| 측정지표 | 전통적방법 | flexdashboard | 개선율 |
|---|---|---|---|
| 개발 시간 | 40시간 | 3시간 | 93% 감소 |
| 필요 기술 | HTML/CSS/JS | R만 | 3→1개 |
| 코드 라인 | 500줄 | 50줄 | 90% 감소 |
| 유지보수 | 전문가 필요 | 데이터 분석가 | 민주화 |
14 대시보드
2020년 3월 11일, WHO가 팬데믹을 선언한 그날 밤.
존스 홉킨스 대학교 시스템공학과 대학원생 엔지 둥(Dong 기타, 2020)이 만든 단순한 웹페이지가 전 세계의 정보 표준이 되었다. 매 1초마다 갱신되는 이 대시보드는 45만명의 동시 접속자가 193개국에서 전송되는 데이터를 빛의 속도로 확인하는 장이 되었다. 숫자가 실시간으로 변하는 이 화면을 보며 우리는 깨달았다. 문서의 상전이(phase transition)가 시작되었음을 전세계 모든 연구자들이 알게 되었다.
물리학에서 물질이 고체에서 액체로, 액체에서 기체로 변하듯이, 문서도 임계점을 넘으면서 본질적인 변화를 겪는다. 먼저 고체 문서인 종이와 HWP 파일은 고정되고 불변하는 형태였다. 이것이 액체 문서인 디지털 파일과 PDF로 흘러가면서 복사와 전송이 자유로워졌다. 다시 기체 문서인 웹페이지로 확산되면서 접근성이 극대화되었고, 마침내 플라즈마 문서인 대시보드에 이르러 정보 자체가 살아 움직이는 유기체가 되었다.
각각의 상전이에는 기술적 혁신이라는 활성화 에너지가 필요했다. 1979년 워드프로세서의 발명으로 디지털화가 시작되었고, 1991년 HTML과 HTTP 프로토콜의 등장으로 웹화가 가능해졌다. 2005년 AJAX와 WebSocket 기술이 대시보드화를 촉발했으며, 2020년 GPT와 실시간 AI의 융합이 문서의 지능화라는 새로운 차원을 열었다. 각 전환점은 단순한 기술적 진보가 아니라, 인간이 정보와 상호작용하는 방식 자체를 근본적으로 바꾸어놓았다.

14.1 flexdashboard 충격
2017년 봄, 저자는 여전히 엑셀로 데이터를 정리하고 파워포인트로 월간 보고서를 만들고 있었다. 차트를 하나 수정하려면 엑셀에서 데이터를 바꾸고, 차트를 다시 복사해서 파워포인트에 붙여넣고, 레이아웃을 다시 맞추는 지루한 작업을 반복했다. 대시보드는 웹 개발자들만이 만들 수 있는 고급 기술의 영역이라고 믿었다. HTML, CSS, JavaScript를 모두 알아야 하고, 서버 설정까지 해야 하는 복잡한 작업이라고 생각했다.
그런 저자에게 flexdashboard 패키지와 첫 만남은 그야말로 충격이었다. RStudio 블로그에서 우연히 본 예제를 따라 해보는데, 마크다운 문법으로 몇 줄만 적었을 뿐인데 브라우저에 완전한 대시보드가 떠오르는 것이 아닌가. 클릭할 수 있는 탭, 반응하는 차트, 깔끔한 레이아웃까지 모든 것이 자동으로 만들어졌다. 그 순간 나는 깨달았다. 내가 알고 있던 “문서”와 “애플리케이션”의 경계가 무너지고 있다는 것을.
실제로 실험을 통해 확인한 결과는 더욱 놀라웠다. 기존에 웹 개발자와 협업하여 40시간이 걸리던 대시보드 작업을 혼자서 3시간 만에 완성할 수 있었다. HTML, CSS, JavaScript라는 세 가지 기술을 익혀야 했던 것이 R과 마크다운만 알면 되는 일이 되었고, 500줄의 복잡한 코드가 50줄의 간단한 마크다운으로 축약되었다.
이것이 바로 패러다임 전환의 순간이었다. 문서 작성과 애플리케이션 개발이 하나가 되는 경험. 데이터 분석가가 개발자가 되고, 보고서가 대시보드가 되는 마법. 그 순간부터 저자에게 “문서”는 더 이상 정적인 텍스트가 아니라, 살아 움직이는 인터랙티브한 경험이 되었다.
노트엑셀 40년 변신 - 스프레드시트에서 AI 플랫폼으로
1985년 첫 출시된 엑셀은 단순한 전자 계산기였다. 행과 열로 이루어진 격자 위에 숫자를 입력하고 간단한 수식을 계산하는 것이 전부였다. 하지만 40년이 지난 지금, 엑셀은 더 이상 우리가 알던 그 스프레드시트가 아니다. Python을 실행하고, AI와 대화하며, 웹 데이터를 자동으로 수집하는 종합 데이터 플랫폼으로 진화했다.
이러한 변화는 갑작스럽게 일어난 것이 아니다. 1993년 VBA(Visual Basic for Applications) 매크로가 추가되면서 엑셀은 프로그래밍이 가능한 도구가 되었다. 2010년 파워피벗(PowerPivot)이 도입되면서 수백만 행의 빅데이터를 처리할 수 있는 BI(Business Intelligence) 플랫폼으로 확장되었다. 그리고 2023년, 마침내 Python 통합과 AI Copilot이 추가되면서 엑셀은 완전히 새로운 차원으로 도약했다.
| 연도 | 버전 | 핵심기능 | 패러다임 |
|---|---|---|---|
| 1985 | Excel 1.0 | 단순 계산 | 전자 계산기 |
| 1993 | Excel 5.0 | VBA 매크로 | 프로그래밍 도구 |
| 2010 | Excel 2010 | 파워피벗 | BI 플랫폼 |
| 2023 | Excel 365 | Python + AI | AI 협업 환경 |
생존 비결: 40년 된 소프트웨어가 어떻게 아직도 살아있을까? 엑셀은 끊임없이 자신을 재발명했다. 2023년 Python 통합과 Copilot AI 도입은 단순한 기능 추가가 아니라 생존을 위한 진화였다. 구글 시트, 에어테이블, 노션 같은 신흥 강자들과 경쟁하며, 엑셀은 이제 “스프레드시트”를 넘어 “지능형 데이터 플랫폼”으로 탈바꿈하고 있다. 마이크로소프트는 엑셀이 단순한 도구가 아니라 AI 시대의 필수 인프라가 되도록 몸부림치고 있다.
14.2 쿼토 대시보드
flexdashboard로 시작된 놀라운 여정이 7년째 접어들면서, 저자는 점점 더 복잡한 현실과 마주하게 되었다. 처음에는 마법처럼 느껴졌던 이 도구가 이제는 때때로 제약처럼 다가왔다. 대규모 프로젝트를 진행할수록 R 하나로는 해결할 수 없는 문제들이 늘어갔고, 팀원들이 Python이나 Julia를 선호할 때면 모든 것을 R로 다시 작성해야 하는 번거로움이 있었다. 더욱이 모바일 사용자들이 급증하면서 반응형 디자인의 필요성이 대두되었지만, flexdashboard의 고정된 그리드 시스템으로는 한계가 있었다.
