graph TD
A[데이터 수집] --> B[데이터 전처리]
B --> C[피쳐 추출]
C --> D[훈련-테스트 데이터셋 분할]
D --> E[모형 선택]
E --> F[모형 학습]
F --> G[모형 평가]
G --> H[하이퍼파라미터 튜닝]
H --> I[모형 배포]
I --> J[모니터링 및 유지보수]
24 챗GPT
기술채택(소비) 속도가 가파라지는 현대 사회에서 챗GPT는 전기, 냉장고, 세탁기, 에어콘, 컴퓨터, 전화기, 휴대폰처럼 혁신적인 와해기술의 한 예라고 할 수 있다. 전화기가 50%의 가정에 보급되기까지 수십 년이 걸렸던 것과 대비해, 휴대폰은 1990년에 동일한 보급율을 달성하는 데 몇년 걸리지 않았다. 혁신적인 기술의 수용기간이 점점 짧아지고 있다는 것이 최근들어 뚜렷하게 나타나고 있다. (McGrath, 2013)
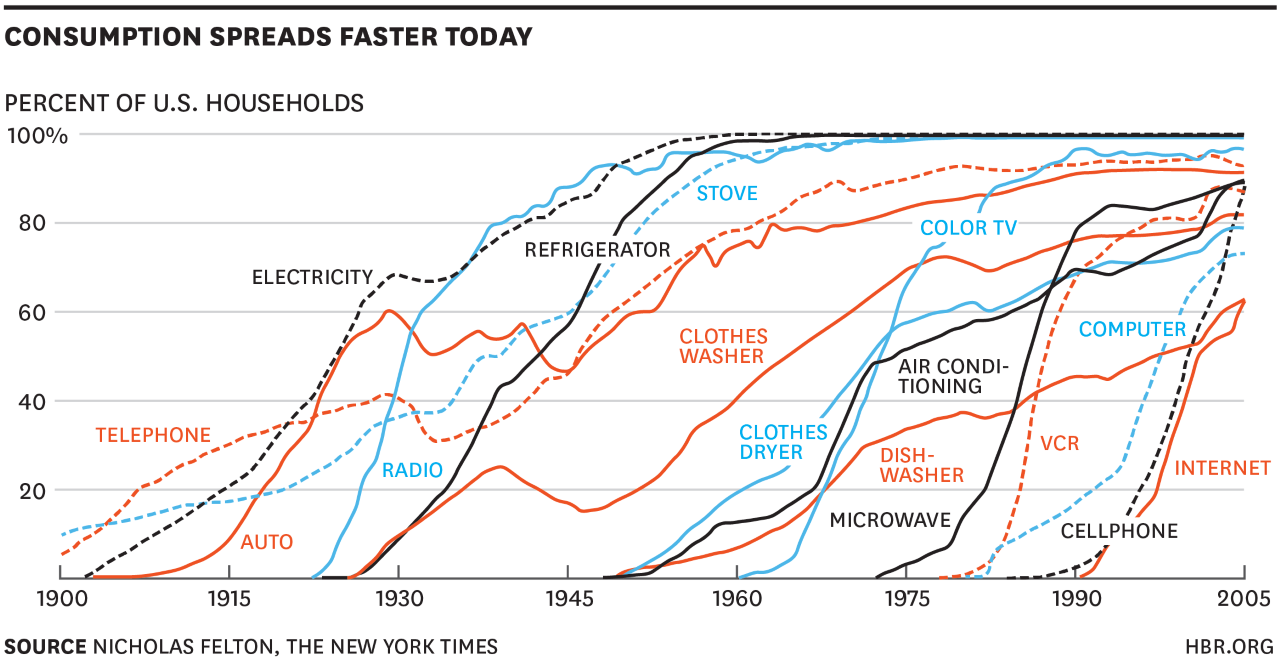
챗GPT 역시 이러한 빠른 채택 속도흐름을 따르고 있다. 2022년 11월 30일에 출시된 이후 단 5일 만에 100만 명의 사용자를 확보했는데 이는 넷플릭스(Netflix), 페이스북(Facebook), 트위터(Twitter)와 같은 대형 플랫폼보다도 빠른 수용율을 보이고 있다. 특히, 백만 사용자를 획득기간이 단 5일에 불과하여 최근 인기를 얻고 있는 스포티파이(Spotify) 150일, 인스타그램(Instagram) 75일을 한참 뛰어넘는 엄청난 수용속도다.
챗GPT, 즉 인공지능(AI)을 빠르게 채택하는 것은 단순히 새로운 기술 트렌드에 빠르게 대응하는 것을 넘어, 챗GPT를 빠르게 수용하여 내재화 하는 사람과 그렇지 않은 사람 사이에 정보 접근성, 편의성, 시간 효율성 등에서 큰 격차를 만들어 내고 있다. 이러한 격차는 개인뿐만 아니라 정부, 기업 차원에서도 중요하기 때문에 빠른 도입을 통해 경험하고 내재화하는 것이 더욱 중요하다고 할 수 있다.
24.1 생성형 AI
24.1.1 JPEG 압축
챗GPT는 웹의 무수한 데이터를 학습한 하나의 압축저장소로 볼 수 있다. 압축을 풀게되면 원본을 정확히 복원할 수 있는 경우도 있지만, 그렇지 않은 경우도 불가피하게 존재한다(Chiang, 2023) .
챗GPT는 “웹의 흐릿한 JPEG”라는 비유로 설명된다. JPEG 기술은 손실 압축 기술로, 무손실 압축 기술인 PNG와 대조된다. 흐릿한 이미지가 선명하지 않거나 정확하지 않은 것처럼, 챗GPT 역시 항상 완벽한 답변을 제공하거나 모든 질문을 정확히 이해하는 것은 아니다. 그러나 사용자와의 상호작용을 통해 지속적인 학습을 통해 개선되고 있다. 더 많은 사람들이 챗GPT를 사용하면 할수록, 그만큼 더 정교하게 사람의 언어를 이해하고 대화할 수 있는 기술로 발전하게 된다.
챗GPT를 비롯한 유사 인공지능(AI)이 너무 강력해져 인간을 대체할 것이라는 우려도 있지만, 챗GPT는 결국 인간의 작업을 더 쉽고 효율적으로 수행할 수 있는 강력한 도구에 불과하기 때문에, 인간을 능가하거나 지배할 가능성은 거의 없다. 챗GPT 즉, 인공지능을 책임감 있고 윤리적으로 사용하는 것은 결국 가계, 기업, 정부, 우리 모두의 책임이다.
