Feature Engineering
기계학습 모형을 개발할 때 피처 공학으로 자주 사용되는 기법은 다음과 같다.
범주형: One-hot encoding
연속형: 정규화(Normalization) 혹은 표준화(standardization)
연속형 → 범주형: 비닝(Binning) 혹은 이산화(discretization)
연속형: 교호작용(interaction) 과 다항식 확장
새로운 피처 생성: 기존 피쳐를 변환 혹은 총계작업
피처 제거: 관련없거나 중복된 피쳐 제거
차원 축소: PCA 등
…
암수구별 예측모형
\[\text{펭귄성별} = f(x) + \epsilon\]
예측 모형 기본
# 기계학습 팩키지 import pandas as pdfrom sklearn.preprocessing import OneHotEncoderfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_score, precision_score, recall_scorefrom palmerpenguins import load_penguins# 데이터셋 = load_penguins()# 데이터 전처리 = penguins.dropna()'sex' ] = penguins['sex' ].map ({'female' : 0 , 'male' : 1 })= penguins[["bill_length_mm" , "bill_depth_mm" , "flipper_length_mm" , "body_mass_g" ]]= penguins["sex" ]# 훈련 시험데이터셋 분리 = train_test_split(X, y, test_size= 0.2 )# 로지스틱 이항 분류모형 = LogisticRegression(max_iter = 1000 , solver = 'lbfgs' ,= 'balance' , random_state= 1717 )# 기계학습 모형 시험
LogisticRegression(class_weight='balance', max_iter=1000, random_state=1717) In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