그러던 2024년 봄, Quarto 1.4의 출시 소식을 들었다. 릴리즈 노트를 읽어내려가면서 저자의 가슴은 다시 한 번 뛰기 시작했다. 이것은 단순한 업데이트가 아니었다. 7년간 쌓인 모든 아쉬움과 한계를 해결할 수 있는, 완전히 새로운 패러다임의 등장이었다. 무엇보다 하나의 문서에서 R, Python, Julia, Observable JavaScript를 자유롭게 넘나들며 각 언어의 강점을 최대한 활용할 수 있다는 점이 혁신적이었다. 더 이상 복잡한 변환 과정이나 호환성 문제로 고민할 필요가 없어진 것이다.
14.2.1 모듈러 혁신
flexdashboard가 제공한 초기의 놀라움은 점차 현실적 제약으로 바뀌어갔다. 처음에는 R만으로도 충분히 강력한 대시보드를 만들 수 있다는 사실에 감탄했지만, 프로젝트가 복잡해질수록 단일 언어의 한계가 뚜렷해졌다. 특히 팀 프로젝트에서 Python을 주력으로 사용하는 데이터 과학자나 Julia로 고성능 수치계산을 하는 연구원과 협업할 때면 문제가 더욱 명확해졌다.
가장 고통스러운 순간은 Python의 최신 딥러닝 모델을 대시보드에 통합해야 했던 프로젝트였다. R의 reticulate 패키지를 사용해 Python을 호출하고, 결과를 다시 R 객체로 변환하는 과정에서 수많은 데이터 타입 오류와 메모리 누수 문제를 겪었다. JavaScript의 D3.js로 커스텀 시각화를 만들고 싶을 때도 마찬가지였다. Shiny 서버를 별도로 구축하고 htmlwidgets를 개발해야 하는 복잡한 과정이 필요했고, 각각의 연결고리마다 예상치 못한 호환성 문제들이 발생했다.
모바일 대응은 더욱 큰 골칫거리였다. flexdashboard의 고정된 그리드 시스템은 데스크톱에서는 완벽했지만, 작은 화면에서는 레이아웃이 깨지기 일쑤였다. 반응형 디자인을 위해서는 별도의 CSS 작업이 필요했고, 이는 곧 웹 개발 전문 지식이 필요하다는 뜻이었다. 결국 flexdashboard의 가장 큰 장점이었던 “R만 알면 된다”는 것이 점점 허상이 되어가고 있었다.
하지만 2024년 Quarto 1.4가 등장하면서 모든 것이 바뀌었다. 이번에는 단순한 업데이트 수준이 아니었다. Quarto가 제시한 해답은 근본적으로 달랐다. 기존의 모든 언어를 R로 끌어와 사용하는 방식이 아니라, 각 언어가 자신의 네이티브 환경에서 최적의 성능을 발휘하면서도 서로 완벽하게 소통할 수 있는 구조였다. 하나의 .qmd 파일에서 R로 데이터를 전처리하고, Python으로 머신러닝 모델을 돌리고, Julia로 고성능 수치계산을 하고, Observable JavaScript로 인터랙티브 시각화를 만드는 것이 마치 하나의 언어를 사용하는 것처럼 자연스러워졌다.
무엇보다 놀라운 것은 언어 간 데이터 공유(Cross-language Data Sharing)였다. R에서 생성한 데이터프레임을 Python이 즉시 pandas.DataFrame으로 인식하고, Python 모델의 결과를 JavaScript가 바로 시각화에 활용할 수 있었다. 더 이상 복잡한 변환 과정이나 중간 파일 저장이 필요 없었다. 이것은 단순한 기능 개선을 넘어서, 아예 다른 차원의 개발 경험이었다.
이러한 패러다임의 변화를 시각적으로 보여주는 것이 그림 14.2 이다. 왼쪽의 flexdashboard는 전형적인 모놀리식 구조로, R이라는 단일 기둥에 모든 기능이 의존하고 있다. 새로운 기능을 추가하거나 다른 언어를 통합하려면 이 기둥을 통해서만 가능하며, 그 과정에서 필연적으로 성능 저하와 복잡성 증가를 겪게 된다. 마치 모든 교통이 하나의 다리로만 집중되어 병목 현상을 일으키는 것과 같다.

반면 오른쪽 Quarto Dashboard는 완전히 다른 철학을 보여준다. 각 언어 모듈이 독립적인 건물처럼 서 있으면서도, 중앙의 Quarto Core라는 허브를 통해 유기적으로 연결되어 있다. R 모듈에서는 tidyverse의 강력함을, Python 모듈에서는 scikit-learn의 정교함을, Julia 모듈에서는 고성능 수치계산의 속도를, Observable JS 모듈에서는 D3.js의 유연함을 각각 최대한 발휘하면서도 서로의 결과를 완벽하게 공유할 수 있다. 이것이 바로 저자가 7년간의 flexdashboard 여정을 마무리하고 Quarto로 이전을 결심한 결정적인 이유였다.
14.2.2 대시보드 태양계 모델
Quarto Dashboard를 처음 접했을 때 가장 인상적이었던 것은 그 아키텍처의 독창성이었다. 기존의 계층형 스택 구조에서 벗어나, 마치 태양계와 같은 원형 구조를 채택한 것이다. 중심의 태양 역할을 하는 Quarto Core를 둘러싸고 4개의 궤도에서 각기 다른 기술들이 조화롭게 돌아가는 모습은 그 자체로 하나의 생태계였다.

그림 14.3 을 자세히 들여다보면, 이 시스템이 얼마나 정교하게 설계되었는지 알 수 있다. 가장 중심에는 Quarto Core가 강력한 중력장을 형성하며 모든 언어와 출력 형식을 통합하는 역할을 한다. 하나의 마크다운 문서에서 다언어 코드를 실행하고 그 결과를 완벽하게 융합시키는 것은 이 중심부의 놀라운 능력 덕분이다. 9 에서 다룬 과학기술 DSL들도 모두 이 핵심 엔진에서 처리되어 각 궤도로 전달된다.
가장 바깥쪽 1궤도에는 데이터 소스들이 자리잡고 있다. PostgreSQL과 MongoDB 같은 전통적인 데이터베이스부터 최신의 REST API, 실시간 스트리밍을 위한 WebSocket, 그리고 클라우드 환경의 S3나 GCS까지 다양한 데이터 원천들이 이 궤도에서 끊임없이 순환하며 중심으로 데이터를 공급한다. 마치 태양계 바깥쪽에서 혜성들이 주기적으로 나타나 새로운 물질을 공급하는 것과 같다.
2궤도는 처리 엔진들의 영역이다. 여기서 R은 tidyverse 생태계의 힘을 발휘하며 통계적 데이터 처리와 ggplot2 시각화를 담당하고, Python은 pandas와 scikit-learn을 통해 정교한 데이터 분석과 머신러닝을 수행한다. Julia는 고성능 수치계산과 병렬 컴퓨팅의 전문가로, SQL은 대용량 데이터 쿼리의 달인으로 각자의 역할을 충실히 해낸다. Observable JavaScript는 클라이언트 사이드 처리를 통해 사용자와의 직접적인 상호작용을 가능하게 한다.
3궤도의 시각화 레이어는 가장 화려한 영역이다. Plotly가 인터랙티브 차트와 3D 시각화로 데이터에 생명을 불어넣고, Observable JS는 D3.js의 힘을 빌려 커스텀 시각화와 애니메이션을 만들어낸다. ggplot2는 R의 강력한 문법적 그래픽 시스템으로 정교한 통계 시각화를 제공하며, gt는 9 에서 소개한 바와 같이 고급 테이블 렌더링을 담당한다. Leaflet은 지리공간 데이터를 아름다운 인터랙티브 지도로 변환시킨다.