챗GPT가 간단한 사칙연산 계산에서 어려움을 겪는 것은 웹에 퍼져 있는 숫자 계산 데이터를 기반으로 학습하여 계산을 모방할 뿐이기 때문이다. 만약 사칙연산에 대한 일반적 원칙을 제대로 이해한다면, 웹에서 발견되는 사칙연산 문제뿐만 아니라 다른 계산 문제도 정확히 해결할 수 있지만 현재로는 그렇지 못하기 때문에 플러그인(Plugin)을 통해 해결하고 있다.

24.1.2 기초모형
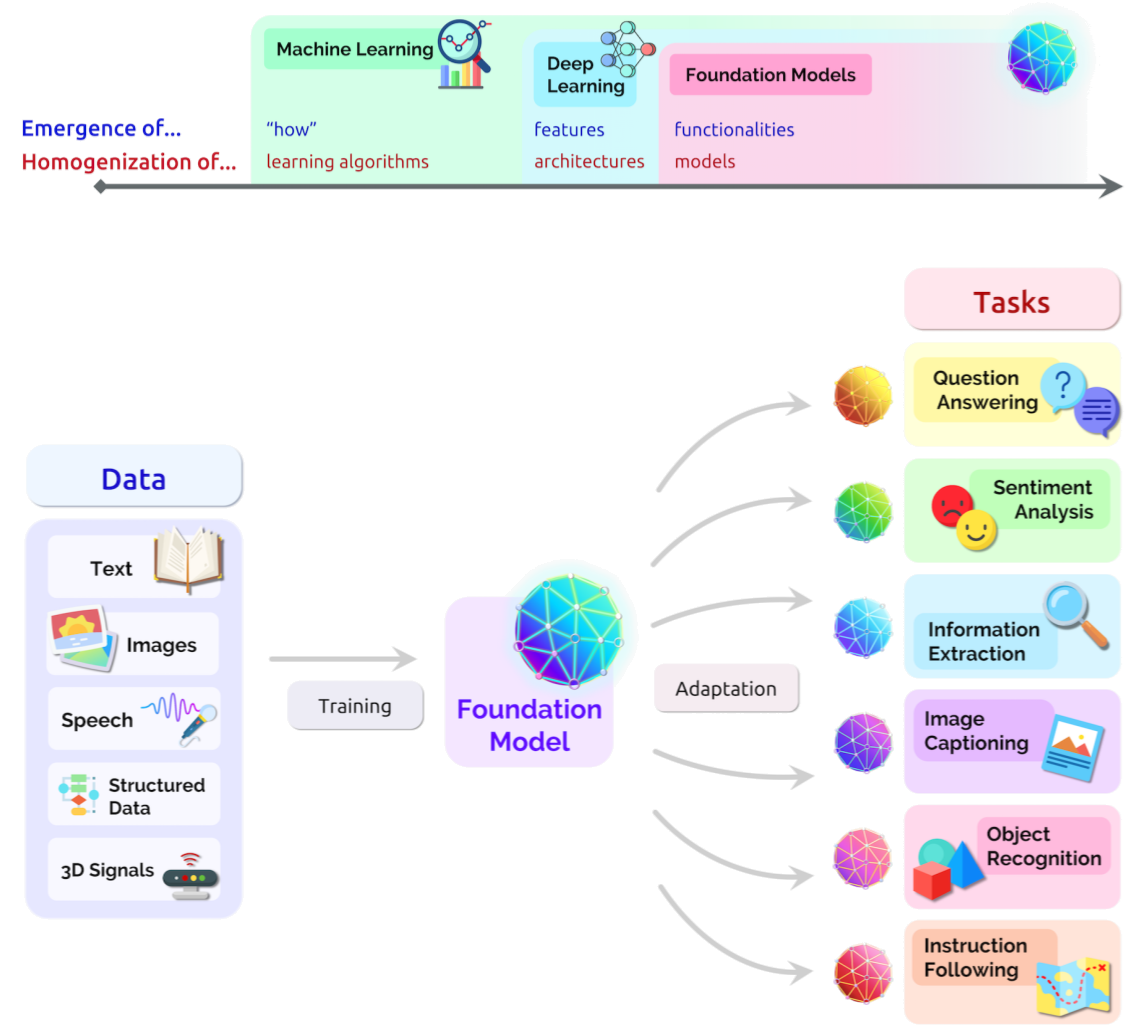
기초모형(Foundation Model)이라는 새로운 패러다임은 인공지능(AI) 시스템 구축에 혁신적인 변화를 가져왔다. 이러한 모델은 광범위한 데이터에 대해 사전에 학습되어 있어, 다양한 실무하위 작업에 적용할 수 있는 범용성을 가지고 있다. BERT, GPT-3, CLIP 등이 대표적인 예로, 이들 모델은 텍스트, 이미지, 음성 등 다양한 형태의 데이터에 대한 처리가 가능하다.
기초모형의 등장은 기존의 특정 작업에 특화된 모델을 개발하는 방식을 넘어, 하나의 모델로 여러 작업을 수행할 수 있는 새로운 접근법을 제시한다. 이로 인해, 모델 개발과 학습에 드는 비용과 시간이 크게 절감되며, 더 빠르고 효율적인 AI 시스템 구축이 가능해진다.
또한, 기초모형은 미세조정(fine-tuning)을 통해 특정 작업에 적합하게 만들 수 있다. 이는 기초모형이 가진 범용성을 더욱 강화하며, 실무하위 작업에 대한 성능도 향상시킨다. 예를 들어, BERT 모델은 자연어 처리 작업에, CLIP 모델은 이미지와 텍스트를 연결하는 작업에 미세조정을 통해 효과적으로 활용될 수 있다.
이러한 기초모형의 패러다임은 AI의 미래를 크게 밝혀준다. 다양한 분야와 작업에서 활용될 수 있는 이러한 모델은 AI 기술의 적용 범위를 더욱 확장시키며, 그 가능성을 무궁무진하게 만든다. 이는 결국 AI가 사회와 산업의 다양한 분야에서 더욱 깊게 활용될 수 있음을 의미한다.
