install.packages("reticulate")
library(reticulate)
install_miniconda(path = "c:/miniconda", update = TRUE)파이썬 환경설정
데이터 과학 파이썬 프로그램 개발 환경을 준비합니다.
1 파이썬 환경구축
1.1 미니콘다 설치
R/쿼토 환경에서 파이썬을 사용하는 가장 간단한 방법은 미니콘다를 사용하는 방식이다. 미니콘다(miniconda)는 작고 가볍기 때문에 아나콘다를 기본 기능을 사용할 수 있는 장점도 있다. 추후 필요한 기능에 필요한 패키지를 설치하여 사용한다.
R에서 이를 가능하게 하는 방식이 reticulate 패키지를 설치한 후 전체 과정을 단순화시킬 수 있다.
1.2 가상환경
미니콘다가 다른 이슈없이 설치되었다면 conda_list() 함수를 사용해서 `r-reticulate``
use_python(): 파이썬이 설치된 경로.use_virtualenv(): 파이썬 가상환경(virtualenv)이 설치된 경로.use_condaenv(): 콘다 환경이 설치된 경로.
conda_list(conda = "c:/miniconda/_conda.exe") name python
1 r-reticulate C:\\miniconda\\envs\\r-reticulate/python.exe
6 miniconda C:\\miniconda/python.exe콘다환경에서 가상환경을 구축한다. 가상환경의 명칭을 pyenv로 특정한다.
use_condaenv(condaenv = "r-reticulate", conda = "c:/miniconda/_conda.exe")
conda_create(envname = "pyenv", conda = "c:/miniconda/_conda.exe")1.3 패키지 설치
reticulate 패키지에 포함된 py_install() 함수로 기계학습과 데이터 과학에 필요한 패키지를 설치한다. 추후 .ipynb 쥬피터 노트북 파이썬 결과물을 쿼토에서 컴파일하는데 필요한 jupyter 패키지도 설치한다.
reticulate::py_install(packages = c("pandas", "scikit-learn", "matplotlib"))
reticulate::py_install(packages = c("jupyter"))2 파이썬 헬로월드
2.1 파이썬 환경구축
콘다환경을 구축하여 파이썬 데이터 과학 프로그램을 실행시킬 수 있는 환경을 구축한다.
library(reticulate)
use_condaenv(condaenv = "r-reticulate", conda = "c:/miniconda/_conda.exe")2.2 시각화
고양이와 개에 대한 피쳐(Feature)를 바탕으로 고양이와 개를 분류하는 분류기계학습 모형을 개발해보자. 먼저, 기계학습을 위한 훈련 시험 데이터를 준비하고 시각화를 한다.
training_set = {'Dog':[[1,2],[2,3],[3,1]], 'Cat':[[11,20],[14,15],[12,15]]}
testing_set = [15,20]
#ploting all data
import matplotlib.pyplot as plt
c = 'x'
for data in training_set:
print(data)
#print(training_set[data])
for i in training_set[data]:
plt.plot(i[0], i[1], c, color='c')
c = 'o'
plt.show()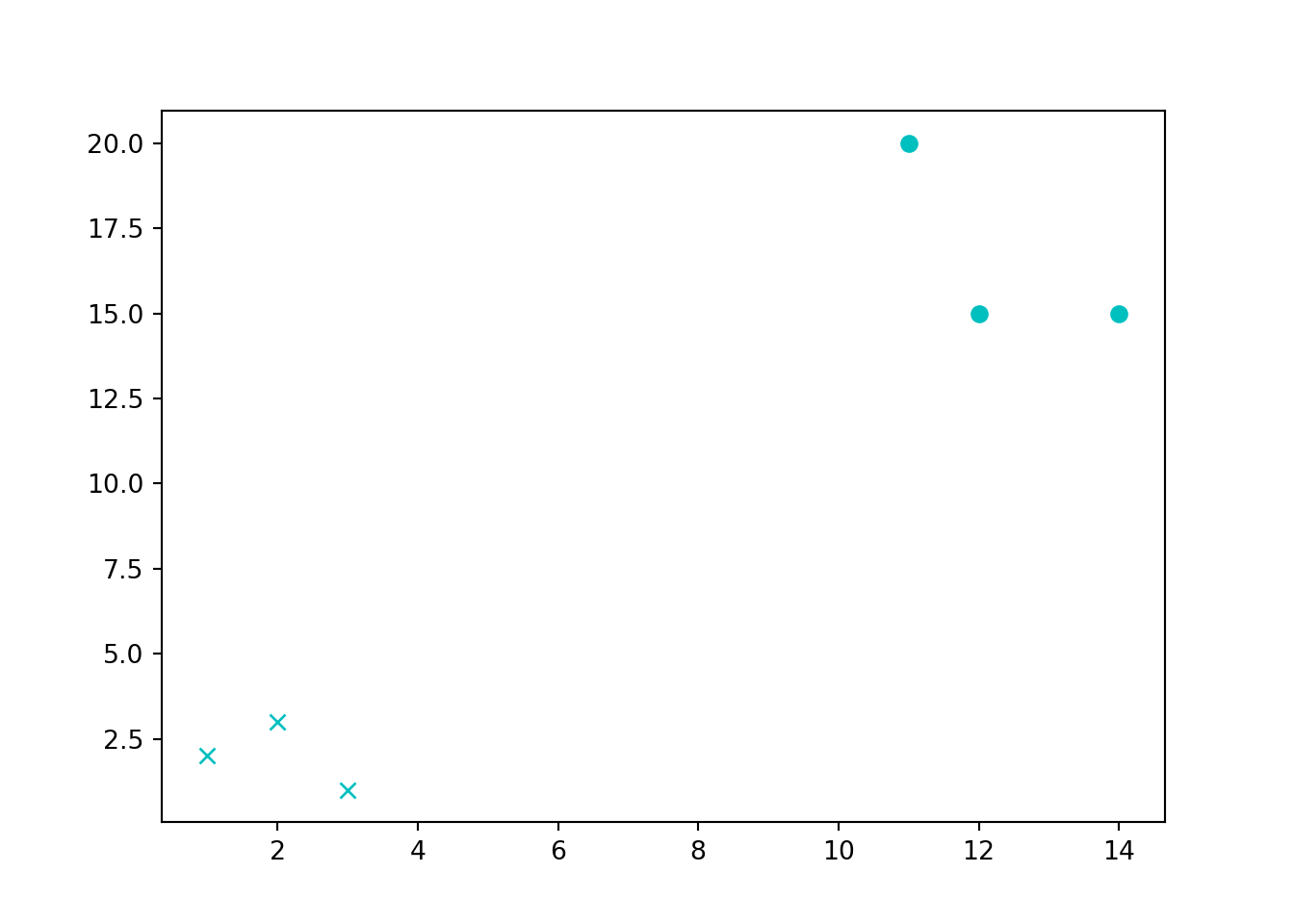
2.3 분류모형
다양한 기계학습모형이 존재하지만 먼저 KNN 분류모형을 적합시켜 고양이와 개 분류 기계학습모형을 개발한다.
# 기계학습모형 데이터셋 준비
x = []
y = []
for group in training_set:
for features in training_set[group]:
x.append(features)
y.append(group)
# 기계학습모형 특정
from sklearn import preprocessing, neighbors
# 데이터에 모형 적합
clf = neighbors.KNeighborsClassifier()
clf.fit(x, y)KNeighborsClassifier()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
KNeighborsClassifier()
2.4 분류모형 성능
데이터에 적합시킨 모형이 얼마나 고양이와 개를 잘 분류하는지 예측 정확도를 따져보자.
# 예측모형 성능 평가
from sklearn.metrics import accuracy_score
import pandas as pd
dog_df = pd.DataFrame.from_dict(training_set['Dog'])
dog_df['Y'] = "Dog"
cat_df = pd.DataFrame.from_dict(training_set['Cat'])
cat_df['Y'] = "Cat"
trainging_df = pd.concat([dog_df, cat_df])
feature_df = trainging_df.drop(['Y'], axis=1)
label_df = trainging_df['Y']
Y_preds = clf.predict(feature_df)
print('모형 정확도 : {:.3f}'.format(accuracy_score(label_df, Y_preds)))모형 정확도 : 1.0002.5 분류모형 예측
실제로 기계학습모형에 사용된 적이 없는 개와 고양이 데이터를 직접 넣어 어떻게 예측하는지 확인해보자.
# 분류모형 예측
import numpy as np
testing_set = np.array(testing_set)
testing_set = testing_set.reshape(1,-1)
# 예측
prediction = clf.predict(testing_set)
print(prediction)['Cat']3 .ipynb ↔︎ .qmd
3.1 .ipynb → .qmd
개와 고양이 분류 예측모형 개발을 파이썬 쥬피터 노트북으로 개발을 하였다면 이를 쿼토로 변환시켜 _quarto.yml 파일에 등재시킬 수 있는 .qmd 파일로 변환시킨다.
$ quarto convert hello_world_jupyter.ipynb
Converted to hello_world_jupyter.qmd3.2 .qmd → .ipynb
마찬가지로 .qmd 파일을 쥬피터 .ipynb 파일로 변환시킬 경우 동일하게 quarto convert 명령어를 사용한다.
$ quarto convert hello_world_qmd.qmd
Converted to hello_world_qmd.ipynb