library(tidyverse)
library(duckdb)
crime_csv <- fs::dir_ls("data/crime/")
crime_raw <- crime_csv |>
enframe(value = "filepath") |>
select(-name) |>
mutate(data = map(filepath, read_csv)) |>
mutate(year = str_extract(filepath, "\\d{4}")) |>
select(year, data)
crime_tbl <- crime_raw |>
unnest(data) |>
janitor::clean_names()
crime_tbl |>
glimpse()
#> Rows: 707,153
#> Columns: 23
#> $ year <chr> "2021", "2021", "2021", "2021", "2021", "2021", "…
#> $ id <dbl> 12342615, 26262, 13209581, 13209369, 12374520, 13…
#> $ case_number <chr> "JE202211", "JE366265", "JG422927", "JG422777", "…
#> $ date <chr> "04/17/2021 03:20:00 PM", "09/08/2021 04:45:00 PM…
#> $ block <chr> "081XX S PRAIRIE AVE", "047XX W HARRISON ST", "01…
#> $ iucr <chr> "0325", "0110", "1563", "1153", "0486", "1153", "…
#> $ primary_type <chr> "ROBBERY", "HOMICIDE", "SEX OFFENSE", "DECEPTIVE …
#> $ description <chr> "VEHICULAR HIJACKING", "FIRST DEGREE MURDER", "CR…
#> $ location_description <chr> "RESIDENCE", "CAR WASH", "APARTMENT", "RESIDENCE"…
#> $ arrest <lgl> TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FA…
#> $ domestic <lgl> FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, F…
#> $ beat <chr> "0631", "1131", "0411", "0915", "1123", "1412", "…
#> $ district <chr> "006", "011", "004", "009", "011", "014", "017", …
#> $ ward <dbl> 6, 24, 8, 11, 28, 35, 45, 25, 25, 20, 9, 44, 28, …
#> $ community_area <dbl> 44, 25, 45, 60, 27, 21, 16, 31, 31, 40, 73, 6, 28…
#> $ fbi_code <chr> "03", "01A", "17", "11", "08B", "11", "11", "17",…
#> $ x_coordinate <dbl> 1179448, 1144907, NA, NA, 1154131, NA, NA, NA, NA…
#> $ y_coordinate <dbl> 1851073, 1896933, NA, NA, 1900784, NA, NA, NA, NA…
#> $ year_2 <dbl> 2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021, 2…
#> $ updated_on <chr> "09/14/2023 03:41:59 PM", "09/14/2023 03:41:59 PM…
#> $ latitude <dbl> 41.74663, 41.87319, NA, NA, 41.88358, NA, NA, NA,…
#> $ longitude <dbl> -87.61803, -87.74345, NA, NA, -87.70948, NA, NA, …
#> $ location <chr> "(41.746626309, -87.618031954)", "(41.873191445, …9 생산성 향상 전략
데이터베이스에 존재하는 데이터를 활용해 분석 및 모델 개발 작업을 수행할 때 생산성을 높일 수 있는 방법은 여러 가지가 있다. 대표적으로 분석에 특화된 데이터베이스를 사용하는 것은 대용량 데이터를 빠르게 처리함으로써 기계시간(Machine time)을 줄여 생산성을 높이는 것이고 다른 한가지 방법은 SQL 쿼리를 직접 작성하지 않고 사람시간(Human time)을 줄여 생산성을 높일 수 있는 dplyr 데이터 문법을 활용하는 방법이 있다.
9.1 DuckDB
SQLite3(Kreibich, 2010)와 DuckDB(Raasveldt & Mühleisen, 2019)를 각각 OLTP(Online Transaction Processing)와 OLAP(Online Analytical Processing)의 관점에서 볼 때, 다른 특성과 사용 사례를 가진다. SQLite3는 OLTP에 더 적합한 데이터베이스로, 애플리케이션의 거래 처리를 위한 운영 데이터 관리에 주로 사용된다. 이는 빠른 쓰기와 읽기, 낮은 지연 시간, 높은 트랜잭션 보장을 필요로 하는 환경에 적합하게 설계되었다. SQLite는 가벼운 구조와 서버리스 아키텍처 덕분에 임베디드 시스템, 모바일 애플리케이션, 소규모 웹 애플리케이션에서 데이터 저장 및 관리에 자주 사용된다.
