A crash reduces
your expensive computer
to a simple stone.5 유니코드와 UTF-8
사람 간의 의사소통은 다양한 기호 체계를 통해 이루어진다. 영어 알파벳, 한글, 한자 등 문자가 의사소통에 사용되는 좋은 예다. 디지털 환경에서 이러한 의사소통을 가능하게 하는 기술적 장치가 바로 문자집합과 문자 인코딩과 디코딩이다.
컴퓨터 시스템은 이진수 바이트를 기본 단위로 사용한다. 바이트는 파일 형태로 묶이거나 네트워크를 통해 전송되어 다른 시스템에 도달한다. 이 데이터가 사람에게 의미 있는 정보로 전달되기 위해서는 인코딩(부호화)과 디코딩(복호화) 과정을 거쳐야 한다.
컴퓨터 시스템은 데이터를 바이트(Byte) 형태로 처리한다. 이 바이트 데이터는 이진수, 즉 010101과 같은 형태로 표현되고, 바이트 데이터를 사람이 읽을 수 있는 문자로 변환하는 최초의 표준이 ASCII(아스키)다. 하지만 ASCII는 256개 문자만을 지원하기 때문에, CJK(중국, 일본, 한국)와 같은 동아시아 문화권에서는 그 한계가 명확하다. 이러한 한계를 해결하기 위해 유니코드(Unicode) 가 도입되었다. 유니코드는 영문자는 물론이고 지구상의 거의 모든 문자와 기호를 디지털로 표현할 수 있는 방법을 제공한다.
유니코드(Unicode)는 글자와 코드가 1:1 매핑되어 있는 단순한 코드표에 불과하고 산업표준으로 일종의 국가 당사자간 약속이다. 한글이 표현된 유니코드 영역도 위키백과 유니코드 영역에서 찾을 수 있다.
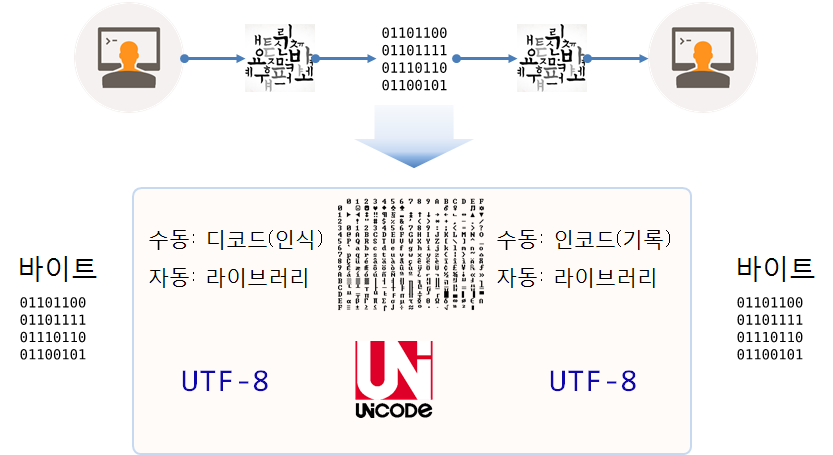
인코딩 (Encoding)
문자 인코딩(character encoding) 줄여서 인코딩은 사용자가 입력한 문자나 기호들을 컴퓨터가 이용할 수 있는 신호로 만드는 것을 말한다. 넓은 의미의 컴퓨터는 이러한 신호를 입력받고 처리하는 기계를 뜻하며, 신호 처리 시스템을 통해 이렇게 처리된 정보를 사용자가 이해할 수 있게 된다.
All text has a character encoding.
