수능이란?
수능은 대한민국에서 실시하는 대학입학 자격시험으로 국어, 수학, 영어, 한국사, 사회탐구, 과학탐구 총 6개 과목으로 구성되어 있다. 수능은 대한민국의 모든 고등학교 졸업생과 검정고시 합격자가 응시할 수 있다. 수능은 대학 입학 전형에 있어 가장 중요한 요소 중 하나로, 수능 성적은 대학 입학 정원의 50% 이상을 차지하는 경우가 많다.
한국교육과정평가원에서 밝히 대한수학능력시험의 성격과 목적은 다음과 같다.
대학 교육에 필요한 수학 능력 측정으로 선발의 공정성과 객관성 확보
고등학교 교육과정의 내용과 수준에 맞는 출제로 고등학교 학교교육의 정상화 기여
개별 교과의 특성을 바탕으로 신뢰도와 타당도를 갖춘 시험으로서 공정성과 객관성 높은 대입 전형자료 제공
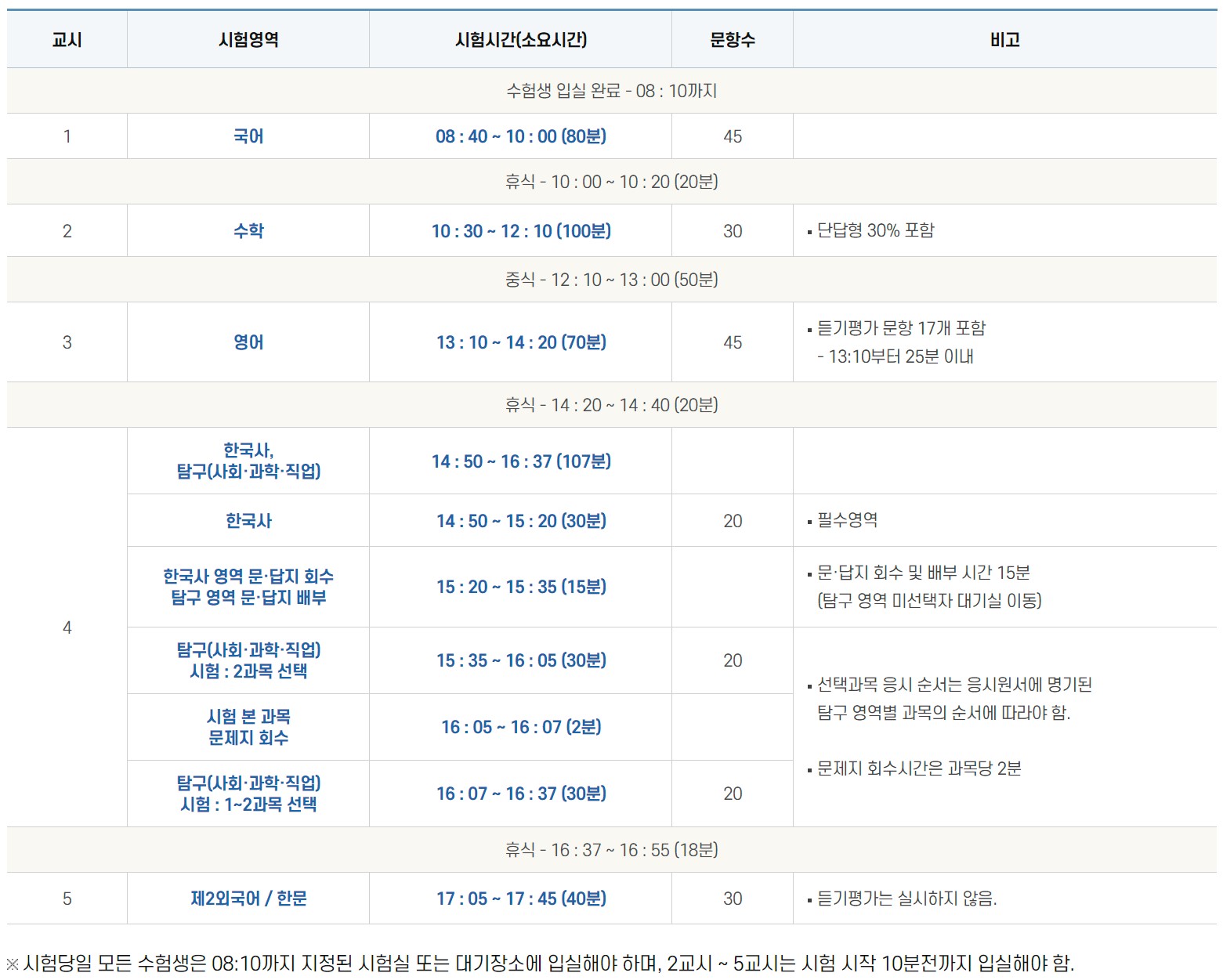
’23년 일정
대한수학능력시험 주요업무추진 일정은 다음과 같다.