24.2 거대언어모형 데이터
24.2.1 인터넷 데이터
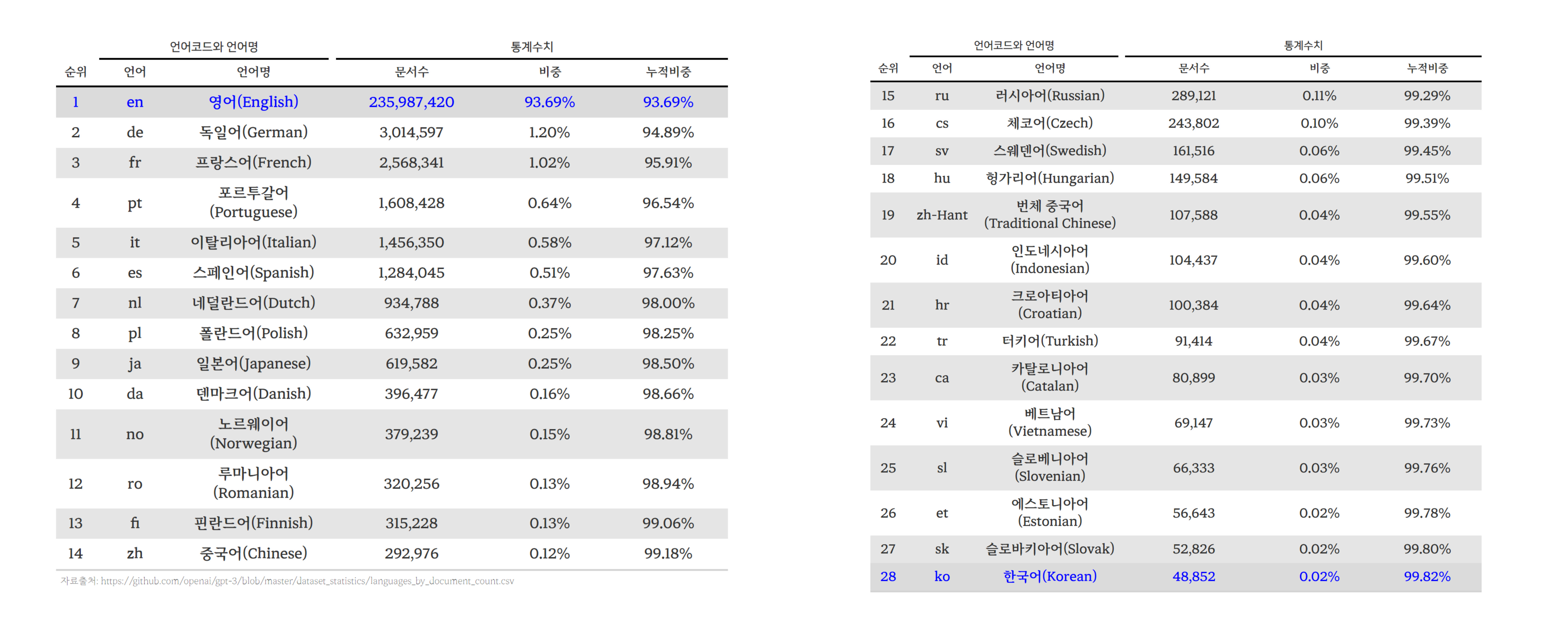
GPT 모델 개발에 있어 언어 데이터는 중요한 자원으로 위키백과 Languages used on the Internet 페이지에서 웹사이트 제작에 사용된 언어 비중을 살펴보는 것은 챗GPT를 이해하는데 도움이 된다. 2023년 9월 16일 기준 위키백과에 따르면, 영어(English)가 웹사이트 제작에 가장 많이 사용되는 언어로, 비중이 53.3%에 달한다. 이는 영어 중심으로 GPT 모델이 개발된 이유를 잘 설명한다. 그 다음으로 스페인어(Spanish)가 5.3%, 러시아어(Russian)가 4.7%, 독일어(German)가 4.5%, 프랑스어(French)가 4.3%로 이어진다. 아시아 언어 중에서 일본어(Japanese)가 4.0%로 가장 높은 비중을 차지하며, 중국어(Chinese)는 1.4%, 한국어(Korean)는 0.7%로 나타난다

24.2.2 GPT-3 훈련 데이터
GPT-3 언어모형 데이터셋 구성을 살펴보면, 영어 문서수가 약 2억 3천만개로 전체의 93.7% 압도적으로 높은 비중을 차지하여 GPT-3 언어모형 학습 데이터가 주로 영어로 구성되어 있음을 의미하며, 이로 인해 영어에 대한 처리 능력이 뛰어날 가능성이 높다. 다음으로 많은 언어는 독일어와 프랑스어로, 각각 전체의 1.2%와 1.02%를 차지하지만 영어와 언어적 유사성이 다른 문화권 언어보다 높아 처리 능력이 높을 것으로 기대할 수 있다.
아시아 언어로 일본어와 중국어가 상위에 랭크되어 있다. 일본어는 약 61만 9천 5백 82개의 문서로 전체의 0.246%를, 중국어는 약 29만 2천 9백 76개의 문서로 0.116%를 차지한다. 한국어는 48,852개의 문서로 전체의 0.0194%를 차지해 GPT-3가 한국어에 대한 처리 능력이 다른 언어와 비교하여 상대적으로 떨어질 수 있음을 시사한다.
24.3 거대언어모형
언어모형이 시간이 지남에 따라 크기가 커져 거대언어모형(Large Language Models, LLMs)이 언어모형을 지칭하는 용어로 자리를 잡아가고 있다. 특히 트랜스포머(Transformer) 기반 사전 훈련된 언어 모형(Pre-trained Language Models, PLMs)은 모형 크기를 확장하면 성능이 향상되고, 특정 규모를 초과하면 거대언어모형에서는 작은 언어모형에서 볼 수 없는 특별한 능력을 발현함을 증명했다. (Zhao 기타, 2023)
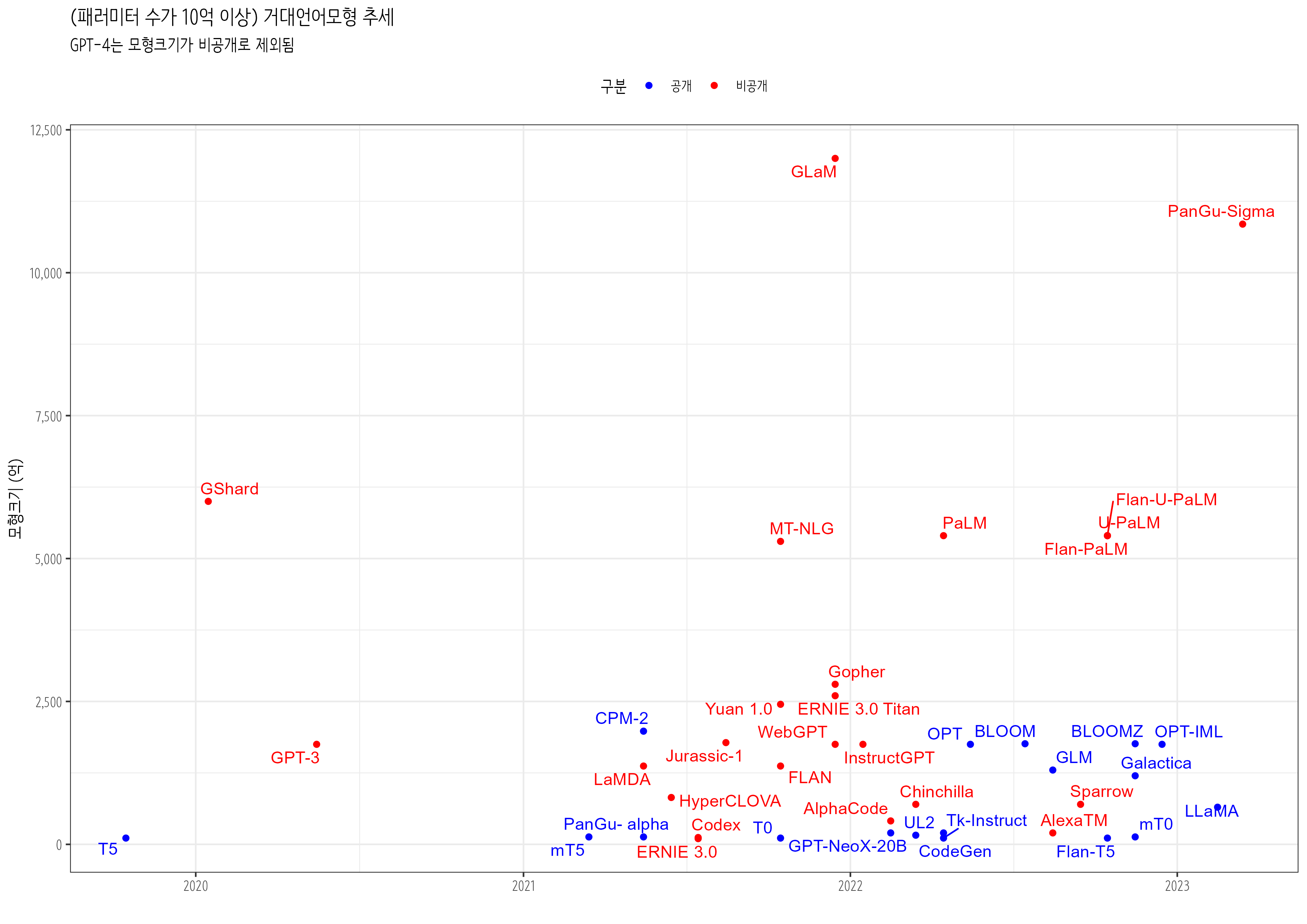
2023년 3월에 발표된 조사에서 10억 이상 패러미터를 가진 거대언어모형이 공개형(Open Source), 폐쇄형(Closed Source)으로 나눠진다. 공개형 거대언어모형은 연구자나 개발자가 자유롭게 접근하여 모형 내부 구조를 이해하거나 수정할 수 있어, 커뮤니티 발전을 촉진하고 다양한 응용 분야에서 활용될 수 있지만 폐쇄형 거대언어모형에 비해 성능이 떨어진다. 반면에 폐쇄형 거대언어모형은 상업적 이익을 목적으로 개발되어 내부 알고리즘에 대한 접근이 제한되지만, 공개형 거대언어모형에 비해 더 뛰어난 성능을 보인다.