5.1 인코딩 문제
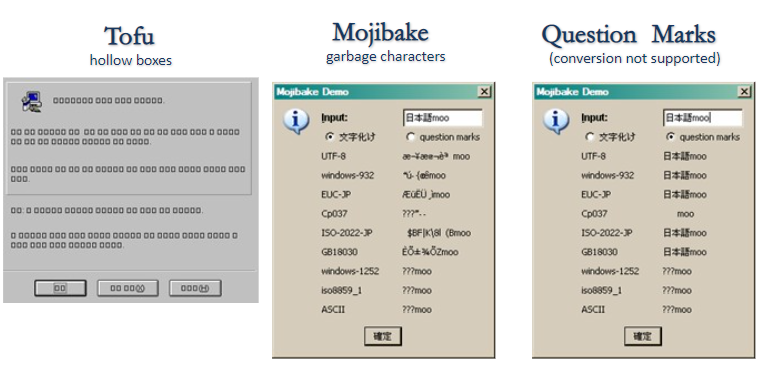
문자 인코딩은 컴퓨터가 텍스트를 바이트로 변환하거나 바이트를 텍스트로 변환하는 방법이다. 인코딩 과정에서는 다양한 문제가 발생할 수 있고, 그 중 세 가지 문제가 많이 알려져있다. 첫번째는 ’두부(Tofu)’라 불리는 상황으로, 컴퓨터가 어떤 문자를 표현해야 할지 알지만, 화면에 어떻게 출력해야 할지 모르기 때문에 빈 사각형 상자로 표시된다. 두번째는 ’문자깨짐(Mojibake, 文字化け)’이다. 특히 일본어에서 자주 발생하며, 한 인코딩 방식으로 작성된 텍스트가 다른 인코딩 방식으로 해석될 때 문자가 깨지는 현상을 의미한다. 세번째는 ’의문부호(Question Marks)’로, 특정 문자가 다른 문자로 변환될 때 발생된다. 문자집합과 인코딩 궁합이 맞지 않을 때 발생하며, 데이터 손실과 오류도 야기된다.
5.2 문자 집합
5.2.1 아스키 코드
디지털 글쓰기는 내용과 상관없이 결국 텍스트로 표현되고, 텍스트는 단지 문자다. 하지만, 컴퓨터가 문자 하나를 어떻게 표현할까?
1960년대 미국식 영문자를 컴퓨터로 표현하는 해결책은 간단했다 - 알파벳 26개(대문자, 소문자), 숫자 10, 구두점 몇개, 그리고 전신을 보내던 시절에 제어를 위해 사용된 몇개 특수 문자(“새줄로 이동”, “본문 시작”, “개행”, “경고음”, 등). 모두 합쳐도 128개보다 적어서, 아스키(ASCII) 위원회가 문자마다 7비트( \(2^7\) = 128)를 사용하는 인코딩으로 표준화했다. 1

그림 fig-ascii 에 아스키 문자표에 제어문자 10개와 출력가능 아스키 문자표 중 영문 대문자 A-I까지 10개를 뽑아 사례로 보여주고 있다. 즉, 문자표는 어떤 문자가 어떤 숫자에 해당하는지를 정의하고 있다.
5.2.2 확장 아스키
아스키(ASCII) 방식으로 숫자 2, 문자 q, 혹은 곡절 악센트 ^ 를 표현하는데 충분하다. 하지만, 투르크어족 추바시어 ĕ, 그리스 문자 β, 러시아 키릴문자 Я 는 어떻게 저장하고 표현해야 할까? 7-비트를 사용하면 0 에서 127까지 숫자를 부여할 수 있지만, 8-비트(즉, 1 바이트)를 사용하게 되면 255까지 표현할 수 있다. 그렇다면, ASCII 표준을 확장해서 추가되는 128개 숫자에 대해 추가로 문자를 표현할 수 있게 된다.
- 아스키: 0…127
- 확장된 아스키: 128…255
불행하게도, 영어문자를 사용하지 않는 세계 곳곳에서 많은 사람들이 시도를 했지만, 방식도 다르고, 호환이 되지 않는 방식으로 작업이 되어, 결과는 엉망진창이 되었다. 예를 들어, 실제 텍스트가 불가리아어로 인코딩되었는데 스페인어 규칙을 사용해서 인코딩한 것으로 프로그램이 간주하고 처리될 경우 결과는 무의미한 횡설수설 값이 출력된다. 이와는 별도로 한중일(CJK) 동아시아 국가들을 비롯한 많은 국가들이 256개 이상 기호를 사용한다. 왜냐하면 8-비트로 특히 동아시아 국가 문자를 표현하는데 부족하기 때문이다.
5.2.3 한글 완성형과 조합형
1980년대부터 컴퓨터를 사용하신 분이면 완성형과 조합형의 표준화 전쟁을 지켜봤을 것이고, 그 이면에는 한글 워드프로세서에 대한 주도권 쟁탈전이 있었던 것을 기억할 것이다. 결국 완성형과 조합형을 모두 포용하는 것으로 마무리 되었지만, 여기서 끝난게 끝난 것이 아니다. 유닉스 계열에서 KSC5601을 표준으로 받아들인 EUC-KR과 90년대와 2000년대를 호령한 마이크로소프트 CP949 가 있었다. 결국 대한민국 정부에서 주도한 표준화 전쟁은 유닉스/리눅스, 마이크로소프트 모두를 녹여내는 것으로 마무리 되었고, 웹과 모바일 시대는 유니코드로 넘어가서 KSC5601이 유니코드의 원소로 들어가는 것으로 마무리 되었다.
