graph TD
A[원본 연구 .qmd] --> B{쿼토 렌더링}
B --> C[학술 논문 PDF]
B --> D[프레젠테이션 HTML]
B --> E[기술 블로그]
B --> F[인터랙티브 대시보드]
B --> G[정책 보고서]
B --> H[교육 자료]
I[데이터 업데이트] --> A
J[AI 어시스턴트] --> A
K[공동 연구자] --> A
style A fill:#e1f5fe
style B fill:#f3e5f5
style C,D,E,F,G,H fill:#e8f5e8
22 다중 출력과 과학기술 커뮤니케이션
중요One Source, Multiple Outputs
한 번의 작성으로 학술논문, 프레젠테이션, 웹사이트, 대시보드까지 다양한 형태로 과학기술 지식을 전달하는 방법을 배워봅시다.
22.1 과학기술 커뮤니케이션의 변화
22.1.1 전통적 한계
과학기술 연구의 전달 과정에서 겪는 어려움:
- 매체별 재작성: 논문, 발표, 블로그, 보고서를 각각 따로 작성
- 일관성 부족: 같은 연구 내용이지만 매체마다 다른 결과나 해석
- 시간 비효율: 하나의 연구를 여러 번 재구성하는 반복 작업
- 업데이트 어려움: 한 곳을 수정하면 모든 매체를 다시 업데이트해야 함
- 협업 제약: 연구자, 디자이너, 커뮤니케이터가 분리된 작업
22.1.2 Document as Code의 해답
22.2 One Source, Multiple Outputs 전략
22.2.1 YAML 헤더 설계
---
title: "AI 기반 텍스트 분류 연구"
subtitle: "Document as Code 패러다임을 활용한 다중 출력 사례"
# 공통 메타데이터
authors:
- name: "이광춘"
affiliation: "공익법인 한국 R 사용자회"
orcid: "0000-0002-9190-0580"
abstract: |
본 연구는 Document as Code 패러다임을 적용하여 AI 기반 텍스트 분류 시스템을
개발하고, 하나의 소스에서 다양한 형태의 과학기술 커뮤니케이션 산출물을
생성하는 방법론을 제시한다.
keywords: ["AI", "텍스트분류", "Document as Code", "과학기술커뮤니케이션"]
date: today
# 다중 출력 포맷 정의
format:
# 학술 논문용 PDF
pdf:
documentclass: article
fontsize: 11pt
geometry: [margin=2.5cm]
number-sections: true
bibliography-title: "참고문헌"
# 프레젠테이션용 HTML
revealjs:
theme: white
slide-number: true
chalkboard: true
scrollable: true
# 웹 공개용 HTML
html:
theme: cosmo
toc: true
code-fold: show
fig-cap-location: bottom
# 대시보드용 (추후 확장)
dashboard:
theme: bootstrap
orientation: columns
# 조건부 내용 제어
params:
target_audience: "academic" # academic, public, policy, education
detail_level: "full" # summary, full, technical
include_code: true
include_data: true
bibliography: assets/references.bib
csl: assets/apa-single-spaced.csl
---22.2.2 조건부 내용 구성
# 서론
::: {.content-visible when-profile="academic"}
## 연구 배경과 문헌 리뷰
최근 자연어 처리 분야에서 transformer 아키텍처의 도입으로
텍스트 분류 성능이 크게 향상되었다 [@vaswani2017attention; @devlin2018bert].
특히 한국어 텍스트 처리에서는...
:::
::: {.content-visible when-profile="public"}
## 왜 텍스트 분류가 중요할까?
매일 쏟아지는 엄청난 양의 텍스트 데이터를 사람이 모두 분류하기는
불가능합니다. AI가 이 문제를 어떻게 해결하는지 알아보겠습니다.
:::
::: {.content-visible when-profile="policy"}
## 정책적 필요성
정부 기관과 공공 부문에서 처리하는 문서량이 급증함에 따라
자동화된 텍스트 분류 시스템 도입이 행정 효율성 향상에 필수적입니다.