Code
library (datapasta)library (tidyverse)library (gtExtras)library (gt)<- tibble:: tribble (~ "주요.업무" , ~ "추진일정" , ~ "비고" ,"시행기본계획 발표" , "3.28.(화)" , NA ,"시행세부계획 공고" , "7.3.(월)" , "중앙 일간지" ,"원서 교부, 접수 및 변경" , "8.24.(목) ~ 9.8.(금)" , "토요일 및 공휴일 제외" ,"시험 실시" , "11.16.(목)" , NA ,"문제 및 정답 이의신청" , "11.16.(목) ~ 11.20.(월)" , "5일간" ,"정답 확정" , "11.28.(화)" , NA ,"채점" , "11.17.(금) ~ 12.8.(금)" , "22일간" ,"성적 통지" , "12.8.(금)" , NA <- schedule_raw %>% :: clean_names (ascii= FALSE ) %>% separate (추진일정, into = c ("시작일" , "완료일" ), sep = "~" ) %>% mutate (시작일 = sub (" \\ (.* \\ )" , "" , 시작일),= sub (" \\ (.* \\ )" , "" , 완료일)) %>% mutate (시작일 = glue:: glue ("2023.{시작일}" ) %>% as.character (.) %>% as.Date (format = "%Y.%m.%d" ),= glue:: glue ("2023.{완료일}" ) %>% as.character (.) %>% as.Date (format = "%Y.%m.%d" ))%>% :: gt () %>% gt_theme_nytimes () %>% cols_align (align = "center" , columns = everything ()) %>% fmt_missing (columns = everything (),missing_text = "-" # replace NA with "-"
주요_업무
시작일
완료일
비고
시행기본계획 발표
2023-03-28
-
- 시행세부계획 공고
2023-07-03
-
중앙 일간지 원서 교부, 접수 및 변경
2023-08-24
2023-09-08
토요일 및 공휴일 제외 시험 실시
2023-11-16
-
- 문제 및 정답 이의신청
2023-11-16
2023-11-20
5일간 정답 확정
2023-11-28
-
- 채점
2023-11-17
2023-12-08
22일간 성적 통지
2023-12-08
-
-
Code
library (vistime)library (timevis)<- schedule %>% mutate (id = row_number ()) %>% mutate (group = c ("시행계획" , "시행계획" , "원서교부" , "시험" , rep ("채점 성적통지" , 4 )) ) %>% set_names (c ("content" , "start" , "end" , "remark" , "id" , "group" ))<- schedule_tv %>% select (id = group, content = group) %>% distinct ()timevis (data = schedule_tv, groups = schedule_grp)
수능통계
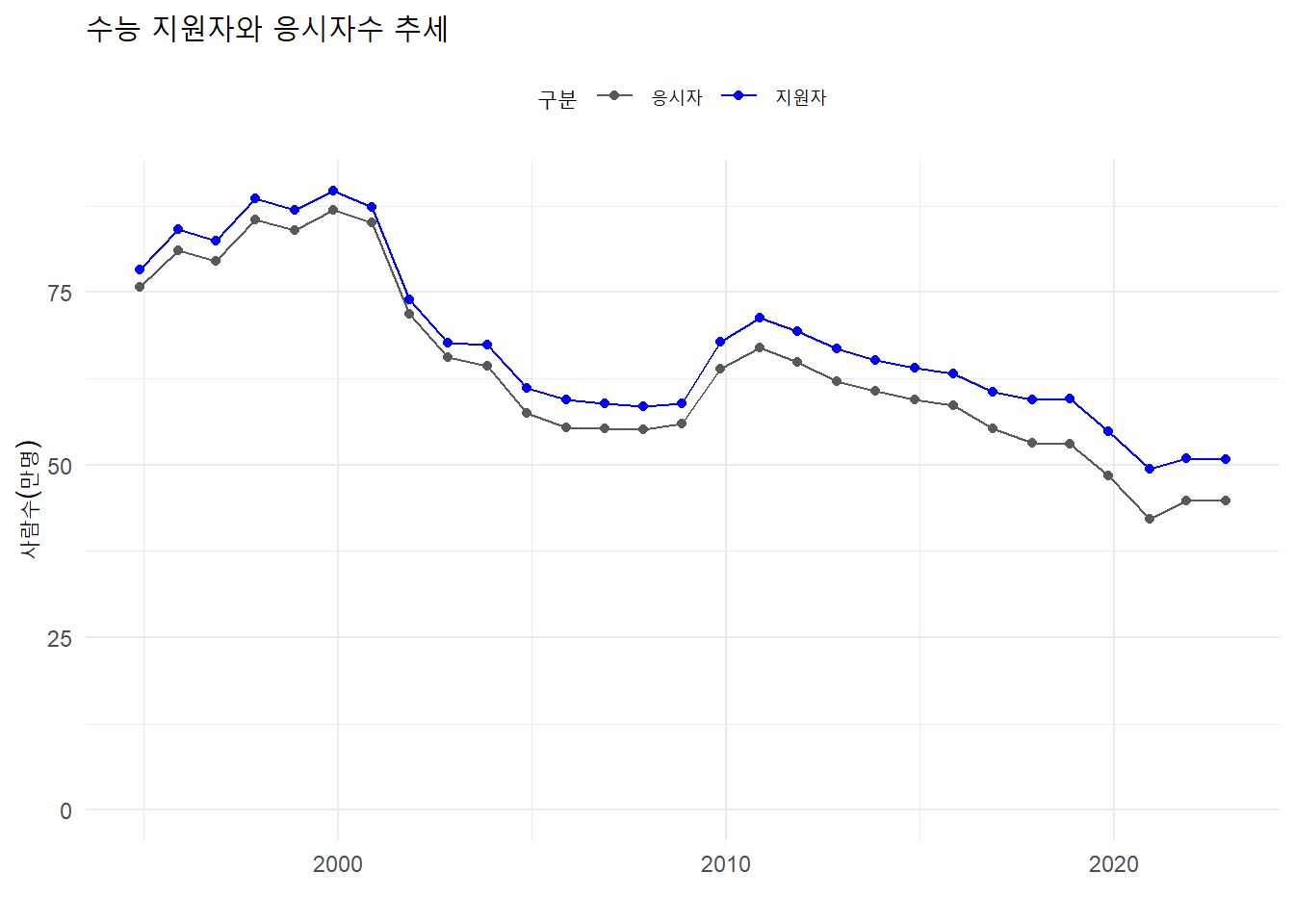
연도별 응시현황
