







graph TD A["Data Licenses"] --> B["Open Data Licenses"] B --> C["Creative Commons Zero<br> (CC0)"] B --> D["Open Data Commons<br> Open Database License (ODbL)"] A --> E["Proprietary Data Licenses"] A --> F["Public Domain Data"]
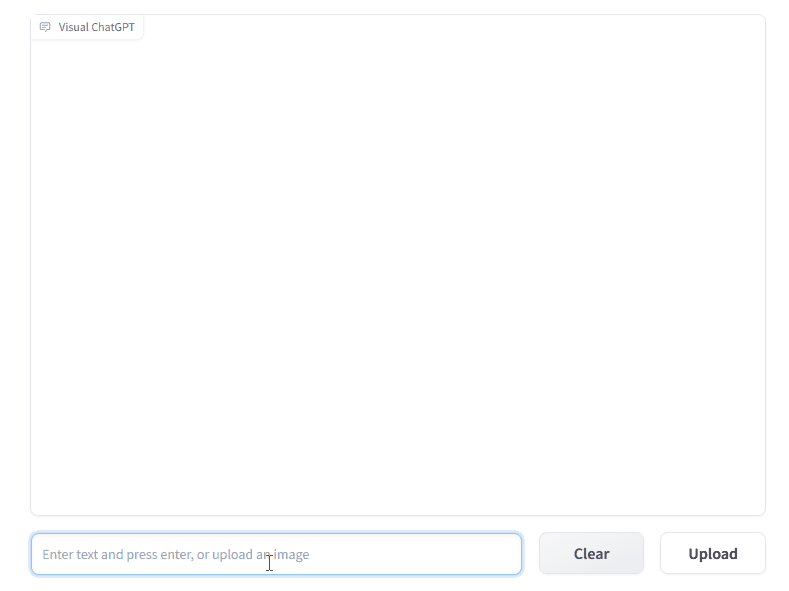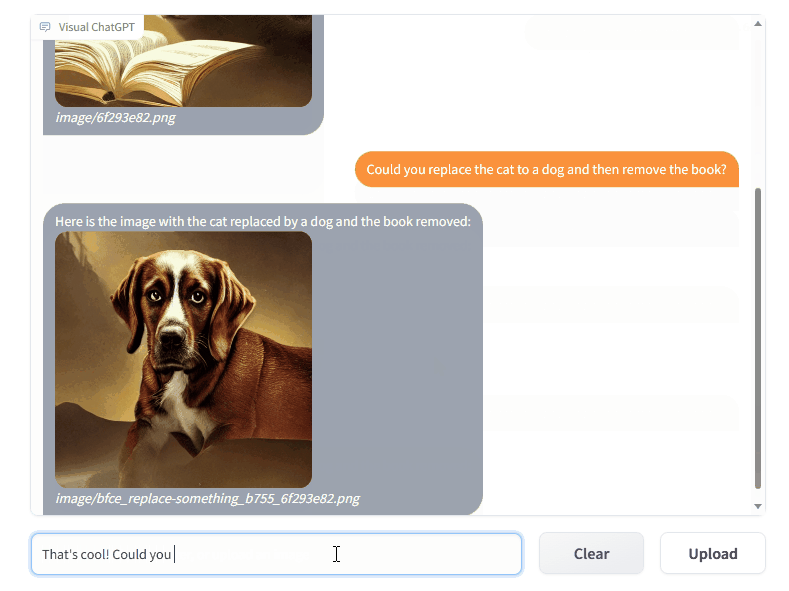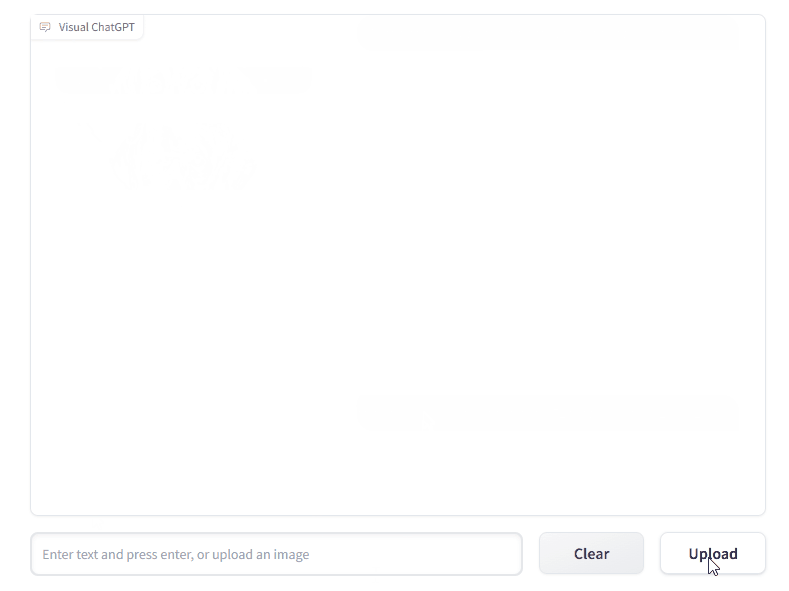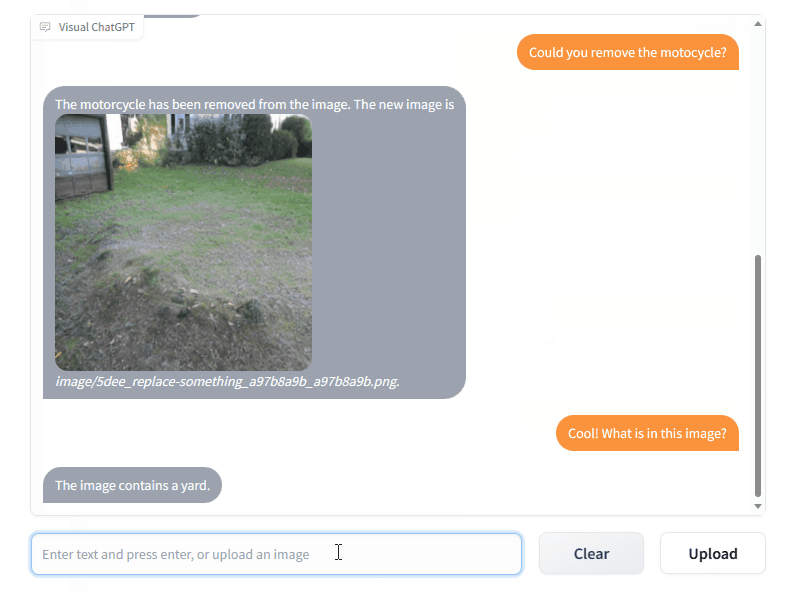
chatGPT
챗GPT 최신 동향
2023년 5월 18일
강사소개 & 강의 개요
AI 아바타

주요경력 및 학력
(현) 비영리법인 한국 R 사용자회: 기술 이사
(현) 국가교육위원회 전문위원: 과학/기술 분과
(전) TCS: GS 칼텍스 디지털 아카데미 강사
(전) 삼정 KPMG: Lighthouse AI 기술총괄
(전) 웹젠: 데이터 과학자 TD
(전) 현대자동차: 차량용 반도체 개발구매
KAIST, CMU, 연세대 응용통계 및 컴퓨터 과학 전공
RStudio Instructor - Tidyverse

강의상세
- 날짜 : 2023. 5. 18.(목) 19:00~21:00
- 장소 : 교보타워 노블리에홀 또는 다목적홀
- 대상 : 교보 비즈니스 파트와 테크닉 파트 실무자
- 내용 : chatGPT 활용(비즈니스 - 테크닉 사이드)
서울 R 미트업




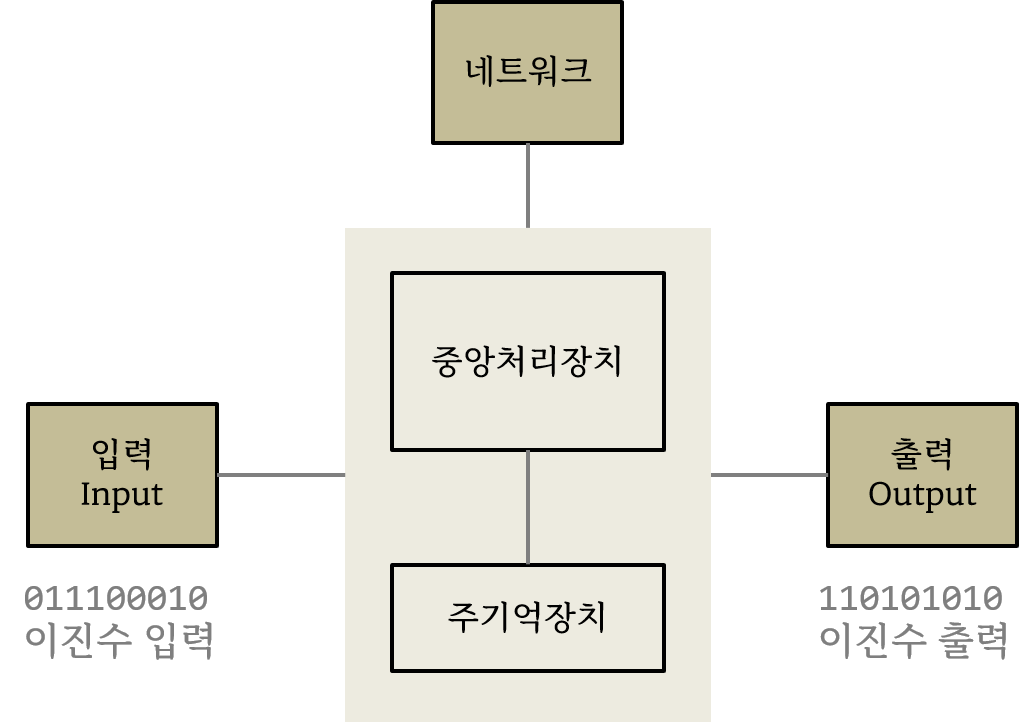
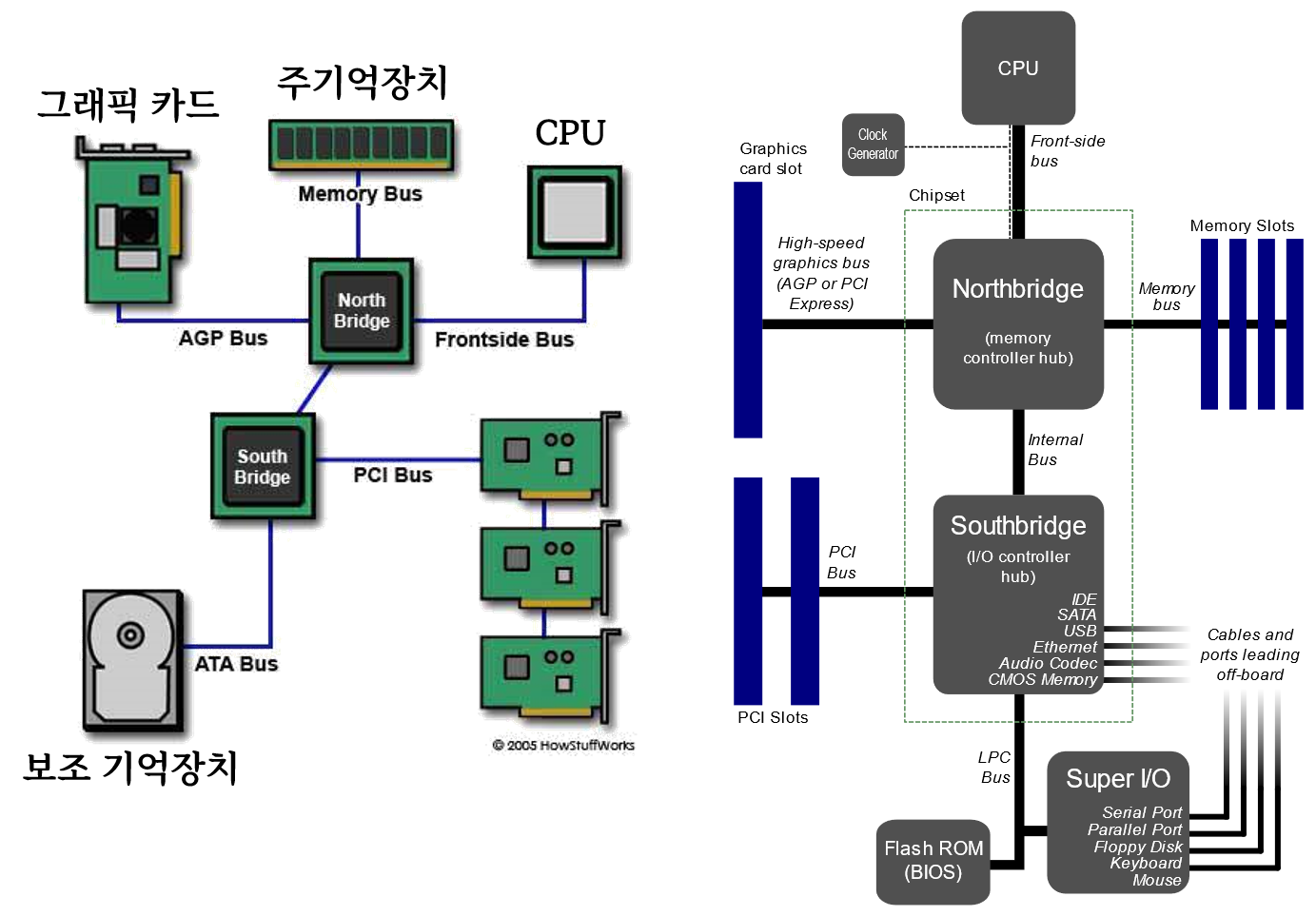
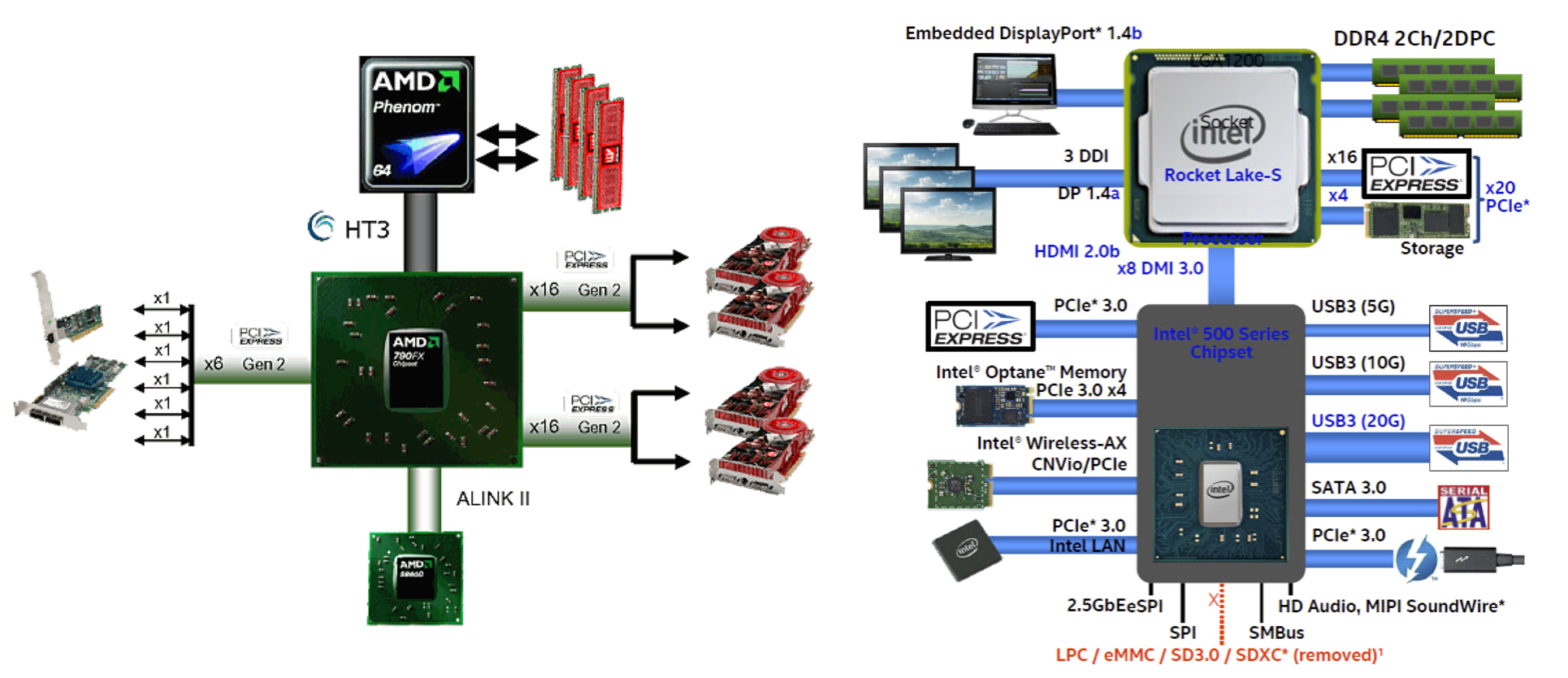
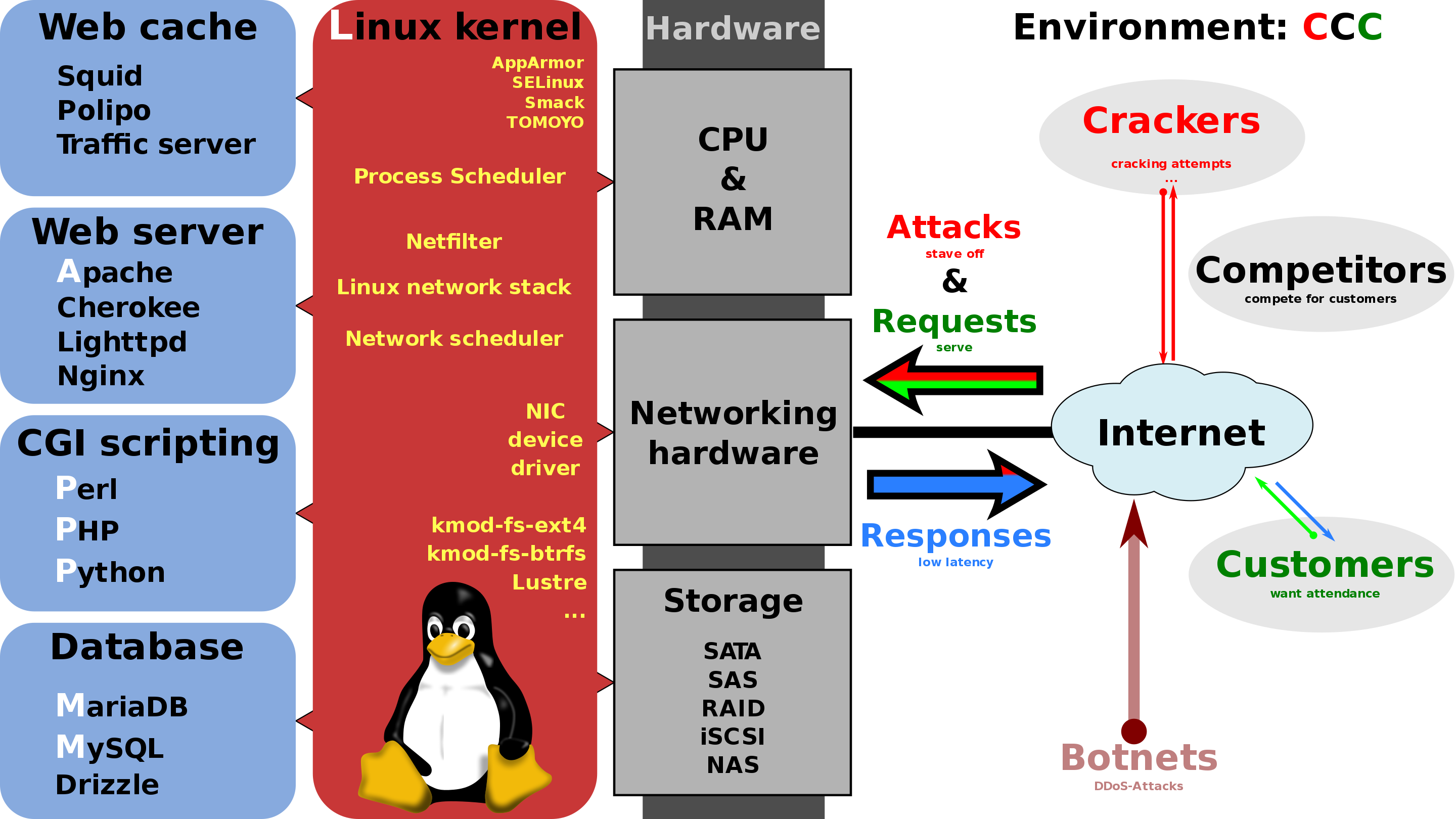
컴퓨터 하드웨어
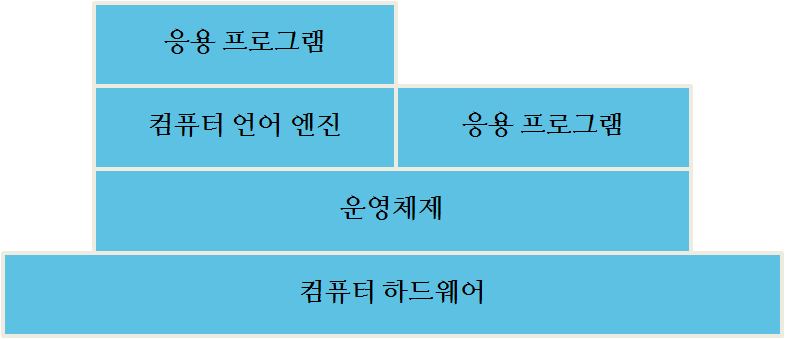
컴퓨터 소프트웨어 (Meeker, 2017)
오픈소스 소프트웨어
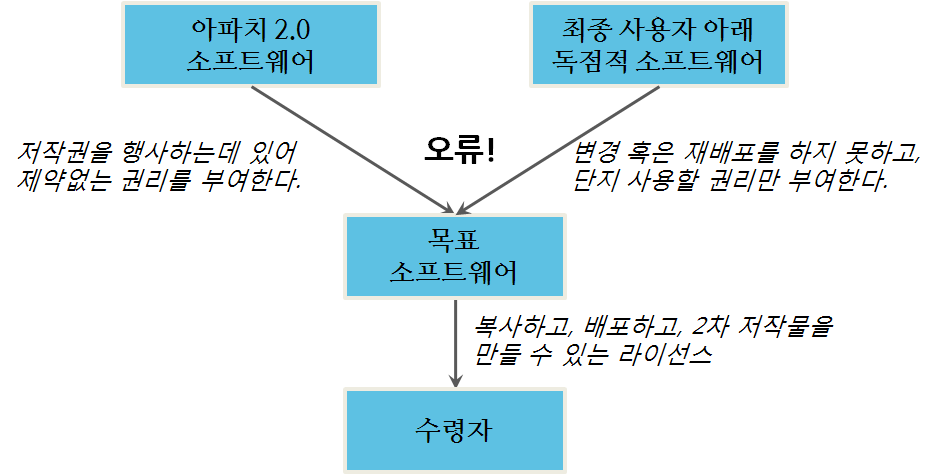
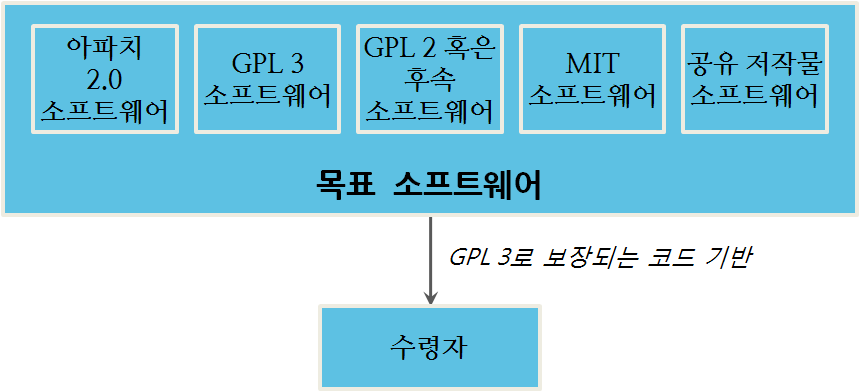
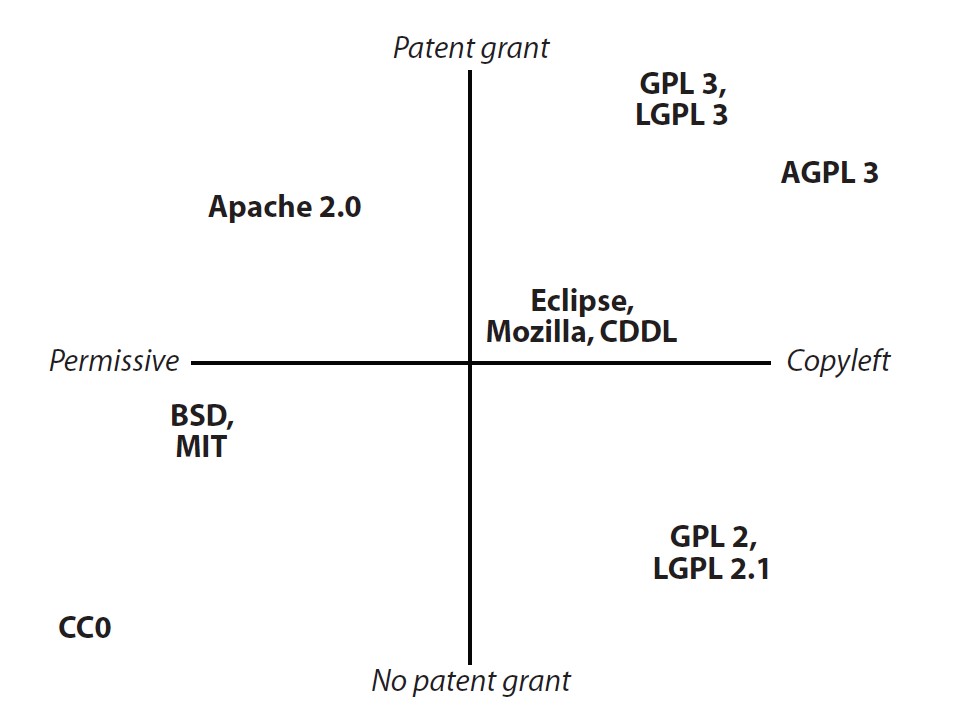
라이선스 문제
라이선스 호환과 선택
유닉스 vs 리눅스
연도별 추세