= clf.predict(X_test)
모형 평가
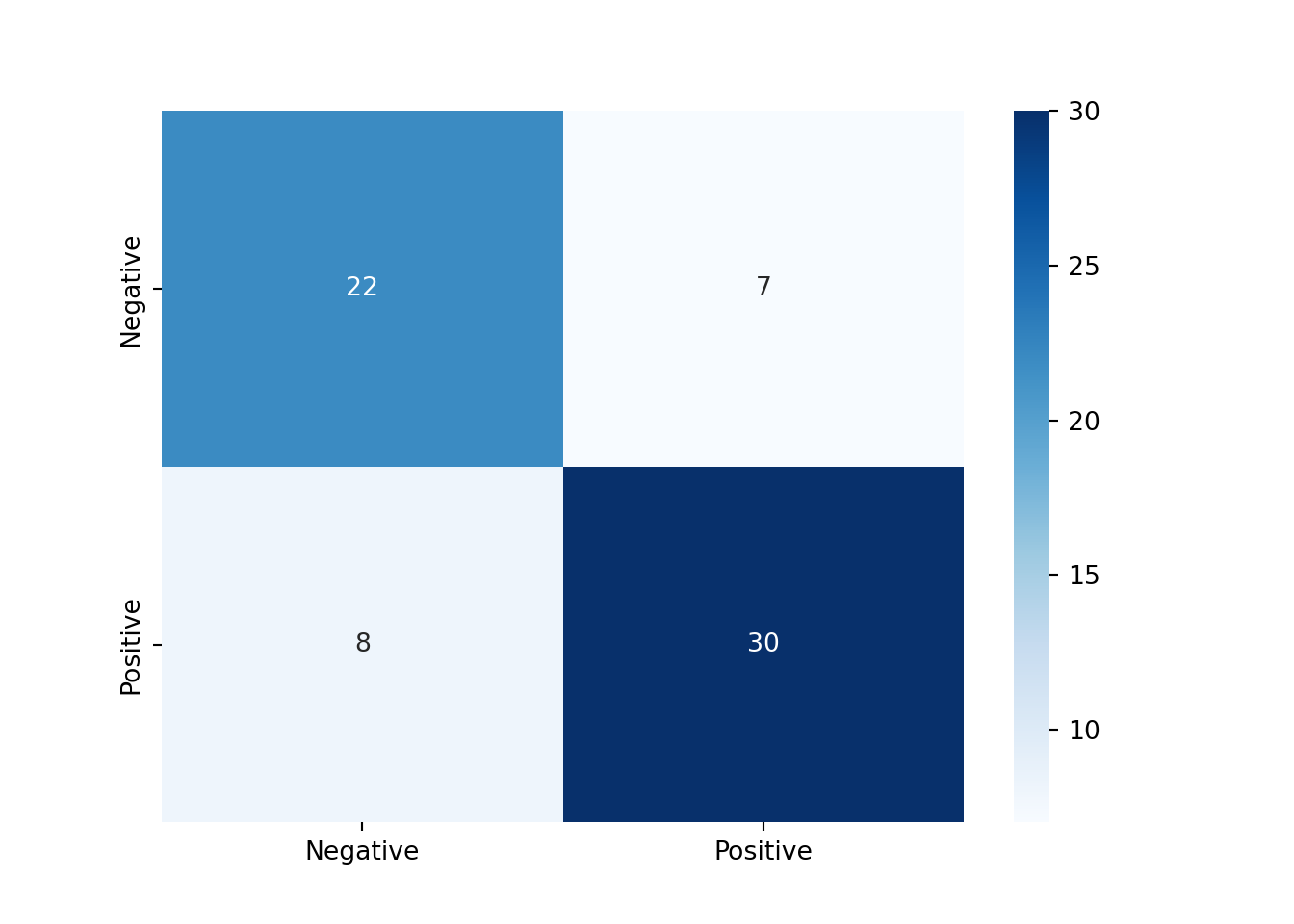
# 시험평가결과 = accuracy_score(y_test, y_pred)= precision_score(y_test, y_pred, pos_label = 1 )= recall_score(y_test, y_pred, pos_label = 1 )print (f"Accuracy: { acc} " )#> Accuracy: 0.7761194029850746 print (f"Precision: { prec} " )#> Precision: 0.8108108108108109 print (f"Recall: { rec} " )#> Recall: 0.7894736842105263
from sklearn.metrics import confusion_matrix= confusion_matrix(y_test, y_pred)print (conf_matrix)#> [[22 7] #> [ 8 30]]
import seaborn as sns= True , = ["Negative" , "Positive" ], = ["Negative" , "Positive" ], cmap= "Blues" )
범주형 Feature
'mode.chained_assignment' , None )# 데이터셋 = load_penguins()# 데이터 전처리 = penguins_fe.dropna()'sex' ] = penguins_fe['sex' ].map ({'female' : 0 , 'male' : 1 })= pd.get_dummies(penguins_fe, columns= ['species' , 'island' , 