학술연구 목적으로 거대언어모형을 사용하려는 경우 공개형 모형이 더 유용할 수 있지만 상업적 활용에서는 폐쇄형 모형이 더 뛰어난 성능을 보이기 더 적합할 수 있다. 거대언어모형이 사회, 정치, 경제, 문화 등 다양한 분야에 영향을 미칠 수 있기 때문에, 거대언어모형 공개여부는 윤리적, 정치적, 사회적 영향을 평가하는 데도 중요한 잣대가 된다.
24.3.1 NLP 활용
거대언어모형은 자연어처리 분야에서 다양한 응용을 가능하게 한다. 특히 텍스트 생성, 기계번역, 질의응답, 요약, 감정분석, 텍스트 분류, 텍스트 유사도 측정 등의 응용이 가능하다.
자연어 처리(NLP)는 텍스트 데이터를 통해 가치를 창출하는 분야에서 중요한 역할을 수행한다. 과거 감정 분석, 텍스트 분류, 개체명 인식(NER) 등 다양한 자연어 처리 작업을 각각 독립적으로 수행하면서 중복되고 파편화된 작업 흐름이 발생했다. 예를 들어, 텍스트 분류 작업을 수행한 후에 감정 분석을 별도 작업으로 수행해야 할 경우, 공통으로 필요한 텍스트 전처리나 피처 추출 과정이 중복된다.
이러한 문제를 해결하기 위해 자연어 처리 작업들을 통합적으로 설계하고 연결하는 것이 중요했다. 텍스트 분류 모형이 특정 주제(예: 스포츠, 정치)에 대한 텍스트를 분류한 후, 해당 주제에 맞는 감정 분석을 적용하거나, 개체명 인식(NER)을 통해 특정 인물이나 조직의 이름을 식별한 후, 이를 기반으로 텍스트 요약이나 질의 응답 시스템을 구축하는 방식이 거대언어모형 출현 이전 많이 사용된 방식이다.
감정 분석, 텍스트 분류, 개체명 인식(NER), 품사(POS) 태깅, 의존성 구문 분석, 기계 번역, 질의 응답, 텍스트 요약, 상호참조해결(Coreference Resolution), 텍스트 생성 등 자연어 처리 작업은 거대언어모형 등장과 함께 한차원 높은 성능 향상을 경험하고 있다. 또한, 기초모형을 활용한 파인튜닝과 프롬프트 공학의 결합으로, 과거 각각의 작업에 특화된 모델을 따로 개발하고 훈련해야 했던 방식과는 대비되고 있다.
- 감정 분석: 긍정, 부정, 중립 등 주어진 텍스트에 표현된 감정을 파악.
- 텍스트 분류: 텍스트 데이터를 미리 정의된 클래스 또는 주제(예: 스포츠, 정치, 연예 등)로 분류.
- 개체명 인식(NER): 텍스트 내에서 사람, 조직, 위치, 날짜 등의 명명된 개체(entity)를 식별하고 분류.
- 품사(POS) 태깅: 주어진 텍스트의 단어에 문법적 레이블(예: 명사, 동사, 형용사)을 할당.
- 의존성 구문 분석: 문장 내 단어 간의 문법 구조와 관계를 식별.
- 기계 번역: 영어에서 스페인어로 또는 중국어에서 프랑스어로와 같이 한 언어에서 다른 언어로 텍스트를 번역.
- 질의 응답: 자연어로 제기된 질문을 이해하고 답변할 수 있는 시스템을 개발.
- 텍스트 요약: 주요 아이디어와 정보를 보존하면서 주어진 텍스트에 대한 간결한 요약을 생성.
- 상호참조해결(Coreference Resolution): 텍스트에서 두 개 이상의 단어나 구가 동일한 개체 또는 개념을 지칭하는 경우 식별.