이제 신경쓸 것은 인코딩 … utf-8 만 신경쓰면 된다. 그리고 남은 디지털 레거시 유산을 잘 처리하면 된다.
유닉스/리눅스(EUC-KR), 윈도우(CP949)
EUC-KR, CP949 모두 2바이트 한글을 표현하는 방식으로 동일점이 있지만, EUC-KR 방식은 KSC5601-87 완성형을 초기 사용하였으나, KSC5601-92 조합형도 사용할 수 있도록 확장되었다. CP949는 확장 완성형으로도 불리며 EUC-KR에서 표현할 수 없는 한글글자 8,822자를 추가한 것으로 마이크로소프트 코드페이지(Code Page) 949를 사용하면서 일반화되었다.
5.2.4 유니코드
1990년대 나타나기 시작한 해결책을 유니코드(Unicode) 라고 부른다. 예를 들어, 영어 A 대문자는 1 바이트, 한글 가는 3 바이트다. 유니코드는 정수값을 서로 다른 수만개 문자와 기호를 표현하는데 정의한다. ’A’는 U+0041, ’가’는 U+AC00과 같이 고유한 코드 포인트를 가진다. 하지만, 파일에 혹은 메모리에 문자열로 정수값을 저장하는 방식을 정의하지는 않는다.
각 문자마다 8-비트를 사용하던 방식에서 32-비트 정수를 사용하는 방식으로 전환하면 되지만, 영어, 에스토니아어, 브라질 포르투칼어 같은 알파벳 언어권에는 상당한 공간 낭비가 발생된다. 접근 속도가 중요한 경우 메모리에 문자당 32 비트를 종종 사용한다. 하지만, 파일에 데이터를 저장하거나 인터넷을 통해 전송하는 경우 대부분의 프로그램과 프로그래머는 이와는 다른 방식을 사용한다.
다른 방식은 (거의) 항상 UTF-8 으로 불리는 인코딩으로, 문자 마다 가변 바이트를 사용한다. 하위 호환성을 위해, 첫 128개 문자(즉, 구 아스키 문자집합)는 바이트 1개에 저장된다. 다음 1920개 문자는 바이트 2개를 사용해서 저장된다. 다음 61,000은 바이트 3개를 사용해서 저장해 나간다.
궁금하면, 동작 방식이 다음 표에 나타나 있다. “전통적” 문자열은 문자마다 1 바이트를 사용한다. 반대로, “유니코드” 문자열은 문자마다 충분한 메모리를 사용해서 어떤 텍스트 유형이든 저장한다. R, 파이썬 3.x 에서 모든 문자열은 유니코드다. 엄청난 바이트를 읽어오거나 저장하여 내보내려고 할때, 인코딩을 지정하는 것은 엄청난 고통이다.
유니코드 문자열은 여는 인용부호 앞에 소문자 U를 붙여 표시한다. 유니코드 문자열을 바이트 문자열로 전환하려면, 인코딩을 명세해야만 된다. 항상 UTF-8을 사용해야만 되고, 그밖의 인코딩을 사용하는 경우 매우, 매우 특별히 좋은 사유가 있어야만 된다. 특별한 인코딩을 사용하는 경우 두번 생각해 보라.