:::22.3 학술 발표와 컨퍼런스
22.3.1 RevealJS 기반 프레젠테이션
## 연구 목표 {.slide-title}
::: {.incremental}
1. **성능**: 한국어 텍스트 분류 정확도 95% 이상
2. **효율성**: 실시간 처리 성능 1,000건/분 이상
3. **재현가능성**: 전체 파이프라인의 버전 관리
4. **확장성**: 다양한 도메인으로의 적용
:::
## 방법론 {.slide-title}
:::: {.columns}
::: {.column width="50%"}
### 기존 방식
- 수동 특성 추출
- 단일 모델 의존
- 하드코딩된 파라미터
- 재현 어려움
:::
::: {.column width="50%"}
### Document as Code
- 자동 특성 학습
- 앙상블 방법
- 파라미터 최적화
- 완전 재현 가능
:::
::::
## 결과 {.slide-title}library(tidyverse)
library(scales)
# 프레젠테이션용 성능 비교 그래프
performance_data <- tibble(
model = c("기존 방법", "Random Forest", "BERT", "제안 방법"),
accuracy = c(0.82, 0.89, 0.94, 0.96),
f1_score = c(0.79, 0.86, 0.92, 0.95)
)
p1 <- performance_data %>%
pivot_longer(cols = c(accuracy, f1_score),
names_to = "metric", values_to = "score") %>%
mutate(
metric = case_when(
metric == "accuracy" ~ "정확도",