- 텍스트 생성: 주어진 입력, 컨텍스트 또는 일련의 조건에 따라 일관되고 의미 있는 텍스트를 생성.
24.3.2 NLP 기계학습
자연어처리(NLP) 기계학습은 통계모형과 거의 비슷한 작업흐름을 갖는다. 차이점이 있다면 데이터 관계의 설명보다 예측에 더 중점을 둔다는 점이라고 볼 수 있다. 감성 분석 및 텍스트 분류 등 텍스트를 데이터로 하는 전통적인 자연어 처리 작업은 다음과 같은 작업흐름을 갖게 된다.
먼저, 데이터 수집 단계에서 분석할 텍스트 데이터를 수집한다. 소셜 미디어, 웹사이트, 뉴스 기사 등 다양한 출처에서 데이터를 가져온다. 데이터 전처리 단계에서는 텍스트를 정제하고 필요한 형태로 변환하는데 불필요한 문자나 단어를 제거하고, 텍스트를 토큰화한다.
특성(Feature) 추출 단계에서는 텍스트 데이터에서 기계학습에 사용될 유용한 특성을 추출한다. 단어 빈도수, TF-IDF 값, 단어 임베딩 등을 예로 들 수 있으며 이렇게 추출된 특성은 기계학습에 사용된다.
기계학습 단계에서는 추출된 특성을 기반으로 분류나 회귀예측 모형을 학습한다. 기계학습모형은 텍스트가 어떤 범주에 속하는지, 어떤 감정을 표현하는지 등을 예측하는 데 사용된다. 기계학습모형 평가 단계에서는 시험 데이터를 사용해 모형성능을 평가한다.
거대언어모형의 등장은 앞선 기계학습 작업흐름에 큰 변화를 가져왔다. 특성 추출과 기계학습 단계를 통합함으로써 자연어 처리 작업 복잡성이 크게 줄어 단순해졌지만 성능은 오히려 향상되는 결과를 가져왔다.
데이터 수집: 텍스트 데이터와 해당 레이블이 포함된 데이터셋을 수집한다. 감성 분석의 경우, 라벨은 ‘긍정’, ‘부정’ 또는 ’중립’이 되고, 텍스트 분류의 경우 레이블은 다양한 주제나 카테고리를 나타낼 수 있다. 즉, 자연어 처리 목적에 맞춰 라벨을 특정하고 연관 데이터를 수집한다.
데이터 전처리: 텍스트 데이터를 정리하고 전처리하여 추가 분석에 적합하도록 작업하는데 소문자화, 토큰화, 불용어 제거, 특수문자 제거, 어간 단어 기본형으로 줄이기 등이 포함된다.
피쳐 추출:사전 처리된 텍스트를 기계 학습 알고리즘에 적합한 숫자 형식으로 변환하는 과정으로 BoW, TF-IDF, 단어 임베딩 등이 흔히 사용되는 기법이다.
훈련-시험 데이터셋 분할: 일반적으로 70-30, 80-20 또는 기타 원하는 분할 비율을 사용하여 데이터셋을 훈련과 시험 데이터셋으로 구분한다.
모형 선택: 적합한 통계, 머신 러닝, 딥러닝 모델을 선정한다.
모형 학습: 적절한 최적화 알고리즘과 손실 함수를 사용하여 훈련 데이터셋에서 선택한 모델을 학습시킨다.
모형 평가: 정확도, 정밀도, 리콜, F1 점수 또는 ROC 곡선 아래 영역과 같은 관련 메트릭을 사용하여 시험 데이터셋에서 학습 모형의 성능을 평가한다.
하이퍼파라미터 튜닝: 격자 검색 또는 무작위 검색과 같은 기술을 사용하여 모형의 하이퍼파라미터를 최적화하여 성능을 개선한다.
모형 배포: 모형을 학습하고 최적화한 후에는 실제 환경에서 사용할 수 있도록 실제 운영 환경에 배포하여 가치를 창출한다.
모니터링 및 유지 관리: 배포된 모형의 성능을 지속적으로 모니터링하고 필요에 따라 새로운 학습데이터로 업데이트하여 정확성과 효율성을 유지한다.
24.4 GPT-4 성능과 가격
GPT-4는 대규모 멀티 모달(Multi Modal) 언어모형으로 트랜스포머(Transformer) 기반 사전훈련되어 텍스트에서 다음 토큰을 생성하는 생성형 AI다. 이전 버전 GPT-3.5와 비교하여 더 뛰어난 성능을 보이며 멀티 모달을 지원하여 컴퓨터와 여러가지 형태(텍스트, 이미지 등)로 의사소통하는 채널을 통해 상호작용할 수 있다.
24.4.1 GPT-4 성능
GPT-4는 인공지능 성장과 능력을 객관적으로 평가하기 위해 다양한 시험과 평가를 수행한다. 모형의 언어 이해, 문제 해결 능력, 논리적 추론 등 다양한 능력을 측정하여 결과를 반영한다. Advanced Placement (AP), AMC 10, AMC 12와 같은 시험들은 원래 학생들의 지식과 능력을 측정하기 위해 만들어졌지만, 인공지능이 시험을 풀게함으로써 GPT-4 능력을 객관적으로 평가할 수도 있다. 시험을 통해, 인공지능이 어려운 문제를 얼마나 효과적으로 해결할 수 있는지, 또 다양한 주제와 문맥에서 어떻게 작동하는지 평가 결과를 통해 객관적으로 확인할 수 있다.
Advanced Placement (AP)는 미국 College Board에 의해 운영되는 프로그램으로 고등학생에게 대학 수준의 교육 과정과 평가를 제공한다. 높은 점수를 얻은 학생은 미국의 다양한 대학에서 학점 인정을 받을 수 있다. 고등학생은 AP를 통해 고등학교 재학기간 동안 대학 수준의 학업을 경험하고, 학점을 얻을 수 있는 기회가 제공된다.
AMC 10은 미국 수학 협회가 주관하는 수학 대회이며, 미국기준 10학년 이하의 학생을 대상으로 한다. 고등학교 교육 과정 중 10학년까지 수학문제를 다루며, 미국에서 국제 수학 올림피아드 (IMO)에 참가하는 팀을 선발하는 일련의 시험 중 첫번째 시험이다.
AMC 12도 마찬가지로 미국 수학 협회가 주관하는 수학 대회로 12학년 이하 학생들을 대상으로 하며, 고등학교 전체 교육 과정을 다루지만, 미적분학은 제외된다. AMC 12는 AMC 10과 함께 국제 수학 올림피아드 (IMO) 참가 팀을 선발하기 위한 시험 중 하나이다.