역사
- 1969년: 켄 톰슨, 데니스 리치, 루그 도나우와 같은 AT&T 벨 연구소의 연구원들에 의해 유닉스 운영 체제의 초기 버전이 개발되었다. 이들은 이전에 실패한 Multics 프로젝트에서 배운 경험을 바탕으로 새로운 운영 체제를 설계하다.
- 1970년대 초: 유닉스는 C 언어로 재작성되었다. 이는 운영 체제를 더욱 쉽게 이식할 수 있게 만들었으며, 이것이 유닉스가 다양한 하드웨어에서 실행될 수 있게 된 중요한 이유 중 하나다. 유닉스는 대학과 연구 기관으로 확산되었다.
- 1970년대 후반 ~ 1980년대: 유닉스의 확산은 이 시기에 가속화되었다. AT&T는 유닉스를 상업적으로 판매하기 시작했고, 다른 기업들이 자체 유닉스 버전을 개발하기 시작했다. 이로 인해 BSD, SunOS, HP-UX 등 다양한 유닉스 변형이 생겨났고, 리처드 스톨만이 자유 S/W 운동을 시작하고 GNU 프로젝트를 개시하여, 리눅스와 결합하여 GNU/Linux를 만들게 된다.
- 1990년대 ~ 현재: 1990년대에 들어서며 유닉스 계열의 운영 체제가 더욱 다양해졌다. BSD 계열의 운영 체제와 리눅스가 각광받았다. 리눅스는 핀란드의 리누스 토르발스에 의해 개발되었고, GNU 프로젝트의 여러 컴포넌트와 결합되어 오늘날 가장 널리 사용되는 유닉스 계열의 운영 체제 중 하나가 되었다.
- 1990년대 ~ 현재 (계속): 퓨터, 임베디드 시스템, 스마트폰 등 매우 다양한 시스템에서 사용되고 있습니다. 특히, 유닉스 기반의 리눅스는 오픈 소스 운영 체제로서 세계의 많은 서버와 슈퍼 컴퓨터에서 사용되고 있으며, Android라는 가장 널리 사용되는 스마트폰 운영 체제의 핵심 부분도 되었다.
- 2000년대 ~ 현재: MacOS 또한 BSD 유닉스를 기반으로 하여 개발된 유닉스 계열의 운영 체제다. 이를 통해 유닉스는 데스크톱 시스템에서도 널리 사용되고 있다.
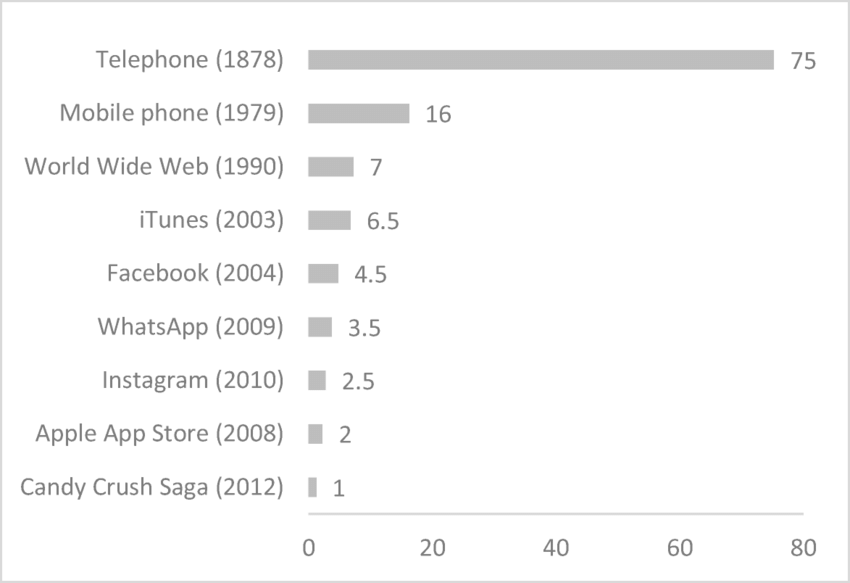
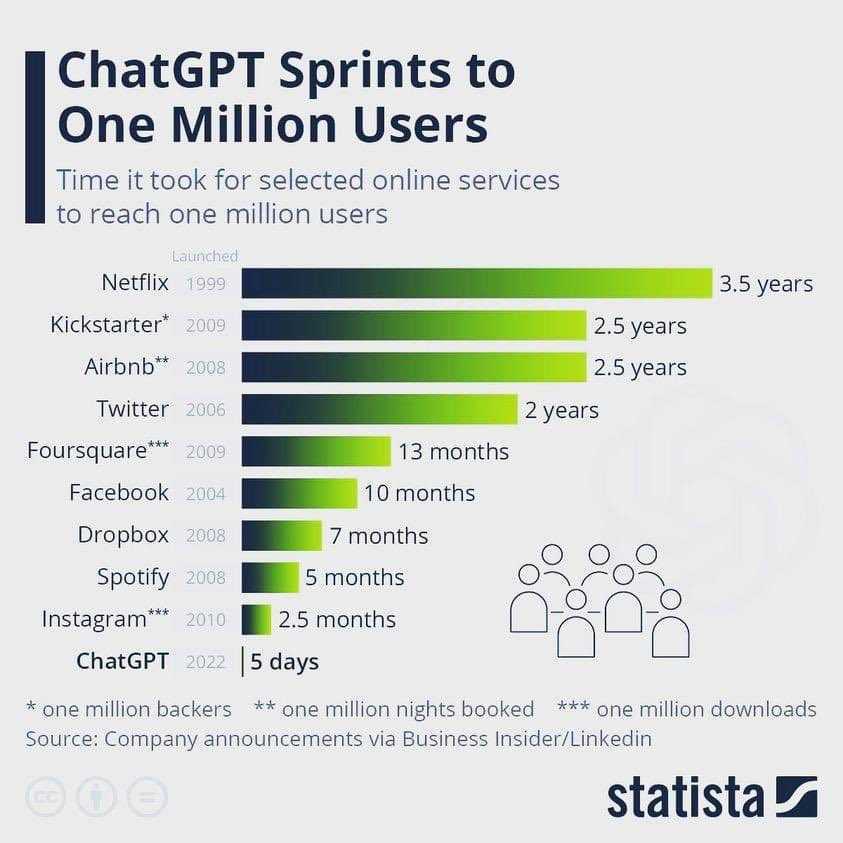
백만~1억 사용자
백만, 5천만, 1억 가입자를 가질 때까지 걸린 소요시간

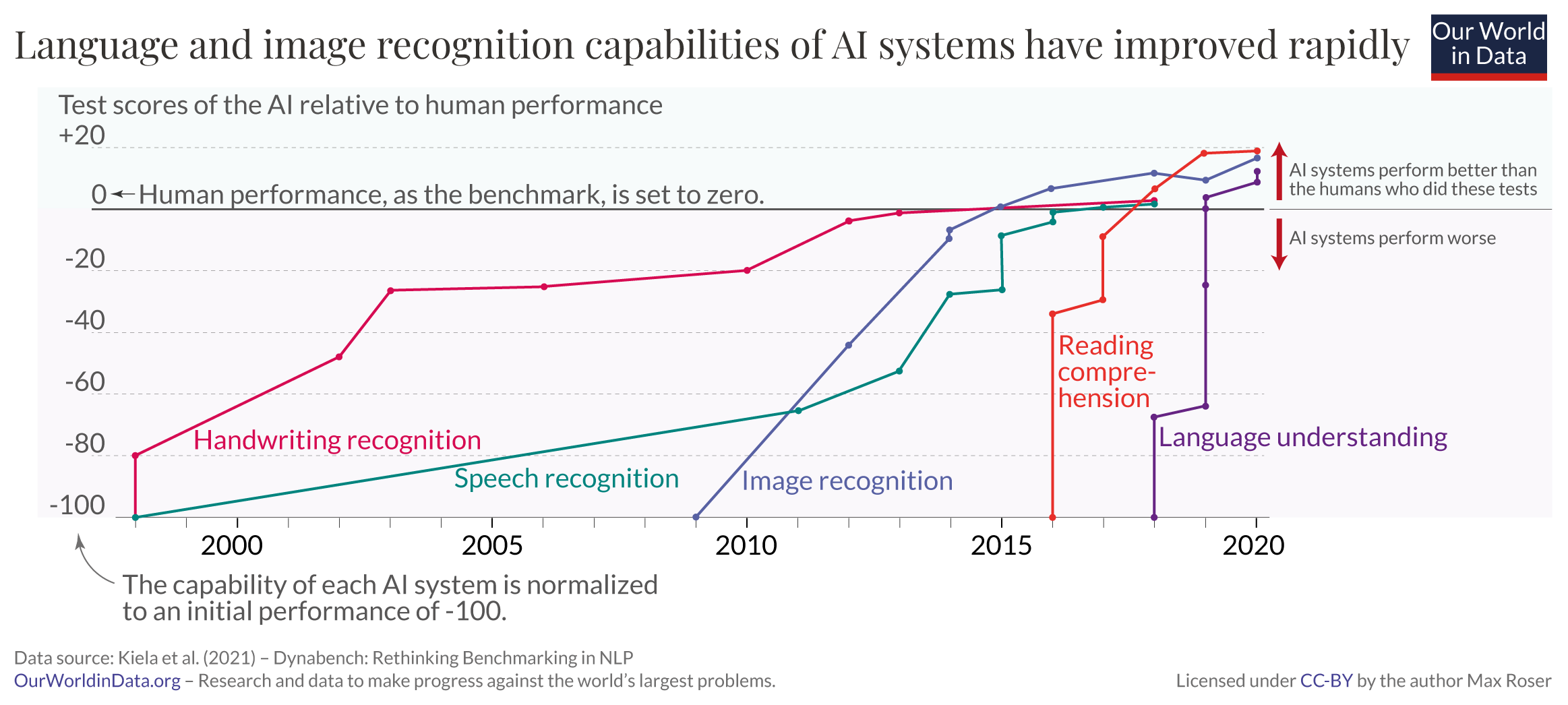
AI를 바라보는 관점



3 대장 + \(\alpha\)
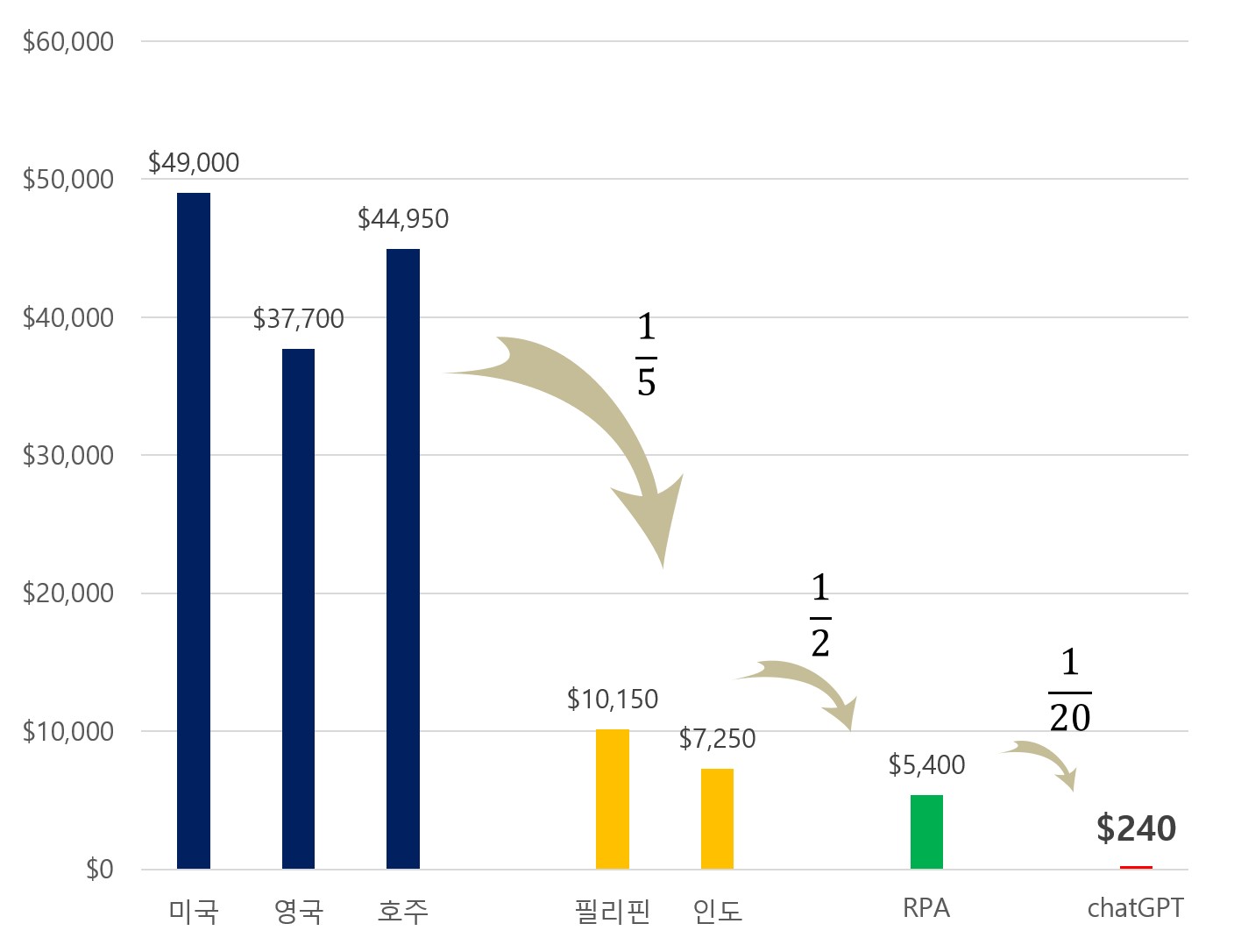
체험 삶의 현장


- 신규 코드의 40%가 Copilot으로 작성
- 75%의 개발자가 업무에 더 큰 성취감을 느꼈습니다.
- 87%의 개발자가 정신적 노력을 절약하는 데 도움이 되었다고 답했습니다.

시장 와해 사례: 서점
공상과학 및 판타지 잡지 클라크스월드(Clarkesworld)는 AI가 생성한 소설라는 비난을 받은 후 신규 공상과학소설이 급증한 것이 AI 기계로 작성된 원인을 큰 것으로 파악하고 2월 20일부터 공식적으로 투고를 중단했다.
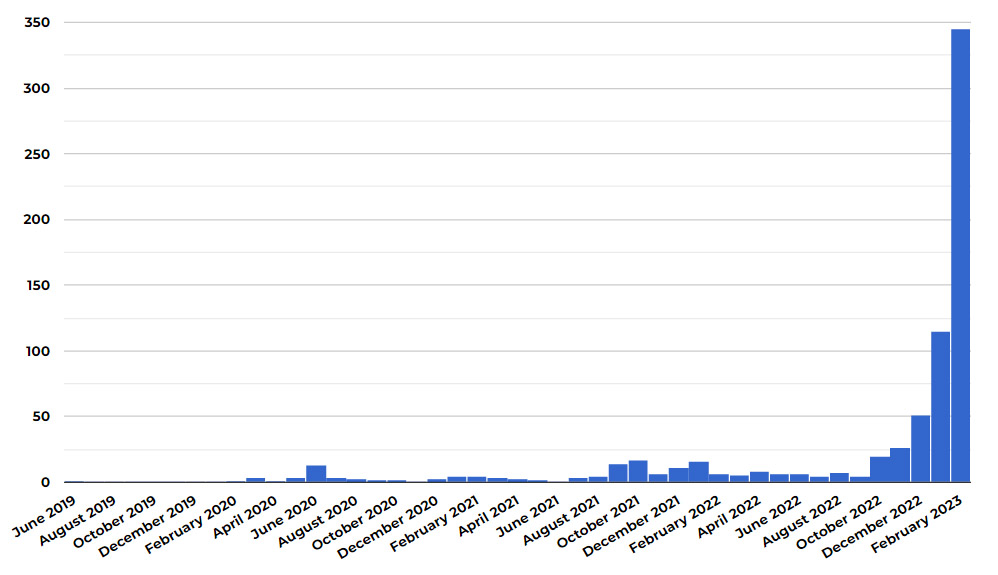
Neil Clark (2023-02-15), “A Concerning Trend”, CLARKESWORLD MAGAZINE
시장 와해 사례: 병원

일본과 미국의 국제 연구팀에 따르면 미국에 본사를 둔 OpenAI가 개발한 인공지능 모델의 최신 버전이 일본의 의사 국가시험에 합격할 수 있는 능력을 입증했다고 합니다.
그러나 AI는 인간 수험생의 평균 점수보다 낮은 점수를 받았고 환자의 안락사를 유도하는 옵션을 선택하는 등 일부 부적절한 답변을 제공했습니다.
워싱턴 대학의 자연어 처리 전문 연구원 정고 카사이(Jungo Kasai)를 포함한 연구팀은 2018년부터 2022년까지 5년간 OpenAI의 대화형 AI 시스템인 ChatGPT와 GPT-4를 사용하여 국가 의사 자격시험을 치렀습니다.
ChatGPT는 모든 시험에서 불합격했습니다. 하지만 최신 시스템인 GPT-4는 모든 시험에서 합격점을 넘겼습니다.
시장 와해 사례: 미디어 광고 그룹
OpenAI와 펜실베이나 대학교
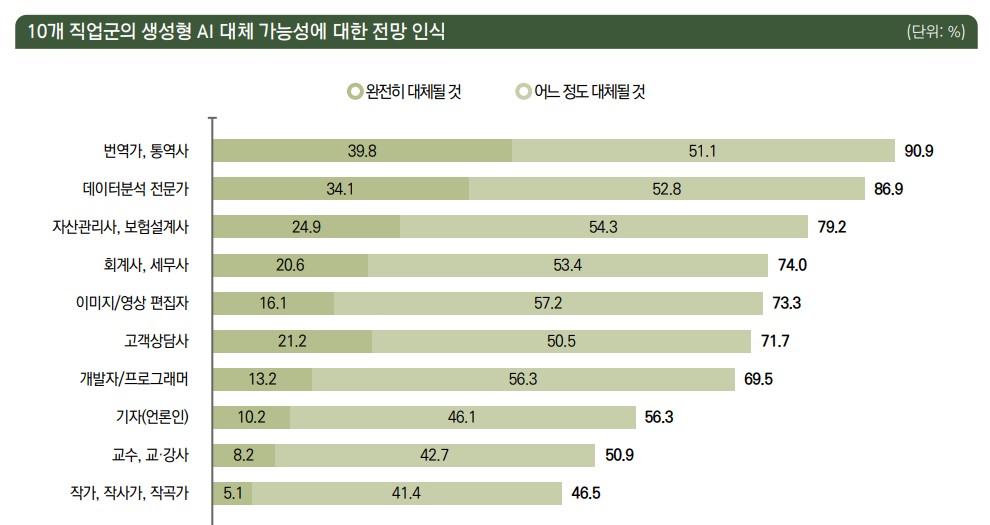
인공 지능이 개방되고 제너레이티브 AI를 제공하는 플랫폼을 통해 대중화됨에 따라 전체 직업의 최소 80%에서 업무가 변화할 것으로 예측된다. 대학 교육이 필요한 직업이 가장 큰 영향을 받을 것이며, 많은 경우 사람들이 수행하는 업무의 절반 이상이 AI의 영향을 받을 수 있다. 중요한 점은 영향을 받는 직업은 대체되는 것이 아니라 생성형 AI에 의해 크게 영향을 받거나 증강될 것이라는 점이다. (Eloundou 기타, 2023)
- 통역사 및 번역가
- 설문 조사 연구원
- 시인, 작사가 및 창작 작가
- 동물 과학자
- 홍보 전문가
- 수학자 / 세무사 / 금융 정량 분석가
- 웹 및 디지털 인터페이스 디자이너
설문조사와 광고기업
중국 최대 미디어 광고 그룹이 카피라이터와 디자이너 등에 대한 아웃소싱(외주)을 무기한 중단하고 챗GPT 같은 생성형 인공지능(AI) 기구로 대체를 선언했다. 14일 홍콩 사우스차이나모닝포스트(SCMP)에 따르면, 광고회사 블루포커스는 내부 이메일을 통해 “생성형 AI를 전적으로 수용하기 위해 카피라이터, 디자이너, 단기 계약직 등 특정 분야의 아웃소싱 비용을 즉시 절감할 것”이라고 밝혔다.
시장 와해 사례: 에너지 기업