metric == "f1_score" ~ "F1 점수"
)
) %>%
ggplot(aes(x = model, y = score, fill = metric)) +
geom_col(position = "dodge", alpha = 0.8) +
geom_text(aes(label = percent(score, accuracy = 0.1)),
position = position_dodge(width = 0.9),
vjust = -0.3, size = 4) +
labs(
title = "모델별 성능 비교",
x = NULL,
y = "점수",
fill = "지표"
) +
scale_fill_manual(values = c("#2E86C1", "#E74C3C")) +
scale_y_continuous(labels = percent_format(), limits = c(0, 1)) +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
p1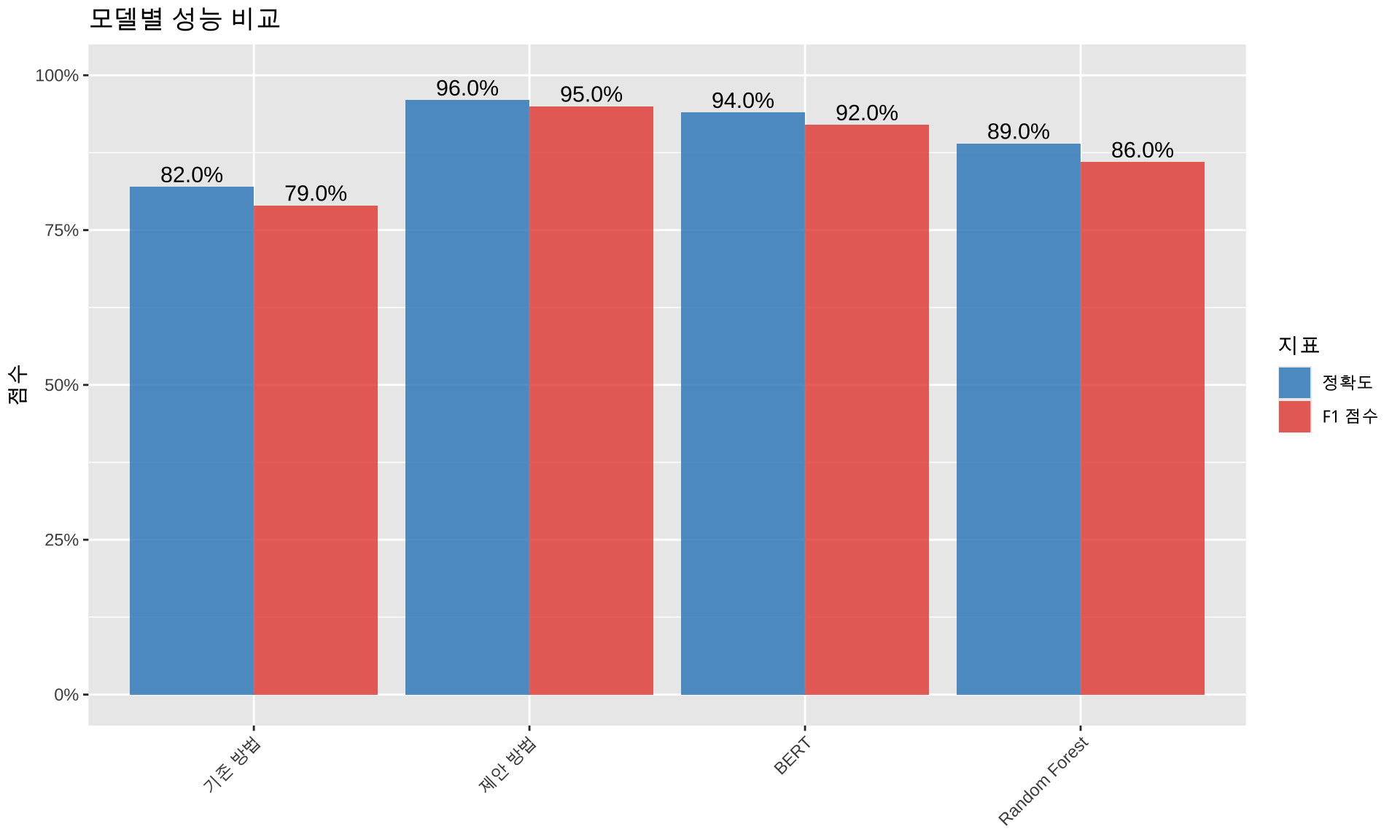
22.3.2 인터랙티브 프레젠테이션
22.4 교육 자료와 워크숍
22.4.1 단계별 학습 모듈
# AI 텍스트 분류 워크숍
## 모듈 1: 기초 개념 {.module}
### 학습 목표
::: {.learning-objectives}
- 텍스트 분류의 정의와 응용 분야 이해
- 머신러닝 기본 개념 습득
- Document as Code 패러다임 소개
:::
### 실습 1: 간단한 텍스트 분류# 실습용 간단한 예제
library(tidytext)
library(stringr)
# 샘플 데이터
texts <- c(
"축구 경기가 흥미진진했다",
