32 . plyr로 데이터프레임을 쪼개고 합치기
앞서, 함수를 사용해서 코드를 단순화하는 방법을 살펴봤다.
gapminder 데이터셋을 인자로 받아, 인구(population)와 인당 GDP를 곱해 GPD를 계산하는
calcGDP 함수를 정의했다.
추가적인 인자를 정의해서, year 연도별, country 국가별 필터를 적용할 수도 있다:
# Takes a dataset and multiplies the population column
# with the GDP per capita column.
calcGDP <- function(dat, year=NULL, country=NULL) {
if(!is.null(year)) {
dat <- dat[dat$year %in% year, ]
}
if (!is.null(country)) {
dat <- dat[dat$country %in% country,]
}
gdp <- dat$pop * dat$gdpPercap
new <- cbind(dat, gdp=gdp)
return(new)
}데이터 작업을 할 때, 흔히 마주치는 작업이 집단별 그룹으로 묶어 계산하는 것이다. 위에서, 단순히 두 칼럼을 곱해서 GDP를 계산했다. 하지만, 대륙별로 평균 GDP를 계산하고자 한다면 어떨까?
calcGDP를 실행하고 나서, 각 대륙별로 평균을 산출한다:
withGDP <- calcGDP(gapminder)
mean(withGDP[withGDP$continent == "Africa", "gdp"])## [1] 2.09e+10
mean(withGDP[withGDP$continent == "Americas", "gdp"])## [1] 3.79e+11
mean(withGDP[withGDP$continent == "Asia", "gdp"])## [1] 2.27e+11하지만, 그다지 멋있지는 않다. 그렇다. 함수를 사용해서, 반복되는 상당량 작업을 줄일 수 있었다. 함수 사용은 멋있었다. 하지만, 여전히 반복이 있다. 여러분이 직접 반복하게 되면, 일단 여러분 시간을 지금은 물론이고 그리고 나중에도 까먹게 되고, 잠재적으로 버그가 스며들 여지를 남기게 된다.
calcGDP처럼 유연성 있는 함수를 새로 작성할 수도 있지만,
제대로 동작하는 함수를 개발하기까지 상당량 노력과 테스트가 필요하다.
여기서 맞닥드린 추상화 문제를 “분할-적용-병합(split-apply-combine)” 전략이라고 부른다:

Split apply combine
데이터를 집단으로 분할(split)하고, 이번 경우에 대륙, 해당 집단에 연산작업을 적용(apply)하고 나서, 선택옵션으로 결과를 묶어 병합(combine)한다.
32.1 plyr 팩키지
R을 예전에 사용했다면, apply 함수 가족에 친숙할 수 있다.
R 내장함수도 동작이 잘 되지만, “분할-적용-병합” 문제를 해결하는데 사용되는 또다른 방법을 소개한다.
plyr 팩키지는 이런 유형의 문제를 해결하는데 훨씬 사용자 친화적인
함수를 집합으로 제공한다.
이전 도전과제에서 plyr 팩키지를 설치했다. 이제 plyr 불러와서 적재한다:
plyr 팩키지에는 리스트(lists), 데이터프레임(data.frames), 배열(arrays, 행렬, n-차원 벡터)
자료형 연산을 위한 함수가 있다. 함수 각각은 다음 작업을 수행한다:
- 분할(split)하는 연산
- 순서대로 각각 쪼갠 것에 함수를 적용(apply)한다.
- 데이터 객체로 출력 데이터로 다시 병합(combine)한다.
입력값으로 예상되는 자료구조와 출력값으로 반환되는 자료구조에 기반해서 함수명이 붙여졌다: [a]rray, [l]ist, [d]ata.frame. 첫번째 문자가 입력 자료구조, 두번째 문자가 출력 자료구조에 대응되고, 함수 나머지에 “ply”를 붙인다.
[a]rray, [l]ist, [d]ata.frame 를 입력과 출력에 조합하면 핵심 **ply 함수 9개가 산출된다.
분할과 적용 단계만 수행하고 병합단계를 거치지 않는 함수가 추가로 3개 있다.
입력 데이터 자료형에 NULL 출력값(_)으로 표현된다. (아래 테이블 참조)
여기서 “배열”에 대한 plyr이 다른 것과 다름에 주목한다.
ply에 사용되는 배열은 벡터 혹은 행렬을 포함할 수 있다.