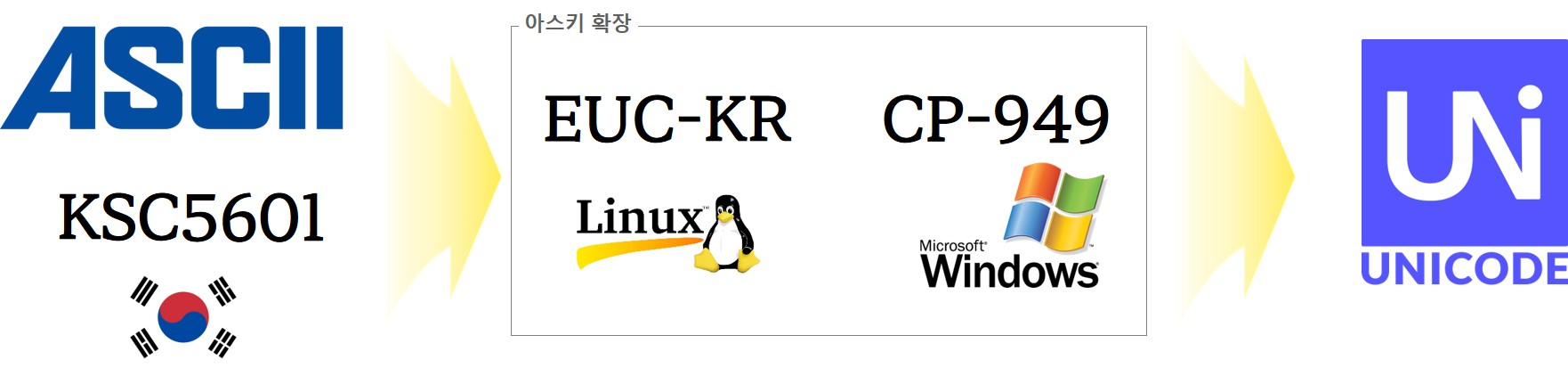
컴퓨터가 처음 등장할 때 미국 영어권 중심 아스키가 아니고 4바이트 전세계 모든 글자를 표현할 수 있는 유니코드가 사용되었다면 한글을 컴퓨터에 표현하기 위한 지금과 같은 번거로움은 없었을 것이다. 돌이켜보면 초기 컴퓨터가 저장용량 한계로 인해 유니코드가 표준으로 자리를 잡더라도 실용적인 이유로 인해서 한글을 컴퓨터에 표현하기 위한 다른 대안이 제시됐을 것도 분명해 보인다. 초창기 영어권을 중심으로 아스키 표준이 정립되어 현재까지 내려오고, 유니코드와 UTF-8 인코딩이 사실상 표준으로 자리잡았으며, 그 사이 유닉스/리눅스 EUC-KR, 윈도우즈 CP949가 빈틈을 한동안 매우면서 역할을 담당했다.
| 항목 | ASCII (1963) | EUC-KR (1980s) | CP949 (1990s) | Unicode (1991) |
|---|---|---|---|---|
| 범위 | 128개의 문자 | 2,350개의 한글 문자 등 | 약 11,172개의 완성형 한글 문자 등 | 143,859개의 문자 (버전 13.0 기준) |
| 비트 수 | 7비트 | 8~16비트 | 8~16비트 | 다양한 인코딩 방식 (UTF-8, UTF-16, UTF-32 등) |
| 표준 | ANSI, ISO/IEC 646 | KS X 2901 | 마이크로소프트 | ISO/IEC 10646 |
| 플랫폼 | 다양한 시스템 | UNIX 계열, 일부 Windows | Windows 계열 | 다양한 플랫폼 |
| 문자 집합 | 영문 알파벳, 숫자, 특수 문자 | 한글, 영문 알파벳, 숫자, 특수 문자 | 한글, 한자, 영문 알파벳, 숫자, 특수 문자 | 전 세계 언어, 특수 문자, 이모티콘 등 |
| 확장성 | 확장 불가능 | 한정적 | 더 많은 문자 지원 | 높은 확장성 |
| 국제성 | 영어 중심 | 한국어 중심 | 한국어 중심 | 다국어 지원 |
| 유니코드 호환 | 호환 가능 (U+0000 ~ U+007F) | 호환 불가, 변환 필요 | 유니코드와 상호 변환 가능 | 자체가 표준 |
5.3 UTF-8
UTF-8(Universal Coded Character Set + Transformation Format – 8-bit의 약자)은 유니코드 중에서 가장 널리 쓰이는 인코딩으로, 유니코드를 위한 가변 길이 문자 인코딩 방식 중 하나로 켄 톰프슨과 롭 파이크가 제작했다.
UTF-8 인코딩의 가장 큰 장점은 아스키(ASCII), 라틴-1(ISO-8859-1)과 호환되어, 문서를 처리하는 경우 아스키, 라틴-1 문서를 변환 없이 그대로 처리할 수 있고 영어를 비롯한 라틴계열 문서로 저장할 때 용량이 매우 작다. 이러한 이유로 많은 오픈소스 소프트웨어와 데이터를 생산하는 미국을 비롯한 유럽언어권에서 UTF-8이 많이 사용되고 있지만, 한글은 한 글자당 3바이트 용량을 차지한다.
