library(RSQLite)
music_db <- "data/music.sqlite"
conn <- dbConnect(drv = SQLite(), dbname= music_db)
dbSendQuery(conn, "CREATE TABLE Tracks (title TEXT, plays INTEGER)")
dbSendQuery(conn, "INSERT INTO Tracks (title, plays) VALUES ( ?, ? )", c('Thunderstruck', 20))
dbSendQuery(conn, "INSERT INTO Tracks (title, plays) VALUES ( ?, ? )", c('My Way', 15))
dbDisconnect(conn)2 들어가며
엑셀로 대표되는 스프레드시트를 사용하는 것은 많은 사람들에게 익숙한 경험이다. 엑셀은 데이터를 쉽게 조작하고 분석할 수 있는 기본적인 도구로 활용되지만, 데이터셋이 복잡해지면서 한계에 부딪힌다. 이때 스프레드시트 한계를 넘어서 다양한 선택지를 살펴보게 되고, 첫번째 선택지로 데이터베이스가 주저없이 선택된다.
간단한 수치 연산에는 스프레드시트로 충분할 수 있지만, 복잡하고 큰 데이터셋을 빠르고 효율적으로 처리하려면 데이터베이스가 필요하다. SQL(Structured Query Language)은 데이터베이스를 관리하고 조작하는 데 있어 중요한 역할을 한다. 데이터베이스가 어떻게 작동하는지 이해하는 것은 단순한 데이터 조작 능력을 넘어서, 현재 사용되는 다양한 시스템들이 왜 이와 같은 방식으로 작동하는지, 왜 데이터를 특정한 방식으로 구조화하는지에 대한 깊은 통찰도 제공한다.
이 책은 데이터베이스의 기본 원리와 SQL(Date 1989)의 사용 방법으로 시작하지만, 데이터베이스 프로그래밍과 데이터 과학자가 알아야 할 다양한 데이터베이스 시스템을 아우르며, 챗GPT로 상징되는 생성형 AI SQL LLM에 대해서도 다룬다. 데이터베이스 기본 개념을 이해하고 SQL을 사용하는 방법을 익히면, 데이터베이스가 활용되는 다양한 시스템을 쉽게 이해할 수 있다. 이러한 시스템들을 이해함으로써, 데이터베이스 기본 개념과 SQL에 대해 더 깊이 이해할 수 있다. 추가적으로, 소프트웨어 카펜트리 콘텐츠(Andrea 기타 2017)에 기반한 “챗GPT 유닉스 쉘”에 이어 “챗GPT SQL”(이광춘 와/과 신종화 2023)을 출판함으로써, 2023년에 큰 인기를 끈 챗GPT를 SQL과 어떻게 접목되는지 살펴보는 것도 큰 의미가 있다고 할 수 있다.
이 책에서 제시하는 데이터베이스와 SQL의 중요성, 기본 개념, 언어, 다양한 시스템, 활용 사례, 그리고 최근 주목받는 챗GPT와 같은 생성형 AI에 대한 내용은 방대하다. 각자 책을 읽는 나만의 방식이 있겠지만, 책을 효과적으로 읽는 방법을 제시하면 다음과 같다.
SQLite3 설치 및 실습: SQLite3를 다운로드하고 설치한 후, 소프트웨어 카펜트리의 SQL 교과목을 따라가며 실습을 시작한다. 이는 데이터베이스 기본 개념을 실제로 적용해보는 첫걸음이다.
데이터베이스 기본개념 공부: 책에 정리된 데이터베이스 기본 개념을 참고하며 학습을 병행한다. 이 과정에서 SQL 실습을 병행하여 이론과 실습을 연결시킨다.
현장 데이터베이스 시스템 실습: 시카고 범죄 데이터를 사용해 분석형 데이터베이스 DuckDB, DVD 렌털 데이터를 활용해 오픈소스 PostgreSQL을 설치하고 실습함으로써 실제 현장에서 사용되는 데이터베이스 시스템 작동 원리를 실습을 통해 이해한다.