응시자가 2000년 전후 정점을 찍은 이후 수능지원자와 응시자수가 꾸준히 줄고 있으며 응시자와 지원자수 사이 간극이 커지고 있다.
Code
# !pip install tabula-py import pandas as pdimport tabulafile = "data/suneung/수능 연도별 응시현황 (2022.12.게시).pdf" = tabula.read_pdf(file , pages= 'all' )= taker[0 ]
Code
library (reticulate)<- py$ taker_pd %>% as_tibble ()<- taker_raw %>% :: clean_names (ascii = FALSE ) %>% slice (3 : n ()) %>% select (- 비고, - unnamed_0) %>% set_names (c ("학년도" , "시험일" , "지원자" , "응시자" , "응시율" )) %>% mutate (시험일 = lubridate:: ymd (시험일)) %>% pivot_longer (cols = 지원자: 응시자, names_to = "구분" , values_to = "사람수" ) %>% mutate (사람수 = parse_number (사람수)) %>% select (시험일, 구분, 사람수)%>% pivot_wider (names_from = 구분, values_from = 사람수) %>% arrange (desc (시험일)) %>% mutate (응시율 = 응시자 / 지원자) %>% :: gt () %>% gt_theme_nytimes () %>% cols_align (align = "center" , columns = everything ()) %>% fmt_missing (columns = everything (),missing_text = "-" # replace NA with "-" %>% fmt_integer ( columns = c (지원자, 응시자)) %>% fmt_percent (응시율, decimals = 1 ) %>% tab_header (title = md ("수능 지원자, 응시자, 응시율표" ),subtitle = md ("1994년 제외" )
수능 지원자, 응시자, 응시율표
1994년 제외
시험일
지원자
응시자
응시율
2022-11-17
508,030
447,669
88.1% 2021-11-18
509,821
448,138
87.9% 2020-12-03
493,434
421,034
85.3% 2019-11-14
548,734
484,737
88.3% 2018-11-15
594,924
530,220
89.1% 2017-11-23
593,527
531,327
89.5% 2016-11-17
605,987
552,297
91.1% 2015-11-12
631,187
585,332
92.7% 2014-11-13
640,621
594,835
92.9% 2013-11-07
650,747
606,813
93.2% 2012-11-08
668,522
621,336
92.9% 2011-11-10
693,631
648,946
93.6% 2010-11-18
712,227
668,991
93.9% 2009-11-12
677,834
638,216
94.2% 2008-11-13
588,839
559,475
95.0% 2007-11-15
584,934
550,588
94.1% 2006-11-16
588,899
551,884
93.7% 2005-11-23
593,806
554,345
93.4% 2004-11-17
610,257
