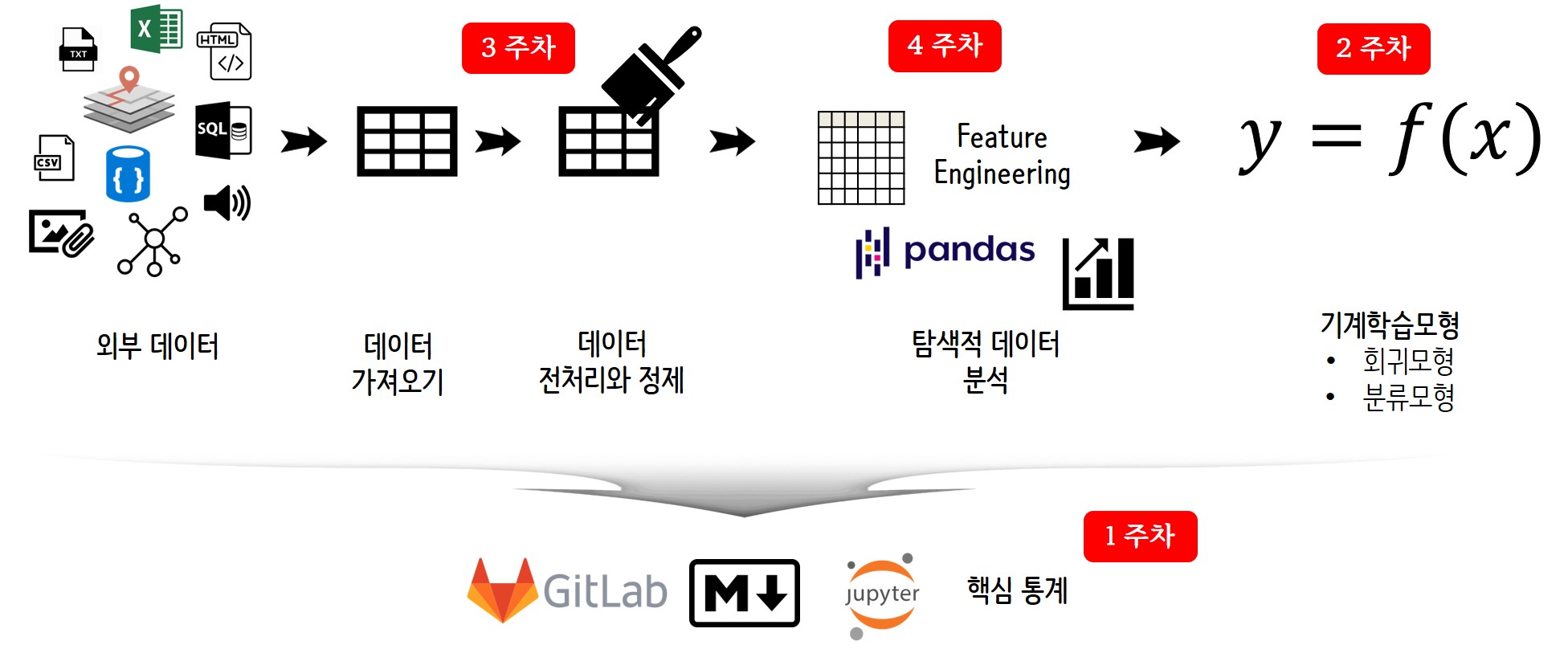
| 1주차 - Introduction |
| - Defining and solving problems |
|
| - Quantifying performance indicators |
|
| - Stats and Probability for Data Science |
|
| 2주차 - Data Science |
| - Python 기초 문법 복습 및 NumPy, Pandas 등 연습 |
|
| - Kaggle: MPG / Titanic - Machine Learning from Disaster를 이용한 EDA의 개념과 Data science의 전체적인 Flow를 습득 |
|
| - EDA, Feature engineering, Visualization, Correlating 등 Preprocessing 작업 수행 |
|
| - Model, predict and evaluation 의 전체 과정을 습득 |
|
| 3주차 - Regression and Prediction |
| - Regression에 대한 개념 및 이론 설명 |
Breast Cancer, Boston housing, California housing prices, Bike-sharing-demand etc. |
| - EDA 및 preprocessing (Impute missing value, Turn categorical into booleans, scale the numerical variables, merge etc.) |
|
| - Linear Regression을 중심으로 설명하되, 추가적으로 CART, SVM, Ensemble기법 등을 적용 |
|
| - Training & Evaluation (MSE, MAE, RMSE, RMSLE, R-Squared, etc.) |
|
| - Basic hyperparameter tuning 수행 |
|
| 4주차 - Classification and Hypothesis Testing |
| - Classification과 필요 개념 및 이론 설명 |
Titanic, Iris, Penuins, San Francisco Crime etc. |
| - EDA & preprocessing |
|
| - Logistic Regression과 Decision Tree를 중심으로 설명하되, 추가적으로 SVC, Random Forest, XGBoost, LGBM 등 적용 |
|
| - Training & Evaluation (Accuracy, Precision, Recall, F1-score, Confusion Matrix, Cross-validation, etc.) |
|
| - Basic hyperparameter tuning 수행 |
|
| 5주차 - Case Studies and Projects |
| - 기존 수업에서 다루었던 이론/실습 개념을 바탕으로 한 Case Study 3종 (+Final Quiz) |
|
| - Case Study 및 Final Quiz 해설 |
|
| - 개인 별 Project 인터뷰 및 Grouping / 공통과제 선정 |
|
| - Project 진행, 발표, Best Project 선정 및 공유 |
|