설치 및 환경설정
이 장에서는 AI-SQL 학습에 필요한 핵심 도구들을 설치하고 설정하는 방법을 다룬다. 소프트웨어 카펜트리의 조사 데이터베이스(survey.db)는 실제 남극 탐사 데이터를 바탕으로 한 학습용 데이터셋이다. SQLite3는 이 데이터를 저장하고 조작하는 경량 데이터베이스 엔진으로 데이터베이스 관리자 역할을 수행한다. SQLite용 DB 브라우저는 데이터베이스를 시각적으로 탐색하고 쿼리를 실행할 수 있는 그래픽 도구다.

SQLite3 특징과 장점
SQLite3는 가볍고 독립적인 데이터베이스 엔진이다. 서버를 필요로 하지 않는 서버리스(serverless) 아키텍처로 설계되어 전체 데이터베이스를 단일 파일에 저장한다. 이러한 특성으로 인해 설정이 간단하고 관리가 쉬우며 플랫폼 간 이동성이 뛰어나다.
SQLite3의 핵심 장점들을 살펴보면, 먼저 경량성과 효율성 측면에서 매우 작은 메모리와 디스크 공간을 사용하면서도 빠른 처리 속도를 제공한다. 자체 포함성도 뛰어나 별도 서버 프로세스 없이 실행되며 설치나 특별한 지원이 거의 필요하지 않다. 설정의 단순함은 SQLite3의 가장 큰 매력 중 하나로, 복잡한 설정이나 관리 작업 없이 즉시 사용할 수 있다. 플랫폼 독립성을 통해 다양한 운영체제에서 호환되며 데이터베이스 파일을 시스템 간에 자유롭게 이동할 수 있다. 마지막으로 신뢰성과 내구성 면에서 ACID(Atomicity, Consistency, Isolation, Durability) 트랜잭션 속성을 완벽히 지원하여 데이터 무결성을 보장한다.
SQLite3는 임베디드 시스템, 모바일 애플리케이션, 소규모 웹 프로젝트 등에서 널리 사용되지만, 대규모 고부하 멀티유저 환경에는 적합하지 않다는 한계가 있다.
SQLite 설치
명령라인(command-line)을 통해 디렉토리를 이동하고 명령문을 실행하는 기본 지식이 필요하다. 명령라인, 콘솔, 쉘 등이 낯설다면 챗GPT 유닉스 쉘(Unix Shell) 학습 자료를 먼저 확인하기 바란다.
SQLite3 설치 방법은 운영체제별로 다르지만 모두 간단하다. 각 환경에 맞는 설치 방법을 아래에서 확인할 수 있다.
Windows 환경에서는 다음 단계를 따른다:
- 다운로드: SQLite 공식 웹사이트에서 Windows용 바이너리 파일을 다운로드한다.
- 압축 해제: 다운로드한 ZIP 파일을 적절한 위치에 압축 해제한다.
- PATH 설정: 압축 해제한 폴더 경로를 시스템 환경 변수 PATH에 추가하여 명령 프롬프트에서 어디서나 SQLite를 실행할 수 있도록 설정한다.
macOS에는 기본적으로 SQLite3가 설치되어 있지만, 최신 버전을 사용하려면 다음과 같이 설치한다:
Homebrew 설치 (없는 경우): 터미널에서 아래 명령을 실행한다.
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"SQLite 설치: 터미널에서 다음 명령을 실행한다.
brew install sqlite3
대부분의 Linux 배포판에는 SQLite3가 이미 설치되어 있다. 설치가 필요하거나 최신 버전으로 업데이트하려면 패키지 관리자를 사용한다:
Ubuntu/Debian 계열:
sudo apt-get install sqlite3Fedora/CentOS 계열:
sudo yum install sqlite # 또는 최신 버전에서는 sudo dnf install sqlite
모든 운영체제에서 설치가 완료되면 다음 명령으로 버전을 확인할 수 있다:
$ sqlite3 --version
3.40.1 2022-12-28 14:03:47 df5c253c0b3dd24916e4ec7cf77d3db5294cc9fd45ae7b9c5e82ad8197f38a24Windows에서 SQLite를 다운로드하고 압축을 해제하면 다음과 같은 파일들을 볼 수 있다. 복잡한 설치 과정을 기대했다면 의외로 간단할 것이다. 이러한 단순함이야말로 SQLite의 핵심 장점이다.