5.3.1 웹 표준 인코딩
스마트폰의 대중화에 따라 더이상 윈도우 운영체제에서 사용되는 문자체계가 더이상 표준이 되지 못하고 여러 문제점을 야기함에 따라 유니코드 + UTF-8 체제가 대세로 자리잡고 있는 것이 확연히 나타나고 있다.
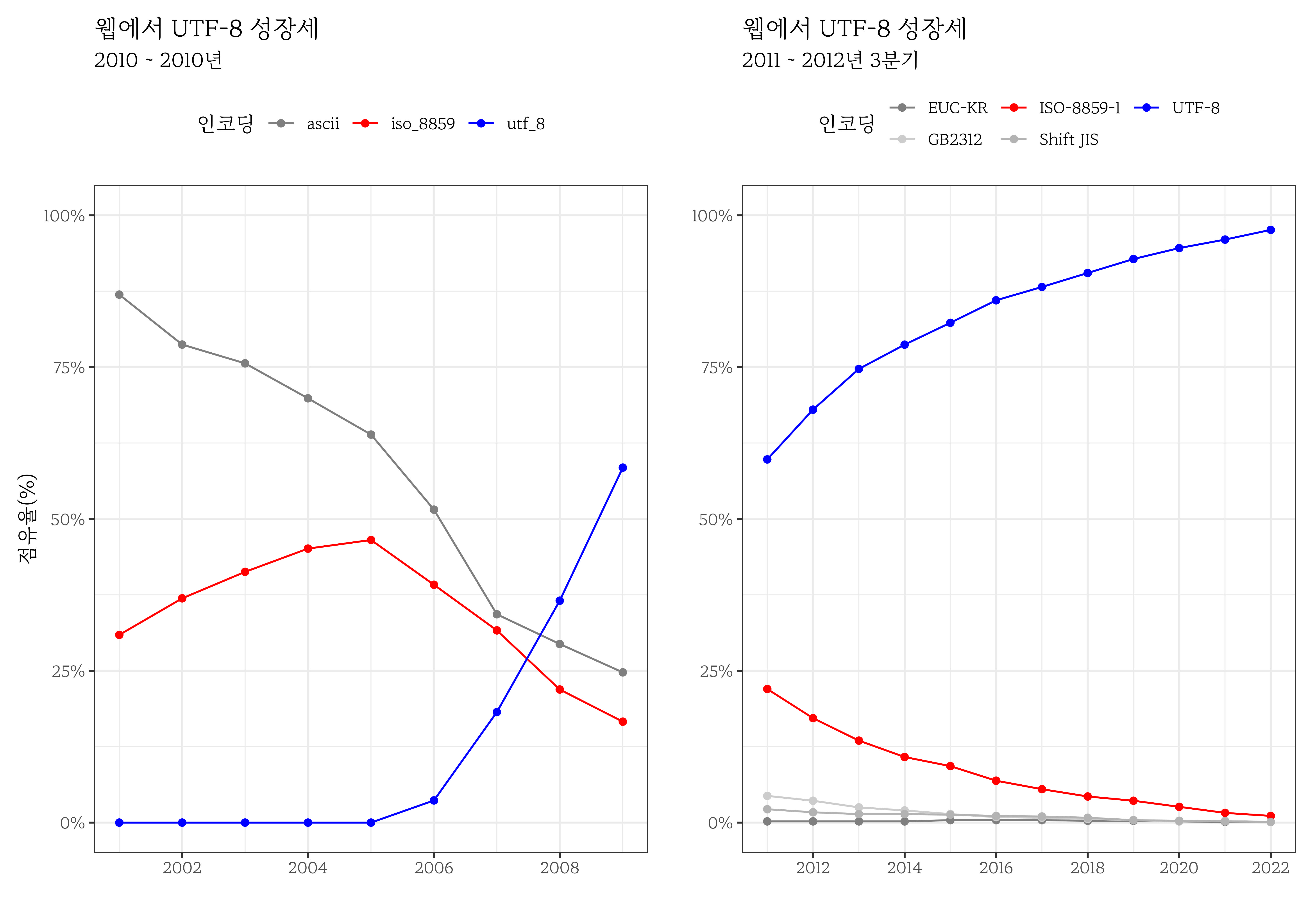
2010년 구글에서 발표한 자료에 의하면 2010년 UTF-8 인코딩이 웹에서 주류로 부상하기 시작한 것이 확인되었다. (Davis, 2010) 웹기반 플롯 디지털 도구를 활용하여 그래프(WebPlotDigitizer)에서 데이터를 추출하여 시각화면 유사한 결과를 시각적으로 표현할 수 있다. 2010년 이후 웹에서 가장 점유율이 높은 인코딩 방식은 UTF-8으로 W3Tech 웹기술조사(Web Technology Surveys)를 통해 확인을 할 수 있다. 여기서 주목할 점은, 프랑스어, 독일어, 스페인어와 같은 서유럽 언어의 문자와 기호 표현하는 ISO-8859-1 인코딩, 종종 “Latin-1”으로 불리는 8비트 문자 인코딩이 현저히 줄고 있다는 점이다.