AI가 에너지 회사에서 250명의 업무를 수행하고 숙련된 직원보다 고객을 더 잘 만족시키고 있다.
영국에 본사를 둔 가정용 에너지 공급업체인 옥토퍼스 에너지의 CEO는 인공지능이 회사 직원 250명의 업무를 대신하고 있다고 말했다.
런던 타임즈에 기고한 글에서 Greg Jackson은 회사가 몇 달 동안 AI를 실험해 왔다고 말했다. 그는 이 기술이 회사 시스템에 통합되어 2월부터 직원들이 일부 고객 이메일에 답장을 보내도록 허용하기 시작했다고 말했다.
현재 AI는 고객 이메일의 3분의 1 이상에 답장하고 있으며, 이는 약 250명의 직원이 처리하는 업무라고 CEO는 말했다.
“AI가 작성한 이메일의 고객 만족도는 80%로, 숙련되고 훈련된 사람이 작성한 65%보다 훨씬 높았다.”
시장 와해 사례: Stackoverflow
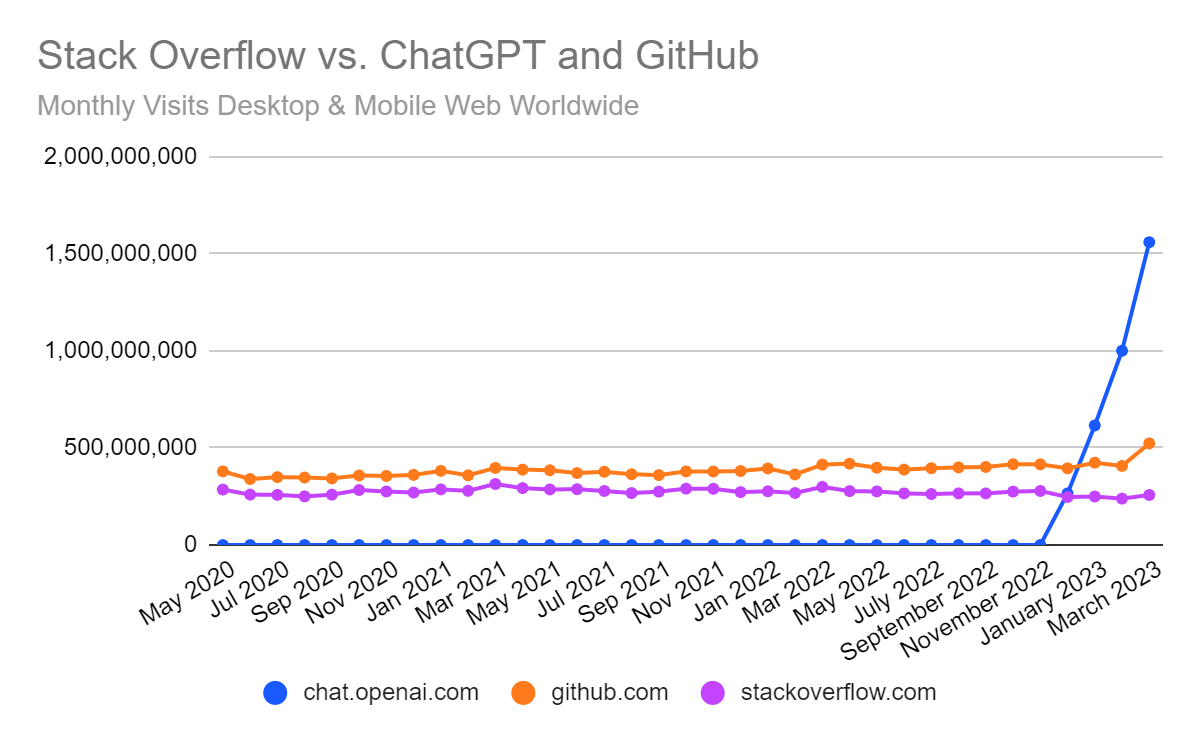


개발자들은 점점 더 많은 조언을 Stackoverflow 게시판이 아닌 AI 챗봇과 GitHub CoPilot에서 얻고 있다.
- 스택 오버플로의 트래픽은 2022년 1월 이후 매월 평균 6%씩 감소하고 있으며, 3월에는 13.9% 감소했다.
- ChatGPT는 11월 말에 출시되어 전년 대비 실적은 없지만, 웹사이트는 그 짧은 시간 동안 전 세계 트래픽에서 Microsoft의 Bing 검색 엔진보다 더 많은 트래픽을 기록하며 세계에서 가장 인기 있는 디지털 자산 중 하나로 자리 잡았다. 3월에는 16억 건, 4월 상반기에는 9억 2,070만 건이 방문했다.
- GitHub 웹사이트도 3월에 전년 대비 26.4% 증가한 5억 2,400만 건의 트래픽을 기록하는 등 강력한 성장세를 보이고 있는데, 일반적으로 Visual Studio Code와 같은 코드 편집기 내에서 이루어지는 CoPilot의 모든 사용량이 반영되어 있지는 않지만, 서비스 구독을 위해 웹사이트를 방문하는 사람들도 포함된다.
- 2월부터 3월까지 GitHub CoPilot 무료 평가판 가입 페이지 방문 수는 3배 이상 증가하여 80만 건을 돌파했다.
구글 검색의 종말(?)
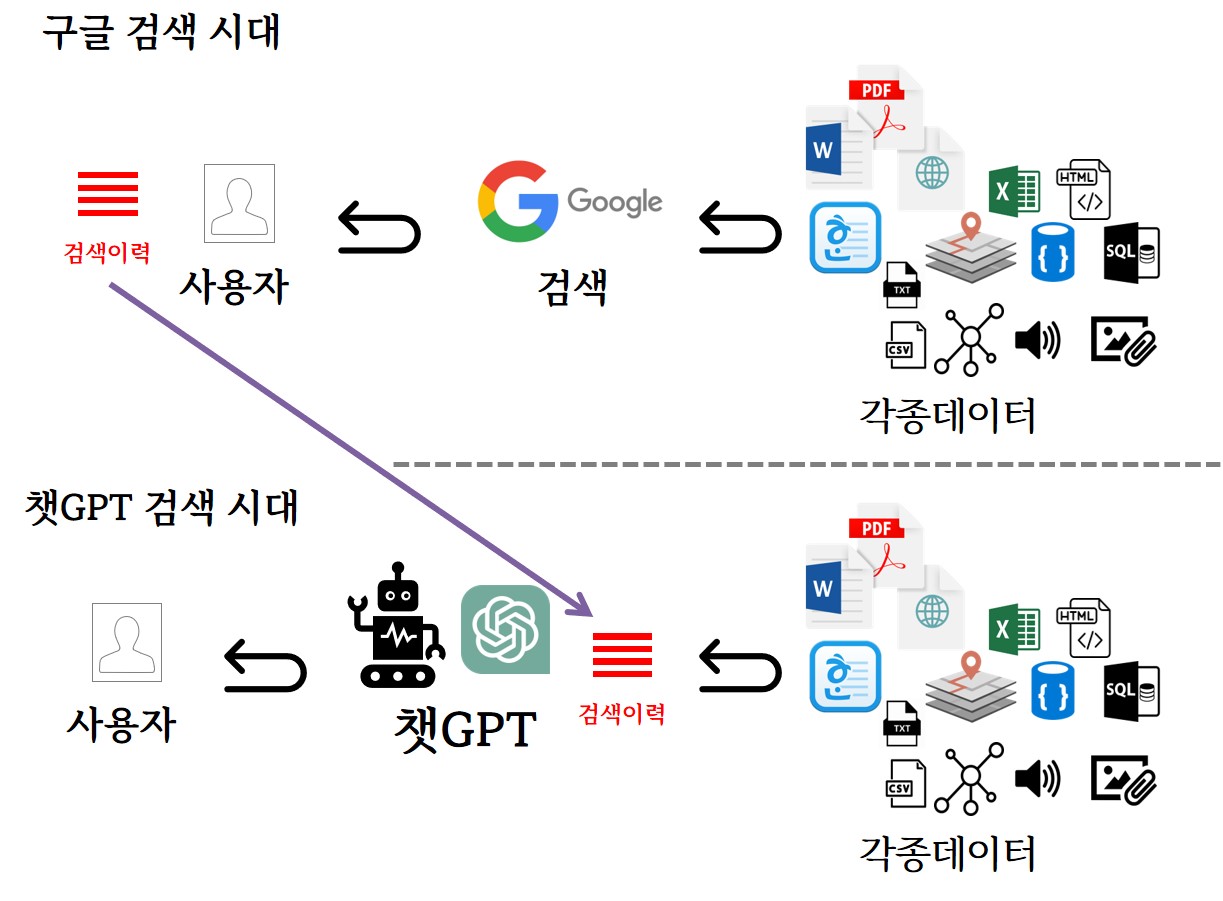
글쓰기 역사

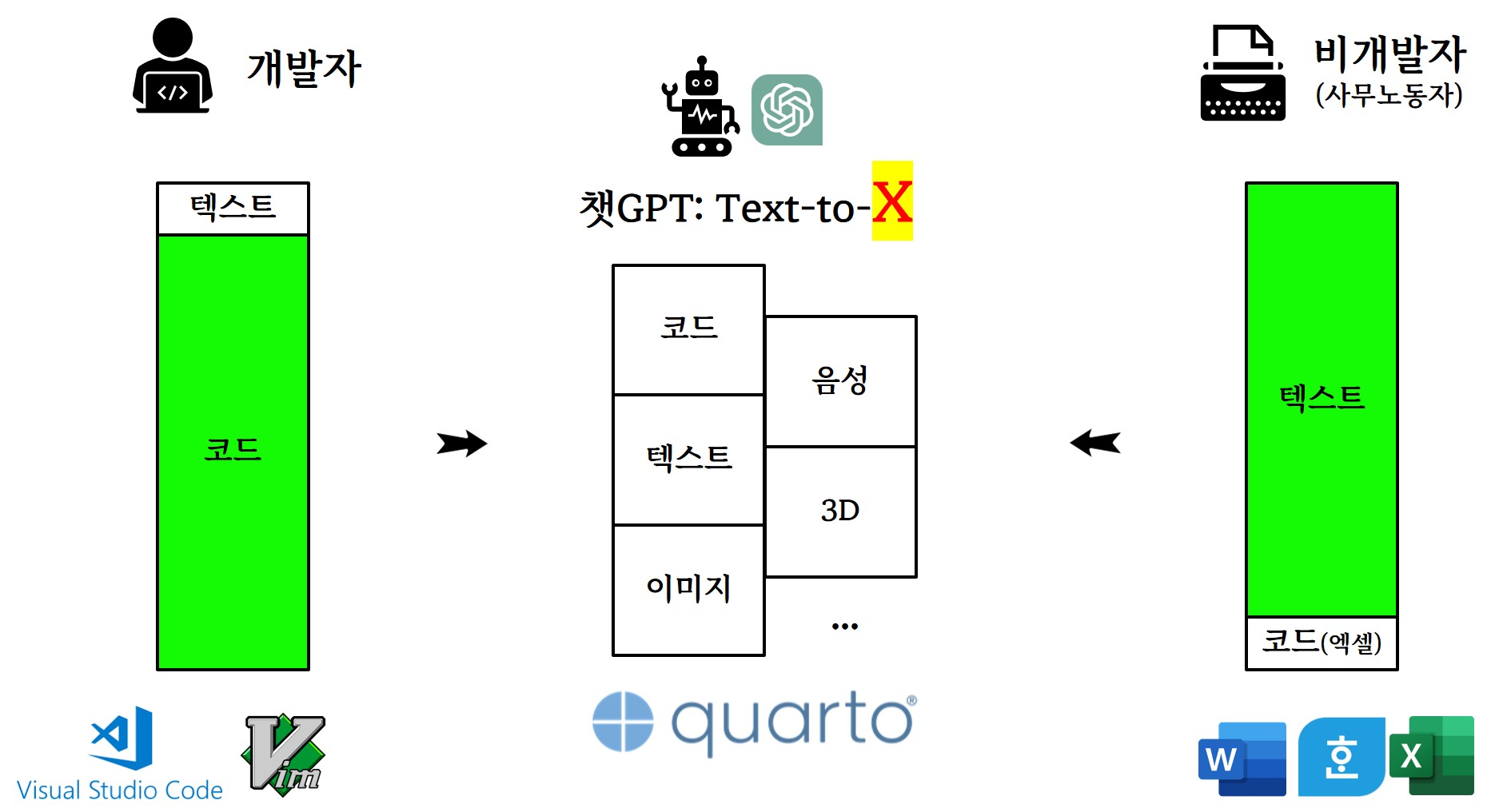
오피스 전쟁: 패러다임 충돌

챗GPT 시대 사무실




챗GPT가 이룬 대통합
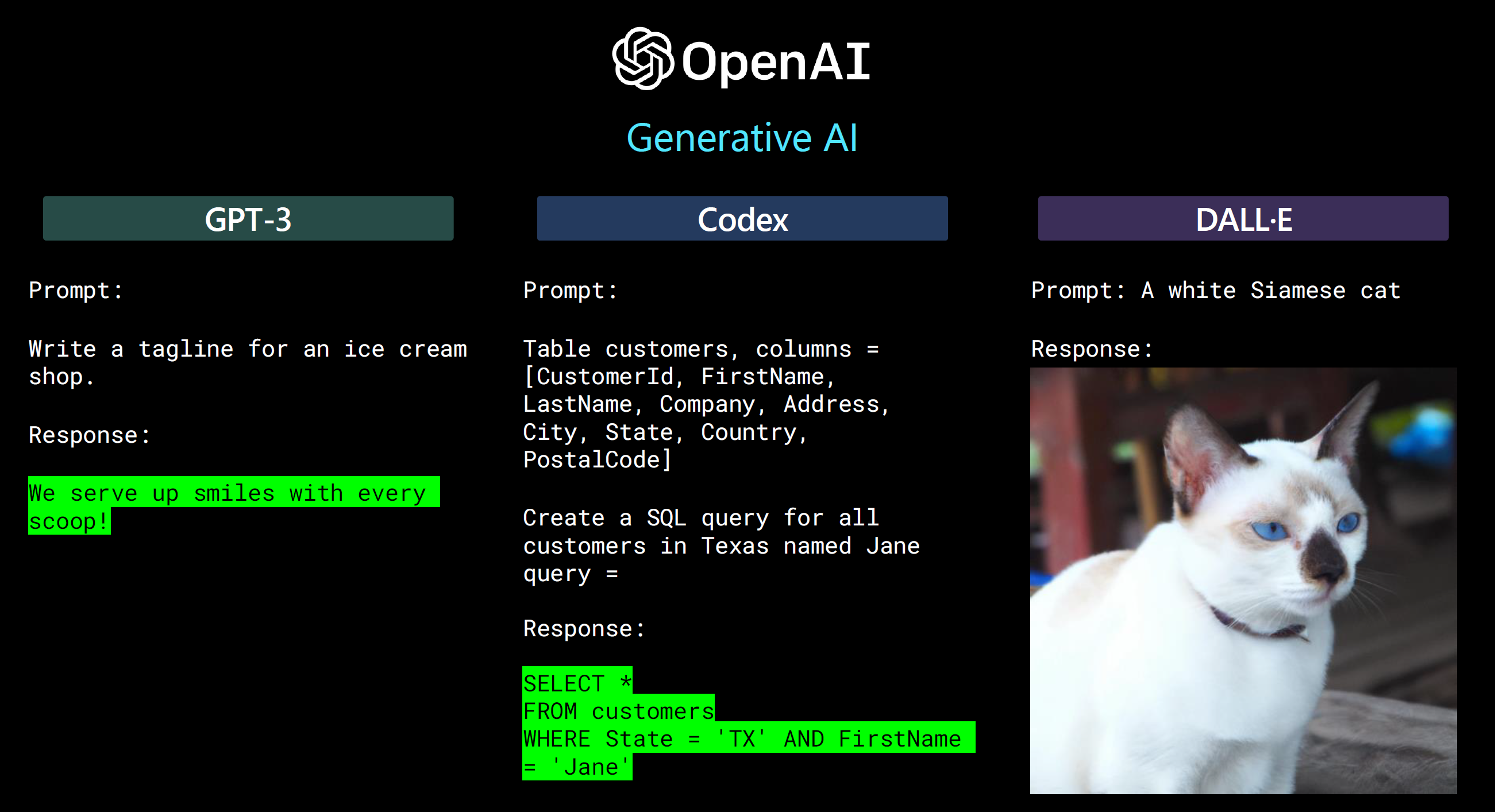
openAI 마이크로소프트 3 대장 + \(\alpha\)
chatGPT 3대장