$ ls
gen-survey-database.sql sqlite3.exe survey.db
sqldiff.exe sqlite3_analyzer.exe각 파일의 역할은 다음과 같다.
- sqlite3.exe: SQLite 실행파일
- gen-survey-database.sql:
survey.db데이터베이스를 생성하는 SQL 스크립트
- survey.db: 생성된 샘플 데이터베이스 파일
샘플 데이터베이스 설정
SQLite3 설치가 완료되었다면 이제 학습용 샘플 데이터베이스를 설정해야 한다. 이 책에서는 남극 탐사대의 실제 측정 데이터를 바탕으로 한 survey.db 데이터베이스를 사용한다.
가장 간단한 방법은 소프트웨어 카펜트리 웹사이트에서 survey.db 파일을 직접 다운로드하는 것이다.
survey.db 다운로드
다운로드한 파일을 작업 디렉토리에 저장하면 바로 사용할 수 있다.
명령라인을 통해 직접 데이터베이스를 생성하려면 다음 단계를 따른다:
작업 디렉토리 생성:
mkdir ~/swc/sql cd ~/swc/sqlSQL 스크립트 다운로드:
# wget 사용 wget https://raw.githubusercontent.com/swcarpentry/bc/master/novice/sql/gen-survey-database.sql # 또는 curl 사용 curl -O https://raw.githubusercontent.com/swcarpentry/bc/master/novice/sql/gen-survey-database.sql데이터베이스 생성:
sqlite3 survey.db < gen-survey-database.sql
이 명령은 SQL 스크립트를 실행하여 테이블 구조를 생성하고 샘플 데이터를 삽입한다.
데이터베이스 연결 확인
설정이 완료되었는지 확인하기 위해 데이터베이스에 연결해보자.
1. SQLite 실행
$ sqlite3 survey.db성공적으로 연결되면 SQLite 프롬프트가 나타난다:
SQLite version 3.40.1 2022-12-28 14:03:47
Enter ".help" for usage hints.
sqlite>2. 데이터베이스 확인
sqlite> .databases
seq name file
--- --------------- ----------------------------------------------------------
0 main ~/swc/sql/survey.db3. 테이블 목록 확인
sqlite> .tables
Person Site Survey Visited네 개의 테이블(Person, Site, Survey, Visited)이 모두 표시되면 설치가 정상적으로 완료된 것이다.
데이터베이스 GUI 도구
SQL을 처음 접하는 사용자나 명령라인 작업이 부담스러운 경우에는 시각적 인터페이스를 제공하는 GUI 도구가 큰 도움이 된다. 마우스 클릭만으로 테이블을 탐색하고, 쿼리 결과를 직관적으로 확인할 수 있어 학습 과정이 훨씬 수월해진다. 또한 복잡한 데이터베이스 구조를 시각화해 보여주기 때문에 데이터 간의 관계를 이해하는 데도 효과적이다. 다양한 도구들이 있지만, 사용자의 경험 수준과 작업 목적에 따라 최적의 선택이 달라진다.
