| 상황1 | 작업 유형 | 실행 방식 | 주요 특징 | 위험도2 |
|---|---|---|---|---|
| reactive() | ||||
| 데이터 필터링 | 변환 | 지연 평가 | 캐싱, 재사용 | 낮음 |
| 통계 계산 | 연산 | 지연 평가 | 캐싱, 재사용 | 낮음 |
| 차트 데이터 준비 | 준비 | 지연 평가 | 캐싱, 재사용 | 낮음 |
| ML 모델 학습 | 학습 | 지연 평가 | 캐싱, 재사용 | 중간 |
| observe() | ||||
| 파일 저장 | 저장 | 즉시 실행 | 부수효과 | 높음 |
| 데이터베이스 업데이트 | 갱신 | 즉시 실행 | 부수효과 | 높음 |
| 로그 기록 | 추적 | 즉시 실행 | 부수효과 | 중간 |
| 알림/이메일 발송 | 통신 | 즉시 실행 | 부수효과 | 높음 |
| 실시간 모니터링 | 감시 | 즉시 실행 | 부수효과 | 중간 |
| 외부 API 호출 | 통신 | 즉시 실행 | 부수효과 | 높음 |
| 1 reactive()는 값을 반환하고 캐싱하여 성능을 최적화합니다. | ||||
| 2 위험도는 외부 의존성과 실패 가능성을 기준으로 평가됩니다. | ||||
15 반응형 문서
2023년 3월, OpenAI가 GPT-4를 발표하는 데모에서 인상적인 장면이 있었다. 개발자가 손으로 그린 웹사이트 스케치 사진을 GPT-4에 보여주자, AI가 실시간으로 HTML 코드를 생성하기 시작했다. 그런데 더 놀라운 것은 그 다음이었다. 생성된 코드가 바로 실행되어 완전히 작동하는 웹사이트가 되었다.
이것이 반응형 문서(Reactive Document)의 진정한 모습이다. 사용자의 요청에 즉시 반응하고, 코드를 실행하며, 결과를 시각화하고, 다시 사용자의 피드백을 받아 개선하는 살아있는 문서.
전통적인 문서는 죽어있다. 한 번 작성되면 그대로 고정된다. 하지만 반응형 문서는 살아 숨쉰다. 사용자가 슬라이더를 움직이면 그래프가 바뀌고, 드롭다운을 선택하면 표가 업데이트되며, 새로운 데이터가 들어오면 자동으로 분석 결과가 갱신된다.
15.1 반응형 문서의 진화
반응형 문서는 하루아침에 만들어진 개념이 아니다. 45년이 넘는 진화의 역사는 인간의 근본적 욕구에서 시작됐다. 즉각적인 피드백과 직관적인 상호작용에 대한 갈망이 기술 발전의 원동력이었고, 각 시대마다 기술적 한계를 극복하려는 끊임없는 노력이 혁신을 낳았다.

반응형 문서의 진화를 관통하는 세 가지 핵심 동력이 있다. 인지적 부담 감소는 복잡한 계산과 반복 작업으로부터의 해방을 의미한다. 사용자는 본질적인 사고에 집중하고 싶어했다. 실시간 탐색은 변화를 가했을 때 즉시 결과를 확인하려는 욕구다. “만약 이렇게 하면 어떻게 될까?”라는 질문에 바로 답을 얻고 싶어했다. 접근성 민주화는 전문가의 도구를 일반 사용자도 쓸 수 있게 만드는 것이다. 기술의 진입 장벽을 낮춰 더 많은 사람이 혜택을 누리게 하려 했다.
15.1.1 자동계산 혁명
1970년대 말, 비즈니스 분석은 극도로 번거로운 작업이었다. 하나의 숫자가 바뀌면 손으로 모든 계산을 다시 해야 했고, 실수라도 하면 처음부터 다시 시작해야 했다. Dan Bricklin이 하버드 비즈니스 스쿨에서 경험한 이 고통이 VisiCalc의 출발점이었다.
VisiCalc의 =A1+B1 공식은 단순해 보이지만 혁명적이었다. 인지적 부담을 획기적으로 줄였다. 이제 사용자는 계산 과정이 아닌 비즈니스 로직에만 집중하면 됐다. 실시간 탐색도 가능해졌다. A1 값을 바꾸면 연결된 모든 셀이 즉시 업데이트됐다. 민주화 효과도 컸다. 프로그래밍을 모르는 회계사도 복잡한 재무 모델을 만들 수 있게 됐다.
하지만 VisiCalc은 한계가 있었다. 텍스트 기반 인터페이스는 직관적이지 않았고, 데이터 시각화 기능도 부족했다. 무엇보다 Apple II에서만 구동되는 제약이 있었다. 이러한 한계가 PC 시대의 새로운 혁신을 부르고 있었다.
15.1.2 PC 킬러 앱: 로터스 1-2-3
1981년 IBM PC가 등장하면서 개인용 컴퓨터 시장이 폭발적으로 성장했다. 하지만 IBM PC에는 VisiCalc이 없었다. 로터스 개발사는 이 기회를 포착했다. Mitch Kapor가 이끈 로터스 팀은 단순히 VisiCalc을 IBM PC로 이식하는 것이 아니라, 완전히 새로운 개념의 통합 소프트웨어를 만들었다.
로터스 1-2-3은 혁명적이었다. 이름에서 알 수 있듯이 세 가지 기능을 통합했다: 스프레드시트(1) + 그래프(2) + 데이터베이스(3). 인지적 부담을 획기적으로 줄였다. 이전에는 데이터 입력, 차트 작성, 데이터베이스 관리를 위해 각각 다른 소프트웨어를 사용해야 했지만, 이제 하나의 프로그램에서 모든 작업을 할 수 있게 됐다. 실시간 탐색도 새로운 차원에 도달했다. VisiCalc보다 5배 빠른 속도로 대용량 데이터를 처리할 수 있었고, 매크로 기능을 통해 복잡한 작업을 자동화할 수 있었다. IBM PC 대중화와 함께 기업의 모든 부서로 스프레드시트가 확산됐다.
로터스 1-2-3의 성공은 폭발적이었다. 1983년 출시 첫 해에 VisiCalc을 추월했고, 1988년까지 스프레드시트 시장의 80%를 장악했다. 로터스 1-2-3은 단순히 소프트웨어가 아니라 IBM PC 킬러 앱이 됐다. “로터스를 쓰기 위해 PC를 산다”는 말이 나올 정도였다. 기업들은 로터스 1-2-3 때문에 IBM PC를 도입했고, 이는 개인용 컴퓨터 시장 전체의 성장을 이끌었다.
하지만 로터스의 성공에는 치명적인 함정이 숨어있었다. DOS 환경에서 압도적 우위에 안주한 나머지, 새로운 패러다임의 변화를 놓쳤다. 1980년대 말 Windows가 등장하면서 그래픽 사용자 인터페이스(GUI) 시대가 열렸지만, 로터스는 여전히 텍스트 기반 인터페이스에 머물렀다. 이러한 전략적 실수가 다음 혁신자에게 기회를 내어주게 됐다.