반면에 DuckDB는 OLAP에 더 적합하며, 데이터 분석 작업에 최적화된 데이터베이스다. 큰 규모의 데이터셋에 대한 복잡한 쿼리와 데이터 분석을 빠르게 처리할 수 있다. DuckDB는 벡터화 쿼리 처리와 멀티 코어 시스템에서의 병렬 처리 능력을 갖추고 있어, 대용량 데이터 분석, 보고서 생성, 데이터 마이닝과 같은 작업에서 뛰어난 성능을 발휘한다. 이러한 특성 때문에 DuckDB는 주로 데이터 과학자들과 분석가들에 의해 사용되며, 빅데이터의 효율적인 처리와 복잡한 분석 쿼리를 신속하게 실행할 수 있는 도구로 인정받고 있다.

DuckDB는 “SQLite for analytics”라는 슬로건으로 알려진, 분석을 위한 임베디드 관계형 SQL 데이터베이스 라이브러리다. DuckDB는 설치가 쉽고, 별도의 설정 없이 메모리 상에서 데이터를 처리하거나 단일 파일 데이터베이스로 데이터를 저장할 수 있다.
SQLite와는 달리 DuckDB는 컬럼 지향적인 테이블 데이터 모델을 사용한다. 이는 R과 같은 데이터 분석 언어의 데이터 모델과 유사하며, 대규모의 데이터를 빠르고 효율적으로 처리하는 데 유리하다.
DuckDB의 가장 인상적인 특징 중 하나는 R과 Python과의 통합이다. R 사용자는 install.packages("duckdb") 명령을 통해 쉽게 설치할 수 있으며, Python 사용자도 마찬가지로 쉽게 설치 및 사용이 가능하다. 이로 인해 데이터 분석가와 개발자 모두에게 매력적인 선택이 될 수 있다.
9.2 시카고 범죄 데이터
DuckDB는 대규모 데이터셋을 분석하기에 적합한 데이터베이스이며, 이는 시카고 범죄 데이터에도 해당된다. DuckDB의 벡터화 쿼리 처리 및 멀티 코어 시스템에서의 병렬 처리 능력은 대용량 데이터에 대한 복잡한 쿼리를 신속하고 효율적으로 처리할 수 있게 한다. 시카고 범죄 데이터는 범죄 유형, 위치, 날짜, 체포 여부 등의 다양한 정보를 포함하고 있어, 이를 통해 시카고의 범죄 패턴과 추세를 이해하는 데 유용하다. 공공 안전 분석, 연구, 정책 개발 등에서 널리 사용되는 이 데이터는 DuckDB를 통해 한정된 메모리를 넘어서는 데이터를 효율적으로 처리하는 데 적합하다. 2021년부터 2023년까지 데이터를 웹페이지에서 다운로드 받아 DuckDB를 활용하여 분석해보자.
R의 tidyverse와 duckdb 라이브러리를 사용하여 범죄 기록 데이터을 파악하는 과정은 다음과 같다. 먼저 지정된 디렉토리(data/crime/) 안의 모든 파일을 파악하고, 각 CSV 파일을 반복적으로 읽어 데이터와 파일 이름에서 추출한 연도를 저장한다. 데이터를 crime_tbl이라는 단일 데이터프레임으로 결합한 후, unnest 함수를 사용하여 이 중첩된 데이터 구조를 펼치고, janitor::clean_names() 함수로 열 이름을 표준화한다. 마지막으로, glimpse()를 호출하여 정리된 데이터를 파악한다.