생성형 AI 챗GPT와의 연계: 마지막으로, OpenAI API와 오픈소스 SQL LLM을 활용하여 생성형 AI 챗GPT를 경험함으로써, 데이터베이스 기술과 AI의 결합을 통해 현재 진행되고 있는 기술의 미래를 탐색한다.
데이터베이스와 SQL 맛보기
데이터베이스와 SQL를 처음 접하는 분들께 도움이 되도록, 저자가 번역하여 출판한 “정보교육을 위한 파이썬(Python for Informatics: Exploring Information)” 책(Severance 2015)에서 관련 내용을 다시 정리한 것으로 최근 추세인 시작과 끝을 짧게 책 서두에 정리하여 책의 구성을 미리 파악할 수 있도록 준비했다.
2.1 맛보기
데이터베이스(database)는 데이터를 저장하기 위한 목적으로 조직된 파일이다. 대부분의 데이터베이스는 키(key)와 값(value)를 매핑한다는 의미에서 딕셔너리처럼 조직되었다. 가장 큰 차이점은 데이터베이스는 디스크(혹은 다른 영구 저장소)에 위치하고 있어서, 프로그램 종료 후에도 정보가 계속 저장된다. 데이터베이스가 영구 저장소에 저장되어서, 컴퓨터 주기억장치(memory) 크기에 제한받는 딕셔너리보다 훨씬 더 많은 정보를 저장할 수 있다.
딕셔너리처럼, 데이터베이스 소프트웨어는 엄청난 양의 데이터 조차도 매우 빠르게 삽입하고 접근하도록 설계되었다. 컴퓨터가 특정 항목으로 빠르게 찾아갈 수 있도록 데이터베이스에 인덱스(indexes)를 추가한다. 데이터베이스 소프트웨어는 인덱스를 구축하여 성능을 보장한다.
다양한 목적에 맞춰 서로 다른 많은 데이터베이스 시스템이 개발되어 사용되고 있다. Oracle, MySQL, Microsoft SQL Server, PostgreSQL, SQLite이 여기에 포함된다. 이 책에서는 SQLite를 집중해서 살펴보고 이후 개념을 다양하게 확장시킬 것이다.
SQLite는 가장 일반적으로 사용되는 데이터베이스 중 하나로 파이썬을 비롯한 다양한 프로그래밍 언어에 이미 내장되어 있어, 개발자들이 SQLite를 별도로 설치하거나 구성할 필요 없이 쉽게 데이터베이스 기능을 즉시 사용할 수 있다.
SQLite는 응용 프로그램 내부에 내장(embedded)되도록 설계되었다는 특징을 갖추고 있어 SQLite가 독립적인 서버가 아닌, 응용 프로그램의 일부로 통합되어 작동한다는 것을 의미한다. 내장형 데이터베이스 특성 때문에, 응용 프로그램은 SQLite를 이용해 쉽게 데이터 저장, 접근 및 관리를 할 수 있다.
SQLite의 이러한 특성으로 인해 특히 모바일 애플리케이션, 데스크톱 애플리케이션, 웹 브라우저 플러그인 등에서 유용하게 활용된다. SQLite는 가벼운 구조를 가지고 있으며, 복잡한 설정이나 관리가 필요하지 않아 소규모 프로젝트나 독립적인 애플리케이션에 적합하다.