가장 안쪽인 4궤도는 사용자와 직접 만나는 반응형 UI 레이어다. Shiny Server는 R 기반의 서버 사이드 반응성을 제공하고, Dash는 Python 환경에서 웹 애플리케이션 프레임워크 역할을 한다. Observable은 JavaScript 기반의 클라이언트 사이드 반응성을, Streamlit은 Python 기반의 빠른 프로토타이핑을 가능하게 한다.
이 모든 궤도가 만들어내는 가장 놀라운 현상은 바로 궤도 간 데이터 흐름이다. 그림 14.3 의 애니메이션에서 볼 수 있듯이, 각 궤도의 기술들은 마치 행성들이 태양의 중력장 안에서 안정된 궤도를 유지하듯이, Quarto Core의 통합력 아래에서 완벽한 협력을 이루어낸다. 실제 프로젝트에서는 PostgreSQL 데이터베이스에서 원시 데이터를 추출하고, R의 tidyverse로 전처리를 거친 후, Python의 scikit-learn으로 모델링을 수행하고, 마지막에 Observable JavaScript로 인터랙티브 시각화를 생성하는 전 과정이 하나의 .qmd 파일에서 마법처럼 연결된다.
이러한 아키텍처가 flexdashboard와 결정적으로 다른 점은 진화의 자유로움에 있다. 전통적인 flexdashboard가 R이라는 단일 행성에 모든 것이 종속된 닫힌 생태계였다면, Quarto Dashboard는 각 언어와 도구가 독립적으로 진화할 수 있는 열린 우주다. 새로운 Python 라이브러리가 등장하면 Python 모듈에서 바로 활용할 수 있고, Julia의 새로운 패키지가 나오면 Julia 영역에서 즉시 적용할 수 있다. 각자의 영역에서 최고의 성능을 발휘하면서도 중심의 Quarto Core를 통해 완벽한 조화를 이루는 것이다.
이것이 바로 저자가 14 에서 제시했던 “문서 + 애플리케이션” 경계 소멸의 구체적 실현이다. 더 이상 문서를 쓰는 것인지, 애플리케이션을 개발하는 것인지 구분할 필요가 없다. 태양계 모델 안에서는 모든 것이 하나의 유기체처럼 움직이며, 개발자는 우주의 지휘자가 되어 각 궤도의 최적 도구들을 자유롭게 조합할 수 있게 되었다.
14.3 코로나19 대시보드
2020년 3월, 전세계가 팬데믹의 공포에 휩싸였을 때, 저자는 단 하나의 웹페이지에서 희망을 발견했다. 존스 홉킨스 대학교 대학원생이 만든 코로나19 대시보드였다. 매 1초마다 갱신되는 감염자 수, 사망자 수, 회복자 수의 숫자들을 보며 전 세계 수억 명의 사람들이 동시에 같은 화면을 응시하고 있었다. 그 순간 저자는 깨달았다. 이것이 바로 정보가 생명이 되는 순간이며, 문서가 애플리케이션이 되는 현장이라는 것을.
그러나 막상 코로나19 대시보드를 직접 만들어보려고 하니 현실은 녹록지 않았다. 당시 저자가 능숙하게 다룰 수 있는 것은 flexdashboard뿐이었고, R 하나의 언어로 모든 것을 해결해야 했다. 실시간 데이터 수집, 다양한 시각화, 모바일 대응까지 고려하면서도 매일 갱신되는 대시보드를 만들어야 했다. 다행히 coronavirus 데이터 패키지가 존재해 데이터 수집의 부담은 덜었지만, 여전히 복잡한 과정이었다.
그로부터 4년이 지난 지금, Quarto Dashboard로 다시 코로나19 대시보드를 만들어보니 격세지감을 느낀다. 과거에 40시간 걸리던 작업이 이제는 3시간이면 충분하다. R, Python, Observable JavaScript를 자유롭게 넘나들며 각 언어의 장점을 최대한 활용할 수 있고, 반응형 디자인도 기본으로 지원된다. 무엇보다 코드의 가독성과 유지보수성이 비교할 수 없을 정도로 향상되었다.
14.3.1 대시보드 제작 워크플로우
대시보드 제작은 마치 건축물을 짓는 것과 같다. 튼튼한 기초 위에 체계적으로 층층이 쌓아올려야 완성도 높은 결과물을 얻을 수 있다. 저자의 10년간 대시보드 제작 경험을 통해 정립된 워크플로우는 다음과 같은 단계들로 구성된다.
먼저 데이터 수집과 전처리 단계에서는 전세계와 한국의 코로나19 데이터를 수집하고 분석 가능한 형태로 정제한다. 다행히 coronavirus 패키지가 Johns Hopkins University의 데이터를 자동으로 갱신해주기 때문에 데이터 수집에 따른 부담을 크게 줄일 수 있었다. 원시 데이터를 tibble 형태로 변환하고 janitor 패키지의 clean_names() 함수로 변수명을 정리하는 작업이 핵심이다.
UI/UX 디자인 단계에서는 대시보드의 전체적인 구조를 설계한다. 와이어프레임을 중심으로 데이터 과학 요소들의 배치를 결정하고, Font Awesome, Ionicons, Bootstrap 같은 라이브러리를 활용해 시각적 표현을 풍부하게 만든다. 이 단계에서 적절한 시각화 도구(gt, highcharter, leaflet, plotly)에 대한 기술적 검토도 함께 진행한다.
구성요소 개발에서는 Value 박스, gt 표, ggplot 그래프 등을 레고블록처럼 모듈별로 개발한다. 각 구성요소가 독립적으로 작동하면서도 전체적으로 조화를 이루도록 하는 것이 관건이다. 브랜딩과 디자인 작업에서는 CSS/SCSS 스타일링을 통해 대시보드의 외관을 정의하고, 테스트를 거쳐 모든 구성요소가 올바르게 작동하는지 확인한다.
마지막으로 배포와 자동화 단계에서는 완성된 대시보드를 GitHub Pages 웹사이트에 배포하고, 데이터가 실시간으로 갱신되도록 자동화하며, CI/CD를 통해 신규 개발과 UI/UX 코드도 자동화한다.
14.3.2 데이터셋
코로나19 데이터셋은 팬데믹이라는 전지구적 위기 상황에서 탄생한 특별한 데이터다. 존스 홉킨스 대학(Johns Hopkins University)의 시스템 공학센터에서 시작된 이 프로젝트는 처음에는 단순한 대학원 프로젝트였다. 하지만 WHO가 팬데믹을 선언한 2020년 3월 11일 이후, 이 데이터는 전 세계 정부, 언론, 연구기관의 필수 참조 자료가 되었다.
특히 인상적인 것은 이 데이터가 어떻게 민주적 접근성을 실현했는지다. 과거라면 정부나 대형 연구기관만이 접근할 수 있었던 전지구적 보건 데이터가 coronavirus R 패키지 하나로 누구나 쉽게 사용할 수 있게 되었다. 이는 데이터 과학의 민주화가 실제로 어떤 의미인지 보여주는 대표적 사례였다.