15.1.3 시각적 직관성 도약
1985년, Microsoft가 Excel을 출시했을 때 로터스 1-2-3은 이미 시장을 장악하고 있었다. 하지만 Microsoft는 정면 승부를 피했다. DOS 시장에서는 로터스와 경쟁하지 않고, 새로 등장한 Macintosh와 Windows 플랫폼에 집중하는 우회 전략을 택했다.
Excel의 진짜 혁신은 그래픽 사용자 인터페이스(GUI)의 도입이었다. 로터스 1-2-3이 여전히 키보드 명령어에 의존할 때, Excel은 마우스와 시각적 인터페이스로 데이터 조작 방식을 근본적으로 바꿨다. 인지적 부담을 혁신적으로 줄였다. 복잡한 키보드 조합 대신 메뉴와 아이콘을 클릭하면 됐고, 드래그 앤 드롭으로 셀을 복사할 수 있었다. 실시간 탐색도 새로운 차원에 도달했다. 차트가 데이터와 완전히 연동되어 숫자를 바꾸면 그래프가 즉시 변했고, 시각적 피드백이 훨씬 직관적이었다. 복잡한 명령어를 외울 필요 없이 누구나 쉽게 스프레드시트를 배울 수 있게 됐다.
Microsoft의 전략은 시간이 지나면서 빛을 발했다. 1990년 Windows 3.0이 대성공을 거두면서 GUI 환경이 대중화됐다. 로터스는 뒤늦게 윈도우용 버전을 출시했지만 이미 때는 늦었다. Excel은 윈도우와 완벽한 통합, 다른 오피스 프로그램과의 연동 등을 무기로 시장을 역전시켰다. 1993년에는 Excel이 로터스 1-2-3을 추월했다.
로터스 1-2-3의 몰락은 기술 역사상 중요한 교훈을 남겼다. 현재의 성공에 안주하면 패러다임 변화를 놓칠 수 있다는 것이다. 하지만 여전히 개인용 도구의 한계는 남아있었다. 여러 사람이 동시에 상호작용할 수는 없었고, 분석 결과를 공유하려면 파일을 복사해서 보내야 했다. 이런 제약이 웹 시대의 새로운 요구를 만들어냈다.
15.1.4 웹 기반 상호작용 탄생
2000년대 말, 웹 2.0 시대가 열렸지만 데이터 분석은 여전히 개인적인 작업이었다. 통계학자들은 R로 뛰어난 분석을 했지만, 결과를 다른 사람들과 공유하기 어려웠다. Joe Cheng이 개발한 R Shiny는 이 문제를 해결했다.
Shiny는 인지적 부담을 혁신적으로 줄였다. JavaScript나 HTML을 몰라도 웹 애플리케이션을 만들 수 있게 했다. 실시간 탐색은 새로운 차원에 도달했다. 슬라이더를 움직이면 그래프가 실시간으로 변하고, 여러 사용자가 동시에 같은 분석을 탐험할 수 있게 됐다. 통계학자의 분석 도구가 웹을 통해 누구나 사용할 수 있는 애플리케이션이 됐다.
Shiny의 성공은 다른 언어 생태계에도 영감을 줬다. R 중심의 반응형 환경이 다른 언어로 확산될 필요성이 대두됐다.
15.1.5 다언어 생태계 번영
R Shiny가 보여준 가능성에 영감을 받아, Python과 JavaScript 진영에서도 비슷한 도구들이 등장했다. Streamlit(Python)과 Observable(JavaScript)이 대표적이다. 이들은 각 언어의 장점을 살린 반응형 도구를 제공했다.
인지적 부담 감소에서 이들의 접근법은 달랐다. Streamlit은 “스크립트가 곧 앱”이라는 철학으로 기존 Python 코드를 거의 그대로 사용할 수 있게 했다. Observable은 노트북 형태로 JavaScript 코드를 셀 단위로 실행하며 즉시 결과를 보여줬다. 실시간 탐색도 언어별 특성을 반영했다. Python의 데이터 과학 라이브러리들과 JavaScript의 D3.js 같은 시각화 도구가 반응형으로 연결됐다. 이를 통해서 각 언어에 익숙한 개발자들이 쉽게 반응형 앱을 만들 수 있게 됐다.
노트Quarto 반응형 생태계 언어별 통합 현황
완전 통합: R Shiny와 Python Shiny는 Quarto 내부에서 server: shiny 옵션을 통해 완벽하게 통합된다. 마크다운 문서에서 바로 반응형 웹 애플리케이션으로 변환되며, Quarto의 모든 출력 형식(HTML, PDF, 프레젠테이션)을 지원한다.
부분 통합: Julia는 ojs_define()을 통한 데이터 전달만 가능하며, 완전한 반응형 프로그래밍은 지원되지 않는다. JavaScript/OJS는 브라우저 기반 반응성을 제공하지만 서버 사이드 계산에는 제약이 있다.
별도 환경: Streamlit(Python)과 Pluto.jl(Julia)은 각각 독립적인 반응형 환경을 제공하지만, Quarto 생태계 밖에서 작동한다. 이런 경우 “한 번 쓰고 어디서나 배포(Write once, render everywhere)” 철학을 온전히 구현할 수 없으며, 문서와 앱의 융합이라는 Quarto의 핵심 가치를 활용하기 어렵다.
하지만 여전히 한 가지 언어로만 작업해야 한다는 제약이 있었다. 연구 보고서를 쓰다가 중간에 인터랙티브 요소를 넣고 싶어도 별도 앱을 만들어야 했다. 이런 불편함이 문서와 앱을 융합하려는 시도를 낳았다.
15.1.6 문서-앱 경계 소멸
Quarto 등장은 문서 작성 패러다임을 바꿨다. 마크다운으로 글을 쓰다가 중간에 server: shiny만 추가하면 그 문서가 인터랙티브 웹 애플리케이션이 됐다. 논문, 보고서, 프레젠테이션, 웹앱이 하나의 소스에서 나올 수 있게 됐다.
인지적 부담을 줄이는 방식이 획기적이었다. 문서를 쓸 때와 앱을 만들 때의 사고 과정을 분리할 필요가 없어졌다. 글을 쓰듯 앱을 만들고, 앱을 만들듯 문서를 작성할 수 있게 됐다. 실시간 탐색도 문서 안에서 자연스럽게 일어났다. 독자는 텍스트를 읽으면서 중간중간 나오는 인터랙티브 요소를 조작할 수 있었다. 복잡한 웹 개발 없이도 자신의 연구를 인터랙티브하게 공유할 수 있게 됐다.
그러나 여전히 코딩 지식이 필요했다. 아이디어를 코드로 구현하는 과정은 여전히 기술적 장벽이 남아있었다. 이 한계를 뛰어넘을 새로운 혁신이 필요했다.
15.1.7 AI 협업 시대
OpenAI의 GPT-4 데모는 충격적이었다. 손으로 그린 웹사이트 스케치를 보여주자 AI가 실시간으로 HTML 코드를 생성했고, 그 코드가 바로 작동하는 웹사이트가 됐다. 아이디어에서 실행까지의 시간이 거의 사라졌다.