2.1.1 데이터베이스 개념
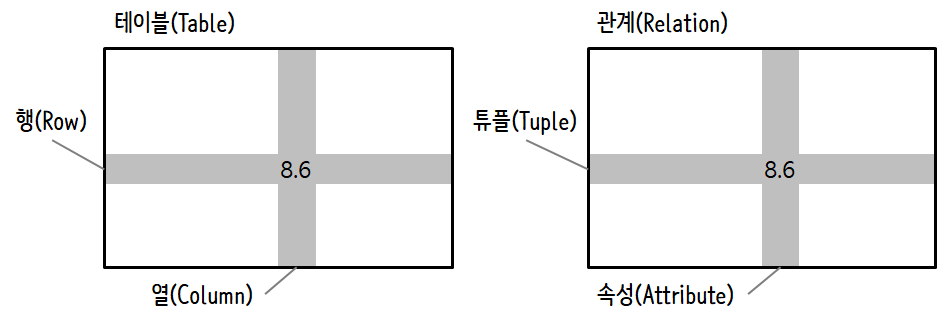
데이터베이스를 처음 보면 마치 엑셀 같은 다중 시트를 지닌 스프레드시트와 비슷하다고 생각할 수 있다. 데이터베이스에서 주요 데이터 구조물은 테이블(tables), 행(rows), 열(columns)이 된다.
그림 fig-db-concept 에 나타난 데이터베이스 개념을 설명하면, 관계형 데이터베이스에서 테이블, 행, 열은 각각 관계(relation), 튜플(tuple), 속성(attribute)으로 형식적으로 매칭된다.
2.1.2 데이터베이스 테이블 생성
데이터베이스는 R의 리스트나 파이썬의 딕셔너리와 달리 더 명확하게 정의된 구조를 요구한다. SQLite는 열에 저장되는 데이터 형식에 대해 유연성을 제공하지만, 이번 장에서는 데이터 형식을 엄격하게 적용해 MySQL과 같은 다른 관계형 데이터베이스 시스템에도 같은 개념을 적용한다.
데이터베이스에 테이블을 생성할 때, 열(column) 명칭과 각 열에 저장될 데이터 형식을 미리 정의해야 한다. 데이터베이스 소프트웨어가 각 열의 데이터 형식을 인식하면, 데이터를 저장하고 검색하는 가장 효율적인 방법을 선택할 수 있어 데이터 무결성을 보장하고, 데이터 처리 성능을 최적화하는 데 도움이 된다.
처음에 데이터 구조를 사전에 정의하는 것이 번거롭게 보일 수 있지만, 이 방법은 대용량 데이터를 다룰 때 데이터의 빠른 접근을 보장하는 큰 장점이 있다. 사전에 정의된 데이터 구조는 데이터베이스가 데이터를 효율적으로 저장하고 관리할 수 있는 기반을 통해 데이터베이스가 각 열의 데이터 유형과 구조를 알고 있기 때문에, 검색, 색인, 업데이트 등 작업을 더 빠르고 정확하게 수행하게 된다.
프로그래밍 언어를 통해 데이터베이스 파일과 데이터베이스에 두개의 열을 가진 Tracks 이름의 테이블을 생성하는 코드는 다음과 같다.
연결 (connect) 연산은 현재 디렉토리 data/music.sqlite3 파일에 저장된 데이터베이스에 “연결(connection)”한다. 파일이 존재하지 않기 때문에 CREATE TABLE 명령어를 사용해 Tracks라는 이름의 테이블을 생성한다. “연결(connection)”이라고 부르는 이유는 때때로 데이터베이스가 응용프로그램이 실행되는 서버로부터 분리된 “데이터베이스 서버(database server)”에 저장되기 때문이다. 지금 간단한 예제 파일의 경우에 데이터베이스가 로컬 파일 형태로 R 코드 마찬가지로 동일한 디렉토리에 있다.
파일을 다루는 파일 핸들(file handle)처럼 데이터베이스에 저장된 파일에 연산을 수행하기 위해서 커서(cursor)를 사용한다. cursor()를 호출하는 것은 개념적으로 텍스트 파일을 다룰 때 readLines()을 호출하는 것과 개념적으로 매우 유사하다.