GPT-4는 다양한 시험에서 이전 GPT-3.5보다 전반적으로 높은 성능을 보였다. 법률, 대학 입학 시험, 과학 시험 등에서 특히 뛰어난 결과를 보였지만 코딩 능력에 대한 시험에서는 상대적으로 낮은 성능을 보였다.
특히 미국 변호사 시험(Uniform Bar Exam)에서 상위 10% 점수를 얻어 GPT-3.5보다 훨씬 나아졌고, LSAT과 SAT 같은 대학 입학 시험에서도 상위 20% 이상 점수를 기록했다. 대학원 입학 시험인 GRE에서 수리영역(Quantitative)과 언어영역(Verbal) 부분에서 상위를 차지했고, 과학 관련 시험인 USABO와 USNCO에서도 높은 백분위를 기록했다. 의학 지식을 평가하는 자가 평가 프로그램(Medical Knowledge Self-Assessment Program, MK-SAP)에서는 75% 점수를 얻었다.
코딩 능력을 평가하는 코드포스(Codeforces)와 리트 코드(Leetcode)에서 상대적으로 낮은 점수를 보였지만, 대부분의 AP 시험에서 상위 20% 이상의 높은 점수를 얻었고 소믈리에 관련 시험에서도 이론 지식 부분에서 77% ~ 92% 사이 점수를 얻었다. (OpenAI, 2023)
| GPT-4 성능 | ||
| OpenAI GPT-4 Technical Report | ||
| gpt_4 | gpt_3_5 | |
|---|---|---|
| 법 | ||
| Uniform Bar Exam (MBE+MEE+MPT) | 298 / 400 (~90th) | 213 / 400 (~10th) |
| LSAT | 163 (~88th) | 149 (~40th) |
| 수능 | ||
| SAT Evidence-Based Reading & Writing | 710 / 800 (~93rd) | 670 / 800 (~87th) |
| SAT Math | 700 / 800 (~89th) | 590 / 800 (~70th) |
| 대학원 | ||
| Graduate Record Examination (GRE) Quantitative | 163 / 170 (~80th) | 147 / 170 (~25th) |
| Graduate Record Examination (GRE) Verbal | 169 / 170 (~99th) | 154 / 170 (~63rd) |
| Graduate Record Examination (GRE) Writing | 4 / 6 (~54th) | 4 / 6 (~54th) |
| 고등 경진대회 | ||
| USABO Semifinal Exam 2020 | 87 / 150 (99th - 100th) | 43 / 150 (31st - 33rd) |
| USNCO Local Section Exam 2022 | 36 / 60 | 24 / 60 |
| 헬스케어 | ||
| Medical Knowledge Self-Assessment Program | 75 % | 53 % |
| 코딩 | ||
| Codeforces Rating | 392 (below 5th) | 260 (below 5th) |
| Leetcode (easy) | 31 / 41 | 12 / 41 |
| Leetcode (medium) | 21 / 80 | 8 / 80 |
| Leetcode (hard) | 3 / 45 | 0 / 45 |
| AP 시험 | ||
| AP Art History | 5 (86th - 100th) | 5 (86th - 100th) |
| AP Biology | 5 (85th - 100th) | 4 (62nd - 85th) |
| AP Calculus BC | 4 (43rd - 59th) | 1 (0th - 7th) |