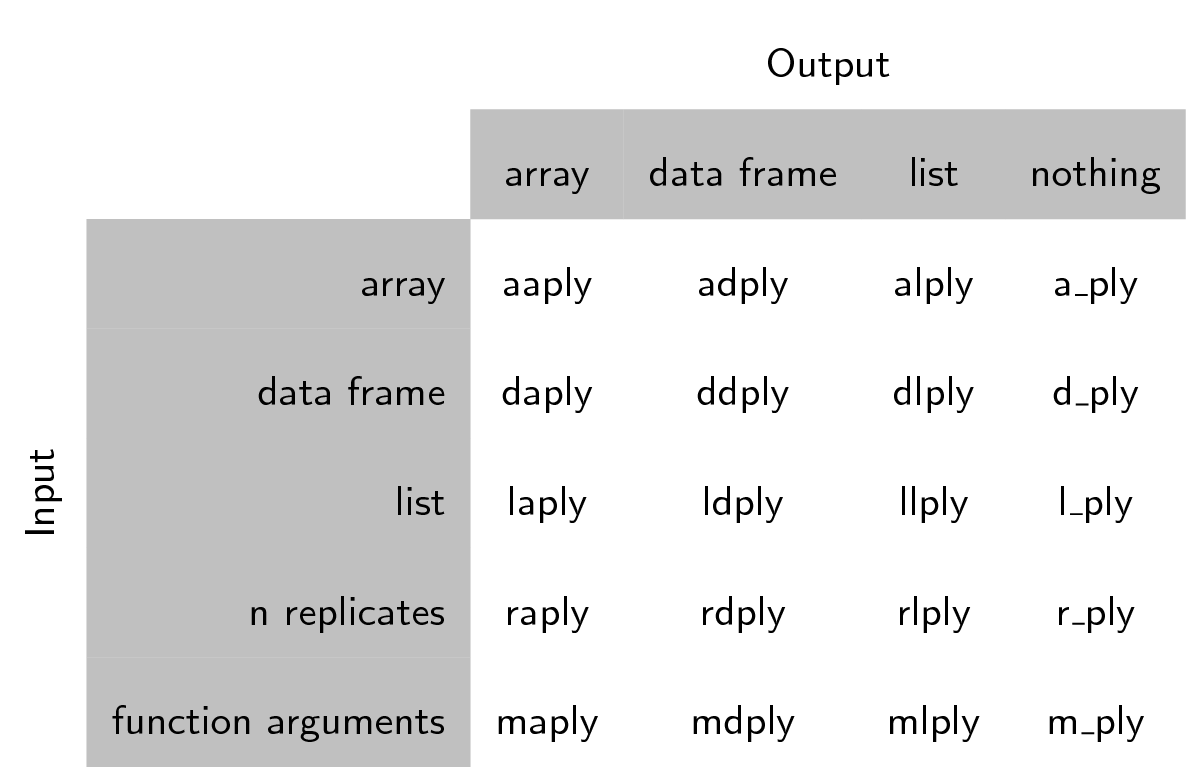
전체 apply 개요
xxply 함수(daply, ddply, llply, laply, …) 각각은 동일한 구조를 갖고,
4가지 주요 기능을 갖는다:
xxply(.data, .variables, .fun)- 함수명 첫글자는 입력 자료형, 함수 두번째 글자는 출력 자료형을 나타낸다.
- .data - 처리될 자료객체를 나타낸다.
- .variables - 분할(split)변수를 식별한다.
- .fun - 각 그룹 집단에 연산작업을 위해 호출되는 함수.
이제, 대륙별로 평균 GDP를 신속하게 계산할 수 있다:
## continent V1
## 1 Africa 2.09e+10
## 2 Americas 3.79e+11
## 3 Asia 2.27e+11
## 4 Europe 2.69e+11
## 5 Oceania 1.88e+11방금전 코드에서 일어난 사건을 복기해 보자:
-
ddply함수에data.frame데이터프레임을 집어넣고(함수명이 d로 시작), 또다른data.frame데이터프레임을 반환한다(함수명 두번째 문자 d). - 전달한 첫번째 인자는 연산작업을 실행하고자 하는 데이터프레임이다: 이번 경우에 gapminder 데이터.
먼저
calcGDP함수를 호출해서, gapminder 데이터프레임에gdp칼럼을 추가한다. - 두번째 인자가 분할 조건을 명시한다: 이번 경우에, “대륙(continent)” 칼럼이다.
부분집합(subsetting) 연산으로 이전에 수행했던 것처럼, 실제 칼럼 자체가 아니라,
칼럼명만 부여했음에 주목한다.
plyr팩키지에 자세한 구현이 되어 있어, 칼럼명만 전달하면 된다. - 세번째 인자는 그룹 집단 각각에 적용하고자 하는 함수다.