인지적 부담의 감소가 극단적 수준에 도달했다. 이제 프로그래밍 언어를 배울 필요도, 복잡한 라이브러리를 익힐 필요도 없어졌다. 자연어로 의도를 설명하면 AI가 코드를 생성했다. 실시간 탐색은 대화형으로 진화했다. “이 버튼을 파란색으로 바꿔줘”, “그래프를 더 크게 만들어줘” 같은 요청에 AI가 즉시 반응했다. 기술적 배경이 전혀 없는 사람도 복잡한 인터랙티브 애플리케이션을 만들 수 있게 됐다.
이제 남은 과제는 이런 AI 협업을 더욱 자연스럽고, 가성비있고, 빠르고, 직관적으로 만드는 것이었다.
15.1.8 완전 자율 반응형 시스템
현재 AI 네이티브 반응형 시스템의 시작점에 있다. “매출이 왜 갑자기 떨어졌지?”라는 자연어 질문에 AI가 데이터를 분석하고, 시각화하며, 인사이트를 제공하는 완전 자율 시스템이 현실화되고 있다.
인지적 부담은 거의 사라지고 있다. 사용자는 궁금한 것을 자연어로 물어보기만 하면 된다. 실시간 탐색은 대화의 형태로 일어난다. AI와 질답을 주고받으며 점점 더 구체적이고 정확한 분석에 도달할 수 있다. 데이터 분석과 시각화의 모든 혜택을 기술적 지식 없이도 누릴 수 있는 시대가 왔다.
15.2 반응형 프로그래밍 철학
반응형 문서의 아키텍처는 전통적 문서와 근본적으로 다른 구조를 가진다. 그림 15.2 에서 보듯이, 사용자의 입력이 단순히 화면에 표시되는 것이 아니라 복잡한 데이터 처리 파이프라인을 거쳐 실시간으로 결과를 생성한다. 사용자가 슬라이더를 움직이거나 드롭다운을 선택하는 순간, 이 변화는 즉시 데이터 계층으로 전파되고, 분석 엔진을 거쳐 시각화 계층에까지 영향을 미친다.

이러한 구조의 핵심은 각 계층 간의 느슨한 결합(Loose Coupling)과 강한 응집(Strong Cohesion)이다. UI 계층은 데이터의 구체적인 형태나 처리 방식을 알 필요 없이 단지 변화를 알리기만 하면 되고, 데이터 계층은 UI의 세부사항을 몰라도 자신의 역할에만 집중할 수 있다. 이는 시스템의 각 부분이 독립적으로 발전하면서도 전체적으로는 완벽하게 동기화될 수 있게 만든다.
무엇보다 중요한 것은 이 모든 과정이 개발자의 명시적 제어 없이도 자동으로 일어난다는 점이다. 전통적 시스템에서는 개발자가 “언제, 무엇을, 어떻게” 업데이트할지 모두 관리해야 했지만, 반응형 아키텍처에서는 시스템이 의존성을 추적하고 변화를 전파하는 모든 과정을 담당한다.
15.2.1 사고 패러다임 전환
반응형 프로그래밍은 단순한 기술적 변화가 아니다. 문제를 바라보는 근본적 사고 방식의 전환이다. 전통적 명령형 프로그래밍이 “어떻게(How) 해야 하는가”에 초점을 맞춘다면, 반응형은 “무엇을(What) 원하는가”에 집중한다.
명령형 사고: “사용자가 필터를 바꾸면 → 데이터를 다시 로드하고 → 차트를 다시 그려야 한다”
반응형 사고: “차트는 항상 현재 필터 조건에 맞는 데이터를 보여준다”
이러한 차이는 혁명적이다. 개발자는 더 이상 ‘언제 업데이트해야 하는지’ 걱정하지 않아도 된다. 대신 데이터 간의 관계만 정의하면, 시스템이 알아서 변화를 추적하고 전파한다.

그림 15.3 는 이러한 패러다임 전환의 핵심을 시각적으로 보여준다. 왼쪽 명령형 프로그래밍에서는 개발자가 순차적인 단계들을 명시적으로 지시해야 한다. 데이터를 로드하고, 필터를 적용하고, 차트를 생성하고, 화면에 표시하는 모든 과정을 순서대로 코딩해야 하며, 변경사항이 있을 때마다 이 모든 단계를 다시 실행해야 한다.
반면 오른쪽 선언형 접근에서는 최종 결과와 의존관계만 정의한다. “차트는 필터된 데이터의 시각화다”, “필터된 데이터는 원본 데이터와 조건의 조합이다”라고 선언하기만 하면, 시스템이 알아서 관계를 추적하고 필요할 때 자동으로 업데이트한다.
다이어그램 중앙 부분은 반응형 시스템의 의존성 그래프를 보여준다. 원본 데이터와 필터 조건이 변하면, 이에 의존하는 모든 요소들이 자동으로 연쇄 업데이트된다. 마치 도미노가 넘어지듯 변화가 전파되지만, 개발자는 이러한 복잡한 과정을 직접 관리할 필요가 없다. 하단의 Push vs Pull 비교는 이러한 자동화의 근본 메커니즘을 설명한다. 전통적인 Pull 방식은 사용자가 능동적으로 업데이트를 요청해야 하지만, 반응형의 Push 방식은 변화가 생기는 순간 자동으로 모든 관련 요소에 알림이 전파된다.
15.2.2 reactive()와 observe()
R Shiny에서 반응형 프로그래밍을 제대로 이해하려면 reactive()와 observe()의 근본적 차이를 알아야 한다. 이 두 함수는 반응형 시스템의 양대 축을 이루지만, 각각이 담당하는 역할은 완전히 다르다.
많은 개발자들이 이 둘을 단순히 “반응형 함수”로 묶어서 생각하지만, 실제로는 함수형 프로그래밍의 순수함수와 명령형 프로그래밍의 부수효과라는 서로 다른 철학을 대변한다. 이러한 구분을 명확히 이해하지 못하면 복잡한 애플리케이션에서 예상치 못한 버그나 성능 문제에 직면하게 된다.
더 중요한 것은 두 함수의 실행 시점과 방식이 정반대라는 점이다. reactive()는 필요할 때까지 기다렸다가 한 번에 처리하는 지연 평가 방식을 사용하며, 계산 결과를 캐싱하여 성능을 최적화한다. 반면 observe()는 의존성이 변하는 순간 즉시 실행되며, 외부 세계에 영향을 미치는 일을 담당한다.