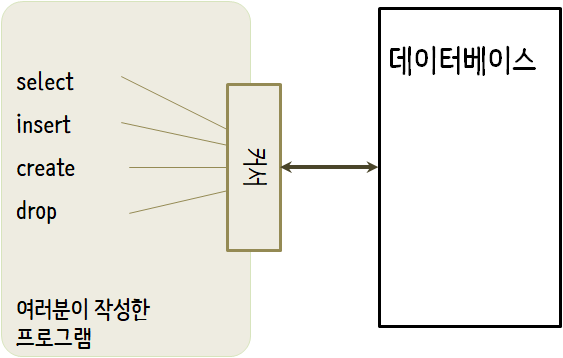
커서가 생성되면, dbGetQuery() 함수를 사용하여 데이터베이스 콘텐츠에 명령어 실행을 할 수 있다.
데이터베이스 명령어는 특별한 언어로 표현된다. 단일 데이터베이스 언어를 학습하도록 서로 다른 많은 데이터베이스 업체 사이에서 표준화되었다.
데이터베이스 언어를 SQL(Structured Query Language 구조적 질의 언어)로 부른다. SQL은 데이터베이스에 저장된 데이터를 검색하고, 추가하고, 삭제하고, 업데이트하는 데 사용된다. 상기 예제에서, 데이터베이스에 두개의 SQL 명령어를 실행했다. 관습적으로 데이터베이스 키워드는 대문자로 표기한다. 테이블명이나 열의 명칭처럼 사용자가 추가한 명령어 부분은 소문자로 표기한다.
첫 SQL 명령어는 만약 존재한다면 데이터베이스에서 Tracks 테이블을 삭제한다. 동일한 프로그램을 실행해서 오류 없이 반복적으로 Tracks 테이블을 생성하도록하는 패턴이다. DROP TABLE 명령어는 데이터베이스 테이블 및 테이블 콘텐츠 전부를 삭제하니 주의한다. (즉, “실행취소(undo)”가 없다.)
dbGetQuery(conn, 'DROP TABLE IF EXISTS Tracks ')두번째 명령어는 title 문자형 열과 plays 정수형 열을 가진 Tracks으로 명명된 테이블을 생성한다.
dbGetQuery(conn, 'CREATE TABLE Tracks (title TEXT, plays INTEGER)')이제 Tracks으로 명명된 테이블을 생성했으니, SQL INSERT 연산을 통해 테이블에 데이터를 넣을 수 있다. 다시 한번, 데이터베이스에 연결하여 커서(cursor)를 얻어 작업을 시작한다. 그리고 나서 커서를 사용해서 SQL 명령어를 수행한다.
SQL INSERT 명령어는 어느 테이블을 사용할지 특정한다. 그리고 나서 (title, plays) 포함할 필드 목록과 테이블 새로운 행에 저장될 VALUES 나열해서 신규 행을 정의를 마친다. 실제 값이 execute() 호출의 두번째 매개변수로 튜플 ('My Way', 15) 로 넘겨는 것을 표기하기 위해서 값을 물음표 (?, ?)로 명기한다.
library(RSQLite)
music_db <- "data/music.sqlite"
conn <- dbConnect(drv = SQLite(), dbname= music_db)
dbSendQuery(conn, "INSERT INTO Tracks (title, plays) VALUES ( ?, ? )",
c('Thunderstruck', 20))
dbSendQuery(conn, "INSERT INTO Tracks (title, plays) VALUES ( ?, ? )",
c('My Way', 15))
print('Tracks:')
dbGetQuery(conn, 'SELECT title, plays FROM Tracks')
dbSendQuery(conn, "DELETE FROM Tracks WHERE plays < 100")
dbDisconnect(conn)먼저 테이블에 두개 열을 삽입(INSERT)하여 데이터를 데이터베이스에 저장되도록 했다. 그리고 나서, SELECT 명령어를 사용하여 테이블에 방금 전에 삽입한 행을 불러왔다. SELECT 명령어에서 데이터를 어느 열(title, plays)에서, 어느 테이블Tracks에서 가져올지 명세한다. 프로그램 실행결과는 다음과 같다.
dbGetQuery(conn, 'SELECT title, plays FROM Tracks')
#> title plays
#> 1 Thunderstruck 20
#> 2 My Way 15프로그램 마지막에 SQL 명령어를 실행 사용해서 방금전에 생성한 행을 모두 삭제(DELETE)했기 때문에 프로그램을 반복해서 실행할 수 있다. 삭제(DELETE) 명령어는 WHERE 문을 사용하여 선택 조건을 표현할 수 있다. 따라서 명령문에 조건을 충족하는 행에만 명령문을 적용한다. 이번 예제에서 기준이 모든 행에 적용되어 테이블에 아무 것도 없게 된다. 따라서 프로그램을 반복적으로 실행할 수 있다. 삭제(DELETE)를 실행한 후에 데이터베이스에서 데이터를 완전히 제거했다.