"새로운 과학 발견이 발표되었다",
"정치인들이 회의를 가졌다"
)
# 간단한 키워드 기반 분류
classify_simple <- function(text) {
case_when(
str_detect(text, "축구|야구|농구") ~ "스포츠",
str_detect(text, "과학|연구|발견") ~ "과학",
str_detect(text, "정치|정부|국회") ~ "정치",
TRUE ~ "기타"
)
}
# 결과 확인
tibble(text = texts, category = map_chr(texts, classify_simple))
#> # A tibble: 3 × 2
#> text category
#> <chr> <chr>
#> 1 축구 경기가 흥미진진했다 스포츠
#> 2 새로운 과학 발견이 발표되었다 과학
#> 3 정치인들이 회의를 가졌다 정치22.4.2 진척도 추적
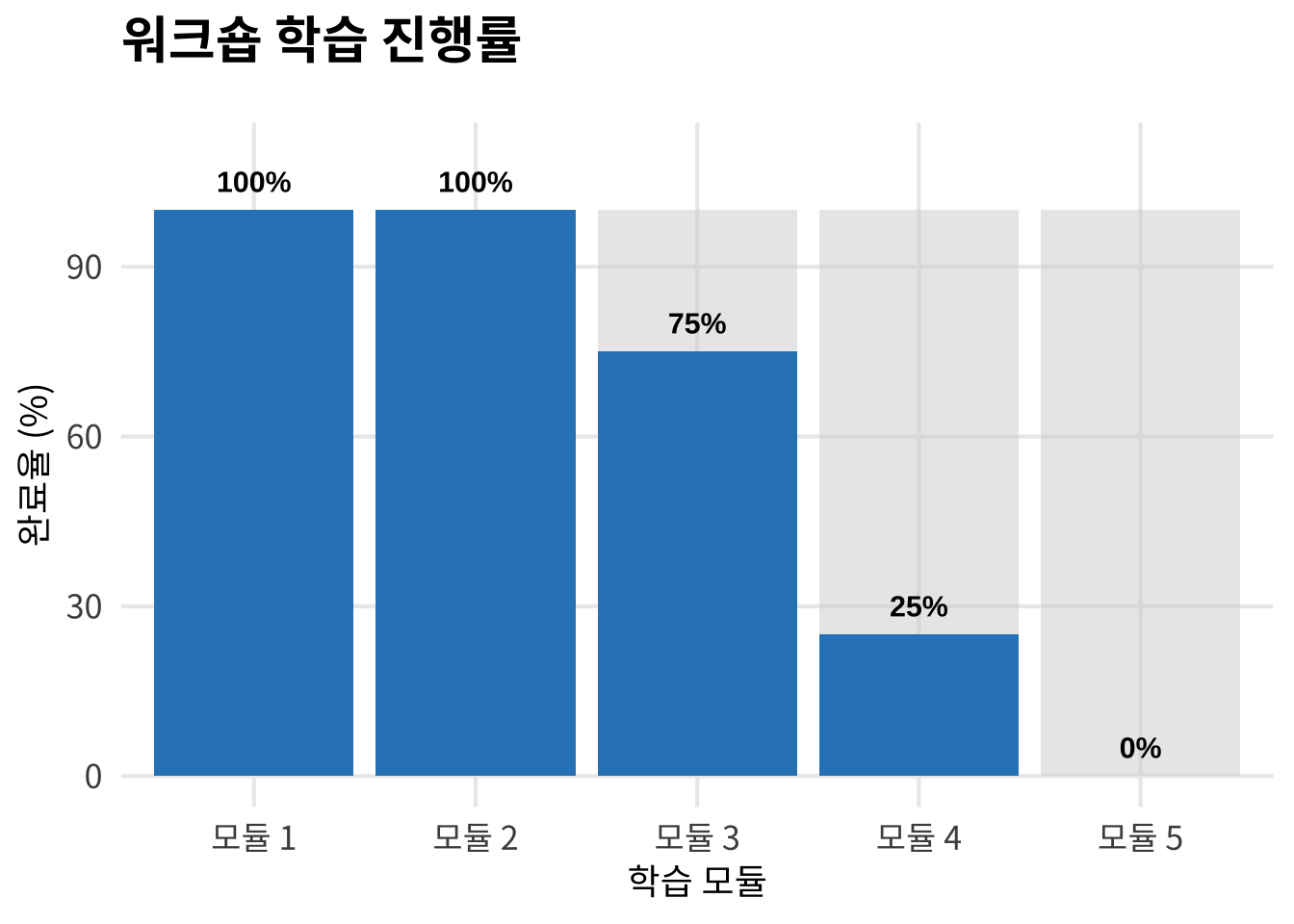
22.5 대중 과학 커뮤니케이션
22.5.1 블로그와 웹 콘텐츠
# AI는 어떻게 텍스트를 이해할까? 🤖
::: {.content-visible when-profile="public"}
## 인간의 언어, 컴퓨터가 이해하려면?
우리가 "이 영화 정말 재밌다!"라고 말할 때, 컴퓨터는 어떻게 이것이
긍정적인 의견임을 알 수 있을까요?
### 1단계: 텍스트를 숫자로 변환
컴퓨터는 숫자만 이해할 수 있어서, 우선 단어들을 숫자로 바꿔야 합니다.
### 2단계: 패턴 학습
수많은 예제를 통해 "재밌다", "좋다" 같은 단어들이 긍정적 의견과
연관된다는 것을 학습합니다.
### 3단계: 새로운 텍스트 분류
학습한 패턴을 바탕으로 처음 보는 텍스트도 분류할 수 있게 됩니다.