이번 경우에는, 짧은 함수를 자체 정의했다:
데이터 각 부분집합은 함수 첫번째 인자,
x에 저장되어 있다. 이것을 람다 함수라고 부른다: 어디서도 정의하지 않았기 때문에, 이름이 없는 무명함수다.ddply함수가 호출되는 범위(scope)에만 존재한다.
출력 자료구조를 달리하면 어떨까?
32.2 도전과제 1
대륙별로 평균 기대수명을 계산하라. 어느 대륙이 가장 기대수명이 긴가? 어느 대륙이 가장 기대수명이 짧은가?
도전과제 1에 대한 해답
## continent V1 ## 1 Africa 48.9 ## 2 Americas 64.7 ## 3 Asia 60.1 ## 4 Europe 71.9 ## 5 Oceania 74.3오세아니아 대륙이 가장 길고 아프리카 대륙이 가장 짧다.
출력 자료구조를 달리하면 어떨까?
## $Africa
## [1] 2.09e+10
##
## $Americas
## [1] 3.79e+11
##
## $Asia
## [1] 2.27e+11
##
## $Europe
## [1] 2.69e+11
##
## $Oceania
## [1] 1.88e+11
##
## attr(,"split_type")
## [1] "data.frame"
## attr(,"split_labels")
## continent
## 1 Africa
## 2 Americas
## 3 Asia
## 4 Europe
## 5 Oceania동일한 함수를 호출했지만, 두번째 문자만 l로 변경했다.
그래서, 출력결과가 리스트로 반환됐다.
다수 칼럼을 지정해서 그룹별로 group by 할 수 있다:
ddply(
.data = calcGDP(gapminder),
.variables = c("continent", "year"),
.fun = function(x) mean(x$gdp)
)## continent year V1
## 1 Africa 1952 5.99e+09
## 2 Africa 1957 7.36e+09
## 3 Africa 1962 8.78e+09
## 4 Africa 1967 1.14e+10
## 5 Africa 1972 1.51e+10
## 6 Africa 1977 1.87e+10
## 7 Africa 1982 2.20e+10
## 8 Africa 1987 2.41e+10
## 9 Africa 1992 2.63e+10
## 10 Africa 1997 3.00e+10
## 11 Africa 2002 3.53e+10
## 12 Africa 2007 4.58e+10
## 13 Americas 1952 1.18e+11
## 14 Americas 1957 1.41e+11
## 15 Americas 1962 1.69e+11
## 16 Americas 1967 2.18e+11
## 17 Americas 1972 2.68e+11
## 18 Americas 1977 3.24e+11
## 19 Americas 1982 3.63e+11
## 20 Americas 1987 4.39e+11
## 21 Americas 1992 4.90e+11
## 22 Americas 1997 5.83e+11
## 23 Americas 2002 6.61e+11
## 24 Americas 2007 7.77e+11
## 25 Asia 1952 3.41e+10
## 26 Asia 1957 4.73e+10
## 27 Asia 1962 6.01e+10
## 28 Asia 1967 8.46e+10
## 29 Asia 1972 1.24e+11
## 30 Asia 1977 1.60e+11
## 31 Asia 1982 1.94e+11
## 32 Asia 1987 2.42e+11
## 33 Asia 1992 3.07e+11
## 34 Asia 1997 3.88e+11
## 35 Asia 2002 4.58e+11
## 36 Asia 2007 6.28e+11
## 37 Europe 1952 8.50e+10
## 38 Europe 1957 1.10e+11
## 39 Europe 1962 1.39e+11
## 40 Europe 1967 1.73e+11
## 41 Europe 1972 2.19e+11
## 42 Europe 1977 2.55e+11
## 43 Europe 1982 2.79e+11
## 44 Europe 1987 3.17e+11
## 45 Europe 1992 3.43e+11
## 46 Europe 1997 3.84e+11
## 47 Europe 2002 4.36e+11
## 48 Europe 2007 4.93e+11
## 49 Oceania 1952 5.42e+10
## 50 Oceania 1957 6.68e+10
## 51 Oceania 1962 8.23e+10
## 52 Oceania 1967 1.06e+11
## 53 Oceania 1972 1.34e+11
## 54 Oceania 1977 1.55e+11
## 55 Oceania 1982 1.76e+11
## 56 Oceania 1987 2.09e+11
## 57 Oceania 1992 2.36e+11
## 58 Oceania 1997 2.89e+11
## 59 Oceania 2002 3.45e+11
## 60 Oceania 2007 4.04e+11
daply(
.data = calcGDP(gapminder),
.variables = c("continent", "year"),
.fun = function(x) mean(x$gdp)
)## year