| AP Chemistry | 4 (71st - 88th) | 2 (22nd - 46th) |
| AP English Language and Composition | 2 (14th - 44th) | 2 (14th - 44th) |
| AP English Literature and Composition | 2 (8th - 22nd) | 2 (8th - 22nd) |
| AP Environmental Science | 5 (91st - 100th) | 5 (91st - 100th) |
| AP Macroeconomics | 5 (84th - 100th) | 2 (33rd - 48th) |
| AP Microeconomics | 5 (82nd - 100th) | 4 (60th - 82nd) |
| AP Physics 2 | 4 (66th - 84th) | 3 (30th - 66th) |
| AP Psychology | 5 (83rd - 100th) | 5 (83rd - 100th) |
| AP Statistics | 5 (85th - 100th) | 3 (40th - 63rd) |
| AP US Government | 5 (88th - 100th) | 4 (77th - 88th) |
| AP US History | 5 (89th - 100th) | 4 (74th - 89th) |
| AP World History | 4 (65th - 87th) | 4 (65th - 87th) |
| 수학시험 | ||
| AMC 103 | 30 / 150 (6th - 12th) | 36 / 150 (10th - 19th) |
| AMC 123 | 60 / 150 (45th - 66th) | 30 / 150 (4th - 8th) |
| 소믈리에 | ||
| Introductory Sommelier (theory knowledge) | 92 % | 80 % |
| Certified Sommelier (theory knowledge) | 86 % | 58 % |
| Advanced Sommelier (theory knowledge) | 77 % | 46 % |
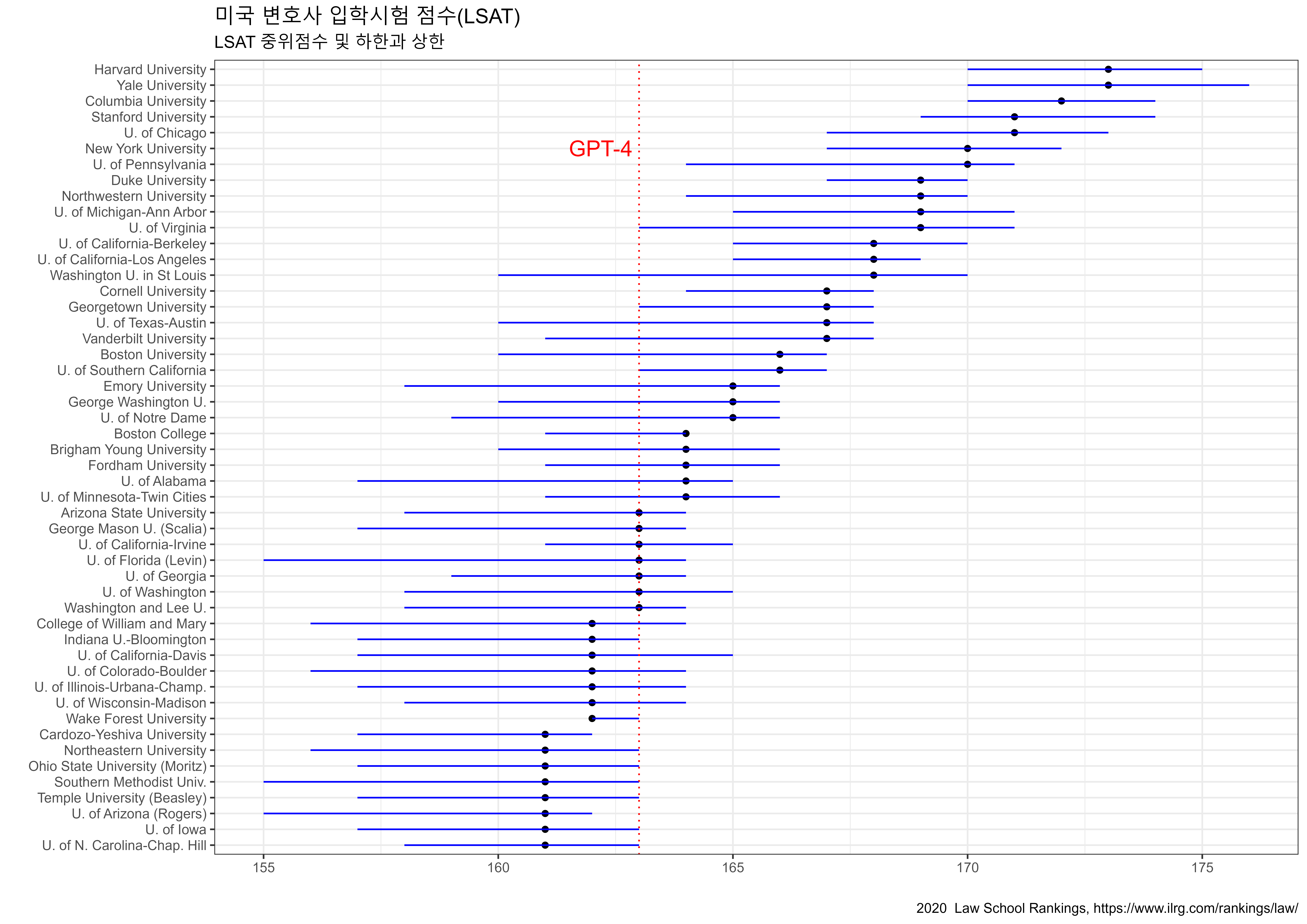
24.4.2 로스쿨 입학시험
GPT-4 LSAT(미국 로스쿨 입학 시험) 성적은 163으로, 대략 88번째 백분위에 해당되어 미국 로스쿨 대학별 입학점수1와 비교하면, 상위 10개 대학을 제외하고는 대부분의 로스쿨에 입학하는 데 큰 문제가 없을 것으로 보이기 때문에 GPT-4가 로스쿨 입학 시험을 잘 풀고 있다는 반증이다.
반면에, GPT-3.5 LSAT 성적은 149로, 대략 40번째 백분위에 해당하여 GPT-4와 비교하면 상대적으로 낮아 대부분의 미국 로스쿨에 입학하기에는 충분한 실력을 갖췄다고 보기 어렵다.
Uniform Bar Exam(미국 변호사 자격증 시험)의 경우, GPT-4는 298/400으로 약 90번째 백분위 성적을 보이고 있어 변호사 자격증을 얻기 위한 충분한 실력을 보여주고 있지만, GPT-3.5는 213/400으로 GPT-4에 훨씬 미치지 못하고 있다.
24.4.3 GPT-4 가격
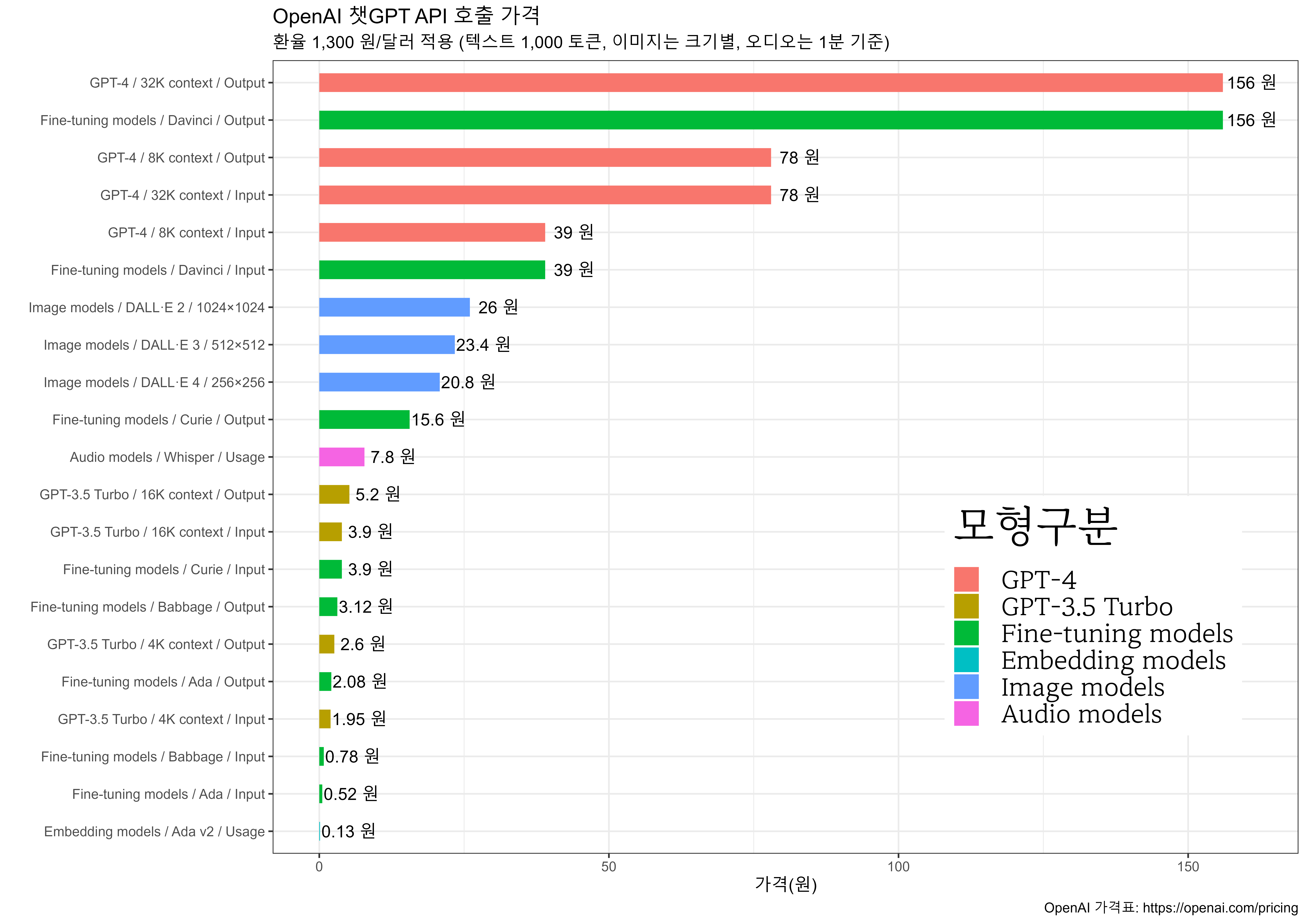
2023년 7월 기준으로 OpenAI API의 가격을 원화(1,300원)로 환산해 보면 여러 특징을 파악할 수 있다. GPT-4는 8K와 32K 컨텍스트(context)에서 1K 토큰당 각각 39원과 78원의 가격을 가지며, 이는 높은 성능과 대용량 처리 능력을 반영한 고가의 언어 모델이다. 반면에 GPT-3.5 터보는 4K와 16K 컨텍스트에서 1K 토큰당 3.9원과 5.2원의 비교적 저렴한 가격을 가지고 있으며, 이는 중간 수준의 성능을 가성비 좋게 제공한다.