실무에서는 이 차이를 정확히 알고 있어야 올바른 함수를 선택할 수 있다. 잘못된 선택은 단순히 코드가 작동하지 않는 것을 넘어서 메모리 누수, 무한 루프, 또는 예상치 못한 부작용을 일으킬 수 있다.
reactive(): 값의 계산과 캐싱
reactive()는 순수 함수(Pure Function)의 철학을 따른다. 입력이 같으면 항상 같은 출력을 반환하며, 외부 세계에 어떤 영향도 주지 않는다:
reactive()는 계산 비용이 높은 작업에서 진가를 발휘한다. 복잡한 데이터 처리나 통계 모델 학습 같은 작업을 reactive() 안에 넣으면, 입력이 변하지 않는 한 이전 결과를 그대로 사용한다. 이러한 지능적 캐싱 덕분에 사용자는 슬라이더를 연속으로 움직여도 실제로는 마지막 값에서만 계산이 수행되어 놀라운 성능을 경험할 수 있다.
또한 reactive() 함수는 다른 reactive() 표현식에서 호출될 수 있어 복잡한 데이터 파이프라인을 구성할 때 유용하다. 마치 함수를 조합하듯 반응형 표현식들을 연결하여 모듈화된 코드를 작성할 수 있다.
observe(): 부수 효과 실행
반면 observe()는 부수 효과(Side Effects)를 위해 존재한다. 값을 반환하지 않고, 오직 외부 세계와 상호작용하기 위해 사용된다:
server <- function(input, output) {
# 사용자 행동 로깅 (즉시 실행)
observe({
DBI::dbWriteTable(db, "logs", data.frame(
user = session$user, action = input$current_action, time = Sys.time()
), append = TRUE)
})
# 조건 만족시 알림 발송 (외부 시스템과 상호작용)
observe({
if (input$threshold > 1000) {
send_alert("임계값 초과 경고")
}
})
}observe()는 reactive()와 정반대의 철학을 가진다. 계산 결과를 저장하지 않으며, 의존성이 변하는 순간 즉시 실행된다. 이러한 특성 때문에 사용자의 모든 행동을 실시간으로 추적해야 하는 로깅이나 모니터링에 적합하다.
실무에서 observe()는 주로 애플리케이션과 외부 시스템을 연결하는 다리 역할을 한다. 데이터베이스 업데이트, 파일 시스템 조작, 이메일 발송, 외부 API 호출 등 애플리케이션 밖으로 나가는 모든 작업이 여기에 해당한다. 중요한 점은 이런 작업들이 실패하더라도 애플리케이션 핵심 기능에는 영향을 주지 않도록 설계해야 한다는 것이다.
reactive()와 observe() 협력 패턴
반응형 프로그래밍에서 가장 중요한 것은 두 함수의 역할을 명확히 구분하여 사용하는 것이다. reactive()는 순수한 계산 작업을 담당하며, observe()는 계산 결과를 바탕으로 외부 세계와 상호작용한다. 이러한 분업은 단순히 기술적인 구분을 넘어서, 애플리케이션의 안정성과 유지보수성을 결정하는 핵심 설계 원칙이다.
실제 애플리케이션에서는 두 함수가 서로 보완적으로 작동한다. 사용자가 입력을 변경하면 reactive() 함수가 새로운 데이터를 계산하고, observe() 함수가 그 결과를 감지하여 필요한 외부 작업을 수행한다. 이때 reactive()의 지연 평가 특성 덕분에 불필요한 계산을 피할 수 있고, observe()의 즉시 실행 특성으로 사용자 행동에 실시간으로 반응할 수 있다.
다음 코드는 데이터 분석 대시보드에서 두 함수가 어떻게 협력하는지 보여준다. reactive()는 사용자가 선택한 날짜 범위에 따라 데이터를 필터링하고 통계를 계산하는 순수한 연산을 담당하며, 이 결과는 화면의 테이블로 출력된다. 동시에 observe()는 계산 결과를 감지하여 파일 저장과 임계값 초과시 알림 발송이라는 부수 효과를 실행한다. 이러한 명확한 역할 분담을 통해 reactive()는 데이터 변환과 계산을, observe()는 외부 시스템과의 상호작용을 담당하여 완전한 반응형 시스템을 구성하며, 코드 가독성과 유지보수성을 크게 향상시킨다.
server <- function(input, output) {
# 데이터 계산 (reactive)
analysis_results <- reactive({
raw_data %>% filter(date >= input$date_range[1]) %>%
summarise(avg = mean(value), count = n())
})
# 화면 출력
output$table <- renderDT({analysis_results()})
# 외부 작업 (observe)
observe({
if (nrow(analysis_results()) > 0) {
saveRDS(analysis_results(), "latest.rds")
if (analysis_results()$avg > 1000) send_alert("높은 수치 감지")
}
})
}15.2.3 지능적 변화 전파 최적화
반응형 시스템의 가장 놀라운 특징은 정밀한 무효화(Invalidation) 메커니즘이다. 변화가 발생했을 때 전체를 다시 계산하는 것이 아니라, 실제로 영향받는 부분만 찾아서 업데이트한다. 비유하면, 마치 거대한 도시에서 정전이 발생했을 때, 전체 도시를 재부팅하는 것이 아니라 문제가 된 구역만 복구하는 것과 같다.
# 복잡한 의존성 체인의 지능적 관리
server <- function(input, output) {
# 1단계: 데이터 로딩 (가장 비용이 큰 작업)
raw_data <- reactive({
heavy_database_query(input$database)
})
# 2단계: 연도별 필터링
yearly_data <- reactive({
raw_data() %>% filter(year == input$year)
})
# 3단계: 통계 계산
stats <- reactive({
yearly_data() %>% summarise(avg = mean(value))
})
# 4단계: 시각화 (여러 dependency)
output$plot <- renderPlot({
ggplot(yearly_data()) +
geom_point() +
geom_hline(yintercept = stats()$avg, color = input$line_color)
})
}시스템에서 input$line_color만 바뀌면 어떻게 될까? 전통적 시스템이라면 모든 계산을 다시 해야 하겠지만, 반응형 시스템은 오직 renderPlot만 실행한다. raw_data(), yearly_data(), stats()는 모두 그대로 캐시된 값을 사용한다. 반대로 input$database가 바뀌면 모든 것이 연쇄적으로 무효화되지만, 이 또한 정확히 필요한 순서대로 일어난다.
이러한 최소 재계산 원칙은 단순한 성능 최적화를 넘어선다. 시스템이 항상 일관성 있는 상태를 보장한다는 의미이기도 하다. 사용자는 절대로 “절반만 업데이트된” 화면을 보지 않는다. Shiny는 모든 의존성이 해결될 때까지 화면 갱신을 지연시키는 무결점 동기화 메커니즘을 통해 실현한다.
가장 인상적인 것은 모든 복잡한 최적화가 개발자에게는 완전히 투명하다는 점이다. 코드를 작성할 때는 단순히 “무엇을 원하는가”만 선언하면 되고, 언제 어떻게 계산할지는 시스템이 알아서 최적의 전략을 찾는다. 이것이 바로 반응형 프로그래밍이 개발자의 생산성을 혁명적으로 향상시키는 이유다.