2.2 SQL 요약
지금까지, R 예제를 통해서 SQL(Structured Query Language)을 사용했고, SQL 명령어에 대한 기본을 다루었다. 대단히 많은 데이터베이스 업체가 존재하기 때문에 호환성의 문제로 SQL(Structured Query Language)이 표준화되었다. 그래서, 여러 업체가 개발한 데이터베이스 시스템 사이에 호환하는 방식으로 커뮤니케이션 가능하다.
관계형 데이터베이스는 테이블, 행과 열로 구성된다. 열(column)은 일반적으로 텍스트, 숫자, 혹은 날짜 자료형을 갖는다. 테이블을 생성할 때, 열의 명칭과 자료형을 지정한다.
CREATE TABLE Tracks (title TEXT, plays INTEGER)테이블에 행을 삽입하기 위해서 SQL INSERT 명령어를 사용한다.
INSERT INTO Tracks (title, plays) VALUES ('My Way', 15)INSERT 문장은 테이블 이름을 명기한다. 그리고 나서 새로운 행에 놓고자 하는 열/필드 리스트를 명시한다. 그리고 나서 키워드 VALUES와 각 필드 별로 해당하는 값을 넣는다.
SQL SELECT 명령어는 데이터베이스에서 행과 열을 가져오기 위해 사용된다. SELECT 명령문은 가져오고자 하는 행과 WHERE절을 사용하여 어느 행을 가져올지 지정한다. 선택 사항으로 ORDER BY 절을 이용하여 반환되는 행을 정렬할 수도 있다.
SELECT * FROM Tracks WHERE title = 'My Way'* 을 사용하여 WHERE 절에 매칭되는 각 행의 모든 열을 데이터베이스에서 가져온다.
주목할 점은 R과 달리 SQL WHERE 절은 등식을 시험하기 위해서 두개의 등치 기호 대신에 단일 등치 기호를 사용한다. WHERE에서 인정되는 다른 논리 연산자는 <,>,<=,>=,!= 이고, 논리 표현식을 생성하는데 AND, OR, 괄호를 사용한다.
다음과 같이 반환되는 행이 필드값 중 하나에 따라 정렬할 수도 있다.
SELECT title,plays FROM Tracks ORDER BY title행을 제거하기 위해서, SQL DELETE 문장에 WHERE 절이 필요하다. WHERE 절이 어느 행을 삭제할지 결정한다.
SELECT title,plays FROM Tracks ORDER BY title다음과 같이 SQL UPDATE 문장을 사용해서 테이블에 하나 이상의 행 내에 있는 하나 이상의 열을 갱신(UPDATE)할 수 있다.
UPDATE Tracks SET plays = 16 WHERE title = 'My Way'UPDATE 문장은 먼저 테이블을 명시한다. 그리고 나서, SET 키워드 다음에 변경할 필드 리스트 와 값을 명시한다. 그리고 선택사항으로 갱신될 행을 WHERE절에 지정한다. 단일 UPDATE 문장은 WHERE절에서 매칭되는 모든 행을 갱신한다. 혹은 만약 WHERE절이 지정되지 않으면,테이블 모든 행에 대해서 갱신(UPDATE)을 한다.
네가지 기본 SQL 명령문(INSERT, SELECT, UPDATE, DELETE)은 데이터를 생성하고 유지 관리하는데 필요한 기본적인 4가지 작업을 가능케 한다.
