
1904년 날짜 시스템에서 지원되는 첫 번째 날짜는 1904년 1월 1일이다. 날짜를 입력하면 1904년 1월 1일의 경우 0부터 시작하여 1904년 1월 1일 이후 경과한 일수를 나타내는 일련 번호로 변환된다. 예를 들어 1998년 7월 5일을 입력하면 Excel은 날짜를 일련 번호 34519로 변환된다.
초기 매킨토시 컴퓨터의 설계로 인해 1904년 1월 1일 이전의 날짜는 지원되지 않는다. 이 설계는 1900년이 윤년이 아니라는 사실과 관련된 문제를 방지하기 위한 것이었다. 과거에 Macintosh용 Excel은 기본적으로 1904년 통합 문서에 1904년 날짜 시스템을 사용하도록 설정되어 있었다. 하지만 이제 Macintosh용 Excel은 기본적으로 1900년 날짜 시스템을 사용하며 1900년 1월 1일부터 날짜를 지원한다.
분석에 사용할 데이터를 Excel 기본 파일 형식(.xls 또는 .xlsx - Excel 버전에 따라 다름)으로 저장하는 것은 좋은 생각이 아니다. 왜 그럴까?
엑셀 파일형식은 독점적인 형식이며, 향후에는 파일을 여는 것이 불가능하지는 않더라도 불편할 정도로 기술이 발전하지 않거나 제조사 마이크로소프트 경영상태에 따라 현재와 같은 지위가 위협받을 수 있다.
다른 스프레드시트 소프트웨어에서는 독점적인 Excel 형식으로 저장된 파일을 열지 못할 수도 있다.
Excel 버전에 따라 데이터를 처리하는 방식이 달라서 데이터가 일관되지 않을 수 있다.
마지막으로, 점점 더 많은 저널과 보조금 지급단체에서 데이터 저장소에 데이터 보관을 의무적으로 요구하고 있으며, 기관 대부분이 Excel 형식을 허용하지 않는다.
위의 사항은 LibreOffice/오픈 오피스에서 사용하는 오픈 데이터 형식과 같은 다른 파일형식에도 공통적으로 적용된다.
Excel/SPSS 등 파일에 비해 CSV 파일의 장점은 텍스트 편집기나 메모장 같은 일반 텍스트 편집기를 포함한 거의 모든 소프트웨어를 사용해 CSV 파일을 열고 읽을 수 있다는 점이다. 또한 CSV 파일의 데이터는 SQLite나 R/파이썬과 같은 다른 형식과 환경으로 쉽게 가져올 수 있다. CSV 파일로 작업할 때 특정 고가의 프로그램 버전에 얽매이지 않으므로 휴대성과 내구성을 극대화하기 위해 작업하기에 좋은 파일형식이다.
Excel에서 열어본 파일을 CSV 형식으로 저장하는 방식은 다음과 같다:

기본적으로 대부분의 코딩 및 통계 환경에서는 줄 바꿈을 나타내는 줄 바꿈으로 UNIX 스타일 줄 바꿈(ASCII LF 문자)이 사용된다. 하지만, Windows에서는 텔레타이프 기반 시스템과의 레거시 호환성을 위해 기본적으로 대체 줄 끝 기호(ASCII CR LF 문자)가 사용된다.
따라서 Excel을 사용하여 CSV로 내보낼 때 텍스트 형식의 데이터는 다음과 같이 표시된다.
data1,data2
1,2 4,5
Excel에서 CSV 파일을 다시 열면 다음과 같이 파싱된다:

그러나 CR 문자를 구문 분석하지 않는 다른 시스템에서 CSV 파일을 열면 CSV 파일이 다르게 해석된다:
그러면 텍스트 형식의 데이터는 다음과 같이 표시됩니다:
data1
data2
1
2
…
그러면 이상한 문자 또는 CR 또는 \r 문자열이 표시될 수 있다:

따라서 데이터에 끔찍한 일이 발생할 수 있다. 예를 들어, 2\r은 유효한 정수가 아니므로 R 또는 Python에서 연산을 시도할 때 (운이 좋으면) 오류가 발생된다. 이는 레거시 Windows 호환성 때문에 Windows뿐만 아니라 OSX용 Excel에서도 발생된다.
CSV 파일에 균일한 UNIX 스타일의 줄 끝을 적용하는 몇 가지 솔루션이 있다:
.git/config 파일을 편집하여 \r\n 줄 끝을 \n으로 자동 변환합니다. 파일에 다음을 추가합니다(자세한 튜토리얼 참조):[filter "cr"]
clean = LC_CTYPE=C awk '{printf(\"%s\\n\", $0)}' | LC_CTYPE=C tr '\\r' '\\n'
smudge = tr '\\n' '\\r'` 그런 다음 해당 줄이 포함된 파일 .gitattributes를 반영한다:
*.csv filter=cr품질 보증은 데이터를 입력하는 동안 값이 유효한지 확인하여 잘못된 데이터가 입력되는 것을 방지한다. 예를 들어, 사이트 A, B, C에서 연구가 수행되는 경우 키보드에서 B 바로 옆에 있는 값 V는 절대 입력해서는 안 된다. 마찬가지로 수집되는 데이터의 종류 중 하나를 세는 경우 0보다 크거나 같은 정수만 허용되어야 한다.
스프레드시트에 입력되는 데이터의 종류를 제어하기 위해 데이터 유효성 검사(Data Validation, Excel) 또는 유효성 검사(Validity, Libre Office Calc)를 사용하여 각 데이터 열에 입력할 수 있는 값을 설정한다.
유효성을 검사할 셀 또는 열을 선택합니다.
데이터(Data) 탭에서 데이터 유효성 검사(Data Validation)를 선택합니다.

허용(Allow) 상자에서 열에 포함할 데이터의 종류를 선택. 옵션에는 정수, 소수, 항목 목록, 날짜 및 기타 값이 포함된다.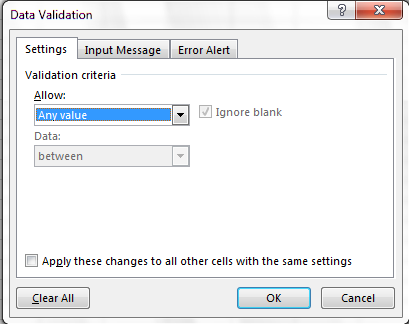
품질 보증을 사용하면 데이터 입력이 더 쉬워질 뿐만 아니라 더 강력해질 수 있다. 예를 들어, 옵션 목록을 사용하여 데이터 입력을 제한하는 경우 스프레드시트에 사용 가능한 항목의 드롭다운 목록이 제공된다.