crime_type_gg <- crime_tbl |>
count(primary_type, sort = TRUE) |>
head(10) |>
ggplot(aes(x = fct_reorder(primary_type, n), y = n)) +
geom_col(width = 0.5) +
coord_flip() +
labs(x = "범죄 유형", y = "범죄 건수", title = "시카고 범죄 유형별 건수") +
scale_y_continuous(labels = scales::comma)
ragg::agg_jpeg("images/chicago_crime_type.jpeg",
width = 10, height = 7, units = "in", res = 600)
crime_type_gg
dev.off()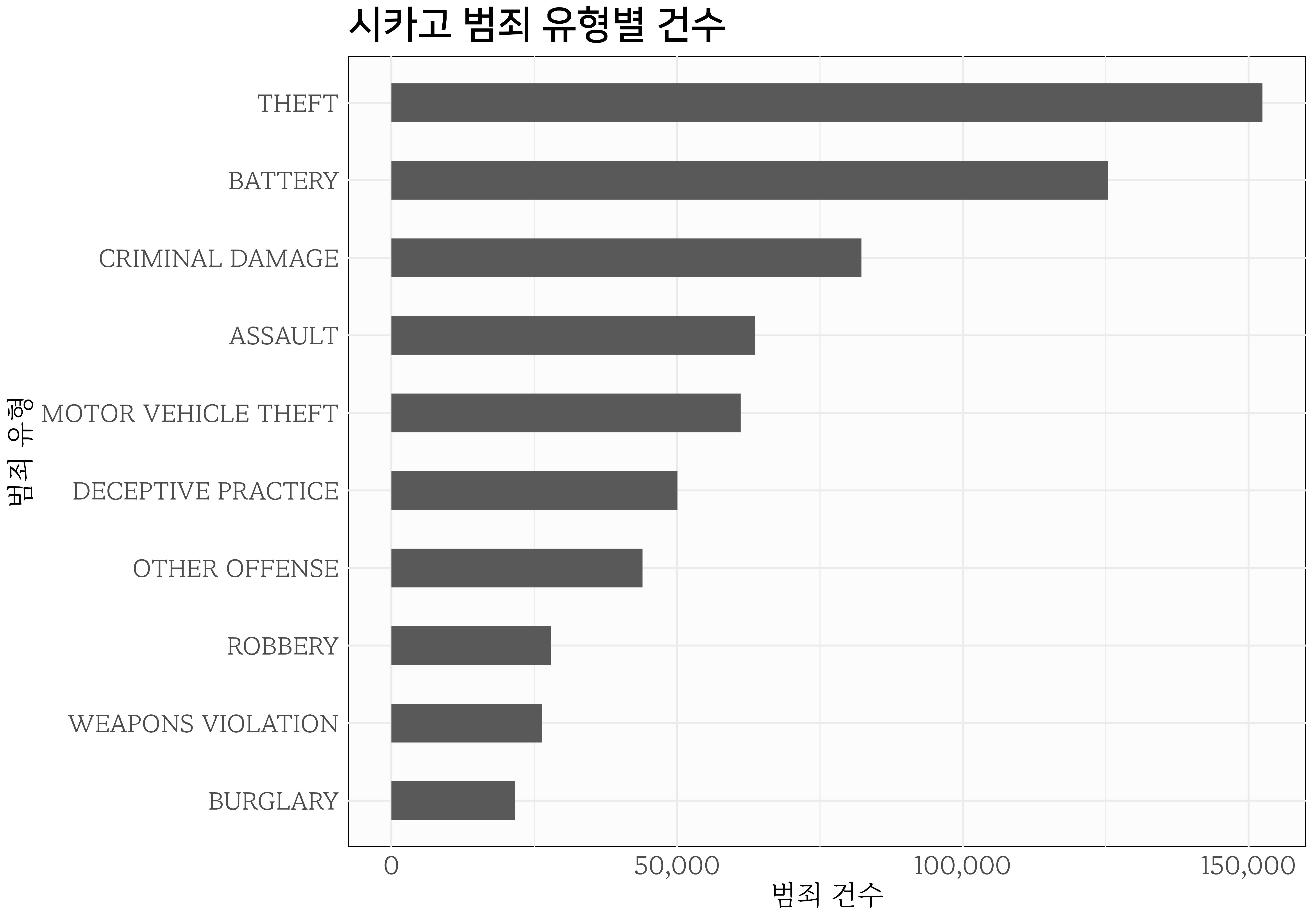
그림 9.1 는 시카고 범죄 데이터셋(crime_tbl)에서 가장 흔한 범죄 유형 상위 10개를 추려내고, 막대 그래프로 시각화하는 과정을 통해 작성되었다. count 함수를 사용해 각 범죄 유형(primary_type)별로 발생 횟수를 계산하고, 내림차순으로 정렬하고, 상위 10개 범죄 유형을 선택하여 ggplot으로 시각화한다. 그래프에 범죄 유형을 x축에, 발생 횟수를 y축에 배치하고, geom_col을 사용해 막대 그래프를 생성하고, coord_flip 함수로 축을 뒤집어 가독성을 높이고, labs 함수로 축과 차트 제목을 설정한 후, scale_y_continuous 함수로 y축 레이블에 쉼표를 추가해 숫자를 보기 쉽게 한다.