힌트엑셀의 숨겨진 반응형 철학
Excel을 단순한 계산기로 생각하는 사람들이 많지만, 실제로는 인류 역사상 가장 성공한 반응형 프로그래밍 플랫폼이다. 수억 명의 사용자가 매일 복잡한 반응형 시스템을 만들고 있다는 사실도 모른 채 말이다. Excel의 진정한 혁신은 반응형 철학을 일반 사용자도 직관적으로 사용할 수 있게 만든 것이다. 셀에 =A1+B1이라고 쓰는 순간, 이미 선언형 프로그래밍을 하고 있는 것이다. 하지만 Excel의 반응형 능력은 여기서 끝나지 않는다.
목표값 찾기(Goal Seek): 일반적인 반응형이 “A가 바뀌면 B가 어떻게 될까?”라면, Goal Seek는 “B를 30으로 만들려면 A가 얼마여야 할까?”를 자동으로 계산한다. 이는 역방향 반응성의 구현이다.
조건부 서식: 셀 값이 바뀌면 색깔, 폰트, 테두리가 자동으로 변한다. 데이터와 시각화가 완전히 동기화된다.
연쇄 드롭다운: 첫 번째 드롭다운에서 “대한민국”을 선택하면 두 번째 드롭다운에 한국 도시들이 나타난다. 선택이 다음 선택의 옵션을 결정하는 계층적 반응성이다.
피벗 테이블: 원본 데이터가 바뀌면 요약 테이블이 자동으로 업데이트된다. 수십만 행의 데이터 변화가 한 번의 새로고침으로 모든 집계에 반영된다.
Excel이 데스크톱에서 반응형의 가능성을 보여주었다면, 이제는 웹에서도 같은 경험을 구현할 차례였다. 하지만 여기서 중요한 질문이 생겨났다. R을 쓰는 통계학자, Python을 쓰는 데이터 과학자, JavaScript를 쓰는 프론트엔드 개발자가 각자 다른 반응형 도구를 써야 할까? 언어마다 다른 생태계에서 같은 일을 반복해야 할까? 이 문제에 대한 혁신적인 답이 바로 Quarto다.
15.3 Quarto: 반응형 생태계
어떤 언어를 쓰든 상관없다. R에 익숙하든, Python을 좋아하든, JavaScript의 자유로움을 선호하든, Julia의 고성능에 매료되었든 말이다. Quarto는 모든 언어의 반응형 능력을 하나의 문서 시스템 안에서 자연스럽게 통합한다. 마크다운으로 글을 쓰다가 필요할 때마다 각 언어의 최고 장점을 끌어내는 것이다.
이것은 단순한 기술적 통합이 아니다. 사고의 통합이다. 더 이상 “분석은 R로, 시각화는 JavaScript로, 머신러닝은 Python으로” 따로 생각할 필요가 없다. 모든 것이 하나의 문서 안에서 자연스럽게 연결되고, 반응형으로 상호작용한다.
한 번 쓰고, 어디서나 렌더링(Write once, render everywhere)의 진정한 의미가 여기에 있다. 하나의 Quarto 문서에서 학술 논문, 인터랙티브 대시보드, PDF 보고서, 웹사이트, 프레젠테이션이 모두 나온다. 내용은 같지만 독자와 목적에 따라 최적화된 형태로 변환되는 것이다.
15.3.1 R Shiny
R Shiny는 반응형 프로그래밍을 웹으로 가져온 선구자다. 핵심은 reactive()와 observe() 패턴으로, 순수한 계산과 부수 효과를 명확히 분리한다.
server <- function(input, output) {
filtered_data <- reactive({
mtcars %>% filter(cyl == input$cylinders)
})
output$scatter <- renderPlot({
ggplot(filtered_data(), aes(wt, mpg)) + geom_point()
})
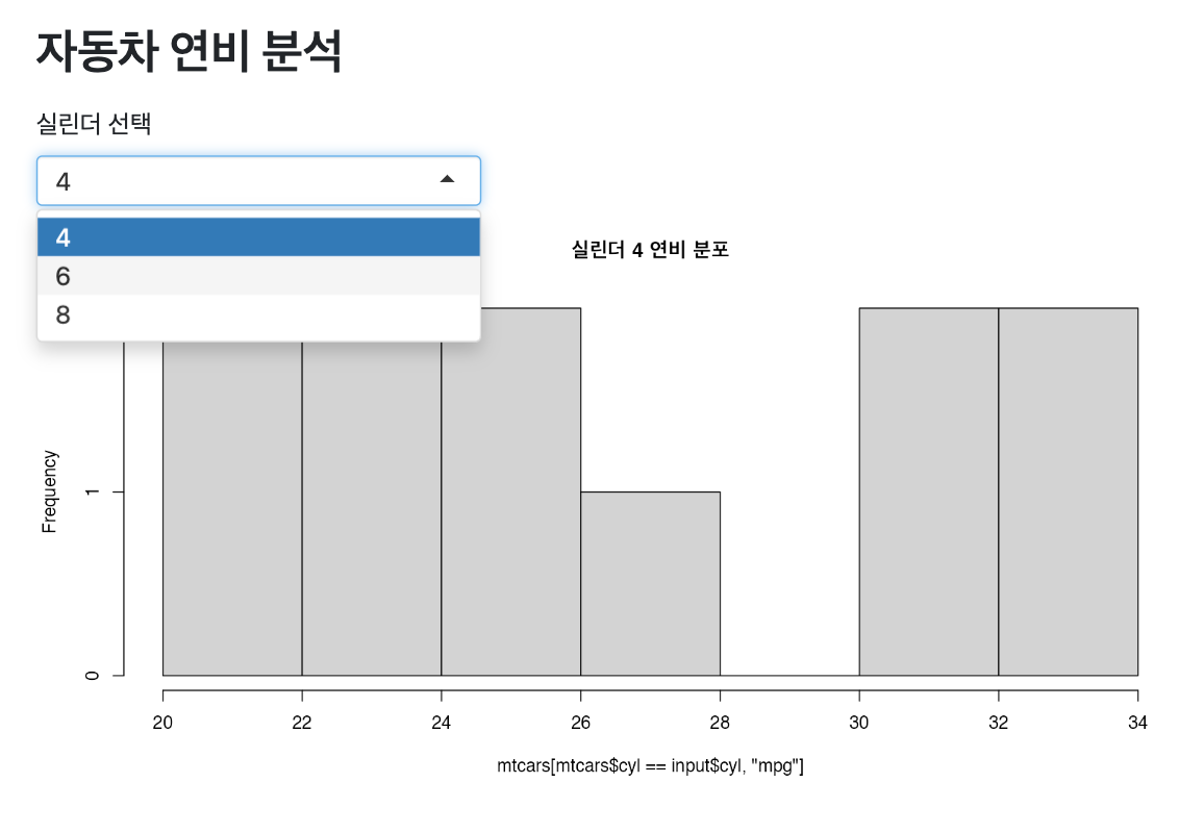
}Quarto에서 Shiny를 사용할 때의 핵심은 UI와 서버 로직의 명확한 분리다. 먼저 selectInput()으로 사용자가 실린더 수를 선택할 수 있는 드롭다운을 만들고, plotOutput()으로 결과 차트가 표시될 공간을 준비한다. 가장 중요한 부분은 #| context: server 옵션이다. 특별한 코드 청크 옵션이 바로 Quarto의 마법이 일어나는 곳이다. 서버 컨텍스트로 지정된 코드는 사용자 입력을 감지하고 실시간으로 차트를 업데이트하는 반응형 엔진이 된다. 이렇게 몇 줄의 코드만 추가하면 평범한 마크다운 문서가 즉시 인터랙티브 웹 애플리케이션으로 변환된다.