574,218
94.1% 2003-11-05
674,154
642,583
95.3% 2002-11-06
675,922
655,384
97.0% 2001-11-07
739,129
718,441
97.2% 2000-11-15
872,297
850,305
97.5% 1999-11-17
896,122
868,366
96.9% 1998-11-18
868,643
839,837
96.7% 1997-11-19
885,321
854,272
96.5% 1996-11-13
824,374
795,338
96.5% 1995-11-22
840,661
809,867
96.3% 1994-11-23
781,749
757,509
96.9%
Code
%>% mutate ( 사람수 = 사람수 / 10 ^ 4 ) %>% ggplot (aes (x = 시험일, y = 사람수, color = 구분)) + geom_line () + geom_point () + labs (title = "수능 지원자와 응시자수 추세" ,x = "" ,y = "사람수(만명)" ) + theme (legend.position = "top" ) + scale_color_manual (values = c ("gray35" , "blue" )) + expand_limits (y = 0 )
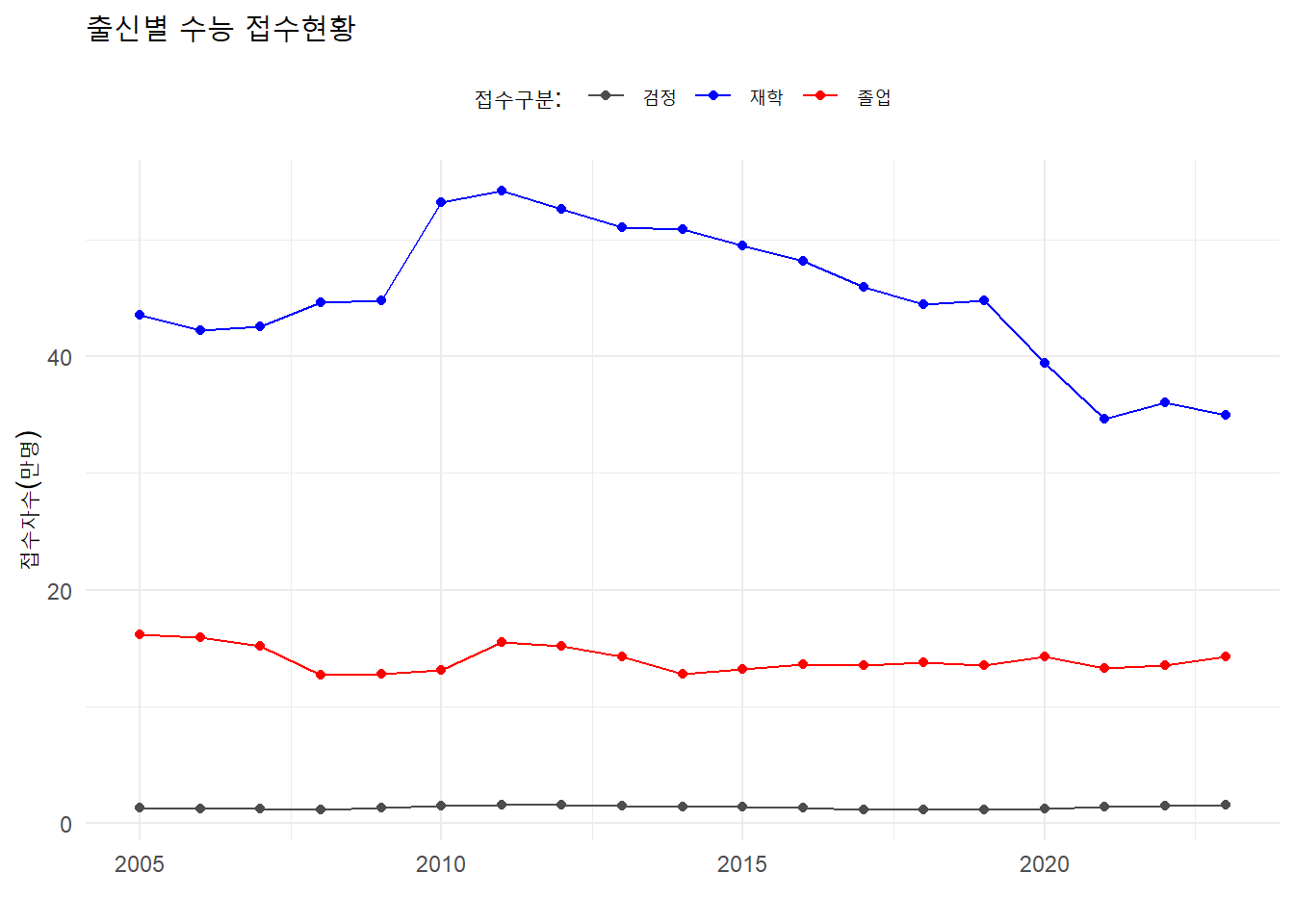
수능 접수현황
Code
import pandas as pdimport tabula= "data/suneung/수능 연도별 접수현황 (2022.12.게시).pdf" = tabula.read_pdf(application_file, pages= 'all' )= application[0 ]= application[1 ]
Code
## 1 페이지 <- py$ applicatin_1_pd %>% as_tibble () <- application_1_raw %>% mutate (학년도 = map_chr (학년도, 1 ) %>% as.integer) %>% filter (학년도 >= 2005 ) %>% :: clean_names (ascii= FALSE ) %>% set_names (c ("학년도" , "기간" , "총계" , "성별_남" , "성별_여" , "계열별" , "출신별_재학" , "출신별_졸업" , "출신별_검정" , "응시료" , "가" , "나" , "다" )) %>% select (학년도, contains ("_" ))## 2 페이지 <- py$ applicatin_2_pd %>% as_tibble () <- application_2_raw %>% slice (2 : n ()) %>% :: clean_names (ascii= FALSE ) %>% set_names (c ("학년도" , "기간" , "총계" , "성별_남" , "성별_여" , "계열별" , "출신별_재학" , "출신별_졸업" , "출신별_검정" , "응시료" )) %>% select (학년도, contains ("_" ))## 1~2 페이지 <- bind_rows (application_1, application_2) %>% pivot_longer (- 학년도) %>% separate (name, into = c ("대구분" , "중구분" ), sep = "_" ) %>% mutate (value = str_remove (value, ' \\ r \\ (.* \\ )' ) %>% parse_number (.))