9.2.1 DuckDB 연결
DuckDB는 Analytical SQLite라는 별명을 갖고 있다. SQLite가 OLTP 데이터베이스라면, DuckDB OLAP 데이터베이스라고 볼 수 있다.
DuckDB에 연결하고, R 데이터프레임(crime_tbl)을 DuckDB 데이터베이스에 테이블로 저장한 후, 저장된 테이블 목록을 조회하고, crime_tbl 테이블 내의 총 범죄 수를 쿼리하는 과정이 다음 코드에 담겨있다.
con_dd <- duckdb::dbConnect(duckdb::duckdb())
duckdb::dbWriteTable(con_dd, "crime_tbl", crime_tbl, overwrite = TRUE)
duckdb::dbListTables(con_dd)
dbGetQuery(con_dd, "SELECT COUNT(*) AS '범죄수' FROM crime_tbl")
#> 범죄수
#> 1 707153대용량 처리에 강점이 있는 DuckDB의 유용성을 부각시키기 위해 R에서 특정 작업의 실행 시간을 측정하기 위해 설계된 사용자 정의 함수 time를 제작한다. 이 함수는 system.time()을 사용하여 함수 호출에 소요된 시간을 측정하는데 무명함수와 결합하여 실행시간 측정을 간결하게 할 수 있다. time함수를 두 가지 DuckDB 작업, 데이터베이스에 테이블 쓰기와 테이블의 레코드 수를 쿼리하는 작업에 적용하여, 쓰기작업은 duckdb::dbWriteTable으로 약 0.71초의 실행 시간이 걸리고 쿼리작업은 dbGetQuery로 crime_tbl 테이블 레코드 수를 세는 것은 거의 즉시(0초) 완료된다.
time <- function(call) {
print(system.time(call())[[1]])
}
time(\() duckdb::dbWriteTable(con_dd, "crime_tbl", crime_tbl, overwrite = TRUE))
#> [1] 0.71
time(\() dbGetQuery(con_dd, "SELECT COUNT(*) AS '범죄수' FROM crime_tbl"))
#> [1] 0R DuckDB와 SQLite 데이터베이스를 사용한 두 가지 상황에서 데이터를 쓰고 쿼리하는 데 걸리는 시간을 비교한다. DuckDB를 사용할 때, crime_tbl 테이블을 작성하는 데 약 0.71초가 걸렸다. 반면, SQLite를 사용할 때는 같은 작업에 1.78초가 소요되었다. 두 데이터베이스에서 crime_tbl 테이블에서 총 범죄 수를 쿼리하는 작업은 모두 0초가 걸렸다. DuckDB가 SQLite보다 데이터 쓰기 작업에서 더 빠르다는 것을 보여주며, 두 데이터베이스 모두 쿼리 작업에서는 유사한 효율성을 보인다.
데이터베이스에 저장된 쿼리문을 작성하기 전에 테이블 구조를 이해하는 데 중요하다. DBI::dbGetQuery 함수를 사용하여 DuckDB 연결(con_dd)에서 ‘duckdb_tables’ 테이블 내용을 조회한다. 이 테이블은 데이터베이스 내의 테이블 구조와 관련된 정보를 담고 있다. select(sql)을 통해 특정 열을 선택하여 스키마 정보를 더 자세히 살펴볼 수 있다.