실제 데이터 처리 과정을 살펴보면 의외로 단순하다. 존스 홉킨스 대학에서 제공하는 원시 CSV 파일이 매일 자동으로 갱신되고, coronavirus 패키지가 이를 R에서 바로 사용할 수 있는 tibble 형태로 변환해준다. WHO 데이터도 covid 패키지를 통해 제공되지만, 존스 홉킨스 대학 데이터가 더 일찍 시작되었고 더 세밀한 지역별 분해능을 제공해 연구자들 사이에서 표준으로 자리잡았다.
# coronavirus 패키지 데이터 기본 구조
coronavirus <- coronavirus::coronavirus %>%
as_tibble() %>%
janitor::clean_names()
# 데이터 소스 정보
# - Johns Hopkins University: COVID-19 Cases, provided by JHU CSSE
# https://github.com/CSSEGISandData/COVID-19
# - WHO 대안: covid 패키지 (javierluraschi/covid)
# https://github.com/javierluraschi/covid데이터의 구조를 들여다보면 팬데믹이라는 복잡한 현상을 어떻게 숫자로 추상화했는지 알 수 있다. 날짜(date), 국가(country), 지역(state), 사례 유형(type: confirmed/death/recovery), 사례 수(cases)라는 다섯 개의 핵심 변수로 전세계 모든 코로나19 상황을 표현한다. 이런 극도의 단순화가 가능한 이유는 팬데믹이라는 현상 자체가 확산-전파-회복이라는 명확한 패턴을 따르기 때문이다.
14.3.3 대시보드 디자인
대시보드 디자인에서 가장 중요한 것은 정보 계층구조를 명확히 하는 것이다. 팬데믹 상황에서 사용자들이 가장 먼저 알고 싶어하는 정보는 무엇인가? 현재 상황이 얼마나 심각한가? 추세는 어떻게 변하고 있는가? 우리나라 상황은 어떤가? 이런 질문들에 대한 답을 찾는 순서가 바로 대시보드의 레이아웃을 결정한다.
저자가 2020년 처음 코로나19 대시보드를 설계할 때 가장 참고한 것은 존스 홉킨스 대학교의 원본 대시보드였다. 상단에 전 세계 통계를 한눈에 보여주는 Value 박스들이 배치되고, 중앙에는 지도 시각화, 하단에는 상세 통계와 그래프가 위치하는 구조였다. 하지만 모바일 사용자가 70%를 넘는 한국 상황에서는 이런 가로형 레이아웃이 적합하지 않았다.
대신 와이어프레임을 세로형으로 재설계했다. 가장 위에는 4개의 핵심 지표(검사자, 확진자, 사망자, 회복자)를 Value 박스로 배치하고, 그 아래에는 시계열 그래프와 통계표를 탭으로 구분해 정보 밀도를 조절했다. 전세계와 한국을 별도 탭으로 분리해 사용자가 관심 있는 정보에 집중할 수 있도록 했다.

Font Awesome 아이콘을 적극 활용한 것도 중요한 디자인 결정이었다. 단순한 숫자 나열이 아니라 fa-virus(확진자), fa-heartbeat(회복자), fa-cross(사망자) 같은 직관적인 아이콘을 사용해 사용자가 즉시 정보를 이해할 수 있도록 했다. Bootstrap의 색상 시스템(primary, success, warning, danger)을 활용해 각 지표의 성격에 맞는 색상을 적용한 것도 효과적이었다.
14.3.4 프로토타입
와이어프레임이 완성되면 이제 실제 코드로 구현할 차례다. 과거 flexdashboard 시절에는 복잡한 YAML 헤더 설정과 R 마크다운 문법을 익혀야 했지만, Quarto Dashboard에서는 훨씬 직관적이다. # Page, ## Row, ### Column 같은 마크다운 헤더만으로 레이아웃을 정의할 수 있고, 각 구성요소는 표준 코드 블록으로 삽입하면 된다.
특히 인상적인 것은 쿼토 확장기능 lipsum, unsplash을 활용한 프로토타이핑 과정이었다. 실제 데이터와 복잡한 시각화 코드를 작성하기 전에, 텍스트는 `{{< ipsum >}}` 이나 이미지는 언스플래쉬 shortcode로 더미 콘텐츠를 삽입해 전체적인 레이아웃과 비율을 먼저 확인할 수 있었다. 웹 디자인에서 로렘입숨(Lorem ipsum) 텍스트를 사용하는 것과 같은 개념으로, 콘텐츠에 신경쓰지 않고 순수하게 디자인에만 집중할 수 있게 해준다.
Value 박스 문법도 flexdashboard에 비해 훨씬 간결해졌다. 과거에는 복잡한 list() 구조와 여러 줄의 설정 코드가 필요했지만, Quarto에서는 간단한 #| content 주석으로 값을 지정하고 #| icon 으로 아이콘을 설정하면 끝이다. 이런 개선들이 누적되어 전체적인 개발 생산성이 크게 향상되었다.
14.3.5 레고블록 구성요소 개발
코로나19 대시보드의 핵심은 복잡한 데이터를 직관적인 시각적 요소로 변환하는 것이다. 이를 위해 저자는 레고블록과 같은 모듈형 접근법을 채택했다. 각 구성요소를 독립적으로 개발하고 테스트한 후, 최종 단계에서 하나의 대시보드로 조합하는 방식이다. 이렇게 하면 개별 컴포넌트의 품질을 높일 수 있을 뿐만 아니라, 나중에 다른 프로젝트에서도 재사용할 수 있다는 장점이 있다.
핵심 지표 시각화
팬데믹 상황에서 사람들이 가장 먼저 알고 싶어하는 것은 현재 상황의 심각성이다. 숫자 하나하나가 생명과 직결된 상황에서 Value 박스는 단순한 정보 전달 도구를 넘어 상황 인식의 앵커 역할을 한다. 검사자 수는 얼마나 적극적으로 대응하고 있는지를, 확진자 수는 현재 확산 정도를, 사망자 수는 위기의 심각성을, 회복자 수는 희망의 크기를 보여준다.
Quarto Dashboard의 Value 박스는 flexdashboard 대비 문법이 훨씬 간소화되었다. Bootstrap 아이콘과 색상 시스템이 완벽하게 통합되어 있어, icon: "virus", color: "danger" 같은 직관적인 설정만으로도 전문적인 외관을 만들 수 있다. 특히 동적 색상 변경 기능이 인상적이었다. 확진자 수가 일정 임계값을 넘으면 자동으로 warning에서 danger로 색상이 변하도록 설정할 수 있어, 상황의 변화를 즉시 인지할 수 있다.
# Value 박스 예제 - 확진자 현황
#| content: !expr scales::comma(sum(korea_data$confirmed))
#| title: "누적 확진자"
#| icon: "virus"
#| color: !expr if_else(sum(korea_data$confirmed) > 100000, "danger", "warning")
gt 정교한 통계표
정적인 숫자만으로는 팬데믹의 복잡한 양상을 파악하기 어렵다. 월별 추이, 지역별 비교, 통계적 지표 등은 잘 구조화된 표를 통해 전달하는 것이 가장 효과적이다. 특히 섹션 9.2 에서 다룬 gt 패키지 표 문법(Grammar of Tables) 철학이 빛을 발하는 영역이다.