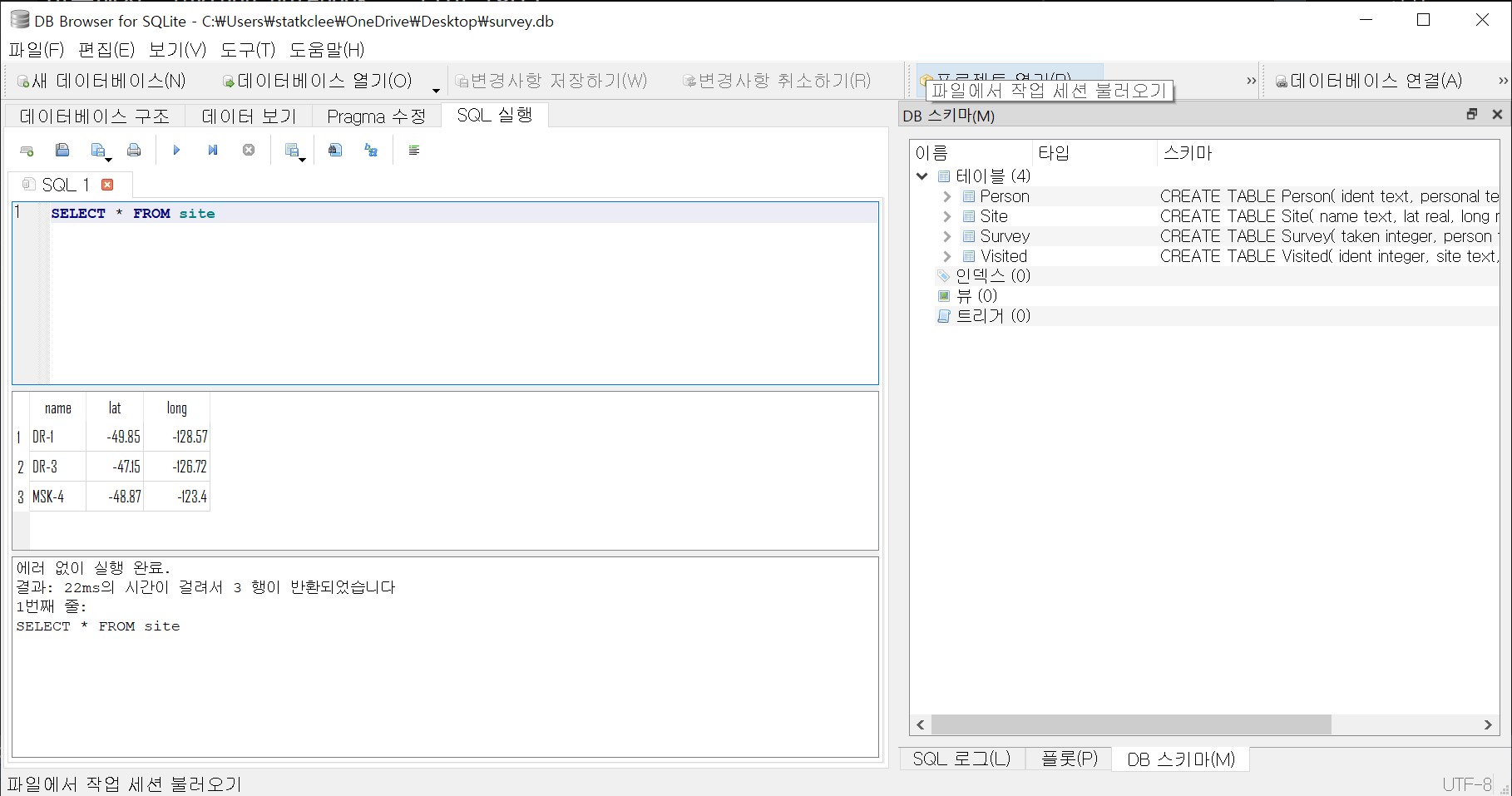
가장 간단하고 직관적인 SQLite 전용 도구로, SQL 초보자에게 이상적이다. 무료 오픈소스로 제공되며 간단한 인터페이스를 통해 초보자도 쉽게 접근할 수 있다. 특히 SQLite 엔진이 내장되어 있어 별도의 복잡한 설정 없이 바로 사용할 수 있는 것이 가장 큰 장점이다. Windows, macOS, Linux 등 모든 주요 운영체제를 지원하므로 어떤 환경에서든 동일한 경험을 제공한다.
설치는 DB Browser 공식사이트에서 운영체제에 맞는 설치파일을 다운로드하기만 하면 된다. 설치 완료 후 survey.db 파일을 열어 테이블 구조를 확인해보자.
데이터베이스 작업에 어느 정도 익숙해졌다면 DBeaver를 고려해볼 만하다. 이 도구는 SQLite뿐만 아니라 MySQL, PostgreSQL, Oracle 등 다양한 데이터베이스를 하나의 인터페이스에서 관리할 수 있는 범용 클라이언트다. 무료 커뮤니티 에디션임에도 불구하고 강력한 SQL 편집기를 제공하며, 문법 하이라이팅과 자동 완성 기능으로 쿼리 작성을 도와준다. 또한 ER 다이어그램 생성, 데이터 시각화, 쿼리 성능 분석 등 고급 기능들도 갖추고 있어 본격적인 데이터베이스 작업에 적합하다.