## continent 1952 1957 1962 1967 1972 1977 1982
## Africa 5.99e+09 7.36e+09 8.78e+09 1.14e+10 1.51e+10 1.87e+10 2.20e+10
## Americas 1.18e+11 1.41e+11 1.69e+11 2.18e+11 2.68e+11 3.24e+11 3.63e+11
## Asia 3.41e+10 4.73e+10 6.01e+10 8.46e+10 1.24e+11 1.60e+11 1.94e+11
## Europe 8.50e+10 1.10e+11 1.39e+11 1.73e+11 2.19e+11 2.55e+11 2.79e+11
## Oceania 5.42e+10 6.68e+10 8.23e+10 1.06e+11 1.34e+11 1.55e+11 1.76e+11
## year
## continent 1987 1992 1997 2002 2007
## Africa 2.41e+10 2.63e+10 3.00e+10 3.53e+10 4.58e+10
## Americas 4.39e+11 4.90e+11 5.83e+11 6.61e+11 7.77e+11
## Asia 2.42e+11 3.07e+11 3.88e+11 4.58e+11 6.28e+11
## Europe 3.17e+11 3.43e+11 3.84e+11 4.36e+11 4.93e+11
## Oceania 2.09e+11 2.36e+11 2.89e+11 3.45e+11 4.04e+11for 루프 자리에 람다 함수를 사용할 수 있다(대체로 더 빠르다):
for 루프 몸통부분을 람다 함수에 작성하면 된다:
d_ply(
.data=gapminder,
.variables = "continent",
.fun = function(x) {
meanGDPperCap <- mean(x$gdpPercap)
print(paste(
"The mean GDP per capita for", unique(x$continent),
"is", format(meanGDPperCap, big.mark=",")
))
}
)## [1] "The mean GDP per capita for Africa is 2,194"
## [1] "The mean GDP per capita for Americas is 7,136"
## [1] "The mean GDP per capita for Asia is 7,902"
## [1] "The mean GDP per capita for Europe is 14,469"
## [1] "The mean GDP per capita for Oceania is 18,622"꿀팁: 숫자 출력하기
format 함수를 사용해서 메시지와 함께 숫자값을 “예쁘게” 출력할 수도 있다.
32.3 도전과제 2
대륙과 연도별로 평균 기대수명을 계산하시오. 2007년에 어느 것이 가장 짧고, 가장 긴가? 1952년과 2007년 사이에 가장 커다란 변화는 어느 것인가?
도전과제 2에 대한 해답
solution <- ddply( .data = gapminder, .variables = c("continent", "year"), .fun = function(x) mean(x$lifeExp) ) solution_2007 <- solution[solution$year == 2007, ] solution_2007## continent year V1 ## 12 Africa 2007 54.8 ## 24 Americas 2007 73.6 ## 36 Asia 2007 70.7 ## 48 Europe 2007 77.6 ## 60 Oceania 2007 80.7오세아니아 대륙이 2007년 가장 긴 평균 기대수명을 갖는 반면 아프리카 대륙이 가장 짧다.
solution_1952_2007 <- cbind(solution[solution$year == 1952, ], solution_2007) difference_1952_2007 <- data.frame(continent = solution_1952_2007$continent, year_1957 = solution_1952_2007[[3]], year_2007 = solution_1952_2007[[6]], difference = solution_1952_2007[[6]] - solution_1952_2007[[3]]) difference_1952_2007## continent year_1957 year_2007 difference ## 1 Africa 39.1 54.8 15.7 ## 2 Americas 53.3 73.6 20.3 ## 3 Asia 46.3 70.7 24.4 ## 4 Europe 64.4 77.6 13.2 ## 5 Oceania 69.3 80.7 11.5아시아 대륙이 가장 큰 차를 보이는 반면 오세아니아 대륙이 가장 적은 차를 보인다.
32.4 대안 도전과제
실제로 실행하지 말고, 다음 중 어떤 코드가 대륙별 평균 기대수명을 계산하는가:
ddply(
.data = gapminder,
.variables = gapminder$continent,
.fun = function(dataGroup) {
mean(dataGroup$lifeExp)
}
)
ddply(
.data = gapminder,
.variables = "continent",
.fun = function(dataGroup) {
mean(dataGroup$lifeExp)
}
)
adply(
.data = gapminder,
.variables = "continent",
.fun = function(dataGroup) {
mean(dataGroup$lifeExp)
}
)도전과제에 대한 해답
대륙별 평균 기대수명을 4번째 R 코드로 계산할 수 있다.