데이터베이스 사용에 대한 주의사항
데이터를 저장하기 위해서 파이썬 딕셔너리나 일반적인 파일보다 데이터베이스를 사용하여 코드를 작성하는 것이 훨씬 복잡하다. 그래서, 만약 작성하는 응용프로그램이 실질적으로 데이터베이스 역량을 필요하지 않는다면 굳이 데이터베이스를 사용할 이유는 없다. 데이터베이스가 특히 유용한 상황은 (1) 큰 데이터셋에서 작은 임의적인 갱신이 많이 필요한 응용프로그램을 작성할 때 (2) 데이터가 너무 커서 딕셔너리에 담을 수 없고 반복적으로 정보를 검색할 때, (3) 한번 실행에서 다음 실행 때까지 데이터를 보관하고, 멈추고, 재시작하는데 매우 긴 실행 프로세스를 갖는 경우다.
많은 응용프로그램 요구사항을 충족시키기 위해서 단일 테이블로 간단한 데이터베이스를 구축할 수 있다. 하지만, 대부분의 문제는 몇개의 테이블과 서로 다른 테이블간에 행이 연결된 관계를 요구한다. 테이블 사이 연결을 만들 때, 좀더 사려깊은 설계와 데이터베이스의 역량을 가장 잘 사용할 수 있는 데이터베이스 정규화 규칙을 따르는 것이 중요하다. 데이터베이스를 사용하는 주요 동기는 처리할 데이터의 양이 많기 때문에, 데이터를 효과적으로 모델링해서 프로그램이 가능하면 빠르게 실행되게 만드는 것이 중요하다.
연습문제
객관식
-
문제: 챗GPT SQL 주요 기능은 무엇입니까?
- 보안 데이터베이스 관리 시스템 제공
- 자연 언어를 이용한 데이터베이스 쿼리 가능
- SQL 쿼리 실행 속도 향상
- 전통적인 SQL 인터페이스 완전 대체
-
문제: 다음 중 챗GPT SQL 사용의 장점은 무엇입니까?
- 데이터베이스 관리자 필요 없음
- 자연 언어를 SQL 쿼리로 해석 및 번역
- 데이터베이스 저장 공간 자동 최적화
- 데이터베이스 설계를 위한 그래픽 인터페이스 제공
-
문제: 챗GPT SQL에서 GPT(Generative Pre-trained Transformer)의 역할은 무엇입니까?
- 주요 데이터베이스 엔진 역할
- SQL 쿼리를 사전 처리하여 성능 향상
- 자연 언어를 SQL로 번역하는 중간자 역할
- 데이터베이스 보안 관리
서술형
- 문제: SQL 구문을 모르는 사용자가 특정 데이터를 데이터베이스에서 검색해야 하는 상황에서 챗GPT SQL이 어떻게 도움이 될 수 있는지 설명하시오. 자연 언어 쿼리가 SQL 쿼리로 어떻게 번역되는지 예를 들어 설명하시오.
- 문제: 비즈니스 환경에서 챗GPT SQL을 사용할 때 발생할 수 있는 잠재적 한계점이나 도전 과제에 대해 논하시오. 정확성, 쿼리의 복잡성, 기존 데이터베이스 시스템과의 통합 등의 측면에 중점을 두고 설명하시오.
Andrea, Paula, Pauline Barmby, Karl Broman, Amy Brown, Abigail Cabunoc Mayes, Daniel Chen, Liam Clark, 기타. 2017. “Software Carpentry: Databases And Sql”. Zenodo. https://doi.org/10.5281/ZENODO.838776.
Date, Chris J. 1989. A Guide to the SQL Standard. Addison-Wesley Longman Publishing Co., Inc.
Severance, Charles Russell. 2015. Python for Informatics: Exploring Information. 번역자: Kwangchun Lee. Korean Edition. CreateSpace Independent Publishing Platform. http://www.pythonlearn.com.
이광춘, 와/과 신종화. 2023. 챗GPT 유닉스쉘. "한국 R 사용자회".