chatGPT 3대장 + \(\alpha\) 추론
디오판토스 묘비
신의 축복으로 태어난 그는 인생의 \(\frac{1}{6}\)을 소년으로 보냈다. 그리고 다시 인생의 \(\frac{1}{12}\) 이 지난 뒤에는 얼굴에 수염이 자라기 시작했다. 다시 \(\frac{1}{7}\)이 지난 뒤 그는 아름다운 여인을 맞이하여 화촉을 밝혔으며, 결혼한 지 5년 만에 귀한 아들을 얻었다. 아! 그러나 그의 가엾은 아들은 아버지의 반 밖에 살지 못했다. 아들을 먼저 보내고 깊은 슬픔에 빠진 그는 그 뒤 4년간 정수론에 몰입하여 스스로를 달래다가 일생을 마쳤다. [^1]
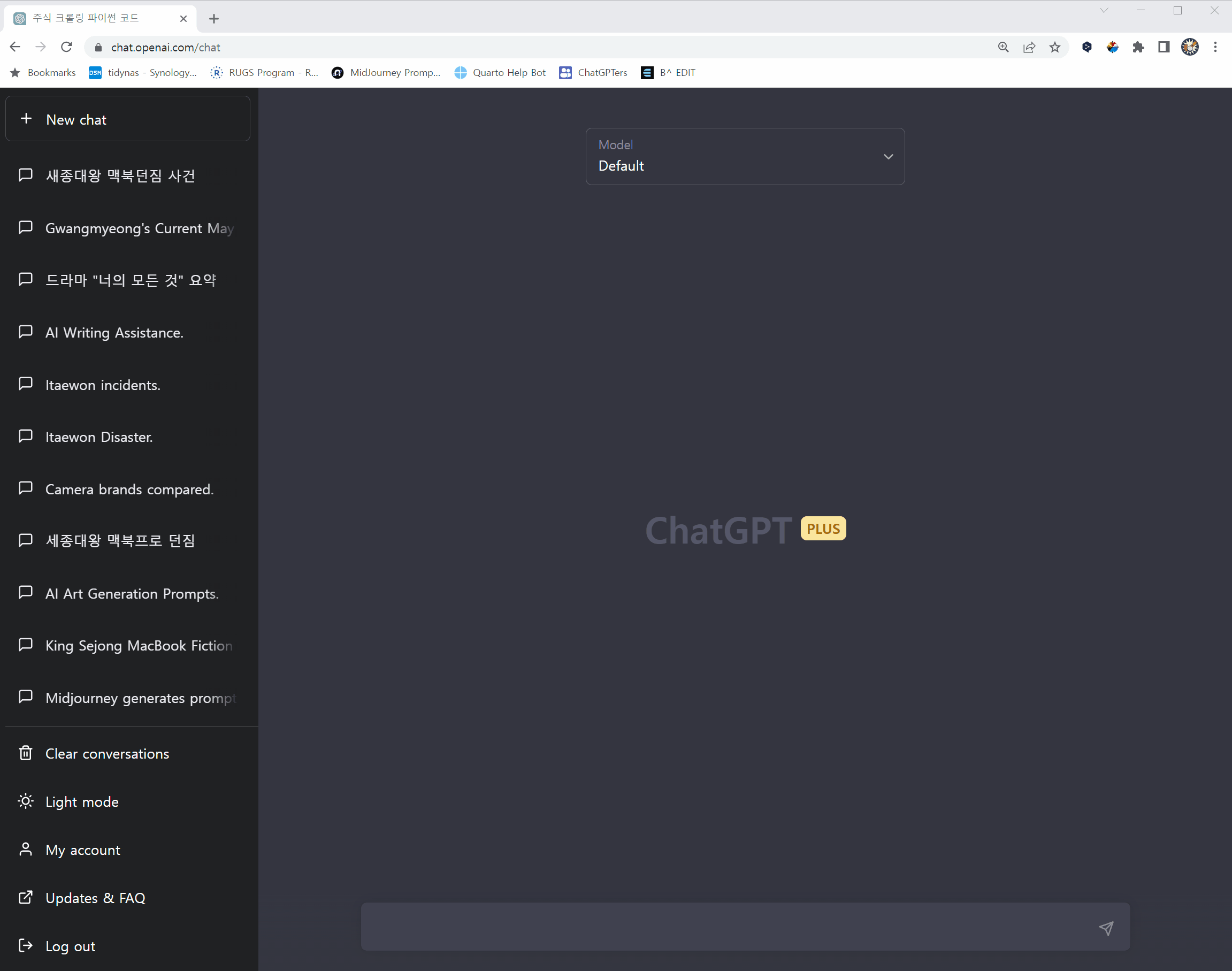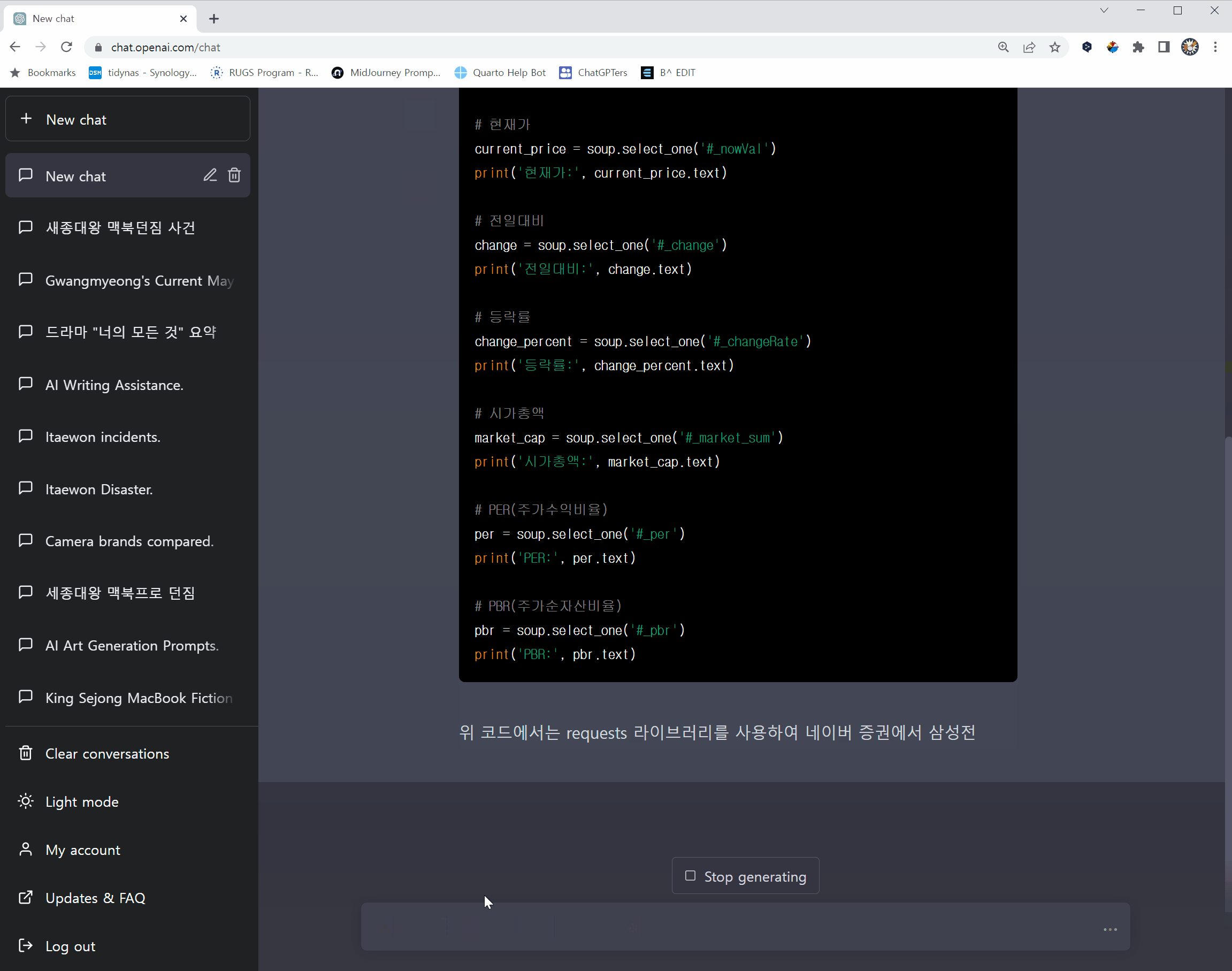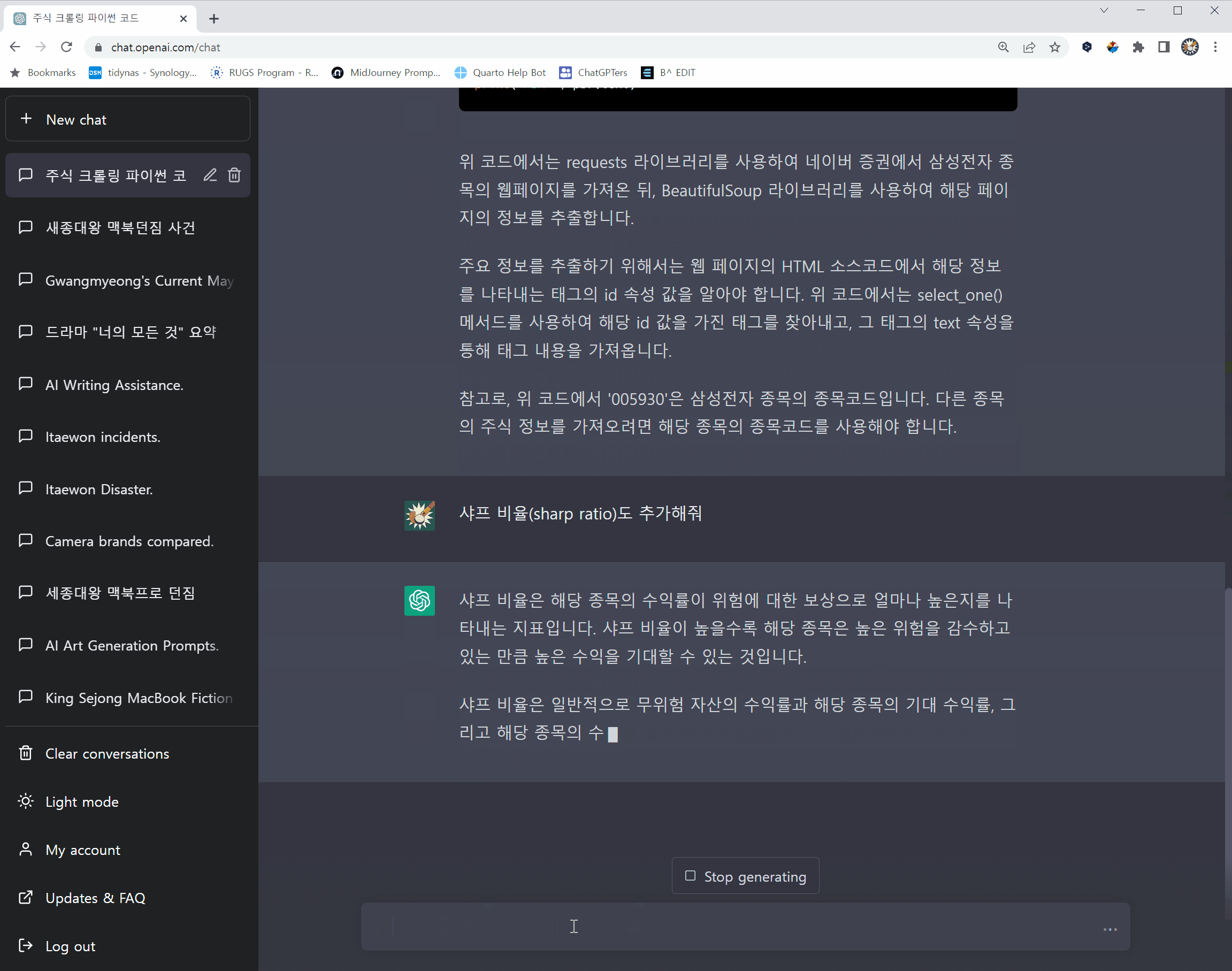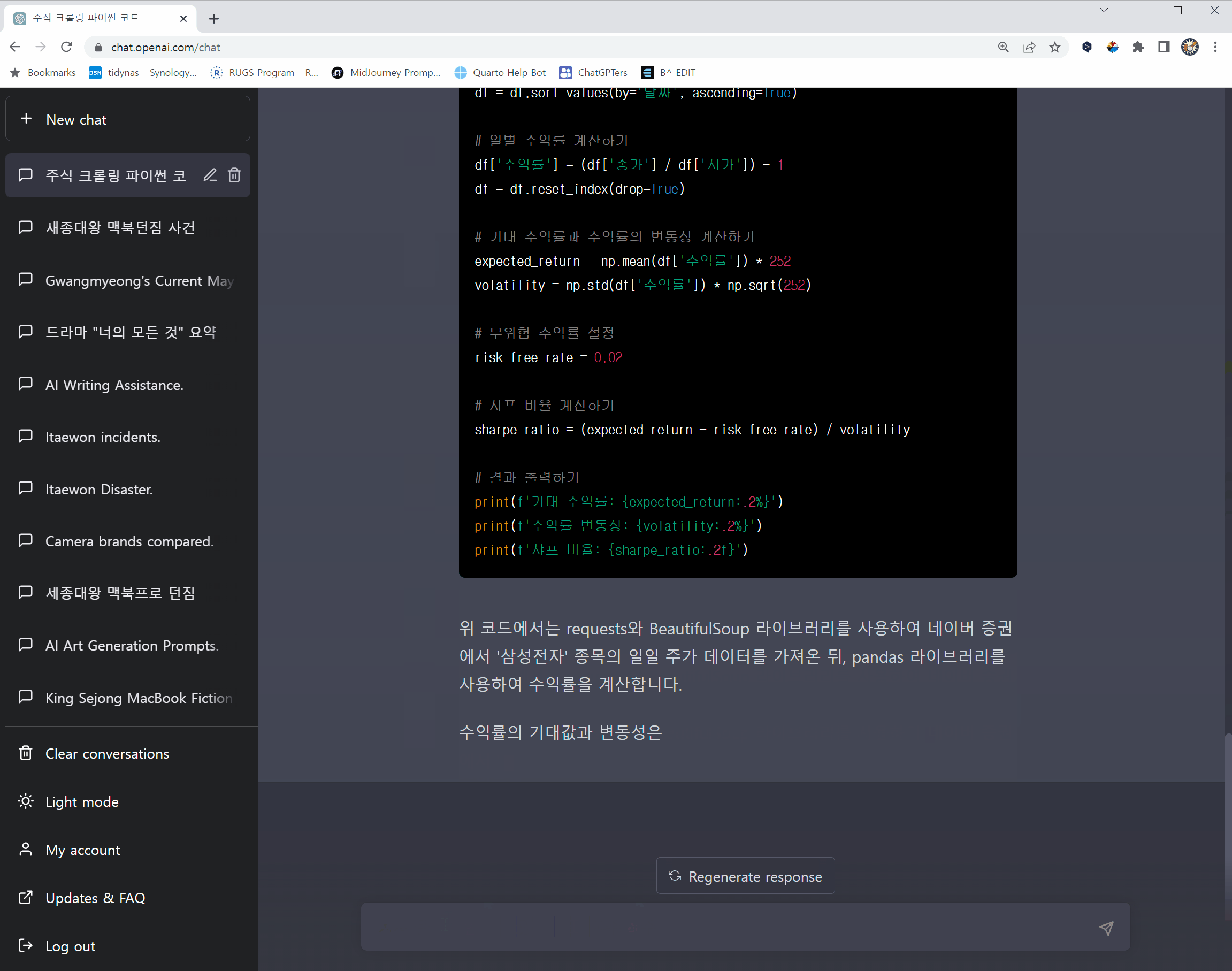
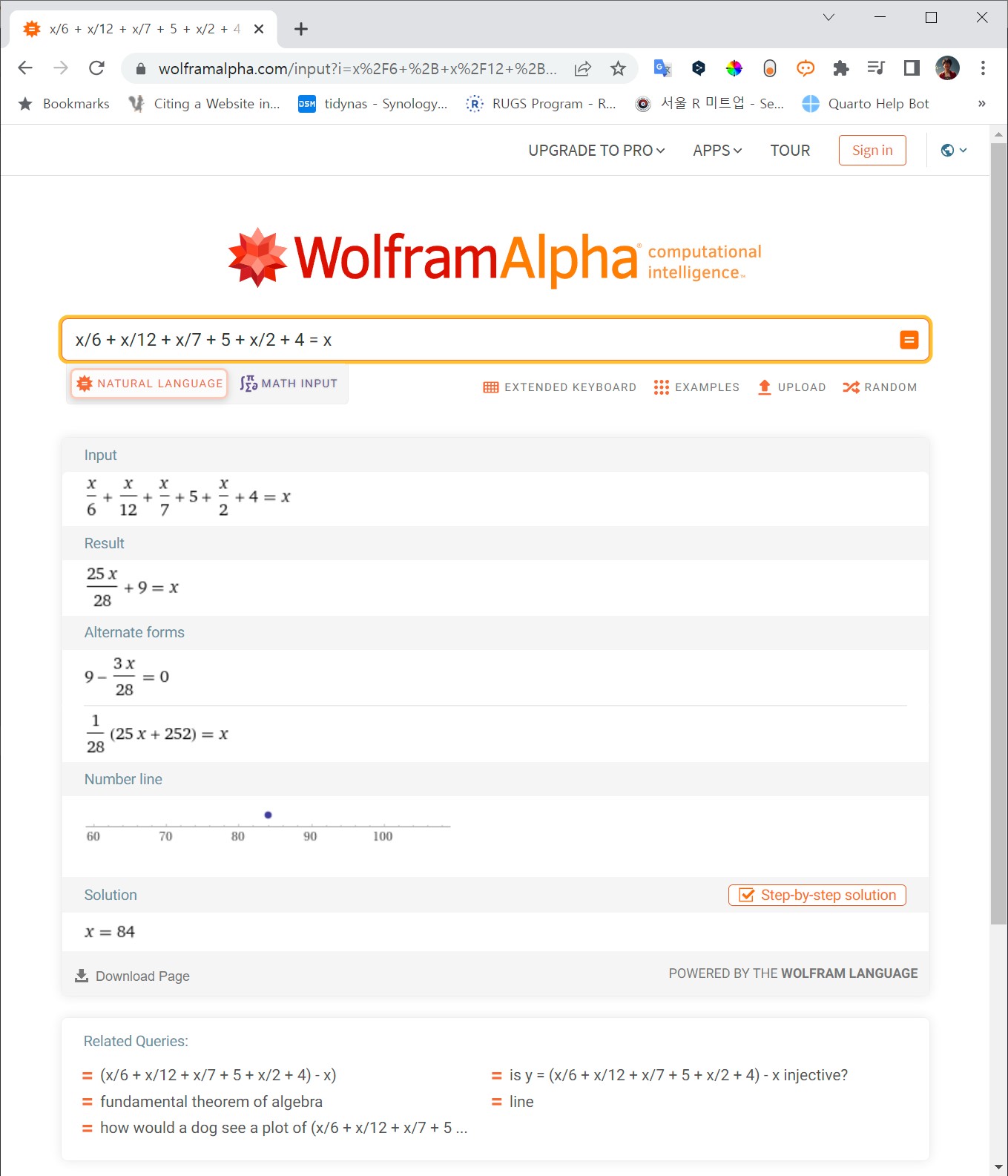
디오판토스가 정확히 언제 태어나고 언제 죽었는지는 명확하지 않지만, 그가 죽었을 때의 나이는 정확히 알 수 있다. 이를 방정식을 통해 풀어보자. 수식을 \(x\)에 대해 정리해서 풀면 84가 나온다.
\[\frac {x} {6} + \frac {x} {12} + \frac {x} {7} + 5 + \frac {x} {2} + 4 = x\]

[{x: 84}]

데이터 분석: Text-to-Analytics

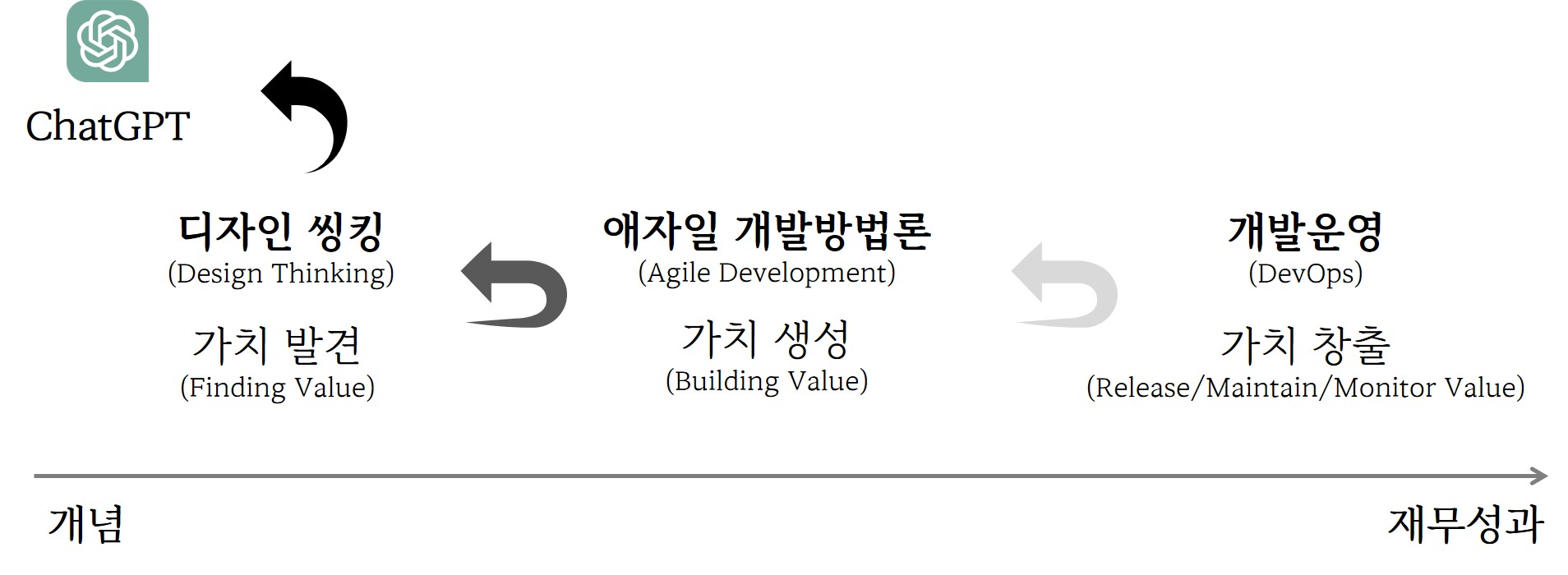
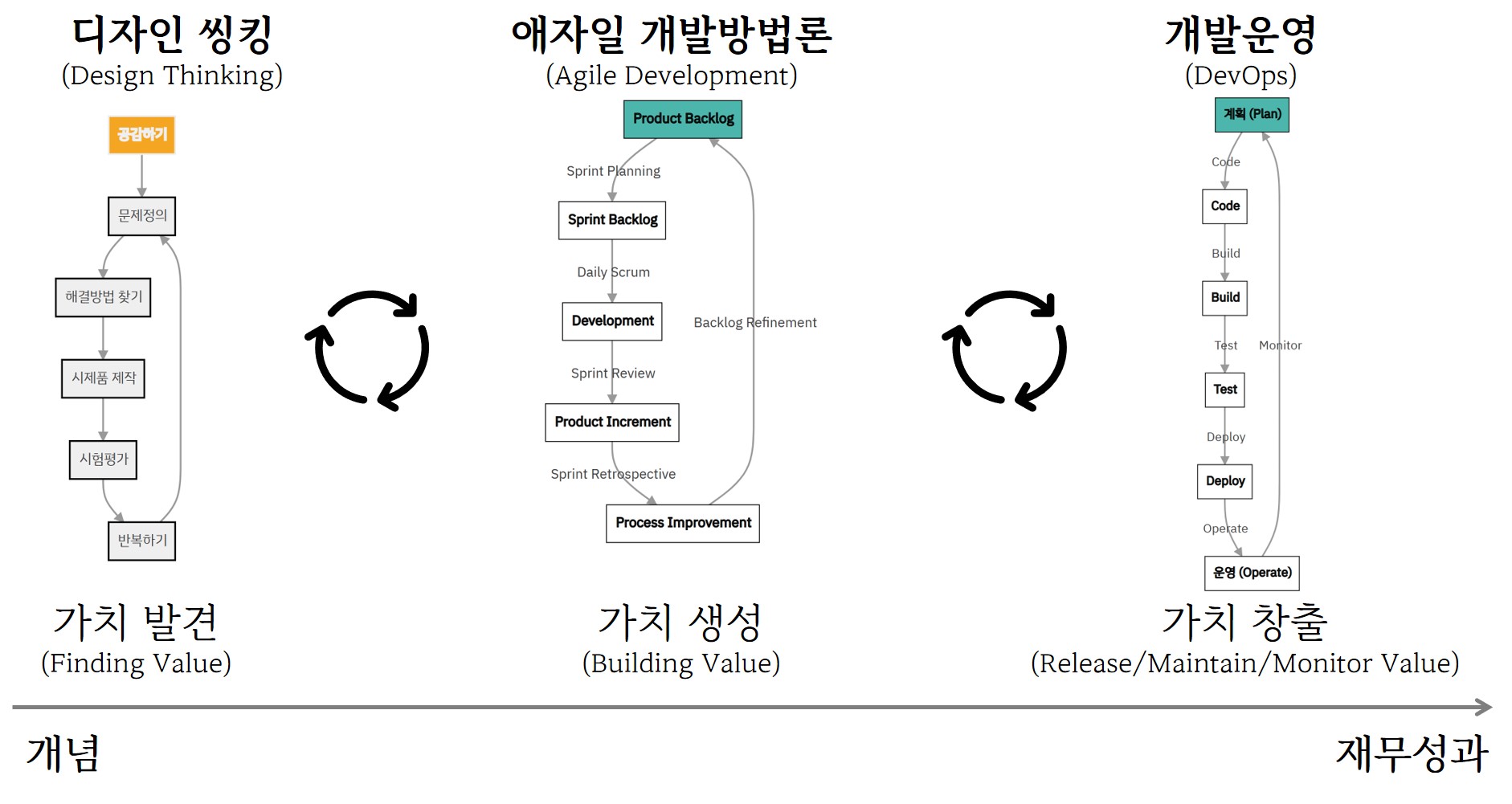
DT → Agile → DevOps


소프트웨어 3.0

Andrej Karpathy
- 소프트웨어 1.0: 코드 작성을 통한 프로그래밍
- 소프트웨어 2.0: 데이터셋 큐레이팅을 통한 프로그래밍
- 소프트웨어 3.0: 프롬프트 엔지니어링을 통한 프로그래밍 (LLM에 입력으로 제공, GPT 스타일)
프롬프트 공학



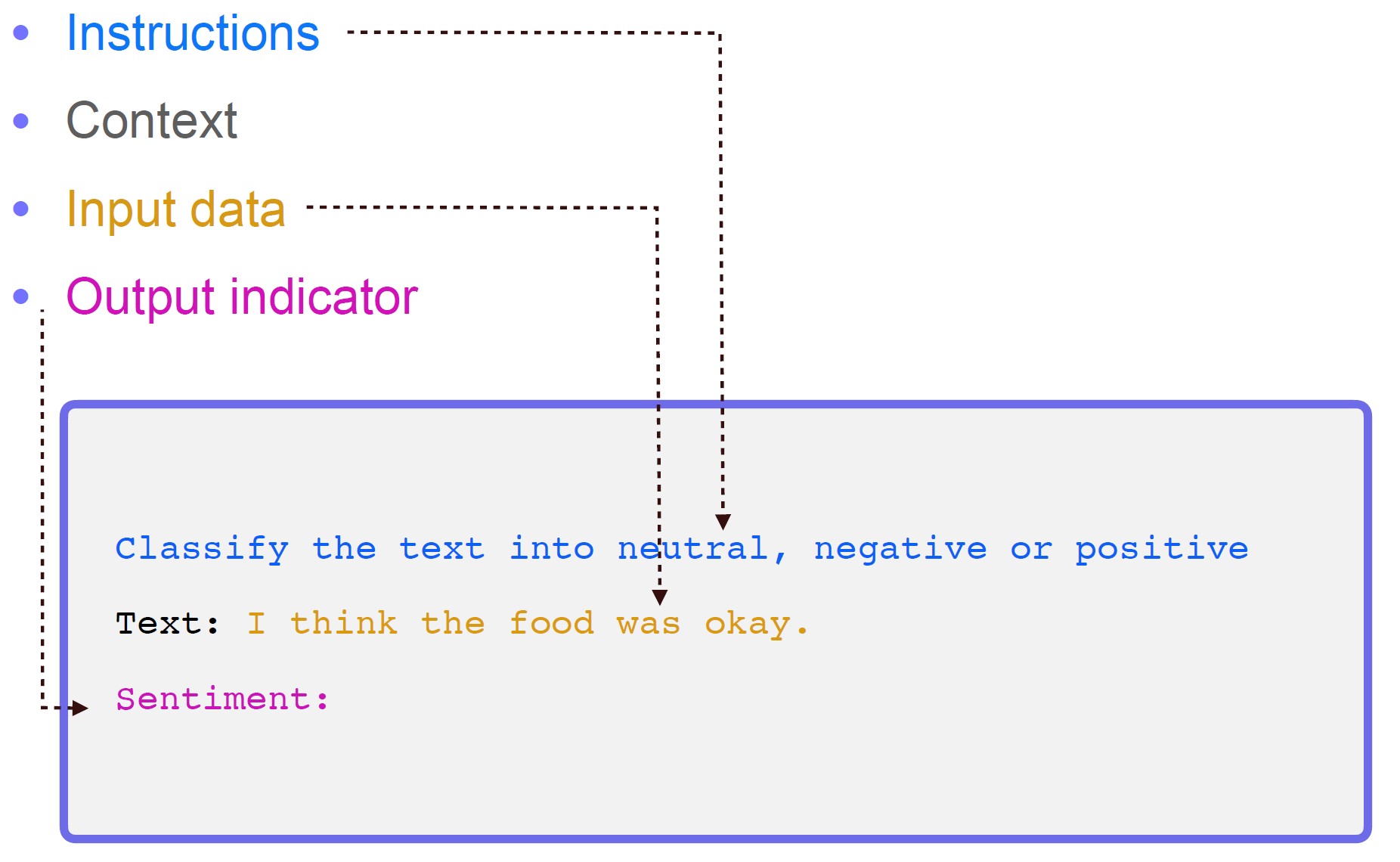
배경 - 프롬프트 엔지니어링


프롬프트 엔지니어링 (Context Stuffing)
보안사고
삼성전자
삼성전자 DS 부문 임직원 A씨는 반도체 설비 계측 데이터베이스(DB) 다운로드 프로그램의 소스 코드를 실행 중 오류를 확인했다. 문제가 된 소스 코드 전부를 복사해 챗GPT에 입력, 해결 방법을 문의했다. 삼성전자 설비 계측과 관련한 소스 코드가 오픈AI 학습 데이터로 입력된 셈이다.
임직원 B씨는 수율·불량 설비 파악을 위해 작성한 프로그램 코드를 챗GPT에 입력하는 사고를 냈다. 관련 소스 전체를 챗GPT에 입력하고 코드 최적화를 요청했다. 임직원 C씨는 스마트폰으로 녹음한 회의 내용을 네이버 클로바 애플리케이션(앱)을 통해 문서 파일로 변환한 뒤 챗GPT에 입력했다. 회의록 작성 요청이 목적이다.
이탈리아
로이터 통신 등에 따르면 이탈리아 데이터 보호청은 “챗GPT가 이탈리아의 개인정보 보호 기준과 규정을 충족할 때까지 서비스 접속을 일시적으로 차단할 것”이라고 밝혔다.
접속 차단 이유는 개인정보 침해 우려 때문이다. 이탈리아 당국은 챗GPT가 알고리즘 학습을 이유로, 개인정보를 대량으로 수집하고 저장하는 행위를 정당화할 법적 근거가 없다고 지적했다. 보호청은 챗GPT 개발사 오픈AI가 20일 이내에 해결책을 내놓지 않으면 전 세계 매출액의 최대 4%에 달하는 벌금을 물게 될 것이라고 경고하기도 했다.
보안 vs 효율 을 높고 많은 공공기관을 비롯한 기업들이 고민을 하고 있다. 거대언어모형(LLM)에 기반하여 모든 것을 자체 개발하면 상관이 없으나 현실적으로 GPT-3/3.5/4 모형을 갖춘 조직이 전무하지만, 이미 대다수의 사람이 오픈AI 챗GPT를 맛보았기 때문에 생산성 향상을 그냥 두고 넘어가기도 어려운 상황이다. 이런 점에서 챗GPT 제한적 사용이 현재시점(’23년 3월) 최선으로 보이며 점차 오픈소스 거대언어모형(LLM)과 전략적 제휴를 통한 챗GPT 사용이 중장기적 추진방향으로 자리 잡고 있다.