## 표 제작 library (scales)### 성별 %>% filter (대구분 == "성별" ) %>% pivot_wider (names_from = 중구분, values_from = value) %>% mutate (총계 = 남 + 여) %>% mutate (남여비율 = glue:: glue ("{scales::percent(남/(남+여), accuracy=0.1)} / {scales::percent(여/(남+여), accuracy=0.1)}" )) %>% arrange (desc (학년도)) %>% :: gt () %>% :: gt_theme_nytimes () %>% fmt_integer (columns = c (남, 여, 총계)) %>% cols_align (align = "center" )
학년도
대구분
남
여
총계
남여비율
2023
성별
260,126
247,904
508,030
51.2% / 48.8% 2022
성별
261,350
248,471
509,821
51.3% / 48.7% 2021
성별
254,027
239,407
493,434
51.5% / 48.5% 2020
성별
282,036
266,698
548,734
51.4% / 48.6% 2019
성별
306,142
288,782
594,924
51.5% / 48.5% 2018
성별
303,620
289,907
593,527
51.2% / 48.8% 2017
성별
310,451
295,536
605,987
51.2% / 48.8% 2016
성별
323,783
307,404
631,187
51.3% / 48.7% 2015
성별
333,204
307,417
640,621
52.0% / 48.0% 2014
성별
342,776
307,971
650,747
52.7% / 47.3% 2013
성별
356,924
311,598
668,522
53.4% / 46.6% 2012
성별
371,771
321,860
693,631
53.6% / 46.4% 2011
성별
379,385
332,842
712,227
53.3% / 46.7% 2010
성별
358,142
319,692
677,834
52.8% / 47.2% 2009
성별
313,002
275,837
588,839
53.2% / 46.8% 2008
성별
312,064
272,870
584,934
53.4% / 46.6% 2007
성별
313,715
275,184
588,899
53.3% / 46.7% 2006
성별
314,323
279,483
593,806
52.9% / 47.1% 2005
성별
324,700
285,557
610,257
53.2% / 46.8%
Code
### 출신별 %>% filter (대구분 == "출신별" ) %>% pivot_wider (names_from = 중구분, values_from = value) %>% mutate (총계 = 재학 + 졸업 + 검정) %>% mutate (출신비율 = glue:: glue ("{scales::percent(재학/총계, accuracy=0.1)} / {scales::percent(졸업/총계, accuracy=0.1)} / {scales::percent(검정/총계, accuracy=0.1)}" )) %>% arrange (desc (학년도)) %>% select (- 대구분) %>% :: gt () %>% :: gt_theme_nytimes () %>% fmt_integer (columns = c (재학, 졸업, 검정, 총계)) %>% cols_align (align = "center" ) %>% cols_label (출신비율 ~ md ("비율 (%)<br> 졸업 / 검정 / 총계" )) %>% tab_spanner (label = md ("**출신별**" ),columns = c (
학년도