crime_schema <- DBI::dbGetQuery(con_dd, 'SELECT * FROM duckdb_tables;')
crime_schema |>
select(sql)
#> sql
#> 1 CREATE TABLE crime_tbl("year" VARCHAR, id DOUBLE, case_number VARCHAR, date VARCHAR, block VARCHAR, iucr VARCHAR, primary_type VARCHAR, description VARCHAR, location_description VARCHAR, arrest BOOLEAN, domestic BOOLEAN, beat VARCHAR, district VARCHAR, ward DOUBLE, community_area DOUBLE, fbi_code VARCHAR, x_coordinate DOUBLE, y_coordinate DOUBLE, year_2 DOUBLE, updated_on VARCHAR, latitude DOUBLE, longitude DOUBLE, "location" VARCHAR);9.2.2 성능비교
난이도 있는 SQL 쿼리문을 작성하여 OLTP Sqlite3와 DuckDB의 성능을 비교한다. 작성된 SQL 쿼리는 시카고 범죄 데이터베이스에서 2021년부터 2023년까지 가장 흔한 범죄 유형 상위 5가지를 찾고, 이들의 평균 발생 위치, 체포 건수, 연도별 발생 횟수를 파악하는 것이다.
-
WHERE절: 범죄 발생 연도를 2021년부터 2023년 사이로 범위를 제한한다. -
GROUP BY절: 결과를 범죄 유형(primary_type)과 발생 연도(year)별로 그룹화한다. -
ROUND(AVG(latitude), 5)및ROUND(AVG(longitude), 5): 각 범죄 유형의 평균 위도와 경도를 계산하여 범죄가 일반적으로 발생하는 위치를 파악한다. 평균은 소수점 다섯째 자리까지 반올림된다. -
SUM(CASE WHEN arrest THEN 1 ELSE 0 END) AS total_arrests: 각 범죄 유형별로 발생한 총 체포 건수를 합산하고,arrest가 참일 때마다 1을 더하는 방식으로 계산한다. -
COUNT(*) AS total_crimes: 각 범죄 유형별로 발생한 총 범죄 건수를 계산한다. -
HAVING COUNT(*) > 100: 100건 이상 발생한 범죄 유형만을 필터링하여 신뢰성 있는 데이터만을 대상으로 한다. -
ORDER BY total_crimes DESC, primary_type: 총 범죄 건수가 많은 순으로 결과를 정렬하고, 동일한 건수일 경우 범죄 유형(primary_type)에 따라 정렬한다. -
LIMIT 5: 결과를 상위 5가지 범죄 유형으로 한정한다.
complex_query <- "
SELECT
primary_type,
ROUND(AVG(latitude), 5) AS avg_latitude,
ROUND(AVG(longitude), 5) AS avg_longitude,
SUM(CASE WHEN arrest THEN 1 ELSE 0 END) AS total_arrests,
COUNT(*) AS total_crimes,
year
FROM
crime_tbl
WHERE
year >= '2021' AND year <= '2023'
GROUP BY
primary_type, year
HAVING
COUNT(*) > 100
ORDER BY
total_crimes DESC, primary_type
LIMIT 5;
"
dbGetQuery(con_dd, complex_query)
#> primary_type avg_latitude avg_longitude total_arrests total_crimes year
#> 1 THEFT 41.86707 -87.66762 2738 56770 2023
#> 2 THEFT 41.86597 -87.66691 2019 54853 2022
#> 3 BATTERY 41.83902 -87.66873 6726 43958 2023
#> 4 BATTERY 41.83833 -87.66838 5932 40924 2022
#> 5 THEFT 41.86354 -87.66865 1552 40806 2021DuckDB와 SQLite3 데이터베이스에서 동일한 복잡한 쿼리(complex_query)를 실행하여 수행 시간을 비교한다. DuckDB에서 쿼리를 실행할 때 걸리는 시간은 약 0.34초이며, SQLite3에서는 약 0.58초가 걸린다. DuckDB가 SQLite3에 비해 해당 쿼리를 더 빠르게 처리할 수 있음을 보여준다.