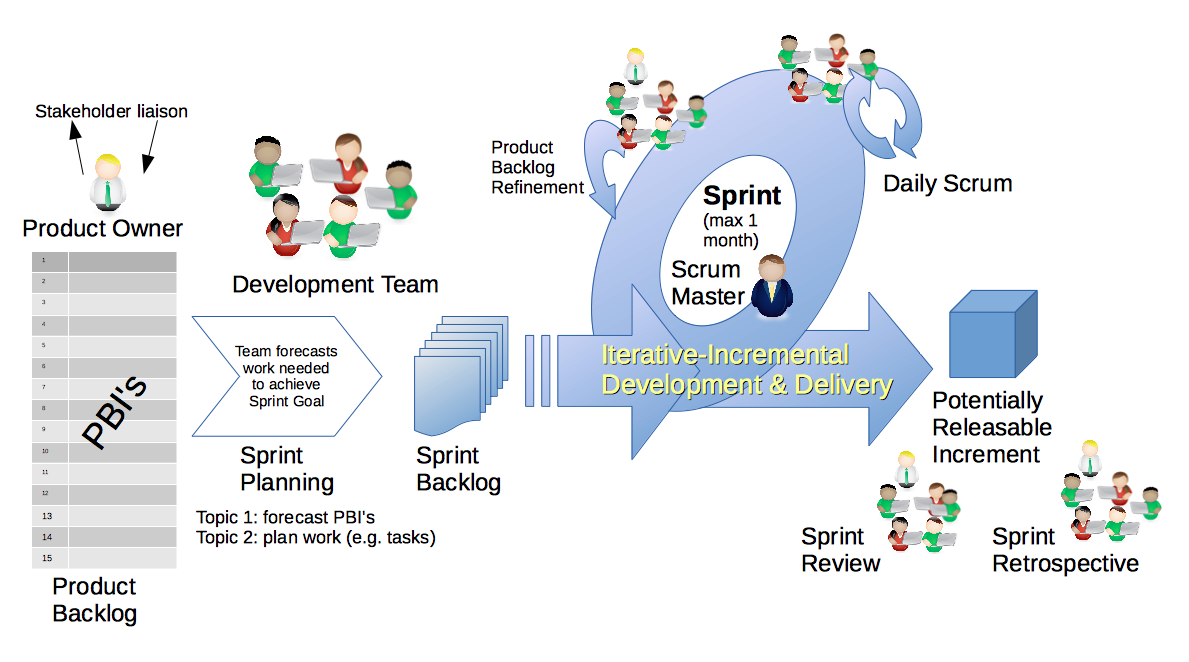
개발방법론 진화


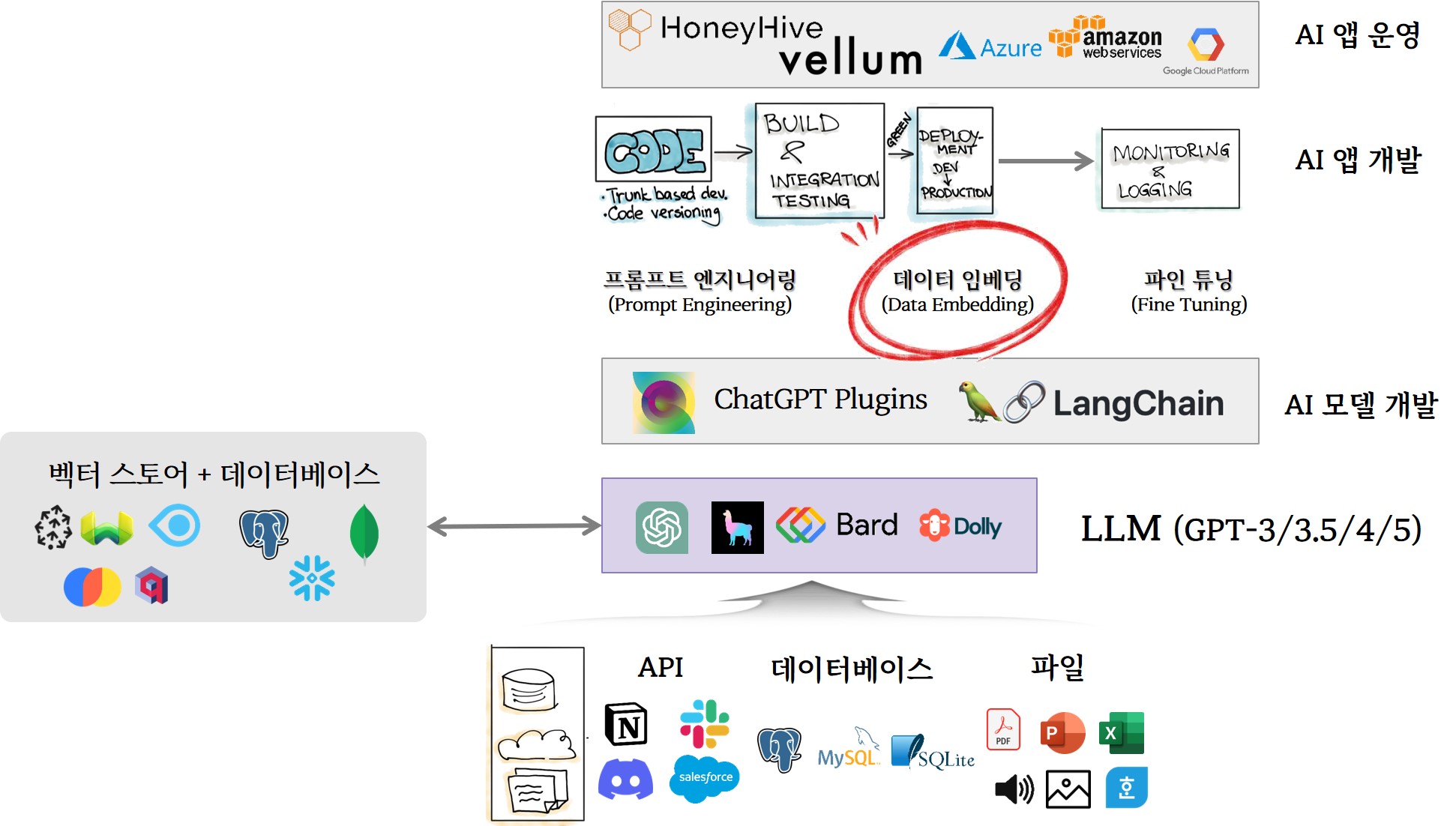
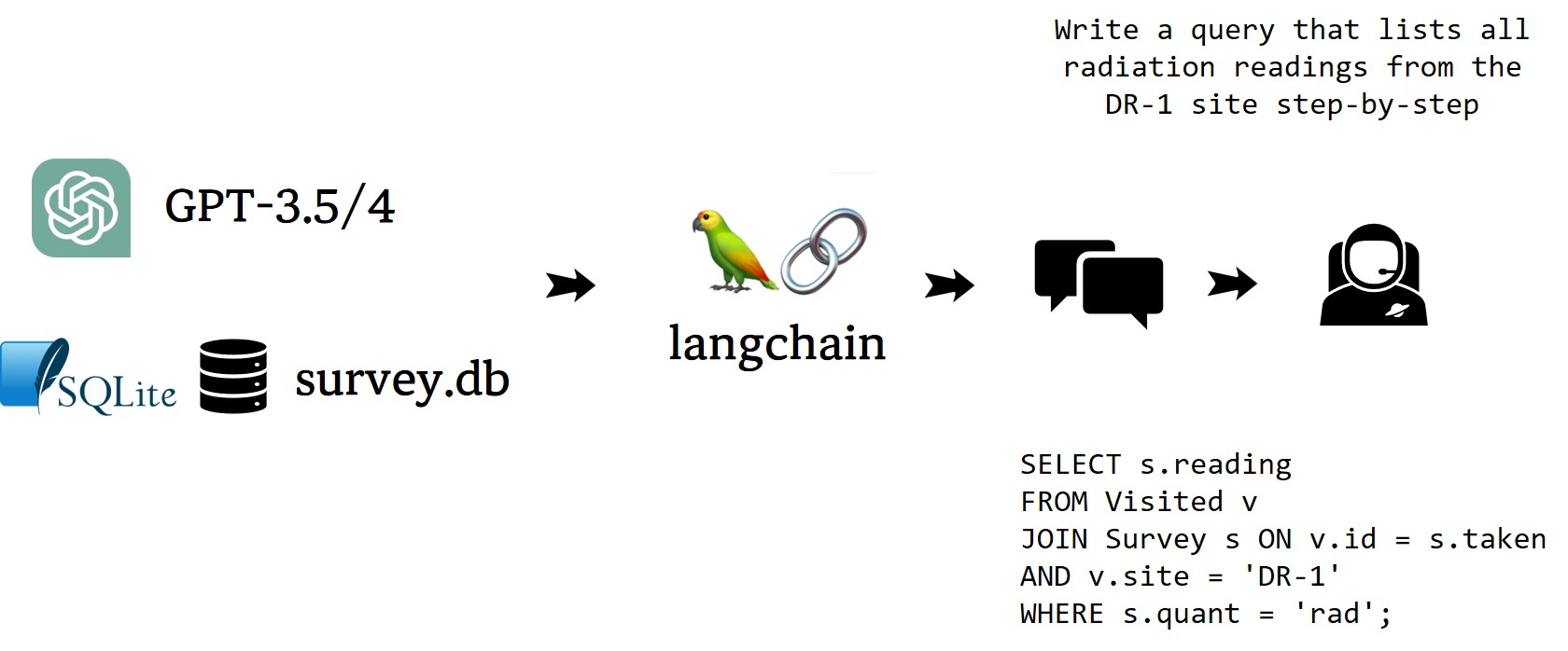
LangChain

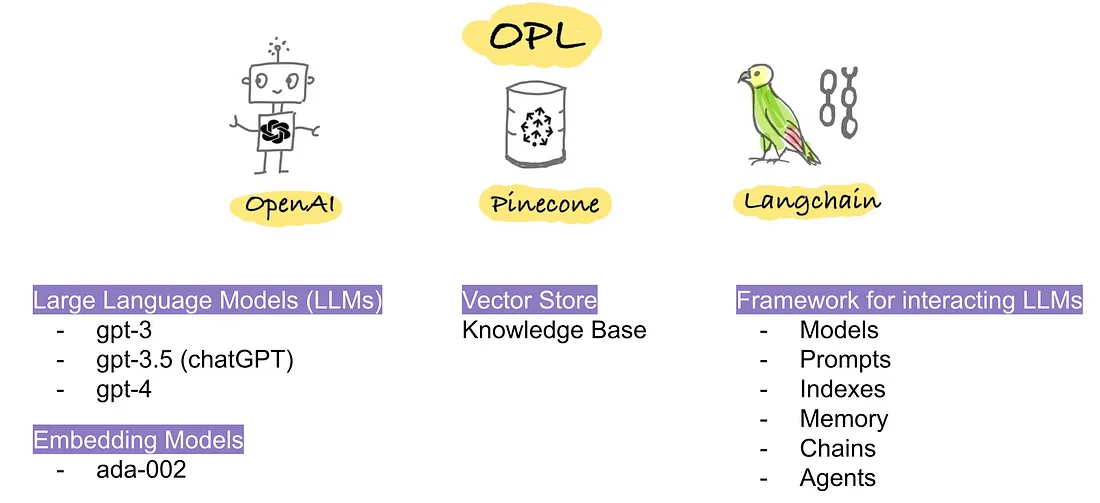
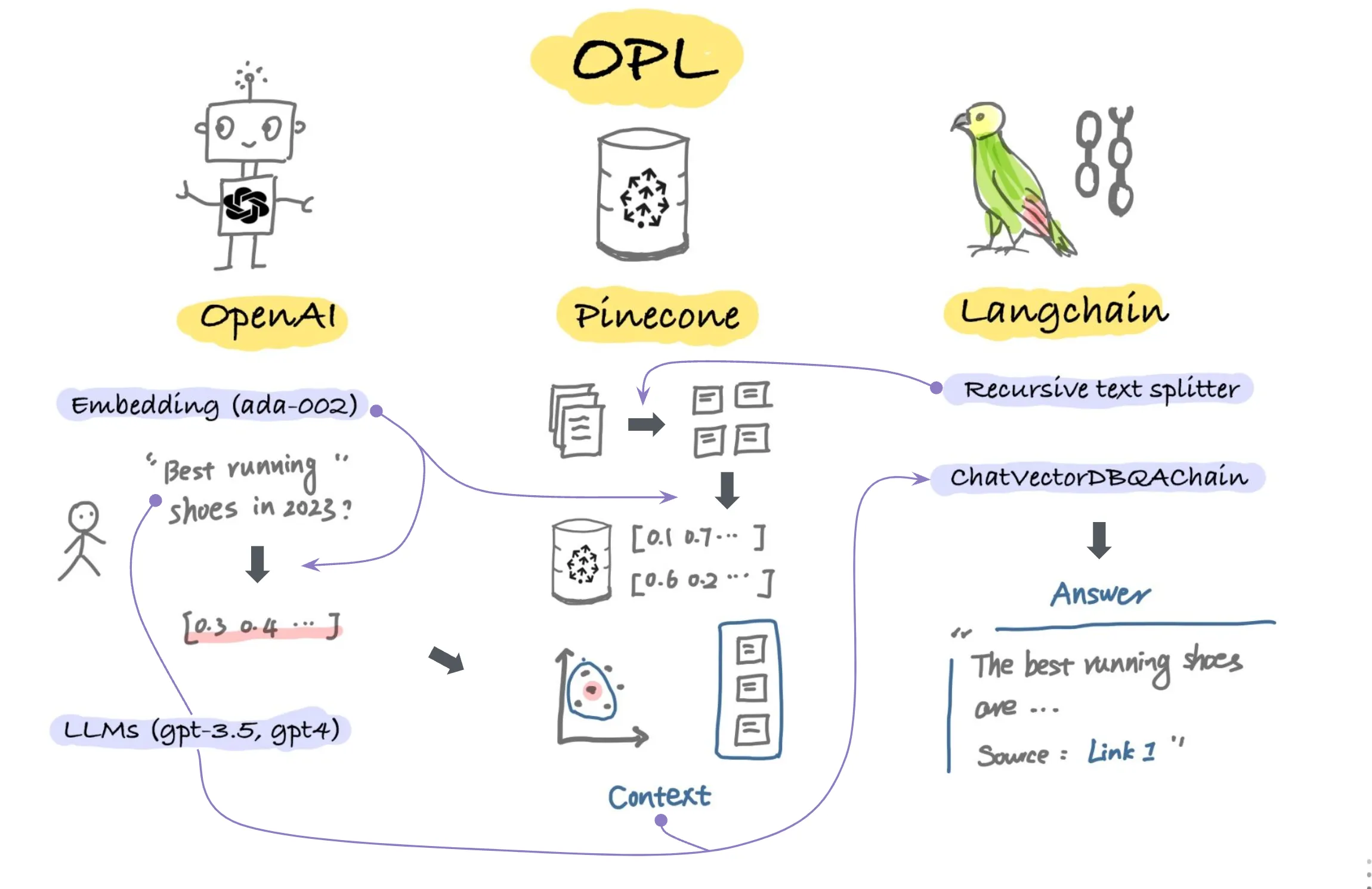
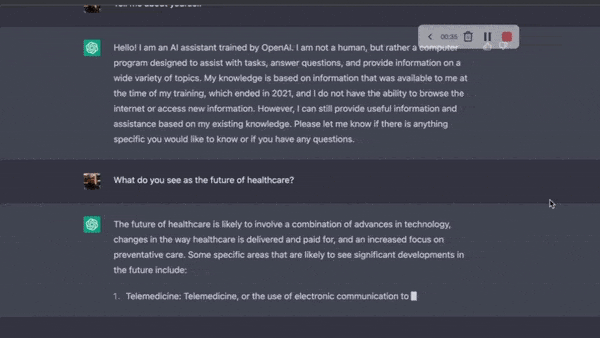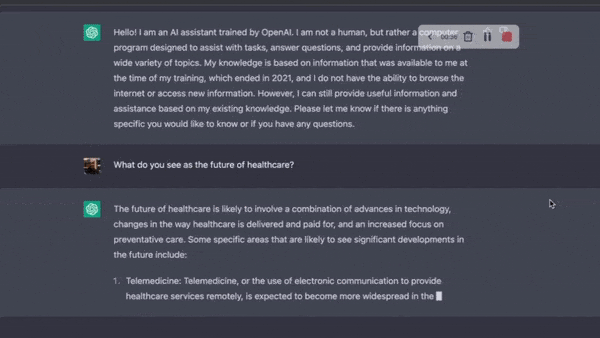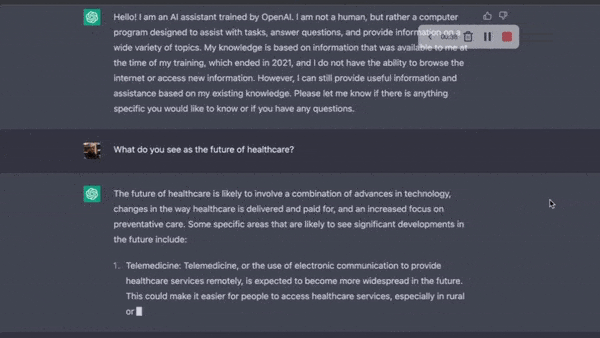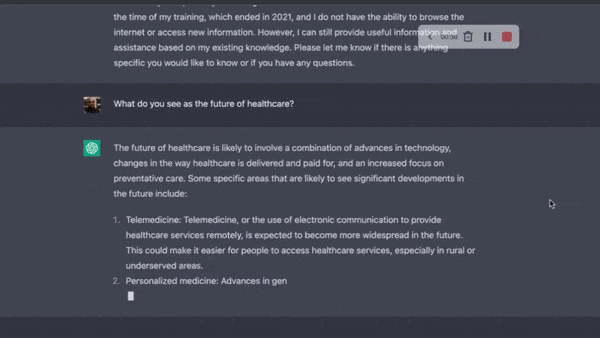
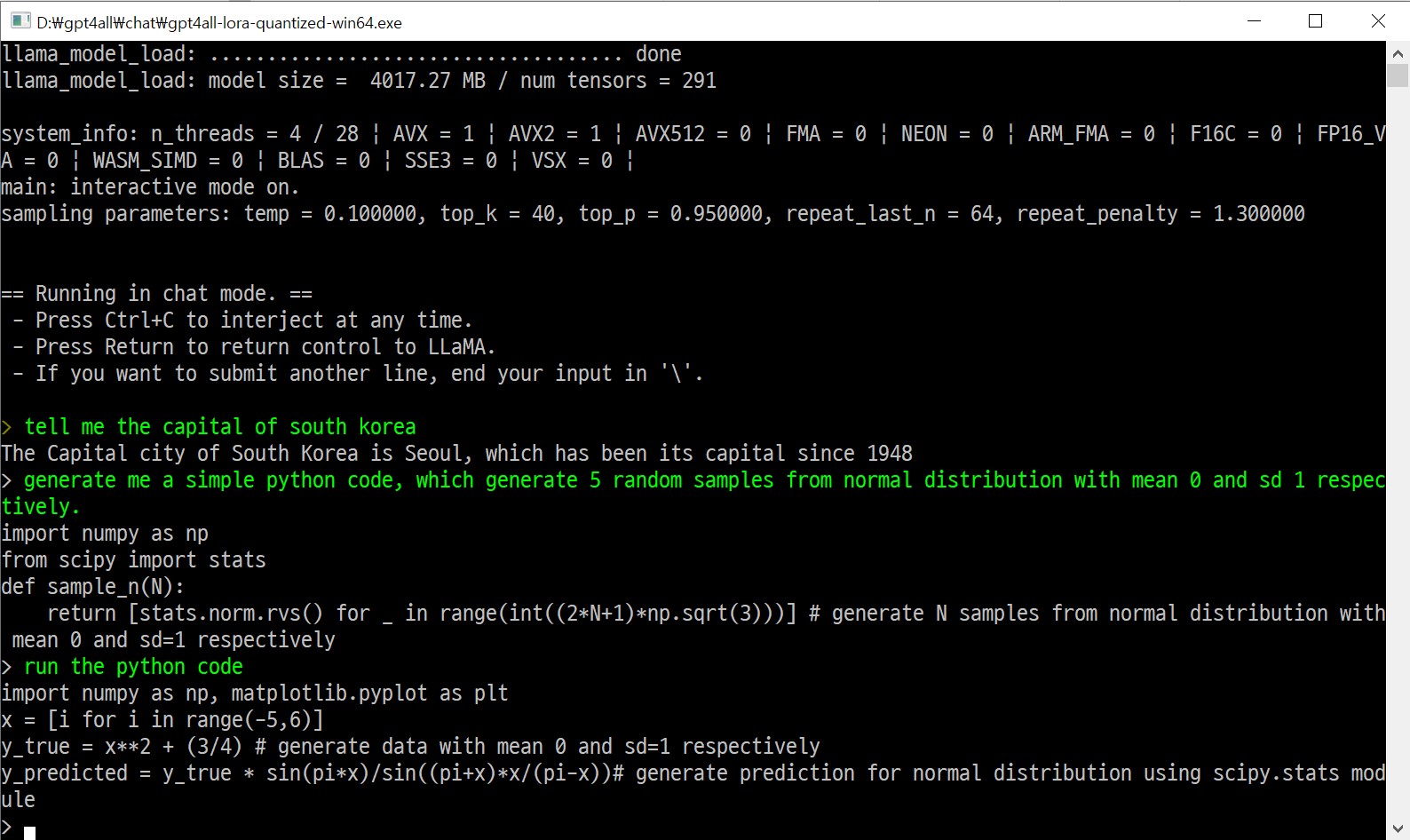
챗GPT 란?