:::
22.5.2 인포그래픽과 데이터 스토리
22.6 인터랙티브 대시보드
22.6.1 Shiny 대시보드 통합
library(shiny)
library(shinydashboard)
library(plotly)
# 대시보드 UI
ui <- dashboardPage(
dashboardHeader(title = "AI 텍스트 분류 모니터링"),
dashboardSidebar(
sidebarMenu(
menuItem("실시간 분류", tabName = "classify", icon = icon("robot")),
menuItem("성능 지표", tabName = "performance", icon = icon("chart-line")),
menuItem("데이터 탐색", tabName = "explore", icon = icon("search"))
)
),
dashboardBody(
tabItems(
tabItem(tabName = "classify",
fluidRow(
box(
title = "텍스트 입력", status = "primary", solidHeader = TRUE,
textAreaInput("input_text", "분류할 텍스트:",
placeholder = "여기에 텍스트를 입력하세요..."),
actionButton("classify_btn", "분류하기", class = "btn-primary")
),
box(
title = "분류 결과", status = "success", solidHeader = TRUE,
verbatimTextOutput("classification_result"),
plotOutput("confidence_plot")
)
)
),
tabItem(tabName = "performance",
fluidRow(
valueBoxOutput("total_requests"),
valueBoxOutput("accuracy_rate"),
valueBoxOutput("avg_response_time")
),
fluidRow(
box(
title = "시간대별 요청량", status = "info", solidHeader = TRUE,
plotlyOutput("hourly_requests")
),
box(
title = "카테고리별 분포", status = "warning", solidHeader = TRUE,
plotlyOutput("category_distribution")
)
)
)
)
)
)
# 대시보드 Server
server <- function(input, output, session) {
# 실시간 분류
observeEvent(input$classify_btn, {
req(input$input_text)
# 실제로는 ML 모델 API 호출
result <- classify_text(input$input_text)
output$classification_result <- renderText({
paste("예측 카테고리:", result$category, "\n",
"신뢰도:", scales::percent(result$confidence))
})
output$confidence_plot <- renderPlot({
# 신뢰도 시각화
})
})
# 성능 지표 박스들
output$total_requests <- renderValueBox({
valueBox(
value = "15,847",
subtitle = "총 처리 요청",
icon = icon("list"),
color = "blue"
)
})
}
shinyApp(ui, server)22.6.2 Observable 기반 인터랙티브 차트
22.7 정책 보고서와 의사결정 지원
22.7.1 정책 입안자용 요약
| AI 텍스트 분류 시스템 도입 효과 | ||||
| 정책 결정자를 위한 핵심 성과 지표 | ||||
| 지표 | 현재값 | 목표값 | 달성률 | 평가 |
|---|---|---|---|---|
| 연간 처리량 | 1,200만 건 | 2,000만 건 | 60% | 보통 |
| 인건비 절약 | 15억원 | 25억원 | 60% | 보통 |
| 처리 시간 단축 | 75% | 85% | 88% | 우수 |
| 정확도 향상 | 20%p | 25%p | 80% | 우수 |
22.7.2 ROI 분석
# ROI 시각화
roi_data <- tibble(
year = 2024:2028,
investment = c(-5, -2, -1, -1, -1), # 억원