DBeaver 공식사이트에서 다운로드한 후, 첫 실행 시 SQLite 드라이버 설치를 제안받게 된다. 새 연결을 생성하여 SQLite를 선택하고 survey.db 파일을 지정하면 바로 사용할 수 있다.
맥 환경에서 작업한다면 TablePlus를 추천한다. 네이티브 macOS 앱으로 설계되어 뛰어난 사용자 경험을 제공하며, 특히 빠른 성능과 아름다운 인터페이스로 유명하다. 유료 도구지만 무료 버전도 제공하므로 개인 학습 목적으로는 충분히 활용할 수 있다. 다른 도구들에 비해 직관적인 디자인과 매끄러운 동작이 특징이다.
Homebrew가 설치되어 있다면 터미널에서 brew install --cask tableplus 명령으로 간편하게 설치할 수 있다.
개발자용: VS Code 확장
이미 Visual Studio Code를 주요 개발 도구로 사용하고 있다면, 별도의 데이터베이스 도구 없이도 충분히 작업할 수 있다. SQLite 확장을 설치하면 VS Code 내에서 직접 데이터베이스를 탐색하고 쿼리를 실행할 수 있다. SQL Tools 확장은 SQLite를 포함한 다양한 데이터베이스 연결을 지원하며, 쿼리 결과를 표 형태로 깔끔하게 표시해준다. CSV 파일을 자주 다룬다면 Rainbow CSV 확장도 함께 설치하는 것이 좋다. 이 확장은 CSV 파일의 각 열을 서로 다른 색상으로 구분해 표시하여 가독성을 크게 향상시켜준다.
통합 개발 환경에서 코드 작성과 데이터베이스 작업을 동시에 진행할 수 있어 개발 효율성이 높아진다. 특히 Python이나 R 같은 데이터 분석 코드를 작성하면서 동시에 데이터베이스를 확인해야 하는 경우에 매우 유용하다.
Python 환경 설정
데이터 분석과 AI-SQL 작업을 위한 Python 환경을 구축할 때는 두 가지 주요 설치 방법이 있다. 각각의 특징을 이해하고 자신의 상황에 맞는 방법을 선택하는 것이 중요하다.
아나콘다 vs 바닐라 Python
Python을 설치하는 방법은 크게 두 가지로 나뉜다. 바닐라 Python은 Python 공식 웹사이트에서 제공하는 순수한 Python 설치 방법이고, Anaconda는 데이터 사이언스에 특화된 Python 배포판이다. 두 방법 모두 장단점이 있어 초보자와 경험자가 선택할 수 있는 옵션이 다르다.
데이터 분석과 AI-SQL을 처음 시작하는 사용자에게는 Anaconda 설치를 강력히 추천한다. Anaconda는 데이터 사이언스에 필요한 대부분의 라이브러리가 미리 설치되어 있고, 패키지 관리가 훨씬 간편하다. 특히 Windows 환경에서 라이브러리 설치 시 발생할 수 있는 컴파일 오류를 피할 수 있어 학습에 집중할 수 있다.
Anaconda 설치는 매우 간단한 과정으로 진행된다. 먼저 anaconda.com에서 자신의 운영체제에 맞는 설치파일을 다운로드한다. 다운로드한 설치파일을 실행하면 설치 마법사가 시작되는데, 특별한 설정 변경 없이 기본 옵션을 그대로 사용하여 설치를 진행하면 된다. 설치가 완료되면 시작 메뉴에서 “Anaconda Navigator”를 찾아 실행하거나, 명령 프롬프트에서 “Anaconda Prompt”를 실행하여 설치가 제대로 되었는지 확인할 수 있다.
설치가 제대로 완료되었는지 검증하려면 다음 명령어들을 실행해보자. 이 명령어들은 각각 conda 패키지 관리자, Python 인터프리터, Jupyter 환경이 정상적으로 설치되어 있는지 버전 정보를 통해 확인해준다.
conda --version
python --version
jupyter --versionAnaconda를 선택했을 때 얻을 수 있는 가장 큰 장점은 복잡한 패키지 설치 과정을 건너뛸 수 있다는 것이다. Jupyter Notebook과 JupyterLab, 데이터 분석의 핵심 라이브러리인 pandas, 그래프 생성을 위한 matplotlib과 seaborn 등이 모두 자동으로 설치된다. 또한 conda라는 강력한 패키지 관리자가 라이브러리 간의 의존성과 충돌 문제를 자동으로 해결해주어, 초보자가 겪기 쉬운 환경 설정 문제를 대폭 줄여준다. 가상환경 관리 기능도 내장되어 있어 프로젝트별로 독립적인 Python 환경을 쉽게 구성할 수 있고, GUI 기반의 Anaconda Navigator를 통해 복잡한 명령어 없이도 패키지와 환경을 관리할 수 있다.