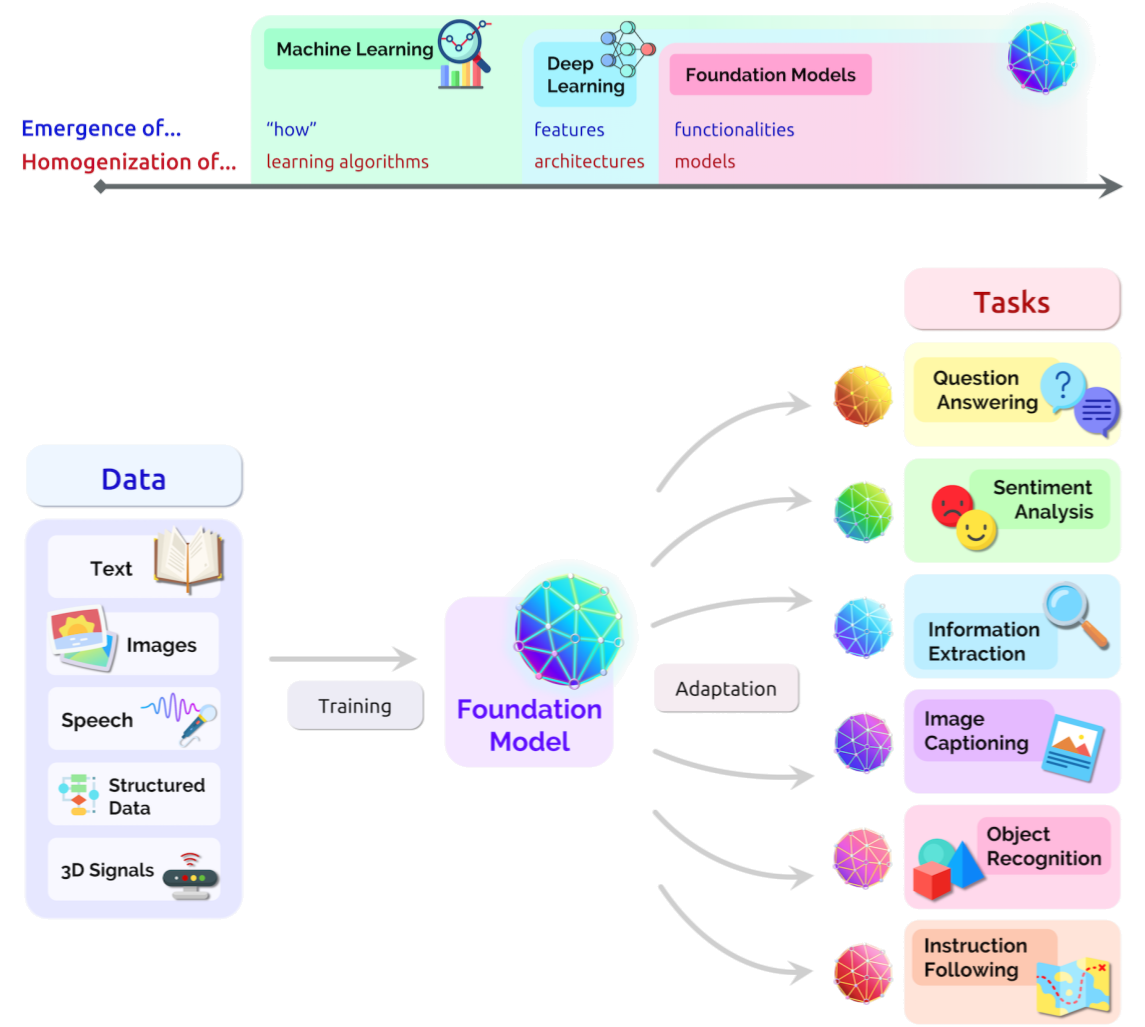
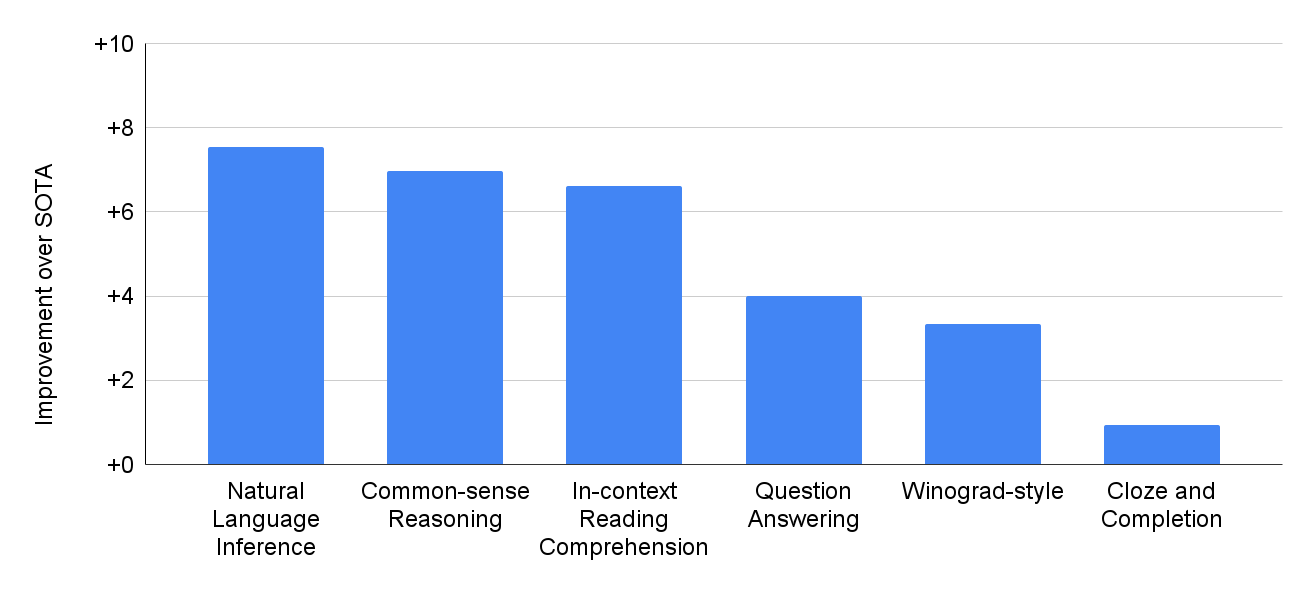
거대 언어모형(LLM)
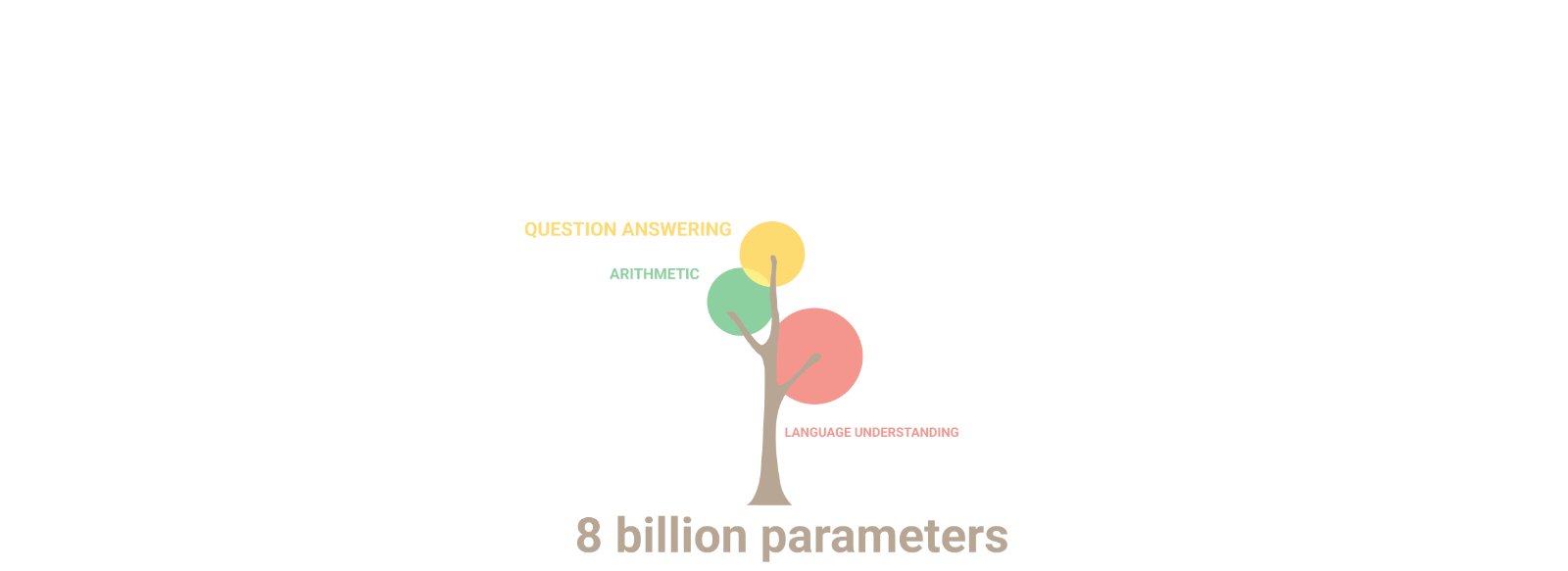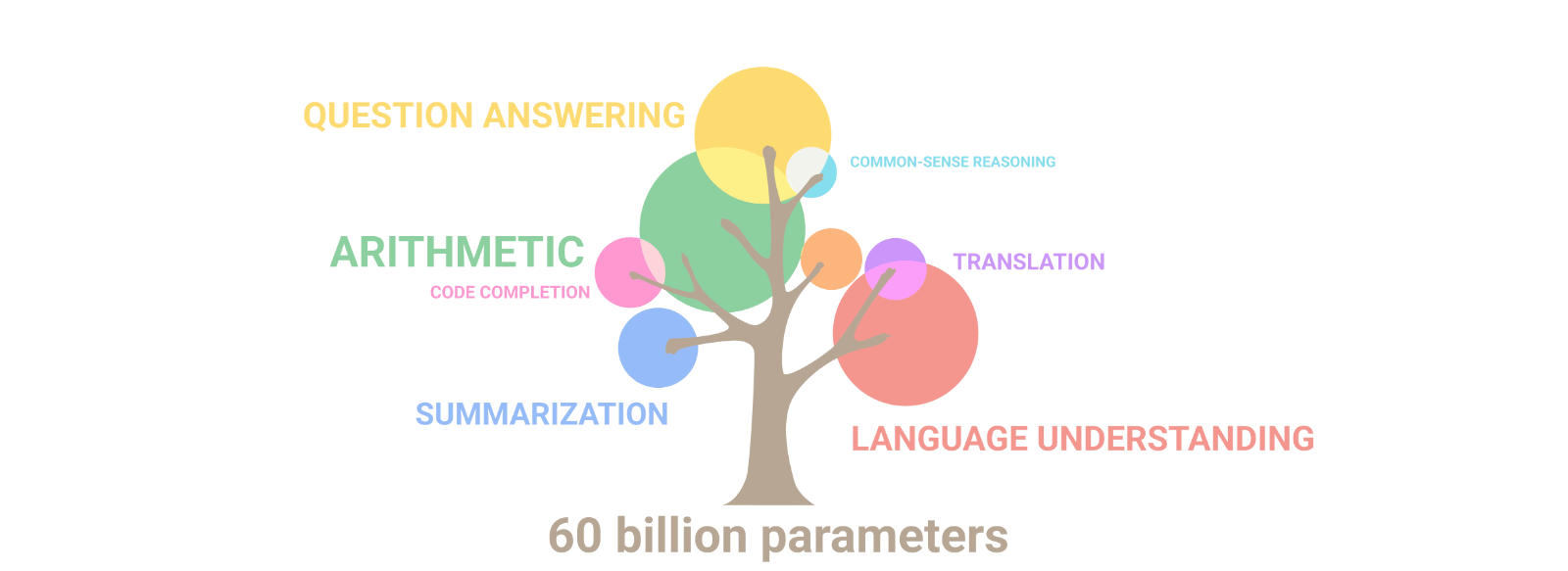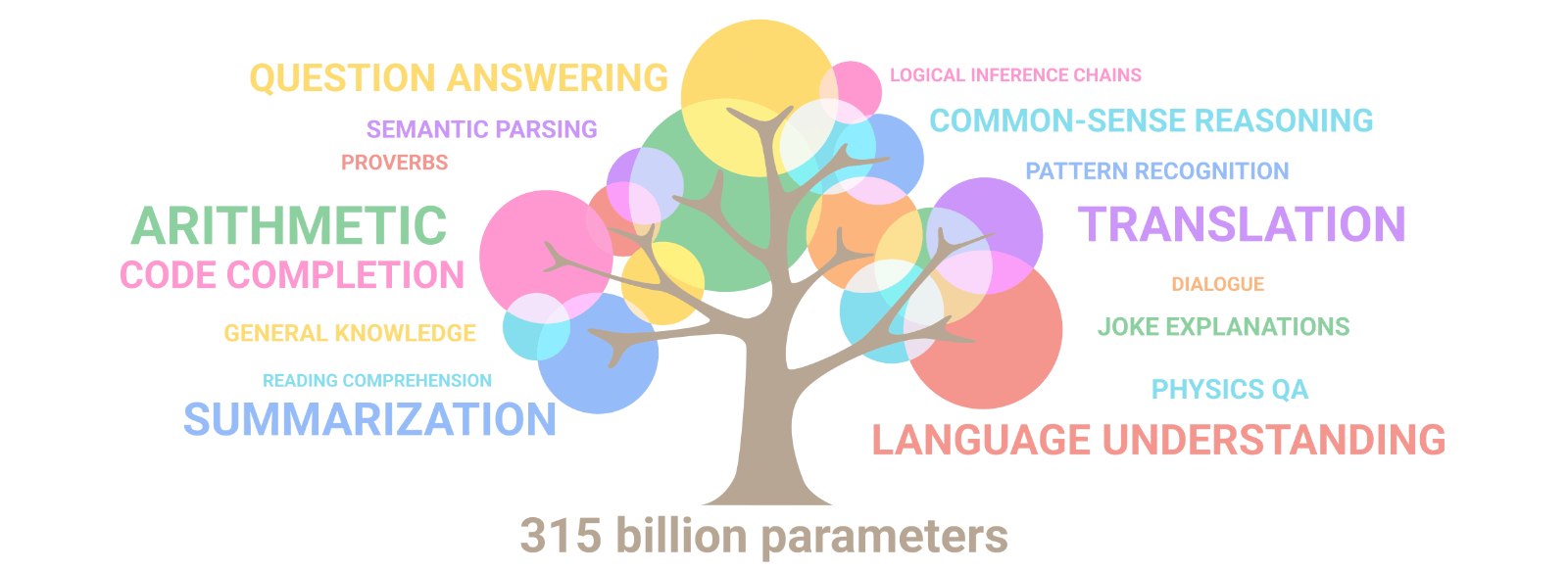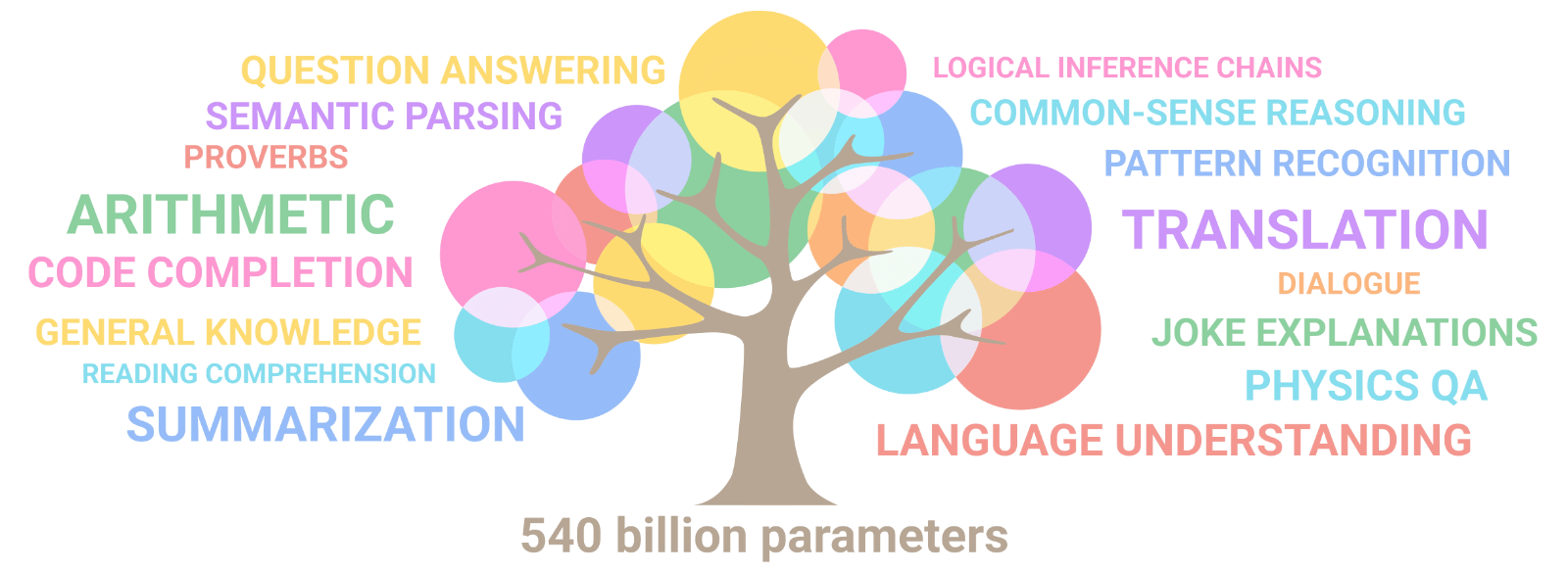
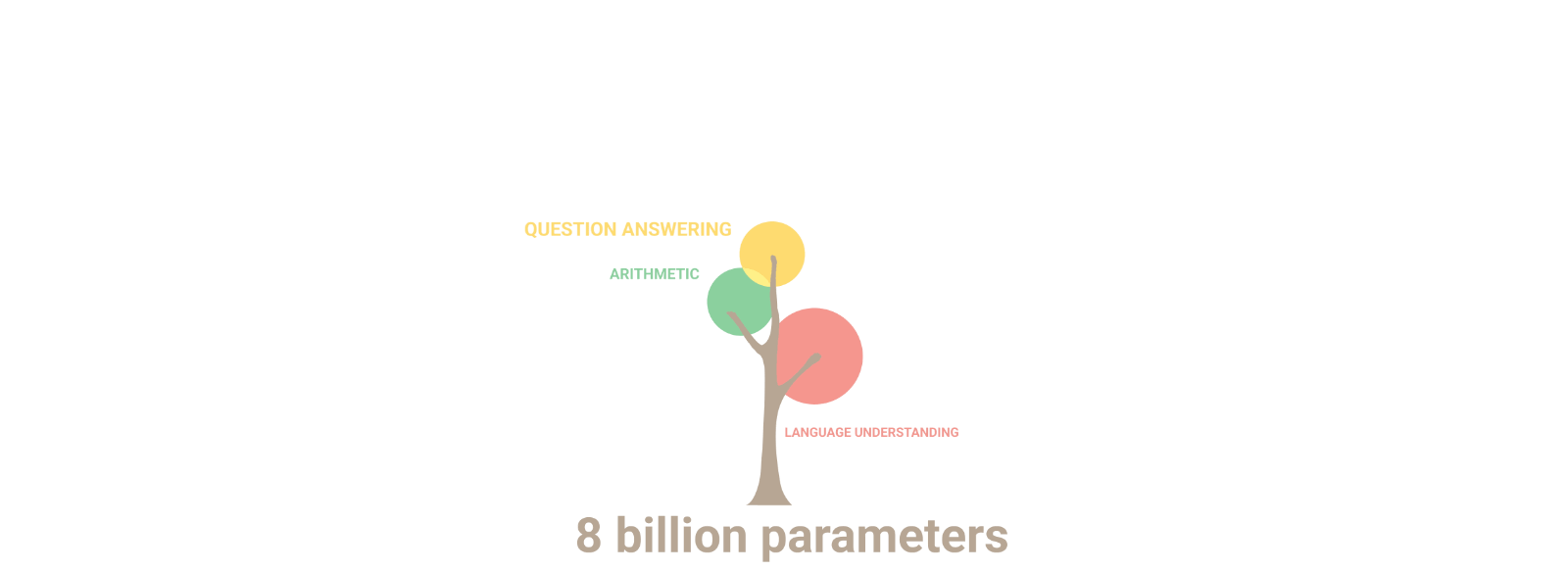
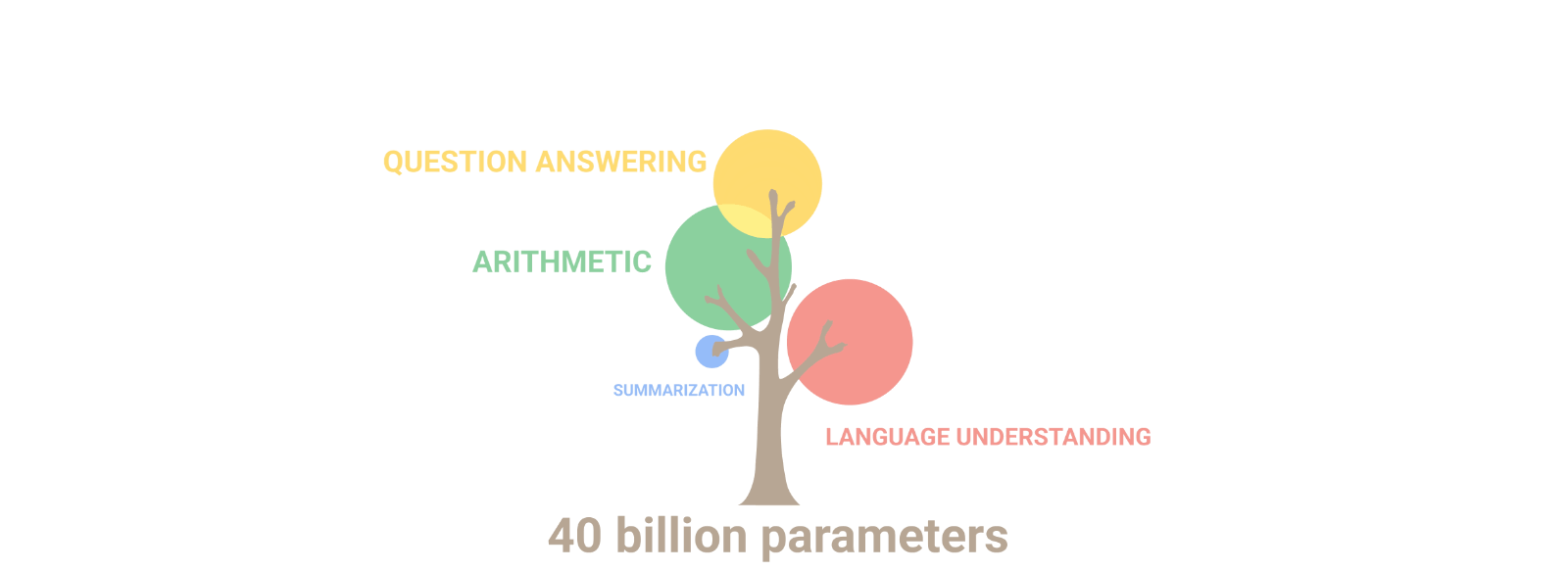
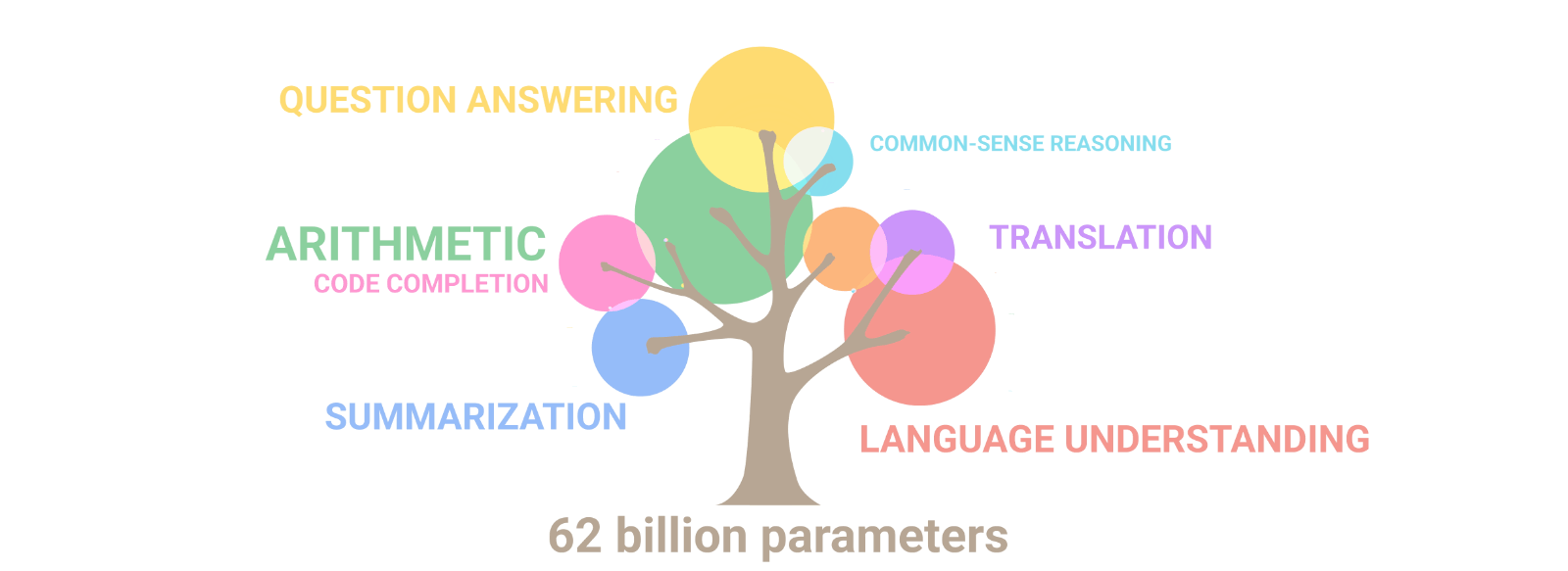
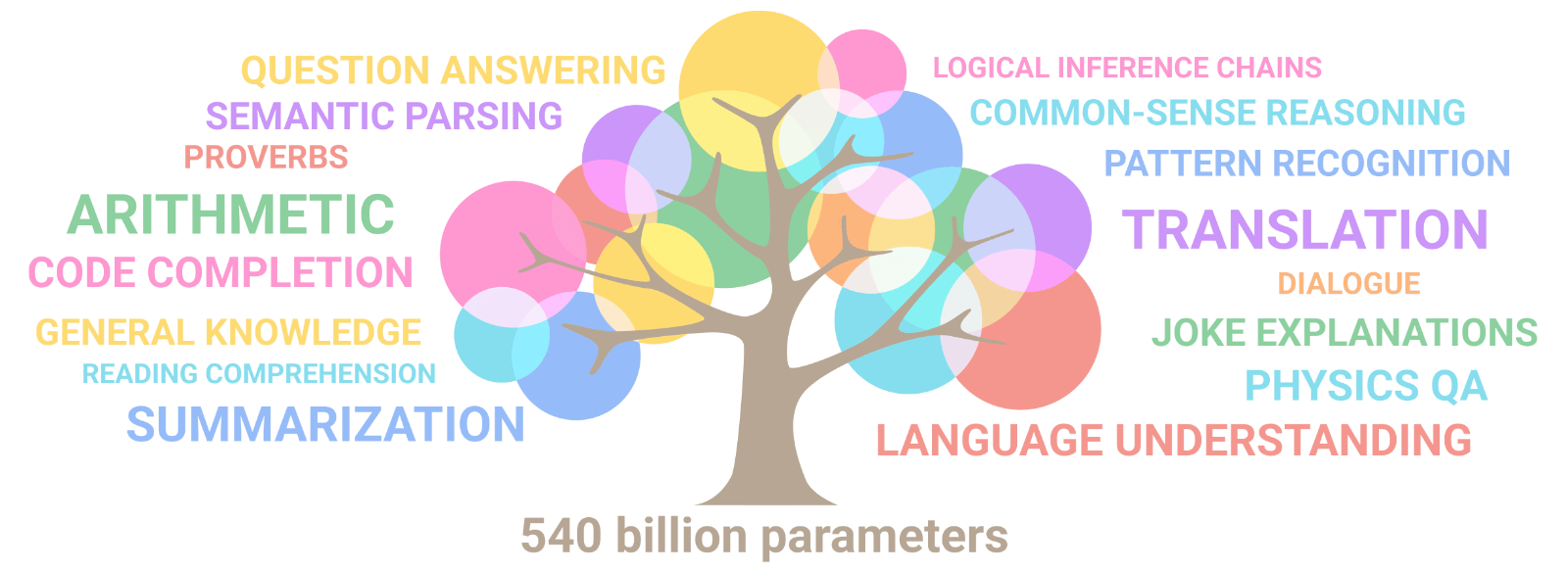
현재 나의 모습