9.3 SQL 대신 dplyr
다음 예제((Lewis, 2021))는 SQL이 데이터 분석의 유일한 해결책이 아님을 보여준다. nycflights13 패키지 flights 데이터셋을 사용하여 “출발지 공항별 상위 3개 목적지”를 찾는 세 가지 다른 접근법을 제시한다. SQL 쿼리를 사용하는 방법은 DuckDB와 연결하여 복잡한 쿼리를 실행한다. 반면, dplyr를 사용하는 방법은 SQL보다 직관적이고 간결한 코드로 동일한 결과를 제공한다. 마지막으로, Base R 문법을 사용하는 방법은 flights 데이터를 분할하고 테이블 함수를 적용하여 목적지를 추출한다.
3가지 방법은 모두 동일한 결과를 제공하지만 코드 작성 시간과 인지적 부하를 생각하면 데이터 문법(grammar of data)을 충실히 구현하고 있는 dplyr 동사를 사용하는 것도 추천할 만하다.
- SQL 쿼리를 사용하는 방법
library(duckdb)
data("flights", package = "nycflights13")
flight_con <- dbConnect(duckdb())
duckdb_register(flight_con, "flights", flights)
dbGetQuery(flight_con,
"SELECT origin, dest
FROM (SELECT origin, dest, n
FROM (SELECT origin, dest, n, RANK() OVER (
PARTITION BY origin ORDER BY n DESC) AS h
FROM (SELECT origin, dest, COUNT(*) AS n
FROM flights
GROUP BY origin, dest
) AS curly
) AS moe
WHERE (h <= 3)
) AS shemp ORDER BY origin;")
#> origin dest
#> 1 EWR ORD
#> 2 EWR BOS
#> 3 EWR SFO
#> 4 JFK LAX
#> 5 JFK SFO
#> 6 JFK BOS
#> 7 LGA ATL
#> 8 LGA ORD
#> 9 LGA CLT
dbDisconnect(flight_con, shutdown=TRUE) -
dplyr문법
flights |>
group_by(origin) |>
count(dest, sort = TRUE) |>
slice_head(n = 3) |>
select(origin, dest)