출신별
총계
비율 (%)
재학
졸업
검정
2023
350,239
142,303
15,488
508,030
68.9% / 28.0% / 3.0% 2022
360,710
134,834
14,277
509,821
70.8% / 26.4% / 2.8% 2021
346,673
133,070
13,691
493,434
70.3% / 27.0% / 2.8% 2020
394,024
142,271
12,439
548,734
71.8% / 25.9% / 2.3% 2019
448,111
135,482
11,331
594,924
75.3% / 22.8% / 1.9% 2018
444,873
137,533
11,121
593,527
75.0% / 23.2% / 1.9% 2017
459,342
135,120
11,525
605,987
75.8% / 22.3% / 1.9% 2016
482,054
136,090
13,043
631,187
76.4% / 21.6% / 2.1% 2015
495,027
131,539
14,055
640,621
77.3% / 20.5% / 2.2% 2014
509,081
127,634
14,032
650,747
78.2% / 19.6% / 2.2% 2013
510,972
142,561
14,989
668,522
76.4% / 21.3% / 2.2% 2012
526,418
151,887
15,326
693,631
75.9% / 21.9% / 2.2% 2011
541,880
154,661
15,686
712,227
76.1% / 21.7% / 2.2% 2010
532,436
130,658
14,740
677,834
78.5% / 19.3% / 2.2% 2009
448,472
127,586
12,781
588,839
76.2% / 21.7% / 2.2% 2008
446,597
126,729
11,608
584,934
76.3% / 21.7% / 2.0% 2007
425,396
151,697
11,806
588,899
72.2% / 25.8% / 2.0% 2006
422,310
159,190
12,306
593,806
71.1% / 26.8% / 2.1% 2005
435,538
161,524
13,195
610,257
71.4% / 26.5% / 2.2%
Code
%>% mutate (value = value/ 10 ^ 4 ) %>% filter ( 대구분 == "출신별" ) %>% ggplot (aes (x = 학년도, y = value, color = 중구분)) + geom_line () + geom_point () + labs (title = "출신별 수능 접수현황" ,x = "" ,y = "접수자수(만명)" ,color = "접수구분: " ) + theme (legend.position = "top" ) + scale_color_manual (values = c ("gray30" , "blue" , "red" ))
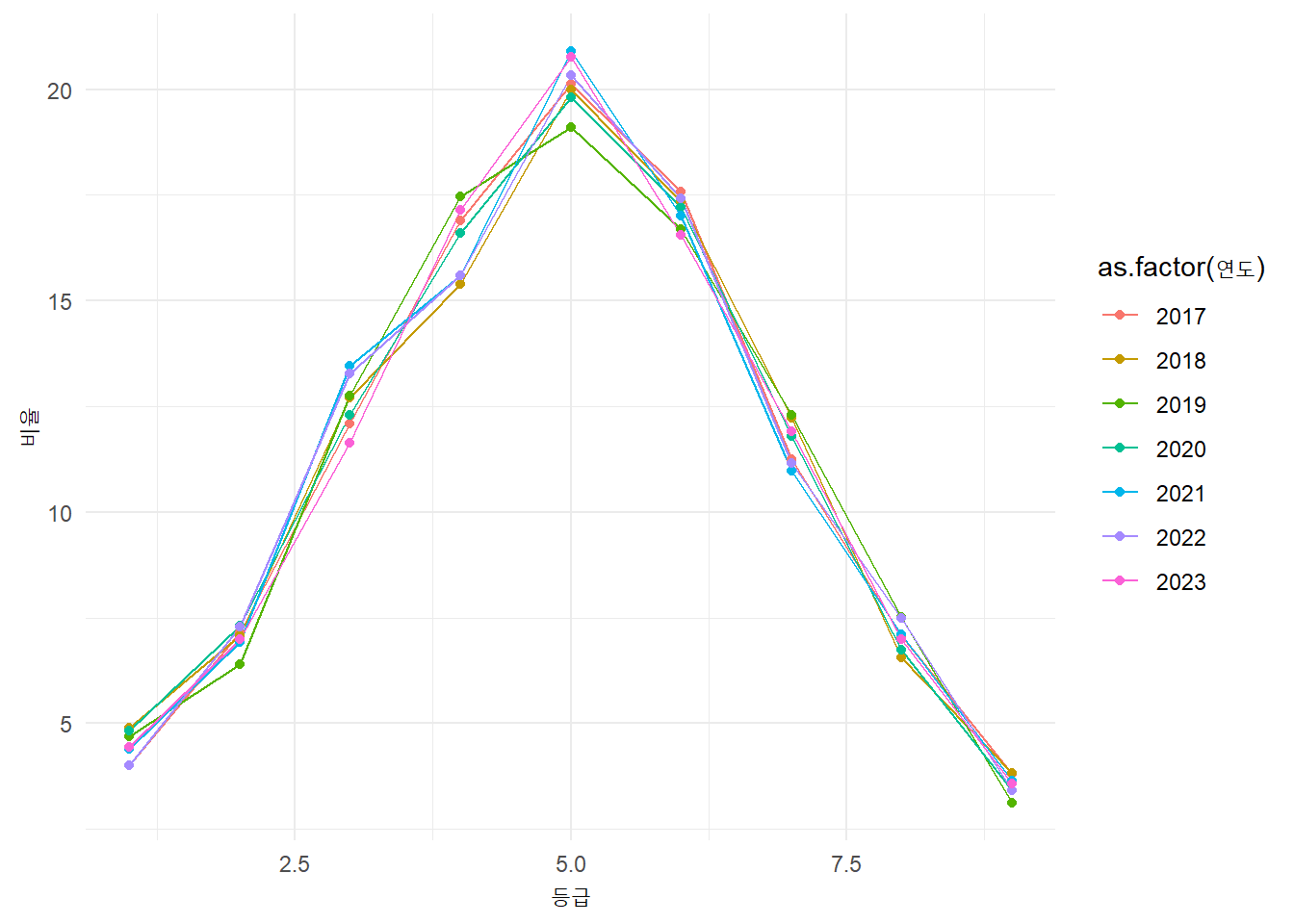
채점: 등급구분
공공데이터포털에서 한국교육과정평가원_대학수학능력시험 등급구분-표준점수 데이터를 가져온다.