Python 개발 경험이 있거나 시스템을 세밀하게 제어하고 싶은 사용자는 바닐라 Python을 선택할 수 있다. 이 방법은 더 가볍고 필요한 패키지만 선별적으로 설치할 수 있다.
바닐라 Python 설치 과정은 Anaconda보다 단순하지만 몇 가지 중요한 주의사항이 있다. 먼저 python.org에서 자신의 운영체제에 맞는 최신 버전을 다운로드한다. 설치 과정에서 가장 중요한 것은 “Add Python to PATH” 옵션을 반드시 체크하는 것이다. 이 옵션을 선택하지 않으면 명령 프롬프트에서 Python을 인식하지 못해 이후 작업에 큰 불편을 겪게 된다. 설치가 완료되면 pip 패키지 관리자를 사용하여 필요한 라이브러리들을 개별적으로 설치해야 한다.
바닐라 Python을 선택했다면 AI-SQL 작업에 필요한 핵심 패키지들을 직접 설치해야 한다. Jupyter 환경을 구축하기 위해서는 pip install jupyter jupyterlab 명령어를 실행한다. 데이터 분석 작업을 위해서는 pandas, sqlalchemy, matplotlib, seaborn 등의 라이브러리가 필요하다. 여기서 주의할 점은 sqlite3의 경우 Python 표준 라이브러리에 포함되어 있어 별도로 설치할 필요가 없다는 것이다.
# Jupyter 환경 설치
pip install jupyter jupyterlab
# 데이터 분석 라이브러리
pip install pandas sqlalchemy matplotlib seaborn
# 참고: sqlite3는 Python 표준 라이브러리로 별도 설치 불필요바닐라 Python의 가장 큰 매력은 설치 용량이 가볍다는 것이다. Anaconda가 수 기가바이트의 용량을 차지하는 반면, 바닐라 Python은 훨씬 적은 공간만 사용한다. 또한 자신이 정말 필요한 패키지만 선별적으로 설치할 수 있어 시스템 리소스를 효율적으로 사용할 수 있다. 개발자에게 특히 유용한 점은 최신 패키지 버전에 빠르게 접근할 수 있다는 것이다. Anaconda는 안정성을 위해 검증된 버전만 제공하는 경우가 많지만, pip를 통해서는 최신 기능이 포함된 패키지를 바로 설치할 수 있다.
Jupyter 환경 실행
설치가 완료되면 Jupyter 환경을 실행하여 AI-SQL 작업을 시작할 수 있다. Jupyter는 코드 작성과 실행, 결과 확인을 한 번에 할 수 있는 통합 환경을 제공하며, 특히 데이터 분석과 AI-SQL 작업에서 그 진가를 발휘한다. 기존의 텍스트 에디터나 IDE와 달리 Jupyter는 코드 셀과 마크다운 셀을 자유롭게 조합하여 분석 과정과 결과를 체계적으로 문서화할 수 있다. 이는 AI와의 대화를 통해 SQL 쿼리를 생성하고 테스트하는 현대적인 데이터 분석 워크플로우에 완벽하게 맞는 환경이다.
Anaconda를 설치한 사용자는 두 가지 방법으로 Jupyter 환경을 실행할 수 있다. 가장 쉬운 방법은 Anaconda Navigator를 실행한 후 JupyterLab 아이콘을 클릭하는 것이다. 이는 GUI 환경에서 마우스 클릭만으로 실행할 수 있어 초보자에게 특히 편리하다. 명령어에 익숙한 사용자라면 Anaconda Prompt를 열고 jupyter lab 명령어를 입력하는 방법도 있다. 이 방법은 특정 디렉토리에서 작업을 시작하고 싶을 때 유용하다.