#> # A tibble: 9 × 2
#> # Groups: origin [3]
#> origin dest
#> <chr> <chr>
#> 1 EWR ORD
#> 2 EWR BOS
#> 3 EWR SFO
#> 4 JFK LAX
#> 5 JFK SFO
#> 6 JFK BOS
#> 7 LGA ATL
#> 8 LGA ORD
#> 9 LGA CLT - Base R 문법
9.4 dplyr 동사 데이터베이스 작업
NoSQL과 빅데이터가 주목을 받고 있지만, 데이터 분석을 하는 입장에서는 여전히 SQL의 중요성이 크다. SQL에 대한 이해는 데이터 조작의 기본을 다지는 데 필수적이며, 이를 바탕으로 DBI 패키지를 사용해 dplyr(Broatch 기타, 2019)과 연결하여 활용하는 방법을 살펴볼 수 있다.
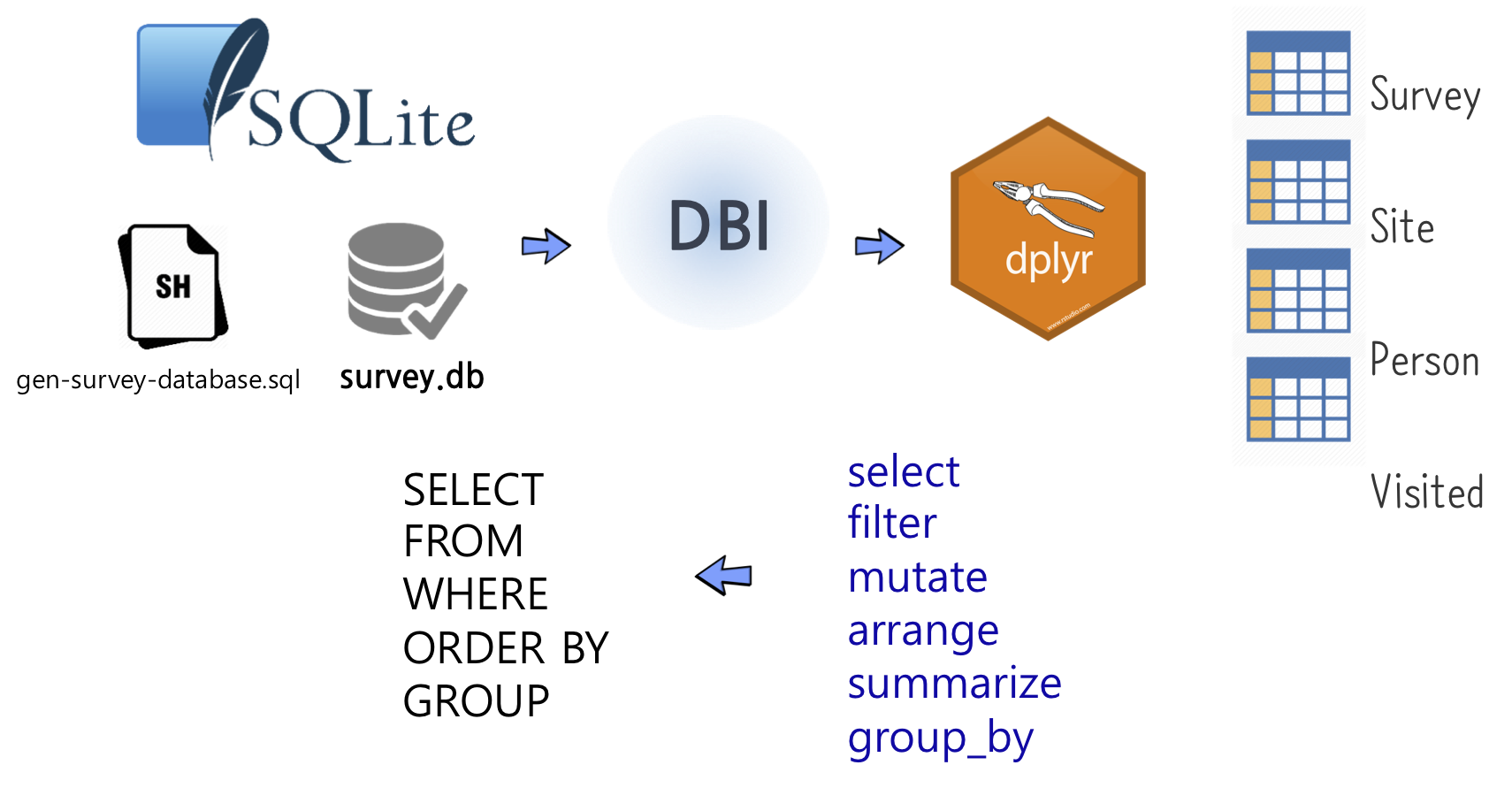
R 개발자들은 데이터 분석을 할 때 dplyr을 사용하고, 데이터베이스 작업을 할 때는 SQL을 사용하는 것이 일반적인 작업 흐름이었다. 이렇게 두 가지 다른 도구를 사용하는 것은 동일한 작업을 중복해서 수행한다는 불편함을 가져왔다. 그러나 dplyr을 다양한 데이터베이스 시스템에 DBI와 odbc와 연결하면 문제를 해결할 수 있다. 즉, dplyr 동사를 직접 사용하여 SQL 작업을 수행할 수 있어 dplyr 동사를 데이터베이스에 직접 던져서 작업을 수행할 수 있는 중간 통역이 제공되어 보다 효율적으로 작업을 진행할 수 있게 된다. 자료를 원하는 방향으로 처리하기 위해서는 다음과 같은 다양한 기본적인 자료 처리 방법을 조합하여 사용한다.
- 데이터 선택하기
- 정렬과 중복 제거하기
- 필터링(filtering)
- 새로운 값 계산하기
- 결측 데이터 (Missing Data)
- 집합 (Aggregation)
- 데이터 조합하기 (Combining Data)
# 칼럼과 행 선택
SELECT 칼럼명1, 칼럼명2....칼럼명N
FROM 테이블명
WHERE 조건;
# 그룹에 따른 정렬 및 총계(aggregation)
SELECT SUM(칼럼명)
FROM 테이블명
WHERE 조건
ORDER BY 칼럼명 {오름차순|내림차순};
GROUP BY 칼럼명;9.4.1 데이터베이스 연결
가장 먼저 앞에서 생성한 sqlite3 데이터베이스에 R과 연결시킨다. 그리고 연결된 데이터베이스에 들어있는 테이블을 살펴본다.