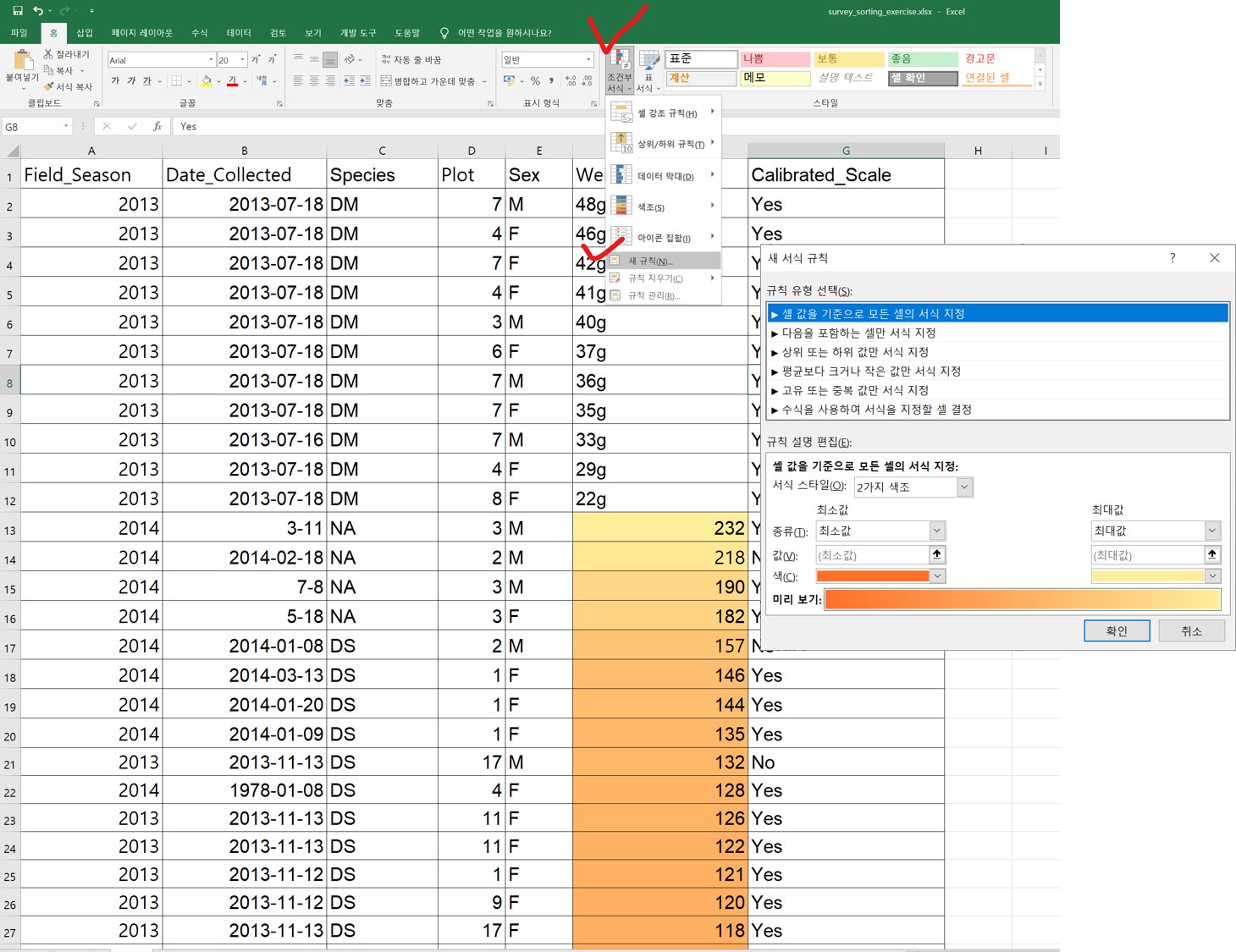
잘못된 값은 종종 열의 아래쪽이나 위쪽으로 정렬된다. 예를 들어, 데이터가 숫자여야 하는 경우 알파벳순 데이터와 null 데이터가 정렬된 데이터의 끝에 그룹화된다. 각 필드별로 데이터를 한 번에 하나씩 정렬한다. 각 열을 스캔하되, 열의 위쪽과 아래쪽에 가장 많은 주의를 기울여 점검한다. 데이터셋이 잘 구조화되어 있고 수식이 포함되어 있지 않은 경우, 정렬이 데이터셋의 무결성에 영향을 미치지 않는다.
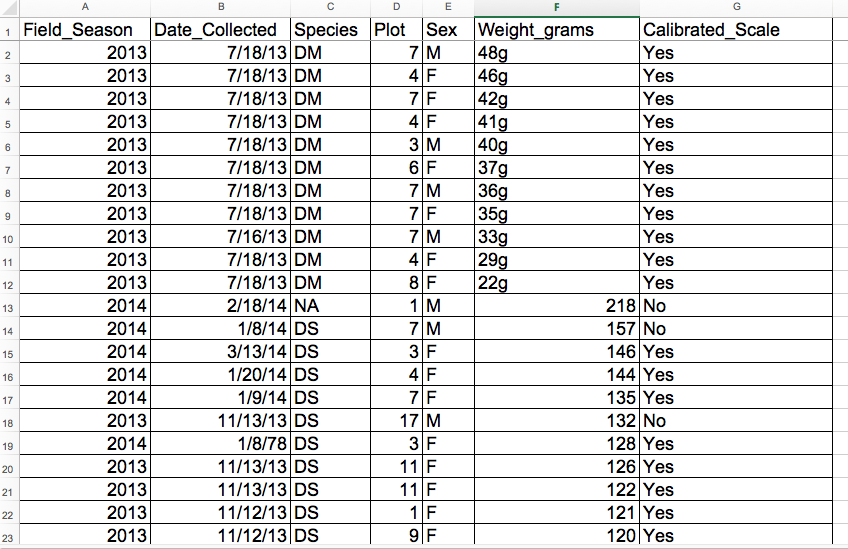
“조건부 서식”은 기본적으로 특정 기준 또는 최저값에서 최고값으로 값을 색상 코딩하는 것과 같은 작업을 수행할 수 있습니다. 이렇게 하면 데이터에서 이상값을 쉽게 검색할 수 있다.
조건부 서식은 신중하게 사용해야 하지만, 데이터를 입력할 때 일관되지 않은 값에 플래그를 지정하는 좋은 방법이 될 수 있습니다.