LLM 진화
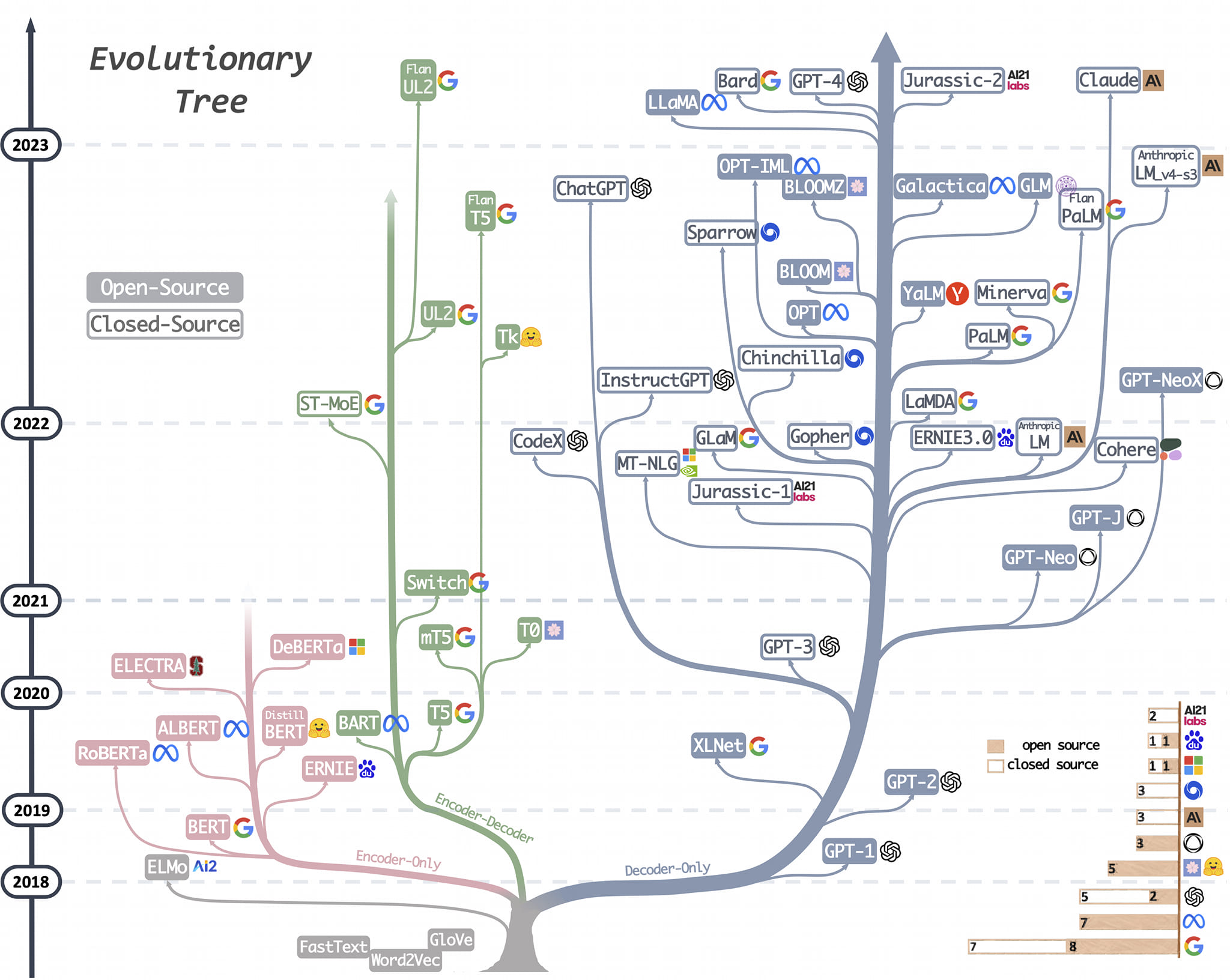
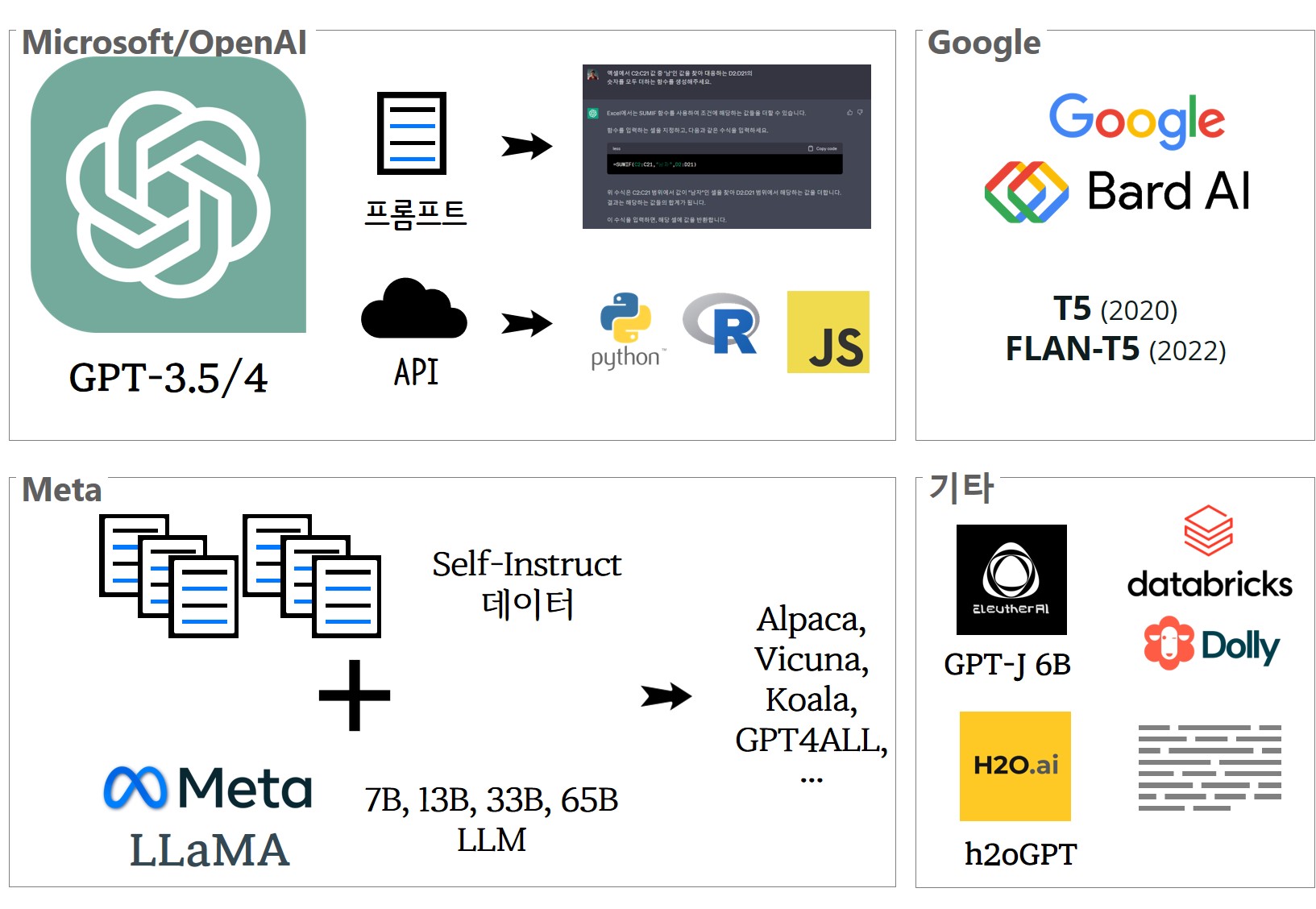
공개형 GPT vs 폐쇄형 GPT
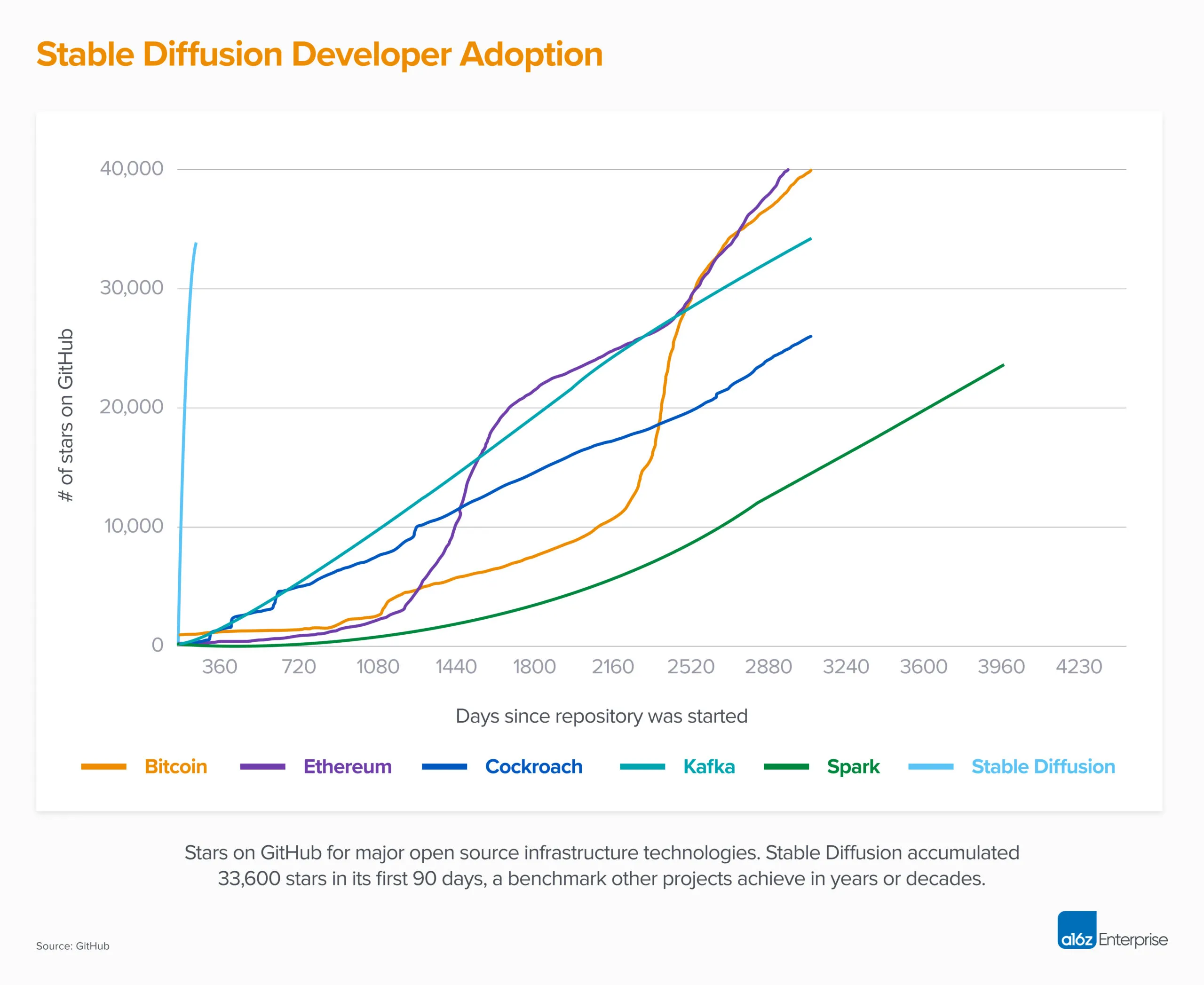

LLM

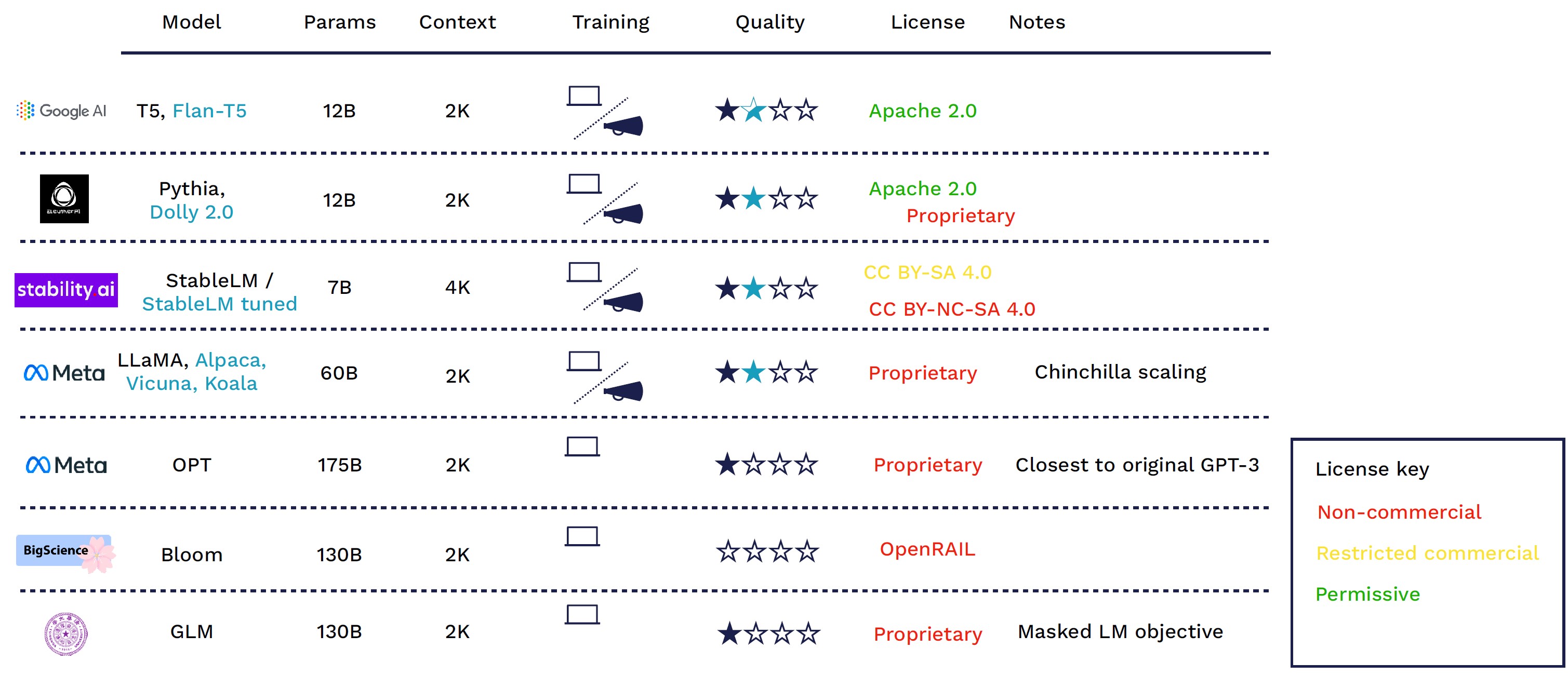
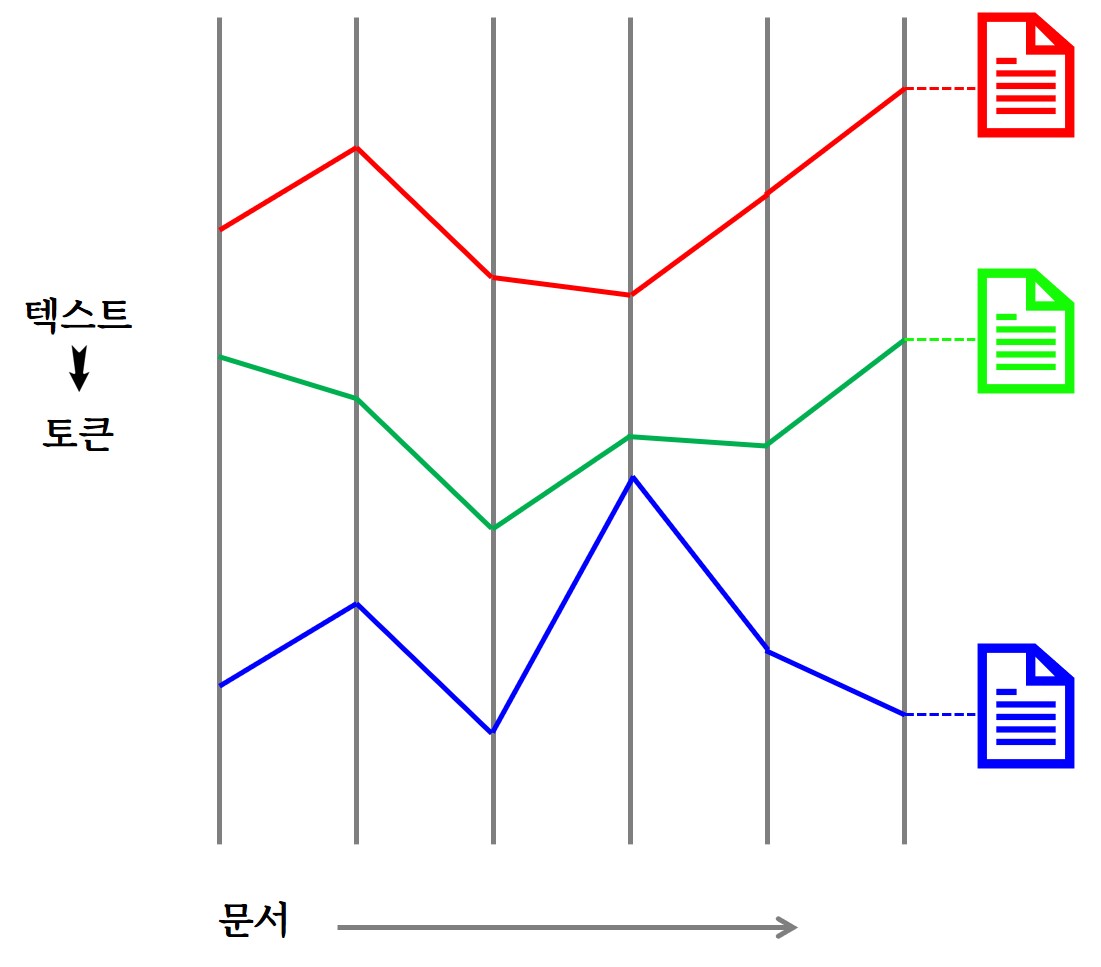
토큰 크기 (Context Length)
| 회사명 | LLM 모형 | Context 길이 (토큰 크기) | 텍스트 크기 |
|---|---|---|---|
| OpenAI | GPT-1 | 512 | 1 쪽, 4 단락, 36줄 |
| 구글 | PaLM | 512 | ↑ |
| OpenAI | GPT-2 | 1024 | 2 쪽, 8 단락, 68줄 |
| OpenAI | GPT-3 | 2048 | 1500 영단어, 4쪽, 139줄 |
| OpenAI | GPT-4 | 2048 | ↑ |
| Meta | Llama | 2048 | ↑ |
| OpenAI | GPT-3.5-Turbo | 4096 | 9쪽, 369줄 |
| 구글 | PaLM2 | 8192 | 13쪽, 단편 소설, 기술 문서 |
| OpenAI | GPT-4 8K | 8192 | ↑ |
| OpenAI | GPT-4 32K | 32000 | 48쪽, 대학학위논문 |
| MosaicML | MPT-7B-StoryWriter | 65000 | 98쪽 |
| Anthropic | Claude | 100000 | 150쪽, 소설책 반권 |
— Dan Fu (realDanFu?) March 29, 2023
HuggingGPT



한계(?) 1

챗GPT시대 공부(?)