savings = c(0, 8, 15, 20, 25), # 억원
cumulative = cumsum(investment + savings)
)
roi_data %>%
pivot_longer(cols = c(investment, savings),
names_to = "type", values_to = "amount") %>%
mutate(
type = case_when(
type == "investment" ~ "투자 비용",
type == "savings" ~ "절약 효과"
),
amount_abs = abs(amount)
) %>%
ggplot(aes(x = year)) +
geom_col(aes(y = amount, fill = type), position = "identity", alpha = 0.7) +
geom_line(data = roi_data, aes(y = cumulative), size = 2, color = "black") +
geom_point(data = roi_data, aes(y = cumulative), size = 4, color = "black") +
geom_text(data = roi_data, aes(y = cumulative + 2, label = paste0(cumulative, "억원")),
size = 3.5, fontweight = "bold") +
theme_presentation +
scale_fill_manual(values = c("투자 비용" = "#E74C3C", "절약 효과" = "#2ECC71")) +
labs(
title = "AI 텍스트 분류 시스템 ROI 분석",
subtitle = "5년간 투자 대비 효과 (누적선: 순수익)",
x = "연도",
y = "금액 (억원)",
fill = "구분"
) +
theme(legend.position = "bottom")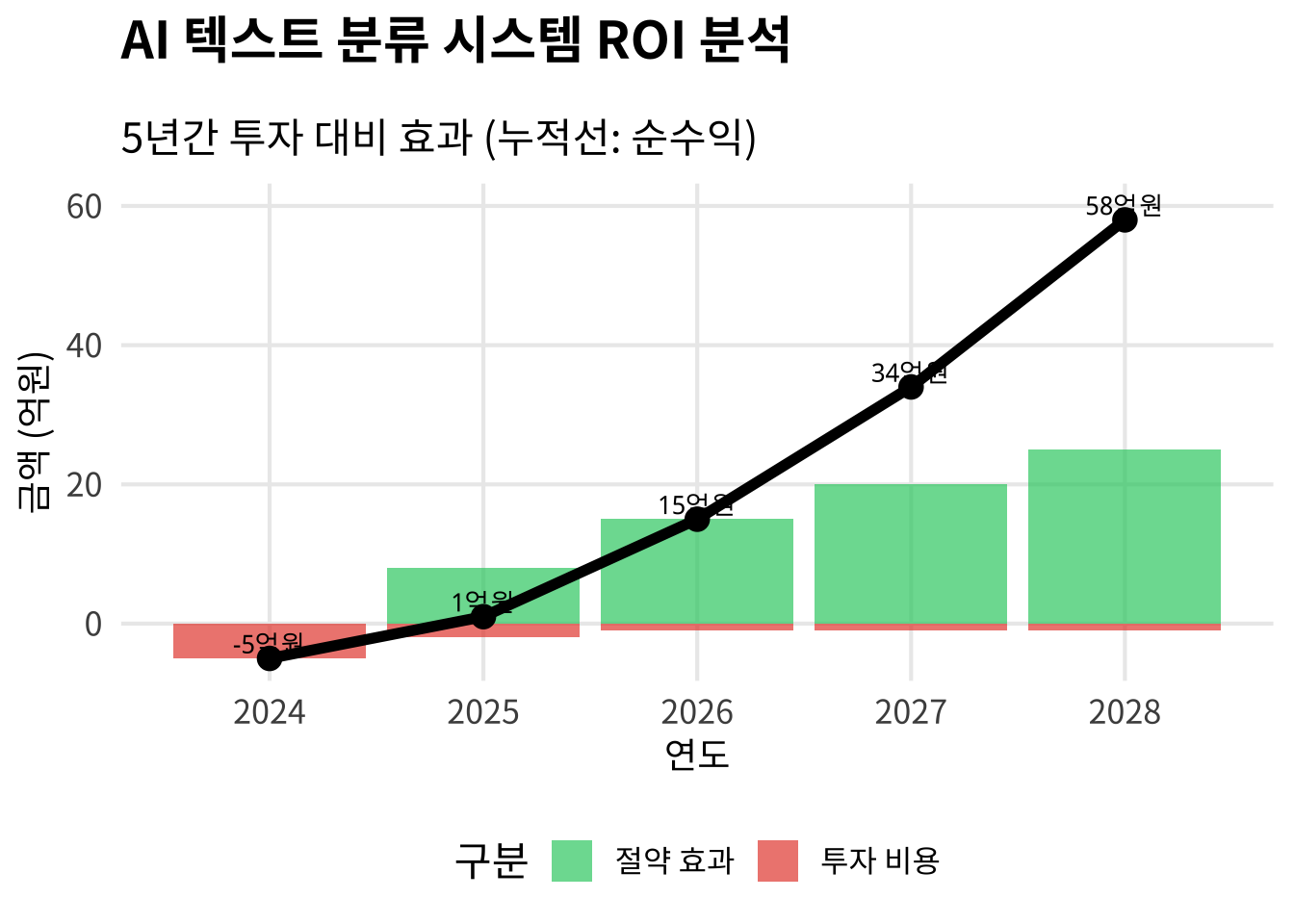
22.8 자동 배포와 업데이트
22.8.1 GitHub Actions 워크플로우
# .github/workflows/multi-format-publish.yml
name: Multi-Format Scientific Communication
on:
push:
branches: [main]
paths:
- 'sci_*.qmd'
- 'data/**'
- '_quarto.yml'
jobs:
render-and-deploy:
runs-on: ubuntu-latest
strategy:
matrix:
format: [pdf, html, revealjs, dashboard]
profile: [academic, public, policy]
steps:
- uses: actions/checkout@v4
- name: Setup Quarto
uses: quarto-dev/quarto-actions/setup@v2
- name: Setup R and Python
uses: r-lib/actions/setup-r@v2
with:
python-version: '3.11'
- name: Install dependencies
run: |
R -e "install.packages(c('tidyverse', 'gt', 'plotly', 'shiny'))"
pip install pandas numpy scikit-learn
- name: Render with profile
run: |
quarto render sci_publishing.qmd \
--to ${{ matrix.format }} \
--profile ${{ matrix.profile }}
- name: Deploy to different channels
run: |
case "${{ matrix.profile }}" in
"academic")
# arXiv 또는 학술지 제출 시스템
echo "Deploy to academic channels"
;;
"public")
# 블로그, SNS, 언론 배포
echo "Deploy to public channels"
;;
"policy")
# 정부 보고서 시스템
echo "Deploy to policy channels"
;;
esac22.8.2 버전 관리와 추적
library(git2r)
library(lubridate)
# 문서 버전 이력 추적
track_document_versions <- function(file_path) {
repo <- repository(".")