세부 튜닝 모형(Fine-tuning models)에는 Ada, Babbage, Curie, Davinci 등이 있으며, 이들은 특정 작업에 최적화되어 성능별로 다양한 가격대를 보인다. 특히 텍스트 임베딩에 특화된 Ada v2 모형은 1K 토큰당 0.13원으로 매우 저렴한 가격으로 제공된다.
이미지 모형 DALL·E 시리즈는 이미지 크기에 따라 20.8원에서 26원 사이의 가격을 가지며, 텍스트 프롬프트에 따른 이미지 생성 작업에 사용된다. 오디오 모형 위스퍼(Whisper)는 분당 7.8원의 가격을 가지고 있으며, 다양한 언어 음성 오디오 처리 작업에 특화되어 있다.
24.5 가자 프롬프트 공학
기계학습과 자연어 처리 분야에서는 시간이 지남에 따라 다양한 공학 기법이 등장하고 발전해왔다. 이러한 공학 기법들은 대체로 피처 공학, 아키텍처 공학, 목적 공학, 그리고 프롬프트 공학으로 구분할 수 있다. 각 기법은 특정 시기에 주목받았으며, 그에 따라 다양한 모델과 알고리즘이 개발되었다. 이러한 공학 기법들의 진화 과정을 살펴보면, 기계학습과 자연어 처리가 어떻게 발전해왔는지 이해할 수 있다.
첫 번째로, 피처 공학의 시대는 대략 2015년까지 이어졌으며, 이 기간 동안 비신경망 지도학습이 주로 사용되었다. 이 단계에서는 수작업으로 특징(Feature)을 추출하고, 그 특징을 기반으로 SVM(Support Vector Machine)이나 CRF(Conditional Random Fields) 같은 비신경망 기계학습 모델을 학습시켰다. 이 방법은 당시에는 효과적이었지만, 수작업으로 특징을 추출하는 과정이 복잡하고 시간이 많이 소요되었다.
두 번째로, 2013년부터 2018년까지는 아키텍처 공학이 주목받았다. 이 시기에는 신경망 지도학습이 대두되면서, 수작업으로 특징을 추출할 필요가 줄었다. 대신, 신경망 아키텍처를 설계하고 수정하는 작업이 중요해졌다. 예를 들어, 텍스트 분류 작업에는 CNN(Convolutional Neural Networks)이 주로 사용되었다. 이 단계에서는 아키텍처의 중요성이 강조되었으며, 사전학습된 언어 모델이나 임베딩 같은 얕은 특징도 사용되기 시작했다.
마지막으로, 2017년부터 현재까지는 목적 공학과 프롬프트 공학이 주를 이루고 있다. 사전학습된 언어 모델을 사용하여 초기 모델을 설정하고, 목적함수를 엔지니어링하는 것이 이 단계의 특징이다. BERT와 같은 모델이 미세조정을 통해 다양한 작업에 적용되고 있다. 또한, 2019년부터는 프롬프트 공학이 두각을 나타내고 있으며, GPT-3와 같은 모델은 프롬프트를 통해 다양한 NLP 작업을 수행할 수 있다. 이 단계에서는 언어 모델에 대한 의존도가 높아져, 아키텍처나 특징 추출에 대한 부담이 줄어들었다. (Amatriain, 2023)
graph LR;
%% Styling
style A fill:#f9d79c,stroke:#f39c12,stroke-width:2px;
style B fill:#aed6f1,stroke:#3498db,stroke-width:2px;
style C fill:#d5f5e3,stroke:#27ae60,stroke-width:2px;
style D fill:#f5b7b1,stroke:#e74c3c,stroke-width:2px;
%% Subgraph for Feature Engineering
subgraph A["피처(Feature) 공학"]
A1["패러다임: 비신경망 지도학습 <br>전성기: ~2015 <br>특징: 수작업 Feature, 비신경망 사용 <br>대표작: SVM, CRF"]
end
%% Subgraph for Architecture Engineering
subgraph B["아키텍처 공학"]
B1["패러다임: 신경망 지도학습 <br>전성기: 2013~2018 <br>특징: 신경망 의존, 네트워크 수정 필요 <br>대표작: 텍스트 분류에 CNN"]
end
%% Subgraph for Objective Engineering
subgraph C["목적(Objective) 공학"]
C1["패러다임: 사전학습, 미세조정 <br>전성기: 2017~현재 <br>특징: 사전학습 LLM 사용, 목적함수 공학 필요 <br>대표작: BERT → Fine Tuning"]
end
%% Subgraph for Prompt Engineering
subgraph D["프롬프트 공학"]
D1["패러다임: 사전학습, 프롬프트, 예측 <br>전성기: 2019~현재 <br>특징: LLM 전적 의존, 프롬프트 공학 필요 <br>대표작: GPT3"]
end
%% Connections
A --> B
B --> C
C --> D
Amatriain, X. (Xavi). (2023). Prompt Engineering 101 - Introduction and resources. Linkedin. https://www.linkedin.com/pulse/prompt-engineering-101-introduction-resources-amatriain/
Chiang, T. (2023). ChatGPT Is a Blurry JPEG of the Web - OpenAI’s chatbot offers paraphrases, whereas Google offers quotes. Which do we prefer? The New Yorker. https://www.newyorker.com/tech/annals-of-technology/chatgpt-is-a-blurry-jpeg-of-the-web
McGrath, R. (2013). The Pace of Technology Adoption is Speeding Up. Harvard Business Review. https://hbr.org/2013/11/the-pace-of-technology-adoption-is-speeding-up
OpenAI. (2023). GPT-4 Technical Report. https://arxiv.org/abs/2303.08774
Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., Du, Y., Yang, C., Chen, Y., Chen, Z., Jiang, J., Ren, R., Li, Y., Tang, X., Liu, Z., … Wen, J.-R. (2023). A Survey of Large Language Models. https://arxiv.org/abs/2303.18223