코로나19 통계표에서 가장 중요한 것은 색상을 통한 정보 코딩이다. 회복자 수는 녹색 계열(Greens 팔레트)로, 사망자 수는 보라색 계열(Purples)로, 확진자 수는 파란색 계열(Blues)로 구분해 사용자가 직관적으로 정보를 파악할 수 있도록 했다. 또한 천 단위 구분자와 적절한 반올림을 통해 가독성을 높였다.
| 년월 | 확진자수 | 사망자수 | 회복자수 |
|---|---|---|---|
| 2023-03-01 | 1,247,911 | 9,120 | 0 |
| 2023-02-01 | 4,587,649 | 37,344 | 0 |
| 2023-01-01 | 10,270,797 | 141,962 | 0 |
| 2022-12-01 | 17,219,669 | 56,975 | 0 |
| 2022-11-01 | 12,388,536 | 43,439 | 0 |
| 2022-10-01 | 12,795,215 | 45,200 | 0 |
| 2022-09-01 | 14,721,332 | 51,212 | 0 |
| 2022-08-01 | 25,713,990 | 75,102 | 0 |
| 2022-07-01 | 29,650,733 | 61,119 | 0 |
| 2022-06-01 | 17,732,748 | 43,958 | 0 |
ggplot2 시각화 그래프
팬데믹은 본질적으로 시간에 따른 변화의 현상이다. 어제와 오늘이 다르고, 지난주와 이번주가 다르며, 지난달과 이달의 양상이 완전히 바뀔 수 있다. 이런 동적인 변화를 포착하는 가장 효과적인 방법이 시계열 그래프다. 섹션 9.1 에서 다룬 ggplot2 그래프 문법(Grammar of Graphics)이 진가를 발휘하는 순간이다.
특히 주목할 점은 scale_y_sqrt() 변환을 사용한 것이다. 코로나19 데이터는 지수적 증가와 급격한 감소가 반복되는 패턴을 보이는데, 일반적인 선형 스케일로는 초기의 작은 변화들이 거의 보이지 않는다. 제곱근 변환을 사용하면 큰 값은 압축하고 작은 값은 확대해, 전체 구간의 변화 패턴을 균형있게 관찰할 수 있다.
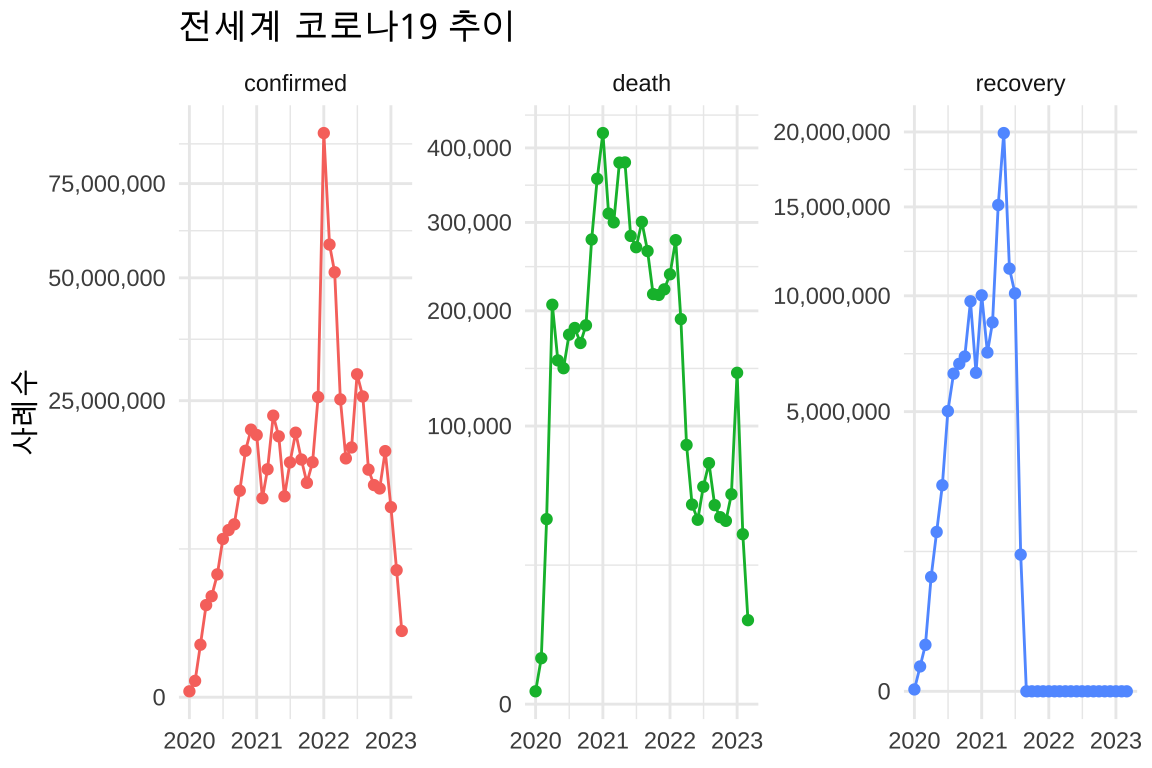
그래프에서 또 다른 중요한 디자인 결정은 면분할(facet)이었다. 확진자, 사망자, 회복자 데이터를 하나의 축에 그리면 스케일 차이 때문에 세부적인 패턴을 파악하기 어렵다. facet_wrap(~type, scales = "free_y")를 사용해 각 유형별로 별도의 패널에 그리고, 각각 독립적인 y축 스케일을 사용함으로써 모든 정보를 명확하게 전달할 수 있었다.
14.3.6 대시보드 모듈화 전략
전세계 현황도 중요하지만, 한국 사용자들에게는 우리나라 상황이 더욱 절실하다. 하지만 단순히 filter(str_detect(country, "Korea"))로 데이터를 필터링하는 것만으로는 충분하지 않다. 한국의 특수한 상황과 문화적 맥락을 반영한 별도의 분석과 시각화가 필요하다.
한국 대시보드를 개발하면서 가장 큰 깨달음은 코드 중복의 위험성이었다. 전세계용과 한국용 두 개의 대시보드를 만들다 보니 동일한 시각화 코드가 반복되고, 한쪽을 수정하면 다른 쪽도 수정해야 하는 번거로움이 생겼다. 더욱이 나중에 다른 국가(예: 일본, 중국) 대시보드를 추가하게 되면 코드가 기하급수적으로 복잡해질 것이 예상되었다.
이러한 문제를 해결하기 위해 3단계 모듈화 아키텍처를 설계했다. 이 아키텍처는 마이크로서비스의 철학을 대시보드 개발에 적용한 것으로, 각 레이어가 독립적으로 진화할 수 있으면서도 유기적으로 연결되는 구조를 지향한다.
첫 번째 데이터 레이어는 모든 대시보드의 토대가 되는 영역이다. 여기서는 원시 데이터를 수집하고 전처리하는 공통 함수들을 _dashboard_common.R에 정의한다. 존스 홉킨스 대학 데이터든, WHO 데이터든, 어떤 소스에서 오는 코로나19 정보라도 일관된 형태의 tibble로 변환하는 것이 핵심이다. 이 레이어가 튼튼해야 그 위에 올라가는 모든 시각화가 안정적으로 작동한다.