commits <- commits(repo, path = file_path, n = 10)
map_dfr(commits, function(commit) {
tibble(
version = str_sub(sha(commit), 1, 7),
date = as.Date(when(commit)),
author = author(commit)$name,
message = str_trunc(message(commit), 50),
outputs_generated = list_outputs(commit, file_path)
)
})
}
# 출력 포맷별 배포 상태 확인
deployment_status <- tibble(
format = c("PDF 논문", "HTML 웹사이트", "RevealJS 발표", "Shiny 대시보드"),
last_update = as.Date(c("2024-01-15", "2024-01-16", "2024-01-16", "2024-01-14")),
status = c("배포됨", "배포됨", "배포됨", "배포 대기"),
url = c(
"https://arxiv.org/abs/2024.001",
"https://r2bit.com/text-classification",
"https://r2bit.com/slides/text-classification",
"https://shiny.r2bit.com/text-classifier"
)
)
deployment_status %>%
gt() %>%
tab_header(
title = "다중 출력 배포 현황",
subtitle = "최근 업데이트 기준"
) %>%
fmt_date(columns = last_update, date_style = 6) %>%
fmt_url(columns = url, label = "링크") %>%
tab_style(
style = cell_fill(color = "lightgreen"),
locations = cells_body(columns = status, rows = status == "배포됨")
)22.9 성과 측정과 피드백
22.9.1 다채널 성과 분석
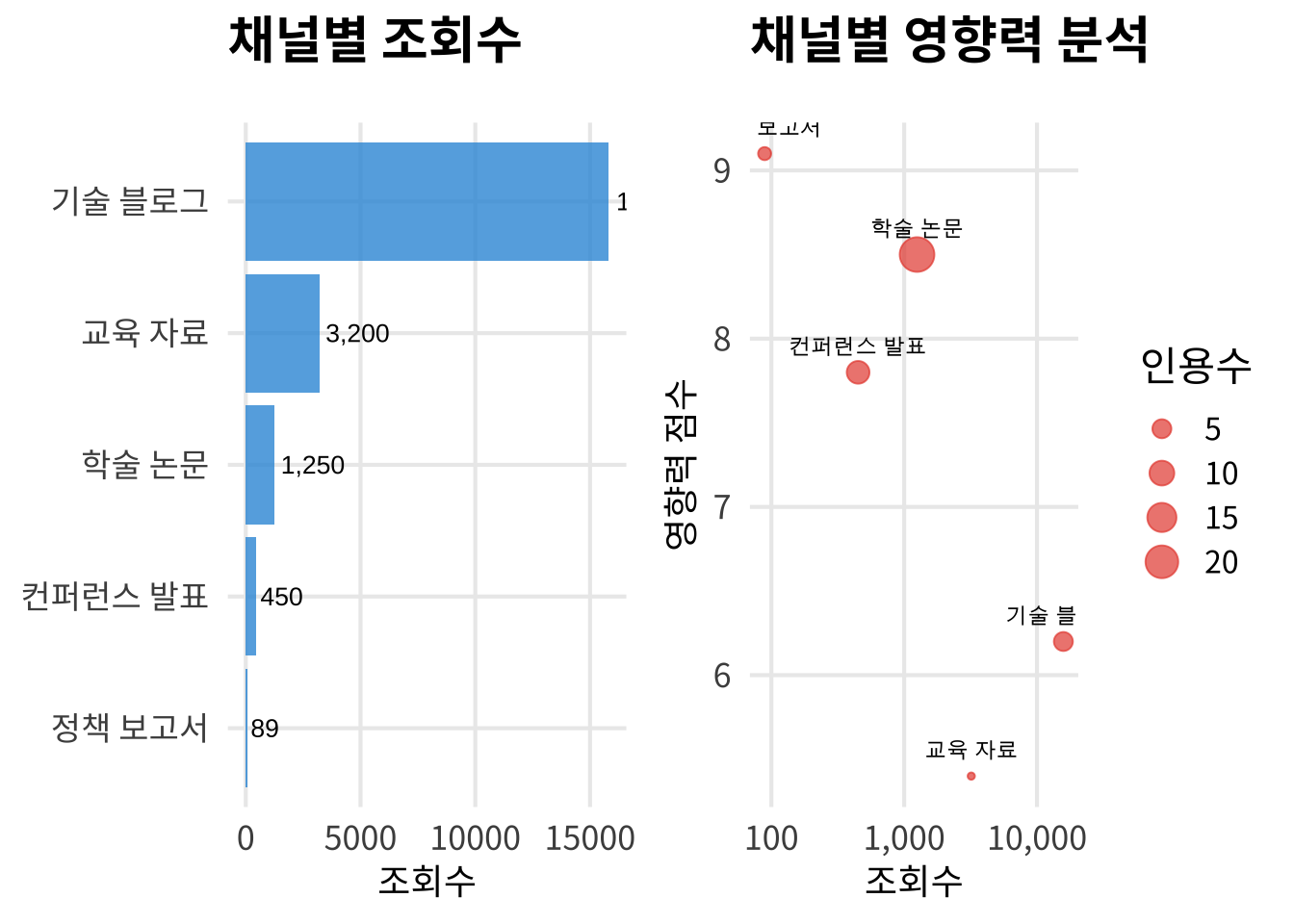
22.9.2 피드백 통합 시스템