Code
library (tidyverse)## 연도별 등급 데이터 <- fs:: dir_ls ("data/suneung/" , glob= "*.csv" )<- map (grade_files, read_csv, locale = locale (encoding = "EUC-KR" ))## 연도 <- map_chr (grade_files, str_extract, pattern = " \\ d{4}" )## 연도별 데이터 정제함수 <- function (df, year) {<- df %>% :: clean_names (ascii = FALSE ) %>% select (! starts_with ("x" )) %>% mutate (연도 = year) %>% set_names (c ("등급" , "과목" , "구분점수" , "도수_명" , "비율" , "연도" )) %>% mutate_all (as.character)return (grade_tbl)## 데이터 결합 <- map2 (grade_raw, grade_year, clean_grade)<- map_df (grade_list, bind_rows)
Code
<- grade_tbl %>% mutate (구분점수 = ifelse (str_detect (구분점수, "미만" ), parse_number (구분점수) - 3 , 구분점수)) %>% mutate (등급 = as.integer (등급),= as.integer (연도),= parse_number (도수_명),= parse_number (구분점수),= parse_number (비율))%>% filter (str_detect (과목, "^국어" )) %>% filter (! str_detect (과목, "[A|B|C|가|나|다]형" )) %>% ggplot (aes (x = 등급, y = 비율, color = as.factor (연도))) + # ggplot(aes(x = 등급, y = 구분점수, color = as.factor(연도))) + # ggplot(aes(x = 구분점수, y = 등급, color = as.factor(연도))) + geom_line () + geom_point ()
Code
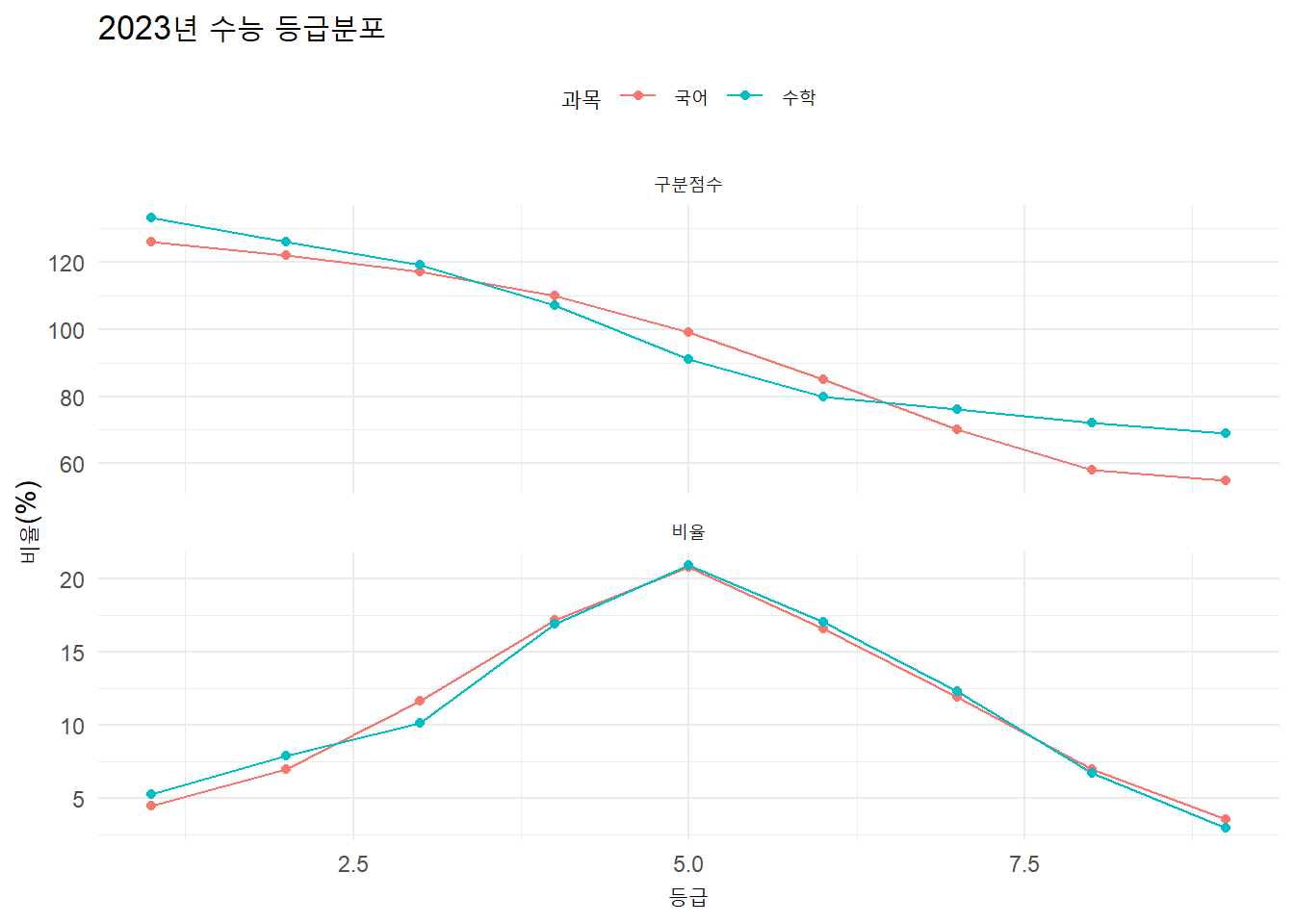
%>% filter (연도 == max (연도),str_detect (과목, "국어|(영어)|수학" )) %>% pivot_longer (cols = c (구분점수, 비율)) %>% ggplot (aes (x = 등급, y = value, color = 과목)) + geom_line () + geom_point () + labs (title = "2023년 수능 등급분포" ,y = "비율(%)" ) + facet_wrap (~ name, nrow = 2 , scales = "free_y" ) + theme (legend.position = "top" )
배점
Code
library (datapasta)library (tidyverse)library (rvest)library (gt)library (gtExtras)<- "https://www.jbe.go.kr/jinro/index.jbe?menuCd=DOM_000001105004005005" <- read_html (table_url) %>% html_elements ("table" ) %>% html_table () %>% 1 ]]<- point_raw %>% :: clean_names (ascii = FALSE ) %>% slice (2 : n ()) %>% set_names (c ("대구분" , "소구분" , "문항수" , "문항유형" , "배점_문항" , "배점_전체" , "시험시간" ,"출제범위" )) %>% mutate_all (.funs = str_remove_all, pattern = "ㆍ? \n\t\t\t | \t\t " ) %>% mutate (대구분 = str_remove (대구분, " \\ (필수 \\ )" ),= str_remove (소구분, " \\ (필수 \\ )" )) %>% mutate (과목수 = ifelse (str_detect (출제범위, "지구과학" ), 2 , 1 )) %>% mutate (배점_전체 = parse_number (배점_전체),= 배점_전체 * 과목수) %>% relocate (과목수, .before= 시험시간) %>% relocate (과목점수, .before= 시험시간)%>% gt (rowname_col = "대구분" ) %>% gt_theme_538 () %>% cols_align ("center" ) %>% tab_options (table.font.size = px (12L),stub.border.width = px (2 ),stub.border.color = "black" %>% tab_spanner (label = md ("**배점**" ),columns = c (%>% cols_label (= "문항" ,= "전체" %>% tab_footnote (footnote = md ("필수" ),locations = cells_body (columns = c (대구분, 소구분),rows = 대구분 == "한국사" )%>% grand_summary_rows (columns = 과목점수,fns = list (= ~ sum (., na.rm = TRUE )
소구분
문항수
문항유형
배점
시험시간
출제범위
문항
전체
과목수
과목점수
국어
국어
45
5지선다형
2,3
100
1
100
80분
공통과목: 독서, 문학 선택과목(택 1): 화법과 작문, 언어와 매체 공통 75%, 선택 25% 내외 수학
수학
30
5지선다형, 단답형
2,3,4
100
1
100
100분
공통과목: 수학Ⅰ, 수학Ⅱ 선택과목(택 1): 확률과 통계, 미적분, 기하 공통 75%, 선택 25% 내외 단답형 30% 포함 영어
영어
45
5지선다형(듣기17문항)
2,3
100
1
100
70분
영어Ⅰ, 영어Ⅱ를 바탕으로 다양한 소재의 지문과 자료를 활용하여 출제 한국사
한국사
20
5지선다형
2,3
50
1
50
30분
한국사를 바탕으로 우리 역사에 대한 기본 소양을 평가하기 위한 핵심 내용 중심으로 출제 탐구
사회과학탐구
과목당 20
5지선다형
2,3
50
2
100
과목당 30분
생활과 윤리, 윤리와 사상, 한국지리, 세계지리, 동아시아사, 세계사, 경제, 정치와 법, 사회・문화물리학Ⅰ, 화학Ⅰ, 생명과학Ⅰ, 지구과학Ⅰ, 물리학Ⅱ, 화학Ⅱ, 생명과학Ⅱ, 지구과학Ⅱ 17개 과목 중 최대 택 2 탐구
직업탐구
과목당 20
5지선다형
2,3
50
1
50
과목당 30분
1과목 선택: 농업 기초 기술, 공업 일반, 상업 경제, 수산・해운 산업 기초, 인간 발달 중 택 1 2과목 선택: 성공적인 직업생활+ 위 5개 과목 중 택1 제2외국어/한문
제2외국어/한문
과목당 30
5지선다형
1,2
50
1
50
과목당40분
독일어Ⅰ, 프랑스어Ⅰ, 스페인어Ⅰ, 중국어Ⅰ, 일본어Ⅰ, 러시아어Ⅰ, 아랍어Ⅰ, 베트남어Ⅰ, 한문Ⅰ 9개 과목 중 택 1 총점
—
—
—
—
—
—
550
—
—