'year' ])= penguins_fe["sex" ]= penguins_fe.drop(['sex' ], axis= 1 )# 훈련 시험데이터셋 분리 = train_test_split(X, y, test_size= 0.2 )# 로지스틱 이항 분류모형 = LogisticRegression(max_iter = 1000 , solver = 'lbfgs' ,= 'balance' , random_state= 1717 )# 기계학습 모형 시험
LogisticRegression(class_weight='balance', max_iter=1000, random_state=1717) In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
= clf.predict(X_test)
모형 평가
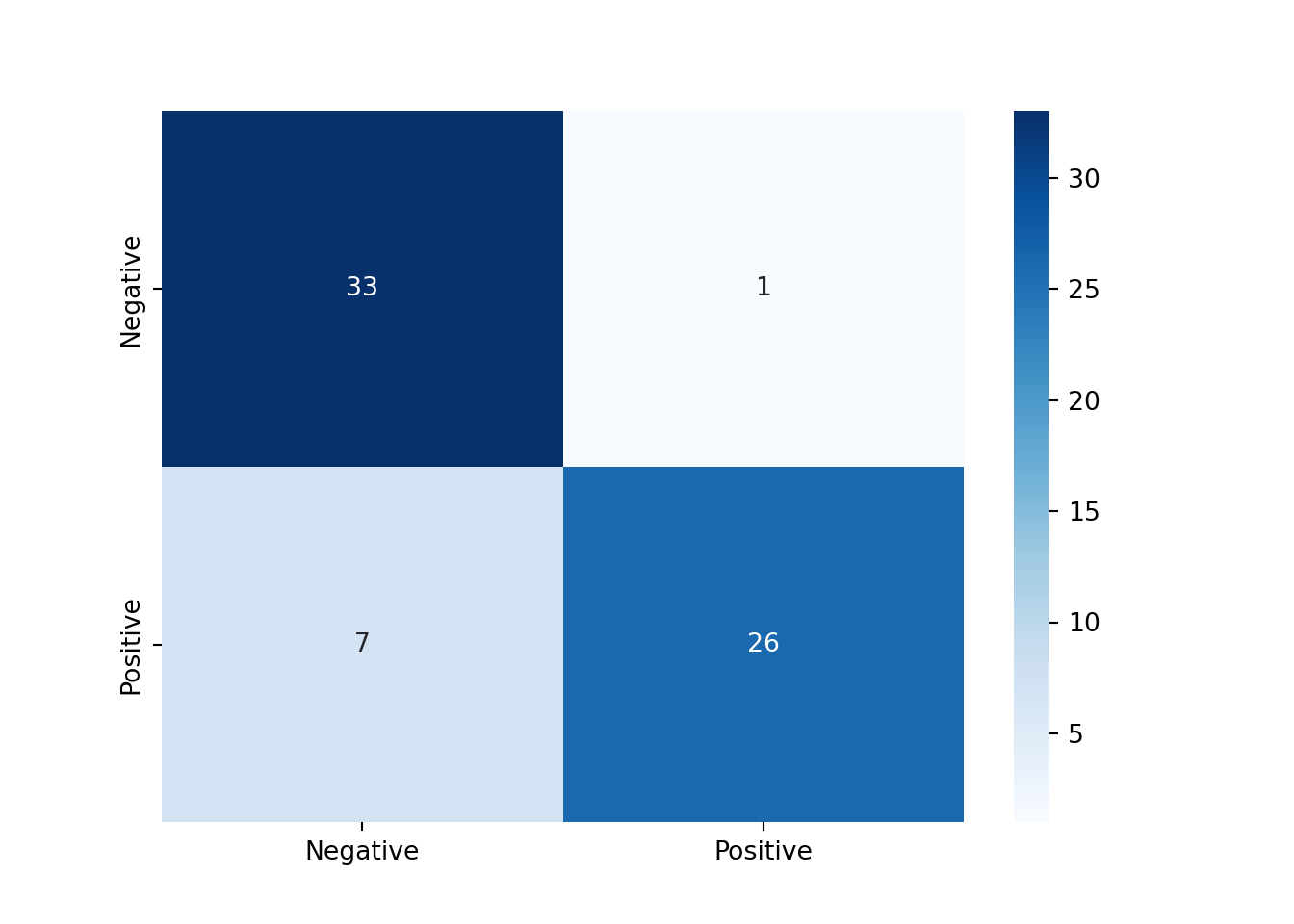
# 시험평가결과 = accuracy_score(y_test, y_pred)= precision_score(y_test, y_pred, pos_label = 1 )= recall_score(y_test, y_pred, pos_label = 1 )print (f"Accuracy: { acc} " )#> Accuracy: 0.8805970149253731 print (f"Precision: { prec} " )#> Precision: 0.9629629629629629 print (f"Recall: { rec} " )#> Recall: 0.7878787878787878
from sklearn.metrics import confusion_matrix= confusion_matrix(y_test, y_pred)print (conf_matrix)#> [[33 1] #> [ 7 26]]
import seaborn as sns= True , = ["Negative" , "Positive" ], = ["Negative" , "Positive" ], cmap= "Blues" )