# Anaconda Navigator에서 JupyterLab 클릭하거나
# Anaconda Prompt에서 실행
jupyter lab바닐라 Python을 설치한 사용자는 운영체제의 기본 명령 프롬프트나 터미널에서 직접 실행한다. jupyter lab 명령어를 실행하면 최신 인터페이스인 JupyterLab이 실행되고, jupyter notebook 명령어를 실행하면 전통적인 노트북 환경이 시작된다. JupyterLab은 탭 기능, 파일 브라우저, 터미널 등 통합 개발 환경의 기능을 제공하므로 대부분의 경우 JupyterLab 사용을 권장한다.
# 명령 프롬프트나 터미널에서 실행
jupyter lab
# 또는 기본 Notebook 환경
jupyter notebookPython 환경이 올바르게 구성되었는지 확인하는 것은 이후 AI-SQL 작업의 성공을 보장하는 중요한 단계다. 새로운 Jupyter 노트북을 생성한 후 다음 코드를 실행하여 핵심 라이브러리들이 정상적으로 작동하는지 검증해보자. 이 코드는 데이터 조작을 위한 pandas, 데이터베이스 연결을 위한 sqlite3, 그래프 생성을 위한 matplotlib이 모두 정상적으로 import되는지 확인한다.
import pandas as pd
import sqlite3
import matplotlib.pyplot as plt
print("AI-SQL 환경 준비 완료!")설치 과정에서 문제가 발생했다면 몇 가지 일반적인 해결방법을 시도해볼 수 있다. PATH 관련 오류가 발생한다면 이는 시스템이 Python이나 Jupyter의 위치를 찾지 못하는 것이므로, 컴퓨터를 재시작한 후 다시 시도해보자. 권한 관련 오류가 나타날 때는 Windows에서는 명령 프롬프트를, macOS나 Linux에서는 터미널을 관리자 권한으로 실행해야 한다. Jupyter 실행 시 포트 충돌 오류가 발생한다면 jupyter lab --port=8889와 같이 다른 포트 번호를 지정하여 실행할 수 있다. 패키지 설치 과정에서 충돌이 발생했다면 Anaconda 사용자는 conda clean --all 명령어로 캐시를 정리하거나 새로운 가상환경을 생성하여 깨끗한 상태에서 다시 시작하는 것이 효과적이다.
데이터베이스 연결 테스트
Python 환경 구축이 완료되면 다음 단계는 SQLite 데이터베이스와의 연결을 확인하는 것이다. 이 테스트는 단순해 보이지만 AI-SQL 작업의 핵심 기반이 되는 매우 중요한 과정이다. SQLite는 파일 기반 데이터베이스로 별도의 서버 설치가 필요 없어 학습 목적에 이상적이며, Python의 sqlite3 모듈을 통해 쉽게 연결할 수 있다. 연결 테스트를 통해 데이터베이스 생성, 테이블 작성, 데이터 삽입과 조회 등의 기본 작업이 정상적으로 수행되는지 확인할 수 있고, 이는 곧 AI가 생성한 SQL 쿼리를 실제로 실행하고 결과를 확인할 준비가 되었음을 의미한다.
AI 도구 설정
AI-SQL 작업을 위해서는 대화형 AI 도구에 접근할 수 있는 환경을 구축해야 한다. 현재 가장 널리 사용되는 도구는 OpenAI의 ChatGPT와 Anthropic의 Claude이며, 두 도구 모두 웹 브라우저를 통해 쉽게 접근할 수 있다. 별도의 복잡한 설치 과정 없이 계정만 생성하면 즉시 사용할 수 있어 초보자도 부담 없이 시작할 수 있다.
ChatGPT 접속 및 설정
ChatGPT는 chat.openai.com에서 접속할 수 있다. Google, Microsoft, 또는 Apple 계정을 사용하여 간편하게 가입할 수 있으며, 이메일 주소로도 새 계정을 만들 수 있다. 무료 계정으로도 기본적인 SQL 쿼리 생성과 데이터베이스 분석에 충분한 기능을 제공한다. 유료 계정(ChatGPT Plus)을 선택하면 더 빠른 응답 속도와 최신 모델에 접근할 수 있지만, 학습 목적이라면 무료 계정으로도 충분하다.