9.4.2 SQL 쿼리 전송
dbGetQuery 명령어를 통해 연결된 con을 통해 데이터베이스에 질의문(query)를 직접 전송하여 실행시킬 수 있다.
# 2. SQL 활용 -----------------------
dbGetQuery(survey_con, 'SELECT * FROM Person LIMIT 5')
#> id personal family
#> 1 dyer William Dyer
#> 2 pb Frank Pabodie
#> 3 lake Anderson Lake
#> 4 roe Valentina Roerich
#> 5 danforth Frank Danforth9.4.3 dplyr 동사 활용
tbl 함수로 con 으로 연결된 데이터베이스의 특정 테이블 “Survey”를 뽑아낸다.
# 3. dplyr 방식 -----------------------
survey_df <- tbl(survey_con, "Survey")
head(survey_df)
#> # Source: SQL [6 x 4]
#> # Database: sqlite 3.41.2 [D:\tcs\gpt-sql\data\survey.db]
#> taken person quant reading
#> <int> <chr> <chr> <dbl>
#> 1 619 dyer rad 9.82
#> 2 619 dyer sal 0.13
#> 3 622 dyer rad 7.8
#> 4 622 dyer sal 0.09
#> 5 734 pb rad 8.41
#> 6 734 lake sal 0.05
노트느긋한 계산법
데이터베이스를 다룰 때, dplyr은 가능한 느긋(laziness)하게 동작한다.
- 명시적으로 요청하지 않는 한, 데이터를 R 환경으로 바로 가져오지 않는다.
- 가능한 마지막 순간까지 작업을 지연시킨다 - 작업하고 싶은 모든 것을 모아 한 단계로 데이터베이스로 보낸다.
9.4.4 데이터프레임 변환
tbl 함수로 con 으로 연결된 데이터베이스의 특정 테이블 “Survey”를 뽑아낸 상태는 아직 R에서 작업이 가능한 데이터프레임이 아니라 collect 함수를 활용해서 데이터프레임으로 변환시켜 후속 작업을 R에서 실행한다.

9.4.5 SQL 변환 과정 살펴보기
show_query 함수를 사용해서 dplyr 동사가 SQL 질의문으로 변환된 상황을 살펴볼 수도 있다.
# 5. 내부 SQL 변환과정 살펴보기 --------------
survey_df |>
filter(quant == "sal") |>
show_query()
#> <SQL>
#> SELECT *
#> FROM `Survey`
#> WHERE (`quant` = 'sal')9.4.6 데이터베이스 연결 끊기
데이터베이스는 혼자 사용하는 것이 아니라 사용하지 않는 경우 필히 연결시켜 놓은 con을 필히 끊어 놓는다.
# 7. 연결 끊기 -----------------------
dbDisconnect(survey_con)연습문제
객관식
-
문제: DuckDB는 어떤 유형의 데이터 처리에 특화되어 있습니까?
- 온라인 트랜잭션 처리 (OLTP)
- 온라인 분석 처리 (OLAP)
- 데이터 스트리밍
- 실시간 데이터 처리
-
문제: PostgreSQL과 DuckDB를 비교했을 때, 어느 데이터베이스가 분석 쿼리에 대해 더 빠른 읽기 성능을 제공합니까?
- DuckDB
- PostgreSQL
- 두 데이터베이스가 유사한 성능을 제공
- 성능은 사용 사례에 따라 다름
-
문제: PostgreSQL은 어떤 종류의 데이터베이스로 가장 잘 알려져 있습니까?
- OLTP 데이터베이스
- OLAP 데이터베이스
- NoSQL 데이터베이스
- 그래프 데이터베이스
서술형
- 문제: DuckDB와 PostgreSQL의 주요 차이점과 각각의 데이터베이스가 적합한 사용 사례에 대해 설명하시오.
- 문제: 데이터 분석에 DuckDB를 사용하는 장점에 대해 설명하시오.