5.4 텍스트 표현
1940년대, 1950년대 펀치카드 기술로 정의된 첫번째 방식이 고정폭 레코드(fixed-width records) 를 사용하는 것으로, 각 줄마다 동일한 고정길이를 갖는다. 예를 들어, 다음 일본 전통 단시 하이쿠(haiku)를 컴퓨터로 아래와 같이 레코드 3개로 배열했다. (점 문자는 “사용되지 않음”을 의미) 이런 방식은 여전히 데이터베이스에도 사용되고 있다.
일본 전통 단시 하이쿠 예시

이런 표기법은 N번째 행 앞으로 뒤로 건너뛰기 쉬운데 이유는 각 행이 동일한 크기를 갖기 때문이다. 하지만, 공간을 낭비하는 약점이 있고, 행마다 얼마나 긴 최대 길이를 갖느냐에 관계없이, 궁극적으로 더 긴 길이를 갖는 행을 기준으로 처리해야만 된다.
시간이 흐름에 따라 개발자 대부분은 다른 표현법으로 전환했다. 전환된 표현법에 따르면 텍스트는 단지 연속된 바이트(byte)에 불과하고, 이런 연속된 바이트 일부에 “현재 라인은 여기서 종료” 라는 의미가 담겨진다. 이러한 표현법으로 일본 전통 단시 하이쿠를 다시 표현하면 다음과 같다.

회색칸이 “행의 끝(end of line)”을 의미한다. 이런 표기법은 더 유연하고, 공간을 덜 낭비하지만, N번째 행 앞으로 뒤로 건너뛰는 것은 어렵게 되었다. 이유는 각각이 다른 길이를 갖기 때문이다. 물론 행 종료를 표시하는데 무엇을 사용할지 결정해야하는 문제가 남았다. 불행히도, 유닉스에서는 행의 끝으로 개행 문자(newline) 한개, \n으로 정했지만, 윈도우에서는 행의 끝으로 복귀문자(carriage return) 다음에 개행문자, \r\n 으로 정했다.
편집기 대부분에서 이런 차이를 탐지하고 처리할 수 있지만, 유닉스와 윈도우를 모두 다뤄야 되는 프로그래머에게는 여전히 성가신 일이다. 윈도우 운영체제 파일에서 데이터를 불러읽어올 경우, 파이썬에서 \r\n 을 \n 으로 전환하고, 데이터를 써서 저장할 경우 반대 방식으로 전환한다. 그러나 이미지, 소리 또는 기타 이진 파일형식에서 \r 또는 \n에 해당하는 문자가 우연히 포함되어 있다면, 원치 않는 변환이 발생할 수 있다.
5.5 현지화/세계화
현지화(Localization)는 세계화(internationalization)의 동전의 양면과 같다. 세계화를 영어로 internationalization으로 길기 때문에 i18n으로 줄여서 현지화는 영어로 Localization으로 길기 때문에 동일한 로직으로 L10N으로 줄여 표현한다. 현지화에 해당되는 사항은 다음이 포함된다. (Oliver, 2017)
- 문자 집합
- 통화
- 날씨 온도(\(^{\circ} C / ^{\circ} F\))
- 길이 (킬로미터, 마일)
- 날짜와 시간
- 키보드 배열
- 좌측에서 우축으로, 위에서 아래, 우측에서 좌측으로 텍스트 작성 방식과 문서양식
- …
Davis, M. (2010). Unicode nearing 50% of the web. https://googleblog.blogspot.com/2010/01/unicode-nearing-50-of-web.html
Oliver, C. (2017). Internationalization Part I: Unicode and Character Encodings. https://slideplayer.com/slide/7684069/