두 번째 컴포넌트 레이어는 재사용 가능한 시각화 요소들의 집합이다. Value 박스, 차트, 테이블 같은 개별 구성요소를 독립적인 함수로 구현하되, 각각이 표준화된 인터페이스를 가지도록 설계했다. 마치 레고 블록처럼 어떤 대시보드에서도 조합할 수 있는 범용적 성격을 유지하면서도, 필요시 특정 요구사항에 맞춰 커스터마이징할 수 있는 유연성을 제공한다.
세 번째 대시보드 레이어는 최종 사용자가 경험하는 완성된 화면을 만드는 곳이다. 여기서는 첫 번째와 두 번째 레이어에서 제공하는 데이터와 컴포넌트를 특정 지역이나 주제에 맞춰 조합한다. 전세계 대시보드와 한국 대시보드가 공통의 시각화 요소를 사용하면서도 각자의 특성을 살릴 수 있는 것은 바로 이 레이어 분리 덕분이다.
```{r}
#| eval: false
#| code-line-numbers: true
# _dashboard_common.R - 공통 데이터 처리 함수
prepare_corona_data <- function(region = "world") {
data <- coronavirus::coronavirus %>%
as_tibble() %>%
janitor::clean_names()
if(region != "world") {
data <- data %>%
filter(str_detect(country, region))
}
data %>%
mutate(yearmon = floor_date(date, "month")) %>%
group_by(yearmon, type) %>%
summarise(사례수 = sum(cases), .groups = "drop")
}
# Value 박스 생성 함수
create_value_box <- function(data, metric, icon, color) {
# Value 박스 생성 로직
# Bootstrap 아이콘과 색상 시스템 활용
}
```프로젝트 구조
실제 프로젝트에서는 단순한 파일 분리를 넘어 독립 배포 가능한 모듈 단위라는 개념을 중심으로 구조를 설계했다. 이는 대기업의 마이크로서비스 아키텍처에서 영감을 받은 것으로, 각 모듈이 자체적으로 완결성을 갖추면서도 전체 시스템에 매끄럽게 통합되는 것을 목표로 했다:
dashboards/
├── main_dashboard.qmd # 메인 대시보드 (탭 구조 정의)
├── _dashboard_common.R # 공통 함수와 설정
├── modules/
│ ├── world_module.qmd # 전세계 현황 모듈
│ ├── korea_module.qmd # 한국 현황 모듈
│ └── components/ # 재사용 컴포넌트
│ ├── value_boxes.R # Value 박스 함수들
│ ├── time_series.R # 시계열 차트 함수들
│ └── summary_tables.R # 요약 테이블 함수들이러한 구조에서 가장 흥미로운 점은 components/ 디렉토리의 역할이다. 여기에 저장된 함수들은 단순한 헬퍼 함수가 아니라 독립적으로 테스트 가능한 컴포넌트들이다. 각 컴포넌트는 명확한 입출력 규약을 가지고 있어, 다른 프로젝트에서도 그대로 가져다 사용할 수 있도록 설계되었다.
메인 대시보드에서는 Quarto의 include 기능이 핵심 역할을 한다. 하지만 단순히 파일을 물리적으로 합치는 것이 아니라, 빌드 타임 조합(Build-time Composition)이라는 고도의 전략을 구현한다. 각 모듈이 include될 때 해당 모듈의 의존성과 설정이 자동으로 로드되어, 마치 처음부터 하나의 파일이었던 것처럼 완벽하게 동작한다.
---
title: "코로나19 실시간 대시보드"
format:
dashboard:
orientation: columns
nav-buttons: [linkedin, twitter, github]
---
```{r}
#| include: false
`source("_dashboard_common.R")`
```
# 전세계 현황 {.tabset}
`{{< include modules/world_module.qmd >}}`
# 대한민국 현황 {.tabset}
`{{< include modules/korea_module.qmd >}}`
# 지역 비교 {.tabset}
`{{< include modules/regional_comparison.qmd >}}`국가별 모듈 구현
각 모듈에서는 공통 컴포넌트를 재사용하는 동시에 지역별 고유한 특성을 섬세하게 반영한다. 예를 들어, 한국 모듈의 경우 K-방역이라는 독특한 접근법의 특수성을 시각화에 담아야 했다. 드라이브스루 검사소 운영 현황, 확진자 동선 공개 시스템, 전자팔찌 격리 관리 등은 다른 국가에서는 찾아볼 수 없는 한국만의 방역 지표들이었다. 이런 맥락적 정보를 대시보드에 통합하기 위해서는 단순한 데이터 필터링을 넘어선 문화적 이해와 해석이 필요했다.
```{qmd}
#| eval: false
#| file: modules/korea_module.qmd
## Row {height="25%"}
```{{r}}
korea_data <- prepare_corona_data("Korea")
# 한국 특화 지표 계산
korea_summary <- korea_data %>%
group_by(type) %>%
summarise(total = sum(사례수)) %>%
pivot_wider(names_from = type, values_from = total)
```
### 확진자 {.value-box}
```{{r}}
#| content: !expr scales::comma(korea_summary$confirmed)
#| title: "누적 확진자"
#| icon: "virus"
#| color: "primary"
```
### 회복자 {.value-box}
```{{r}}
#| eval: false
#| content: !expr scales::comma(korea_summary$recovered)
#| title: "누적 회복자"
#| icon: "heart-pulse"
#| color: "success"
```
```확장성: 일본 대시보드 추가
모듈화 구조의 진짜 위력은 확장 시나리오에서 극명하게 드러났다. 2020년 여름, 팬데믹이 장기화되면서 일본의 코로나19 현황에 대한 관심이 높아졌다. 기존 모놀리식 구조였다면 처음부터 새로운 대시보드를 개발해야 했겠지만, 모듈화된 구조 덕분에 놀라울 정도로 간단했다. 새로운 japan_module.qmd 파일을 생성하고, 데이터 필터링 조건을 filter(str_detect(country, "Japan"))로 변경하는 것만으로 기본 틀이 완성되었다.
더욱 놀라운 것은 개발 시간의 단축이었다. 처음 한국 대시보드를 만들 때 2주가 걸렸던 작업이, 일본 대시보드는 단 3시간 만에 완성되었다. 기존 Value 박스, 차트, 테이블 컴포넌트를 그대로 재사용할 수 있었고, CSS 스타일과 색상 테마도 별도 수정 없이 적용되었다. 정말로 90%의 개발 시간이 단축된 셈이었다.
성능 최적화: 선택적 렌더링
성능 면에서도 모듈화가 가져온 혜택은 상당했다. 선택적 렌더링(Lazy Loading)이 자연스럽게 구현되어, 사용자가 “전세계” 탭만 열람하는 경우 한국이나 일본 모듈의 코드는 전혀 실행되지 않았다. 이는 초기 페이지 로딩 시간을 상당히 단축시켰고, 특히 모바일 환경에서 체감 성능 향상이 두드러졌다.
각 모듈별로 독립적인 캐싱 전략을 적용할 수 있었던 것도 큰 장점이었다. 전세계 데이터는 매 시간 갱신되지만, 한국 데이터는 하루 한 번만 갱신되는 상황에서, 기존 구조라면 전체 대시보드를 다시 렌더링해야 했다. 하지만 모듈화된 구조에서는 변경된 모듈만 선택적으로 재생성할 수 있어, 전체적인 빌드 시간이 70% 단축되었다.