ChatGPT가 정상적으로 작동하는지 확인하려면 간단한 테스트 프롬프트를 입력해보자:
다음 SQLite 테이블에서 모든 연구자의 이름을 조회하는 SQL 쿼리를 작성해줘:
Person(ident, personal, family)AI가 올바른 SELECT 문을 생성하면 설정이 완료된 것이다. 응답이 부정확하거나 오류가 발생한다면 브라우저를 새로고침하거나 다른 브라우저에서 시도해보자.
Claude 접속 및 설정
Claude는 claude.ai에서 접속할 수 있다. 이메일 주소나 Google 계정으로 가입이 가능하며, 전화번호 인증 과정을 거쳐야 한다. Claude는 더 신중하고 정확한 응답을 제공하는 경향이 있어 데이터베이스 관련 작업에서 높은 신뢰성을 보인다. 무료 계정으로도 상당한 수준의 대화가 가능하며, Claude Pro 계정은 더 많은 메시지와 우선순위 접근을 제공한다.
브라우저 환경 최적화
AI 도구들은 웹 브라우저에서 실행되므로 안정적인 인터넷 연결과 최신 브라우저 환경이 필요하다. Chrome, Firefox, Safari, Edge 등 주요 브라우저에서 모두 정상적으로 작동하지만, 때로는 브라우저별로 약간의 인터페이스 차이가 있을 수 있다. 긴 대화를 진행할 때는 브라우저가 갑자기 종료되어도 대화 내용이 보존되는지 확인해보는 것이 좋다.
데이터 분석 작업 시에는 여러 도구를 동시에 사용하는 것이 효율적이다. 브라우저에서 다음과 같이 탭을 구성하면 작업 흐름이 원활해진다:
- 탭 1: Jupyter Lab (Python/SQL 코드 실행)
- 탭 2: ChatGPT 또는 Claude (쿼리 생성)
- 탭 3: 데이터베이스 도구 (DBeaver 등, 필요시)
- 탭 4: 참고 문서나 스키마 정보
이렇게 구성하면 AI가 생성한 쿼리를 바로 Jupyter에서 테스트하고, 결과를 확인한 후 다시 AI에게 개선을 요청하는 순환적 작업이 가능하다.
환경 통합 테스트
모든 도구가 설치되었다면 전체 워크플로우가 원활하게 작동하는지 종합적으로 테스트해야 한다. AI-SQL 작업의 이상적인 흐름은 사용자가 자연어로 질문하면 AI가 SQL 쿼리를 생성하고, 이를 Jupyter에서 실행하여 결과를 확인한 후 필요시 개선하는 순환적 과정이다. 다음 다이어그램은 이러한 통합 환경에서의 작업 흐름을 보여준다.

위 다이어그램에서 보는 것처럼, 연구자는 중앙에서 전체 프로세스를 관리하며 세 가지 핵심 도구가 유기적으로 연결되어 작동한다. Jupyter Lab에서 새로운 노트북을 생성하고, AI 도구에서 간단한 SQLite 쿼리를 생성받은 후, 이를 Python에서 실행해보는 과정을 거쳐보자.
다음 단계를 순서대로 실행하여 AI-SQL 환경이 완전히 구축되었는지 확인하자:
Jupyter Lab 실행:
jupyter lab명령어로 환경 시작새 노트북 생성: Python 3 커널로 새 노트북 작성
기본 라이브러리 확인:
import sqlite3 import pandas as pd print("라이브러리 준비 완료")AI에게 쿼리 요청: “sample.db에 Person 테이블을 생성하는 SQL을 작성해줘”
생성된 쿼리 실행: AI 응답을 복사하여 Jupyter에서 실행
결과 확인: 오류 없이 테이블이 생성되는지 검증
모든 단계가 성공적으로 완료되면 AI-SQL 작업 환경이 완전히 준비된 것이다.
문제해결 및 대안
설정 과정에서 문제가 발생할 수 있는 주요 상황들과 해결방법을 정리해두면 도움이 된다. AI 서비스에 접속이 안 될 때는 네트워크 연결 상태를 먼저 확인하고, 서비스 장애가 아닌지 공식 상태 페이지를 확인해보자. 계정 생성이나 로그인에 문제가 있다면 다른 이메일 주소나 인증 방법을 시도해볼 수 있다. 브라우저에서 쿠키나 캐시 문제로 오작동할 때는 시크릿 모드나 다른 브라우저에서 접속을 시도해보는 것이 효과적이다.