22.10 실제 프로젝트로: 다음 여정
이론과 방법론을 배웠으니 이제 실제 프로젝트에 적용해볼 차례입니다. 다음 파트인 ‘실전 프로젝트’에서는 여러분이 직접 Document as Code 패러다임을 실천하는 구체적인 방법들을 다룹니다.
22.10.1 이론에서 실천으로의 전환
지금까지 배운 것들 - Document as Code 철학과 원칙 - 문서 구성요소와 과학적 DSL - AI 통합과 자동화 기법 - 학술 논문과 기술 문서 작성 - 다중 출력과 커뮤니케이션 전략
이제 실천할 것들
- AI 논문 작성 프로젝트: 실제 연구 주제로 완전한 논문 제작 - 기술 블로그 운영: 지속가능한 콘텐츠 생산 시스템 구축 - 협업 문서 시스템: 팀 단위의 문서 워크플로우 설계
22.10.2 미래 지향적 역량 개발
Document as Code는 단순한 기술이 아닌 미래 지향적 사고방식입니다:
# 차세대 과학기술 소통의 특징
## 1. AI 네이티브 워크플로우
- 인간-AI 협업 최적화
- 자동화된 품질 보장
- 지속적인 학습과 개선
## 2. 리액티브 문서 생태계
- 데이터 변화에 실시간 반응
- 독자 피드백 즉시 반영
- 자가 진화하는 콘텐츠
## 3. 경계 없는 지식 공유
- 플랫폼 간 자유로운 이동
- 다양한 형태로의 즉시 변환
- 글로벌 협업 네트워크실전 프로젝트를 통해 이러한 미래를 미리 경험해보세요.
힌트실습 과제
현재 진행 중인 연구나 프로젝트를 선택하여 다중 출력 전략을 설계해보세요: 1. 학술 논문용 정식 버전 2. 일반인을 위한 블로그 버전
3. 관련 업계를 위한 기술 보고서 버전 4. 정책 결정자를 위한 요약 버전
하나의 .qmd 파일에서 조건부 내용과 포맷 설정을 통해 이 모든 것을 관리해보세요.
노트지속가능한 과학소통
Document as Code는 단순히 효율성만을 위한 것이 아닙니다. 투명하고 재현가능하며 협업 가능한 과학기술 커뮤니케이션을 통해 더 나은 과학 생태계를 만들어가는 것이 목표입니다.
경고AI 윤리와 투명성
AI를 활용한 콘텐츠 생성과 개인화 과정에서는 반드시 투명성을 유지하고, 편향을 방지하며, 독자의 프라이버시를 보호해야 합니다. 모든 AI 사용 내역을 명시하고 검증 가능한 방식으로 공개하세요.