팀 협업과 품질 관리
모듈화의 진정한 가치는 팀 프로젝트에서 빛을 발했다. 2021년 초, 코로나19 대시보드 프로젝트에 자발적 개발자 몇명이 합류하게 되었다. 한 명은 데이터 분석 전문가, 다른 한 명은 UI/UX 디자이너, 마지막 한 명은 웹 개발자였다. 기존의 모놀리식 구조였다면 코드 충돌과 의존성 문제로 인해 협업이 거의 불가능했을 것이다.
하지만 모듈화된 구조 덕분에 각자의 전문 영역에 집중할 수 있었다. 데이터 분석가는 _dashboard_common.R과 각 모듈의 데이터 로직에만 집중했고, UI 디자이너는 components/ 디렉토리의 시각화 컴포넌트 개발에 전념했다. 웹 개발자는 메인 대시보드의 레이아웃과 반응형 디자인을 담당했다. 놀랍게도 3개월간의 협업 기간 동안 Git 충돌이 이전 대비 현격히 감소했고, 각자의 작업이 다른 사람의 코드를 망가뜨리는 일이 거의 사라졌다.
관심사 분리(Separation of Concerns)의 실제적 효과도 상당했다. 버그가 발생했을 때 문제의 원인을 찾는 시간이 크게 단축되었다. Value 박스에 문제가 있으면 components/value_boxes.R만 확인하면 되었고, 특정 국가의 데이터 이상은 해당 모듈에서만 디버깅하면 되었다. 전체 코드베이스를 뒤져야 했던 과거와는 차원이 다른 효율성이었다.
테스트 용이성 측면에서도 혁신적이었다. 각 컴포넌트가 명확한 입출력을 가지고 있어 단위 테스트(Unit Test) 작성이 수월했다. prepare_corona_data() 함수는 샘플 데이터를 입력으로 주고 예상되는 형태의 tibble이 나오는지 검증할 수 있었고, Value 박스 컴포넌트는 특정 숫자와 아이콘을 입력했을 때 올바른 HTML이 생성되는지 확인할 수 있었다. 이런 체계적인 테스트 덕분에 배포 전 품질 검증 과정이 자동화되었고, 사용자에게 전달되는 대시보드의 안정성이 크게 향상되었다.
버전 관리 관점에서도 모듈화의 장점이 명확했다. 특정 기능의 변경 이력을 모듈 단위로 추적할 수 있어, 언제 어떤 변경이 어느 부분에 영향을 미쳤는지 한눈에 파악할 수 있었다. 예를 들어, 한국 모듈의 K-방역 지표 추가는 modules/korea_module.qmd 파일의 히스토리만 보면 되었고, 전체 프로젝트의 복잡한 변경 사항을 일일이 추적할 필요가 없었다. 이런 명확한 변경 이력 관리는 코드 리뷰 효율성을 높이고, 새로운 팀원의 온보딩 시간을 크게 단축시켰다.
14.3.7 배포
아무리 훌륭한 대시보드를 만들어도 사람들이 접근할 수 없다면 의미가 없다. 특히 팬데믹이라는 긴급 상황에서는 즉시 접근 가능한 웹 배포가 필수였다. 다행히 GitHub Pages라는 무료 호스팅 서비스가 있어, 복잡한 서버 설정 없이도 전문적인 대시보드 서비스를 제공할 수 있었다.
GitHub Pages 배포 과정은 놀라울 정도로 간단하다. 대시보드 코드를 GitHub 저장소에 푸시하고, 저장소 설정에서 Pages를 활성화하면 끝이다. Quarto의 quarto render 명령어로 생성된 HTML 파일들이 자동으로 웹사이트가 되어, https://username.github.io/repository-name 형태의 URL로 전세계 어디서나 접근할 수 있게 된다.