---
title: "자동차 연비 분석"
server: shiny
---```{r}
selectInput("cyl", "실린더 선택",
choices = c(4, 6, 8))
plotOutput("p")
``````{r}
#| context: server
output$p <- renderPlot({
hist(mtcars[mtcars$cyl == input$cyl, "mpg"],
main = paste("실린더", input$cyl, "연비 분포"))
})
```
15.3.2 Python Shiny
리액티브 프로그래밍의 복잡함을 제거하고 순수 Python만으로 펭귄 데이터를 시각화해보자. 8줄의 간결한 코드로 종별 부리 길이 분포를 한눈에 파악할 수 있다. Seaborn의 직관적인 API는 데이터 과학자들이 빠르게 탐색적 분석을 수행할 수 있게 해준다.
import seaborn as sns
import matplotlib.pyplot as plt
penguins = sns.load_dataset("penguins")
sns.displot(data=penguins, x="bill_length_mm", hue="species",
kind="kde", multiple="stack")
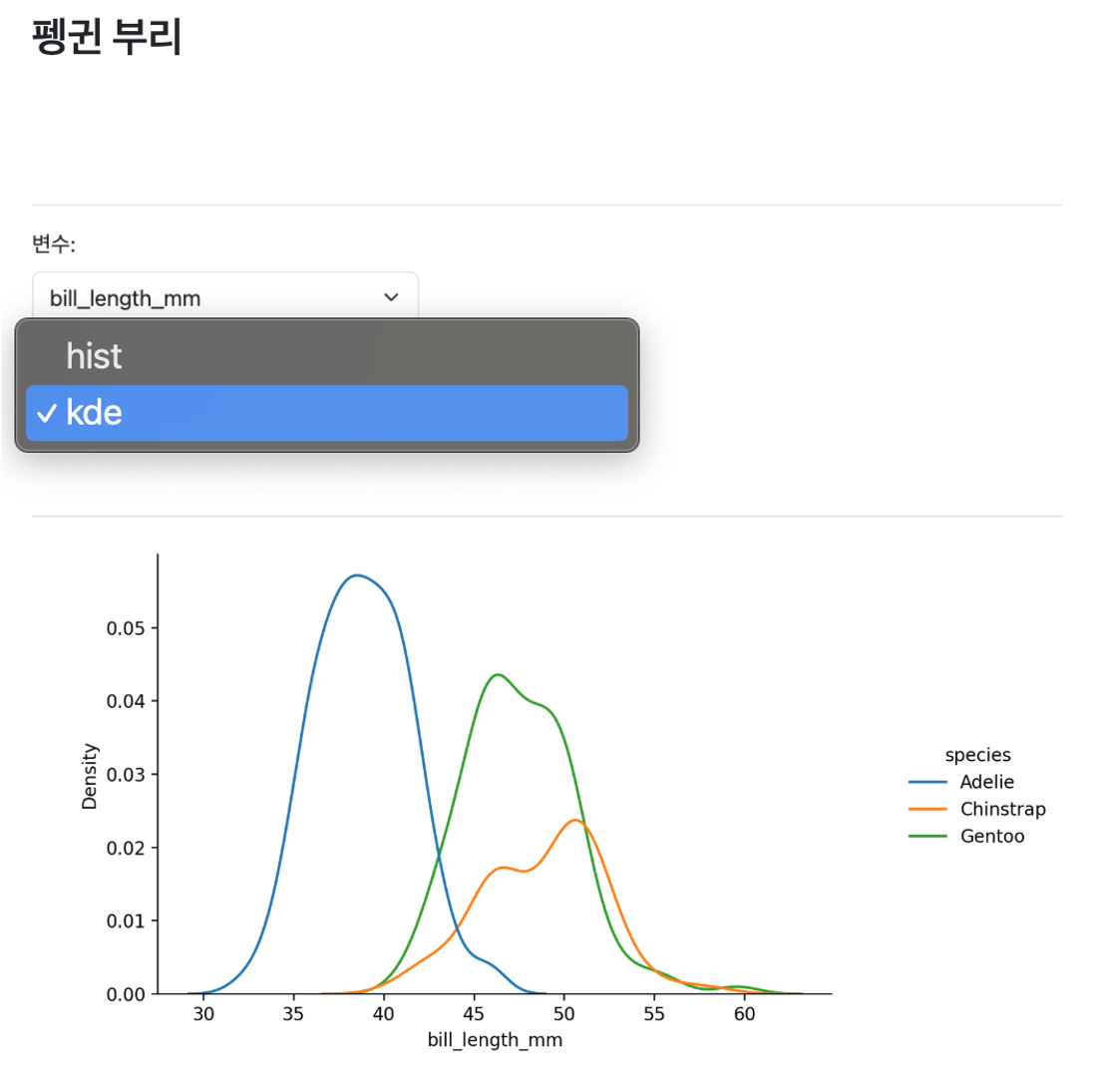
plt.show()Python Shiny는 R Shiny의 강력한 리액티브 프로그래밍 패러다임을 Python 생태계로 가져온다. 데이터 과학자들이 익숙한 pandas, matplotlib, seaborn과 같은 라이브러리를 그대로 활용하면서도 인터랙티브한 웹 애플리케이션을 구축할 수 있다. 특히 Jupyter 환경에서 개발한 분석 코드를 최소한의 수정으로 웹 앱으로 전환할 수 있어 Python 데이터 과학 워크플로우와 자연스럽게 통합된다.