인터페이스 (Interface)
flowchart TB
subgraph A["사용자 인터페이스"]
direction LR
CLI["CLI<br>Command Line Interface<br> 1950~"] --> GUI["GUI <br> Graphic User Inferface<br> 1970~"]
GUI --> WI["Web Interface <br> 1994~"]
WI --> MI["Mobile Interface <br> 2007~"]
MI --> NUI["LUI <br> Language User Interface <br> 2023~"]
end
class A nodeStyle
classDef nodeStyle fill:#fcfbfa,stroke:#000000,stroke-width:0.7px,font-weight:bold,font-size:14px;




챗GPT NUI
- 챗GPT (ChatGPT)

- OpenAI Playground
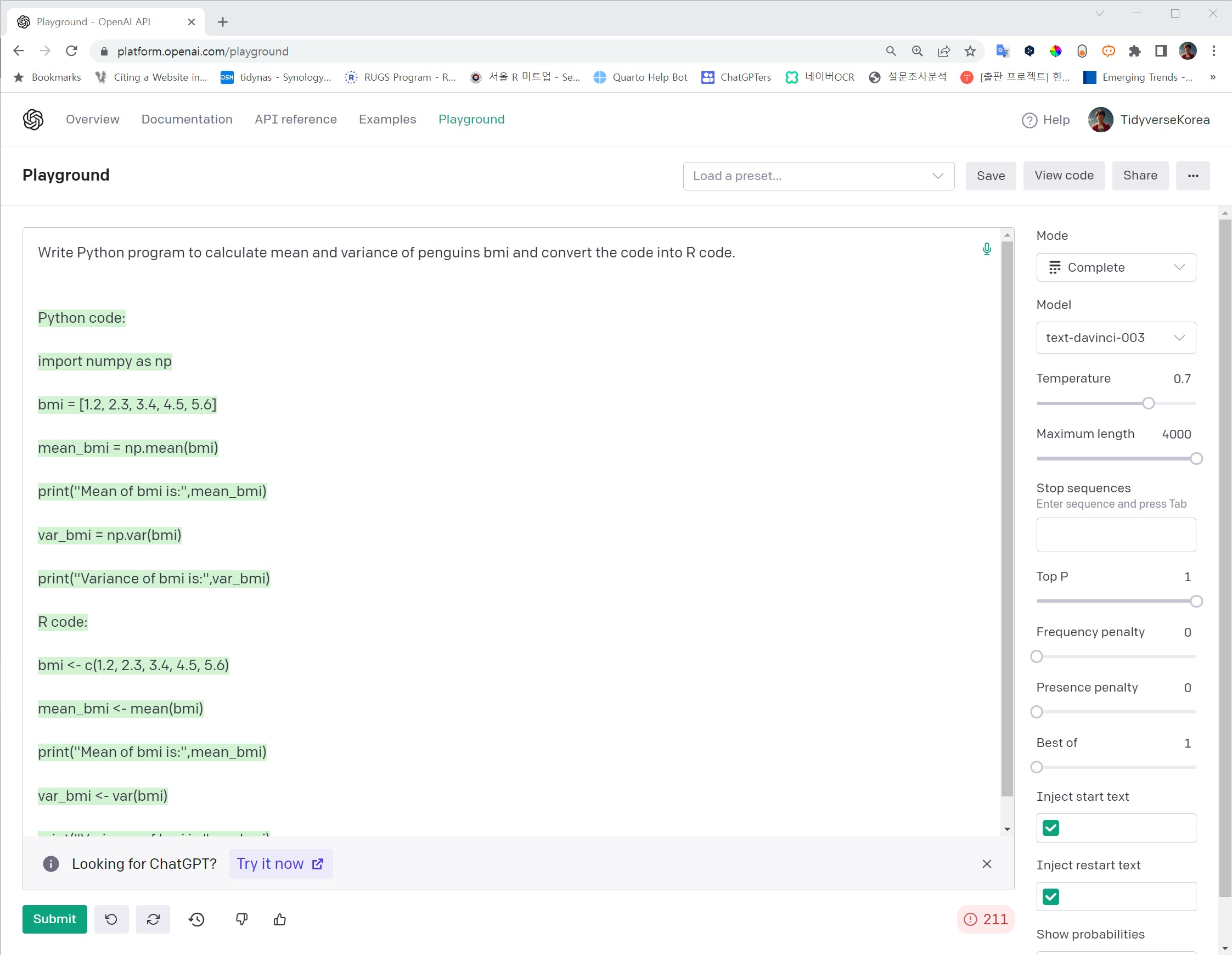
- GitHub Copilot



Command Palette 역사
- 60년대로 거슬러 올라가는 명령 팔레트는 최근 기술 업계에서 다시 인기를 얻고 있으며 사용자 중심 소프트웨어의 필수적인 부분으로 간주됨.
- CLI는 개인용 컴퓨터가 대중화되기 전 초기 컴퓨팅을 지배했으며 사용자가 시스템을 작동하기 위해 특정 명령을 알아야 했다. 1984년 Apple의 매킨토시와 함께 도입된 그래픽 사용자 인터페이스(GUI)는 중요한 혁신으로 여겨졌지만, 소프트웨어의 복잡성이 증가함에 따라 GUI만으로는 탐색하기가 점점 더 어려워졌다.
- 사용자가 항목 이름의 짧은 약어입력하여 앱과 파일을 검색할 수 있는 런처가 점점 더 보편화 되었다. 예를 들어 2001년에 출시된 Mac OS X용 LaunchBar, Quicksilver, 2005년에 출시된 Apple의 시스템 전체 Spotlight가 있다. 검색과 CLI의 결합은 Command Palette의 탄생으로 이어졌다.
- 오늘날 우리가 알고 있는 현대식 명령 팔레트는 2011년 Sublime Text 2 베타 Joe Skinner가 처음 소개. 명령줄 사용에 익숙한 프로그래머들이 단축키를 모두 외울 필요 없이 더 빠르게 작업할 수 있어 중요한 발전이 됨.
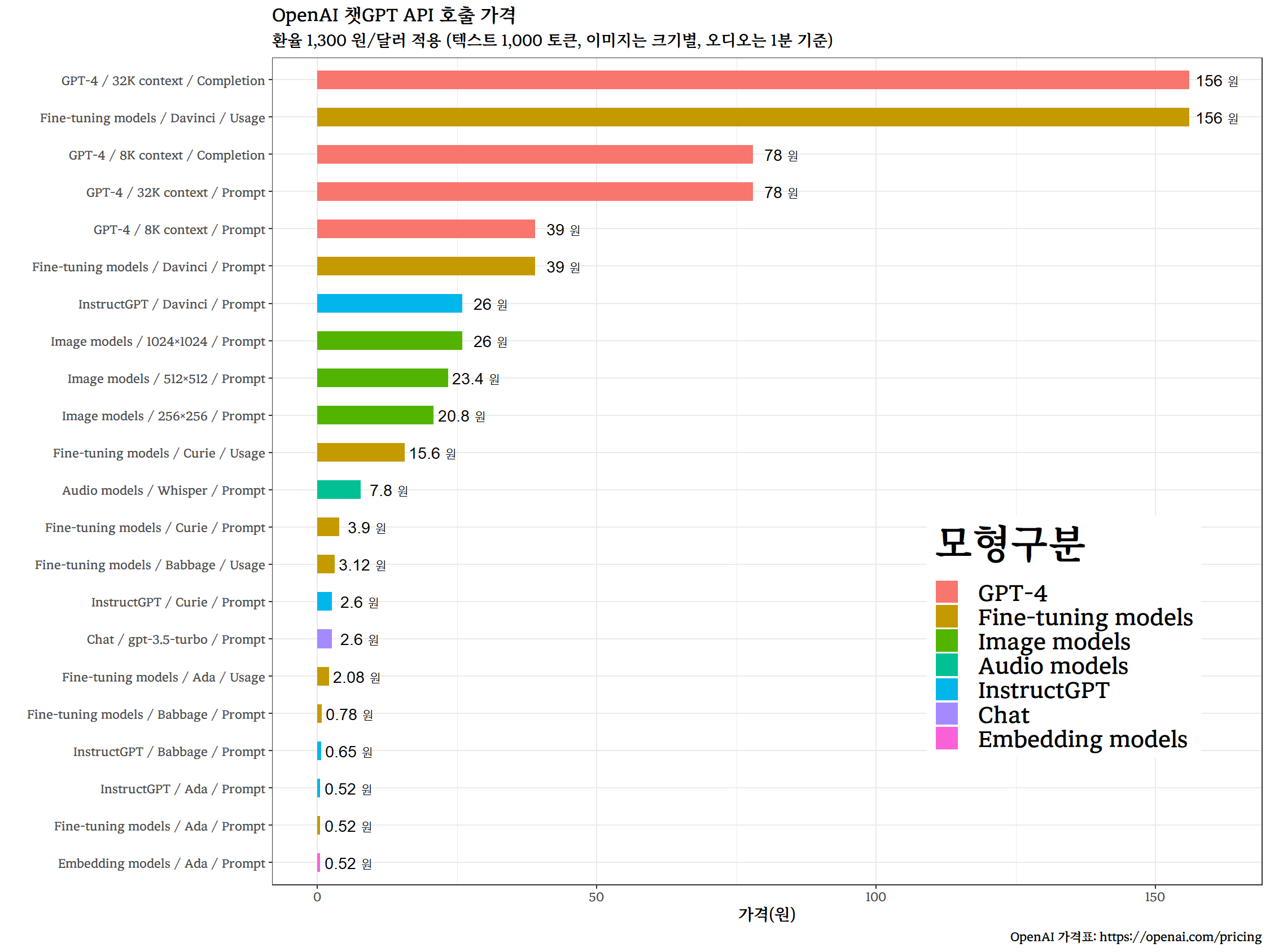
챗GPT API 가격
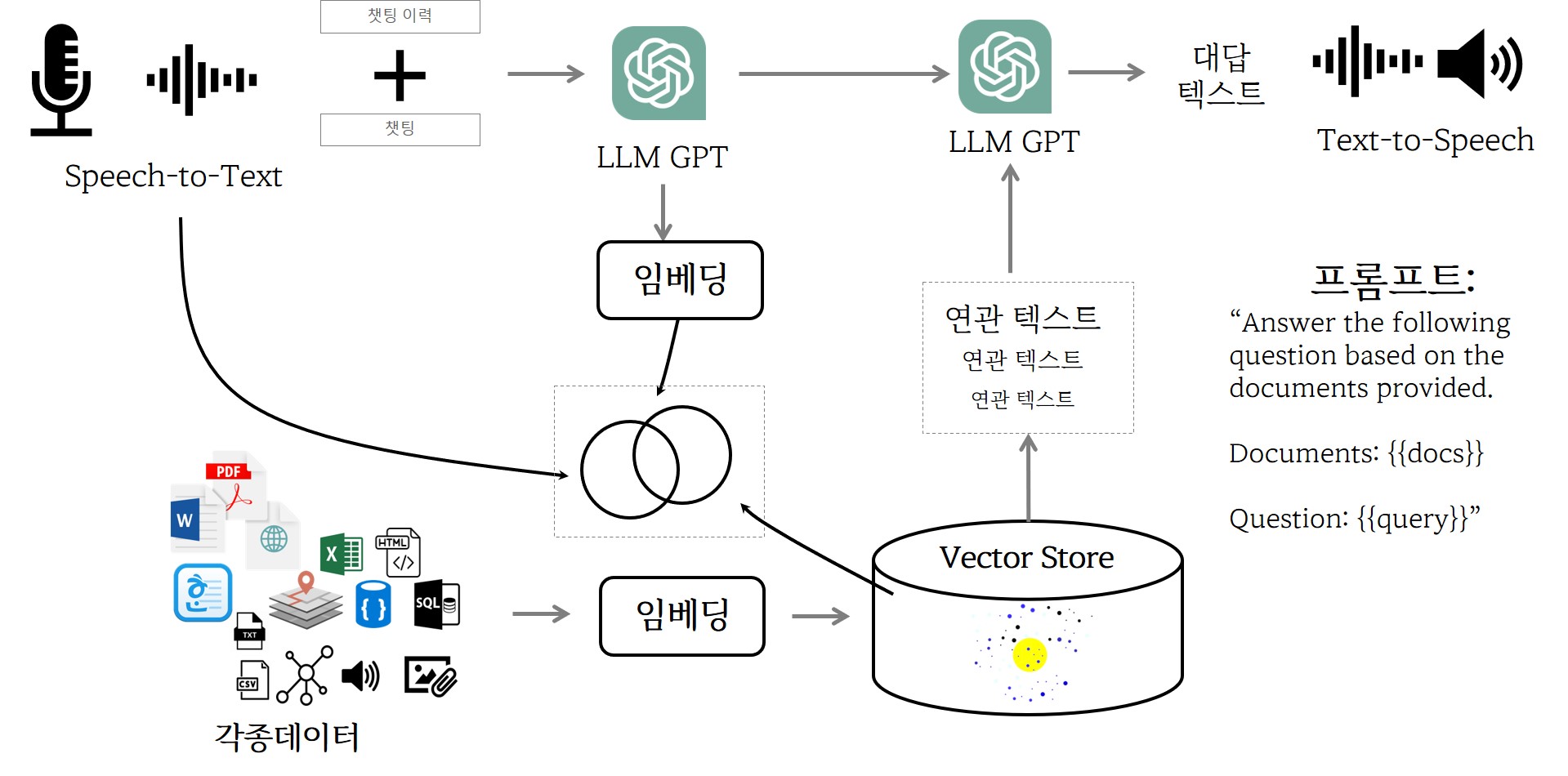
OpenAI 임베딩

| Models | Use Cases | |
|---|---|---|
| Text similarity: Captures semantic similarity between pieces of text. | text-similarity-{ada, babbage, curie, davinci}-001 | Clustering, regression, anomaly detection, visualization |
| Text search: Semantic information retrieval over documents. | text-search-{ada, babbage, curie, davinci}-{query, doc}-001 | Search, context relevance, information retrieval |
| Code search: Find relevant code with a query in natural language. | code-search-{ada, babbage}-{code, text}-001 | Code search and relevance |

NLI 자사 검색 엔진 (구글 X)
R 컨퍼런스 (2021)
참고문헌
Charles Frye, J. T., Sergey Karayev. (2023). LLM Bootcamp 2023. https://fullstackdeeplearning.com/llm-bootcamp/spring-2023/augmented-language-models/
"ChatGPT활용연구TFT. (2023). [업무활용편] ChatGPT 활용사례 및 활용 팁. 서울디지털재단. https://sdf.seoul.kr/research-report/2003
ChatGPT활용연구TFT. (2023). [일상생활·창작활동·교육분야편] ChatGPT 활용사례 및 팁. 서울디지털재단. https://sdf.seoul.kr/research-report/2059
Eloundou, T., Manning, S., Mishkin, P., & Rock, D. (2023). GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models. https://arxiv.org/abs/2303.10130
Meeker, H. (2017). Open Source For Business: A Practical Guide to Open Source Software Licensing. Createspace Independent Publishing Platform. https://books.google.co.kr/books?id=aKHGswEACAAJ
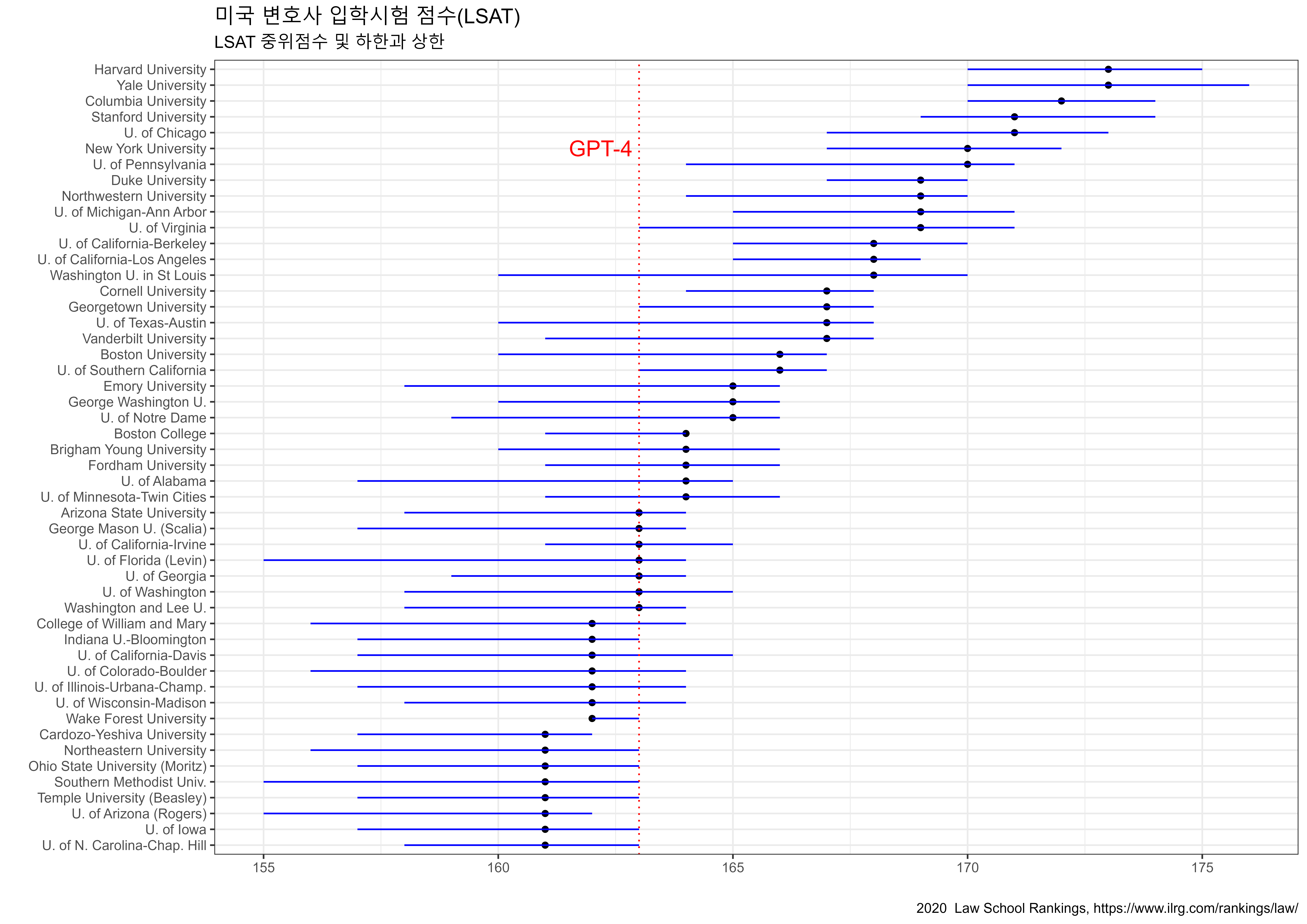
OpenAI. (2023). GPT-4 Technical Report. https://arxiv.org/abs/2303.08774
Reimers, N. (2022). OpenAI GPT-3 Text Embeddings - Really a new state-of-the-art in dense text embeddings? Medium.com. https://medium.com/@nils_reimers/openai-gpt-3-text-embeddings-really-a-new-state-of-the-art-in-dense-text-embeddings-6571fe3ec9d9
Shen, Y., Song, K., Tan, X., Li, D., Lu, W., & Zhuang, Y. (2023). HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace. https://arxiv.org/abs/2303.17580
Skrabut, S. (2023). 80 Ways to Use ChatGPT in the Classroom: Using AI to Enhance. Stan Skrabut.
Song, A. K. (2019). The Digital Entrepreneurial Ecosystem—a critique and reconfiguration. Small Business Economics, 53(3), 569–590.
Yang, J., Jin, H., Tang, R., Han, X., Feng, Q., Jiang, H., Yin, B., & Hu, X. (2023). Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond. https://arxiv.org/abs/2304.13712
Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., Du, Y., Yang, C., Chen, Y., Chen, Z., Jiang, J., Ren, R., Li, Y., Tang, X., Liu, Z., … Wen, J.-R. (2023). A Survey of Large Language Models. https://arxiv.org/abs/2303.18223
김현진. (2021). 웹툰 이미지 제작공정 단계별 활용 가능한 스케치 관련 인공지능 기술. 한국정보과학회.
양정애. (2023). 챗GPT 이용 경험 및 인식 조사. 한국언론진흥재단. https://www.kpf.or.kr/front/board/boardContentsListPage.do?board_id=246