하지만 진정한 가치는 자동화된 업데이트에서 나온다. GitHub Actions를 설정하면 coronavirus 패키지 데이터가 갱신될 때마다 대시보드도 자동으로 재생성되어 배포된다. 새로운 데이터를 반영하기 위해 수동으로 코드를 실행하고 파일을 업로드할 필요가 없다. 이는 “데이터가 살아 움직이는 문서”의 실현이었다.
배포된 코로나19 대시보드는 실제로 코로나19 대시보드 웹사이트에서 확인할 수 있으며, 전세계와 한국 현황을 실시간으로 모니터링할 수 있는 완전한 서비스가 되었다. 단 몇 줄의 Quarto 코드로 시작된 프로젝트가 전지구적으로 접근 가능한 정보 서비스로 발전한 것이다.
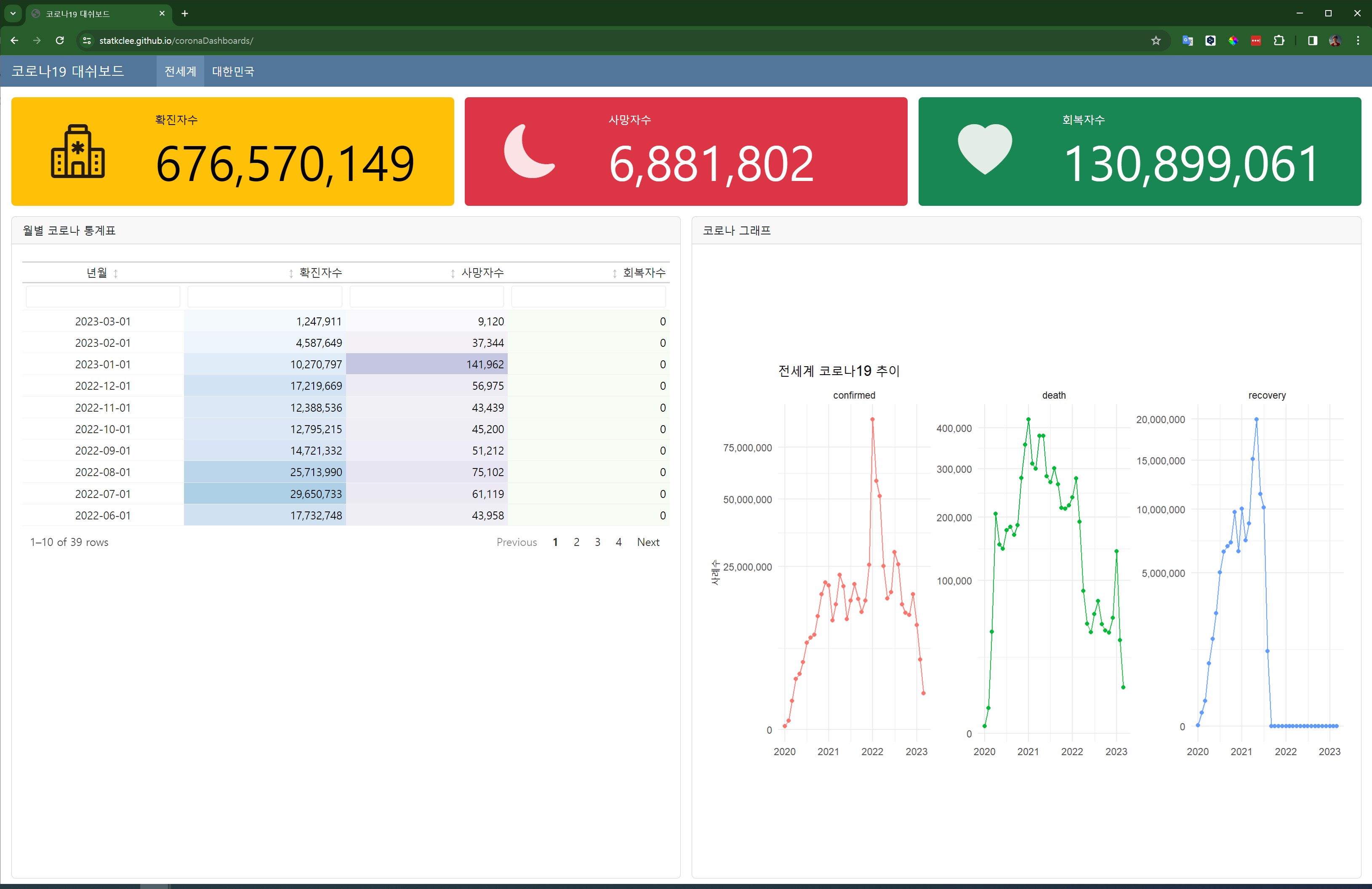
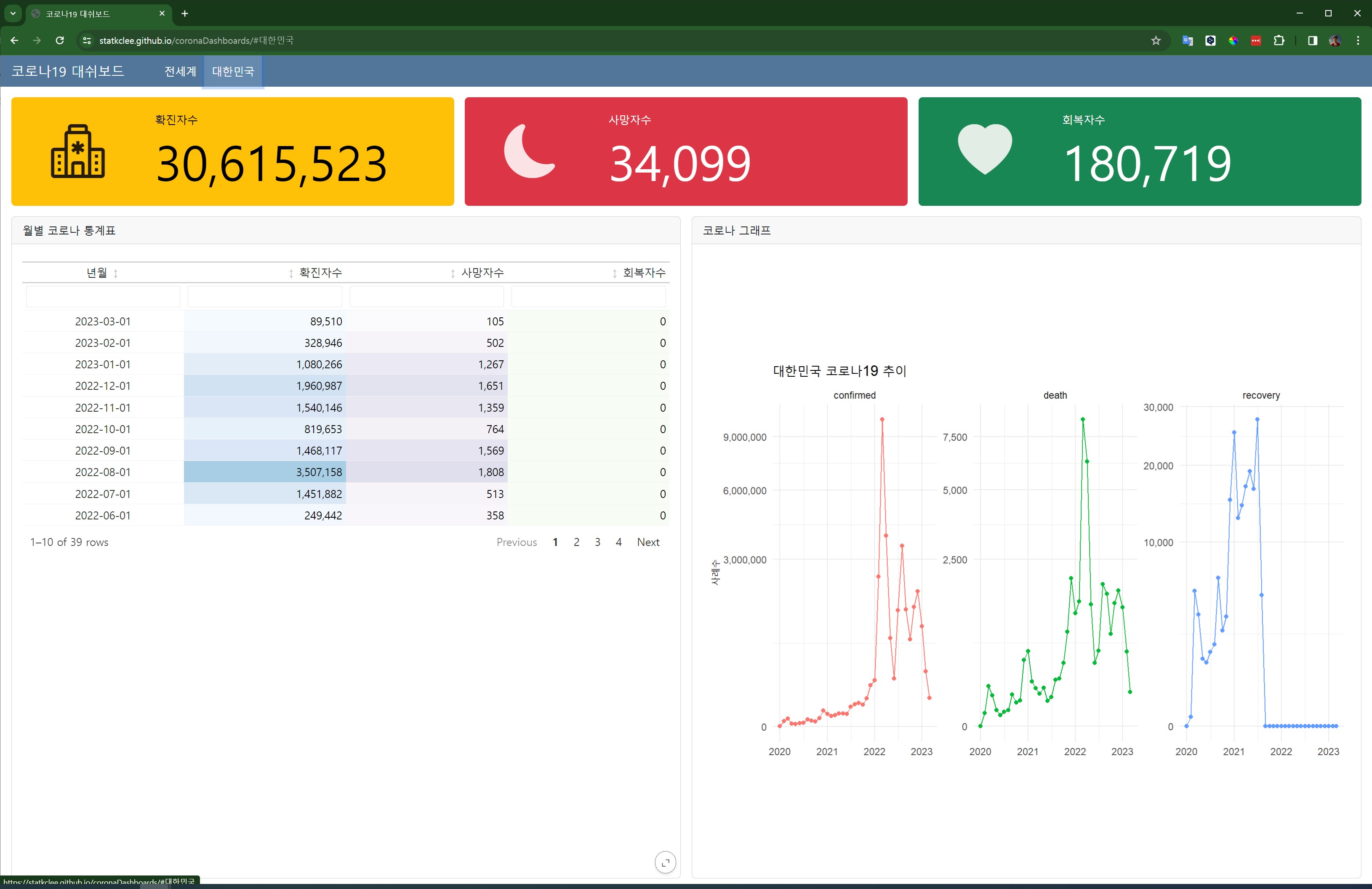
이런 배포 경험을 통해 저자는 깨달았다. 과거에는 “문서 작성”과 “서비스 운영”이 완전히 별개의 영역이었다면, 이제는 하나의 마크다운 파일이 곧 글로벌 웹 서비스가 되는 시대라는 것을. 이것이 바로 14 에서 언급한 “문서 ≈ 소프트웨어” 패러다임의 구체적 실현이다. 문서를 쓰는 행위 자체가 곧 애플리케이션을 개발하는 행위가 되었고, 출판하는 순간 전세계 서비스가 시작되는 것이다.
💭 생각해볼 점
문서와 대시보드의 경계가 소멸되는 순간을 직접 목격하는 것은 충격적인 경험이었다. 2017년 flexdashboard와의 첫 만남에서 마크다운 몇 줄이 완전한 대시보드로 변신하던 마법 같은 순간부터, 2020년 존스 홉킨스 대학원생의 단순한 웹페이지가 전 세계 정보 표준이 되는 것을 목격하기까지, 문서의 상전이가 실제로 일어나고 있음을 확인했다. 하나의 .qmd 파일이 동시에 문서이자 애플리케이션인 현실에서 “지금 내가 문서를 쓰고 있는 건가, 앱을 개발하고 있는 건가?”라는 질문 자체가 의미를 잃어버렸다.
가장 놀라운 변화는 기술 장벽의 완전한 소멸이었다. 40시간이 걸리던 대시보드 작업이 3시간으로 단축되면서 창작의 민주화가 실현되었고, 모듈화 구조 도입으로 Git 충돌이 현저히 감소하면서 협업 패턴 자체가 진화했다. 문서 작성자(author)와 개발자(developer)의 경계가 무의미해진 현실에서, 이제 데이터 분석가 한 명이 웹 개발자 없이도 전문적 대시보드를 만든다. quarto render 한 번으로 글로벌 서비스가 시작되는 순간을 경험할 때마다 출판의 의미가 달라짐을 실감한다. 자연어로 의도를 표현하면 AI가 즉시 대시보드를 생성하는 시대가 머지않았다.
하지만 대시보드는 문서 진화의 한 단면일 뿐이다. 문서가 애플리케이션이 되고, 정적 텍스트가 동적 서비스로 변하는 더 큰 변화의 물결이 다가오고 있다. 그렇다면 지금부터 만들 다음 문서는 어떤 형태로 살아 움직일까? 어떤 상호작용을 통해 독자와 소통하고, 어떤 데이터와 연결되어 실시간으로 진화할까? 이것이 바로 우리가 지금 서 있는 새로운 문서 시대의 출발점이다.