---
title: "펭귄 부리"
server: shiny
---
```{python}
import seaborn as sns
from shiny.express import render, ui
penguins = sns.load_dataset("penguins")
```
## {.sidebar}
```{python}
ui.input_select("x", "변수:", choices=["bill_length_mm", "bill_depth_mm"])
ui.input_select("dist", "분포:", choices=["hist", "kde"])
```
## {.main}
```{python}
@render.plot
def displot():
sns.displot(data=penguins, hue="species", x=input.x(), kind=input.dist())
```
15.3.3 Observable JS
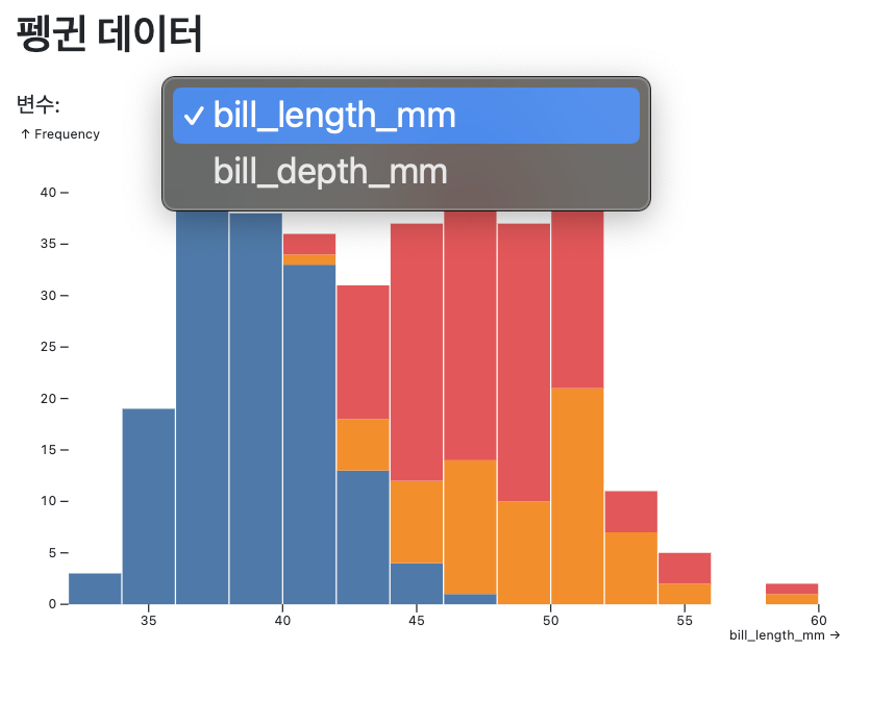
Observable JS는 서버 의존성을 완전히 제거한 클라이언트 중심의 데이터 시각화를 구현한다. 모든 계산과 렌더링이 브라우저에서 직접 수행되어 네트워크 지연 없이 즉시 반응하는 시각화를 경험할 수 있다. 특히 D3.js와 Plot.js 생태계와의 완벽한 통합을 통해 복잡한 데이터 시각화와 인터랙션을 단 몇 줄의 코드로 구현할 수 있으며, JavaScript의 강력함과 데이터 과학의 편의성을 동시에 제공한다.
---
title: "펭귄 데이터"
format: html
---
```{ojs}
//| echo: false
data = FileAttachment("data/penguins.csv").csv({typed: true})
viewof variable = Inputs.select(["bill_length_mm", "bill_depth_mm"], {label: "변수:"})
Plot.plot({
marks: [
Plot.rectY(data, Plot.binX({y: "count"}, {x: variable, fill: "species"}))
]
})
```
15.3.4 Julia
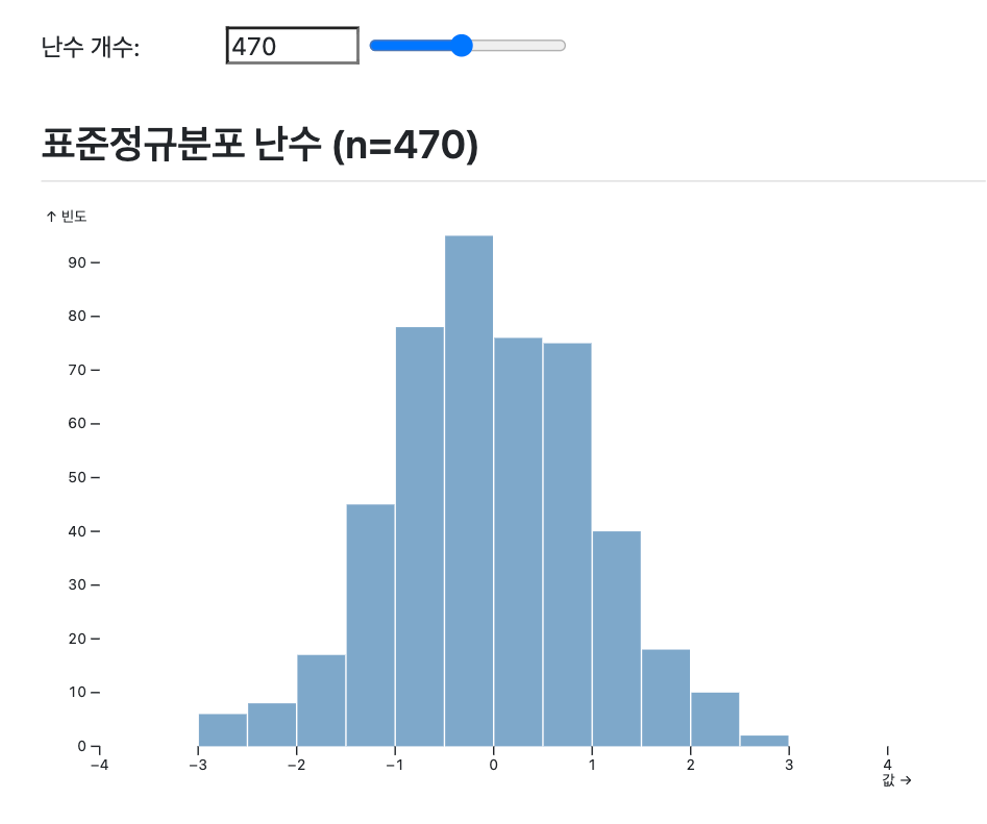
Julia의 Quarto 통합은 흥미로운 딜레마를 보여준다. Julia는 과학 계산에서 Python보다 10-100배 빠른 성능을 제공하지만, Quarto 환경에서는 반응형 프로그래밍의 핵심인 실시간 상호작용에 제약이 있다. Julia 코드는 문서 렌더링 시점에 한 번만 실행되며, 사용자의 입력 변화에 직접적으로 반응할 수 없기 때문이다.
하지만 이러한 한계에도 불구하고 Julia의 강력한 계산 능력을 활용하는 방법이 있다. 핵심은 “Julia는 데이터 생성, OJS는 반응형 시각화”라는 역할 분담이다. Julia에서 복잡한 수치 계산을 수행한 후 ojs_define()을 통해 결과를 OJS로 전달하면, 브라우저에서 빠르고 부드러운 상호작용을 구현할 수 있다.
using Random, JSON3
Random.seed!(123)
# Julia의 고성능 난수 생성
samples = randn(1000)
ojs_define(data = samples)viewof n = Inputs.range([10, 1000], {step: 10})
selected = data.slice(0, n)
Plot.plot({
marks: [Plot.rectY(selected, Plot.binX({y: "count"}, {x: d => d}))],
title: `표준정규분포 (n=${n})`
})
이와 같은 접근법의 장점은 명확하다. Julia의 놀라운 수치 계산 성능과 OJS의 매끄러운 브라우저 반응성을 동시에 얻을 수 있다. 복잡한 시뮬레이션이나 최적화 문제는 Julia가 담당하고, 사용자 인터페이스와 실시간 탐색은 OJS가 처리하는 것이다.
진정한 Julia 반응형 프로그래밍을 원한다면 Pluto.jl이 답이다. Pluto는 @bind 매크로를 통해 완벽한 반응형 환경을 제공하며, 셀 간 자동 의존성 추적으로 Excel 수준의 직관적 상호작용을 구현한다. 하지만 Pluto는 별도의 환경이므로 Quarto의 “한 번 쓰고 어디서나 배포” 철학과는 거리가 있다.
미래에는 WebAssembly를 통한 브라우저 내 Julia 실행이나 Quarto와 Pluto의 통합이 실현될 수 있다. 하지만 현재로서는 Julia의 계산 파워와 웹의 반응성을 조합하는 하이브리드 접근법이 가장 실용적인 해답이다.
15.4 미래 반응형 시스템
반응형 프로그래밍은 2025년부터 2030년 사이에 근본적인 아키텍처 혁신을 겪을 것으로 전망된다. 핵심 변화는 LLM 기반 코드 생성과 실시간 컴파일 파이프라인의 통합이다. 전통적인 명령형 UI 조작 패러다임에서 선언적 자연어 명세로의 전환은 반응형 시스템의 추상화 레벨을 근본적으로 상향 조정할 것이다.
15.4.1 LLM 통합 반응형 아키텍처
2025년경부터 등장할 차세대 반응형 시스템은 자연어-코드 변환(NL2Code) 파이프라인을 핵심으로 한다. 사용자의 자연어 쿼리는 먼저 의미론적 파싱(semantic parsing)을 거쳐 추상 구문 트리(AST)로 변환되고, 이후 도메인 특화 언어(DSL) 코드로 변환 컴파일된다. 생성된 코드는 애플리케이션 재시작 없이 모듈을 실시간으로 교체하는 핫 모듈 교체(Hot Module Replacement, HMR) 메커니즘을 통해 반응형 컴포넌트에 주입되어, 지연시간 없는 동적 UI 재구성을 실현한다.
핵심 기술은 증분적 코드 생성(Incremental Code Generation)이다. LLM이 생성한 코드 조각들은 의존성 그래프 분석을 통해 최소 변경 집합(minimal change set)으로 분해되고, 반응형 스트림의 특정 노드들만 선택적으로 업데이트된다. 이는 O(1) 복잡도의 부분 재계산을 가능하게 하여 대규모 데이터셋에서도 실시간 응답성을 보장한다.

15.4.2 적응형 UI 최적화 시스템
2027년경에는 강화학습 기반의 적응형 인터페이스 최적화가 표준화될 것이다. 시스템은 사용자의 클릭, 스크롤, 머무는 시간 등 상호작용 패턴을 지속적으로 관찰하고, 이를 통계적 예측 모델에 입력하여 다음 행동을 예측한다. 핵심은 새로운 시도와 검증된 방법의 균형을 자동으로 조절하는 온라인 학습 방식이다. 예를 들어, 사용자가 특정 차트를 자주 확인한다면 해당 영역을 더 크게 표시하거나 접근하기 쉬운 위치로 이동시킨다.
기술적 구현은 네트워크 기반 AI 상태 관리에 의존한다. 사용자 인터페이스의 모든 요소(버튼, 차트, 메뉴 등)는 서로 연결된 네트워크로 모델링되어, 하나의 변화가 전체 시스템에 어떤 영향을 미치는지 추적한다. 이 네트워크에서 정보 전달 방식을 통해 상태 변화가 전파되며, 중요도 판단 기능을 통해 핵심적인 컴포넌트에 계산 리소스를 집중한다. 결과적으로 각 사용자의 작업 패턴에 최적화된 반응형 인터페이스가 실시간으로 구성된다.
15.4.3 분산 반응형 컴퓨팅 패러다임
2029년경부터는 웹어셈블리 기반의 엣지 컴퓨팅 반응형 시스템이 주류가 될 것이다. 핵심은 충돌 없는 분산 데이터 동기화 기술이다. 여러 디바이스가 동시에 데이터를 수정해도 충돌 없이 자동으로 병합되는 방식으로, 각 디바이스는 독립적으로 작업하면서도 전체적인 일관성을 유지한다.
프라이버시 보호를 위해서는 차등 프라이버시와 연합학습이 반응형 시스템에 직접 통합된다. 사용자의 실제 데이터는 디바이스를 떠나지 않고, 대신 노이즈가 추가된 학습 결과만 서버로 전송된다. 이 과정에서 암호화 계산 기술이 개별 사용자의 정보 노출을 완전히 차단한다.
15.4.4 선언적 반응형 프로그래밍 추상화
가장 혁신적인 변화는 시각적 프로그래밍 환경의 성숙화다. 2025년 말경부터 등장할 차세대 노코드 플랫폼은 자동 최적화 레이아웃 엔진을 핵심으로 한다. 사용자가 드래그 앤 드롭으로 정의한 제약조건들은 수학적 최적화 알고리즘을 통해 최선의 배치로 변환되고, 이를 바탕으로 반응형 연결이 자동 생성된다.
기술적으로는 함수형 반응형 프로그래밍 방식의 완전한 추상화가 이뤄진다. 모든 데이터 처리는 순수 함수들의 조합으로 표현되고, 예측 불가능한 부작용들은 별도로 격리되어 관리된다. 이는 시간에 따라 변화하는 데이터를 신호(Signal) 개념으로 통합하여, 복잡한 반응형 동작을 직관적으로 기술할 수 있게 한다. 결과적으로 개발자는 “무엇을” 달성하고자 하는지만 명세하면, 시스템이 “어떻게” 구현할지를 자동으로 결정한다.
💭 생각해볼 점
반응형 시스템의 진화는 단순한 기술 발전을 넘어 인간-컴퓨터 상호작용의 패러다임 전환을 의미한다. 2025년부터 2030년까지 변화는 데이터와 소통하는 방식을 근본적으로 바꿀 것이다. 자연어로 질문하면 즉시 반응형 시각화가 생성되고, 사용 패턴을 학습해서 개인 맞춤형 인터페이스가 자동으로 구성되며, 여러 디바이스 간에 끊김 없는 협업이 가능해진다. 이는 Excel의 셀 기반 반응성에서 시작된 개념이 AI와 분산 컴퓨팅을 만나 완전히 새로운 차원으로 진화하는 과정이다.
핵심은 추상화 레벨의 상승이다. 개발자는 더 이상 상태 관리나 이벤트 처리 복잡성에 얽매이지 않고, 순수하게 비즈니스 로직에 집중할 수 있게 된다. 반응형 시스템이 스스로 최적화하고 학습하며 진화하는 동안, 인간은 창의적 문제 해결에 집중할 수 있다. 이러한 변화는 소프트웨어 개발의 생산성을 기하급수적으로 향상시킬 뿐만 아니라, 데이터 분석과 의사결정의 민주화를 가능하게 한다.
하지만 이런 미래를 맞이하기 위해서는 지금부터 체계적인 준비가 필요하다. 기술적 역량뿐만 아니라 사고방식의 전환, 조직 문화의 변화, 새로운 협업 방식의 도입이 수반되어야 한다. 다음 장에서는 이러한 변화에 어떻게 대비하고 적응할 수 있는지, 실무자들이 당장 시작할 수 있는 구체적인 방법들을 살펴보겠다.